
Chapter 5. Process Design Patterns
Processes in Erlang systems can act as gateways to databases, handle protocol stacks, or manage the logging of trace messages. Although these processes may handle different requests, there will be similarities in how these requests are handled. We call these similarities design patterns. In this chapter, we are going to cover the most common patterns you will come across when working with Erlang processes.
The client/server model is commonly used for processes responsible for a resource such as a list of rooms, and services that can be applied on these resources, such as booking a room or viewing its availability. Requests to this server will allow clients (usually implemented as Erlang processes) to access these resources and services.
Another very common pattern deals with finite state machines, also referred to
as FSMs. Imagine a process handling events in an instant messaging (IM)
session. This process, or finite state machine as we should call it, will be
in one of three states. It could be in an offline state, where the
session with the remote IM server is being established. It could be in
an online state, enabling the
user to send and receive messages and status updates. And finally, if the
user wants to remain online but not receive any messages or status updates,
it could be in a busy state. State changes
are triggered through process messages we call events.
An IM server informing the FSM that the user is logged on successfully would
cause a state transition from the offline state to the online state. Events received by the FSM do not
necessarily have to trigger state transitions. Receiving an instant message
or a status update would keep the FSM in an online state while a logout event would cause it
to go from an online or busy state to the offline state.
The last pattern we will cover is the event handler. Event handler processes will receive messages of a specific type. These could be trace messages generated in your program or stock quotes coming from an external feed. Upon receiving these events, you might want to perform a set of actions such as triggering an SMS (Short Message Service message) or sending an email if certain conditions are met, or simply logging the time stamp and stock price in a file.
Many Erlang processes will fall into one of these three categories. In this chapter, we will look at examples of process design patterns, explaining how they can be used to program client/servers, finite state machines, and event handlers. An experienced Erlang programmer will recognize these patterns in the design phase of the project and use libraries and templates that are part of the OTP framework. For the time being, we will use Erlang without the OTP framework. We will introduce OTP behaviors in Chapter 12.
Client/Server Models
Erlang processes can be used to implement client/server solutions, where both clients and servers are represented as Erlang processes. A server could be a FIFO queue to a printer, window manager, or file server. The resources it handles could be a database, calendar, or finite list of items such as rooms, books, or radio frequencies. Clients use these resources by sending the server requests to print a file, update a window, book a room, or use a frequency. The server receives the request, handles it, and responds with an acknowledgment and a return value if the request was successful, or with an error if the request did not succeed (see Figure 5-1).

When implementing client/server behavior, clients and servers are represented as Erlang processes. Interaction between them takes place through the sending and receiving of messages. Message passing is often hidden in functional interfaces, so instead of calling:
printerserver ! {print, File}a client would call:
printerserver:print(File)
This is a form of information hiding, where we do not make the client aware that the server is a process, that it could be registered, and that it might reside on a remote computer. Nor do we expose the message protocol being used between the client and the server, keeping the interface between them safe and simple. All the client needs to do is call a function and expect a return value.
Hiding this information behind a functional interface has to be done with care. The message response times will differ if the process is busy or running on a remote machine. Although this should in most cases not cause any problems, the client needs to be aware of it and be able to cope with a delay in response time. You also need to factor in that things can go wrong behind this function call. There might be a network glitch, the server process might crash, or there might be so many requests that the server response times become unacceptable.
If a client using the service or resource handled by the server
expects a reply to the request, the call to the server has to be
synchronous, as in Figure 5-2. If the client does
not need a reply, the call to the server can be
asynchronous. When you encapsulate synchronous and
asynchronous calls in a function call, asynchronous calls commonly return
the atom ok, indicating that the
request was sent to the server. Synchronous calls will return the value
expected by the client. These return values usually follow the format
ok, {ok,
Result}, or {error,
Reason}.

A Client/Server Example
Enough with the theory! So that you understand what we are talking about, let’s walk through a client/server example and test it in the shell. This server is responsible for managing radio frequencies on behalf of its clients, the mobile phones connected to the network. The phone requests a frequency whenever a call needs to be connected, and releases it once the call has terminated (see Figure 5-3).

When a mobile phone has to set up a connection to another
subscriber, it calls the frequency:allocate() client function. This call has the effect of generating a
synchronous message which is sent to the server. The server handles it
and responds with either a message containing an available frequency or
an error if all frequencies are being used. The result of the allocate/0 call will therefore be either
{ok, Frequency} or {error, no_frequencies}.
