
Meta-Learning for Fast Dialog System Habituation to New Users
Abstract: When a new user comes on board a mobile dialog app, the system needs to quickly learn this user’s preferences in order to provide customized service. Learning speed depends on miscellaneous parameters such as probability smoothing parameters. When a system already has a large number of other users, then we show how meta-learning algorithms can leverage that corpus to find parameter values which improve the learning speed on new users.
1 Motivation
You arrive at the office in the morning and say to your new assistant:
“Get me Joe on the phone, please.”
The assistant looks at your address book: “Is that Joe Smith or Joe Brown?”
You say, “Brown.”
Next morning, again, “I need to talk to Joe.”
Assistant: “Brown, right? Not Smith?”
You: “Yes, Brown.”
The next time you want Joe, the assistant probably doesn’t even ask, maybe just confirms:
“OK, calling Joe Brown.”
A psychologist might call the assistant’s changing responses “habituation,” a clearly useful characteristic of human behavior, necessary for establishing rapport between individuals. But that assistant might not be a person – it could be a software app. That app, too, must habituate quickly. To achieve this, we show that it needs to draw on its experiences with other users it has encountered before you. It learns your preferences by observing you, but it must first learn how to learn by observing a sample of other users.
Rapport, of course, is a two-way street. While the assistant learns to anticipate your needs, you come to know the assistant’s mind. For example, after calling Joe
Raimo Bakis: IBM T. J. Watson Research Center, 1101 Kitchawan Rd, Yorktown Heights, NY 10598, USA, e-mail: [email protected]
Jiří Havelka, Jan Cuřín: IBM Prague Research Lab, V Parku 2294/4, Prague, 148 00, Czech Republic, e-mail: {havelka, jan_curin}@cz.ibm.com
Brown a few times, you know you must now say the full name if you want Joe Smith, or the assistant would dial the wrong Joe.
For efficient communication with an electronic assistant, that device, too, needs to behave in a sufficiently human-like manner to enable the user to develop a sense of mutual understanding. This is another reason for software to mimic human traits like habituation.
Finally, a mystery challenge: you often talk to Joe Brown in the morning, but not in the afternoon, and now it is late in the day, and you are calling a man named Joe. Is it likely to be the same person?
2 Related Work
In recent years, there has been a great amount of research into statistical dialog systems. Partially Observable Markov Decision Processes (POMDPs) offer a general framework for implementing a statistical dialog manager (DM) module, consisting of a belief estimation sub-module (modeling the DM’s beliefs about the user’s state) and an action policy sub-module (specifying what action to take in a belief state). POMDPs represent a principled and theoretically well-grounded approach to implementing statistical spoken dialog system, see Young et al. (2013) for a survey of the current state of art in the development of POMDP-based spoken dialog systems.
Even though a POMDP can be used as a theoretical model for implementing the whole DM in a dialog system, doing so is a challenging and highly non-trivial task, requiring a model of the domain and a source of data for optimizing hidden parameters of the model. From a mundane point of view, replacing an existing rule-based dialog management module in a spoken dialog system might be infeasible due to practical reasons and costs.
In this work we present an approach that allows us to take a step in the direction of incremental introduction of statistical modules into dialog systems, be it into existing or newly developed dialog applications. We concentrate on modeling beliefs over sub-parts of the full dialog state that can be used by hand-crafted or automatically learned policies for sub-dialogs. Such “local” eliefs can be exposed to a dialog app developer in a simple and non-intrusive way, allowing him or her to take advantage of them and potentially greatly simplify the implementation of dialog flow (policy), while at the same time improving the quality of the app, for example by shortening average task completion time.
Discovering users’ preferences and using them appropriately is essential for providing personalized user experience, see e.g. Jannach and Kreutler (2005). Our approach could be described as non-intrusive preference elicitation where information gathered across users is used for tuning shared parameters that allow for quickly adapting a particular user’s model, thus mitigating the so-called new user problem (poor models for new users).
We show that it is possible to estimate beliefs in an unknown and changing environment (such as, for example, a user’s preferred contacts in his/her changing contact list) in a uniform manner, allowing the use of dialog policies common to all users. We believe that this addresses environments different from those generally employed in POMDP-based dialog systems, which tend to be stable and shared by all users, such as bus scheduling (Black et al. 2011) or tourist information domains (Young et al. 2010).
3 Outline
In the next section, we introduce meta-learning using a small pilot experiment, based on actual mobile-user dialogs, in which the system learns to efficiently estimate probabilities of user intents in a scenario similar to the hypothetical one introduced above. Subsequently, in section 5, we view this experiment in a larger context and discuss extended applications of similar principles. There we also address the question of the mysterious contact you are calling late in the day, which we mentioned at the end of section 1.
4 Meta-Learning Introduced via a Pilot Experiment
We address our motivating problem from section 1: Given a “short list” of contacts, our goal in this experiment is to reduce the DM’s remaining uncertainty –measured in terms of entropy – about the user’s intent to as low a value as possible.
