
Chapter 6. Process Error Handling
Whatever the programming language, building distributed, fault-tolerant, and scalable systems with requirements for high availability is not for the faint of heart. Erlang’s reputation for handling the fault-tolerant and high-availability aspects of these systems has its foundations in the simple but powerful constructs built into the language’s concurrency model. These constructs allow processes to monitor each other’s behavior and to recover from software faults. They give Erlang a competitive advantage over other programming languages, as they facilitate development of the complex architecture that provides the required fault tolerance through isolating errors and ensuring nonstop operation. Attempts to develop similar frameworks in other languages have either failed or hit a major complexity barrier due to the lack of the very constructs described in this chapter.
Process Links and Exit Signals
You might have heard of the “let it crash and let someone else deal with
it” and “crash early” approaches. That’s the Erlang way! If something goes
wrong, let your process terminate as soon as possible and let another
process deal with the problem. The link/1 BIF will have been used by this
other process to allow it to monitor and detect abnormal terminations and
handle them generically.
The link/1 BIF takes a pid
as an argument and creates a bidirectional link between the calling
process and the process denoted by the pid. The spawn_link/3 BIF will
yield the same result as calling spawn/3 followed by link/1, except that it will do so
atomically (i.e., in a single step, so either both
calls succeed or neither one does). In diagrams of Erlang processes, you
denote processes linked to each other with a line, as shown in Figure 6-1.

As links are bidirectional, it does not matter whether process A linked to process B or B to A; the result will be the same. If a linked process terminates abnormally, an exit signal will be sent to all the processes to which the failing process is linked. The process receiving the signal will exit, propagating a new exit signal to the processes that it is linked to (this collection is also know as its link set).
The exit signal is a tuple of the format {'EXIT', Pid, Reason}, containing the atom
'EXIT', the Pid of the terminating process, and the Reason for its termination. The process on the
receiving end will terminate with the same reason and propagate a new exit
signal with its own pid to all the processes in its link set, as shown in
Figure 6-2.

When process A fails, its exit signal propagates to process B. Process B terminates with the same reason as A, and its exit signal propagates to process C (see Figure 6-3). If you have a group of mutually dependent processes in a system, it is a good design practice to link them together to ensure that if one terminates, they will all terminate.

Type the following example in an editor, or download it from the
book’s website. It is a simple
program that spawns a process that links to its parent. When sent an
integer N by the process in the message
{request, Pid, N}, the process adds one
to N and returns the result to the
Pid. If it takes more than one second
to compute the result, or if the process crashes, the request/1 function
returns the atom timeout. There are no
checks to the arguments passed to request/1, so sending anything but an integer
will cause a runtime error that terminates the process. As the process is
linked to its parent, the exit signal will propagate to the parent and
terminate it with the same reason:
-module(add_one).
-export([start/0, request/1, loop/0]).
start() ->
register(add_one, spawn_link(add_one, loop, [])).
request(Int) ->
add_one ! {request, self(), Int},
receive
{result, Result} -> Result
after 1000 -> timeout
end.
loop() ->
receive
{request, Pid, Msg} ->
Pid ! {result, Msg + 1}
end,
loop().Test this program by sending it a noninteger, and see how the shell
reacts. In the example that follows, we send the atom one, causing the process to crash. As the
add_one process is linked to the shell,
the propagation of the exit signal will cause the shell process to
terminate as well. The error report shown in the shell comes from the add_one process, while the exception exit printout comes from the shell
itself. Note how we get a different pid when calling the self() BIF before and
after the crash, indicating that the shell process has been
restarted:
1>self().<0.29.0> 2>add_one:start().true 3>add_one:request(1).2 4>add_one:request(one).=ERROR REPORT==== 21-Jul-2008::16:29:38 === Error in process <0.37.0> with exit value: {badarith,[{add_one,loop,0}]} ** exception exit: badarith in function add_one:loop/0 5>self().<0.40.0>
So far, so good, but you are now probably asking yourself how a process can handle abnormal terminations and recovery strategies if the only thing it can do when it receives an exit signal is to terminate itself. The answer is by trapping exits.
