
Chapter 3
Normalizing Your Data
In This Chapter
![]() Understanding why single-table databases are inadequate
Understanding why single-table databases are inadequate
![]() Recognizing common data anomalies
Recognizing common data anomalies
![]() Creating entity-relationship diagrams
Creating entity-relationship diagrams
![]() Using MySQL Workbench to create data diagrams
Using MySQL Workbench to create data diagrams
![]() Understanding the first three normal forms
Understanding the first three normal forms
![]() Defining data relationships
Defining data relationships
Databases can be deceptive. Even though databases are pretty easy to create, beginners usually run into problems as soon as they start working with actual data.
Computer scientists (particularly a gentleman named E. F. Codd in the 1970s) have studied potential data problems and defined techniques for organizing data. This scheme is called data normalization. In this chapter, you discover why single-table databases rarely work for real-world data and how to create a well-defined data structure according to basic normalization rules.
 On the website, I include a script called buildHero.sql that builds all the tables in this chapter. Feel free to load that script into your MySQL environment to see all these tables for yourself.
On the website, I include a script called buildHero.sql that builds all the tables in this chapter. Feel free to load that script into your MySQL environment to see all these tables for yourself.
Recognizing Problems with Single-Table Data
Packing everything you've got into a single table is tempting. Although you can do it pretty easily (especially with SQL), and it seems like a good solution, things can go wrong pretty quickly.
Table 3-1 shows a seemingly simple database describing some superheroes.

It seems that not much can go wrong here because the database is only three records and six fields. The data is simple, and there isn't that much of it. Still, a lot of trouble is lurking just under the surface. The following sections outline potential problems.
The identity crisis
What's Table 3-1 about? At first, it seems to be about superheroes, but some of the information is really about things related to the superhero, such as villains and missions. This issue may not seem like a big deal, but it causes all kinds of practical problems later on. A table should be about only one thing. When it tries to be about more than that, it can't do its job as well.
Every time a beginner (and, often, an advanced data developer) creates a table, the table usually contains fields that don't belong there. You have to break things up into multiple tables so that each table is really about only one thing. The process for doing so solves a bunch of other problems, as well.
The listed powers
Take a look at the powers field. Each superhero can have more than one power. Some heroes have tons of powers. The problem is, how do you handle a situation where one field can have a lot of values? You frequently see the following solutions:
- One large text field: That's what I did in this case. I built a massive (255 character) VARCHAR field and hoped it would be enough. The user just has to type all the possible skills.
- Multiple fields: Sometimes, a data designer just makes a bunch of fields, such as power1, power2, and so on.
Both these solutions have the same general flaw. You never know how much room to designate because you never know exactly how many items will be in the list. Say that you choose the large text field approach. You may have a really clever hero with a lot of powers, so you fill up the entire field with a list of powers. What happens if your hero learns one more power? Should you delete something just to make things fit? Should you abbreviate?
If you choose to have multiple power fields, the problem doesn't go away. You still have to determine how many skills the hero can have. If you designate ten skill fields and one of your heroes learns an eleventh power, you've got a problem.
The obvious solution is to provide far more room than anybody needs. If it's a text field, make it huge; and if it's multiple fields, make hundreds of them. Both solutions are wasteful. Remember, a database can often have hundreds or thousands of records, and each one has to be the same size. If you make your record definition bigger than it needs to be, this waste is multiplied hundreds or thousands of times.
 You may argue that this is not the 1970s. Processor power and storage space are really cheap today, so why am I worrying about saving a few bytes here and there? Well, cheap is still not free. Programmers tend to be working with much larger data sets than they did in the early days, so efficiency still matters. And here's another important change. Today, data is much more likely to be transmitted over the Internet. The big deal today isn't really processor or storage efficiency. Today's problem is transmission efficiency, which comes down to the same principle: Don't store unnecessary data.
You may argue that this is not the 1970s. Processor power and storage space are really cheap today, so why am I worrying about saving a few bytes here and there? Well, cheap is still not free. Programmers tend to be working with much larger data sets than they did in the early days, so efficiency still matters. And here's another important change. Today, data is much more likely to be transmitted over the Internet. The big deal today isn't really processor or storage efficiency. Today's problem is transmission efficiency, which comes down to the same principle: Don't store unnecessary data.
When databases have listed fields, you tend to see other problems. If the field doesn't have enough room for all the data, people will start abbreviating. If you're looking for a hero with invisibility, you can't simply search for “invisibility” in the powers field because it may be “inv,” “in,” or “invis” (or even “can't see”). If you desperately need an invisible hero, the search can be frustrating, and you may miss a result because you didn't guess all the possible abbreviations. (I guess you can't see the invisible hero.)
