
An Evolutionary Game Theoretic Approach to Word Sense Disambiguation
Abstract: This paper present a Semi Supervised approach to WSD, formulated in terms of Evolutionary Game Theory, where each word to be disambiguated is represented as a node on a graph and each sense as a class. The proposed algorithm performs a consistent class assignment of senses according to the similarity information of each word with the others, so that similar words are constrained to similar classes. The propagation of the information over the graph is formulated in terms of a non-cooperative multi-player game, where the players are the data points to decide their class memberships and equilibria correspond to consistent labeling of the data. The results have been provided by an analysis of their statistical significance. Preliminary experimental results demonstrate that our approach performs well compared with state-of-the-art algorithms, even though with the current setting it does not use contextual information or sense similarity information.
1 Introduction
Word Sense Disambiguation (WSD) is a task to identify the intended sense of a word in a computational manner based on the context in which it appears (Navigli, 2009). Understanding the ambiguity of natural languages is considered an AI-hard problem (Mallery, 1988). Computational problems like this are the central objectives of Artificial Intelligence (AI) and Natural Language Processing (NLP) because they aim at solving the epistemological question of how the mind works. It has been studied since the beginning of NLP (Weaver 1949) and also today is a central topic of this discipline.
Understanding the intended meaning of a word is a hard task, also humans have problem with it. This happens because people use words in a different manner from their literal meaning, and misinterpretation is a consequence of this habit. In order to solve this task, it is not only required to have a deep knowledge of the language, but also to be an active speaker of the language. In addition, languages change over time, in an evolutionary process, by virtue of the use of language by speakers, and this leads to the formation of new words and new meanings which could be understood only be active speakers of the language.
Rocco Tripodi, Marcello Pelillo: DAIS, Università Ca’ Foscari di Venezia Via Torino 155, 30172 Venezia, Italy, e-mail: [email protected]
Rodolfo Delmonte: Language Science Department, Università Ca’ Foscari, Ca’ Bembo, dd. 1075, 30123, Venezia, Italy, e-mail: {pelillo, delmont}@unive.it
WSD is also a central topic in applications like Text Entailment (Dagan and Glickman, 2004), Machine Translation (Vickrey, et al., 2005), Opinion Mining (Smrž, 2006) and Sentiment Analysis (Rentoumi et al. 2009). All of these applications require the disambiguation of ambiguous words, as preliminary process; otherwise they remain on the surface of the word (Pantel and Lin, 2002), compromising the coherence of the data to be analyzed.
The rest of this paper is structured as follows. Section 2 introduces the graph transduction technique and some notion of noncooperative game theory. Next, Section 3 shows our approach to WSD. Section 4 reports experimental results. Finally we review related studies in Section 5 and conclude in Section 6.
2 Graph-Based Semi-Supervised Learning
Our approach to WSD is based on two fundamental principles: the homophily principle , borrowed from social network analysis, and the transductive learning. The former simply states that objects which are similar to each other are expected to have the same label (Easley and Kleinberg, 2010). We extended this principle assuming that objects (words), which are similar, are expected to have a similar (semantic) class. The latter is a case of semi-supervised learning (Sammut and Webb, 2010) particularly suitable for relational data, which is used to propagate the class membership information from node to node. In our system we used an evolutionary process to propagate the information over a grah. This process is described in Section 2.2. In particular we extended the algorithm proposed by Erdem and Pelillo (2012) and used it in a scenario where the labels are fine-grained and their distribution is not uniform among the nodes of the graph. In fact in our case each node could be mapped to a disjoint set of classes (see Section 3).
2.1 Graph Transduction Model
Graph transduction is a semi-supervised method to solve labeling tasks wherein the objects to be labeled coincide with the nodes on a graph and the weights over the edges are the similarity measures among themselves. In this scenario, the geometry of the data is modeled with a weighted graph in which there are labeled and unlabeled points. The purpose of this method is to transfer the information given by the labeled points to the unlabeled ones, exploiting the pairwise similarity among nodes (homophily principle). Formally we have a graph G = (D, E, w) in which D is the set of nodes representing both labeled and unlabeled points, D = {Dl, Du} and w : E → ℝ+ is a weight function assigning a similarity value to each edge ∊ ∈ E. The task of transduction learning is to estimate the labels of the unlabeled points given the pairwise similarity for each node and a set of possible labels φ = {1, . . . , c}.
