
437
28
ACache‐AwareHybridSorter
Manny Ko
DreamWorks Animation
Sorting is one of the most basic building blocks of many algorithms. In graphics,
a sort is commonly used for depth-sorting for transparency [Patney et al. 2010]
or
to get better Z-cull performance. It is a key part of collision detection [Lin 2000].
Dynamic state sorting is critical for minimizing state changes in a scene graph
renderer. Recently, Garanzha and Loop [2010] demonstrated that it is highly
profitable to buffer and sort rays within a ray tracer to extract better coherency,
which is key to high GPU performance. Ray sorting is one example of a well-
known practice in scientific computing, where parallel sorts are used to handle
irregular communication patterns and workloads.
Well, can’t we just use the standard template library (STL) sort? We can, but
we can also do better. How about up to six times better? Quicksort is probably
the best comparison-based sort and, on average, works well. However, its worst-
case behavior can be
2
On
, and its memory access pattern is not very cache-
friendly. Radix sort is the only practical
On sort out there (see the appendix for
a quick overview of radix sort). Its memory access pattern during the first pass,
where we are building counts, is very cache-friendly. However, the final output
phase uses random scatter writes. Is there a way for us to use radix sort but min-
imize its weaknesses?
Modern parallel external sort (e.g., AlphaSort [Nyberg et al. 1995]) almost
always uses a two-pass approach of in-memory sort followed by a merge. Each
item only has to be read from disk twice. More importantly, the merge phase is
very I/O friendly since the access is purely sequential. Substitute “disk” with
“main memory” and “memory” with “cache,” and the same considerations ap-
ply—we want to minimize reads from main memory and also love the sequential
access pattern of the merge phase.
438 28.ACache‐AwareHybridSorter
Hence, if we partition the input into substreams that fit into the cache and
sort each of them with radix sort, then the scatter writes now hit the cache, and
our main concern is addressed. One can substitute shared memory for cache in
the above statement and apply it to a GPU-based sort. Besides the scattering con-
cern, substreams also enable us to keep the output of each pass in cache so that it
is ready for the next pass without hitting main memory excessively.
Our variant of radix sort first makes one pass through the input and accumu-
lates four sets of counters, one for each radix digit. We are using radix-256,
which means each digit is one byte. Next, we compute the prefix sums of the
counters, giving us the final positions for each item. Finally, we make several
passes through the input, one for each digit, and scatter the items into the correct
order. The output of the scattering pass becomes the input to the next pass.
Radix sort was originally developed for integers since it relies on extracting
parts of it using bit operations. Applying it directly to floating-point values works
fine for positive numbers, but for negative numbers, the results are sorted in the
wrong order. One common approach is to treat the most significant radix digit as
a special case [Terdiman 2000]. However, that involves a test in the inner loop
that we would like to avoid. A nice bit hack by [Herf 2001] solves this nasty
problem for radix sort.
For efficient merging, we use an oldie but goodie called the
loser tree. It is a
lot more efficient than the common heap-based merger.
At the end we get a sorter that is two to six times faster than STL and has
stable performance across a wide range of datasets and platforms.
28.1StreamSplitting
This chapter discusses a class using Wright’s [2006] sample as a base to obtain
the cache and translation lookaside buffer description of various Intel and AMD
CPUs. The basic code is very simple since it uses the
cpuid instruction, as shown
in Listing 28.1. Some of the detailed information is not available directly from
the returned results. In the sample code on the website, a lot of the details based
on Intel’s application notes are manually entered. They are not needed for the
purpose of the sample code, which only requires the size of the caches.
U32 CPU::CacheSize(U32 cachelevel)
{
U32 ax, bx, cx, dx;
cx = cachelevel;

28.1StreamSplitting 439
cpuid(kCacheParameters, &ax, &bx, &cx, &dx);
if ((ax & 0x1F) == 0) return (0);
U32 sets = cx + 1;
U32 linesize = bx & 0x0FFF; // [11:0]
U32 partitions = (bx >> 12) & 0x03FF; // [21:12]
U32 ways = (bx >> 22) & 0x03FF; // [31:22]
return ((ways + 1) * (partitions + 1) * (linesize + 1) * sets);
}
static void GetCacheInfo(U32 *cacheLineSize)
{
U32 ax, bx, cx, dx;
cpuid(kProcessorInfo, &ax, &bx, &cx, &dx);
*cacheLineSize = ((bx >> 8) & 0xFF) * 8; // Intel only
// For AMD Microprocessors, the data cache line size is in CL and
// the instr cache line size is in DL after calling cpuid function
// 0x80000005.
U32 csize0 = CacheSize(0); // L0
U32 csize1 = CacheSize(1); // L1
U32 csize2 = CacheSize(2); // L2
U32 csize3 = CacheSize(3); // L3
}
Listing 28.1. Returns the actual cache sizes on the CPU.
To determine our substream size, we have to consider the critical step for our
radix sorter, the scatter phase. To perform scattering, the code has to access the
count table using the next input radix digit to determine where to write the item
to in the output buffer. The input stream access is sequential, which is good for
the prefetcher and for cache hits. The count table and output buffer writes are
both random accesses using indexing, which means they should both be in the
cache. This is very important since we need to make several passes, one for each
radix digit. If we are targeting the L1 cache, then we should reserve space for the
counters (1–2 kB) and local temporaries (about four to eight cache lines). If we
440 28.ACache‐AwareHybridSorter
are targeting the L2 cache, then we might have to reserve a little more space in
L2 since the set-associative mechanism is not perfect.
