
Extraction of Polish Multiword Expressions
Abstract: Natural language processing for fusional languages often requires using inflection dictionaries which lack multiword expressions (MWE) – proper names and other sequences of words that have new properties as a whole. This paper describes an effort to extract such MWEs from Polish text. The search is not limited to any particular domain and there are no predefined categories, gazetteers or manually defined rules, what makes it different from named entity recognition (NER). As there are no Polish linguistic resources containing MWEs, we cannot use supervised learning techniques, so Wikipedia content and link structure are used to create syntactic patterns that are recognised in text using non-deterministic automata. The results can be used directly or transformed into an inflection dictionary of MWEs. Several algorithms are presented as well as results of a test on a corpus of Polish press releases.
1 Introduction
Natural language processing usually makes use of either simple word frequency statistics or more advanced language-dependent features. For Polish (and other inflecting languages) such features are: part of speech (POS), lemma and grammatical tags: gender, case etc. Feature extraction can be done using statistical algorithms (Kuta et al. 2007) or with a morphological analyser such as Morfeusz (Woliński 2006) or Morfologik47. Alternatively, one can use the Polish Inflection Dictionary (SFJP)48. The dictionary is still being improved and current effort aims at extending it with semantic information – full semantic relations are introduced for as many words as possible (Pohl 2009, Chap. 12.2) while the rest of them should have short semantic labels (Chrząszcz 2012). However, SFJP, as well as other inflection resources for Polish, is missing multiword expressions (MWEs). They are lexemes that consist of multiple tokens and have properties that differ from what can be inferred from individual tokens. We could roughly define them as “idiosyncratic interpretations that cross word boundaries” (Sag et al. 2002). MWE often has a completely new meaning: “panna młoda” means bride, while literal meaning would be young maid (Lubaszewski 2009). Proper names are also often MWEs. Their meaning and inflection should definitely be present in inflection dictionaries to allow their recognition and processing.
Paweł Chrzązcz: Computational Linguistics Department, Jagiellonian University, ul. Gołębia 24, 31-007 Kraków, and Computer Science Department, AGH University of Science and Technology, Aleja Adama Mickiewicza 30, 30-059 Kraków, e-mail: [email protected]
Tab. 1: Examples of nominal MWEs that we focus on.
| Word type | Examples |
|---|---|
| Person names | Maciej Przypkowski, Allen Vigneron, Szymon z Wilkowa (Szymon from Wilków) |
| Other proper names | Lazurowa Grota (Azure Cave), Polski Związek Wędkarski (Polish Fishing Association) |
| Other named entities | rzeka Carron (River Carron), jezioro Michigan (Lake Michigan), premier Polski (Prime Minister of Poland) |
| Terms of art | martwica kości (bone necrosis), dioda termiczna (thermal diode), zaimek względny (relative pronoun) |
| Idioms and other common words | panna młoda (bride), piłkarz ręczny (handball player), baza wojskowa (military base) |
The goal of this paper is to present several methods of automatic extraction of MWEs from Polish text. The algorithms use the Polish Wikipedia to learn syntactic patterns that are later recognized in raw text. The results include inflection information and can either be used directly or transformed into an inflection dictionary of MWEs. We focus on nominal MWEs (table 1), because the majority of MWEs are nouns and Wikipedia headwords are nominal phrases.
1.1 Related Work
A widespread type of multiword recognition is Named Entity (NE) Recognition (NER). NEs are phrases that represent entities belonging to predefined categories: people, geographical objects, dates etc. NER often makes use statistical methods e.g. maximum entropy model (Tjong Kim Sang and De Meulder 2003) or HMMs that can be combined with predefined syntactic and semantic rules as well as gazetteers, e.g. Zhou and Su (2002) for English, Piskorski et al. (2004) for Polish. Wikipedia has also been used as a source for NER. One could use links and definitions (Nothman et al. 2009) or categories and interwiki links (Richman and Schone 2008) as the training data. Although these attempts often reached F1 (F-measure) of 70–90% on various corpora, they were limited to carefully selected NE categories (usually the ones giving best results) and used manual rules or gazetteers. As our goal is to detect all nominal MWEs without any rules or limits, we must look for a more general approach.