4.1 Data Sample
From a sample consisting of logs of 2,790 dialog sessions on mobile devices, we extracted all those where a user asked to make a phone call but the dialog manager (DM) was unable to determine a unique phone number on the basis of the user’s initial request. The DM then presented a list of choices to the user, both in a GUI display and by Text-To-Speech. We selected only those dialogs in which the user subsequently made a unique selection from that list and where the DM then dialed that number. We found 134 such dialogs – these constitute the sample for the following discussion. We will assume that the telephone number which the DM finally dialed in each of these dialogs represented user’s true intent for that dialog.
In all the dialogs in this sample, a rule-based component of the DM had already determined that the user’s intent was to make a phone call, and had furthermore narrowed down the possible intended contacts to a short list. In this experiment a statistical algorithm then attaches a probability or “belief” to each candidate in the short list. Our discussion applies to a generic statistical algorithm; in section 4.3 we present a concrete instance of such an algorithm and show how we can tune it using a data sample.
4.2 Formulation as Optimization Problem
We formulate the above task as an optimization problem, which allows us to find optimal values of parameters of a statistical algorithm of our interest using standard numerical optimization methods.
Let K be the number of dialogs; in the present study, K = 134. Let Ik be the length of the contact short list in the k-th dialog, where k = 1, 2, . . . , K.
Now consider the contact who appears in position i in that list. Let nk,i be the total number of times this contact has already been called by the same person who is the user in the k-th dialog. Furthermore, let ik be the index of that user’s true intent in the short list in this, the k-th dialog.
The statistical algorithm calculates a belief (subjective probability) bk(i) for the i-th contact in the short list in the k-th dialog. These values are normalized so that
Now let pk (i) designate the true probability of the i-th candidate in the k-th dialog. Because we assume we know the user’s actual intent with certainty, we have pk (ik) = 1 and pk(j) = 0 for all j ∈ {1, 2, . . . , Ik } such that j ≠ ik. In that case, the entropy of the true probabilities is zero, H (pk) = 0, and hence the cross-entropy H (pk, bk ) becomes equal to the Kullback-Leibler divergence DKL (pk‖bk ) of the beliefs bk from the true probabilities pk , which in turn becomes equal to − log bk (ik ).
We now define our objective function as the average value of that cross-entropy:
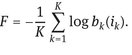
Clearly, if the beliefs were always correct, so that
then F would achieve its minimum value, F = 0. In practice, we will generally not reach that value, but our aim is to minimize F.
Whenever we can evaluate the gradient of an objective function with respect to its parameters, we can try to find optimal values of the parameters using standard numerical optimization methods, such as gradient descent or L-BFGS (Liu and Nocedal 1989). In our case, we would tune any relevant parameters of a statistical algorithm implementing belief estimation of our choice.
4.3 A Concrete Algorithm – Laplace Smoothing
When a statistical algorithm calculates bk (i), it is, in principle, allowed to use all information in existence at the time of that computation. In section 5 we discuss the use of several kinds of data.
In this pilot study, however, we restricted that computation to use only the counts nk,i and one additional parameter α. We denote this by writing
When, for some k, all counts are large, that is
then it might be reasonable to use the maximum-likelihood estimator for all i = 1, 2, . . . , Ik
But we are interested in hitting the ground running, so to speak. Our probability estimates must be as accurate as possible even when nk,i = 0 for some k and i. In those cases Equation (2) would clearly be wrong, because it would set bk(i) = 0 whenever nk,i = 0. This would imply that the DM knew with certainty that the user was not calling candidate i in dialog k. For example, if by the time dialog k started, the user had called Joe Brown once but had never yet called Joe Smith, and if that user did now want to call Joe Smith, then the DM would have to assume that it mis-heard, or that the user mis-spoke, because according to Equation (2) the probability of calling Joe Smith in dialog k would be zero – an exact mathematical zero with no wiggle-room.
But if Equation (2) is wrong, then what is the true probability of calling somebody new, somebody this user has never called before with this app? That question – how to calculate the probability of a hitherto unseen event – has vexed philosophers for centuries. What is the probability that the sun will not rise tomorrow? Or the probability of a black swan? Fortunately, in our application, we don’t have to philosophize or speculate, we can determine the answer empirically through meta-learning.
