
A Rational Statistical Parser
Abstract: A model of syntactic parsing that combines elements of information and probability theory is proposed. The model assigns probability and entropy scores to parse trees: trees with higher probabilities are preferred while trees with higher entropies are penalized. This model is argued to be psycholinguistically motivated by means of rational analysis. Using a grammar extracted from the Penn Treebank, the implemented model was evaluated on the section 23 of the corpus. The results present a modest but general improvement in almost all types of phenomena analyzed, suggesting that the inclusion of entropy is beneficial during parsing and that, given our formulation, its relevance decreases polynomially as the syntactic trees develop during incremental processing.
1 Introduction
John Anderson (1991) proposes a framework to study cognitive systems dubbed as rational analysis. The main assumption is that humans are adapted to their environment and goals, and therefore if there is an optimal path to the solution of a task, the human cognitive system should converge towards a similar solution. This means that for some tasks, if we want to model human behavior, it is useful to first identify an optimal solution given resource limitations and the environment; this solution should be similar to the one that humans would apply.
Applying this rationale to syntactic parsing, we propose a framework for parsing that integrates probability estimations of parse derivations with predictions about unseen parsing events in the form of entropy. Models within this framework will be argued to be accomplishing three rational goals: a)retrieving the most probable analyses according to experience, b) being quick in order to cope with communication time constraints, and c)retrieving analyses minimizing cognitive costs.
The organization will be as follows: section 2 corresponds to some background information, section 3 presents the main ideas of our parsing model, section 4 corresponds to the experiments, and we end with the conclusion in section 5.
Jesús Calvillo and Matthew Crocker: Deparment of Computational Linguistics and Phonetics, Saarland University, Germany, e-mail: [email protected], [email protected]. de
2 Background
Chater et al. (1998) apply the rational analysis framework to formulate a model of human syntactic processing. According to them, one goal of the parser is to retrieve the correct parse minimizing the probability of either failing during extensive backtracking or mistakenly dismissing the correct parse. Thus, the human syntactic parser follows the best parsing paths according to a parsing score f(φ) consisting of: the probability of the path P(φ), the probability of settling on that path P(settle φ) and the probability of escaping from that path if it is incorrect P(escape φ). These are traded off to achieve a sequence of how the parser should explore the parsing space maximizing the probability of success.
(1)
Hale (2011) also applies rational analysis to parsing, obtaining a formulation that comprises two types of cost in an A* search: the cost paid to reach the current state from a starting point g(n), and the expected cost of following a specific path from the current state ĥ(n). In this case, the goal is to retrieve the correct parse as soon as possible as an urge due to time pressures.
(2)
Hale (2006) further argues that comprehenders may be sensitive to the uncertainty of the rest of the sentence, and uses the notion of Entropy of a Nonterminal as Grenander (1967) defines it, which is the same that we will use: the entropy H(nt) of each non-terminal nt in a PCFG G can be calculated as the sum of two terms. Let the set of production rules in G be R and the subset rewriting the ith non-terminal nti be R(nti ). Denote by P(r) the probability of rule r. Then:
(3)
The first term corresponds to the definition of entropy for a discrete random variable. The second term is the recurrence. It expresses the intuition that derivational uncertainty is propagated from children (ntj1 , ntj2 , . . . ) to parents (nti ) (Hale, 2006). The solution to the recurrence can be written as a matrix equation and directly calculated from the rule probabilities of a PCFG.
Building up on these ideas, we will present a framework for parsing that will also be argued to be complying with rational analysis.
3 Parsing Framework
We can define a parsing path as a sequence of transitions between parsing states. Each state ω corresponds to the configuration that the parser has in a specific moment regarding a possible derivation of the analyzed sentence. Transitions between states are performed through actions. Each parsing state has an associated set of actions that can be possibly done from that state according to the parsing algorithm. For example, using a left-corner algorithm each parsing state corresponds to a particular state of the stack and the so far derived tree. After performing one of the operations of left-corner parsing: scan, shift or project, the parser arrives to a new state. When the parser can perform more than one action at a particular state, we say that it is at a point of ambiguity and the parser has to decide which action is preferred, which path to follow.
