
Chapter 12. OTP Behaviors
In previous chapters, we introduced patterns that recur when you program using the Erlang concurrency model. We discussed functionality common to concurrent systems, and you saw that processes will handle very different tasks in a similar way. We also emphasized special cases and potential problems that have to be handled when dealing with concurrency.
For example, picture a project with 50 developers spread across several geographic locations. If the project is not properly coordinated and no templates are provided, how many different client/server implementations might the project end up with? Even more dangerous, how many of these implementations will handle special borderline cases and concurrency-related errors correctly, if at all? Without a code review, can you be sure there is a uniform way across the system to handle server crashes that occur after clients have sent a request to the server? Or guarantee that the response from a request is indeed the response, and not just any message that conforms to the internal message protocol?
OTP behaviors address all of these issues by providing library modules that implement the most common concurrent design patterns. Behind the scenes, without the programmer having to be aware of it, the library modules ensure that errors and special cases are handled in a consistent way. As a result, OTP behaviors provide a set of standardized building blocks used in designing and building industrial-grade systems. The subject of OTP behaviors and their related middleware is vast. In this chapter, we provide the overview you need to get started.
Introduction to OTP Behaviors
OTP behaviors are a formalization of process design patterns. They are implemented in library modules that are provided with the standard Erlang distribution. These library modules do all of the generic process work and error handling. The specific code, written by the programmer, is placed in a separate module and called through a set of predefined callback functions.
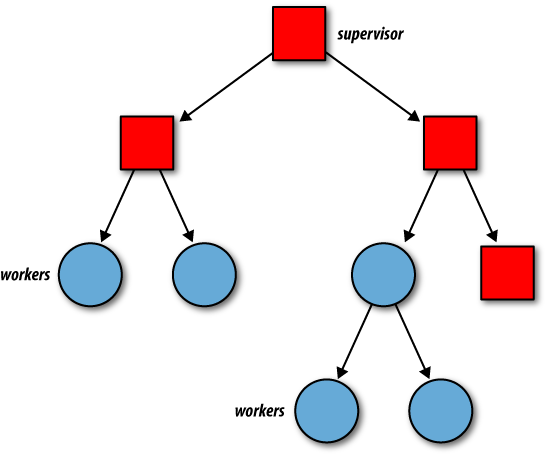
OTP behaviors include worker processes, which do the actual processing, and supervisors, whose task is to monitor workers and other supervisors. Worker behaviors, often denoted in diagrams as circles, include servers, event handlers, and finite state machines. Supervisors, denoted in illustrations as squares, monitor their children, both workers and other supervisors, creating what is called a supervision tree (see Figure 12-1).
Supervision trees are packaged into a behavior called an application. OTP applications not only are the building blocks of Erlang systems, but also are a way to package reusable components. Industrial-grade systems consist of a set of loosely coupled, possibly distributed applications. These applications are part of the standard Erlang distribution or are specific applications developed by you, the programmer.
Do not confuse OTP applications with the more general concept of an application, which usually refers to a more complete system that solves a high-level task. Examples of OTP applications include the Mnesia database, which we cover in Chapter 13; an SNMP agent; or the mobile subscriber database introduced in Chapter 10, which we will convert to an application using behaviors later in this chapter. An OTP application is a reusable component that packages library modules together with supervisor and worker processes. From now on, when we refer to an application, we will mean an OTP application.
The behavior module contains all of the generic code. Although it is possible to implement your own behavior module, doing so is rare because the behavior modules that come as part of the Erlang/OTP distribution will cater to most of the design patterns you would use in your code. The generic functionality provided in a behavior module includes operations such as the following:
Spawning and possibly registering the process
Sending and receiving client messages as synchronous or asynchronous calls, including defining the internal message protocol
Storing the loop data and managing the process loop
Stopping the process
Although the behavior module is provided, the programmer has to develop the callback module (see Figure 12-2). We introduced the concept of callback modules in Chapter 5. A callback module contains all of the specific code required to deliver the desired functionality. The specific code is invoked through a callback interface that is standardized for each behavior.

The loop data is a variable that will contain the data the behavior needs to store in between calls. After the call, an updated variant of the loop data is returned. This updated loop data, often referred to as the new loop data, is passed as an argument in the next call. Loop data is also commonly referred to as the behavior state.
The functionality to be included in the callback module to deliver the specific behavior required includes the following:
Initializing the process loop data, and, if the process is registered, the process name.
Handling the specific client requests, and, if synchronous, the replies sent back to the client.
Handling and updating the process loop data in between the process requests.
Cleaning up the process loop data upon termination.
There are many advantages to splitting the code into generic behavior libraries and specific callback modules:
Because many of the special cases and errors that might occur are already handled in the solid, well-tested behavior library, you can expect fewer bugs in your product.
For this reason, and also because so much of the code is already written for you, you can expect to have a shorter time to market.
It forces the programmer to write code in a way that avoids errors typically found in concurrent applications.
Finally, your whole team will come to share a common programming style. When reading someone else’s code while armed with a basic comprehension of the existing behaviors, no effort is required to understand the client/server protocol, looking for where and how processes are started or terminated, or how the loop data is handled. All of it is managed by the generic behavior library. Instead of having to focus on how everything is done, you can focus on what is being done specifically in this case, as coded in the callback module.
In the sections that follow, we will look at some of the most important behaviors—including generic servers and supervisors—and how to package them into applications.
Generic Servers
Generic servers that implement client/server behaviors are defined in
the gen_server behavior that
comes as part of the standard library application. In this chapter, you
will use the mobile customer database example from Chapter 10 to understand how the callback principle
works. If you do not remember the example, take a quick look at it before
proceeding.
We will rewrite the usr.erl
module, migrating it from an Erlang process to a gen_server behavior. In doing so, we will not
touch the usr_db module, keeping
the backend database as it is. When working your way through the example,
if you are interested in the details, have the manual pages for the
gen_server module at hand.
Starting Your Server
With the gen_server behavior,
instead of using the spawn and
spawn_link BIFs, you will use
the gen_server:start/4
and gen_server:start_link/4 functions.
