
Chapter 18. Types and Documentation
The basic types in Erlang—integers, floating-point numbers, atoms, strings, tuples, and lists—were introduced in Chapter 2; records were covered in Chapter 7; and further types—binaries and references—in Chapter 9. When we have declared functions and other definitions, we have also given an informal description of the types of their inputs and outputs.
This chapter shows how you can write down the types of functions as a part of their formal documentation in Erlang, using the EDoc documentation framework, written by Richard Carlsson. What you write down as the type of a function can be checked for consistency against the function definition using the TypEr tool, built by the implementers of Dialyzer. TypEr will infer types without any user input, and so it can be an essential tool for program understanding. TypEr and Dialyzer are the result of the High Performance Erlang (HiPE) team’s research at Uppsala University. All of these tools are part of the standard Erlang distribution.
Types in Erlang
Let’s start this chapter with an example and follow it with an overview of the type notation for Erlang.
An Example: Records with Typed Fields
We discussed record definitions earlier in the book. In the example of the mobile user database in Chapter 10, you saw a declaration of a record to hold information about a particular user of the mobile phone system:
-record(usr, {msisdn, %int()
id, %term()
status = enabled %atom(), enabled | disabled
plan, %atom(), prepay | postpay
services = []}). %[atom()], service flag listThe usr record has five
fields, and in the comments that follow, each field type is indicated.
You can take that a step further, however, and make these comments a part of the program itself. First, you introduce type declarations defining types for the kind of plan, user status, and service:
-type(plan() :: prepay | postpay). -type(status() :: enabled | disabled). -type(service() :: atom()).
The three type declarations define the plan, status, and service types. As with constant functions,
they are followed by a set of parentheses, ():
plan()Has two elements, the atoms
prepayandpostpay. You use the|symbol to indicate alternatives (as you would in regular expressions and grammars). Here, the alternatives are the two possible members of the type.status()Also has two elements, the atoms
enabledanddisabled.service()Is a synonym for
atom(), but makes it clear that when it is used, the intention is for an atom in this position to represent a service of some kind.
With these definitions in place, you can explicitly give types to the record fields in this record with typed fields:
-record(usr, {msisdn ::integer(),
id ::integer(),
status = enabled ::status(),
plan ::plan(),
services = [] ::[service()]
}).This more clearly indicates what the elements of the usr record type should be and how they should
be used by programs that manipulate them. But most importantly, it
provides tools with information that will help you detect type errors in
the code. This short example provided you with a taste of the Erlang
type notation. Now let’s cover it in more detail.
Erlang Type Notation
A number of Erlang types are predefined, and they include the following:
any()Includes all Erlang data values (as does its synonym,
term()).atom()binary()boolean()byte()Contains the numbers 0–255.
char()deep_string()float()function()integer()Consists of all integer values; recall that these are “big integers.”
list(T)Is the type of a list of type
T; it can also be written[T].nil()Has one element, the empty list
[].none()Is a void type with no elements; it is used as the return type of functions that never return.
number()Consists of the union of the
float()andinteger()types.pid(),port(),reference()string()tuple()
You can find details of other predefined types in the EDoc and Dialyzer documentation. In addition to the aforementioned predefined types, you can define your own types using the following notation:
atomAny atom can be used as a type; for example, the type
okhas the elementok.|or+You can use these to form the union of two types, as in
true|false.#rec{}This is the record type named
rec.{T1,T2,...}This is the type of a tuple whose first element comes from type
T1, second element from typeT2, and so on. So, for example,{error,atom()}consists of all pairs where the first element is the atomerrorand the second is any atom.[T]This is the type of a list whose elements come from the type
T.L..UThis is the range of integers from lower bound
Lto upper boundU. This is used in definingbyte()andchar()and a number of other built-ins, includingpos_integer().
A function type has the following form:
(Argument_types) -> Result_type
where the argument types may also contain the names of the corresponding parameters.
You use a –spec statement to
specify a type (or prototype) for a function in a program.To be clear,
-spec is used to specify
the type of a function, whereas –type is used to define a
type. Revisiting the usr_db example from Chapter 10, you can say:
-spec(create_tables(FileName::string()) -> {ok, ref()} | {error, atom()}).
create_tables(FileName) ->
... .