Trapping Exits
Processes can trap exit signals by setting
the process flag trap_exit, and by executing the function
call process_flag(trap_exit,
true). The call is usually made in the initialization
function, allowing exit signals to be converted to messages of the
format {'EXIT', Pid, Reason}. If a
process is trapping exits, these messages are saved in the process
mailbox in exactly the same way as other messages. You can retrieve
these messages using the receive
construct, pattern matching on them like any other message.
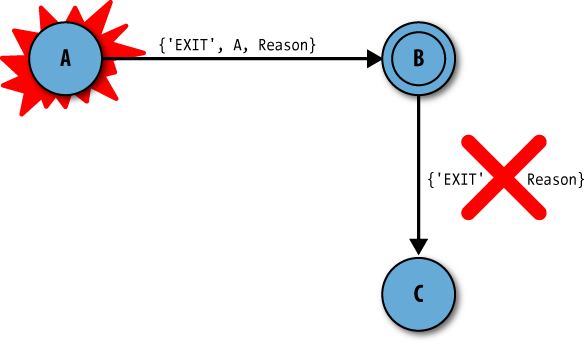
If an exit signal is trapped, it does not propagate further. All processes in its link set, other than the one that terminated, are not affected. You usually denote processes that are trapping exits with a double circle, as shown in Figure 6-4.

Let’s take a specific example, shown in Figure 6-5. Process B, marked with a
double circle, is trapping exits. If a runtime error occurs in process
A, it will terminate and send out an exit signal of the format {'EXIT', A, Reason}, where A is the pid of the process that has failed
and Reason is the reason for its
termination. The atom 'EXIT' is used
to tag the tuple and facilitate pattern matching. This message is stored
in process B’s mailbox without affecting C. Unless B explicitly informs
C that A has terminated, C will never know.
Let’s revisit the add_one
example, letting the shell trap exits. The result, instead of a crash,
should be an 'EXIT' message sent to
the shell. You can retrieve this signal using the flush/0 command, as it will not pattern-match
against any of the receive clauses in
the request
function:
1>process_flag(trap_exit, true).false 2>add_one:start().true 3>add_one:request(one).=ERROR REPORT==== 21-Jul-2008::16:44:32 === Error in process <0.37.0> with exit value: {badarith,[{add_one,loop,0}]} timeout 4>flush().Shell got {'EXIT',<0.37.0>,{badarith,[{add_one,loop,0}]}} ok
It is also possible to explicitly catch the exit message sent to
the shell. In the following variant of the earlier program, the request function has an additional pattern
match over {'EXIT',_,_} to trap the
exit message from the loop() process:
-module(add_two).
-export([start/0, request/1, loop/0]).
start() ->
process_flag(trap_exit, true),
Pid = spawn_link(add_two, loop, []),
register(add_two, Pid),
{ok, Pid}.
request(Int) ->
add_two ! {request, self(), Int},
receive
{result, Result} -> Result;
{'EXIT', _Pid, Reason} -> {error, Reason}
after 1000 -> timeout
end.
loop() ->
receive
{request, Pid, Msg} ->
Pid ! {result, Msg + 2}
end,
loop().Note how we call process_flag(trap_exit,
true) in the start/0
function. Run the program and you should observe the following
output:
1>c(add_two).{ok, add_two} 2>add_two:start().{ok, <0.119.0>} 3>add_two:request(6).8 4>add_two:request(six).{error,{badarith,[{add_two,loop,0}]}} =ERROR REPORT==== 24-Aug-2008::18:59:30 === Error in process <0.36.0> with exit value: {badarith,[{add_two,loop,0}]}
The response to command 4 in the shell comes from matching the
{'EXIT',_,_} raised when loop() fails on the atom six.
If you want to stop trapping exits, use process_flag(trap_exit, false). It is
considered a bad practice to toggle the trap_exit flag, as it makes your program hard
to debug and maintain. The trap_exit
flag is set to false by default when
a process is spawned.