The main difference between spawn and start is the synchronous
nature of the call. Using start
instead of spawn makes starting the
worker process more deterministic and prevents unforeseen race
conditions, as the call will not return the pid of the worker until it
has been initialized. You call the functions as follows (we show two
variants for each of the two functions):
gen_server:start_link(ServerName, CallBackModule, Arguments, Options) gen_server:start(ServerName, CallBackModule, Arguments, Options) gen_server:start_link(CallBackModule, Arguments, Options) gen_server:start(CallBackModule, Arguments, Options)
In the preceding calls:
ServerNameIs a tuple of the format
{local, Name}or{global, Name}, denoting a local or globalNamefor the process if it is to be registered. If you do not want to register the process and instead reference it using its pid, you omit the argument and use thestart_link/3orstart/3call instead.CallbackModuleIs the name of the module in which the specific callback functions are placed.
ArgumentsIs a valid Erlang term that is passed to the
init/1callback function. You can choose what type of term to pass: if you have many arguments to pass, use a list or a tuple; if you have none, pass an atom or an empty list, ignoring it in the callback function.OptionsIs a list that allows you to set the memory management flags
fullsweep_afterandheapsize, as well as tracing and debugging flags. Most behavior implementations just pass the empty list.
The start functions will spawn
a new process that calls the init(Arguments) callback function in the
CallbackModule, with the Arguments supplied. The init function must initialize the LoopData of the server and has to return a
tuple of the format {ok, LoopData}. LoopData contains the first instance of the
loop data that will be passed between the callback functions. If you
want to store some of the arguments you passed to the init function, you would do so in the LoopData variable.
The obvious difference between the start_link and start functions is
that start_link links to its parent
and start doesn’t. This needs a
special mention, however, as it is an OTP behavior’s responsibility to
link itself to the supervisor. The start functions are often used when testing
behaviors from the shell, as a typing error causing the shell process to
crash would not affect the behavior. All of the start and start_link variants return {ok, Pid}.
Before going ahead with the example, let’s quickly review what we
have discussed so far. You start a gen_server behavior using the gen_server:start_link
call. This results in a new process that calls the init/1 callback function. This function
initializes the LoopData and returns
the tuple {ok, LoopData}.
In our example, we call start_link/4, registering the process with the
same name as the callback module, calling the MODULE macro. We pass one argument, the
filename of the Dets table. The options list is kept empty:
start_link(FileName) ->
gen_server:start_link({local, ?MODULE}, ?MODULE, FileName, []).
init(FileName) ->
usr_db:create_tables(FileName),
usr_db:restore_backup(),
{ok, null}.Although the supervisor process might call the start_link/4 function, the init/1 callback is called by a different
process: the one that was just spawned. We don’t really need the
LoopData variable in our server, as
the ETS and Dets tables are named. Nonetheless, a value still has to be
included when returning the {ok,
LoopData} structure, so we’ll get around it by returning the
atom null. Had the ETS and Dets
tables not been named_tables, we
would have passed their references here.
Do only what is necessary and minimize the operations in your
init function, as the call to
init is a synchronous call that
prevents all of the other serialized processes from starting until it
returns.
Passing Messages
If you want to send a message to your server, you use the following calls:
gen_server:cast(Name, Message) gen_server:call(Name, Message)
In the preceding calls:
NameIs either the local registered name of the server or the tuple
{global, Name}. It could also be the process identifier of the server.MessageIs a valid Erlang term containing a message passed on to the server.
For asynchronous message requests, you
use cast/2. If you’re
using a pid, the call will immediately return the atom ok, regardless of whether the gen_server to which you are sending the
message is alive. These semantics are no different from the standard
Name ! Message construct, where if
the registered process Name does not
exist, the calling process terminates.
Upon receiving the message, gen_server will call the callback function
handle_cast(Message, LoopData) in the
callback module. Message is the
argument passed to the cast/2
function, and LoopData is the
argument originally returned by the init/1 callback
function. The handle_cast/1 callback
function handles the specifics of the message, and upon finishing, it
has to return the tuple {noreply,
NewLoopData}. In future calls to the server, the NewLoopData value most recently returned will
be passed as an argument when a message is sent to the server.
If you want to send a synchronous message to
the server, you use the call/2
function. Upon receiving this message, the process uses the handle_call(Message, From,
LoopData) function in the callback module. It contains
specific code for the particular server, and having completed, it
returns the tuple {reply, Reply,
NewLoopData}. Only now does the call/3 function synchronously return the value
Reply. If the process you are sending
a message to does not exist, regardless of whether it is registered, the
process invoking the call function terminates.
Let’s start by taking two functions from our service API; we will provide the whole program later. They are called by the client process and result in a synchronous message being sent to the server process registered with the same name as the callback module. Note how we are validating the data on the client side. If the client sends incorrect information, it terminates.
set_status(CustId, Status) when Status==enabled; Status==disabled->
gen_server:call(?MODULE, {set_status, CustId, Status}).
delete_disabled() ->
gen_server:call(?MODULE, delete_disabled).Upon receiving the messages, the gen_server process calls the handle_call/3 callback function dealing with
the messages in the same order in which they were sent:
handle_call({set_status, CustId, Status}, _From, LoopData) ->
Reply = case usr_db:lookup_id(CustId) of
{ok, Usr} ->
usr_db:update_usr(Usr#usr{status=Status});
{error, instance} ->
{error, instance}
end,
{reply, Reply, LoopData};
handle_call(delete_disabled, _From, LoopData) ->
{reply, usr_db:delete_disabled(), LoopData}.Note the return value of the callback function. The tuple contains
the control atom reply, telling the gen_server generic code that the second
element of the tuple is the Reply to
be sent back to the client. The third element of the tuple is the new
LoopData, which, in a new iteration
of the server, is passed as the third argument to the handle_call/3
function; in both cases here it is unchanged. The argument
_From is a tuple containing a unique
message reference and the client process identifier. The tuple as a
whole is used in library functions that we will not be discussing in
this chapter. In the majority of cases, you will not need it.
The gen_server library module
has a number of mechanisms and safeguards built in that function behind
the scenes. If your client sends a synchronous message to your server
and you do not get a response within five seconds, the process executing
the call/2 function is terminated.
You can override this by using the following code:
gen_server:call(Name, Message, Timeout)
where Timeout is a value in
milliseconds or the atom infinity.
The timeout mechanism was originally put in place for deadlock
prevention purposes, ensuring that servers that accidentally call each
other are terminated after the default timeout. The crash report would
be logged, and hopefully would result in a patch. Most applications will
function appropriately with a timeout of five seconds, but under very
heavy loads, you might have to fine-tune the value and possibly even use
infinity; this choice is very application-dependent. All of the critical
code in Erlang/OTP uses infinity.
