
13. Backtesting and Stress Testing
The objective in this chapter is to consider the ex ante risk measure forecasts from the model and compare them with the ex post realized portfolio return. The risk measure forecast could take the form of a Value-at-Risk (VaR), an Expected Shortfall (ES), the shape of the entire return distribution, or perhaps the shape of the left tail of the distribution only. We need to be able to backtest any of these risk measures of interest. The backtest procedures developed in this chapter can be seen as a final diagnostic check on the aggregate risk model, thus complementing the various specific diagnostics covered in previous chapters. The discussion on backtesting is followed by a section on stress testing at the end of the chapter.
Keywords: Real-life VaRs, VaR violations, dependence, distribution forecast evaluation, coherent stress testing.
1. Chapter Overview
The first 12 chapters have covered various methods for constructing risk management models. Along the way we also considered several diagnostic checks. For example, in Chapter 1 we looked at the autocorrelations of returns to see if the assumption of a constant mean was valid. In Chapter 4 and Chapter 5 we looked at the autocorrelation function of returns squared divided by the time-varying variance to assess if we had modeled the variance dynamics properly. We also ran variance regressions to assess the forecasting performance of the suggested GARCH models. In Chapter 6, we studied the so-called QQ plots to see if the distribution we assumed for standardized returns captured the extreme observations in the sample. We also looked at the reaction of various risk models to an extreme event such as the 1987 stock market crash. In Chapter 9 we looked at Threshold Correlations. Finally, in Chapter 10 we illustrated option pricing model misspecification in terms of implied volatility smiles and smirks.
The objective in this chapter is to consider the ex ante risk measure forecasts from the model and compare them with the ex post realized portfolio return. The risk measure forecast could take the form of a Value-at-Risk (VaR), an Expected Shortfall (ES), the shape of the entire return distribution, or perhaps the shape of the left tail of the distribution only. We want to be able to backtest any of these risk measures of interest. The backtest procedures developed in this chapter can be seen as a final diagnostic check on the aggregate risk model, thus complementing the various specific diagnostics covered in previous chapters. The discussion on backtesting is followed up by a section on stress testing at the end of the chapter. The material in the chapter will be covered as follows:
• We take a brief look at the performance of some real-life VaRs from six large (and anonymous) commercial banks. The clustering of VaR violations in these real-life VaRs provides sobering food for thought.
• We establish procedures for backtesting VaRs. We start by introducing a simple unconditional test for the average probability of a VaR violation. We then test the independence of the VaR violations. Finally, we combine the unconditional test and the independence test in a test of correct conditional VaR coverage.
• We consider using explanatory variables to backtest the VaR. This is done in a regression-based framework.
• We broaden the focus to include the entire shape of the distribution of returns. The distributional forecasts can be backtested as well, and we suggest ways to do so. Risk managers typically care most about having a good forecast of the left tail of the distribution, and we therefore modify the distribution test to focus on backtesting the left tail of the distribution only.
• We define stress testing and give a critical survey of the way it is often implemented. Based on this critique we suggest a coherent framework for stress testing.
Before we get into the technical details of backtesting VaRs and other risk measures, it is instructive to take a look at the performance of some real-life VaRs. Figure 13.1 shows the exceedances (measured in return standard deviations) of the VaR in six large (and anonymous) U.S. commercial banks during the January 1998 to March 2001 period. Whenever the realized portfolio return is worse than the VaR, the difference between the two is shown. Whenever the return is better, zero is shown. The difference is divided by the standard deviation of the portfolio across the period. The return is daily, and the VaR is reported for a 1% coverage rate. To be exact, we plot the time series of
 |
| Figure 13.1 Value-at-Risk exceedences from six major commercial banks. Notes: The figure shows the VaR exceedences on the days where the loss was larger than the VaR. Each panel corresponds to a large U.S. commercial bank. The figure is reprinted from Berkowitz and O'Brien (2002) |
Bank 4 has no violations at all, and in general the banks have fewer violations than expected. Thus, the banks on average report a VaR that is higher than it should be. This could either be due to the banks deliberately wanting to be cautious or the VaR systems being biased. Another culprit is that the returns reported by the banks contain nontrading-related profits, which increase the average return without substantially increasing portfolio risk.
More important, notice the clustering of VaR violations. The violations for each of Banks 1, 2, 3, 5, and 6 fall within a very short time span and often on adjacent days. This clustering of VaR violations is a serious sign of risk model misspecification. These banks are most likely relying on a technique such as Historical Simulation (HS), which is very slow at updating the VaR when market volatility increases. This issue was discussed in the context of the 1987 stock market crash in Chapter 2.
Notice also how the VaR violations tend to be clustered across banks. Many violations appear to be related to the Russia default and Long Term Capital Management bailout in the fall of 1998. The clustering of violations across banks is important from a regulator perspective because it raises the possibility of a countrywide banking crisis.