A parsing state ω is deemed better if it has higher probability, and/or if from that state we can predict that we will arrive to a goal state with higher probability or sooner. A goal state corresponds to a complete syntactic analysis of the sentence. These two factors can be formalized as a score S(ω):
(4)
where P(ω) is the probability of the so far derived parse tree according to a PCFG, given the past decisions; and Ent(ω) contains information, in the form of Entropy, of how the rest of the derivation is going to be from the current state to a goal state.
More precisely we will formulate our parsing score as:
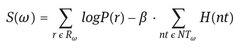
(5)
where Rω is the sequence of rules employed in the derivation of ω , NTω is the set of nonterminals contained in ω , and β is the trade off between the two addends.
3.1 Entropies, Probabilities and Lengths
In Information Theory, entropy is a measure of uncertainty in a random event (Shannon, 1948). By taking another point of view, it can also be seen as a negative expectation of a log probability. Having a nonterminal symbol nti of a PCFG G, there is a set of rewritings R(nti) available for this nonterminal according to the grammar. Each of these rewritings corresponds to one grammar rule r that in turn has a probability associated P(r). If we take the rewriting of the nonterminal as a discrete random variable, then the expectation of the log probabilities associated with the possible rewritings of nti is defined by:

(6)
which is the same as first term in the previous formulation of the Entropy of a Nonterminal in (3), with the difference of the sign. This corresponds to a single rewriting of nti .
Applying the same reasoning to the recursion in (3) and since the recursion factors into single rewriting steps, we can draw a similar relation between the Entropy of a Nonterminal H(nt) and the Expected Log Probability of a tree whose root is nt. In other words, the entropy of a nonterminal is equal to the negative expectation of the log probability of a tree whose root is the nonterminal:
(7)
Then, a parser that follows low entropy paths is not only preferring low uncertainty, but it also prefers derivations that in average have high log probabilities.
From a different perspective and according to Hale (2011), this definition of entropy of a nonterminal correlates to the estimated derivation length taken from a corpus. This is perhaps not very surprising given the way that derivation probabilities are calculated using PCFGs. In a PCFG, the probability of a tree results from the product of the rule probabilities used in the derivation. Since probabilities range from 0 to 1, the more rules applied in the derivation, the less probable the parse tree becomes. If this is true, then we can see probability as a derivation length, and entropy as expected derivation length, one related to the already seen input and the other one to predictions about future input.
Summing up, we argue that regarding parsing derivations:
- – A parser that minimizes entropies is at the same time maximizing expected log probabilities and/or minimizing expected lengths.
- – Log probabilities are related to lengths as expected log probabilities (negative entropies) are related to expected lengths.
- – A parser that maximizes probabilities is at the same time minimizing lengths.
Thus, on the one hand our model can be seen as minimizing derivation lengths and expected derivation lengths, and therefore following the rational goal of being quick, just as Hale (2011). On the other hand, the model maximizes probabilities and expected probabilities and therefore follows the rational goal of being accurate according to experience.
3.2 Surprisal and Entropy Reduction
According to the Entropy Reduction Hypothesis (ERH), the transition from states with high entropies to states with low entropies represents a high cognitive effort as result of disambiguation work that the parser has to achieve when incorporating new information (Hale, 2006). Similarly, Surprisal is regarded as a cognitive load measure that is high when the parser is forced to process improbable events, and its related effort is argued to be the result of the disambiguation that the parser performs in view of new information (Hale, 2001).
The first addend of our model is related to the probability of the derivation so far processed. Using log probabilities, we arrive to a definition of Surprisal of a tree τ by simply changing its sign:
(8)
so a maximization of probabilities is at the same time a minimization of surprisal.
Noticing the form of the surprisal formulation, it is easy to see that the definition of entropy is equal to the expected value of surprisal. Hence, Roark (2011) dubbed it Expected Surprisal:
(9)
where τnt is a tree whose root is the nonterminal nt.