For some languages, e.g. French, MWEs are included in dictionaries and corpora (Constant et al. 2012), what makes it possible to recognise them with F1 over 70%. For other languages, one could use association measures such as Mutual Information (MI), χ 2 or Permutation Entropy (Zhang et al. 2006). Ramisch et al. (2008) evaluated these methods on simple structures (e.g. adjective-noun), but although they used language-dependent information, precision remained low. Attia et al. (2010) used Wikipedia to extract nominal semantic non-decomposable MWEs relying on Crossligual Correspondence Asymmetries. The extraction results were promising with F1 over 60%, but there was no recognition test on a corpus. Finally, Farahmand et al. (2014) used a manually tagged sample of 10K negative and positive English MWE examples to train an SVM classifier. The results were very positive (89% F1) but the test was performed only on the predefined examples. Our approach differs from the previous attempts as no MWE resources are used, inflection information is extracted, we do not limit the nominal MWEs in any way and we test various algorithms by tagging a corpus sample.
1.2 Anatomy of Polish Nominal MWEs
A multiword expression consists of two or more tokens: words, numbers or punctuation marks. A token that is a Polish word can be either fixed or inflectable. Inflectable words form the core of the MWE. They are mostly nouns and adjectives, but can also be numerals and participles. In the base form, all inflectable tokens must occur in nominative case. The number is usually singular, but there are also some pluralia tantum – all inflectable tokens must be plural for them. The inflectable tokens need not have the same gender, e.g. “kobieta kot” (catwoman).
Example: “Związek Lekkoatletyczny Krajów Bałkańskich” (Athletic Association of Balkan Countries). This expression begins with an inflectable non-animate male noun “związek” followed by an inflectable non-animate male nominative adjective “lekkoatletyczny”, followed by two fixed words: a noun and an adjective, both in genitive case. The instrumental case of this expression would be “Związkiem Lekkoatletycznym Krajów Bałkańskich” – inflectable tokens change their form accordingly. We consider it illegal to change the gender of any word or to modify their order. We use SFJP for word recognition.
2 MWE Extraction Methods
2.1 Extraction Using the Wikipedia as a Dictionary
The simplest way to use the Wikipedia for MWE recognition is to treat it as a dictionary. We filtered out headwords with only one token as well as the ones for which we could not extract semantic labels (Chrząszcz 2012). The remaining headwords were used to create patterns that consist of one entry for each token. For words that can be inflectable, the pattern contains the word ID (from SFJP) and the grammatical categories49. For fixed tokens (punctuation, words not in SFJP, prepositions, verbs etc. as well as words in non-nominative cases) the pattern contains just the token itself.
Example: For the headword “Związek Lekkoatletyczny Krajów Bałkańskich” the pattern is shown below in a simplified form. ’?’ means maybe inflectable. It is not possible to tell if “związek” should be capitalised because all Wikipedia headwords are capitalised.
[? (z|Z)wiązek male non-animate singular noun] [? Lekkoatletyczny male singular adj.] [Krajów] [Bałkańskich]
2.1.1 Dictionary Pattern Matching (DM)
To check if a sequence of tokens matches a pattern, we created a non-deterministic finite automaton with one transition per pattern option for each token. If a pattern entry for a token is ambiguous, the automaton forks into multiple states and its diagram becomes a tree.
Each matching step means checking all the possible transitions for the current state set and the current input token. For a fixed token, it is enough to check if the token is the same as the pattern entry. For an inflectable word though, the matching process is more complex. One has to check if the word ID is the same and if the form is a valid inflected one. This would e.g. eliminate the phrase “Związkiem Lekoatletyczną Krajów Bałkańskich” (second token changed gender to female). The form has to agree for all inflected words, so for the first of them the grammatical categories (number, case) are extracted and they need to be the same for all subsequent inflected tokens. This would eliminate e.g. “Związkiem Lekkoatletycznemu Krajów Bałkańskich” (first token in instrumental case, second in accusative case).