-spec(close_tables() -> ok | {error, atom()}).
close_tables() ->
... .The type of create_tables here
indicates that the FileName argument
is a string, and that there are two alternatives for the return
type:
If the operation is successful, this is signaled by returning a tuple with the first element
ok, and the second element a reference to the tables created.If it fails, a tuple with the first element
errorwill be returned. Its second element is an atom, presumably indicating the nature of the error.
The use of FileName here is
optional. Writing the following would have the same effect:
-spec(create_tables(string()) -> {ok, ref()} | {error, atom()}).However, including the parameter name—assuming it is chosen to reflect its purpose—improves the documentation.[44]
TypEr: Success Types and Type Inference
The TypEr system, built by Tobias Lindahl and Kostis Sagonas,[45] is used to check the validity of –spec annotations, as well as to infer the types
of functions in modules without type annotations.
You use TypEr from the command line. You can see the full range of options by typing:
typer --help
Taking the example of the mobile user database from Chapter 10, the following command:
typer --show usr.erl usr_db.erl
gives the following output (shortened for brevity):
Unknown functions: [{ets,safefixtable,2}]
%% File: "usr.erl"
%% ---------------
-spec start() -> 'ok' | {'error','starting'}.
-spec start(_) -> 'ok' | {'error','starting'}.
-spec stop() -> any().
-spec add_usr(_,_,_) -> any().
-spec delete_usr(_) -> any().
...
%% File: "usr_db.erl"
%% ------------------
-spec create_tables(_) -> any().
-spec close_tables() -> any().
-spec add_usr(#usr{}) -> 'ok'.
-spec update_usr([tuple()] | tuple()) -> 'ok'.
-spec delete_usr(_) -> 'ok' | {'error','instance'}.
...In a statically typed language such as Haskell, the type of a function inferred by the type checker will provide a guarantee that the function will not fail if applied to arguments of the input type. Erlang is a dynamically typed language, and so the TypEr tool takes a different approach.
Note
TypEr infers success types, which encapsulate all the ways in which a function can be applied successfully. In general, this cannot be accurate, but it will always be an overapproximation, so using the function in any other way will be guaranteed to fail.
To make this clear, if a function f is given a success typing (S) -> T, and E is any Erlang expression so that f(E) successfully evaluates to V, then E
must be of type S, and V of type T.
In the usr_db.erl example
earlier, no useful information could be inferred for create_tables/1, as its input and
output types are any(). Just to be
clear, TypEr was applied to a version of usr_db without type
annotations; if you add these, the result of applying TypEr may be
different:
-spec(create_tables(string()) -> {ok, ref()} | {error, atom()}).
create_tables(FileName) ->
ets:new(subRam, [named_table, {keypos, #usr.msisdn}]),
ets:new(subIndex, [named_table]),
dets:open_file(subDisk, [{file, FileName}, {keypos, #usr.msisdn}]).
-spec(close_tables() -> ok | {error, atom()}).
close_tables() ->
ets:delete(subRam),
ets:delete(subIndex),
dets:close(subDisk).
-spec(add_usr(#usr{}) -> ok).
add_usr(#usr{msisdn=PhoneNo, id=CustId} = Usr) ->
ets:insert(subIndex, {CustId, PhoneNo}),
update_usr(Usr).
-spec(update_usr(#usr{}) -> ok).
update_usr(Usr) ->
ets:insert(subRam, Usr),
dets:insert(subDisk, Usr),
ok.
-spec(delete_usr(integer()) -> ok|{error,atom()}).
delete_usr(CustId) ->
case get_index(CustId) of
{ok,PhoneNo} ->
delete_usr(PhoneNo, CustId);
{error, instance} ->
{error, instance}
end.
-spec(delete_usr(integer(),integer()) -> ok|{error,atom()}).
delete_usr(PhoneNo, CustId) ->
dets:delete(subDisk, PhoneNo),
ets:delete(subRam, PhoneNo),
ets:delete(subIndex, CustId),
ok.