Motivated by this sobering evidence of misspecification in existing commercial bank VaRs, we now introduce a set of statistical techniques for backtesting risk management models.
2. Backtesting VaRs
Recall that a  measure promises that the actual return will only be worse than the
measure promises that the actual return will only be worse than the  forecast
forecast  of the time. If we observe a time series of past ex ante VaR forecasts and past ex post returns, we can define the “hit sequence” of VaR violations as
of the time. If we observe a time series of past ex ante VaR forecasts and past ex post returns, we can define the “hit sequence” of VaR violations as
2.1. The Null Hypothesis
If we are using the perfect VaR model, then given all the information available to us at the time the VaR forecast is made, we should not be able to predict whether the VaRwill be violated. Our forecast of the probability of a VaR violation should be simply p every day. If we could predict the VaR violations, then that information could be used to construct a better risk model. In other words, the hit sequence of violations should be completely unpredictable and therefore distributed independently over time as a Bernoulli variable that takes the value 1 with probability p and the value 0 with probability (1 − p). We write
When backtesting risk models, p will not be 1/2 but instead on the order of 0.01 or 0.05 depending on the coverage rate of the VaR. The hit sequence from a correctly specified risk model should thus look like a sequence of random tosses of a coin, which comes up heads 1% or 5% of the time depending on the VaR coverage rate.
2.2. Unconditional Coverage Testing
We first want to test if the fraction of violations obtained for a particular risk model, call it π, is significantly different from the promised fraction, p. We call this the unconditional coverage hypothesis. To test it, we write the likelihood of an i.i.d. Bernoulli(π) hit sequence
Under the unconditional coverage null hypothesis that π = p, where p is the known VaR coverage rate, we have the likelihood
The choice of significance level comes down to an assessment of the costs of making two types of mistakes: We could reject a correct model (Type I error) or we could fail to reject (that is, accept) an incorrect model (Type II error). Increasing the significance level implies larger Type I errors but smaller Type II errors and vice versa. In academic work, a significance level of 1%, 5%, or 10% is typically used. In risk management, the Type II errors may be very costly so that a significance level of 10% may be appropriate.
Often, we do not have a large number of observations available for backtesting, and we certainly will typically not have a large number of violations, T1, which are the informative observations. It is therefore often better to rely on Monte Carlo simulated P-values rather than those from the  distribution. The simulated P-values for a particular test value can be calculated by first generating 999 samples of random i.i.d. Bernoulli(p) variables, where the sample size equals the actual sample at hand. Given these artificial samples we can calculate 999 simulated test statistics, call them
distribution. The simulated P-values for a particular test value can be calculated by first generating 999 samples of random i.i.d. Bernoulli(p) variables, where the sample size equals the actual sample at hand. Given these artificial samples we can calculate 999 simulated test statistics, call them  The simulated P-value is then calculated as the share of simulated
The simulated P-value is then calculated as the share of simulated  values that are larger than the actually obtained
values that are larger than the actually obtained 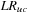 test value. We can write
test value. We can write
To calculate the tests in the first place, we need samples where VaR violations actually occurred; that is, we need some ones in the hit sequence. If we, for example, discard simulated samples with zero or one violations before proceeding with the test calculation, then we are in effect conditioning the test on having observed at least two violations.
2.3. Independence Testing
Imagine all the VaR violations or “hits” in a sample happening around the same time, which was the case in Figure 13.1. Would you then be happy with a VaR with correct average (or unconditional) coverage? The answer is clearly no. For example, if the 5% VaR gave exactly 5% violations but all of these violations came during a three-week period, then the risk of bankruptcy would be much higher than if the violations came scattered randomly through time. We therefore would very much like to reject VaR models that imply violations that are clustered in time. Such clustering can easily happen in a VaR constructed from the Historical Simulation method in Chapter 2, if the underlying portfolio return has a clustered variance, which is common in asset returns and which we studied in Chapter 4.
If the VaR violations are clustered, then the risk manager can essentially predict that if today is a violation, then tomorrow is more than  likely to be a violation as well. This is clearly not satisfactory. In such a situation, the risk manager should increase the VaR in order to lower the conditional probability of a violation to the promised p.
likely to be a violation as well. This is clearly not satisfactory. In such a situation, the risk manager should increase the VaR in order to lower the conditional probability of a violation to the promised p.