Through a functional interface, we hide the message-passing mechanism, the format of these messages, and the fact that the frequency server is implemented as a registered Erlang process. If we were to move the server to a remote host, we could do so without having to change the client interface.
When the client has completed its phone call and releases the
connection, it needs to deallocate the frequency so that other clients
can reuse it. It does so by calling the client function frequency:deallocate(Frequency). The call
results in a message being sent to the server. The server can then make
the frequency available to other clients and responds with the atom
ok. The atom is sent back to the
client and becomes the return value of the deallocate/1 call. Figure 5-4 shows the message
sequence diagram of this example.

The code for the server is in the frequency module. Here is the first
part:
-module(frequency).
-export([start/0, stop/0, allocate/0, deallocate/1]).
-export([init/0]).
%% These are the start functions used to create and
%% initialize the server.
start() ->
register(frequency, spawn(frequency, init, [])).
init() ->
Frequencies = {get_frequencies(), []},
loop(Frequencies).
% Hard Coded
get_frequencies() -> [10,11,12,13,14,15].The start function spawns a new
process that starts executing the init function in the frequency module. The spawn returns a pid that is passed as the
second argument to the register BIF.
The first argument is the atom frequency, which is the alias with which the
process is registered. This follows the convention of registering a
process with the same name as the module in which it is defined.
Note
Remember that when spawning a process, you have to export the
init/0 function as it is used by
the spawn/3 BIF. We have put this
function in a separate export
clause to distinguish it from the client functions, which are supposed
to be called from other modules. Calling frequency:init() from anywhere in
your code would be considered a very bad practice, and should not be
done.
The newly spawned process starts executing in the init function. It creates a tuple consisting
of the available frequencies, retrieved through the get_frequencies/0 call, and a list of the
allocated frequencies—initially given by the empty list—as the server
has just been started. The tuple, which forms what we call the
state or loop data, is bound
to the Frequencies variable and
passed as an argument to the receive-evaluate function, which in this
example we’ve called loop/1.
In the init/0 function, we use
the variable Frequencies for
readability reasons, but nothing is stopping us from creating the tuple
directly in the loop/1 call, as in
the call loop({get_frequencies(),
[]}).
Here is how the client functions are implemented:
%% The client Functions
stop() -> call(stop).
allocate() -> call(allocate).
deallocate(Freq) -> call({deallocate, Freq}).
%% We hide all message passing and the message
%% protocol in a functional interface.
call(Message) ->
frequency ! {request, self(), Message},
receive
{reply, Reply} -> Reply
end.Client and supervisor[16] processes can interact with the frequency server using
what we refer to as client functions. These exported
functions include start, stop, allocate, and deallocate. They call the call/1 function,
passing the message to be sent to the server as an argument. This
function will encapsulate the message protocol between the server and
its clients, sending a message of the format {request, Pid, Message}. The atom request is a tag in the tuple, Pid is the process identifier of the calling
process (returned by calling the self() BIF in the calling process), and
Message is the argument originally
passed to the call/1 function.
When the message has been sent to the process, the client is
suspended in the receive clause
waiting for a response of the format {reply,
Reply}, where the atom reply is a tag and the variable Reply is the actual response. The server
response is pattern-matched, and
the contents of the variable Reply
become the return value of the client functions.
Pay special attention to how message passing and the message protocol have been abstracted to a format independent of the action relating to the message itself; this is what we referred to earlier as information hiding, allowing the details of the protocol and the message structure to be modified without affecting any of the client code.
Now that we have covered the code to start and interact with the frequency server, let’s take a look at its receive-evaluate loop:
%% The Main Loop
loop(Frequencies) ->
receive
{request, Pid, allocate} ->
{NewFrequencies, Reply} = allocate(Frequencies, Pid),
reply(Pid, Reply),
loop(NewFrequencies);
{request, Pid , {deallocate, Freq}} ->
NewFrequencies = deallocate(Frequencies, Freq),
reply(Pid, ok),
loop(NewFrequencies);
{request, Pid, stop} ->
reply(Pid, ok)
end.
reply(Pid, Reply) ->
Pid ! {reply, Reply}.The receive clause will accept
three kinds of requests originating from the client
functions, namely allocate, deallocate, and stop. These requests follow the same format
defined in the call/1 function, that
is, {request, Pid, Message}. The
Message is pattern-matched in the
expression and used to determine which clause is executed. This, in
turn, determines the internal functions that are called. These internal
functions will return the new loop data, which in our example consists
of the new lists of available and allocated frequencies, and where
needed, a reply to send back to the client. The client pid, sent as part
of the request, is used to identify the calling process and is used in
the reply/2 call.