If the database uses the listed fields model, you have another problem. Now, your search has to look through all ten (or hundreds of) power fields because you don't know which one holds the “invisible” power. This problem makes your search queries far more complicated and slower than they would have been otherwise.
 Another so-called solution you sometimes see is to have a whole bunch of Boolean fields: Invisibility, Super-speed, X-ray vision, and so on. This fix solves part of the problem because Boolean data is small. It's still troublesome, though, because now the data developer has to anticipate every possible power. You may have an other field, but it then reintroduces the problem of listed fields.
Another so-called solution you sometimes see is to have a whole bunch of Boolean fields: Invisibility, Super-speed, X-ray vision, and so on. This fix solves part of the problem because Boolean data is small. It's still troublesome, though, because now the data developer has to anticipate every possible power. You may have an other field, but it then reintroduces the problem of listed fields.
Listed fields are a nightmare.
Repetition and reliability
Another common problem with data comes with repetition. If you allow data to be repeated in your database, you can have some really challenging side effects. Refer to Table 3-1, earlier in this chapter, and get ready to answer some questions about it. . . .
What is the Slime Master's evil plot?
This question seems simple enough, but Table 3-1 provides an ambiguous response. If you look at the first row (The Plumber), the plot is Overcome Chicago with slime. If you look at The Janitor, you see that the plot is to Overcome New York with slime. Which is it? Presumably, it's the same plot, but in one part of the database, New York is the target, and elsewhere, it's Chicago. From the database, you can't really tell which is correct or if it could be both. I was required to type in the plot in two different records. It's supposed to be the same plot, but I typed it differently. Now, the data has a conflict, and you don't know which record to trust.
Is it possible the plots were supposed to be different? Sure, but you don't want to leave that assumption to chance. The point of data design is to ask exactly these questions and to design your data scheme to reinforce the rules of your organization.
Here's a related question. What if you needed to get urgent information to any hero fighting the Septic Slime Master? You'd probably write a query like
SELECT * FROM hero WHERE villain = 'Septic Slime Master'
That query is a pretty reasonable request, but it wouldn't work. The villain in The Janitor record is the Septic Slim Master. Somebody mistyped something in the database, and now The Janitor doesn't know how to defeat the Slime Master.
 If your database allows duplication, this type of mistake will happen all the time.
If your database allows duplication, this type of mistake will happen all the time.
In general, you don't want to enter anything into a database more than once. If you have a way to enter the Septic Slime Master one time, that should eliminate this type of problem.
Fields with changeable data
Another kind of problem is evident in the Age field. (See, even superheroes have a mandatory retirement age.) Age is a good example of a field that shouldn't really be in a database because it changes all the time. If you have age in your database, how are you going to account for people getting older? Do you update the age on each hero's birthday? (If so, you need to store that birthday, and you need to run a script every day to see whether it's somebody's birthday.) You could just age everybody once a year, but this solution doesn't seem like a good option, either.
Whenever possible, you want to avoid fields that change regularly and instead use a formula to generate the appropriate results when you need them.
Deletion problems
Another kind of problem is lurking right under the surface. Say that you have to fire the Binary Boy. (With him, everything is black and white. You just can't compromise with that guy.) You delete his record, and then you want to assign another hero to fight Octal. When you delete Binary Boy, you also delete all the information about Octal and his nefarious scheme because the only place Octal's information was stored was in Binary Boy's record.
In a related problem, what if you encounter a new villain and you haven't yet assigned a hero to this villain? The current data design doesn't allow you to add villains without heroes. You have to make up a fake hero, and that just doesn't seem right. Villains deserve their own table, and that's exactly what they will get.
Introducing Entity-Relationship Diagrams
You can solve all the problems with the database shown in Table 3-1 by breaking the single table into a series of smaller, more specialized tables.
The typical way of working with data design is to use a concept called an Entity-Relationship (ER) diagram. This form of diagram usually includes the following:
- Entities: Typically, a table is an entity, but you see other kinds of entities, too. An entity is usually drawn as a box with each field listed inside.
- Relationships: Relationships are drawn as lines between the boxes. As you find out about various forms of relationships, I show you the particular symbols used to describe these relationship types.
Using MySQL Workbench to draw ER diagrams
You can create ER diagrams with anything (I typically use a whiteboard), but some very nice free software can help. One particularly nice program is called MySQL Workbench (http://dev.mysql.com/downloads/tools/). This software has a number of really handy features:
- Visual representation of database design: MySQL Workbench allows you to define a table easily and then see how it looks in ER form. You can create several tables and manipulate them visually to see how they relate.
- An understanding of ER rules: MySQL Workbench is not simply a drawing program. It's specialized for drawing ER diagrams, so it creates a standard design for each table and relationship. Other data administrators can understand the ER diagrams you create with this tool.