Our task is to establish a test that will be able to reject a VaR with clustered violations. To this end, assume the hit sequence is dependent over time and that it can be described as a so-called first-order Markov sequence with transition probability matrix
If we observe a sample of T observations, then we can write the likelihood function of the first-order Markov process as

Allowing for dependence in the hit sequence corresponds to allowing π01 to be different from π11. We are typically worried about positive dependence, which amounts to the probability of a violation following a violation (π11) being larger than the probability of a violation following a nonviolation (π01). If, on the other hand, the hits are independent over time, then the probability of a violation tomorrow does not depend on today being a violation or not, and we write  Under independence, the transition matrix is thus
Under independence, the transition matrix is thus
We can test the independence hypothesis that  using a likelihood ratio test
using a likelihood ratio test
In large samples, the distribution of the  test statistic is also
test statistic is also  with one degree of freedom. But we can calculate the P-value using simulation as we did before. We again generate 999 artificial samples of i.i.d. Bernoulli variables, calculate 999 artificial test statistics, and find the share of simulated test values that are larger than the actual test value.
with one degree of freedom. But we can calculate the P-value using simulation as we did before. We again generate 999 artificial samples of i.i.d. Bernoulli variables, calculate 999 artificial test statistics, and find the share of simulated test values that are larger than the actual test value.
As a practical matter, when implementing the 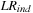 tests we may incur samples where
tests we may incur samples where  In this case, we simply calculate the likelihood function as
In this case, we simply calculate the likelihood function as
2.4. Conditional Coverage Testing
Ultimately, we care about simultaneously testing if the VaR violations are independent and the average number of violations is correct. We can test jointly for independence and correct coverage using the conditional coverage test
Notice that the  test takes the likelihood from the null hypothesis in the
test takes the likelihood from the null hypothesis in the  test and combines it with the likelihood from the alternative hypothesis in the
test and combines it with the likelihood from the alternative hypothesis in the  test. Therefore,
test. Therefore,

2.5. Testing for Higher-Order Dependence
In Chapter 1 we used the autocorrelation function (ACF) to assess the dependence over time in returns and squared returns. We can of course use the ACF to assess dependence in the VaR hit sequence as well. Plotting the hit-sequence autocorrelations against their lag order will show if the risk model gives rise to autocorrelated hits, which it should not.
As in Chapter 3, the statistical significance of a set of autocorrelations can be formally tested using the Ljung-Box statistic. It tests the null hypothesis that the autocorrelation for lags 1 through m are all jointly zero via
3. Increasing the Information Set
The preceding tests are quick and easy to implement. But because they only use information on past VaR violations, they might not have much power to detect misspecified risk models. To increase the testing power, we consider using the information in past market variables, such as interest rate spreads or volatility measures. The basic idea is to test the model using information that may explain when violations occur. The advantage of increasing the information set is not only to increase the power of the tests but also to help us understand the areas in which the risk model is misspecified. This understanding is key in improving the risk models further.
If we define the vector of variables available to the risk manager at time t as Xt, then the null hypothesis of a correct risk model can be written as
The first hypothesis says that the conditional probability of getting a VaR violation on day t + 1 should be independent of any variable observed at time t, and it should simply be equal to the promised VaR coverage rate, p. This hypothesis is equivalent to the conditional expectation of a VaR violation being equal to p. The reason for the equivalence is that  can only take on one of two values: 0 and 1. Thus, we can write the conditional expectation as
can only take on one of two values: 0 and 1. Thus, we can write the conditional expectation as
3.1. A Regression Approach
Consider regressing the hit sequence on the vector of known variables, Xt. In a simple linear regression, we would have
The hypothesis that  is then equivalent to
is then equivalent to
There is, of course, no particular reason why the explanatory variables should enter the conditional expectation in a linear fashion. But nonlinear functional forms could be tested as well.
4. Backtesting Expected Shortfall
In Chapter 2, we argued that the Value-at-Risk had certain drawbacks as a risk measure, and we defined Expected Shortfall (ES),
Consider again a vector of variables, Xt, which are known to the risk manager and which may help explain potential portfolio losses beyond what is explained by the risk model. The ES risk measure promises that whenever we violate the VaR, the expected value of the violation will be equal to  We can therefore test the ES measure by checking if the vector Xt has any ability to explain the deviation of the observed shortfall or loss,
We can therefore test the ES measure by checking if the vector Xt has any ability to explain the deviation of the observed shortfall or loss,  , from the Expected Shortfall on the days where the VaR was violated. Mathematically, we can write
, from the Expected Shortfall on the days where the VaR was violated. Mathematically, we can write
To test the null hypothesis that the risk model from which the ES forecasts were made uses all information optimally  , and that it is not biased
, and that it is not biased  , we can jointly test that
, we can jointly test that 
Notice that now the magnitude of the violation shows up on the left-hand side of the regression. But notice that we can still only use information in the tail to backtest. The ES measure does not reveal any particular properties about the remainder of the distribution, and therefore, we only use the observations where the losses were larger than the VaR.