Assume a client wants to initiate a call. To
do so, it would request a frequency by calling the frequency:allocate()
function. This function sends a message of the format {request, Pid, allocate} to the frequency
server, pattern matching in the first clause of the receive statement. This message will result in
the server function allocate(Frequencies, Pid) being
called, where Frequencies is the loop
data containing a tuple of allocated and available frequencies. The
allocate function (defined shortly)
will check whether there are any available frequencies:
If so, it will return the updated loop data, where the newly allocated frequency has been moved from the available list and stored together with the pid in the list of allocated ones. The reply sent to the client is of the format
{ok, Frequency}.If no frequencies are available, the loop data is returned unchanged and the
{error, no_frequency}message is returned as a reply.
The Reply is sent to the
reply(Pid, Message) call, which
formats it to the internal client/server message format and sends it
back to the client. The function then calls loop/1 recursively,
passing the new loop data as an argument.
Deallocation works in a similar way. The
client function results in the message {request, Pid, deallocate} being sent and
matched in the second clause of the receive statement. This makes a call to
deallocate(Frequencies, Frequency)
and the deallocate function moves the
Frequency from the allocated list to
the deallocated one, returning the updated loop data. The atom ok is sent back to the client, and the loop/1
function is called recursively with the updated loop
data.
If the stop request is
received, ok is returned to the
calling process and the server terminates, as there is no more code to
execute. In the previous two clauses, loop/1 was called in the final expression of
the case clause, but not in this
case.
We complete this system by implementing the allocation and deallocation functions:
%% The Internal Help Functions used to allocate and
%% deallocate frequencies.
allocate({[], Allocated}, _Pid) ->
{{[], Allocated}, {error, no_frequency}};
allocate({[Freq|Free], Allocated}, Pid) ->
{{Free, [{Freq, Pid}|Allocated]}, {ok, Freq}}.
deallocate({Free, Allocated}, Freq) ->
NewAllocated=lists:keydelete(Freq, 1, Allocated),
{[Freq|Free], NewAllocated}.The allocate/2 and
deallocate/2 functions are local to
the frequency module, and are what we
refer to as internal help functions:
If there are no available frequencies,
allocate/2will pattern-match in the first clause, as the first element of the tuple containing the list of available frequencies is empty. This clause returns the{error, no_frequency}tuple alongside the unchanged loop data.If there is at least one available frequency, the second clause will match successfully. The frequency is removed from the list of available ones, paired up with the client pid, and moved to the list of allocated frequencies.
The updated frequency data is returned by the allocate function. Finally, deallocate will remove the newly freed
frequency from the list of allocated ones using the lists:keydelete/3
library function and concatenate it to the list of available frequencies.
This frequency allocator example has used all of the key sequential and concurrent programming concepts we have covered so far. They include pattern matching, recursion, library functions, process spawning, and message passing. Spend some time making sure you understand them. You should test the example using the debugger and the process manager, following the message passing protocols between the client and server and the sequential aspects of the loop function. You can see an example of the frequency allocator in action now:
1>c(frequency).{ok,frequency} 2>frequency:start().true 3>frequency:allocate().{ok,10} 4>frequency:allocate().{ok,11} 5>frequency:allocate().{ok,12} 6>frequency:allocate().{ok,13} 7>frequency:allocate().{ok,14} 8>frequency:allocate().{ok,15} 9>frequency:allocate().{error,no_frequency} 10>frequency:deallocate(11).ok 11>frequency:allocate().{ok,11} 12>frequency:stop().ok
A Process Pattern Example
Now let’s look at similarities between the client-server example we just described and the process skeleton we introduced in Chapter 4. Picture an application, either a web browser or a word processor, which handles many simultaneously open windows centrally controlled by a window manager. As we aim to have a process for each truly concurrent activity, spawning a process for every window is the way to go. These processes would probably not be registered, as many windows of the same type could be running concurrently.