- Integration with MySQL: After you've created a data design you like, you can have MySQL Workbench create a MySQL script to create the databases you've defined. In fact, you can even have Workbench look at an existing MySQL database and create an ER diagram from it.
Creating a table definition in Workbench
Creating your tables in MySQL Workbench is a fairly easy task:
- Create a new model.
Choose File ⇒ New to create a new model. Figure 3-1 shows the MySQL Workbench model screen.
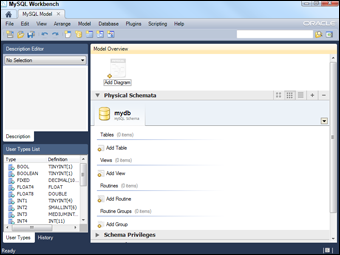
Figure 3-1: MySQL Workbench main screen.
- Create a new table.
Use the Add Table icon (near the top of the screen) to create a new table. A new dialog box opens at the bottom of the screen, allowing you to change the table name. You see a new table form like the one in Figure 3-2. Change the table name to hero but leave the other values blank for now.

Figure 3-2: Now your model has a table in it.
- Edit the columns.
Select the Columns tab at the bottom of the screen to edit the table's fields. You can add field names and types here. Create a table that looks like the hero table shown in Figure 3-3. You can use the tab key to add a new field.
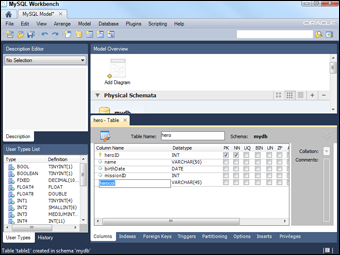
Figure 3-3: Editing the table definition.
- Make a diagram of the table.
So far, MySQL Workbench seems a lot like phpMyAdmin. The most useful feature of Workbench is the way it lets you view your tables in diagram form. You can view tables in a couple of ways, but the easiest way is to select Create Diagram from Catalog Objects from the Model menu. When you do so, you'll see a screen, as shown in Figure 3-4.

Figure 3-4: Now you have a diagram of your table.
The diagram doesn't show the contents of the table, just the design. In fact, MySQL Workbench doesn't really care that much about what is in the database. The key idea here is how the data is organized. This matters because you will be creating several tables to manage your superheroes.
- Extract the code.
If you want, you can see the SQL code used to create the table you just designed. Simply right-click the table and choose Copy SQL to Clipboard. The CREATE statement for this table is copied to the Clipboard, and you can paste it to your script. Here's the code created by Workbench:
CREATE TABLE IF NOT EXISTS 'mydb'.'hero' (
'heroID' INT NOT NULL ,
'name' VARCHAR(50) NULL ,
'birthDate' DATE NULL ,
'missionID' INT NULL ,
PRIMARY KEY (heroID) )
ENGINE = InnoDB
The code generated is similar to the code described in Chapter 2 of this minibook, with a few variations:
- Default NULL values are indicated: Most fields are defined with a default value of NULL. (Of course, the primary key can't be NULL, and it's defined that way.)
- Field and table names are quoted: The auto-generated code uses single quotes around all field and table names. Single quotes are needed when identifiers have spaces in them. Because I rarely use spaces in the name of anything, I tend not to use quotes because they complicate the code.
- The primary key notation is different: Rather than defining the primary key in the field definition, the primary key is set up as a separate entry in the table definition. This is simply a matter of style.
Introducing Normalization
Trying to cram all your data into a single table usually causes problems. The process for solving these problems is called data normalization. Normalization is really a set of rules. When your database follows the first rule, it's said to be in first normal form. For this introductory book, you get to the third normal form, which is suitable for most applications.
First normal form
The official definitions of the normal forms sound like the offspring of a lawyer and a mathematician. Here's an official definition of the first normal form:
A table is in first normal form if and only if it represents a relation. It does not allow nulls or duplicate rows.
Yeah, whatever.
Here's what it means in practical terms:
Eliminate listed fields.
A database is in first normal form if
- It has no repeating fields. Take any data that would be in a repeating field and make it into a new table.
- It has a primary key. Add a primary key to each table. (Some would argue that this requirement isn't necessarily part of first normal form, but it'll be necessary in the next step, anyway.)
In a practical sense, the first normal form means getting rid of listed fields and making a new table to contain powers. You'll need to go back to the model view to create a new table and then create the diagram again. Figure 3-5 shows an ER diagram of the data in first normal form.
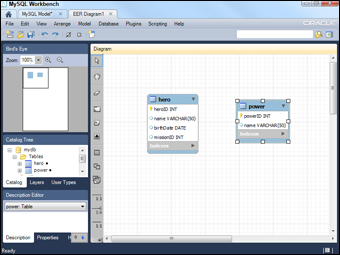
Figure 3-5: Now I have two tables.