5. Backtesting the Entire Distribution
Rather than focusing on particular risk measures from the return distribution such as the Value-at-Risk or the Expected Shortfall, we could instead decide to backtest the entire return distribution from the risk model. This would have the benefit of potentially increasing further the power to reject bad risk models. Notice, however, that we are again changing the object of interest: If only the VaR is reported, for example, from Historical Simulation, then we cannot test the distribution.
Consider a risk model that at the end of each day produces a cumulative distribution forecast for next day's return, call it  Then at the end of every day, after having observed the actual portfolio return, we can calculate the risk model's probability of observing a return below the actual. We will denote this so-called transform probability by
Then at the end of every day, after having observed the actual portfolio return, we can calculate the risk model's probability of observing a return below the actual. We will denote this so-called transform probability by 
If we are using the correct risk model to forecast the return distribution, then we should not be able to forecast the risk model's probability of falling below the actual return. In other words, the time series of observed probabilities  should be distributed independently over time as a Uniform(0,1) variable. We therefore want to consider tests of the null hypothesis
should be distributed independently over time as a Uniform(0,1) variable. We therefore want to consider tests of the null hypothesis
For example, if the true portfolio return data follows a fat-tailed Student's t(d) distribution, but the risk manager uses a normal distribution model, then we will see too many  s close to zero and one, too many around 0.5, and too few elsewhere. This would just be another way of saying that the observed returns data have more observations in the tails and around zero than the normal distribution allows for. Figure 13.2 shows the histogram of a
s close to zero and one, too many around 0.5, and too few elsewhere. This would just be another way of saying that the observed returns data have more observations in the tails and around zero than the normal distribution allows for. Figure 13.2 shows the histogram of a  sequence, obtained from taking
sequence, obtained from taking  to be normally distributed with zero mean and variance
to be normally distributed with zero mean and variance  , when it should have been Student's t(d), with d = 6. Thus, we use the correct mean and variance to forecast the returns, but the shape of our density forecast is incorrect.
, when it should have been Student's t(d), with d = 6. Thus, we use the correct mean and variance to forecast the returns, but the shape of our density forecast is incorrect.
 |
| Figure 13.2 |
The histogram check is of course not a proper statistical test, and it does not test the time variation in  If we can predict
If we can predict  using information available on day t, then
using information available on day t, then  is not i.i.d., and the conditional distribution forecast,
is not i.i.d., and the conditional distribution forecast,  is therefore not correctly specified either. We want to consider proper statistical tests here.
is therefore not correctly specified either. We want to consider proper statistical tests here.
Unfortunately, testing the i.i.d. uniform distribution hypothesis is cumbersome due to the restricted support of the uniform distribution. We therefore transform the i.i.d. Uniform  to an i.i.d. standard normal variable
to an i.i.d. standard normal variable  using the inverse cumulative distribution function,
using the inverse cumulative distribution function,  We write
We write
We are now left with a test of a variable conforming to the standard normal distribution, which can easily be implemented.
We proceed by specifying a model that we can use to test against the null hypothesis. Assume again, for example, that we think a variable Xt may help forecast  Then we can assume the alternative hypothesis
Then we can assume the alternative hypothesis
The parameter estimates  can be obtained from maximum likelihood or, in this simple case, from linear regression. We can then write a likelihood ratio test of correct risk model distribution as
can be obtained from maximum likelihood or, in this simple case, from linear regression. We can then write a likelihood ratio test of correct risk model distribution as
5.1. Backtesting Only the Left Tail of the Distribution
In risk management, we often only really care about forecasting the left tail of the distribution correctly. Testing the entire distribution as we did earlier may lead us to reject risk models that capture the left tail of the distribution well, but not the rest of the distribution. Instead, we should construct a test that directly focuses on assessing the risk model's ability to capture the left tail of the distribution, which contains the largest losses.
Consider restricting attention to the tail of the distribution to the left of the 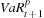 —that is, to the
—that is, to the  largest losses.
largest losses.
If we want to test that the  observations from, for example, the 10% largest losses are themselves uniform, then we can construct a rescaled
observations from, for example, the 10% largest losses are themselves uniform, then we can construct a rescaled  variable as
variable as
Figure 13.3 shows the histogram of  corresponding to the 10% smallest returns. The data again follow a Student's t(d) distribution with d = 6 but the density forecast model assumes the normal distribution. We have simply zoomed in on the leftmost 10% of the histogram from Figure 13.2. The systematic deviation from a flat histogram is again obvious.
corresponding to the 10% smallest returns. The data again follow a Student's t(d) distribution with d = 6 but the density forecast model assumes the normal distribution. We have simply zoomed in on the leftmost 10% of the histogram from Figure 13.2. The systematic deviation from a flat histogram is again obvious.
 |
| Figure 13.3 |
To do formal statistical testing, we can again construct an alternative hypothesis as in
6. Stress Testing
Due to the practical constraints from managing large portfolios, risk managers often work with relatively short data samples. This can be a serious issue if the historical data available do not adequately reflect the potential risks going forward. The available data may, for example, lack extreme events such as an equity market crash, which occurs very infrequently.