The result of traversing the above automaton is a list of visited accepting states (alternatively: a list of paths leading to these states). This concept can be expanded to allow matching multiple patterns at once – all automata can be combined into one. Its output will be a list of (pattern, path) pairs. This automaton can be then applied to raw text by starting it for each subsequent word. Whole corpus can be then analysed in one pass by performing all the matching simultaneously.
The desired output format is a list of matching words with their declension information. We decided not to allow overlapping words. The tests revealed that in these cases choosing a non-overlapping subset covering as many tokens as possible is the best option.
2.2 Extraction Using Syntactic Patterns
The performance of DM is limited to the headwords of Wikipedia, so that method is incapable of recognising any unknown words. One can observe that there are groups of MWEs which share similar syntactic structure, e.g. “tlenek węgla” (carbon dioxide) and “chlorek sodu” (sodium chloride) both contain one inflectable male noun and one fixed male noun in genitive case. What is more, they both often appear in the text in similar context – e.g. in genitive case after a noun (“roztwór chlorku sodu” – a solution of sodium chloride, “reakcja tlenku węgla” – a reaction of carbon dioxide) or after the preposition “z” (with) in instrumental case (“reakcja . . . z chlorkiem sodu” – a reaction of . . . with sodium chloride). We decided to automatically create syntactic patterns that would express these regularities and recognise them in text using an automaton similar to the one used for DM. The matching algorithm is called Syntactic pattern Matching (SM). The patterns should not be created by hand – otherwise they would be limited to the structures known to their author. We tested several possible pattern structures and chose the one presented below. For each token of the MWE the pattern contains one entry:
- – For inflectable words, it begins with an asterisk (*) and contains the POS and (when possible) gender, number and case of the base form. Each of these features can be ambiguous.
- – For prepositions and some punctuation marks, the token itself is the pattern.
- – For fixed words that are in SFJP, it contains the POS and (when possible) gender and case. Each of these features can be ambiguous.
- – For other tokens it contains the category of the token (word, number, punctuation, other).
Example. The pattern for “czarna dziura” (black hole) is:
[* fem. singular noun] [* fem. singular adj.]
To include the information about the context, we decided that each pattern may be connected to one or more context patterns that have a similar structure to the core pattern (of course context tokens are not inflectable). The context covers one word before and one after the MWE. For example, if “czarna dziura” occurs in the expression: “(...) masywnej czarnej dziury.”, the context pattern will be:
[fem. singular noun, gen., acc. or loc.] [* fem. singular noun] [* fem. singular adj.][punct.]
2.2.1 Pattern Construction
For each headword from Wikipedia we need to know which tokens are inflectable, how they are inflected (for ambiguous words), in what context they appear in text and if the first word is lowercase. Our choice was to gather this information from links from other articles leading to the given headword as well as occurrences of the inflected word in the article itself. Having a list of inflected occurrences of the MWE with their contexts, inferring the inflection pattern does not seem complicated, but the algorithm is actually fairly complex. This is due to the ambiguities of fusional languages and errors present all over Wikipedia. The algorithm thus has to find the largest subset of occurrences that lead to a non-contradictory pattern and has exponential complexity, so we implemented several optimisations that successfully limit the impact of this fact.
Because we know how many times each context pattern occurred in each grammatical form, the automaton performing SM can calculate a score of each matched phrase: it would be the total number of all occurrences of the matched patterns for the recognised form50. We use the scores to choose the best among overlapping expressions and as a threshold used to filter out low quality matches.
2.3 Compound Methods
In an attempt to improve recognition performance, one can combine the two methods described above. The most important possibilities are listed below. Some of them are using Wikipedia Corpus (WC) that we created from the whole Wikipedia text. We also tried an iterative approach, but it did not provide significant improvement.