A couple of things happen here:
- Make a new table called power.
This table contains nothing but a key and the power name.
- Take the power field away from the hero table.
The hero table no longer has a power field.
- Add a primary key to both tables.
Both tables now have an integer primary key. Looking over my tables, there are no longer any listed fields, so I'm in first normal form.
All this is well and good, but the user really wants this data connected, so how do you join it back together? For that answer, see Chapter 4 of this minibook.
Second normal form
The official terminology for the second normal form is just as baffling as the first normal form:
A table is in second normal form (2NF) only if it is in 1NF and all nonkey fields are dependant entirely on the entire candidate key, not just part of it.
Huh? You've gotta love these computer scientists.
In practical terms, second normal form is pretty easy, too. It really means
Eliminate repetition.
Look at all those places where you've got duplicated data and create new tables to take care of them.
In the hero data (shown in Table 3-1, earlier in this chapter), you can eliminate a lot of problems by breaking the hero data into three tables. Figure 3-6 illustrates one way to break up the data.
Many of the problems in the badHero design happen because apparently more than one hero can be on a particular mission, and thus the mission data gets repeated. By separating mission data into another table, I've guaranteed that the data for a mission is entered only once.
Note that each table has a primary key, and none of them has listed fields. The same data won't ever be entered twice. The solution is looking pretty good!
Notice that everything related to the mission has been moved to the mission table. I added one field to the hero table, which contains an integer. This field is called a foreign key reference. You can find out much more about how foreign key references work in Chapter 4 of this minibook.
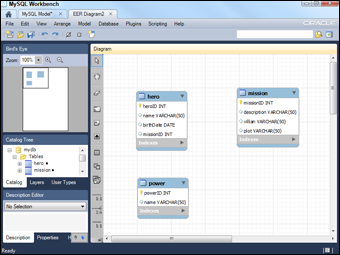
Figure 3-6: Now I have three tables: hero, power, and mission.
Third normal form
The third normal form adds one more requirement. Here is the official definition:
A table is in 3NF if it is in 2NF and has no transitive dependencies on the candidate key.
Wow! These definitions get better and better. Once again, it's really a lot easier than it sounds:
Ensure functional dependency.
In other words, check each field of each table and ensure that it really describes what the table is about. For example, is the plot related to the mission or the hero? What about the villain?
The tricky thing about functional dependency is that you often don't really know how the data is supposed to be connected. Only the person who uses the data really knows how it's supposed to work. (Often, they don't know, either, as it turns out.) You have to work with the client to figure out exactly what the business rules (the rules that describe how the data really works) are. You can't really tell from the data itself.
The good news is that, for simple structures like the hero data, you're often already in third normal form by the time you get to second normal form. Still, you should check. After a database is in third normal form, you've reduced the possibility of several kinds of anomalies, so your data is far more reliable than it was in the past. Several other forms of normalization exist, but third normal form is enough for most applications.
Identifying Relationships in Your Data
After you normalize the data (see the preceding section), you've created the entities (tables). Now, you need to investigate the relationships among these entities.
Three main types of data relationships exist (and of these, only two are common):
- One-to-one relationship: Each element of table A is related to exactly one element of table B. This type of relationship isn't common because if a one-to-one relationship exists between two tables, the information can be combined safely into one table.
- One-to-many relationship: For each element of table A, there could be many possible elements in table B. The relationship between mission and hero is a one-to-many relationship, as each mission can have many heroes, but each hero has only one mission. (My heroes have attention issues and can't multitask very well.) Note that hero and mission are not a one-to-many relationship, but a many-to-one. The order matters.
- Many-to-many relationship: This type of relationship happens when an element of A may have many values from B, and B may also have many values of A. Usually, listed fields turn out to be many-to-many relationships. In the hero data, the relationship between hero and power is a many-to-many relationship because each hero can have many powers, and each power can belong to multiple heroes.
You can use an ER tool to diagram the various relationship types. Figure 3-7 shows this addition to the hero design.

Figure 3-7: Now I've added relationships.
Note that MySQL Workbench doesn't actually allow you to draw many-to-many joins. I drew that into Figure 3-7 to illustrate the point. In the next chapter, I show how to emulate many-to-many relationships with a special trick called a link table.
ER diagrams use special symbols to represent different kinds of relationships. The line between tables indicates a join, or relationship, but the type of join is indicated by the markings on the ends of the lines. In general, the crow's feet or filled-in circle indicate many, and the double lines indicate one.
ER diagrams get much more complex than the simple ones I show here, but for this introduction, the one and many symbols are enough to get you started.