To make up for the inadequacies of the available data, it can be useful to artificially generate extreme scenarios of the main factors driving the portfolio returns (see the exposure mapping discussion in Chapter 7) and then assess the resulting output from the risk model. This is referred to as stress testing, since we are stressing the model by exposing it to data different from the data used when specifying and estimating the model.
At first pass, the idea of stress testing may seem vague and ad hoc. Two key issues appear to be (1) how should we interpret the output of the risk model from the stress scenarios, and (2) how should we create the scenarios in the first place? We deal with each of these issues in turn.
6.1. Combining Distributions for Coherent Stress Testing
Standard implementation of stress testing amounts to defining a set of scenarios, running them through the risk model using the current portfolio weights, and if a scenario results in an extreme loss, then the portfolio manager may decide to rebalance the portfolio. Notice how this is very different from deciding to rebalance the portfolio based on an undesirably high VaR or Expected Shortfall (ES). VaR and ES are proper probabilistic statements: What is the loss such that I will lose more only 1% of the time (VaR)? Or what is the expected loss when I exceed my VaR(ES)? Standard stress testing does not tell the portfolio manager anything about the probability of the scenario happening, and it is therefore not at all clear what the portfolio rebalancing decision should be. The portfolio manager may end up overreacting to an extreme scenario that occurs with very low probability, and underreact to a less extreme scenario that occurs much more frequently. Unless a probability of occurring is assigned to each scenario, then the portfolio manager really has no idea how to react.
On the other hand, once scenario probabilities are assigned, then stress testing can be very useful. To be explicit, consider a simple example of one stress scenario, which we define as a probability distribution  of the vector of factor returns. We simulate a vector of risk factor returns from the risk model, calling it
of the vector of factor returns. We simulate a vector of risk factor returns from the risk model, calling it  and we also simulate from the scenario distribution,
and we also simulate from the scenario distribution,  . If we assign a probability α of a draw from the scenario distribution occurring, then we can combine the two distributions as in
. If we assign a probability α of a draw from the scenario distribution occurring, then we can combine the two distributions as in
Data from the combined distribution is generated by drawing a random variable Ui from a Uniform(0,1) distribution. If Ui is smaller than α, then we draw a return from  ; otherwise we draw it from
; otherwise we draw it from  The combined distribution can easily be generalized to multiple scenarios, each of which has its own preassigned probability of occurring.
The combined distribution can easily be generalized to multiple scenarios, each of which has its own preassigned probability of occurring.
Notice that by simulating from the combined distribution, we are effectively creating a new data set that reflects our available historical data as well our view of the deficiencies of it. The deficiencies are rectified by including data from the stress scenarios in the new combined data set.
Once we have simulated data from the combined data set, we can calculate the VaR or ES risk measure on the combined data using the previous risk model. If the risk measure is viewed to be inappropriately high then the portfolio can be rebalanced. Notice that now the rebalancing is done taking into account both the magnitude of the stress scenarios and their probability of occurring.
Assigning the probability, α, also allows the risk manager to backtest the VaR system using the combined probability distribution  . Any of these tests can be used to test the risk model using the data drawn from
. Any of these tests can be used to test the risk model using the data drawn from  If the risk model, for example, has too many VaR violations on the combined data, or if the VaR violations come in clusters, then the risk manager should consider respecifying the risk model. Ultimately, the risk manager can use the combined data set to specify and estimate the risk model.
If the risk model, for example, has too many VaR violations on the combined data, or if the VaR violations come in clusters, then the risk manager should consider respecifying the risk model. Ultimately, the risk manager can use the combined data set to specify and estimate the risk model.
6.2. Choosing Scenarios
Having decided to do stress testing, a key challenge to the risk manager is to create relevant scenarios. The scenarios of interest will typically vary with the type of portfolio under management and with the factor returns applied. The exact choice of scenarios will therefore be situation specific, but in general, certain types of scenarios should be considered. The risk manager ought to do the following:
• Simulate shocks that are more likely to occur than the historical database suggests. For example, the available database may contain a few high variance days, but if in general the recent historical period was unusually calm, then the high variance days can simply be replicated in the stress scenario.
• Simulate shocks that have never occurred but could. Our available sample may not contain any stock market crashes, but one could occur.
• Simulate shocks reflecting the possibility that current statistical patterns could break down. Our available data may contain a relatively low persistence in variance, whereas longer samples suggest that variance is highly persistent. Ignoring the potential persistence in variance could lead to a clustering of large losses going forward.