After being spawned, each process would call the initialize
function, which draws and displays the window and its contents. The return
value of the initialize function
contains references to the widgets displayed in the window. These
references are stored in the state variable and are used whenever the
window needs updating. The state variable is passed as an argument to a
tail-recursive function that implements the receive-evaluate loop.
In this loop function, the process waits for events originating in
or relating to the window it is managing. It could be a user typing in a
form or choosing a menu entry, or an external process pushing data that
needs to be displayed. Every event relating to this window is translated
to an Erlang message and sent to the process. The process, upon receiving
the message, calls the handle function,
passing the message and state as arguments. If the event were the result
of a few keystrokes typed in a form, the handle function might want to display them. If
the user picked an entry in one of the menus, the handle function would
take appropriate actions in executing that menu choice. Or, if the event
was caused by an external process pushing data, possibly an image from a
webcam or an alert message, the appropriate widget would be updated. The
receipt of these events in Erlang would be seen as a generic pattern in
all processes. What would be considered specific and change from process
to process is how these events are handled.
Finally, what if the process receives a stop message? This message might have originated
from a user picking the Exit menu entry or clicking the Destroy button, or
from the window manager broadcasting a notification that the application
is being shut down. Regardless of the reason, a stop message is sent to the process. Upon
receiving it, the process calls a terminate function,
which destroys all of the widgets, ensuring that they are no longer
displayed. After the window has been shut down, the process terminates
because there is no more code to execute.
Look at the following process skeleton. Could you not fit all of the
specific code into the initialize/1,
handle_msg/2, and terminate/1 functions?
-module(server).
-export([start/2, stop/1, call/2]).
-export([init/1]).
start(Name, Data) ->
Pid = spawn(generic_handler, init,[Data])
register(Name, Pid), ok.
stop(Name) ->
Name ! {stop, self()},
receive {reply, Reply} -> Reply end.
call(Name, Msg) ->
Name ! {request, self(), Msg},
receive {reply, Reply} -> Reply end.
reply(To, Msg) ->
To ! {reply, Msg}.
init(Data) ->
loop(initialize(Data)).
loop(State) ->
receive
{request, From, Msg} ->
{Reply,NewState} = handle_msg(Msg, State),
reply(From, Reply),
loop(NewState);
{stop, From} ->
reply(From, terminate(State))
end.
initialize(...) -> ...
handle_msg(...,...) -> ...
terminate(...) -> ...Using the generic code in the preceding skeleton, let’s go through the GUI example one last time:
The
initializefunction draws the window and displays it, returning a reference to the widget that gets bound to thestatevariable.Every time an event arrives in the form of an Erlang message, the event is taken care of in the
handle_msgfunction. The call takes the message and the state as arguments and returns an updatedStatevariable. This variable is passed to the recursiveloopcall, ensuring that the process is kept alive. Any reply is also sent back to the process where the request originated.If the
stopmessage is received,terminateis called, destroying the window and all the widgets associated with it. Theloopfunction is not called, allowing the process to terminate normally.
Finite State Machines
Erlang processes can be used to implement finite state machines. A finite state machine, or FSM for short, is a model that consists of a finite number of states and events. You can think of an FSM as a model of the world which will contain abstractions from the details of the real system. At any one time, the FSM is in a specific state. Depending on the incoming event and the current state of the FSM, a set of actions and a transition to a new state will occur (see Figure 5-5).

In Erlang, each state is represented as a tail-recursive function,
and each event is represented as an incoming message. When a message is
received and matched in a receive
clause, a set of actions are executed. These actions are followed by a
state transition achieved by calling the function corresponding to the new
state.
An FSM Example
As an example, think of modeling a fixed-line phone as a finite
state machine (see Figure 5-6). The phone can be in
the idle state when it is plugged in
and waiting either for an incoming phone call or for a user to take it
off the hook. If you receive an incoming call from your aunt,[17] the phone will start ringing. Once it has started ringing,
the state will change from idle to
ringing and will wait for one of two
events. You can pretend to be asleep, hopefully resulting in your aunt
giving up on you and putting the phone on her end back on the hook. This
will result in the FSM going back to the idle state (and you going back to
sleep).
If instead of ignoring it, you take your phone off the hook, it
would stop ringing and the FSM would move to the connected state, leaving you to talk to your
heart’s content. When you are done with the call and hang up, the state
reverts to idle.