...Running TypEr on the annotated file will check the specified types, and will give this result:
%% File: "usr_db.erl"
%% ------------------
-spec create_tables(string()) -> {'ok',ref()} | {'error',atom()}.
-spec close_tables() -> 'ok' | {'error',atom()}.
-spec add_usr(#usr{}) -> 'ok'.
-spec update_usr(#usr{}) -> 'ok'.
-spec delete_usr(integer()) -> 'ok' | {'error',atom()}.
-spec delete_usr(integer(),integer()) -> 'ok' | {'error',atom()}.
...In doing this, TypEr will check the specified type against the
inferred type, and report any inconsistencies. For example, if you change
the –spec for add_usr to the following:
-spec(add_usr(#usr{}) -> integer()).TypEr will report this:
typer: Error in contract of function usr_db:add_usr/1
The contract is: (#usr{}) -> integer()
but the inferred signature is: (#usr{}) -> 'ok'On the other hand, if you change the spec of create_tables/1, no error will be reported,
since the inferred type for this function is consistent with
any one-argument function type.
Dialyzer: A DIscrepancy AnaLYZer for ERlang Programs
TypEr gives an analysis of types in Erlang programs. Dialyzer extends this to perform static analysis on Erlang programs to identify software discrepancies, including redundant tests and unreachable code, as well as obvious type errors.
To speed up its operation, Dialyzer can create a Persistent Lookup Table (PLT), using the --build_plt option. When you include the
kernel, standard libraries, and Mnesia, as shown here:
dialyzer --build_plt -r<erl-lib>/kernel-2.12.5/ebin<erl-lib>/stdlib-1.15.5/ebin<erl-lib>/mnesia-4.4.7/ebin
it takes some minutes to generate the PLT and produce this report:
Creating PLT /Users/simonthompson/.dialyzer_plt ... re.erl:41: Call to missing or unexported function unicode:characters_to_binary/2 re.erl:134: Call to missing or unexported function unicode:characters_to_list/2 re.erl:200: Call to missing or unexported function re:compile/2 re.erl:226: Call to missing or unexported function unicode:characters_to_binary/2 re.erl:245: Call to missing or unexported function unicode:characters_to_list/2 re.erl:505: Call to missing or unexported function unicode:characters_to_list/2 re.erl:545: Call to missing or unexported function unicode:characters_to_binary/2 Unknown functions: compile:file/2 compile:forms/2 compile:noenv_forms/2 compile:output_generated/1 crypto:des3_cbc_decrypt/5 crypto:start/0 done in 16m43.44s done (warnings were emitted)
Subsequently calling Dialyzer on the files for the running example gives this report (in less than a second):
dialyzer -c usr.erl usr_db.erl
Checking whether the PLT /Users/simonthompson/.dialyzer_plt is up-to-date... yes
Proceeding with analysis...
usr.erl:110: The pattern [] can never match the type {'error','instance'}
usr_db.erl:69: Call to missing or unexported function ets:safefixtable/2
done in 0m0.33s
done (warnings were emitted)You can find more information about Dialyzer in the online documentation.
Documentation with EDoc
It is sometimes said that functional programs are self-documenting. Sadly, although functional programming languages may produce programs that are more readable, complex programs are not self-documenting, let alone obvious to understand. Free text comments in program modules, if kept up-to-date, are a first step in describing a program. However, they have the disadvantage of lacking structure as well as being difficult to scan, search, and read independently of the program text.
EDoc provides a documentation framework for Erlang that overcomes these disadvantages and generates documentation from information you have inserted in your modules:
EDoc provides a structure for comments, including
typeandspecinformation as well as textual comments on functions.EDoc is a documentation generator: a standard style of HTML document is generated from the structured information in each module.
EDoc provides a framework for adding information covering a whole set of modules (e.g., in an application or a package), providing an overview of the larger-scale structure or assumptions for the whole system.
EDoc is part of the standard Erlang distribution, and it has a lot in common with similar systems such as Haddock (for Haskell), Javadoc, pydoc, and RDoc (for Ruby). In this section, we will introduce you to many of EDoc’s features by documenting the mobile user database example from Chapter 10.