2.2 Normal Form Games
Game Theory provides predictive power in interactive decision situations. The simplest formulation of a game (normal form game, von Neumann and Morgenstern, 1943) assumes that games involve two players and pij is the payoff for player taking the ith action against player taking the jth action. The player’s goal is to maximize his utility, which is the satisfaction a player derives from the outcome of the game computed by a utility function. In this kind of games it is assumed that the players are rational and have a complete knowledge of the strategy sets and associated payoffs (Szabó and Fath, 2007). An example of the information possessed by the players is described in Table 1, which depicts the famous prisoner dilemma game.
Tab. 1: Prisoner dilemma game.
| p1/p2 | Cooperate | Defect |
|---|---|---|
| Cooperate | 1, 1 | 0, 2 |
| Defect | 2, 0 | 0, 0 |
As in Erdem and Pelillo (2012), we interpreted the graph transduction process in terms of noncooperative game, where each node5 of the graph is a player (i ∈ I) participating in the game which can choose a strategy (class membership) among a set of strategies6, Si = {1, . . . , c} (classes). Si is a probability distribution over its pure strategies which can be described as a vector xi = (xi1 , . . . , ximi)T in which
each component xih denotes the probability that player i choose its hth pure strategy, where ![]() and xih ≥ 0 for all h.
and xih ≥ 0 for all h.
In each game a player try to maximize its utility, choosing the strategy with the higher payoff. The final payoff of each player is given by the sum of payoff gained from each game played with its neighbors. Formally the pure strategy profile of player i is given by equation 1, where Aij is the similarity value for player i and j.
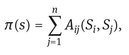
This solution allows each player to exploit the information about the pure strategies of its neighbor and to converge to a consistent strategy, since the games are played only between similar players (neighbours) which are likely to have the same class and labeled players (or unambiguous words) do not play the game to maximize their payoffs but act as bias over the choices of unlabeled players (Erdem and Pelillo, 2012).
When equilibrium is reached, the label of a player is the strategy with the highest payoff, which is computed with equation 2.
3 WSD Games
3.1 Graph Construction
The graph is constructed selecting the target words from a dataset, denoted by ![]() , where xi corresponds to the i-th word to be disambiguated and N is the number of target words. From X we constructed the N × N similarity matrix W where each element wij is the similarity value assigned for the words i and j. W can be exploited as an useful tool for graph-based algorithms since it is treatable as weighted adjacency matrix of a weighted graph.
, where xi corresponds to the i-th word to be disambiguated and N is the number of target words. From X we constructed the N × N similarity matrix W where each element wij is the similarity value assigned for the words i and j. W can be exploited as an useful tool for graph-based algorithms since it is treatable as weighted adjacency matrix of a weighted graph.
A crucial factor for the graph construction is the choice of the similarity measure, s(⋅, ⋅) → ℝ to weights the edges of the graph. For our experiments we decided to use the the following formula to compute the word similarities:
(3)
where Dice(xi, xj) is the Dice coefficient (Dice, 1945) to determine the strength of co-occurrence between any two words xi and xj which is computed as follows:
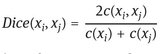
(4)
where c(xi) is the total number of occurrence of xi in a large corpus and c(xi, xj) is the co-occurrence of the words xi and xj in the same corpus. This formulation is particularly useful to decrease the ranking of words that tend to co-occur frequently with many other words. For our experiments we used as corpus the Google Web1T (Brants and Franz 2006), a large collection of n-grams (with a window of max 5 words) occurring in one terabyte of Web documents as collected by Google.
At this point we have the similarity graph W, which encodes the information of how two target words are similar, in a distributional semantics perspective (Harris, 1954). We recall that we will use W in order to classify similar words to similar classes, propagating the class membership information from node to node. For this reason, at first we need to smooth the data in W and then to choose only the most significant js for each i ∈ X. The first point is solved using a gaussian kernel on ![]() , where σ is the kernel width parameter; the second point is solved applying a knearest neighbor (k-nn) algorithm to W, which allows us to remove the edges which are less significant for each i ∈ X. In our experiments we used σ = 0.5 and k = 20. Moreover, this operation reduces the computational cost of the algorithm and focuses only on relevant similarities.