If the phone is in the idle
state and you take it off the hook, a dial tone is started. Once the
dial tone has started, the FSM changes to the dial state and you enter your aunt’s phone
number. Either you can hang up and your FSM goes back to the idle state, or your aunt picks up and you go
to the connected state.
State machines are very common in all sorts of processing applications. In telecom systems, they are used not only to handle the state of equipment, as in the preceding example, but also in complex protocol stacks. The fact that Erlang handles them graciously is not a surprise. When prototyping with the early versions of Erlang between 1987 and 1991, it was the Plain Old Telephony System (POTS) finite state machines described in this section that the development team used to test their ideas of what Erlang should look like.
With a tail-recursive function for every state, actions
implemented as function calls, and events represented as messages, this
is what the code for the idle state
would look like:
idle() ->
receive
{Number, incoming} ->
start_ringing(),
ringing(Number);
off_hook ->
start_tone(),
dial()
end.
ringing(Number) ->
receive
{Number, other_on_hook} ->
stop_ringing(),
idle();
{Number, off_hook} ->
stop_ringing(),
connected(Number)
end.
start_ringing() -> ...
start_tone() -> ...
stop_ringing() -> ...We leave the coding of the functions for the other states as an exercise.
A Mutex Semaphore
Let’s look at another example of a finite state machine, this time implementing a mutex semaphore. A semaphore is a process that serializes access to a particular resource, guaranteeing mutual exclusion. Mutex semaphores might not be the first thing that comes to mind when working with Erlang, as they are commonly used in languages with shared memory. However, they can be used as a general mechanism for managing any resource, not just memory.
Assume that only one process at a time is allowed to use the file
server, thus guaranteeing that no two processes are simultaneously
reading or writing to the same file. Before making any calls to the file
server, the process wanting to access the file calls the mutex:wait() function,
putting a lock on the server. When the process has finished handling the
files, it calls the function mutex:signal(),
removing the lock (see Figure 5-7).

If a process called PidB tries to call mutex:wait() when the semaphore is busy with
PidA, PidB is
suspended in its receive clause until
PidA calls signal/0. The semaphore becomes available, and
the process whose wait message is first in the message queue,
PidB in our case, will be allowed to access the file
server. The message sequence diagram in Figure 5-8 demonstrates
this.

Look at the following code to get a feel for how to use
tail-recursive functions to denote the states, and messages to denote
events. And before reading on, try to figure out what the terminate function should do to clean up when
the mutex is terminated.
-module(mutex).
-export([start/0, stop/0]).
-export([wait/0, signal/0]).
-export([init/0]).
start() ->
register(mutex, spawn(?MODULE, init, [])).
stop() ->
mutex ! stop.
wait() ->
mutex ! {wait, self()},
receive ok -> ok end.
signal() ->
mutex ! {signal, self()}, ok.
init() ->
free().
free() ->
receive
{wait, Pid} ->
Pid ! ok,
busy(Pid);
stop ->
terminate()
end.
busy(Pid) ->
receive
{signal, Pid} ->
free()
end.
terminate() ->
receive
{wait, Pid} ->
exit(Pid, kill),
terminate()
after
0 -> ok
end.The stop/0 function sends a
stop message that is handled only in the free state. Prior to terminating the mutex
process, all processes that are waiting for or holding the semaphore are
allowed to complete their tasks. However, any process that attempts to
wait for the semaphore after stop/0
is called will be killed unconditionally in the terminate/0 function.
Event Managers and Handlers
Try to picture a process that receives trace events generated in your system. You might want to do many things with these trace events, but you might not necessarily want to do all of them at the same time. You probably want to log all the trace events to file. If you are in front of the console, you might want to print them to standard I/O. You might be interested in statistics to determine how often certain errors occur, or if the event requires some action to be taken, you might want to send an SMS or SNMP[18] trap.
At any one time, you will want to execute some, if not all, of these actions, and toggle between them. But if you walk away from your desk, you might want to turn the logging to the console off while maintaining the gathering of statistics and logging to file.
An event manager does what we just described. It is a process that receives a specific type of event and executes a set of actions determined by the type of event. These actions can be added and removed dynamically throughout the lifetime of the process, and are not necessarily defined or known when the code implementing the process is first written. They are collected in modules we call the event handlers.