• Simulate shocks that reflect structural breaks that could occur. A prime example in this category would be the sudden float of the previously fixed Thai baht currency in the summer of 1997.
Even if we have identified a set of scenario types, pinpointing the specific scenarios is still difficult. But the long and colorful history of financial crises may serve as a source of inspiration. Examples could include crises set off by political events or natural disasters. For example, the 1995 Nikkei crisis was set off by the Kobe earthquake, and the 1979 oil crisis was rooted in political upheaval. Other crises such as the 1997 Thai baht float and subsequent depreciation mentioned earlier could be the culmination of pressures such as a continuing real appreciation building over time resulting in a loss of international competitiveness.
The effects of market crises can also be very different. They can result in relatively brief market corrections, as was the case after the October 1987 stock market crash, or they can have longer lasting effects, such as the Great Depression in the 1930s. Figure 13.4 depicts the 15 largest daily declines in the Dow Jones Industrial Average during the past 100 years.
 |
| Figure 13.4 |
Figure 13.4 clearly shows that the October 19, 1987, decline was very large even on a historical scale. We see that the second dip arriving a week later on October 26, 1987 was large by historical standards as well: It was the tenth-largest daily drop. The 2008–2009 financial crisis shows up in Figure 13.4 with three daily drops in the top 15. None of them are in the top 10 however. October–November 1929, which triggered the Great Depression, has four daily drops in the top 10—three of them in the top 5. This bunching in time of historically large daily market drops is quite striking. It strongly suggests that extremely large market drops do not occur randomly but are instead driven by market volatility being extraordinarily high. Carefully modeling volatility dynamics as we did in Chapter 4 and Chapter 5 is therefore crucial.
6.3. Stress Testing the Term Structure of Risk
Figure 13.5 shows nine episodes of prolonged market downturn—or bear markets—which we define as at least a 30% decline lasting for at least 50 days. Figure 13.5 shows that the bear market following the 1987 market crash was relatively modest compared to previous episodes. The 2008–2009 bear market during the recent financial crises was relatively large at 50%.
 |
| Figure 13.5 |
Figure 13.5 suggests that stress testing scenarios should include both rapid corrections, such as the 1987 episode, as well as prolonged downturns that prevailed in 2008–2009.
The Filtered Historical Simulation (or bootstrapping) method developed in Chapter 8 to construct the term structure of risk can be used to stress test the term structure of risk as well. Rather than feeding randomly drawn shocks through the model over time we can feed a path of historical shocks from a stress scenario through the model. The stress scenario can for example be the string of daily shocks observed from September 2008 through March 2009. The outcome of this simulation will show how a stressed market scenario will affect the portfolio under consideration.
7. Summary
The backtesting of a risk model can be seen as a final step in model building procedure, and it therefore represents the final chapter in this book. The clustering in time of VaR violations as seen in actual commercial bank risk models can pose a serious threat to the financial health of the institution. In this chapter, we therefore developed backtesting procedures capable of capturing such clustering. Backtesting tools were introduced for various risk measures including VaR, Expected Shortfall (ES), the entire return density, and the left tail of the density.
The more information is provided in the risk measure, the higher statistical power we will have to reject a misspecified risk model. The popular VaR risk measure does not, unfortunately, convey a lot of information about the portfolio risk. It tells us a return threshold, which we will only exceed with a certain probability, but it does not tell us about the magnitude of violations that we should expect. The lack of information in the VaR makes it harder to backtest. All we can test is that the VaR violations fall randomly in time and in the proportion matching the promised coverage rate. Purely from a backtesting perspective, other risk measures such as ES and the distribution shape are therefore preferred.
Backtesting ought to be supplemented by stress testing, and we have outlined a framework for doing so. Standard stress testing procedures do not specify the probability with which the scenario under analysis will occur. The failure to specify a probability renders the interpretation of stress testing scenarios very difficult. It is not clear how we should react to a large VaR from an extreme scenario unless the likelihood of the scenario occurring is assessed. While it is, of course, difficult to pinpoint the likelihood of extreme events, doing so enables the risk manager to construct a pseudo data set that combines the actual data with the stress scenarios. This combined data set can be used to backtest the model. Stress testing and backtesting are then done in an integrated fashion.
Further Resources
The VaR exceedances from the six U.S. commercial banks in Figure 13.1 are taken from Berkowitz and O'Brien (2002). See also Berkowitz et al. (2011) and O'Brien and Berkowitz (2006). Deng et al. (2008) and Perignon and Smith (2010) present empirical evidence on VaRs from an international set of banks.
The VaR backtests of unconditional coverage, independence, and conditional coverage are developed in Christoffersen (1998). Kupiec (1995) and Hendricks (1996) restrict attention to unconditional testing. The regression-based approach is used in Christoffersen and Diebold (2000). Christoffersen and Pelletier (2004) and Candelon et al. (2011) construct tests based on the duration of time between VaR hits. Campbell (2007) surveys the available backtesting procedures.