, where σ is the kernel width parameter; the second point is solved applying a knearest neighbor (k-nn) algorithm to W, which allows us to remove the edges which are less significant for each i ∈ X. In our experiments we used σ = 0.5 and k = 20. Moreover, this operation reduces the computational cost of the algorithm and focuses only on relevant similarities.
3.2 Strategy Space
For each player i, its strategy profile is defined as:
(5)
subject to the constraints described in Section 2.2, where c is the total number of possible senses, according to WordNet 3.0 (Miller, 1995). We can now define the strategy space S of the game in matrix form as:
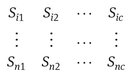
where each row correspond to the strategy space of a player and each column correspond to a class. Formally it is a c-dimensional space defined as:
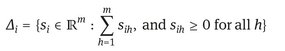
(6)
each mixed strategy profile lives in the mixed strategy space of the game, given by the Cartesian product:
(7)
For example in the case there are only two words, area and country, in our dataset, we first use WordNet in order to collect the sense inventories Mi = 1, . . . , m of each word, where m is the number of synsets associated to word i. Then we set all the sense inventories and obtain the set of all possible senses, C = 1, . . . , c. In our example the two words have 6 and 5 synsets respectively, with a synset in common, so the strategy space S will have 10 dimension and could be represented as follows.
Tab. 2: strategy space.

At this point the strategy space can be initialized with the formula in order to follow the constraints described in Section 2.2.

(8)
The initialization of the strategy space is described in Table 3.
Tab. 3: strategy space initialization.

In our example we have 10 synsets since area and country have a synset in common 7 (s2), and each strategy profile Si lies in the 10-dimensional simplex Δi. Each sij ∈ S express a certain hypothesis about the membership of an object in a class, we set to zero senses, which are not in the sense inventory of a word to avoid that a word could choose a class, which is not in its intension.
3.3 System Dynamics
Since we have the similarity graph W and the strategy space S, we can compute the payoff for each player according to equation (1). What is left is to compute the Nash equilibrium of the system, which means that each player’s strategy is optimal against those of the others (Nash, 1951).
As in Erdem and Pelillo (2012) we used the dynamic interpretation of Nash equilibria in which the game is played repeatedly, until the system converges and dominant strategies emerge, updating S at time t + 1 with the following equation:
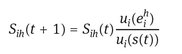
(9)
which allows higher value of payoff to increase with higher rate, and where and where the utility function is computed as follows8:
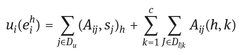
(10)
and
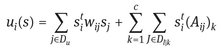
(11)
The payoffs associated with each player are additively separable and contribute to determine the final utility of each strategy ![]() .
.
4 Experimental Results
To make our experiments comparable to state-of-the-art systems, we used the official dataset of the SemEval-2 English all-words task (Agirre et al., 2010), which consists of three documents, 6000 word chunk with 1398 target words, annotated by hand using double-blind annotation by the organizer. Those texts were parsed using the TreeTagger tool (Schmid, 1994) to obtain lemmata and part-of-speech (POS).
The results are shown in Figure 1 where we compared our experiment with Semeval10 best, CFILT-2 (Khapra et al., 2010) (recall 0.57), and with the most common sense (MCS) approach (recall 0.505).

Fig. 1: Recall comparison
Figure 1 shows the mean recall rates and one standard deviation bars over 100 trials different sizes of randomly selected labeled points. We evaluated the results of our algorithm with the scoring tool provided with the emEval-2 English all-words dataset as described Agirre et al. (2010). Since our answers are in probabilistic format we evaluated all sense probabilities calculating the recall as the sum of the probabilities assigned by our system to the correct sense for each unlabeled word and dividing this sum by the number of unlabeled words, taking no notice of the labeled points which we used only as bias for our system.
The main difference between our approach and CFILT-2 is that we do not use domain specific knowledge-base in order to train our system. We need only a small amount of labeled data, which are easier to obtain and then propagate this information overt the graph. Our system is more similar to IIITTH, proposed by Agirre and Soroa (2009), which instead of using evolutionary dynamics over the graph, uses the personalized PageRank algorithm. This system has a recall of 0.534 on SemEval-2 English all-words task. Recently Tanigaki et al. (2013) proposed a smoothing model with a combinatorial optimization scheme for WSD, which exploits both contextual and sense similarity information to compute the maximum marginal likelihood for a sense given a specific target word. The main difference with this approach is semi-supervised, uses evolutionary dynamics in order to exploit the contextual information of a target word and with the current setting does not use contextual or sense similarity information, but only word similarity and relational information. This system has a recall of 50.8 on the same dataset we used for our experiments.