The monitor BIFs
Links are bidirectional. When the need arose to monitor processes
unidirectionally, the erlang:monitor/2 BIF
was added to Erlang. When you call the following:
erlang:monitor(process, Proc)
a monitor is created from the calling process to the process
denoted by Proc, where Proc can be either a process identifier or a
registered name. When the process with the pid terminates, the message
{'DOWN',Reference,process,Pid,Reason}
is sent to the monitoring process. This message includes a
reference to the monitor. References, which we
cover in more detail in Chapter 9, are (essentially)
unique values that you can use to identify entities such as responses to
particular requests; you can compare references for equality and use
them in pattern-matching definitions.
If you try to link to a nonexistent process, the calling process
terminates with a runtime error. The monitor BIF behaves differently. If Pid has already terminated (or never existed)
when monitor is called, the 'DOWN' message is immediately sent with the
Reason set to noproc. Repeated calls to erlang:monitor(process,Pid) will return
different references, creating multiple independent
monitors. They will all send their 'DOWN' message when Pid terminates.
Monitors are removed by calling erlang:demonitor(Reference). The 'DOWN' message could have been sent right
before the call to demonitor, so the
process using the monitor should not forget to flush its mailbox. To be
on the safe side, you can use erlang:demonitor(Reference, [flush]),
which will turn off the monitor while removing any 'DOWN' message from the Reference provided.
In the following example, we spawn a process that crashes
immediately, as the module it is supposed to execute does not exist. We
start monitoring it and immediately receive the 'DOWN' message. When retrieving the message,
we pattern-match on both the Reference and the Pid, returning the reason for termination.
Notice that the reason is noproc, the
error stating that process Pid does
not exist: compare this with the runtime error we get when trying to
link to a nonexistent process:
1>Pid = spawn(crash, no_function, []).=ERROR REPORT==== 21-Jul-2008::15:32:02 === Error in process <0.32.0> with exit value: {undef,[{crash,no_function,[]}]} <0.32.0> 2>Reference = erlang:monitor(process, Pid).#Ref<0.0.0.31> 3>receive{'DOWN',Reference,process,Pid,Reason} -> Reason end. noproc 4>link(Pid).** exception error: no such process or port in function link/1 called as link(<0.32.0>)
When would you pick monitoring over linking? Links are established permanently, as in supervision trees, or when you want the propagation path of the exit signal to be bidirectional. Monitors are ideal for monitoring the client call to a behavior process, where you do not want to affect the state of the process you are calling and don’t want it to receive an exit signal if the client terminates as a result of a link to another process.
The exit BIFs
The BIF call exit(Reason) causes
the calling process to terminate, with the reason for termination being
the argument passed to the BIF. The terminating process will generate an exit signal that is
sent to all the processes to which it is linked. If exit/1 is called within the scope of a
try...catch construct (see Figure 6-6), it can be caught, as it can within
a catch itself.

If you want to send an exit signal to a particular
process, you call the exit
BIF using exit(Pid, Reason), as shown
in Figure 6-7. The result is almost the
same as the message sent by a process to its link set on termination,
except that the Pid in the {'EXIT',Pid,Reason} signal is the process
identifier of the receiving process itself, rather than the process that
has terminated. If the receiving process is trapping exits, the signal
is converted to an exit message and stored in the process mailbox. If
the process is not trapping exits and the reason is not normal, it will terminate and propagate an
exit signal. Exit signals sent to a process cannot be caught with a
catch and will result in the process
terminating. We discuss propagation of errors in more detail in the
section Propagation Semantics.

