
Chapter 18. Specialized Tools and Techniques
CONTENTS
Section 18.1 Optimizing Memory Allocation 754
Section 18.2 Run-Time Type Identification 772
Section 18.3 Pointer to Class Member 780
Section 18.4 Nested Classes 786
Section 18.5 Union: A Space-Saving Class 792
Section 18.6 Local Classes 796
Section 18.7 Inherently Nonportable Features 797
The first four parts of this book discussed how to use those parts of C++ that are generally useful. Those features are likely to be used at some point by almost all C++ programmers. In addition, C++ defines some features that are more specialized. Many programmers will never (or only rarely) need to use these features presented in this chapter.
18.1 Optimizing Memory Allocation
Memory allocation in C++ is a typed operation: new (Section 5.11, p. 174) allocates memory for a specified type and constructs an object of that type in the newly allocated memory. A new expression automatically runs the appropriate constructor to initialize each dynamically allocated object of class type.
The fact that new allocates memory on a per-object basis can impose unacceptable run-time overhead on some classes. Such classes might need to make user-level allocation of objects of the class type faster. A common strategy such classes use is to preallocate memory to be used when new objects are created, constructing each new object in preallocated memory as needed.
Other classes want to minimize allocations needed for their own data members. For example, the library vector class preallocates (Section 9.4, p. 330) extra memory to hold additional elements if and when they are added. New elements are added in this reserved capacity. Preallocating elements allows vector to efficiently add elements while keeping the elements in contiguous memory.
In each of these cases—preallocating memory to hold user-level objects or to hold the internal data for a class—there is the need to decouple memory allocation from object construction. The obvious reason to decouple allocation and construction is that constructing objects in preallocated memory is wasteful. Objects may be created that are never used. Those objects that are used must be reassigned new values when the preallocated object is actually used. More subtly, some classes could not use preallocated memory if it had to be constructed. As an example, consider vector, which uses a preallocation strategy. If objects in preallocated memory had to be constructed, then it would not be possible to have vectors of types that do not have a default constructor—there would be no way for vector to know how to construct these objects.

The techniques presented in this section are not guaranteed to make all programs faster. Even when they do improve performance, they may carry other costs such as space usage or difficulty of debugging. It is always best to defer optimization until the program is known to work and when run-time measurements indicate that improving memory allocation will solve known performance problems.
18.1.1 Memory Allocation in C++
In C++ memory allocation and object construction are closely intertwined, as are object destruction and memory deallocation. When we use a new expression, memory is allocated, and an object is constructed in that memory. When we use a delete expression, a destructor is called to destroy the object and the memory used by the object is returned to the system.
When we take over memory allocation, we must deal with both these tasks. When we allocate raw memory, we must construct object(s) in that memory. Before freeing that memory, we must ensure that the objects are properly destroyed.
Assigning to an object in unconstructed memory rather than initializing it is undefined. For many classes, doing so causes a crash at run time. Assignment involves obliterating the existing object. If there is no existing object, then the actions in the assignment operator can have disastrous effects.
C++ provides two ways to allocate and free unconstructed, raw memory:
- The
allocatorclass, which provides type-aware memory allocation. This class supports an abstract interface to allocating memory and subsequently using that memory to hold objects. - The library
operator newandoperator deletefunctions, which allocate and free raw, untyped memory of a requested size.
C++ also provides various ways to construct and destroy objects in raw memory:
- The
allocatorclass defines members namedconstructanddestroy, which operate as their names suggest. Theconstructmember initializes objects in unconstructed memory; thedestroymember runs the appropriate destructor on objects. - The placement
newexpression takes a pointer to unconstructed memory and initializes an object or an array in that space. - We can directly call an object’s destructor to destroy the object. Running the destructor does not free the memory in which the object resides.
- The algorithms
uninitialized_fillanduninitialized_copyexecute like thefillandcopyalgorithms except that they construct objects in their destination rather than assigning to them.

