
Automatically Evaluating Atypical Language in Narratives by Children with Autistic Spectrum Disorder
Abstract: We conducted an automatic analysis of transcribed narratives by children with autistic spectrum disorder. Compared to previous work, we use a much larger dataset with control groups that allow for the distinction between delayed language development and autism-specific difficulties, and that allows differentiation between episodic and generalized narratives. We show differences related to expression of sentiment, topic coherence and general language level. Some features thought to be autism-specific present as delayed language development.
1 Introduction
In recent years, there has been a growing interest in automated diagnostic analysis of texts which detects idiosyncratic language caused by certain mental conditions: while standard approaches to text classification mostly focus on pure identification of certain users or user groups, often with hardly interpretable features (like function words), diagnostic analysis has the additional goal of making sense out of the actual features. The hope here is to gain more insight into the underlying disorder by analysing how it affects language.
Our focus is on the diagnostic analysis of texts by adolescents with autistic spectrum disorder (ASD). ASD is a neurodevelopmental disorder characterised by impairment in social interaction and communication. Whilst there has been much research on ASD, there are not many corpus analyses to support assumptions on language development and ASD. In general, it is difficult to gather large datasets with meaningful control groups. Previous approaches employed small datasets of very restricted domains like retellings [14, 18].
Our work is based on the largest available dataset with narratives told by teenagers with ASD [11]. In contrast to other datasets, this has carefully matched control groups, which enables the distinction of delayed language development from ASD-specific difficulties. We analyse this data according to different features, which are in line with theories on ASD and language, and which have partially been used in previous work on texts from children with ASD (like term frequency × inverse document frequency). We (re-)evaluate all these features and compare their prevalence in the ASD group with two control groups, and show where we can find meaningful differences – and where we cannot. The result is a survey on differences of the language of adolescents with ASD and their typically developing peers.
Michaela Regneri: Dept. of Computational Linguistics, Saarland University, Saarbrücken, Germany, e-mail: [email protected]
Diane King: National Foundation for Educational Research, London, United Kingdom, e-mail: [email protected]
We first review previous research on ASD-specific language and related work on automated analysis (Sec. 2). We then describe the dataset and, based on this, our research objectives (Sec. 3) before presenting the results of our data analysis (Sec. 4). After a resumee on the results (Sec. 5) we conclude with a summary and suggestions for future work (Sec. 6).
2 Related Work
Many automated approaches to diagnostic analysis detect Alzheimer’s and related forms of dementia [8, 12]. Some classifiers are capable of automated diagnosis from continuous speech [1], or even predicting the cognitive decline decades before its actual onset [15].
Other systems recognize spontaneous speech by individuals with more general mild cognitive impairments, for adults [16] and also for children [7]. [9] present an unusual study on the language of adult patients with schizophrenia.
Previous research on narratives of children with ASD has reported difficulties with both structural and evaluative language. Individuals with ASD have difficulties in expressing sentiment, and make fewer references to mental states [4, 20]. However, other research shows, when carefully matched with comparison groups, many of these differences are not evident.
More basic problems emanate from a general lower syntactic complexity [21]. Subjects also seem to struggle with discourse coherence [13], which may, in part, be related to difficulties with episodic memory [2].
Some of these language difficulties have been subject to automated analysis: [14] analyzed data of very young children (6–7 years old). They built an automated classifier that distinguishes sentences uttered by children with ASD from sentences of two control groups (one with children with a language-impairment, one with typically developing children). The authors themselves note some drawbacks of their underlying dataset, in particular that some children in the ASD group were also classified as language-impaired. In consequence, a clear distinction between these groups was impossible.
In a follow-up study, [18] analysed whole narratives (retellings) told by children (mean age 6.4) with ASD compared to a typically developing control group (with the same average age and IQ). They used the tf × idf measure to identify idiosyncratic words uttered by children in the ASD group. The texts from the control group and some crowdsourced retellings from typically developing adults served as a basis for determining unusualness.