Then we can see the similarity between surprisal and entropy reduction. Both measure how improbable an event is, or in our context, a syntactic analysis. The first one will be high when the parser follows a low probability path, and the second will be high when the parser is forced to follow paths that are expected to have low probabilities.
From this point of view, instead of maximizing probabilities, the parse score used in our model can be rewritten as a cost or cognitive load measure consisting of two elements: one related to the effort of the already processed part of the sentence (Surprisal) and another one related to possible predictions about the rest of the sentence (Expected Surprisal) during incremental processing:
(10)
Consequently, we can see our model as being on the one hand maximizing probabilities and on the other hand minimizing cognitive load. Thus, for a given sentence, the parser would assign the tree ![]() the following way:
the following way:
(11)
where T is the set of all trees matching the sentence and licensed by the grammar.
If improbable analyses are more difficult to process by people, then it is rational that people should naturally follow paths with less expected cognitive load during incremental parsing. By doing so, the parser also achieves a rational goal of retrieving the analyses using the least amount of resources.
3.3 Implemented Model
The implemented model lies at the computational level of analysis, describing an estimation of how preferable a parse tree is, regardless of the algorithm used for its construction.
One assumption is that during production speakers are cognitively constrained and prone to generate cognitively manageable constructions. Also, in order to maximize the probability of a successful communication, the speaker should modulate the complexity of his/her utterances in a way such that the comprehender is able to follow, as Jaeger and Levy (2006) suggest. If this is true, we can expect that normal/understandable sentences should show a bias towards cognitively manageable constructions, avoiding peaks in cognitive load.
In this model, each parsing state corresponds to a parse (sub)tree τ :
(12)
where Rτ is the sequence of rules employed during the derivation of τ and NTτ is the set of all the nonterminals also used during the derivation of τ.
Finally, it is still necessary a complete definition of how entropies interact with probabilities. That is, we expect that the parser will mainly pursue high probability paths and only recur to entropies to disambiguate when the analyses show similar probabilities. How small are the weights of entropies and how they evolve during processing is something that still needs to be empirically defined.
4 Experiments
The parser with which the experiments were performed is an augmented version of the system developed by Roger Levy (2008), which is an implementation of the Stolcke parser (Stolcke, 1995). The latter is itself an extension of the Earley Parsing Algorithm (Earley, 1970) that calculates incrementally prefix probabilities.
The grammar was extracted from the sections 02–22 of the Penn Treebank (Marcus et al., 1993). Applying transformations on the trees would also change the entropy values, adding another variable to the model. Because of that, the only transformations performed were the removal of functional annotations and a preprocessing using the software by David Vadas (2010).
4.1 Formulation Refinement
As mentioned previously, the second part of our model’s formulation still needed to be refined in order to arrive to an optimal trade off between the two addends. To do so, we used the section 24 of the Penn Treebank as development set.
First, the best 50 parses according to the traditional PCFG parse probability score were retrieved. For each of the retrieved trees, f-scores were associated using Evalb and the gold standard trees. Then we proceeded to re-rank them according to different variations of our model. Several functions were tested in order to combine the entropies with the probabilities.
We found that the contribution of the entropy of each nonterminal had to be in function of its location within the tree. More precisely, the contribution HL(nt) of each nonterminal nt varied according to the distance between the location of the nt and the beginning of the tree according to a preorder representation. For example, if we have the following tree in preorder representation (terminal symbols were removed for readability):
(ROOT (S(NP(DT )(NNS))(ADVP(RB))(VP(VBD))(.)))
the distance of “NP” in the tree to the root node “ROOT” is 1 because there is one nonterminal symbol between “NP” and “ROOT”. Likewise, the distance to “ADVP” is 4 for the same reason. Thus, if we define the distance of nt to the beginning of the tree or root, a localized entropy contribution of each nonterminal HL can be defined as:
(13)
where H(nt) is the entropy of the nonterminal nt according to the grammar, and α is another parameter that needed to be found and that denotes the polynomial decrease of entropy’s relevance according to its location.