BIFs and Terminology
Before trying some examples and looking at these constructs in more depth, let’s review the terminology and the most important BIFs dealing with termination:
The BIFs that are related to concurrent error handling include:
link(Pid)Sets a bidirectional link between the calling process and
Pid.unlink(Pid)spawn_link(Mod, Fun, Args)Atomically spawns and sets a link between the calling process and the spawned process.
spawn_monitor(Mod, Fun, Args)Atomically spawns and sets a monitor between the calling process and the spawned process.
process_flag(trap_exit, Flag)Sets the current process to convert exit signals to exit messages. The
Flagcontains the atomstrue(turning on exit trapping) andfalse(turning it off).erlang:monitor(process,Pid)Creates a unidirectional monitor toward
Pid. It returns a reference to the calling process; this reference can be used to identify the terminated process in a pattern match.erlang:demonitor(Reference)Clears the monitor so that monitoring no longer takes place. Don’t forget to flush messages that might have arrived prior to calling the
demonitorBIF.erlang:demonitor(Reference,[flush])Is the same as
demonitor/1, but removes the{_,Reference,_,_,_}message if it was sent as a result of a race condition.exit(Reason)exit(Pid,Reason)Sends an exit signal to
Pid.
Even in code written using monitor and link, race conditions can occur. Look at the
following code fragments. The first statement spawns a child, binds the
process identifier to the variable Pid, and allows the process executing the code
to link to it:
link(Pid = spawn(Module, Function, Args))
The second statement spawns a child, links to it, and binds the
process identifier to the variable Pid:
Pid = spawn_link(Module, Function, Args)
At first sight, both examples appear to do the same thing, except
that spawn_link/3 does it
atomically. By atomic operation, we mean an
operation that has to be completed before the process can be suspended.
When dealing with concurrency, what is apparently a small detail, such
as whether an operation is atomic, can make all the difference in how
your program behaves:
If you use
spawn_link/3, the process is spawned and linked to the parent. This operation cannot be suspended in between thespawnand thelink, as all BIFs are atomic. The earliest the process can be suspended is after executing the BIF.If you instead execute
spawnandlinkas two separate operations, the parent process callingspawnmight get suspended right after spawning the process and binding the variablePid, but before callinglink/1. The new process starts executing, encounters a runtime error, and terminates. The parent process is preempted, and the first thing it does is to link to a nonexistent process. This will result in a runtime error instead of an exit signal being received.
This problem is similar to the example of race conditions that we
looked at in Chapter 4, where the
outcome may vary depending on the order of events, itself a consequence
of where the processes are suspended and which core they are running on.
A rule of thumb is to always use spawn_link unless you are toggling between
linking and unlinking to the process, or if it is not a child process
you are linking to. Before going on to the next section, ask yourself
how to solve the preceding problem using the monitor BIF.
Propagation Semantics
Now that we have covered the most important terminology and BIFs, let’s
look at the details of the propagation semantics associated with the
exit signals as summarized in Table 6-1. When a process terminates it
sends an exit signal to the processes in its link set. These exit
signals can be normal or
nonnormal. Normal exit signals are generated either
when the process terminates because there is no more code to execute, or
by calling the exit BIFs with the reason normal.
A process that is not trapping exit signals terminates if it
receives a nonnormal exit signal. Exit signals with reason normal are ignored. A process that is trapping
exit signals converts all incoming exit signals, normal and nonnormal,
to conventional messages that are stored in the mailbox and handled in a
receive statement.
If Reason in any of the exit
BIFs is kill, the process is
terminated unconditionally, regardless of the trap_exit flag.[19] An exit signal is propagated to processes in its linked
set with reason killed. This will
ensure that processes trapping exits are not terminated if one of the
peers in its link set is killed unconditionally.
Robust Systems
In Erlang, you build robust systems by layering. Using processes, you create a tree in which the leaves consist of the application layer that handles the operational tasks while the interior nodes monitor the leaves and other nodes below them, as shown in Figure 6-8. Processes at any level will trap errors occurring at a level immediately below them. A process whose only task is to supervise children—in our case the nodes of the tree—is called a supervisor. A leaf process performing operational tasks is called a worker. When we refer to child processes, we mean both supervisors and workers belonging to a particular supervisor.
In well-designed systems, application programmers will not have to worry about error-handling code. If a worker crashes, the exit signal is sent to its supervisor, which isolates it from the higher levels of the system. Based on a set of preconfigured parameters and the reason for termination, the supervisor will decide whether the worker should be restarted.