We consider this work of Rouhizadeh et al. as a basis and want to move further with a different dataset and different features: First, the dataset we are using [11] is much larger than any of the other automatically analysed ASD-datasets. Furthermore, the age range of the participants (11–14 years) is more suitable for this study, because narrative abilities are not fully in place before the age of nine years [10]. Additionally, this dataset allows us to properly distinguish ASD-specific features from language development issues. Finally, we want to add features concerning references to mental states.
As our main objective, we do not aim to build a classifier that finds stories by children with ASD, but rather want to examine which automatically derived features can further our understanding of language and ASD, and which (presumably relevant) features might question existing theories.
3 Corpus & Analysis Objectives
In the following, we will describe the dataset and why it is suited for this task, and then summarize the core techniques and objectives of our analysis.
3.1 A Dataset of Narratives by Children with ASD
We base our analysis on an existing dataset [11]. The corpus contains transcripts of narratives about 6 everyday scenarios: SPENDING FREE TIME, BEING ANGRY, GOING ON HOLIDAYS, HAVING A BIRTHDAY, HALLOWEEN and BEING SCARED.
The subjects were divided in three groups: 27 children with ASD, one comparison group of 27 children matched by chronological age and nonverbal ability, and another of 27 children individually matched on a measure of expressive language and on nonverbal ability. All groups had average scores on nonverbal and verbal measures, as measured by the Matrices test of the BAS II and the BPVS II. The average age difference between the language-matched control group and the two other groups is 17 months.
Each child told two stories for each scenario: first a specific narrative about a particular instance (answering a prompt like “Can you tell me about a time when you went on holiday?”), and second a general narrative that contains a script-like prototypical scenario description (“What usually happens when someone goes on holiday?”). This distinction of general and specific narratives allows us to assess both the episodic memory of the children and their ability to generalize to commonsense knowledge. Each of the 27 subjects told 2 × 6 stories which sums up to 972 narratives (324 per group).
King et al.transcribed all texts and added annotations coding references to mental states, causal statements, negative comments, hedges, emphatic remarks and direct speech. Table 1 shows some basic statistics on the corpus. The figures distinguish the subject groups and also the general (GEN) and specific (SEN) event narratives. The narratives from the ASD group were, in general, shorter, both with respect to the number of utterances and the number of words per utterance. We also find fewer references to mental states for the general narratives, which will later be an anchor point for our own analyses.
Tab. 1: Text and utter. length & mental state references, by group and story type.

This dataset is particularly well suited to analyse difficulties with coherence (because it contains whole narratives), expression of sentiment (because it contains emotion-centered scenarios), and the distinction of language development issues from ASD-specific difficulties (because it has a language-matched control group). We further want to make use of the differences for general and specific narratives, because this distinction offers new perspectives on more general cognitive capabilities behind the language in children with ASD.
3.2 Automatic Analysis of ASD-Specific Language
Our goal is to look for evidence in the data that heuristically tests theories on ASD and language. The following details the theoretical issues underpinning this and the corresponding automatically retrievable features we want to explore:
- General language difficulties: As a first step, we show features potentially indicating general language development difficulties in the ASD group: we assess the use of low-frequency words and idiosyncrasies in pronoun use.
- Difficulties with topic coherence: We want to re-visit the use of unusual words and the degree of their unusualness by subjects with ASD, using tf × idf (like Rouhizadeh et al.). We consider words as unusual if they are off-topic, i.e. deviate considerably from the current narrative focus.
- Difficulties with verbalizing sentiments: Individuals with ASD are known to have difficulties with references to mental states. We use a state-of-the-art sentiment analyser to compare which kind of sentiments are expressed most frequently by which subject group. Further, we generally consider the scenarios of being SCARED and ANGRY as potential source of difficulties.