Note
It is intended that in later releases of Erlang/OTP, EDoc will
share information with TypEr, and so will use the type information in
the –type and –spec declarations. In the meantime, this
typing information is given in a different format, described in this
section.
Documenting usr_db.erl
EDoc generates documentation from tags of the form @tag text, embedded within comments. Each tag
can continue over multiple lines, until the next tag or noncomment line.
You can use different kinds of tags in different ways:
- Module tags
Provide module-level documentation. Occurrences must precede the module declaration itself.
- Function tags
Are associated with the function that follows them, and give information about that particular function.
- Generic tags
Might include “to do” information or a type definition, but can occur anywhere within a file.
We will look at these in turn for the usr_db example.
Module tags
In the example, the module tags are as follows:
%% @author Francesco Cesarini <[email protected]> %% @author Simon Thompson [http://www.cs.kent.ac.uk/~sjt/] %% @doc Back end for the mobile subscriber database. %% The module provides an example of using ETS and DETS tables. %% @reference <a href="http://oreilly.com/catalog/9780596518189/"> Erlang Programming</a>, %% <em> Francesco Cesarini and Simon Thompson</em>, %% O'Reilly, 2009. %% @copyright 2009 Francesco Cesarini and Simon Thompson
The tags give information about the following:
@authorThe author(s) of the module and optional contact information (email or HTML).
@copyrightA copyright statement.
@docA description of the module, in well-formed XHTML text. The first sentence of this text is used as a summary of the module.
@referenceA reference giving further information, which can include XHTML links.
You can use other tags to give information about version number
(@version), when the module was
introduced into the system (@since), and whether the documentation
should be visible or not (@hidden
or @private).
Function tags
The principal documentation for a function is given by its type and a description of what it does:
@specGives the type for a function. The form of the type description was given earlier. In future versions, it is expected that this will be replaced by use of information in a
–specdeclaration.@docIndicates the general documentation for a function, using XHTML markup.
Other available tags include a cross-reference to another
object’s documentation (@see), a
description of which types of exceptions can be thrown (@throws), and whether a function is
deprecated (@deprecated); @hidden, @private, and @since, as described earlier, can also be
used.
For a fragment of the usr_db
module, the documentation will be as follows:
%% @doc Create the ETS and DETS tables which implement the database. The
%% argument gives the filename which is used to hold the DETS table.
%% If the table can be created, an 'ok' tuple containing a
%% reference to the created table is returned; if not, it returns an 'error'
%% tuple with an atom describing the error.
%% @spec create_tables(string()) -> {ok, reference()} | {error, atom()}
-spec(create_tables(string()) -> {ok, ref()} | {error, atom()}).
create_tables(FileName) ->
ets:new(subRam, [named_table, {keypos, #usr.msisdn}]),
ets:new(subIndex, [named_table]),
dets:open_file(subDisk, [{file, FileName}, {keypos, #usr.msisdn}]).
%% @doc Close the ETS and DETS tables implementing the database.
%% Returns either 'ok' or an 'error'
%% tuple with the reason for the failure to close the DETS table.
%% @spec close_tables() -> ok | {error, atom()}
-spec(close_tables() -> ok | {error, atom()}).
close_tables() ->
ets:delete(subRam),
ets:delete(subIndex),
dets:close(subDisk).
%% @doc Add a user (of the 'usr' record type) to the database.
%% @spec add_usr(#usr{}) -> ok
-spec(add_usr(#usr{}) -> ok).
add_usr(#usr{msisdn=PhoneNo, id=CustId} = Usr) ->
ets:insert(subIndex, {CustId, PhoneNo}),
update_usr(Usr).In the preceding code, we provided the types using @spec; it is expected that in future
releases of Erlang, -spec
declarations will be used instead, making @spec tags superfluous.
Generic tags
Generic tags can appear anywhere in a module:
@typeWill give a definition of a type and is picked up by EDoc to include in the generated documentation. It is expected that in future releases this will be replaced by the use of
-typedeclarations.@todoUsed to indicate “to do” notes; these will not appear in the generated documentation unless the
todooption is activated.