Supervisors aren’t the only processes that might want to monitor other processes, however. If a process has a dependency on another process that is not necessarily its child, it will want to link itself to it. Upon abnormal termination, both processes can take appropriate action.

In large Erlang systems, you should never allow processes that are not part of a supervision tree; all processes should be linked either to a supervisor or to another worker. As Erlang programs will run for years without having to be restarted, millions, if not billions, of processes will be created throughout the system’s lifetime. You need to have full control of these processes, and, if necessary, be able to take down supervision trees. You never know how bugs manifest themselves; the last thing you want is to miss an abnormal process termination as a result of it not being linked to a supervisor. Another danger is hanging processes, possibly as (but not limited to) a result of errors or timeouts, causing a memory leakage that might take months to detect.
Note
Imagine an upgrade where you have to kill all processes dealing with a specific type of call. If these processes are part of a supervision tree, all you need to do is terminate the top-level supervisor, upgrade the code, and restart it. We get the shivers just thinking of the task of having to go into the shell and manually find and terminate all the processes which are not linked to their parent or supervisor. If you do not know what processes are running in your system, the only practical way to do it is to restart the shell, something which goes against the whole principle of high availability.
If you are serious about your fault tolerance and high availability, make sure all of your processes are linked to a supervision tree.
Monitoring Clients
Remember the section A Client/Server Example in Chapter 5? The server is unreliable! If the client crashes before it sends the frequency release message, the server will not deallocate the frequency and allow other clients to reuse it.
Let’s rewrite the server, making it reliable by monitoring the clients. When a client is allocated a frequency, the server links to it. If a client terminates before deallocating a frequency, the server will receive an exit signal and deallocate it automatically. If the client does not terminate, and deallocates the frequency using the client function, the server removes the link. Here is the code from Chapter 5; all of the new code is highlighted:
-module(frequency). -export([start/0, stop/0, allocate/0, deallocate/1]). -export([init/0]). %% These are the start functions used to create and %% initialize the server. start() -> register(frequency, spawn(frequency, init, [])). init() -> process_flag(trap_exit, true), Frequencies = {get_frequencies(), []}, loop(Frequencies). % Hard Coded get_frequencies() -> [10,11,12,13,14,15]. %% The client Functions stop() -> call(stop). allocate() -> call(allocate). deallocate(Freq) -> call({deallocate, Freq}). %% We hide all message passing and the message %% protocol in a functional interface. call(Message) -> frequency ! {request, self(), Message}, receive {reply, Reply} -> Reply end. reply(Pid, Message) -> Pid ! {reply, Message}. loop(Frequencies) -> receive {request, Pid, allocate} -> {NewFrequencies, Reply} = allocate(Frequencies, Pid), reply(Pid, Reply), loop(NewFrequencies); {request, Pid , {deallocate, Freq}} -> NewFrequencies=deallocate(Frequencies, Freq), reply(Pid, ok), loop(NewFrequencies); {'EXIT', Pid, _Reason} -> NewFrequencies = exited(Frequencies, Pid), loop(NewFrequencies); {request, Pid, stop} -> reply(Pid, ok) end. allocate({[], Allocated}, _Pid) -> {{[], Allocated}, {error, no_frequencies}}; allocate({[Freq|Frequencies], Allocated}, Pid) -> link(Pid), {{Frequencies,[{Freq,Pid}|Allocated]},{ok,Freq}}. deallocate({Free, Allocated}, Freq) -> {value,{Freq,Pid}} = lists:keysearch(Freq,1,Allocated), unlink(Pid), NewAllocated=lists:keydelete(Freq,1,Allocated), {[Freq|Free], NewAllocated}. exited({Free, Allocated}, Pid) -> case lists:keysearch(Pid,2,Allocated) of {value,{Freq,Pid}} -> NewAllocated = lists:keydelete(Freq,1,Allocated), {[Freq|Free],NewAllocated}; false -> {Free,Allocated} end.