- Differences between recalling episodes and generalizing scenarios: Our dataset contains scenario-matched general (script-like) and specific (episodic) narratives, which allows us to evaluate which of the two are more difficult and in which respect. This is particularly interesting because tasks related to episodic memory as well as the development of generic common sense knowledge are, in theory, challenging for individuals with ASD.
- Differences between language development issues and ASD-specific symptoms: Language-related problems of children with ASD are hard to classify as either general language-development problems or as ASD-specific. Because our dataset contains a control group which is matched for language capabilities, we can examine this distinction.
4 Analysis of Linguistic Features
We evaluate different linguistic features on the dataset, which can indicate different language idiosyncrasies for ASD: We apply some measures for the general state of language development (Sec. 4.1), difficulties with topic coherence (Sec. 4.2), and the expression of sentiments (Sec. 4.3).
4.1 General Language Competence
The language competence of the children with ASD is reported to be in the average range and to match the respective control group. We try to validate those results, first by assessing the use of low-frequency words, which is associated with high language competence. Second, we analyse pronoun use: both a generally low pronoun use and an over-proportional use of first person singular pronouns indicate earlier stages of language development [6].
Low-Frequency Words
To measure word frequencies, we mainly employ Kilgariff’s frequency list29 drawn from parts of the BNC corpus [5]. We have chosen this particular corpus because it includes both written language and transcribed speech, and because it is reasonably large (100M source tokens).
Evaluating the average word (type) frequency per narrative does not yield any difference between the subject groups. (We also tested word and bigram frequencies from google n-grams [3], with the same result.) We also show a more focused analysis on low-frequency words: we count low-frequency words according to different frequency thresholds. E.g. if we set a threshold of 0.01%, we measure the proportion of tokens from a type which contributes less than 0.01% to the tokens in the reference corpus.
Table 2 shows the results, listed by subject group and frequency threshold. While the proportion of low-frequency words is basically equal in the age-matched control group and the (younger) language-matched control group, it is slightly lower in the narratives from the ASD group. This is only partially explainable by a lower language-competence of the ASD group, in particular given the equal results for both control groups.
Tab. 2: Token proportions below small frequency thresholds (w.r.t. the source corpus).

Pronoun Use
As indicators of language development level, we analyse the overall proportion of pronouns, and the proportion of first person singular pronouns (1psg, I, my etc.). In general, pronoun use increases with language development, while the use of 1psgs decreases during language development.
Table 3 shows the results: column 2 indicates the overall (token-based) proportion of pronouns (relative to all word tokens). The following columns show the proportion of 1psgs, relative to all pronouns; col. 3 shows the overall average, col. 4 & 5 split the numbers up by narrative type (specific vs. generic).
Tab. 3: Overall pronoun use & Proportion of first person singular pronouns, also contrasting general event narratives (SEN) and specific event narratives (GEN).
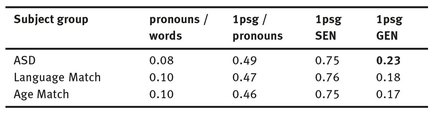
The results show that there are differences in pronoun use, but that these appear to have other reasons than differences in language ability: on average, all three groups show comparable results. However, there is an over-proportional use of 1psgs in the general narratives from the ASD group. This might indicate that the difficulties of the children with ASD are not due to language capabilities, but rather to other systematic problems.
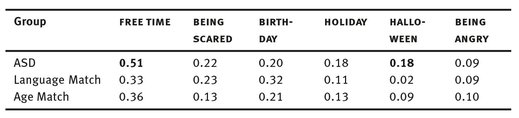
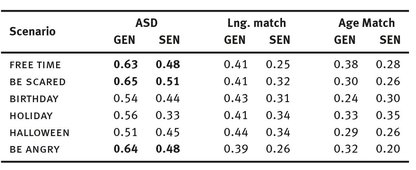
As shown in table 4, those differences in general narratives are not equal for all scenarios. In many cases, the ASD group shows no differences to their language-matched controls (SCARED) or even their age-matched controls (BIRTHDAY, ANGRY). However, event-driven topics (FREE TIME, HALLOWEEN) seem to cause more difficulties in generalizing away from the first person perspective.