Running EDoc
The main EDoc functions are in the edoc module. A call
to edoc:application/1
will generate the documentation for an application, and a call to
edoc:files/1 will generate the
documentation for a set of files; these functions use the default EDoc
options. Two-argument versions of the functions allow a set of option
choices to be passed in the second argument.
Module pages
Figure 18-1
shows the page generated for the usr_db module that results from running edoc:files(["usr_db.erl", "usr.erl"]). This shows the structure of a
typical EDoc page for an Erlang module.
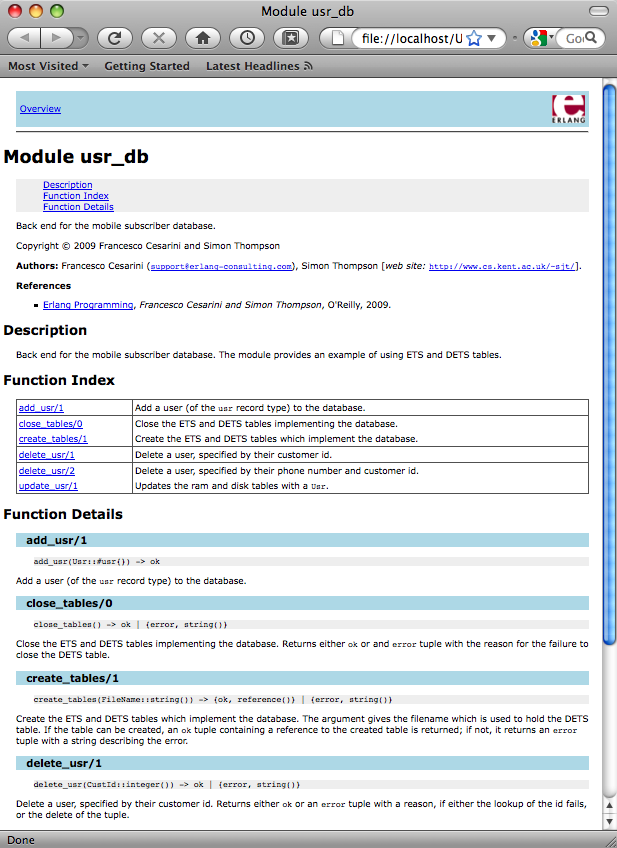
The page begins with links to its major sections, and is followed by the one-sentence summary of the module and other module tags; the full description of the module follows.
In the function index, functions are listed in alphabetical
order, rather than in their order in the file. Each function is
hyperlinked to its details, and is given a one-sentence overview: the
first sentence of its @doc
tag.
Each function has details regarding its type. Note that the
information contains not only the types of the arguments and results,
but also the names of the arguments that are automatically extracted
from the source code. For instance, the @spec for create_tables/1 says the following:
%% @spec create_tables(string()) -> {ok, reference()} | {error, atom()}Here is the documentation that is produced:
create_tables(FileName::string()) -> {ok, reference()} | {error, atom()}This gives you the useful extra information that the string
argument represents a filename.
Without any @spec information, EDoc
will still include the names of the parameters in the generated
information.
Overview page
For each project, an overview page will be generated, providing an index for the modules in the project. Further information can be provided for this in an overview.edoc file, which should typically appear in a doc subdirectory where the other documentation will be placed.
The overview.edoc file has the same content tags as the header for a module, but it is not necessary to enclose each line in a comment. The results of this for the running example are shown in Figure 18-2, as generated from a file that begins like this:
@author Francesco Cesarini <[email protected]> @author Simon Thompson [http://www.cs.kent.ac.uk/~sjt/] @reference <a href="http://oreilly.com/catalog/9780596518189/">Erlang Programming</a>, <em> Francesco Cesarini and Simon Thompson</em>, O'Reilly, 2009.