DM for words with patterns (pDM) Like DM, but the input headwords are limited to the ones for which syntactic patterns were created. This allows identifying inflectable tokens and lowercase first tokens. The matches are scored according to the number of occurrences of the pattern for the given word. The main drawback is that the number of words is reduced.
DM for SM results (SM-DM) Like pDM, but uses a second dictionary, created from the results of SM on WC. To obtain this dictionary, SM results are grouped by lemma (they also need some disambiguation and conflict resolution). A concept of word score is introduced – it is the sum of all scores of the contributing matches. SM-DM provides scores for results – they are pDM scores from the first dictionary and word scores from the second one. This method significantly increases recall at the cost of precision.
SM for SM results (SM-SM) Like SM, but uses a second set of patterns. It is created from the results of SM on WC. A dictionary is constructed (like for SM-DM) and the syntactic patterns are created from that dictionary. The goal of the first SM phase is to find more words that can be used to create patterns.
SM for pDM results (pDM-SM) Like SM-SM, but the dictionary is created using pDM, not SM. The pDM phase aims at providing additional context patterns for SM.
SM for DM results (DM-SM) This method is an attempt to create the syntactic patterns using the whole Wikipedia – a dictionary is created from the results of DM on WC and it is used to create the patterns for SM. The main drawback is that a lot of inflection ambiguities remain from the DM phase.
3 Tests and Results
There are no known corpora of Polish text tagged for MWEs, so we needed to create the test set from a corpus. We already had the Wikipedia Corpus, but cutting a part of Wikipedia was problematic as its network structure (which was used by the methods in multiple places) was broken. As a result, we decided to use a corpus of press releases of the Polish Press Agency (PAP), as it is a large collection of texts from multiple domains. 100 randomly chosen press releases were tagged manually by two annotators. All disagreements were discussed and resolved. An example of a tagged release is given below:
We wtorek [*mistrz *olimpijski], świata i Europy w chodzie [*Robert *Korzeniowski] weźmie udział w stołecznym [*Lesie *Kabackim] w [*Biegu ZPC SAN] o [*Grand *Prix] Warszawy oraz o [*Grand *Prix] [*Polskiego *Związku Lekkiej Atletyki].
The were two types of the test: the structural test required only the tokens of the MWE to be the same for the expected and matched expressions and the syntactic test also required the inflectable words to be correctly indicated. All parameters of the tested methods were optimised using a separate test set of 10 press releases –the main test sample was used only for the final evaluation.
3.1 Test Results
Table 2 shows results optimized for best F1 score of the structural test. Basic dictionary algorithms have high precision but low recall, because Wikipedia does not contain all possible MWEs. DM has poor syntactic test results because the inflection patterns are unknown. SM0 is SM without the pattern contexts. SM preforms a bit better because of the contexts, but it is limited by sparse link connections in Wikipedia. The only compound method that brings significant improvement is SM-DM. Fig. 1 (left) presents precision-recall graphs for the best performing methods.
All the errors for the best performing method, SM-DM, were analysed one by one. It turned out that in many cases the identified phrases are not completely wrong. Such problematic cases are:
Tab. 2: Results of the test on a sample of 100 tagged PAP press releases.
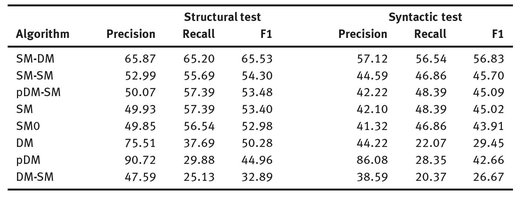
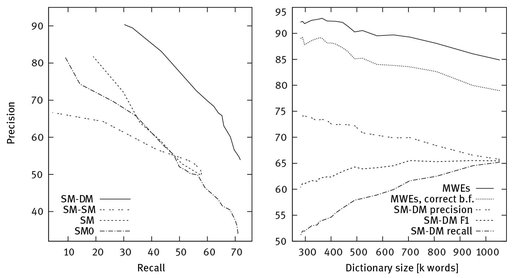
Fig. 1: Left: precision-recall graphs for the structural test. Right: Quality of the dictionary created by the SM phase of SM-DM as a function of changing dictionary size after applying different word score thresholds. From top to bottom: % of true MWEs in the dictionary created by the SM phase, % of true MWEs with correctly identified base forms, precision, F1 and recall of SM-DM.