Large systems usually have an event manager for every type of event. Event types commonly include alarms, equipment state changes, errors, and trace events, just to mention a few. When they are received, one or more actions are applied to each event.
The most common form of event manager found in almost all industrial-grade systems handles alarms (see Figure 5-9). Alarms are raised when a problem occurs and are cleared when it goes away. They might require automated or manual intervention, but this is not always the case. An alarm would be raised if the data link between two devices is lost and be cleared if it recovers. Other examples include a cabinet door being opened, a fan breaking, or a TCP/IP connection being lost.
The alarm handler will often log these alarms, collect statistics, and filter and forward them to agents. Agents might receive the events and try to resolve the issues themselves. If a communication link is down, for example, an agent would automatically try to reconfigure the system to use the standby link, requesting human intervention only if the standby link goes down as well.
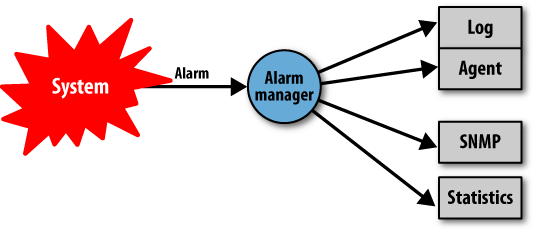
A Generic Event Manager Example
Here is an example of an event manager that allows you to add and remove handlers during runtime. The code is completely generic and independent of the individual handlers. Handlers can be implemented in separate modules and have to export a number of functions, referred to as callback functions. These functions can be called by the event manager. We will cover them in a minute. Let’s first look at how we’ve implemented the event manager, starting with its client functions:
start(Name, HandlerList)Will start a generic event manager, registering it with the alias
Name.HandlerListis a list of tuples of the form{Handler, Data}, whereHandleris the name of the handler callback module andDatais the argument passed to the handler’sinitcallback function.HandlerListcan be empty at startup, as handlers can be subsequently added using theadd_handler/2call.stop(Name)Will terminate all the handlers and stop the event manager process. It will return a list of items of the form
{Handler, Data}, whereDatais the return value of theterminatecallback function of the individual handlers.add_handler(Name, Handler, Data)Will add the handler defined in the callback module
Handler, passingDataas an argument to the handler’sinitcallback function.delete_handler(Name, Handler)Will remove the handler defined in the callback module
Handler. The handler’sterminatecallback function will be called, and its return value will be the return value of this call. This call returns the tuple{error, instance}ifHandlerdoes not exist.get_data(Name, Handler)Will return the contents of the state variable of the
Handler. This call returns the tuple{error, instance}ifHandlerdoes not exist.send_event(Name, Event)
Here is the code for the generic event manager module:
-module(event_manager).
-export([start/2, stop/1]).
-export([add_handler/3, delete_handler/2, get_data/2, send_event/2]).
-export([init/1]).
start(Name, HandlerList) ->
register(Name, spawn(event_manager, init, [HandlerList])), ok.
init(HandlerList) ->
loop(initialize(HandlerList)).
initialize([]) -> [];
initialize([{Handler, InitData}|Rest]) ->
[{Handler, Handler:init(InitData)}|initialize(Rest)].Here is an explanation of what the code is doing:
The
start(Name, HandlerList)function spawns the event manager process and registers it with the aliasName.The newly spawned process starts executing in the
init/1function with aHandlerListtuple list of the format{Handler, Data}as an argument.We traverse the list in the
initialize/1function callingHandler:init(Data)for every entry.The result of this call is stored in a list of the format
{Handler, State}, whereStateis the return value of theinitfunction.This list is passed as an argument to the event manager’s
loop/1function.
When stopping the event manager process, we send a stop message received in the loop/1 function. If you are looking for
loop/1, you will find it with the
generic code at the end of this module. Receiving the stop message results in terminate/1 traversing the list of handlers
and calling Handler:terminate(Data)
for every entry. The return value of these calls, a list of the format
{Handler, Value}, is sent back to the
process that originally called stop/1
and becomes the return value of this function:
stop(Name) ->
Name ! {stop, self()},
receive {reply, Reply} -> Reply end.
terminate([]) -> [];
terminate([{Handler, Data}|Rest]) ->
[{Handler, Handler:terminate(Data)}|terminate(Rest)].Now we’ll look at the client functions used to add, remove, and
inspect the event handlers, as well as forwarding them the events.