Christoffersen and Pelletier (2004) discuss the details in implementing the Monte Carlo simulated P-values, which were originally derived by Dufour (2006).
Christoffersen et al. (2001), Giacomini and Komunjer (2005) and Perignon and Smith (2008) develop tests for comparing different VaR models. Andreou and Ghysels (2006) consider ways of detecting structural breaks in the return process for the purpose of financial risk management. For a regulatory perspective on backtesting, see Lopez (1999) and Kerkhof and Melenberg (2004). Lopez and Saidenberg (2000) focus on credit risk models. Zumbach (2006) considers different horizons.
Engle and Manganelli (2004), Escanciano and Olmo, 2010 and Escanciano and Olmo, 2011 and Gaglianone et al. (2011) suggest quantile-regression approaches and allow for parameter estimation error.
Procedures for backtesting the Expected Shortfall risk measures can be found in McNeil and Frey (2000) and Angelidis and Degiannakis (2007).
Graphical tools for assessing the quality of density forecasts are suggested in Diebold et al. (1998). Crnkovic and Drachman (1996), Berkowitz (2001) and Bontemps and Meddahi (2005) establish formal statistical density evaluation tests, and Berkowitz (2001), in addition, suggested focusing attention to backtesting the left tail of the density. See also the survey in Tay and Wallis (2007) and Corradi and Swanson (2006).
The coherent framework for stress testing is spelled out in Berkowitz (2000). See also Kupiec (1998), Longin (2000) and Alexander and Sheedy (2008). Rebonato (2010) takes a Bayesian approach and devotes an entire book to the topic of stress testing.
The May 1998 issue of the World Economic Outlook, published by the International Monetary Fund (see www.imf.org), contains a useful discussion of financial crises during the past quarter of a century. Kindleberger and Aliber (2000) take an even longer historical view.
Alexander, C.; Sheedy, E., Developing a stress testing framework based on market risk models, J. Bank. Finance 32 (2008) 2220–2236.
Andreou, E.; Ghysels, E., Monitoring distortions in financial markets, J. Econom. 135 (2006) 77–124.
Angelidis, T., Degiannakis, S.A., 2007. Backtesting VaR models: An expected shortfall approach. http://ssrn.com/paper=898473.
Berkowitz, J., A coherent framework for stress testing, J. Risk Winter 2 (2000) 1–11.
Berkowitz, J., Testing density forecasts, applications to risk management, J. Bus. Econ. Stat. 19 (2001) 465–474.
Berkowitz, J., Christoffersen, P., Pelletier, D., 2011. Evaluating value-at-risk models with desklevel data. Manag. Sci. forthcoming.
Berkowitz, J.; O'Brien, J., How accurate are the value-at-risk models at commercial banks?J. Finance 57 (2002) 1093–1112.
Bontemps, C.; Meddahi, N., Testing normality: A GMM approach, J. Econom. 124 (2005) 149–186.
Campbell, S., A review of backtesting and backtesting procedures, J. Risk 9 (Winter) (2007) 1–17.
Candelon, B.; Colletaz, G.; Hurlin, C.; Tokpavi, S., Backtesting value-at-risk: A GMM duration-based test, J. Financ. Econom. 9 (2011) 314–343.
Christoffersen, P., Evaluating interval forecasts, Int. Econ. Rev. 39 (1998) 841–862.
Christoffersen, P.; Diebold, F., How relevant is volatility forecasting for financial risk management?Rev. Econ. Stat. 82 (2000) 12–22.
Christoffersen, P.; Hahn, J.; Inoue, A., Testing and comparing value-at-risk measures, J. Empir. Finance 8 (2001) 325–342.
Christoffersen, P.; Pelletier, D., Backtesting portfolio risk measures: A duration-based approach, J. Financ. Econom. 2 (2004) 84–108.
Corradi, V.; Swanson, N., Predictive density evaluation, In: (Editors: Elliot, G.; Gringer, C.; Timmcrmann, A.) Handbook of Economic Forecasting, vol. 1 (2006) Elsevier, North Holland, pp. 197–284.
Crnkovic, C.; Drachman, J., Quality control, Risk (September 9) (1996) 138–143.
Deng, Z; Perignon, C.; Wang, Z., Do banks overstate their value-at-risk?J. Bank. Finance 32 (2008) 783–794.
Diebold, F.X.; Gunther, T.; Tay, A., Evaluating density forecasts, with applications to financial risk management, Int. Econ. Rev. 39 (1998) 863–883.
Dufour, J.-M., Monte Carlo tests with nuisance parameters: A general approach to finite sample inference and non-standard asymptotics, J. Econom. 133 (2006) 443–477.