A frequently used method for getting rid of the zero probabilities for unseen events is probability smoothing. Perhaps the simplest and oldest way of doing this is additive smoothing, also known as Laplace smoothing (Manning et al. 2008). This method simply adds a “smoothing constant” α to each observed count n. The probability estimate for candidate i in the k-th dialog becomes then for all i = 1, 2, . . . , Ik
Under certain theoretical assumptions, the correct value for the smoothing constant would be α = 1. In realistic situations, however, this is generally not the optimal value. Imagine, for example, a population of users who called all contacts in their phone books equally often. Then it is easy to see that the DM should ignore the observed counts – these would be just statistical noise. Optimal smoothing, in that case, would be achieved when α → ∞, which would yield equal probabilities for all candidates in the short list. At the other extreme, consider a population where every user only ever called one person, regardless of how many contacts they had in their phone book. In that case α = 0 would be the correct value. Real populations of users fall somewhere in between. That is why it is necessary to determine α empirically. Within any given population of users, of course, there is also variation of behaviors, but we can at least determine the best value for the population average.
Figure 1 shows how the average cross-entropy defined by Equation (1) depends on α in our sample. For this population of users we found the optimal value to be α = 0.205. This is significantly lower than the sometimes-quoted theoretical value of 1, but is definitely larger than zero, which vindicates that meta-learning can indeed improve belief estimation for new users using data from a population of other users.
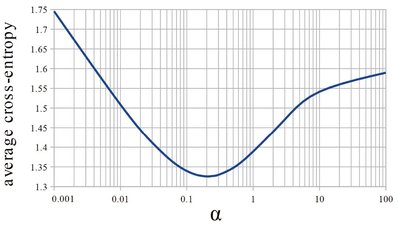
Fig. 1: Average cross-entropy depending on smoothing constant α
5 Future Work
The beliefs calculated from Equation (3) are the same in the morning as in the evening. To accommodate the hypothetical example in the introduction where you might call Joe Brown more often in the morning, we could let the values nk,i in Equation (3) be functions of the time of day. Let ϕ be the time-of-day phase of the proposed new call: 0 at midnight, 2π next midnight. Then we might write
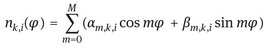
(4)
or we might prefer a log-linear model where

(5)
The α and β coefficients would be computed by some algorithm from not only the total number of previous calls to the same contact by the same caller, but also from the times of these calls. Space does not permit a detailed discussion here, but algorithms related to Fourier analysis are obvious candidates. These algorithms would involve parameters affecting smoothing across candidates as well as smoothing across time. All such parameters would be optimized empirically in ways analogous to that illustrated in the previous section.
The predicted beliefs could be allowed to depend on many other variables as well, in addition to the time of day. Obviously, a user’s preferences change as time passes, which could be modeled using a decay parameter (a function of elapsed time) applied to individual past observations. The user’s geographic location at the time of the call may predict which pizza shop gets the order. The probability of calling a taxi service may depend on the weather, etc.
When the beliefs are calculated as functions of quantities for which we have good intuitive models, then we can design special-purpose functions such as those in Equations (3)–(5). When this is not possible, then more general families of parametric functions may be appropriate, such as artificial neural nets, see for example Bishop (2006), Rumelhart et al. (1986).
6 Summary
Cognitive behavior on the part of a mobile device – behavior which appears thoughtful and intelligent to the user – requires, among other things, that the system anticipate users’ wishes and intents as quickly as possible. How fast and how accurately it learns a new user’s preferences depends on parameter settings which, in turn, must be learned from a sample of other users from the same population. In this report, we illustrated this principle by means of a simple probability-smoothing example, and we sketched extensions of the algorithm for handling more complex patterns.
Bibliography
Bishop, C.M. (2006) Pattern Recognition and Machine Learning. Springer
Black, A.W., Burger, S., Conkie, A., Hastie, H., Keizer, S., Lemon, O., Merigaud, N., Parent, G., Schubiner, G., Thomson, B., et al. (2011) Spoken dialog challenge 2010: Comparison of live and control test results. In: Proceedings of the SIGDIAL 2011 Conference. pp. 2–7. Association for Computational Linguistics
Jannach, D., Kreutler, G. (2005) Personalized User Preference Elicitation for e-Services. In: Cheung, W., Hsu, J. (eds.), Proceedings of the 2005 IEEE International Conference on e-Technology, e-Commerce and e-Service. pp. 604–611. IEEE
Liu, D.C., Nocedal, J. (1989) On the limited memory BFGS method for large scale optimization. Mathematical Programming 45(1–3):503–528
Manning, C.D., Raghavan, P., Schütze, H. (2008) Introduction to Information Retrieval. Cambridge University Press, Cambridge, UK
Rumelhart, D.E., McClelland, J.L., et al. (1986) Parallel Distributed Processing: Volume 1: Foundations. MIT Press, Cambridge, MA
Young, S., Gašić, M., Thomson, B., Williams, J. (2013) POMDP-Based Statistical Spoken Dialog Systems: A Review. Proceedings of the IEEE 101(5):1160–1179
Young, S., Gašić, M., Keizer, S., Mairesse, F., Schatzmann, J., Thomson, B., Yu, K. (2010) The Hidden Information State Model: a practical framework for POMDP-based spoken dialogue management. Computer Speech & Language 24(2):150–174