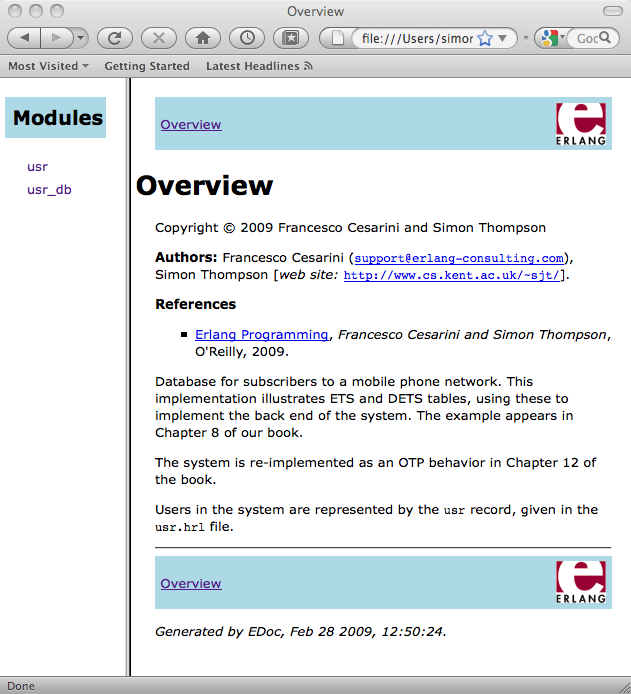
Types in EDoc
The usr_db.erl module
contains no type definitions, but usr.hrl contains a number of these, and they
are referenced in usr.erl. Types are
documented like this: the definition is given first, and this can be
followed by an optional description:
%% @type plan() = prepay|postpay. The two payment types for mobile subscribers. %% @type status() = enabled | disabled. The status of a customer can be enabled %% or disabled. %% @type service() = atom(). Services are specified by atoms, including %% (but not limited to) 'data', 'lbs' and 'sms'. 'Data' confirms the user %% has subscribed to a data plan, 'sms' allows the user to send and receive %% premium rated smses, while 'lbs' would allow third parties to execute %% location lookups on this particular user.
This is extracted in the documentation for the usr module, and if a
defined type is used in the @spec for
a function, this is hyperlinked to its definition. The information about
types appears in the documentation after the general description and
before the function index. Figure 18-3 shows a fragment of
the documentation for usr.erl, with
the data type definitions appearing after the module description.

Going Further with EDoc
If you want to generate comprehensive documentation for applications and other projects, EDoc provides a number of facilities for formatting, cross-referencing, and preprocessing.
EDoc comes with a set of predefined macros,
called by enclosing them in braces, thus: {@name} and {@name
argument}. These include @date, @time, @module, and @version as well as the {@link reference. description} form. This
creates a link to the object identified by the
reference; the description gives the text for the anchor of
the link.
References include name/arity for
functions within the module, and Mod:name/arity for functions in the module
Mod. A typename() refers to a type within the same
module, and Mod:typename() in
another. So, for example, the following link:
{@link set_status/2. 'set_status/2'}gives a link to the documentation for the set_status/2 function in the same
module.
In this example, the link is also labeled set_status/2: you use another EDoc facility
for verbatim quotation. The quotation of the text
'...' puts the enclosed text into
verbatim (code) form, properly escaping any XHTML-significant characters
in the text, such as <, =, and >. y shows an example using the @link construct, where the description part of
the documentation gives an index for the functions divided according to
function, rather than alphabetically.
For author convenience, EDoc supports wiki-style
formatting instead of XHTML. Blank lines are taken to delimit
paragraphs (i.e., <p> ...
</p> elements). Headings can be generated automatically
from ==Heading==, and similarly from
===, however, = should not be used.
This header markup will automatically generate an anchor (equivalent to
<a name="Heading">), which can
then be referred to by an EDoc macro, {@section
Heading}. For further details on formatting and
cross-referencing in EDoc, see the online documentation.
Exercises
Rather than give formal exercises for this chapter, we encourage you to try TypEr, Dialyzer, and EDoc on the solutions you wrote for exercises earlier in the book.
[44] The EDoc system described later in the chapter will
automatically include parameter names in its generated type
documentation even if they do not appear in the –spec statement.
[45] TypEr is described in the papers from the Erlang Workshops in 2005 (Tallin) and 2007 (Freiburg) (http://doi.acm.org/10.1145/1088361.1088366 and http://doi.acm.org/10.1145/1292520.1292523).