4.1 Conclusion
In this paper we presented a new graph based semi-supervised algorithm for WSD. Experimental results showed that our method improves the performances of conventional methods. Instead of train the system on large corpora, which are difficult to create and are not suitable for domain specific tasks, our system infers the class membership of a target word from a small amount of labeled data exploiting the relational information provided by labeled data. In our current implementation we use only the word similarity information in order to construct the graph. We think that the use of other sources of information could open new possible direction for further research in the area of transductive learning.
Bibliography
Agirre, E., Soroa, A.: Personalizing pagerank for word sense disambiguation. In: Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics, Association for Computational Linguistics (2009) 33–41
Agirre, E., De Lacalle, O.L., Fellbaum, C., Marchetti, A., Toral, A., Vossen, P.: Semeval-2010 task 17: All-words word sense disambiguation on a specific domain. In: Proceedings of the Workshop on Semantic Evaluations: Recent Achievements and Future Directions, Association for Computational Linguistics (2009) 123–128
Brants, T., Franz, A.: Web 1t 5-gram version 1. Linguistic Data Consortium, Philadelphia (2006)
Dagan, I., Glickman, O.: Probabilistic textual entailment: Generic applied modeling of language variability. (2004)
Dice, L.R.: Measures of the amount of ecologic association between species. Ecology 26(3) (1945) 297–302
Easley, D., Kleinberg, J.: Networks, crowds, and markets. Cambridge University
Erdem, A., Pelillo, M.: Graph transduction as a noncooperative game. Neural Computation 24(3) (2012) 700–723
Harris, Z.S.: Distributional structure. Word (1954)
Khapra, M.M., Shah, S., Kedia, P., Bhattacharyya, P.: Domain-specific word sense disambiguation combining corpus based and wordnet based parameters. In: In 5th International Conference on Global Wordnet (GWC2010, Citeseer (2010)
Mallery, J.C.: Thinking about foreign policy: Finding an appropriate role for artificially intelligent computers. In: Master’s thesis, MIT Political Science Department, Citeseer (1988)
Miller, G.A.: Wordnet: a lexical database for english. Communications of the ACM 38(11) (1995) 39–41
Nash, J.: Non-cooperative games. Annals of mathematics (1951) 286–295
Navigli, R.: Word sense disambiguation: A survey. ACM Computing Surveys (CSUR) 41(2) (2009) 10
Pantel, P., Lin, D.: Discovering word senses from text. In: Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, ACM (2002) 613–619
Rentoumi, V., Giannakopoulos, G., Karkaletsis, V., Vouros, G.A.: Sentiment analysis of figurative language using a word sense disambiguation approach. In: RANLP. (2009) 370–375
Sammut, C., Webb, G.I.: Encyclopedia of machine learning. Springer (2011)
Schmid, H.: Probabilistic part-of-speech tagging using decision trees. In: Proceedings of the international conference on new methods in language processing. Volume 12., Manchester, UK (1994) 44–49
Smrž, P.: Using wordnet for opinion mining. In: Proceedings of the Third International WordNet Conference, Masaryk University (2006) 333–335
Szabó, G., Fath, G.: Evolutionary games on graphs. Physics Reports 446(4) (2007) 97–216
Tanigaki, K., Shiba, M., Munaka, T., Sagisaka, Y.: Density maximization in context-sense metric space for all-words wsd. In: ACL (1), Citeseer (2013) 884–893
Von Neumann, J., Morgenstern, O.: Theory of Games and Economic Behavior (60th Anniversary Commemorative Edition). Princeton university press (2007)
Vickrey, D., Biewald, L., Teyssier, M., Koller, D.: Word-sense disambiguation for machine translation. In: Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing, Association for Computational Linguistics (2005) 771–778
Weaver, W.: Translation. Machine translation of languages 14 (1955) 15–23
Zhu, X., Ghahramani, Z.: Learning from labeled and unlabeled data with label propagation. Technical report, Technical Report CMU-CALD-02-107, Carnegie Mellon University (2002)