In order to translate this into the actual parser, it was necessary to find an approximation of the distance measure that could be calculated during parsing when the complete tree is not yet known. One approximation was the following:
(14)
where (i, j) are the coordinates of the nonterminal in the Earley parsing chart and | x | is the size of the sentence. This formula takes advantage of the chart which could be seen as a tree where the root is in position (0, | x |) and the leaves are on the diagonal.
Having a measure of distance, β and α were tuned using grid search, finding that 0.6 and 2 were good values for β and α respectively. After this, we have all the elements to get a final formulation by plugging HL into our model:
(15)
4.2 Results
Having generated the grammar and tuned the parser, experiments were conducted on the section 23 of the Penn Treebank (2416 sentences). For each sentence the parser was fed with the gold POS-tags in order to avoid tokenization errors and errors concerning words that did not appear in the training set.
The Baseline was a parser that retrieved the best analyses according only to probabilities. The resulting trees were compared to the gold standard using Evalb, obtaining the results shown in Table 1.
Tab. 1: Comparison of the output of Evalb for the baseline and our model.
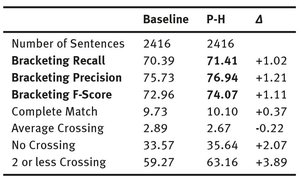
The first numeric column pertains to the Baseline, the second one corresponds to our system and the third one shows the difference between them. We see that although the improvement is modest, the new model outperforms the baseline in every field, suggesting overall benefits of the model.
In order to have a better characterization of what exactly the parser is doing better, another analysis was performed. In this case the output was converted to dependency trees using the software by Johansson and Nugues (2007) using options in order to emulate the conventions used in CoNLL Shared Task 2007.
After obtaining the dependency trees, the output was evaluated using the CoNLL-07 shared task evaluation script. This gives a more fine grained output that specifies among other information how the parser performed for each type of dependency relation; which can be seen in Table 2, where light gray highlighted rows correspond to dependencies where the new model outperformed the baseline and dark gray where the opposite occurred.
Tab. 2: Precision and Recall of Dependency Relations.
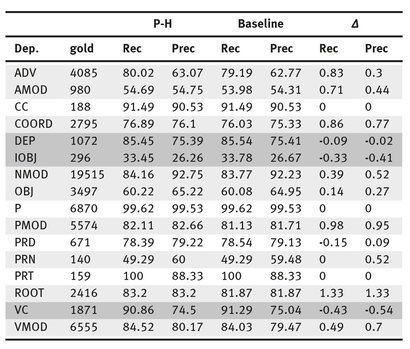
As we can see, the most frequent dependency relations like NMOD, VMOD, PMOD, etc. were handled better by the new model. Infrequent dependencies show no difference. It is only slightly infrequent dependencies (DEP, IOBJ, VC) that show some disadvantage, perhaps due to data sparsity. Because of lack of space we are unable to show all the output of the evaluation script, however, the rest of the results are very similar to Table 2: frequent structures were handled better, infrequent ones showed no difference, and only slightly infrequent ones show a disadvantage for the new model. Namely, this pattern arose for dependency relations across POS-TAGS and dependency relations plus attachment. Finally the new model gave a general improvement regarding the direction of the dependencies and regarding long distance dependencies.
4.3 Discussion
Addressing the formulation refinement, we see that the distance of each nonterminal to the root is an important factor. Indeed, it was only after considering this aspect, that some real improvement was obtained during development trials.
Its form entails a rapid decrease of the relevance of entropies as the sentence develops. One possible explanation resides on the predictive nature of the model. At the beginning of production it is possible that the speaker constructs the syntactic structure to be as concise as possible, making decisions that should lead the parser to quick and/or highly probable paths. As the speaker continues, the possible continuations become less and less as syntactic and semantic restrictions arise. At the end, it is possible that the speaker has very few options, so the only paths available are specifically those that match the semantic and syntactic representations already constructed.