Note how in the exited/2 function we
ensure that the pair consisting of the client Pid and the frequency is a member of the list
containing the allocated frequencies. This is to avoid a potential race
condition where the client correctly deallocates the frequency but
terminates before the server is able to handle the deallocate message
and unlink itself from the client. As a result, the server will receive
the exit signal from the client, even if it has already deallocated the
frequency.
1>frequency:start().true 2>frequency:allocate().{ok,10} 3>exit(self(), kill).** exception exit: killed 4>frequency:allocate().{ok,10}
In this example, we used a bidirectional link instead of the unidirectional monitor. This design decision is based on the fact that if our frequency server terminates abnormally, we want all of the clients that have been allocated frequencies to terminate as well.
A Supervisor Example
Supervisors are processes whose only task is to start children and monitor
them. How are they implemented in practice? Children can be started
either in the initialization phase of the supervisor, or dynamically,
once the supervisor has been started. Supervisors will trap exits and
link to their children when spawning them. If a child process
terminates, the supervisor will receive the exit signal. The supervisor
can then use the Pid of the child in
the exit signal to identify the process and restart it.
Supervisors should manage process terminations and restarts in a uniform fashion, making decisions on what actions to take. These actions might include doing nothing, restarting the process, restarting the whole subtree, or terminating, making its supervisor resolve the problem.
Supervisors should behave in a similar manner, irrespective of what the system does. Together with clients/servers, finite state machines, and event handlers, they are considered a process design pattern:
The generic part of the supervisor starts the children, monitors them, and restarts them in case of a termination.
The specific part of the supervisor consists of the children, including when and how they are started and restarted.
In the following example, the supervisor we have implemented takes
a child list of tuples of the form {Module,
Function, Arguments}. This list describes the children that
the supervisor has to supervise by giving the functions that have to be
called to start the child processes: an example is given by {add_two, start, []}, introduced at the
beginning of the chapter. In doing this, we assume that the child
process is started using the spawn_link/3 BIFs,
and that the function, if successful, returns the tuple {ok, Pid}; you can verify that this is the
case for add_two:start/0.
The supervisor, which is also started with the spawn_link/3 BIF as it needs to be linked to
its parent, starts executing in the init/1 function. It starts trapping exits, and
by calling the start_children/1
function, it spawns all of the children. If the apply/3 call creating
the child was successful and the function returned {ok, Pid}, the entry {Pid, {Module, Function, Arguments}} is added
to the list of spawned children that is passed to the loop/1 function:
-module(my_supervisor).
-export([start_link/2, stop/1]).
-export([init/1]).
start_link(Name, ChildSpecList) ->
register(Name, spawn_link(my_supervisor, init, [ChildSpecList])), ok.
init(ChildSpecList) ->
process_flag(trap_exit, true),
loop(start_children(ChildSpecList)).
start_children([]) -> [];
start_children([{M, F, A} | ChildSpecList]) ->
case (catch apply(M,F,A)) of
{ok, Pid} ->
[{Pid, {M,F,A}}|start_children(ChildSpecList)];
_ ->
start_children(ChildSpecList)
end.The loop of the supervisor
waits in a receive clause for
EXIT and stop messages. If a child terminates, the
supervisor receives the EXIT signal
and restarts the terminated child, replacing its entry in the list of
children stored in the ChildList
variable:
restart_child(Pid, ChildList) ->
{value, {Pid, {M,F,A}}} = lists:keysearch(Pid, 1, ChildList),
{ok, NewPid} = apply(M,F,A),
[{NewPid, {M,F,A}}|lists:keydelete(Pid,1,ChildList)].
loop(ChildList) ->
receive
{'EXIT', Pid, _Reason} ->
NewChildList = restart_child(Pid, ChildList),
loop(NewChildList);
{stop, From} ->
From ! {reply, terminate(ChildList)}
end.We stop the supervisor by calling the synchronous client function
stop/0. Upon receiving the stop message, the supervisor runs through the
ChildList, terminating the children
one by one. Having terminated all the children, the atom ok is returned to the process that initiated
the stop call:
stop(Name) ->
Name ! {stop, self()},
receive {reply, Reply} -> Reply end.
terminate([{Pid, _} | ChildList]) ->
exit(Pid, kill),
terminate(ChildList);
terminate(_ChildList) -> ok.In our example, the supervisor and the children are linked to each
other. Can you think of a reason why you should not use the monitor BIF? The reason for this design choice
is similar to the one in our frequency server example. Should the
supervisor terminate, we want it to bring down all of its children, no
matter how horrid that may sound!