Other safeguards when using the gen_server:call/2
function include the case of sending a message to a nonexisting server
or a server that crashes before sending its reply. In both cases, the
calling process will terminate. In raw Erlang, sending a message that is
never pattern-matched in a receive
clause is a bug that can cause a memory leak.
What do you think happens if you do a call or a cast to your
server, but do not handle the message in the handle_call/3 and handle_cast/2 calls, respectively? In OTP,
when a call or a cast is called, the message will always be extracted
from the process mailbox and the respective callback functions are
invoked. If none of the callback functions pattern-matches the message
passed as the first argument, the process will crash with a function
clause error. As a result, such issues will be caught in the early
stages of the testing phase and dealt with accordingly.
Stopping the Server
How do you stop the server? In your handle_call/3 and handle_cast/2 callback functions, instead of
returning {reply, Reply, NewLoopData}
or {noreply, NewLoopData}, you can
return {stop, Reason, Reply,
NewLoopData} or {stop, Reason,
NewLoopData}, respectively. Something has to trigger this
return value, often a stop message sent to the server. Upon receiving
the stop tuple containing the
Reason and LoopData, the generic code executes the
terminate(Reason, LoopData)
callback.
The terminate function is
the natural place to insert the code needed to clean up the LoopData of the server and any other
persistent data used by the system. In this example, it would mean
closing the ETS and Dets tables. The stop call does not have to occur within a
synchronous call, so let’s use cast
when implementing it:
stop() ->
gen_server:cast(?MODULE, stop).
handle_cast(stop, LoopData) ->
{stop, normal, LoopData}.
terminate(_Reason, _LoopData) ->
usr_db:close_tables().Remember that stop/0 will be
called by the client process, while the handle_cast/2 and handle_call/2 are called by the behavior
process. In the handle_cast/2
callback, we return the reason normal
in the stop construct. Any reason
other than normal will result in an
error report being generated.
With thousands of generic servers potentially being spawned and terminated every second, generating error reports for every one of them is not the way to go. You should return a nonnormal value only if something that should not have happened occurs and you have no way to recover. A socket being closed or a corrupt message from an external port is not a reason to generate a nonnormal termination. On the other hand, corrupt internal data or a missing configuration file is.
If your server crashes because of a runtime error, terminate/2 will be called. But if your
behavior receives an EXIT signal from
its parent, terminate will be called
only if you are trapping exits. Watch out for this special case, as
we’ve been caught by it many times, especially when starting the
behavior from the shell using start_link.
Warning
Use of the behavior callbacks as library functions and invoking
them from other parts of your program is an extremely bad practice.
For example, you should never call usr_db:init(FileName) from another module to
create and populate your database. Calls to behavior callback
functions should originate only from the behavior library modules as a
result of an event occurring in the system, and
never directly by the user.
The Example in Full
Here is the usr.erl module from Chapter 10,
rewritten as a gen_server
behavior:
%%% File : usr.erl
%%% Description : API and gen_server code for cellphone user db
-export([start_link/0, start_link/1, stop/0]).
-export([init/1, terminate/2, handle_call/3, handle_cast/2]).
-export([add_usr/3, delete_usr/1, set_service/3, set_status/2,
delete_disabled/0, lookup_id/1]).
-export([lookup_msisdn/1, service_flag/2]).
-behavior(gen_server).
-include("usr.hrl").
%% Exported Client Functions
%% Operation & Maintenance API
start_link() ->
start_link("usrDb").
start_link(FileName) ->
gen_server:start_link({local, ?MODULE}, ?MODULE, FileName, []).
stop() ->
gen_server:cast(?MODULE, stop).
%% Customer Services API
add_usr(PhoneNum, CustId, Plan) when Plan==prepay; Plan==postpay ->
gen_server:call(?MODULE, {add_usr, PhoneNum, CustId, Plan}).
delete_usr(CustId) ->
gen_server:call(?MODULE, {delete_usr, CustId}).
set_service(CustId, Service, Flag) when Flag==true; Flag==false ->
gen_server:call(?MODULE, {set_service, CustId, Service, Flag}).
set_status(CustId, Status) when Status==enabled; Status==disabled->
gen_server:call(?MODULE, {set_status, CustId, Status}).
delete_disabled() ->
gen_server:call(?MODULE, delete_disabled).
lookup_id(CustId) ->
usr_db:lookup_id(CustId).
%% Service API
lookup_msisdn(PhoneNo) ->
usr_db:lookup_msisdn(PhoneNo).
service_flag(PhoneNo, Service) ->
case usr_db:lookup_msisdn(PhoneNo) of
{ok,#usr{services=Services, status=enabled}} ->
lists:member(Service, Services);
{ok, #usr{status=disabled}} ->
{error, disabled};
{error, Reason} ->
{error, Reason}
end.
%% Callback Functions
init(FileName) ->
usr_db:create_tables(FileName),
usr_db:restore_backup(),
{ok, null}.
terminate(_Reason, _LoopData) ->
usr_db:close_tables().
handle_cast(stop, LoopData) ->
{stop, normal, LoopData}.
handle_call({add_usr, PhoneNo, CustId, Plan}, _From, LoopData) ->
Reply = usr_db:add_usr(#usr{msisdn=PhoneNo,
id=CustId,
plan=Plan}),
{reply, Reply, LoopData};
handle_call({delete_usr, CustId}, _From, LoopData) ->
Reply = usr_db:delete_usr(CustId),
{reply, Reply, LoopData};
handle_call({set_service, CustId, Service, Flag}, _From, LoopData) ->
Reply = case usr_db:lookup_id(CustId) of
{ok, Usr} ->
Services = lists:delete(Service, Usr#usr.services),
NewServices = case Flag of
true -> [Service|Services];
false -> Services
end,
usr_db:update_usr(Usr#usr{services=NewServices});
{error, instance} ->
{error, instance}
end,
{reply, Reply, LoopData};
handle_call({set_status, CustId, Status}, _From, LoopData) ->
Reply = case usr_db:lookup_id(CustId) of
{ok, Usr} ->
usr_db:update_usr(Usr#usr{status=Status});
{error, instance} ->
{error, instance}
end,
{reply, Reply, LoopData};
handle_call(delete_disabled, _From, LoopData) ->
{reply, usr_db:delete_disabled(), LoopData}.Running gen_server
When testing the gen_server
instance in the shell, you get exactly the same behavior as when you
used the server process that you coded yourself. However, the code is
more solid, as deadlocks, server crashes, timeouts, and other errors
related to concurrent programming are handled behind the scenes:
1>c(usr)./Users/Francesco/otp/usr.erl:11: Warning: undefined callback function code_change/3 (behaviour 'gen_server') /Users/Francesco/otp/usr.erl:11: Warning: undefined callback function handle_info/2 (behaviour 'gen_server') {ok,usr_db} 2>c(usr_db).{ok,usr_db} 3>rr("usr.hrl").[usr] 4>usr:start_link().{ok,<0.86.0>} 5>usr:add_usr(700000000, 0, prepay).ok 6>usr:set_service(0, data, true).ok 7>usr:lookup_id(0).{ok,#usr{msisdn = 700000000,id = 0,status = enabled, plan = prepay, services = [data]}} 8>usr:set_status(0, disabled).ok 9>usr:service_flag(700000000,lbs).{error,disabled} 10>usr:stop().ok
Did you notice the –behavior(gen_server) directive in the module?