Another factor that could partially explain this phenomenon is that during parsing, nodes nearer to the leaves are more determined. The very first level of parsing, POS-tagging, is a task that has a very high degree of accuracy; as the nodes go up on the tree, this determinacy is less and therefore the need for non-local accounts arises. The distance measure here used precisely gives less relevance to entropies that reside at lower levels of the tree.
It is worth mentioning that even though the relevance of entropy lowers as the analysis continues, it never reaches zero. That is, at the beginning of the sentence the weight of entropy can possibly override that of probabilities, making the parser follow paths that are not necessarily the most probable. This power of overriding probabilities diminishes as the parser continues, but even though it can be very small, for structures with equal probabilities, the parser would still prefer the one with lowest entropy.
Regarding the results of the experiments, we can see a modest but general improvement; only few structures are not handled better, and those happen to be rather infrequent.
The new model performs better especially for structures that are source of attachment ambiguities, such as coordination and long distance dependencies. This further supports the model as a means for preferring shorter and simpler structures when it comes to decide between structures of equal probability.
We should not expect every structure to seek a quick finalization, one could argue that there must be structures that actually mark that the sentence is going to be longer or shorter. It seems reasonable that the relevance of entropy depends also on lexical, syntactic or semantic information. A more complete model with this information, as well as experimentation with other languages and grammars should give more precise ways of using entropies during parsing.
5 Conclusion
We proposed a framework that makes use of entropies as a way to predict/weight syntactic trees. Models within this framework are argued to be pursuing three rational goals: a)retrieving the most probable analyses according to experience, b) being quick in order to cope with communication time constraints, and c)retrieving analyses minimizing cognitive costs.
With this, we implemented a model that provides a definition of syntactic parsing at the computational level, ranking parses according to a trade-off between probability and entropy. After testing, we concluded that it is indeed beneficial to use probabilities and entropies to rank syntactic trees.
Bibliography
John Anderson. The place of cognitive architectures in rational analysis. In K. VanLehn, editor, Architectures for Cognition. Lawrence Erlbaum, Hillsdale, NJ, 1991.
Nicholas Chater, Matthew Crocker, and Martin Pickering. The rational analysis of inquiry: The case of parsing. In Chater and Oaksford, editors, Rational Models of Cognition. Oxford University Press, Oxford, 1998.
Jay Earley. An efficient context-free parsing algorithm. Communications of the ACM, 13(2): 94–102, 1970.
Ulf Grenander. Syntax-controlled probabilities. Division of Applied Mathematics, Brown University, 1967.
John Hale. A probabilistic earley parser as a psycholinguistic model. In Proceedings of the second meeting of the North American Chapter of the Association for Computational Linguistics on Language technologies, pages 1–8. Association for Computational Linguistics, 2001.
John Hale. Uncertainty about the rest of the sentence. Cognitive Science, 30(4):643–672, 2006.
John Hale. What a rational parser would do. Cognitive Science, 35(3):399–443, 2011. URL http://dx.doi.org/10.1111/j.1551-6709.2010.01145.x.
TF Jaeger and Roger P Levy. Speakers optimize information density through syntactic reduction. In Advances in neural information processing systems, pages 849–856, 2006.
Richard Johansson and Pierre Nugues. Extended constituent-to-dependency conversion for English. In Proceedings of NODALIDA 2007, pages 105–112, Tartu, Estonia, May 25–26 2007.
Roger Levy. Expectation-based syntactic comprehension. Cognition, 106(3):1126–1177, 2008.
Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beatrice Santorini. Building a large annotated corpus of english: The penn treebank. Computational linguistics, 19(2):313–330, 1993.
Brian Roark. Expected surprisal and entropy. Oregon Health & Science University, Tech. Rep, 2011.
Claude E. Shannon. A mathematical theory of communication. The Bell System Technical Journal, 27:379–423, 623–656, July, October 1948.
Andreas Stolcke. An efficient probabilistic context-free parsing algorithm that computes prefix probabilities. Computational linguistics, 21(2):165–201, 1995.
David Vadas. Statistical parsing of noun phrase structure. 2010.