Through the call/2 function, they
send the request to the event manager process which handles them in
handle_msg/2. Pay particular
attention to the send_event/2 call,
which traverses the list of handlers, calling the callback function
Handler:handle_event(Event, Data).
The return value of this call replaces the old Data and is used by the handler the next time
one of its callbacks is invoked:
add_handler(Name, Handler, InitData) ->
call(Name, {add_handler, Handler, InitData}).
delete_handler(Name, Handler) ->
call(Name, {delete_handler, Handler}).
get_data(Name, Handler) ->
call(Name, {get_data, Handler}).
send_event(Name, Event) ->
call(Name, {send_event, Event}).
handle_msg({add_handler, Handler, InitData}, LoopData) ->
{ok, [{Handler, Handler:init(InitData)}|LoopData]};
handle_msg({delete_handler, Handler}, LoopData) ->
case lists:keysearch(Handler, 1, LoopData) of
false ->
{{error, instance}, LoopData};
{value, {Handler, Data}} ->
Reply = {data, Handler:terminate(Data)},
NewLoopData = lists:keydelete(Handler, 1, LoopData),
{Reply, NewLoopData}
end;
handle_msg({get_data, Handler}, LoopData) ->
case lists:keysearch(Handler, 1, LoopData) of
false -> {{error, instance}, LoopData};
{value, {Handler, Data}} -> {{data, Data}, LoopData}
end;
handle_msg({send_event, Event}, LoopData) ->
{ok, event(Event, LoopData)}.
event(_Event, []) -> [];
event(Event, [{Handler, Data}|Rest]) ->
[{Handler, Handler:handle_event(Event, Data)}|event(Event, Rest)].The following code, together with the start and stop functions we already covered, is a direct
rip off from the process pattern example. By now, you should have
spotted the recurring theme—processes that handle very
different tasks do so in similar ways, following a
pattern:
call(Name, Msg) ->
Name ! {request, self(), Msg},
receive {reply, Reply} -> Reply end.
reply(To, Msg) ->
To ! {reply, Msg}.
loop(State) ->
receive
{request, From, Msg} ->
{Reply, NewState} = handle_msg(Msg, State),
reply(From, Reply),
loop(NewState);
{stop, From} ->
reply(From, terminate(State))
end.Event Handlers
In our event manager implementation, our event handlers have to export the following three callback functions:
init(InitData)Initializes the handler and returns a value that is used the next time a callback function belonging to the handler is invoked.
terminate(Data)Allows the handler to clean up. If we have opened files or sockets in the
init/1callback, they would be closed here. The return value ofterminate/1is passed back to the functions that originally instigated the removal of the handler. In our event manager example, they are thedelete_handler/2andstop/1calls.handle_event(Event, Data)Is called when an event is forwarded to the event manager through the
send_event/2call. Its return value will be used the next time a callback function for this handler is invoked.
Using these callback functions, let’s write two handlers—one that pretty-prints the events to the shell, and one that logs the events to file.
The io_handler event
handler filters out events of the format {raise_alarm, Id, Type} and {clear_alarm, Id, Type}. All other events are
ignored. In the init/1 function, we
set a counter which is incremented every time an event is
handled.
The handle_event/2
callback uses this counter every time an alarm event is received,
displaying it together with information on the alarm:
-module(io_handler).
-export([init/1, terminate/1, handle_event/2]).
init(Count) -> Count.
terminate(Count) -> {count, Count}.
handle_event({raise_alarm, Id, Alarm}, Count) ->
print(alarm, Id, Alarm, Count),
Count+1;
handle_event({clear_alarm, Id, Alarm}, Count) ->
print(clear, Id, Alarm, Count),
Count+1;
handle_event(Event, Count) ->
Count.
print(Type, Id, Alarm, Count) ->
Date = fmt(date()), Time = fmt(time()),
io:format("#~w,~s,~s,~w,~w,~p~n",
[Count, Date, Time, Type, Id, Alarm]).
fmt({AInt,BInt,CInt}) ->
AStr = pad(integer_to_list(AInt)),
BStr = pad(integer_to_list(BInt)),
CStr = pad(integer_to_list(CInt)),
[AStr,$:,BStr,$:,CStr].
pad([M1]) -> [$0,M1];
pad(Other) -> Other.The second handler that we implement logs all the events of the
format {EventType, Id, Description}
in a comma-separated file, ignoring everything else that is not a tuple
of size 3.