This tells the compiler that your module is a gen_server callback module, and as a result,
it has to expect a number of callback functions. If all callback
functions are not implemented, you will get the warnings you noticed as
a result of the compile operation in
the first command line. Don’t write your code to avoid these warnings.
If your server has no asynchronous calls, you will obviously not need a
handle_cast/2. Ignore the
warnings.
Note
British or Canadian readers: don’t despair or shake your heads!
You are welcome to use the U.K.
English spelling in your directive: -behaviour(gen_server). The
compiler is bilingual and can handle both U.S. and U.K.
English.
What happens if you send a message to the server using raw Erlang
message passing of the form Pid!Msg?
It should be possible, as the gen_server is an Erlang process capable of
sending and receiving messages like any other process. Don’t be shy; try
it:
11>{ok, Pid} = usr:start_link().{ok,<0.119.0>} 12>Pid ! hello.hello =ERROR REPORT==== 24-Jan-2009::18:08:07 === ** Generic server usr terminating ** Last message in was hello ** When Server LoopData == null ** Reason for termination == ** {'function not exported',[{usr,handle_info,[hello,null]}, {gen_server,handle_msg,5}, {proc_lib,init_p,5}]} **exception exit: undefin function usr:handle_info/2 called as usr:handle_info(hello,null) in call from gen_server:handle_msg/5 in call from proc_lib:init_p/5
Oops! Something did not go according to plan. Look at the error
and try to figure out what happened. Use of Pid!Msg does not comply with the internal OTP
message protocol. Upon receiving a message that is not compliant, the
gen_server process tries to call the
function usr:handle_info(hello,
null), where hello is the
message and null is the loop
data.
The callback function handle_info/2[29] is called whenever the process receives a message it
doesn’t recognize. These could include “node down” messages from nodes
you are monitoring, exit signals from processes you are linked to, or
simply messages sent using the ...!... construct. If you are expecting such
messages but are not interested in them, add the following definition to
your callback module, and don’t forget to export it:
handle_info(_Msg, LoopData) ->
{noreply, LoopData}.If, on the other hand, you do want to do something with the
messages, you should pattern-match them in the first argument of the
call. If your server is not expecting nonOTP-compliant messages, don’t
add the handle_info/2 call, which
ignores incoming messages, “just in case.” Doing so is considered
defensive programming, which will probably make any fault you are hiding
hard to detect.
Warning
One of the downsides of OTP is the layering that the various
behavior modules require. This will affect performance. In the attempt
to save a few microseconds from their calls, developers have been
known to use the Pid ! Msg
construct instead of a gen_server
cast, handling their messages in the handle_info/2 callback.
Don’t do this! You will make your code impossible to support and maintain, as well as losing many of the advantages of using OTP in the first place. If you are obsessed with saving microseconds, try to hold on and optimize only when you know your program is not fast enough. We discuss optimizations in Chapter 20 and will cover there what really affects the performance of your code.
Before we look at the next behavior, here is a summary of the
exported gen_server API, the
resulting callback functions, and their expected return values:
- Setup
The following calls:
start(Name, Mod, Arguments, Opts) start_link(Name, Mod, Arguments, Opts),
where
Nameis an optional argument, spawn a new process. The process will result in the callback functioninit(Arguments)being called, which should return one of the values{ok, LoopData}or{stop, Reason}. Ifinit/1returns{stop, Reason}theterminate/2“cleanup” function will not be called.- Synchronous communication
Use
call(Name, Msg)to send a synchronous message to your server. It will result in the callback functionhandle_call(Msg, From, LoopData)being called by the server process. The expected return values include the following:{reply, Reply, NewLoopData} {stop, Reason, Reply, NewLoopData}.- Asynchronous communication
If you want to send an asynchronous message, use
cast(Name, Msg). It will be handled in thehandle_cast(Msg, LoopData)callback function, returning either{noreply, NewLoopData}or{stop, Reason, NewLoopData}.- Non-OTP-compliant messages
Upon receiving non-OTP-compliant messages,
gen_serverwill execute thehandle_info(Msg, LoopData)callback function. The function should return either{noreply, NewLoopData}or{stop, Reason, NewLoopData}.- Termination
Upon receiving a
stopconstruct from one of the callback functions (except forinit), or upon abnormal process termination when trapping exits, theterminate(Reason, LoopData)callback is invoked. Interminate/2, you would typically undo things you did ininit/1. Its return value is ignored.
Supervisors
The supervisor behavior’s task is to monitor its children and, based on
some preconfigured rules, take action when they terminate. The children
that make up the supervision tree include both supervisors and worker
processes. Worker processes are OTP behaviors including gen_server, gen_fsm (supporting finite state machine
behavior), and gen_event (which
provides event-handling functionality).
Worker processes have to link themselves to the supervisor behavior and handle specific system messages that are not exposed to the programmer. This is different from the way in which one process links to another in raw Erlang, and because of this, we cannot mix the two mechanisms. For this reason, it is not possible to add Erlang processes to the supervision tree in the form you know them. So, for the remainder of this section, we will stick to describing supervision within the OTP framework.
You start a supervisor using the start or start_link
function:
supervisor:start_link(ServerName, CallBackModule, Arguments) supervisor:start(ServerName, CallBackModule, Arguments) supervisor:start_link(CallBackModule, Arguments) supervisor:start(CallBackModule, Arguments)
In the preceding calls:
ServerNameIs the name to be registered for the supervisor, and is a tuple of the format
{local, Name}or{global, Name}. If you do not want to register the supervisor, you use the functions of arity two.CallbackModuleIs the name of the module in which the
init/1callback function is placed.ArgumentsIs a valid Erlang term that is passed to the
init/1callback function when it is called.