Tab. 4: Proportion of 1st person singular pronouns in general narratives, by scenario.
4.2 Topic Coherence
Another commonly described phenomenon in children with ASD is difficulty with topic maintenance. [18] describe how to use tf × idf to detect idiosyncratic words in texts by children with ASD. We wanted to validate their underlying assumption that children with ASD in fact use more out-of-topic words than typically developing children.
Unusual Off-Topic Words
Term Frequency / Inverse Document Frequency [17, tf × idf ] is an established measure in information retrieval to quantify the association of a term t with a document dj from a document collection D = {d1, d2 , ...dn }. We compute the tf and idf , as follows, with freq(t, d) as the number of t′s occurrence in d:
Intuitively, a term t has a high tf × idf score for a document d if t is very frequent in d, and very infrequent in all other documents. The division by the maximum frequency of any term in d normalizes the result for document length. We compute tf × idf for each narrative with all narratives of the same scenario as underlying document collection. This is similar to the experiment by [18], with the additional normalization for text length, and with less narrow topics.
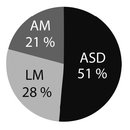
Fig. 1: Distribution of the 1% most unusual words according to tf × idf scores.
Table 5 shows the results. There were no indicative differences on general and specific narratives, so we omit the distinction (tf × idf was always higher for specific narratives). On average, there are only small absolute differences between the ASD group and both control groups. The maximal scores are the same for both the ASD group and their language-matched controls, which indicates the strong relationship of tf × idf with lexical knowledge development.
Tab. 5: tf × idf scores detailed by scenario; maximum scores are on the left, average scores on the right. LM and AM mark language and age match, respectively.
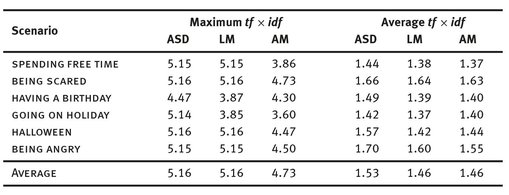
Comparing scenarios, we find some wider topics with fewer “usual” words (SCARED and ANGRY). For the more episodic narratives like BIRTHDAY and HALLOWEEN, the difference between the ASD group and the control groups is clearer.
Whilest the overall picture does not show the expected difference, words with the highest tf × idf occur more frequently in the ASD group: Figure 1 shows the distribution of the 1% words with the highest tf × idf scores. More than half of those outstandingly unusual words come from the ASD group, while the other half is divided in comparable pieces between the two control groups.
4.3 Sentiment & References to Mental States
Our dataset confirms that conveying emotions presents more difficulties for children with ASD than for their typically developing peers. Of particular interest are the narratives that specifically point to the emotionally defined situations of BEING SCARED and ANGRY. The mere frequency of references to mental states is reported to be is much lower in the ASD group than in any of the other two groups [11] We want to test whether we can confirm such an analysis with scalable automated means, and additionally evaluate the type and distribution of emotions conveyed. We use one of the best automatic sentiment analysers [19], which evaluates sentences as either neutral, positive or negative.
Table 6 shows that there are considerably more neutral sentences in the narratives of the ASD group than in the control groups. Further, they contain very few negative sentences but a similar proportion of positive sentences. Table 7 shows that references to the mental states of other people seems to be most difficult for the children with ASD, with the emotion-defined scenarios (SCARED & ANGRY), showing the highest proportion of neutral statements.
Tab. 6: Proportions of negative, neutral and positive sentences in the dataset.
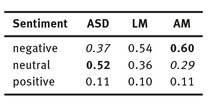
Tab. 7: Proportion of neutral sentences in general narratives.