Engle, R.; Manganelli, S., CAViaR: Conditional value at risk by quantile regression, J. Bus. Econ. Stat. 22 (2004) 367–381.
Escanciano, J.; Olmo, J., Backtesting parametric value-at-risk with estimation risk, J. Bus. Econ. Stat. 28 (2010) 36–51.
Escanciano, J.; Olmo, J., Robust backtesting tests for value-at-risk models, J. Financ. Econom. 9 (2011) 132–161.
Gaglianone, W.; Lima, L.; Linton, O., Evaluating value-at-risk models via quantile regression, J. Bus. Econ. Stat. 29 (2011) 150–160.
Giacomini, R.; Komunjer, I., Evaluation and combination of conditional quantile forecasts, J. Bus. Econ. Stat. 23 (2005) 416–431.
Hendricks, D., Evaluation of value-at-risk models using historical data, Econ. Policy Rev., Federal Reserve Bank of New York 2 (1996) 39–69.
International Monetary Fund, World Economic Outlook, May. (1998) IMF, Washington, DC; Available from: www.IMF.org..
Kerkhof, J.; Melenberg, B., Backtesting for risk-based regulatory capital, J. Bank. Finance 28 (2004) 1845–1865.
Kindleberger, C.; Aliber, R., Manias, Panics and Crashes: A History of Financial Crisis. (2000) John Wiley and Sons, New York.
Kupiec, P., Techniques for verifying the accuracy of risk measurement models, J. Derivatives 3 (1995) 73–84.
Kupiec, P., Stress testing in a value at risk framework, J. Derivatives 6 (1998) 7–24.
Longin, F.M., From value at risk to stress testing: The extreme value approach, J. Bank. Finance 24 (2000) 1097–1130.
Lopez, J., Regulatory evaluation of value-at-risk models, J. Risk 1 (1999) 37–64.
Lopez, J.; Saidenberg, M., Evaluating credit risk models, J. Bank. Finance 24 (2000) 151–165.
McNeil, A.; Frey, R., Estimation of tail-related risk measures for heteroskedastic financial time series: An extreme value approach, J. Empir. Finance 7 (2000) 271–300.
O'Brien, J.; Berkowitz, J., Bank trading revenues, VaR and market risk, In: (Editors: Stulz, R.; Carey, M.) The Risks of Financial Institutions (2006) University of Chicago Press for NBER, Chicago, Illinois, pp. 59–102.
Perignon, C.; Smith, D., A new approach to comparing VaR estimation methods, J. Derivatives 15 (2008) 54–66.
Perignon, C.; Smith, D., The level and quality of value-at-risk disclosure by commercial banks, J. Bank. Finance 34 (2010) 362–377.
Rebonato, R., Coherent Stress Testing: A Bayesian Approach to the Analysis of Financial Stress. (2010) John Wiley and Sons, Chichester, West Sussex, UK.
Tay, A.; Wallis, K., Density forecasting: A survey, In: (Editors: Clements, M.; Hendry, D.) A Companion to Economic Forecasting (2007) Blackwell Publishing, Malden, MA, pp. 45–68.
Zumbach, G., Backtesting risk methodologies from one day to one year, J. Risk 11 (2006) 55–91.
1. Compute the daily variance of the returns on the S&P 500 using the RiskMetrics approach.
2. Compute the 1% and 5% 1-day Value-at-Risk for each day using RiskMetrics and Historical Simulation with 500 observations.
3. For the 1% and 5% value at risk, calculate the indicator “hit” sequence for both RiskMetrics and Historical Simulation models. The hit sequence takes on the value 1 if the return is below the (negative of the) VaR and 0 otherwise.
4. Calculate the  ,
,  and
and  tests on the hit sequence from the RiskMetrics and Historical Simulation models. (Excel hint: Use the CHIINV function.) Can you reject the VaR model using a 10% significance level?
tests on the hit sequence from the RiskMetrics and Historical Simulation models. (Excel hint: Use the CHIINV function.) Can you reject the VaR model using a 10% significance level?
5. Using the RiskMetrics variances calculated in exercise 1, compute the uniform transform variable. Plot the histogram of the uniform variable. Does it look flat?
7. Take all the values of the uniform variable that are less than or equal to 0.1. Multiply each number by 10. Plot the histogram of this new uniform variable. Does it look flat? Why should it?
8. Transform the new uniform variable to a normal variable using the inverse CDF of the normal distribution. Plot the histogram of the normal variable. What is the mean, standard deviation, skewness, and kurtosis? Does the variable appear to be normally distributed?
The answers to these exercises can be found in the Chapter13Results.xlsx file on the companion site.
For more information see the companion site at http://www.elsevierdirect.com/companions/9780123744487
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.