- – Overlapping expressions difficult to choose from (even for a human): “Piłkars-ka reprezentacja Brazylii” contains two MWEs: a term “reprezentacja piłkars-ka” with altered token order (a football team) and a named entity “reprezentacja Brazylii” (Brazilian team).
- – Unusually long names, spelling and structural errors: “Doroty Kędzierzwskiej” (misspelled surname), “Polska Fundacja Pomocy humanitarnej ‘Res Humanae’” (unusual structure and an accidental lowercase letter).
- – Phrases that are not MWEs in the particular (semantic) context: “osoba paląca sporadycznie” contains the term “osoba paląca” (a smoker) while it means a person smoking sporadically.
- – For the inflection errors: one of the words is not in SFJP (usually a surname): “Janusz Steinhoff”, “Władysław Bartoszewski”.
The SM phase of SM-DM produces a dictionary of 4.45 million words that can be filtered by score to achieve either high precision or recall. The threshold of 150 yielded best results (65.5% F1 for SM-DM), so we analysed the quality of the dictionary for a random sample of 1000 entries above that score. About 79% of the resulting 1.05 million words were correct MWEs and further 6% were MWEs, but had wrong base forms. This quality can be further increased at the cost of dictionary size and SM-DM recall (fig. 1, right). Although it is difficult to estimate the target size of an MWE lexicon as it is unclear how large human lexicons are (Church 2013), the results make us consider SM a good method for building MWE lexicons.
3.2 Future Work
There seems to be some significant room for further improvement, especially in the SM algorithm. The first step would be to eliminate the errors that are results of words missing from SFJP either by adding another dictionary (e.g. Morfologik) or by filling missing people (sur)names directly in SFJP. We also remind that one of our assumptions was not to use any user-defined rules. However, there were many false positives in the dictionary that could be eliminated by manual patterns, e.g. “wrzesień 2011” (September 2011), “część Sztokholmu” (a part of Stockholm ), “pobliże Jerozolimy” (vicinity of Jerusalem). This could improve the dictionary quality and increase the precision of SM-DM accordingly. We could also use other Polish corpora instead of the Wikipedia content. The tests could also be improved to allow overlapping words (they are not necessarily errors). After improving the algorithms, we plan to incorporate the resulting MWEs into SFJP and transfom SM-DM into an integral part of this dictionary.
4 Conclusions
The presented algorithms are the first successful attempt (known to the authors) of automatic extraction of all Polish MWEs. It is not easy to compare the results to other papers on NER or MWE recognition as they either limit the scope of MWEs to specific categories or use resources that do not exist for Polish. We would like to continue our research and improve the quality of the algorithms as well as the tests. Finally, we would like to extend SFJP with MWEs. Our opinion is that the research is going in the right direction and the final goal is likely to be reached in the near future.
Bibliography
Attia, M., Tounsi, L., Pecina, P., van Genabith, J., and Toral, A. (2010) Automatic extraction of arabic multiword expressions. In: Proceedings of the Workshop on Multiword Expressions: from Theory to Applications, Beijing, China, 28 August 2010, pp. 18–26.
Chrząszcz, P. (2012) Enrichment of inflection dictionaries: automatic extraction of semantic labels from encyclopedic definitions. In: Sharp, B. and Zock, M. (eds.), Proceedings of the 9th International Workshop on Natural Language processing and Cognitive Science, Wrocław, Poland, 28 June – 1st July 2012, pp. 106–119.
Church, K. (2013) How many multiword expressions do people know? ACM Transactions on Speech and Language Processing (TSLP), 10(2):4.
Constant, M., Sigogne, A., and Watrin, P. (2012) Discriminative strategies to integrate multi-word expression recognition and parsing. In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers – Volume 1, Jeju, Korea, 8–14 July 2012, pp. 204–212.