Note that the supervisor, unlike the gen_server, does not take any options. The
start and start_link functions will spawn a new process
that calls the init/1 callback
function. Upon initializing the supervisor, the init function has to return a tuple of the
following format:
{ok, {SupervisorSpecification, ChildSpecificationList}}The supervisor specification is a tuple containing information on how to handle process crashes and restarts. The child specification list specifies which children the supervisor has to start and monitor, together with information on how to terminate and restart them.
Supervisor Specifications
The supervisor specification is a tuple consisting of three elements describing how the supervisor should react when a child terminates:
{RestartStrategy, AllowedRestarts, MaxSeconds}The restart strategy determines how other children are affected if one of their siblings terminates. It can be one of the following:
one_for_oneWill restart the child that has terminated, without affecting any of the other children. You should pick this strategy if all of the processes at this level of the supervision tree are not dependent on each other.
one_for_allWill terminate all of the children and restart them. You should use this if there is a strong dependency among all of the children regardless of the order in which they were started.
rest_for_oneWill terminate all of the children that were started after the child that crashed, and will restart them. This strategy assumes that processes are started in order of dependency, where spawned processes are dependent only on their already started siblings.
What will happen if your process gets into a cyclic restart? It
crashes and is restarted, only to come across the same corrupted data,
and as a result, it crashes again. This can’t go on forever! This is
where AllowedRestarts comes in, by
specifying the maximum number of abnormal terminations the supervisor is
allowed to handle in MaxSeconds
seconds. If more abnormal terminations occur than are allowed, it is
assumed that the supervisor has not been able to resolve the problem,
and it terminates. The supervisor’s supervisor receives the exit signal
and, based on its configuration, decides how to proceed.
Finding reasonable values for AllowedRestarts and MaxSeconds is not easy, as they will be
application-dependent. In production, we’ve used anything from ten
restarts per second to one per hour. Your choice will have to depend on
what your child processes do, how many of them you expect the supervisor
to monitor, and how you’ve set up your supervision strategy.
Child Specifications
The second argument in the structure returned by the init/1 function is a
list of child specifications. Child specifications provide the
supervisor with the properties of each of its children, including
instructions on how to start it. Each child specification is of the
following form:
{Id, {Module, Function, Arguments}, Restart, Shutdown, Type, ModuleList}In the preceding code:
IdIs a unique identifier for a particular child within a supervisor. As a child process can crash and be restarted, its process identifier might change. The identifier is used instead.
The supervisor uses the tuple
{Module, Function, Arguments}to start the child process. The supervisor has to eventually call thestart_linkfunction for the particular OTP behavior, and return{ok, Pid}.RestartIs one of the atoms
transient,temporary, orpermanent. Transient processes are never restarted. Temporary processes are restarted only if they terminate abnormally, and permanent processes are always restarted, regardless of whether the termination was normal or nonnormal.ShutdownSpecifies how many milliseconds a behavior that is trapping exits is allowed to execute in its
terminatecallback function after receiving theshutdownsignal from its supervisor, either because the supervisor has reached its maximum number of allowed child restarts or because of arest_for_oneorone_for_allrestart strategy.If the child process has not terminated by this time, the supervisor will kill it unconditionally.
Shutdownwill also take the atominfinity, a value which should always be chosen if the process is a supervisor, or the atombrutal_kill, if the process is to be killed unconditionally.TypeSpecifies whether the child process is a
workeror asupervisor.ModuleListIs a list of the modules that implement the process. The release handler uses it to determine which processes it should suspend during a software upgrade. As a rule of thumb, always include the behavior callback module.
In some cases, child specifications are created dynamically from a
config file. In most cases, however, they are statically coded in the
supervisor callback module. The init/1 function is the only callback
function that needs to be exported.
It can be easy to insert syntactical and semantic errors in child
specification lists, as they tend to get fairly complex. The help
function check_childspecs/1 in
the supervisor module takes a list of child specifications and returns
ok or the tuple {error, Reason}. An example of a child
specification for the mobile subscriber database will follow in the next
section. To ensure that you understand what is happening, map all of the
entries to their respective fields in the child specification
structure.
Supervisor Example
In this example, the usr_sup module is a
supervisor behavior, supervising one child that is the usr example of a gen_server from earlier in the chapter.
We’ll start the supervisor using the start_link/0 call.
Note that we’ve omitted the option of passing a filename for the Dets
tables, as it was originally included for test purposes. Pay particular
attention to the child and the supervisor specifications returned by the
init/1 function:
-module(usr_sup).
-behavior(supervisor).
-export([start_link/0]).
-export([init/1]).
start_link() ->
supervisor:start_link({local, ?MODULE}, ?MODULE, []).
init(FileName) ->
UsrChild = {usr,{usr, start_link, []},
permanent, 2000, worker, [usr, usr_db]},
{ok,{{one_for_all,1,1}, [UsrChild]}}.Now you can try it out from the shell. Do not test only positive
cases; also try to kill the child and ensure that it has been restarted.
Finally, kill the server more than MaxRestart times in MaxSeconds (twice in one second in this
example), to see whether the supervisor terminates:
13>c(usr_sup).{ok,usr_sup} 14>usr_sup:start_link().{ok,<0.149.0>} 15>whereis(usr).<0.150.0> 16>exit(whereis(usr), kill).true 17>whereis(usr).<0.156.0> 18>usr:lookup_id(0).{ok,#usr{msisdn = 700000000,id = 0,status = disabled, plan = prepay, services = [data]}} 19>exit(whereis(usr), kill).true 20>exit(whereis(usr), kill).** exception exit: shutdown
Note
When a process terminates, all of the ETS tables that it created
are destroyed. If you want ETS tables to survive process restarts
without incurring the overhead of dealing with Dets tables or the
filesystem, a trick is to let your supervisor create the tables in its
init/1 function, rather than in the
processes spawned.
Dynamic Children
So far, we have looked only at static children. What if you need a
supervisor that dynamically creates a child whose task is to handle a
specific event, take care of the task, and terminate when completed? It
could be for every incoming instant message (IM) or buddy update coming
into your IM server. You can’t specify these children in your init callback function, as they are created
dynamically. Instead, you need to use the calls to functions supervisor:???_child/2:
supervisor:start_child(SupervisorName, ChildSpec) supervisor:terminate_child(SupervisorName, Id) supervisor:restart_child(SupervisorName, Id) supervisor:delete_child(SupervisorName, Id).