5 Discussion
Our evaluation is an initial exploration, and more research needs to be done to arrive at a final analysis suite for ASD-related language. The results we found do not provide clear answers with respect to all of our original research objectives. Nevertheless, we found some interesting first evidence:
The use of low-frequency words is slightly less common in the ASD group, while the results for the two control groups are very similar. This is interesting because the feature, at first glance, looks like an indicator of language deficiency, but on further examination seems to be a by-product of other difficulties specific to the ASD group (e.g. a general difficulty of describing certain scenarios).
Contrary to our expectation, we did not find any differences in the overall pronoun use (indicating text coherence). With first person pronouns, generalization over episodic scenarios is harder for children with ASD.
The picture for topic coherence is less clear than expected. [18] also used tf × idf , but did not provide evidence that this is a distinctive feature. Contrary to their basic assumption, words with high tf × idf are not something exclusive to children with ASD, but rather occur in all groups. Comparing maximal tf × idf scores also raises the question as to whether the results are actually underpinned by language deficiencies. What can be shown is that the words with the highest tf×idf are twice as likely to stem from a child with ASD.
Our clearest evidence concerns sentiment and references to mental states. Whilst it was clear from the corpus annotation that children with ASD use fewer direct references to mental states, we did not know before this analysis about differences of emotion types and differences between scenarios. Automated sentiment analysis gave first answers to both: while we have no differences between the subject groups in the use of positive sentences, there are far more neutral sentences in the ASD group, and far fewer negative ones. Further, the differences are scenario-dependent, and are particularly striking for the “emotional” scenarios, which require references to mental states by default.
6 Conclusion
We have presented an explorative analysis of narrative language produced by children with ASD. In contrast to previous approaches, we used a much larger dataset that allows for the distinction between language deficiencies and ASD-SPECIFIC symptoms. We further applied a wider diversity of automated analyses, and showed that some features (like unusual words as classified by tf × idf) are not necessarily very distinctive for narratives produced by children with ASD.
What we did not provide is an actual classifier for the automatic distinction between texts by children with ASD and texts produced by one of the control groups. One reason for this is that although some very shallow features (like text length) would yield a very good result on our datasets, rather than finding the most distinctive features, we wanted to find the most telling features which show where the actual language difficulties for children with ASD are. Classifying according to length e.g. would only summarize the outcome of all those difficulties in one rather meaningless classification metric.
We also did not discriminate between individuals who may be on different points of the spectrum, because the dataset does not account for this. The diagnosis of autism was not made by the researchers but by clinicians and we have no information other than that the child was ‘high functioning’ or had Asperger Syndrome. Most had a diagnosis of high functioning autistic spectrum disorder. A more fine-grained analysis could be an an interesting area for future research.
In future work, we want to explore more features and details of the dataset. One direction would be to more closely examine topic models and the nature of content they actually produce in order to gain more information on topic coherence. We also want to explore different text types (such as fictional narrative), and also use texts by adults to evaluate if, and to what degree, language difficulties persist in adulthood.
Acknowledgements
We want to thank Julie Dockrell and Morag Stuart for their advice on collection of the original data. We also thank the anonymous reviewers for their helpful comments. – The first author was funded by the Cluster of Excellence “Multimodal Computing and Interaction” in the German Excellence Initiative.