We open the file in the init/1 function, write
to it in handle_event/2, and close it
in the terminate function. As this
file will probably be read and manipulated by other programs, we will
provide more detail in the information we write to it and spend less
effort with its formatting. Instead of time() and date(), we use the now() BIF which gives us a timestamp with a
much higher level of accuracy. It returns a tuple containing the mega
seconds, seconds, and microseconds that have elapsed since January 1,
1970. When the log_handler is deleted
from the event manager, the terminate/2 call
will close the file:
-module(log_handler).
-export([init/1, terminate/1, handle_event/2]).
init(File) ->
{ok, Fd} = file:open(File, write),
Fd.
terminate(Fd) -> file:close(Fd).
handle_event({Action, Id, Event}, Fd) ->
{MegaSec, Sec, MicroSec} = now(),
Args = io:format(Fd, "~w,~w,~w,~w,~w,~p~n",
[MegaSec, Sec, MicroSec, Action, Id, Event]),
Fd;
handle_event(_, Fd) ->
Fd.Try out the event manager and the two handlers we’ve implemented
in the shell. We start the event manager with the log_handler, after which we add and delete the
io_handler. In between, we generate a
few alarms and test the other client functions we’ve implemented in the
event manager work:
1>event_manager:start(alarm, [{log_handler, "AlarmLog"}]).ok 2>event_manager:send_event(alarm, {raise_alarm, 10, cabinet_open}).ok 3>event_manager:add_handler(alarm, io_handler, 1).ok 4>event_manager:send_event(alarm, {clear_alarm, 10, cabinet_open}).#1,2009:03:16,08:33:14,clear,10,cabinet_open ok 5>event_manager:send_event(alarm, {event, 156, link_up}).ok 6>event_manager:get_data(alarm, io_handler).{data,2} 7>event_manager:delete_handler(alarm, stats_handler).{error,instance} 8>event_manager:stop(alarm).[{io_handler,{count,2}},{log_handler,ok}]
Exercises
Exercise 5-1: A Database Server
Write a database server that stores a database in its loop data.
You should register the server and access its services through a
functional interface. Exported functions in the my_db.erl module should include:
my_db:start() ⇒ ok.
my_db:stop() ⇒ ok.
my_db:write(Key, Element) ⇒ ok.
my_db:delete(Key) ⇒ ok.
my_db:read(Key) ⇒ {ok, Element} | {error, instance}.
my_db:match(Element) ⇒ [Key1, ..., KeyN].Hint: use the db.erl module as
a backend and use the server skeleton from the echo server from Exercise
4-1 in Chapter 4. Example:
1>my_db:start().ok 2>my_db:write(foo, bar).ok 3>my_db:read(baz).{error, instance} 4>my_db:read(foo).{ok, bar} 5>my_db:match(bar).[foo]
Exercise 5-2: Changing the Frequency Server
Using the frequency server example in this chapter, change the code to ensure that only the client who allocated a frequency is allowed to deallocate it. Make sure that deallocating a frequency that has not been allocated does not make the server crash.
Hint: use the self() BIF in the
allocate and deallocate functions called by the
client.
Extend the frequency server so that it can be stopped only if no frequencies are allocated.
Finally, test your changes to see whether they still allow
individual clients to allocate more than one frequency at a time. This
was previously possible by calling allocate_frequency/0 more than once.
Limit the number of frequencies a client can allocate to three.
Exercise 5-3: Swapping Handlers
What happens if you want to close and open a new file in the log_handler? You would have to call event_manager:delete_handler/2 immediately
followed by event_manager:add_handler/2. The risk
with this is that in between these two calls, you might miss an event.
Therefore, implement the following function:
event_manager:swap_handlers(Name, OldHandler, NewHandler)
which swaps the handlers atomically, ensuring that no events are
lost. To ensure that the state of
the handlers is maintained, pass the return value of OldHandler:terminate/1 to the
NewHandler:init/1 call.
Exercise 5-4: Event Statistics
Write a stats_handler module
that takes the first and second elements of the event tuple {Type, Id, Description} in our example and
keep a count of how many times the combination of {Type, Description} occurs. Users should be
able to retrieve these statistics by using the client function event_manager:get_data/2.