In the preceding calls:
SupervisorNameIs either the process identifier of the supervisor or its registered name
ChildSpecIs a single child specification tuple, as described in the section Child Specifications
IdIs the unique child identifier defined in the
ChildSpec
Of particular importance in the ChildSpec tuple is the child Id. Even after termination, the ChildSpec will be stored by the supervisor and
referenced through its Id, allowing
processes to stop and restart the child. Only upon deletion will the
child specification be permanently removed.
Note
If you’ve been skimming through the manual page for the
supervisor behavior, you probably realize that it does not export a
stop function. As supervisors are
never meant to be stopped by anyone other than their parent
supervisors, this function was not implemented.
You can easily add your own stop function by including the following
code in your supervisor callback module. However, this will work only
if stop is called by the
parent:
stop() -> exit(whereis(?MODULE), shutdown).
If your supervisor is not registered, use its pid.
Applications
The application behavior is used to package Erlang modules into reusable components. An Erlang system will consist of a set of loosely coupled applications. Some are developed by the programmer or the open source community, and others will be part of the OTP distribution. The Erlang runtime system and its tools will treat all applications equally, regardless of whether they are part of the Erlang distribution.
There are two kinds of applications. The most common form of applications, called normal applications, will start the supervision tree and all of the relevant static workers. Library applications such as the Standard Library, which come as part of the Erlang distribution, contain library modules but do not start the supervision tree. This is not to say that the code may not contain processes or supervision trees. It just means they are started as part of a supervision tree belonging to another application.
In this section, we will cover all the functionality needed to encapsulate the mobile subscriber system into an OTP application, starting its top-level supervisor. When done, this application will behave like any other normal application. And don’t forget, when we talk about applications in this chapter, we mean OTP applications.
Applications are loaded, started, and stopped as one unit. A
resource file associated with every application not only describes it, but
also specifies its modules, registered processes, and other configuration
data. Applications have to follow a particular directory structure which
dictates where beam, module, resource, and include files have to be
placed. This structure is required for many of the existing tools, built
around behaviors, to function correctly. To find out which applications
are running in your Erlang runtime system, you use application:which_applications():
1> application:which_applications().
[{stdlib,"ERTS CXC 138 10","1.15.2"},
{kernel,"ERTS CXC 138 10","2.12.2"}]The Standard Library and the Kernel are part of the basic Erlang applications and together form the minimal OTP subset when starting the runtime system. The first item in the application tuple is the application name. The second is a description string, and the third is the application version number. If you are wondering what the description string in the preceding example means, you are not alone. It is the internal Ericsson product numbering scheme.
We will show you where to configure the description of your applications later in this chapter.
Directory Structure
In your Erlang shell, type code:get_path(). You did this when we were explaining how to manipulate the code search path in the code server. What you probably did not realize at the time was that each code path was pointing to a specially structured directory of an OTP application.
Let’s pick the Inets application and inspect its contents in more detail. In Mac OS X, the path for this particular installation of Erlang would be as follows:
/usr/local/lib/erlang/lib/inets-5.0.12/
In other operating systems, just cd to the lib directory from the Erlang root directory,
typically something like /usr/local/lib/erlang/lib or C:/Program Files/erl5.6.2/lib/, and look for
the latest Inets release. Among all the subdirectories in an
application, the following ones comprise an OTP release of the
application in question:
- src
Contains the source code of all the Erlang modules in the application.
- ebin
Contains all of the compiled beam files and the application resource file; in this example, it’s inets.app.
- include
Contains all the Erlang header files (
hrl) intended for use outside the application. By using the following directive:-include_lib("Application/include/Name.hrl")where
Applicationis the application directory name without the version number (in the example it would beinets) andName.hrlis the name of the include file, the compiler will automatically pick up the version of the application pointed to by the code search path.- priv
Is an optional directory that contains necessary scripts, graphics, configuration files, or other non-Erlang-related resources. You can access it without knowing the application version by using the
code:priv_dir(Application)call.
You will notice that Inets (and other) applications may have a few more directories, including docs and examples. These have no effect on the system during runtime, and are there just for convenience. In some applications, you might not find the priv directory. If you do not use it, omitting it is not a problem, even if it might not be considered a good practice by some. In live systems, the only mandatory directory is ebin. This is because you probably don’t want to include your source code when shipping your system to clients!
It is common to use scripts to create these directory structures, and to use make files which, having compiled your code, move the beam files to the ebin directory. How you set this up depends on the operating systems, build systems, repositories, and many other non-Erlang-related dependencies in your application. Although it might be feasible to set this up manually for small projects, you will probably want to use templates and automate the task for larger projects.
The Application Resource File
The application resource file, also known as the app file, contains information on your application resources and dependencies. Move into the ebin subdirectory of the Inets application and look for the inets.app file. This is the resource file of the Inets application. On closer inspection, you will notice that all other applications also have an inets.app file. The application resource file consists of a tuple where the first element is the application tag, the second is the application name, and the third is a list of features.
Let’s go through the features individually. Note that for space considerations, we’ve omitted some of the modules in the example:
{application,inets,
[{description,"INETS CXC 138 49"},
{vsn,"5.0.5"},
{modules,[inets,inets_sup,inets_app,inets_service,
%% FTP
ftp, ftp_progress,ftp_response,ftp_sup,
%% HTTP client:
http,httpc_handler,httpc_handler_sup,httpc_manager,
%% TFTP
tftp,tftp_binary,tftp_engine,tftp_file,tftp_lib,tftp_sup
]},
{registered,[inets_sup, httpc_manager]},
{applications,[kernel,stdlib]},
{mod,{inets_app,[]}}]}.In the preceding code, the description is a string that is displayed as a
result of calling the application:which_application/0 function. The
vsn attribute is a string denoting
the version of the application. This should be the same as the suffix of
the application directory. In larger build systems, the application
version is usually updated automatically through proprietary scripts
executed when committing your code.
The modules tag lists all the
modules that belong to this application. The purpose of listing them is
twofold. The first is to ensure that all of them are present when
building the system and that there are no name clashes with any other
applications. The second is to be able to load them either at startup or
when loading the application. For every module, there should be a
corresponding beam file. To ensure that there are no registered name clashes with other
applications, we list all of the registered processes in this field. Clashes in
module and registered process names are detected by the release-handling
tools used when creating your boot file. We will look at boot files in
the next section. Just including them in the application resource files
will have no effect unless these tools are used.