Farahmand, M. and Martins, R. (2014) In: A supervised model for extraction of multiword expressions based on statistical context features. Proceedings of the 10th Workshop on Multiword Expressions, Gothenburg, Sweden, 26–27 April 2014, pp. 10–16.
Gajęcki, M. (2009) Słownik fleksyjny jako biblioteka języka c. In: Lubaszewski, W. (ed.), Słowniki komputerowe i automatyczna ekstrakcja informacji z tekstu, pp. 107–134. Wydawnictwa AGH, Kraków.
Kuta, M., Chrząszcz, P., and Kitowski, J. (2007) A case study of algorithms for morphosyntactic tagging of polish language. Computing and Informatics, 26(6):627–647.
Lubaszewski, W. (2009) Wyraz. In: Lubaszewski, W. (ed.), Słowniki komputerowe i automatyczna ekstrakcja informacji z tekstu, pp. 15–36. Wydawnictwa AGH, Kraków.
Lubaszewski, W., Wróbel, H., Gajęcki, M., Moskal, B., Orzechowska, A., Pietras, P., Pisarek, P., and Rokicka, T. (2001) (ed.), Słownik Fleksyjny Języka Polskiego. Lexis Nexis, Kraków.
Nothman, J., Murphy, T., and Curran, J. R. (2009) Analysing wikipedia and gold-standard corpora for ner training. In: Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics, Athens, Greece, 30 March – 3 April 2009, pp. 612–620.
Piskorski, J., Homola, P., Marciniak, M., Mykowiecka, A., Przepiórkowski, A., and Woliński, M. (2004) Information extraction for polish using the sprout platform. In: Kłopotek, A., Wierzchoń, T. and Trojanowski, K. (eds.), Proceedings of the International IIS: IIPWM’ 05 Conference, Gdańsk, Poland, 13–16 June 2005, pp. 227–236.
Pohl, A. (2009) Rozstrzyganie wieloznacznołści, maszynowa reprezentacja znaczenia wyrazu i ekstrakcja znaczeń In: Lubaszewski, W. (ed.), Słowniki komputerowe i automatyczna ekstrakcja informacji z tekstu, pp. 241–255. Wydawnictwa AGH, Kraków.
Ramisch, C., Schreiner, P., Idiart, M., and Villavicencio, A. (2008) An evaluation of methods for the extraction of multiword expressions. In: Proceedings of the LREC Workshop – Towards a Shared Task for Multiword Expressions, Marrakech, Morocco, 1 June 2008, pp. 50–53.
Richman, A. E. and Schone, P. (2008) Mining wiki resources for multilingual named entity recognition. In: Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Columbus, OH, USA, 15–20 June 2008, pp. 1–9.
Sag, I. A., Baldwin, T., Bond, F., Copestake, A., and Flickinger, D. (2002) Multiword expressions: A pain in the neck for nlp. In: Gelbukh, A. (ed.), Proceedings of the Third International Conference on Computational Linguistics and Intelligent Text Processing, Mexico City, Mexico, 17–23 February 2002, pp. 1–15.
Tjong Kim Sang, E. F. and De Meulder, F. (2003). Introduction to the conll-2003 shared task: Language-independent named entity recognition. In: Daelemans, W. and Osborne, M. (eds.), Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, 27 May – 1 June 2003, Edmonton, Canada, Vol. 4, pp. 142–147.
Woliński, M. (2006) Morfeusz – a practical tool for the morphological analysis of polish. Advances in Soft Computing, 26(6):503–512.
Zhang, Y., Kordoni, V., Villavicencio, A., and Idiart, M. (2006) Automated multiword expression prediction for grammar engineering. In: Proceedings of the Workshop on Multiword Expressions: Identifying and Exploiting Underlying Properties, July 2006, Sydney, Australia, pp. 36–44.
Zhou, G. and Su, J. (2002) Named entity recognition using an hmm-based chunk tagger. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 7–12 July 2002, Philadelphia, PA, USA, pp. 473–480.