For the counting phase, the only critical data that should be in the cache is
the counts table. Our use of radix-256 implies a table size of
256 *
sizeof(int)
, which is 1 kB or 2 kB. For a GPU-based sort that has limited
shared memory, one might consider a lower radix and a few extra passes.
28.2SubstreamSorting
At first glance, once we have partitioned the input, we can just use the “best” se-
rial sort within each partition. Our interest is in first developing a good usable
serial algorithm that is well suited for parallel usage. In a parallel context, we
would like each thread to finish in roughly the same time given a substream of
identical length. Keep in mind that one thread can stall the entire process since
other threads must wait for it to finish before the merge phase can commence.
Quicksort’s worst-case behavior can be
2
On
and is data dependent. Radix sort
is
On, and its run time is not dependent on the data.
Our radix sorter is a highly optimized descendent of Herf’s code, which is
built on top of Terdiman’s. It is a radix-256 least-significant-bit sort. The main
difficulty with using radix sort on game data is handling floating-point values.
An IEEE floating-point value uses a sign-exponent-mantissa format. The sign bit
makes all negative numbers appear to be larger than positive ones. For example,
2.0 is
0x40000000, and 2.0
is 0xC0000000 in hexadecimal, while 4.0
is
0xC0800000, which implies 4.0 2.0 2.0
, just the opposite of what we want.
The key idea is Herf’s rule for massaging floats:
1. Always invert the sign bit.
2. If the sign bit was set, then invert the exponent and mantissa too.
Rule 1 turns 2.0 into
0xC0000000, 2.0
into 0x40000000, and 4.0
into
0x40800000, which implies 2.0 4.0 2.0 . This is better, but still wrong. Ap-
plying rule 2 turns 2.0
into 0x3FFFFFFF and 4.0
into 0x3F7FFFFF, giving
2.0 2.0 4.0 , which is the result we want. This bit hack has great implica-
tions for radix sort since we can now treat all the digits the same. Interested read-
ers can compare Terdiman’s and Herf’s code to see how much this simple hack
helps to simplify the code.
The code in Listing 28.2 is taken from Herf’s webpage. Like Herf’s code, we
build all four histograms in one pass. If you plan on sorting a large number of
items and you are running on the CPU, you can consider Herf’s radix-2048 opti-
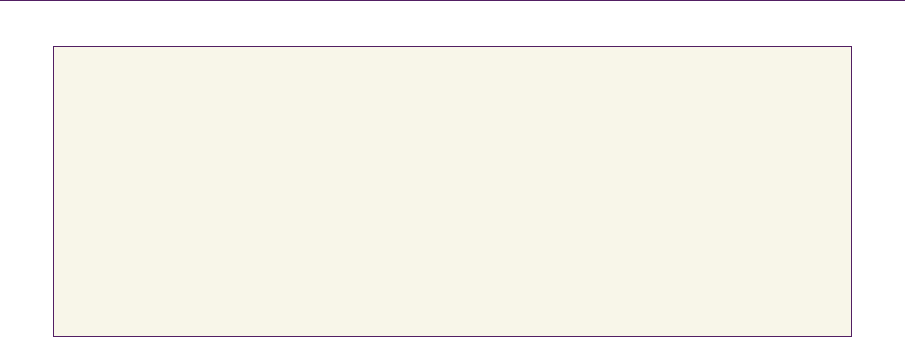
28.2SubstreamSorting 441
static inline U32 FloatFlip(U32 f)
{
U32 mask = -int32(f >> 31) | 0x80000000;
return (f ^ mask);
}
static inline U32 IFloatFlip(U32 f)
{
U32 mask = ((f >> 31) - 1) | 0x80000000;
return (f ^ mask);
};
Listing 28.2. Herf’s original bit hack for floats and its inverse (IFloatFlip).
mization, which reduces the number of scattering passes from four to three. The
histogram table is bigger since
11
22kB
, and you need three of them. Herf re-
ported a speedup of 40 percent. Keep in mind that the higher radix demands more
L1 cache and increases the fixed overhead of the sorter. Our substream split
strategy reduces the benefit of a higher radix since we strive to keep the output of
each pass within the cache.
One small but important optimization for
FloatFlip is to utilize the natural
sign extension while shifting signed numbers. Instead of the following line:
U32 mask = -int32(f >> 31) | 0x80000000;
we can write
int32 mask = (int32(f) >> 31) | 0x80000000;
The right shift smears the sign bit into a 32-bit mask that is used to flip the input
if the sign bit is set, hence implementing rule 2.
Strictly speaking, this behavior is
not guaranteed by the C++ standard. Practically all compilers we are likely to
encounter during game development do the right thing. Please refer to the chapter
“Bit Hacks for Games” in this book for more details. The same idea can be ap-
plied to
IFloatFlip, as follows:
static inline void IFloatFlip(int32& f)
{
f ^= (int32(f ^ 0x80000000) >> 31) | 0x80000000;
}
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.