Most applications will have to be started after other applications
on which they depend. Your application will not start if the
applications in the applications list
included in your app file are not
already started. kernel and
stdlib are the basic standard
applications on which every other application depends. After that, the
particular dependencies will be based on the nature of the
application.
Finally, the mod parameter is a
tuple containing the callback module and the arguments passed to the
start/2 callback function.
Not necessary to the Inets application, but certainly important to
applications in general, are environment variables.
The env tag indicates a list of
key-value tuples that can be accessed from within the application using
calls to the following functions:
application:get_env(Tag) application:get_all_env().
To access environment variables belonging to other applications,
just add the application Name to
either function call, as in the following:
application:get_env(Name,Tag) application:get_all_env(Name).
The application resource file usr.app of our mobile subscriber service database would contain four modules, two registered processes, and dependencies on the stdlib and kernel applications. Let’s also add the filename for the Dets table among the environment variables:
{application, usr,
[{description, "Mobile Services Database"},
{vsn, "1.0"},
{modules, [usr, usr_db, usr_sup, usr_app]},
{registered, [usr, usr_sup]},
{applications, [kernel, stdlib]},
{env, [{dets_name, "usrDb"}]},
{mod, {usr_app,[]}}]}.Starting and Stopping Applications
You start and stop applications using the following commands:
application:start(ApplicationName). application:stop(ApplicationName).
In the preceding code, ApplicationName is an atom denoting the name
of your application.
The application controller loads the
environment variables belonging to the application, as well as starts
the top-level supervisor through a set of callback functions. When
calling start/1, the start(StartType, Arguments) function in the
application callback module is invoked. StartType is usually the atom normal, but if you are dealing with
distributed applications,[30] you might come across the start types takeover and failover. Arguments is a value of any valid Erlang data
type, which together with the callback module is defined in the
application resource file.
Start has to return the tuple
{ok, Pid} or {ok, Pid, Data}. Pid denotes the process identifier of the
top-level supervisor. Data is a valid
Erlang data type used to store data that is needed when terminating the
application.
If you stop your application, the top-level supervisor is sent a
shutdown message. This results in the termination of all of its children
in reverse startup order, propagating the exit path through the
supervision tree. Once the supervision tree has terminated, the callback
function stop(Data) is called in the
application callback module. Data was
originally returned in the {ok, Pid,
Data} construct of the start/2 callback function. If your start/2 function did not return any data, just
ignore the argument. Should you want a callback function to be called
before terminating the supervision tree, export the function prep_stop(Data) in
your callback module.
So, armed with all of the preceding information, how would you
package your usr server database into
an application, what would the directory structure look like, and what
are the contents of the app file?
Let’s start with the application callback file. We export the
start/2 and stop/1 functions:
-module(usr_app).
-behaviour(application).
-export([start/2, stop/1]).
start(_Type, StartArgs) ->
usr_sup:start_link().
stop(_State) ->
ok.As you can see, the application callback module is relatively
simple. Although we have not done it in our example, it is not uncommon
to join the supervisor and application behavior modules into one. You
would have the two –behaviour
directives next to each other, and if there is no conflict with the
callback functions, the compiler will not issue any warnings.
This leaves one minor change to be made in the usr.erl module, where we read the environment variable in the start_link/0 call:
start_link() ->
{ok, FileName} = application:get_env(dets_name),
start_link(FileName).With all of this in place, all that remains is our application directory structure, placing the relevant files in there:
usr-1.0/src/usr.erl
usr_db.erl
usr_sup.erl
usr_app.erl
/ebin/usr.beam
usr_db.beam
usr_sup.beam
usr_app.beam
usr.app
/priv/
/include/usr.hrlLet’s compile all the modules and take them for a test run. Move
the beam files to the ebin
directory, and make sure they are accessible by telling the system about
the path to them. You can do that either with the erl –pa Dir directive when starting Erlang, or
directly in the shell using code:add_path(Dir).
In the following interaction, we start the application and run a
few operations on the customer settings before stopping it. In doing so,
we check that the supervisor and
gen_server processes no longer
exist:
1>code:add_path("usr-1.0/ebin").true 2>application:start(usr).ok 3>application:start(usr).{error,{already_started,usr}} 4>usr:lookup_id(10).{error,instance} 5>application:get_env(usr, dets_name).{ok,"usrDb"} 6>application:stop(usr).=INFO REPORT==== 27-Jan-2009::22:14:33 === application: usr exited: stopped type: temporary ok 6>whereis(usr_sup).undefined
Note how we retrieved the dets_name environment variable from the
environment. In our usr example, we
are calling the function from within the application, and as a result,
we do not need to specify the application name. Look through the manual
page of the application module and experiment with the various options
for retrieving application environment variables to get a better understanding of what is
available.
The Application Monitor
The application monitor is a tool that provides an overview of all running
applications. Upon launching it with the appmon:start() call,
you are presented with a list of all the applications running on all
distributed nodes. The various menus allow you to manipulate the node
and presentation, and the bar on the left shows the load on the node
under scrutiny (see Figure 12-3).

In Figure 12-3, note how the
stdlib application is not shown.
Only applications with a supervision tree appear. Double-clicking the
application opens a new window with a view of its supervision tree (see
Figure 12-4). The menus
and buttons allow you to manipulate the various processes. The top
processes linking to usr_sup are part
of the application controller. They are the ones that start, monitor,
and stop the top-level supervisor.

Release Handling
From our behaviors, we’ve created a supervision tree. The supervision tree is packaged in an application that can be loaded, started, and stopped as one entity. Erlang systems consist of a set of loosely coupled applications specified in a release file. This includes the basic Erlang installation you have been running. From your Erlang root directory, enter the releases directory, followed by one of the release subdirectories. In our example, it is R12B (see Figure 12-5).
In it, you will find a list of release files, indicated by the .rel suffix, as shown in Figure 12-5. Pick start_clean.rel and inspect it:
{release, {"OTP APN 181 01","R12B"}, {erts, "5.6.2"},
[{kernel,"2.12.2"},
{stdlib,"1.15.2"}]}.It consists of a tuple where the first element is the release tag and the second element is a tuple
with a release name and release version number. The third element is a
tuple with the version of the Erlang runtime system. The last element in
the tuple is a list of applications and their version numbers, defined in
the order in which they should be started.