Let’s run the example in the shell and make sure it works:
1>my_supervisor:start_link(my_supervisor, [{add_two, start, []}]).ok 2>whereis(add_two).<0.125.0> 3>exit(whereis(add_two), kill).true 4>add_two:request(100).102 5>whereis(add_two).<0.128.0>
This supervisor example is relatively simple. We extend it in the exercises that follow.
Exercises
Exercise 6-1: The Linked Ping Pong Server
Modify processes A and B from Exercise 4-1 in Chapter 4 by linking the processes to each
other. When the stop function is
called, instead of sending the stop
message, make the first process terminate abnormally. This should result
in the EXIT signal propagating to the
other process, causing it to terminate as well.
Exercise 6-2: A Reliable Mutex Semaphore
Suppose that the mutex semaphore from the section Finite State Machines in Chapter 5 is unreliable. What happens if a process that currently holds the semaphore terminates prior to releasing it? Or what happens if a process waiting to execute is terminated due to an exit signal? By trapping exits and linking to the process that currently holds the semaphore, make your mutex semaphore reliable.
In your first version of this exercise, use try...catch
when calling link(Pid). You have to
wrap it in a catch just in case the
process denoted by Pid has terminated
before you handle its request.
In a second version of the exercise, use erlang:monitor(type, Item). Compare and
contrast the two solutions. Which one of them do you prefer?
Exercise 6-3: A Supervisor Process
The supervisor we provided in the example is very basic. We want to expand its features and allow it to handle more generic functionality. In an iterative test-and-develop cycle, add the following features one at a time:
If a child terminates both normally and abnormally, the supervisor will receive the exit signal and restart the child. We want to extend the
{Module, Function, Argument}child tuple to include aTypeparameter, which can be set topermanentortransient. If the child is transient, it is not restarted if it terminated normally. Restart it only upon abnormal termination.What happens if the supervisor tries to spawn a child whose module is not available? The process will crash, and its
EXITsignal is sent to the supervisor that immediately restarts it. Our supervisor does not handle the infinite restart case. To avoid this case, use a counter that will restart a child a maximum of five times per minute, removing the child from the child list and printing an error message when this threshold is reached.Your supervisor should be able to start children even once the supervisor has started. Add a unique identifier in the child list, and implement the function
start_child(Module, Function, Argument), which returns the uniqueIdand the childPid. Don’t forget to implement thestop_child(Id)call, which stops the child. Why do we choose to identify the child through itsIdinstead of thePidwhen stopping it?
Base your supervisor on the example in this chapter. You can download the code from the website for the book as a starting point.
To test your supervisor, start the mutex semaphore and database server processes, as shown in Figure 6-9.
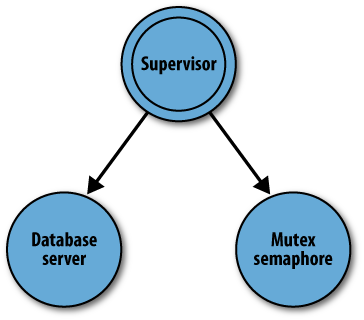
You will have to change the
startfunction to ensure that the processes link themselves to their parent and return{ok,Pid}.Kill your processes using
exit(whereis(ProcName), kill).See whether they have been restarted by calling
whereis(ProcName)and ensure that you are getting different process IDs every time.If the process is not registered, kill it by calling
exit(Pid, kill). You will getPidfrom the return value of thestart_childfunction. (You can then start many processes of the same type.)Once killed, check whether the process has been restarted by calling the
i()help function in the shell.
[19] You can catch the call exit(kill). A process will be
unconditionally killed only when exit(Pid,kill) is used.