Bibliography
- [1] Baldas, V., Lampiris, C., Capsalis, C., Koutsouris, D.: Early diagnosis of alzheimer’s type dementia using continuous speech recognition. Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering, vol. 55, pp. 105–110. Springer Berlin Heidelberg (2011)
- [2] Boucher, J., Bowler, D.: Memory In Autism: Theory and Evidence. Memory in Autism: Theory and Evidence, Cambridge University Press (2010), http://books.google.de/books?id=ExOccQAACAAJ
- [3] Brants, T., Franz, A.: Web 1t 5-gram version 1. Linguistic Data Consortium (2006)
- [4] Capps, L., Losh, M., Thurber, C.: “the frog ate the bug and made his mouth sad”: Narrative competence in children with autism. Journal of Abnormal Child Psychology 28(2), 193–204 (2000), http://dx.doi.org/10.1023/A%3A1005126915631
- [5] Clear, J.H.: The digital word. chap. The British National Corpus, pp. 163–187. MIT Press, Cambridge, MA, USA (1993), http://dl.acm.org/citation.cfm?id=166403.166418
- [6] Forrester, M.: The Development of Young Children’s Social-cognitive Skills. Essays in developmental psychology, Lawrence Erlbaum Associates (1992), http://books.googlede/books?id=ABp6Tv- fl- sC.
- [7] Gabani, K., Sherman, M., Solorio, T., Liu, Y., Bedore, L., Peña, E.: A corpus-based approach for the prediction of language impairment in monolingual english and spanish-english bilingual children. In: Proceedings of NAACL-HLT 2009 (2009)
- [8] Hirst, G., Wei Feng, V.: Changes in style in authors with alzheimer’s disease. English Studies 93(3) (2012)
- [9] Hong, K., Kohler, C.G., March, M.E., Parker, A.A., Nenkova, A.: Lexical differences in autobiographical narratives from schizophrenic patients and healthy controls. In: Proceedings of EMNLP-CoNLL 2012 (2012)
- [10] Karmiloff-Smith, A.: Language and cognitive processes from a developmental perspective. Language and Cognitive Processes 1(1), 61–85 (1985), http://www.tandfonline.com/doi/abs/10.1080/01690968508402071
- [11] King, D., Dockrell, J.E., Stuart, M.: Event narratives in 11–14 year olds with autistic spectrum disorder. International Journal of Language & Communication Disorders 48(5) (2013)
- [12] Le, X., Lancashire, I., Hirst, G., Jokel, R.: Longitudinal detection of dementia through lexical and syntactic changes in writing: a case study of three british novelists. Literary and Linguistic Computing 26(4) (2011)
- [13] Loveland, K., Tunali, B.: Narrative language in autism and the theory of mind hypothesis: a wider perspective. In: Baron-Cohen, S., Tager-Flusberg, H., Cohen, D.J. (eds.), Narrative language in autism and the theory of mind hypothesis: a wider perspective. Oxford University Press (1993)
- [14] Prud’hommeaux, E.T., Roark, B., Black, L.M., van Santen, J.: Classification of atypical language in autism. ACL HLT 2011 p. 88 (2011)
- [15] Riley, K.P., Snowdon, D.A., Desrosiers, M.F., Markesbery, W.R.: Early life linguistic ability, late life cognitive function, and neuropathology: findings from the nun study. Neurobiology of Aging 26(3) (2005)
- [16] Roark, B., Mitchell, M., Hosom, J., Hollingshead, K., Kaye, J.: Spoken language derived measures for detecting mild cognitive impairment. Audio, Speech, and Language Processing, IEEE Transactions on 19(7), 2081–2090 (2011)
- [17] Robertson, S.E., Sparck Jones, K.: Document retrieval systems. Taylor Graham Publishing (1988)
- [18] Rouhizadeh, M., Prud’hommeaux, E., Roark, B., van Santen, J.: Distributional semantic models for the evaluation of disordered language. In: Proceedings of NAACL-HLT 2013 (2013)
- [19] Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C.D., Ng, A.Y., Potts, C.: Recursive deep models for semantic compositionality over a sentiment treebank. In: Proceedings of EMNLP 2013 (2013)
- [20] Tager-Flusberg, H.: Brief report: Current theory and research on language and communication in autism. Journal of Autism and Developmental Disorders 26(2) (1996)
- [21] Tager-Flusberg, H., Sullivan, K.: Attributing mental states to story characters: A comparison of narratives produced by autistic and mentally retarded individuals. Applied Psycholinguistics 16 (1995)