Each application in this list points to an application resource
file. When you call the function systools:make_rel(Name,
Options), these app files are retrieved and inspected. Module
and registered process name conflicts are checked, and if everything
matches, Name.boot and Name.script files are produced.
Name.boot is a binary file
containing instructions on loading the application modules and starting
the top-level supervisors. The Name.script file is a text version of its
binary counterpart. The Options
argument is a list in which the most important data includes {path, [Dir]}, which describes any paths to the
application ebin directories not
known by the code server. The paths commonly point to the ebin directories of your applications. The
local directive is another option to
make_rel/2, stating that the boot file
should not assume that all the applications will be found under lib in the Erlang root directory. The latter is
useful if you want to separate the Erlang installation and your
applications.
In a deployed system, you will release only the applications that
are relevant to your system. These applications include both your
applications and the subset of the ones you need from the OTP release.
They should all be stored in the lib
subdirectory of the Erlang root, but you can easily override this
recommendation by adding paths in the code search path used by the code
server. We are in fact overriding this in our example by using the
local directive in the options
list.
When the boot file has been created, you can start your system using the following command:
erl -boot Name
This ensures that all of the modules specified in the boot file are loaded and that the applications and their respective supervision trees are started correctly. If anything fails at startup, the Erlang node will not start.
The release file of our mobile subscriber database, usr.rel, would include kernel and stdlib, the two mandatory applications of any
OTP release, together with version 1.0 of our usr application:
{release, {"Mobile User Database","R1"}, {erts, "5.6.2"},
[{kernel,"2.12.2"},
{stdlib,"1.15.2"},
{usr,"1.0"}]}.Because in the running example we are using the shell where we
previously added the path to usr-1.0/ebin, we create a boot file which runs
with the existing code path. Had we not set the path
in the shell, we would have had to add the option {dir, ["usr-1.0/ebin"]} to the release
file:
7> systools:make_script("usr", [local]).
ok
8> ls().
usr-1.0
usr.boot
usr.rel
usr.script
usrDbWe can now start our system using erl –boot usr.
Note
Have a look at the usr.script
file that was generated when creating the boot file. We will not explain
it in this book, as most of its commands should be fairly
straightforward. You can edit the files and generate a new boot file
using the systools:script2bootfile/1
call.
Spare a thought for the early pioneers of OTP. In its first
release back in 1996, script files had to be generated manually, as the
make_script/2 function had not been
implemented!
Other Behaviors and Further Reading
What we described in this chapter should cover a majority of the cases you will come across when using OTP behaviors. However, you can go in more detail when working with generic servers, supervisors, and applications. Behaviors we have not covered but which we briefly introduced in this chapter include finite state machines, event handlers, and special processes. All of these behavior library modules have manual pages that you can reference. In addition, the Erlang documentation has a section on OTP design principles that provides more details and examples of these behaviors.
Finite state machines are a crucial component of telecom systems. In Chapter 5, we introduced the idea of modeling a
phone as a finite state machine. If the phone is not being used, it is in
state idle. If an incoming call
arrives, it goes to state ringing. This
does not have to be a phone; it could instead be an ATM cross-connect or
the handling of data in a protocol stack. The gen_fsm module provides
you with a finite state machine behavior that you can use to solve these
problems. States are defined as callback functions that return a tuple
containing the next State and the
updated loop data. You can send events to these states synchronously and
asynchronously. The finite state machine callback module should also
export the standard callback functions such as init, terminate, and handle_info. As gen_fsm is a standard OTP behavior, it can be
linked to the supervision tree.
Event handlers and managers are another behavior implemented in the
gen_event library module. The idea is to create a centralized point that
receives events of a specific kind. Events can be sent synchronously and
asynchronously with a predefined set of actions being applied when they
are received. Possible responses to events include logging them to file,
sending off an alarm in the form of an SMS, or collecting statistics. Each
of these actions is defined in a separate callback module with its own
LoopData, preserved in between calls.
Handlers can be added, removed, or updated for every specific event
manager. So, in practice, for every event manager, there could be many
callback modules, and different instances of these callback modules could
exist in different managers.
Sometimes you might want to add to the supervision tree processes that are not generic OTP behaviors. This might be for efficiency reasons, where you have implemented the process using plain Erlang. You might want to attach to a supervision tree legacy code that was written before OTP was available, or you might have abstracted a design pattern and implemented your own behavior.
Writing your own behaviors is straightforward. The main differences
are in how you spawn your processes, and the system calls you need to
handle. You should create processes using the proc_lib library, which
exports both spawn and start functions. Using the proc_lib function stores the start data of the
process, provides the means to start the process synchronously, and
generates error reports upon abnormal termination. To be OTP-compliant,
processes need to handle system messages and events, yielding the control
of the loop to the sys library module. They
also need to be linked to their parent, and if they are trapping exits,
they need to terminate when the parent terminates. You can find more
information on writing your own OTP behaviors in the sys and proc_lib library modules.
Exercises
Exercise 12-1: Database Server Revisited
Rewrite Exercise 5-1 in Chapter 5
using the gen_server behavior
module. Use the lists backend
database module, saving your list in the loop data. You should register
the server and access its services through a functional interface.
Exported functions in the my_db_gen.erl module should include the
following:
my_db_gen:start() ⇒ ok.
my_db_gen:stop() ⇒ ok.
my_db_gen:write(Key,Element) ⇒ ok.
my_db_gen:delete(Key) ⇒ ok.
my_db_gen:read(Key) ⇒ {ok,Element}|{error,instance}.
my_db:match(Element) ⇒ [Key1, ..., KeyN].Hint: if you are using Emacs or Eclipse, use the gen_server skeleton template:
1> my_db:start().
ok
2> my_db:write(foo, bar).
ok
3> my_db:read(baz).
{error, instance}
4> my_db:read(foo).
{ok, bar}
5> my_db:match(bar).
[foo]Exercise 12-2: Supervising the Database Server
Implement a supervisor that starts and monitors the gen_server in Exercise 12-1. Your supervisor
should be able to handle five crashes per hour. Your child should be
permanent and be given at least 30 seconds to terminate, as it might
take some time to close a large Dets file.
Exercise 12-3: The Database Server As an Application
Encapsulate your supervision tree from Exercise 12-2 in an application, setting up the correct directory structure, complete with application resource file.