Modern C++ programs ordinarily ought to use the allocator class to allocate memory. It is safer and more flexible. However, when constructing objects, the placement new expression is more flexible than the allocator::construct member. There are some cases where placement new must be used.
18.1.2 The allocator Class
The allocator class is a template that provides typed memory allocation and object construction and destruction. Table 18.1 on the following page outlines the operations that allocator supports.
Table 18.1. Standard allocator Class and Customized Algorithms

The allocator class separates allocation and object construction. When an allocator object allocates memory, it allocates space that is appropriately sized and aligned to hold objects of the given type. However, the memory it allocates is unconstructed. Users of allocator must separately construct and destroy objects placed in the memory it allocates.
Using allocator to Manage Class Member Data
To understand how we might use a preallocation strategy and the allocator class to manage the internal data needs of a class, let’s think a bit more about how memory allocation in the vector class might work.
Recall that the vector class stores its elements in contiguous storage. To obtain acceptable performance, vector preallocates more elements than are needed (Section 9.4, p. 330). Each vector member that adds elements to the container checks whether there is space available for another element. If so, then the member initializes an object in the next available spot in preallocated memory. If there isn’t a free element, then the vector is reallocated: The vector obtains new space, copies the existing elements into that space, adds the new element, and frees the old space.
The storage that vector uses starts out as unconstructed memory; it does not yet hold any objects. When the elements are copied to or added in this preallocated space, they must be constructed using the construct member of allocator.
To illustrate these concepts we’ll implement a small portion of vector. We’ll name our class Vector to distinguish it from the standard vector class:

Each Vector<T> type defines a static data member of type allocator<T> to allocate and construct the elements in Vectors of the given type. Each Vector object keeps its elements in a built-in array of the indicated type and maintains three pointers into that array:
• elements, which points to the first element in the array
• first_free, which points just after the last actual element
• end, which points just after the end of the array itself
Figure 18.1 illustrates the meaning of these pointers.
Figure 18.1. Vector Memory Allocation Strategy
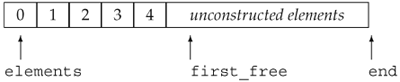
We can use these pointers to determine the size and capacity of the Vector:
• The size of a Vector (the number of elements actually in use) is equal to first_free – elements.
• The capacity of a Vector (the total number of elements that could be defined before the Vector has to be reallocated) is equal to end – elements.
• The free capacity (the number of elements that can be added before a reallocation is necessary) is end – first_free.
Using construct
The push_back member uses these pointers to add a new element to the end of the Vector:

The push_back function starts by determining whether there is space available. If not, it calls reallocate. That member allocates new space and copies the existing elements. It resets the pointers to point to the newly allocated space.
Once push_back knows that there is room for the new element, it asks the allocator object to construct a new last element. The construct function uses the copy constructor for type T to copy the value t into the element denoted by first_free. It then increments first_free to indicate that one more element is in use.
Reallocating and Copying Elements
The reallocate function has the most work to do:

We use a simple but surprisingly effective strategy of allocating twice as much memory each time we reallocate. The function starts by calculating the current number of elements in use, doubling that number, and asking the allocator object to obtain the desired amount of space. If the Vector is empty, we allocate two elements.
If Vector holds ints, the call to allocate allocates space for newcapacity number of ints. If it holds strings, then it allocates that space for the given number of strings.
The call to uninitialized_copy uses a specialized version of the standard copy algorithm. This version expects its destination to be raw, unconstructed memory. Rather than assigning elements from the input range to the destination, it copy-constructs each element in the destination. The copy constructor for T is used to copy each element from the input range to the destination.
The for loop calls the allocator member destroy on each object in the old array. It destroys the elements in reverse order, starting with the last element in the array and finishing with the first. The destroy function runs the destructor for type T to free any resources used by the old elements.
Once the elements have been copied and destroyed, we free the space used by the original array. We must check that elements actually pointed to an array before calling deallocate.
deallocate expects a pointer that points to space that was allocated by allocate. It is not legal to pass deallocate a zero pointer.
Finally, we have to reset the pointers to address the newly allocated and initialized array. The first_free and end pointers are set to denote one past the last constructed element and one past the end of the allocated space, respectively.
18.1.3 operator new and operator delete Functions
The previous subsection used the vector class to show how we could use the allocator class to manage a pool of memory for a class’ internal data storage. In the next three subsections we’ll look at how we might implement the same strategy using the more primitive library facilities.
First, we need to understand a bit more about how new and delete expressions work. When we use a new expression
// new expression
string * sp = new string("initialized");
three steps actually take place. First, the expression calls a library function named operator new to allocate raw, untyped memory large enough to hold an object of the specified type. Next, a constructor for the type is run to construct the object from the specified initializers. Finally, a pointer to the newly allocated and constructed object is returned.
When we use a delete expression to delete a dynamically allocated object:
delete sp;
two steps happen. First, the appropriate destructor is run on the object to which sp points. Then, the memory used by the object is freed by calling a library function named operator delete.
Terminology: new Expression versus operator new Function
The library functions operator new and operator delete are misleadingly named. Unlike other operator functions, such as operator=, these functions do not overload the new or delete expressions. In fact, we cannot redefine the behavior of the new and delete expressions.
A new expression executes by calling an operator new function to obtain memory and then constructs an object in that memory. A delete expression executes by destroying an object and then calls an operator delete function to free the memory used by the object.
The operator new and operator delete Interface
There are two overloaded versions of operator new and operator delete functions. Each version supports the related new and delete expression:

Using the Allocation Operator Functions
Although the operator new and operator delete functions are intended to be used by new expressions, they are generally available functions in the library. We can use them to obtain unconstructed memory. They are somewhat analogous to the allocate and deallocate members of the allocator class. For example, instead of using an allocator, we could have used the operator new and operator delete functions in our Vector class. When we allocated new space we wrote
// allocate space to hold newcapacity number of elements of type T
T* newelements = alloc.allocate(newcapacity);
which could be rewritten as
![]()
Similarly, when we deallocated the old space pointed to be the Vector member elements we wrote
// return the memory that held the elements
alloc.deallocate(elements, end - elements);
which could be rewritten as
// deallocate the memory that they occupied
operator delete[](elements);
These functions behave similarly to the allocate and deallocate members of the allocator class. However, they differ in one important respect: They operate on void* pointers rather than typed pointers.

In general, it is more type-safe to use an allocator rather than using the operator new and operator delete functions directly.
The allocate member allocates typed memory, so programs that use it can avoid the necessity of calculating the byte-count amount of memory needed. They also can avoid casting (Section 5.12.4, p. 183) the return from operator new. Similarly, deallocate frees memory of a specific type, again avoiding the necessity for converting to void*.
18.1.4 Placement new Expressions
The library functions operator new and operator delete are lower-level versions of the allocator members allocate and deallocate. Each allocates but does not initialize memory.
There are also lower-level alternatives to the allocator members construct and destroy. These members initialize and destroy objects in space allocated by an allocator object.
Analogous to the construct member, there is a third kind of new expression, referred to as placement new. The placement new expression initializes an object in raw memory that was already allocated. It differs from other versions of new in that it does not allocate memory. Instead, it takes a pointer to allocated but unconstructed memory and initializes an object in that memory. In effect, placement new allows us to construct an object at a specific, preallocated memory address.
The form of a placement new expression is:
new (place_address) type
new (place_address) type (initializer-list)
where place_address must be a pointer and the initializer-list provides (a possibly empty) list of initializers to use when constructing the newly allocated object.
We could use a placement new expression to replace the call to construct in our Vector implementation. The original code
// construct a copy t in the element to which first_free points
alloc.construct (first_free, t);
would be replaced by the equivalent placement new expression
// copy t into element addressed by first_free
new (first_free) T(t);
Placement new expressions are more flexible than the construct member of class allocator. When placement new initializes an object, it can use any constructor, and builds the object directly. The construct function always uses the copy constructor.
For example, we could initialize an allocated but unconstructed string from a pair of iterators in either of these two ways:

The placement new expression uses the string constructor that takes a pair of iterators to construct the string directly in the space to which sp points. When we call construct, we must first construct the string from the iterators to get a string object to pass to construct. That function then uses the string copy constructor to copy that unnamed, temporary string into the object to which sp points.
Often the difference is irrelevant: For valuelike classes, there is no observable difference between constructing the object directly in place and constructing a temporary and copying it. And the performance difference is rarely meaningful. But for some classes, using the copy constructor is either impossible (because the copy constructor is private) or should be avoided. In these cases, use of placement new may be necessary.
18.1.5 Explicit Destructor Invocation
Just as placement new is a lower-level alternative to using the allocate member of the allocator class, we can use an explicit call to a destructor as the lower-level alternative to calling destroy.
In the version of Vector that used an allocator, we clean up each element by calling destroy:
![]()
For programs that use a placement new expression to construct the object, we call the destructor explicitly:
![]()
Here we invoke a destructor directly. The arrow operator dereferences the iterator p to obtain the object to which p points. We then call the destructor, which is the name of the type preceded by a tilde (~).
The effect of calling the destructor explicitly is that the object itself is properly cleaned up. However, the memory in which the object resided is not freed. We can reuse the space if desired.
Calling the operator delete function does not run the destructor; it only frees the indicated memory.
18.1.6 Class Specific new and delete
The previous subsections looked at how a class can take over memory management for its own internal data structure. Another way to optimize memory allocation involves optimizing the behavior of new expressions. As an example, consider the Queue class from Chapter 16. That class doesn’t hold its elements directly. Instead, it uses new expressions to allocate objects of type QueueItem.
It might be possible to improve the performance of Queue by preallocating a block of raw memory to hold QueueItem objects. When a new QueueItem object is created, it could be constructed in this preallocated space. When QueueItem objects are freed, we’d put them back in the block of preallocated objects rather than actually returning memory to the system.
The difference between this problem and our Vector implementation is that in this case, we want to optimize the behavior of new and delete expressions when applied to objects of a particular type. By default, new expressions allocate memory by calling the version of operator new that is defined by the library. A class may manage the memory used for objects of its type by defining its own members named operator new and operator delete.
When the compiler sees a new or delete expression for a class type, it looks to see if the class has a member operator new or operator delete. If the class defines (or inherits) its own member new and delete functions, then those functions are used to allocate and free the memory for the object. Otherwise, the standard library versions of these functions are called.
When we optimize the behavior of new and delete, we need only define new versions of the operator new and operator delete. The new and delete expressions themselves take care of constructing and destroying the objects.
Member new and delete Functions
A class member operator new function must have a return type of void* and take a parameter of type size_t. The function’s size_t parameter is initialized by the new expression with the size, in bytes, of the amount of memory to allocate.
A class member operator delete function must have a void return type. It can be defined to take a single parameter of type void* or to take two parameters, a void* and a size_t. The void* parameter is initialized by the delete expression with the pointer that was deleted. That pointer might be a null pointer. If present, the size_t parameter is initialized automatically by the compiler with the size in bytes of the object addressed by the first parameter.
The size_t parameter is unnecessary unless the class is part of an inheritance hierarchy. When we delete a pointer to a type in an inheritance hierarchy, the pointer might point to a base-class object or an object of a derived class. In general, the size of a derived-type object is larger than the size of a base-class object. If the base class has a virtual destructor (Section 15.4.4, p. 587), then the size passed to operator delete will vary depending on the dynamic type of the object to which the deleted pointer points. If the base class does not have a virtual destructor, then, as usual, the behavior of deleting a pointer to a derived object through a base-class pointer is undefined.
These functions are implicitly static members (Section 12.6.1, p. 469). There is no need to declare them static explicitly, although it is legal to do so. The member new and delete functions must be static because they are used either before the object is constructed (operator new) or after it has been destroyed (operator delete). There are, therefore, no member data for these functions to manipulate. As with any other static member function, new and delete may access only static members of their class directly.
Array Operator new[] and Operator delete[]
We can also define member operator new[] and operator delete[] to manage arrays of the class type. If these operator functions exist, the compiler uses them in place of the global versions.
A class member operator new[] must have a return type of void* and take a first parameter of type size_t. The operator’s size_t parameter is initialized automatically with a value that represents the number of bytes required to store an array of the given number of elements of the specified type.
The member operator delete[] must have a void return type and a first parameter of type void*. The operator’s void* parameter is initialized automatically with a value that represents the beginning of the storage in which the array is stored.
The operator delete[] for a class may also have two parameters instead of one, the second parameter being a size_t. If present, the additional parameter is initialized automatically by the compiler with the size in bytes of the storage required to store the array.
Overriding Class-Specific Memory Allocation
A user of a class that defines its own member new and delete can force a new or delete expression to use the global library functions through the use of the global scope resolution operator. If the user writes
![]()
then new invokes the global operator new even if class Type defines its own class-specific operator new; similarly for delete.
If storage was allocated with a new expression invoking the global operator new function, then the delete expression should also invoke the global operator delete function.
18.1.7 A Memory-Allocator Base Class
Like the generic handle class (Section 16.5, p. 666) this example represents a fairly sophisticated use of C++. Understanding this example requires (and demonstrates) a good grasp of both inheritance and templates. It may be useful to delay studying this example until you are comfortable with these features.
Having seen how to declare class-specific member new and delete, we might next implement those members for QueueItem. Before doing so, we need to decide how we’ll improve over the built-in library new and delete functions. One common strategy is to preallocate a block of raw memory to hold unconstructed objects. When new elements are created, they could be constructed in one of these preallocated objects. When elements are freed, we’d put them back in the block of preallocated objects rather than actually returning memory to the system. This kind of strategy is often known as maintaining a freelist. The freelist might be implemented as a linked list of objects that have been allocated but not constructed.
Rather than implementing a freelist-based allocation strategy for QueueItem, we’ll observe that QueueItem is not unique in wanting to optimize allocation of objects of its type. Many classes might have the same need. Because this behavior might be generally useful, we’ll define a new class that we’ll name CachedObj to handle the freelist. A class, such as QueueItem, that wants to opimize allocation of objects of its type could use the CachedObj class rather than implementing its own new and delete members directly.
The CachedObj class will have a simple interface: Its only job is to allocate and manage a freelist of allocated but unconstructed objects. This class will define a member operator new that will return the next element from the freelist, removing it from the freelist. The operator new will allocate new raw memory whenever the freelist becomes empty. The class will also define operator delete to put an element back on the freelist when an object is destroyed.
Classes that wish to use a freelist allocation strategy for their own types will inherit from CachedObj. Through inheritance, these classes can use the CachedObj definition of operator new and operator delete along with the data members needed to represent the freelist. Because the CachedObj class is intended as a base class, we’ll give it a public virtual destructor.
As we’ll see, CachedObj may be used only for types that are not involved in an inheritance hierarchy. Unlike the member new and delete operations, CachedObj has no way to allocate different sized objects depending on the actual type of the object: Its freelist holds objects of a single size. Hence, it may be used only for classes, such as QueueItem, that do not serve as base classes.
The data members defined by the CachedObj class, and inherited by its derived classes, are:
• A static pointer to the head of the freelist
• A member named next that points from one CachedObj to the next
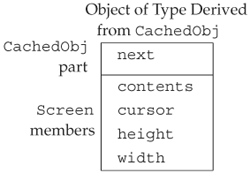
The next pointer chains the elements together onto the freelist. Each type that we derive from CachedObj will contain its own type-specific data plus a single pointer inherited from the CachedObj base class. Each object has an extra pointer used by the memory allocator but not by the inherited type itself. When the object is in use, this pointer is meaningless and not used. When the object is available for use and is on the freelist, then the next pointer is used to point to the next available object.
If we used CachedObj to optimize allocation of our Screen class, objects of type Screen (conceptually) would look like the illustration in Figure 18.2.
Figure 18.2. Illustration of a CachedObj Derived Class
The CachedObj Class
The only remaining question is what types to use for the pointers in CachedObj. We’d like to use the freelist approach for any type, so the class will be a template. The pointers will point to an object of the template type:

The class is quite simple. It provides only three public members: operator new, operator delete, and a virtual destructor. The new and delete members take objects off and return objects to the freelist.
The static members manage the freelist. These members are declared as static because there is only one freelist maintained for all the objects of a given type. The freeStore pointer points to the head of the freelist. The member named chunk specifies the number of objects that will be allocated each time the freelist is empty. Finally, add_to_freelist puts objects on the freelist. This function is used by operator new to put newly allocated objects onto the freelist. It is also used by operator delete to put an object back on the free list when an object is deleted.
Using CachedObj
The only really tricky part in using CachedObj is understanding the template parameter: When we inherit from CachedObj, the template type we use to instantiate CachedObj will be the derived type itself. We inherit from CachedObj in order to reuse its freelist management. However, CachedObj holds a pointer to the object type it manages. The type of that pointer is pointer to a type derived from CachedObj.
For example, to optimize memory management for our Screen class we would declare Screen as
![]()
This declaration gives Screen a new base class, the instance of CachedObj that is parameterized by type Screen. Each Screen now includes an additional inherited member named next in addition to its other members defined inside the Screen class.
Because QueueItem is a template type, deriving it from CachedObj is a bit complicated:

This declaration says that QueueItem is a class template that is derived from the instantiation of CachedObj that holds objects of type QueueItem<Type>. For example, if we define a Queue of ints, then the QueueItem<int> class is derived from CachedObj< QueueItem<int> >.
No other changes are needed in our class. QueueItem now has automatic memory allocation that uses a freelist to reduce the number of allocations required when creating new Queue elements.
How Allocation Works
Because we derived QueueItem from CachedObj, any allocation using a new expression, such as the call from Queue::push:
![]()
allocates and constructs a new QueueItem. Each new expression:
- Uses the
QueueItem<T>::operator newfunction to allocate an object from the freelist - Uses the element type copy constructor for type
Tto construct an object in that storage
Similarly, when we delete a QueueItem pointer such as
delete pt;
the QueueItem destructor is run to clean up the object to which pt points and the class operator delete is called. That operator puts the memory the element used back on the freelist.
Defining operator new
The operator new member returns an object from the freelist. If the freelist is empty, new must first allocate a new chunk of memory:

The function begins by verifying that it is being asked to allocate the right amount of space.
This check enforces our design intent that CachedObj should be used only for classes that are not base classes. The fact that CachedObj allocates objects on its freelist that have a fixed size means that it cannot be used to handle memory allocation for classes in an inheritance hierarchy. Classes related by inheritance almost always define objects of different sizes. A single allocator would have to be much more sophisticated than the one we implement here to handle such classes.
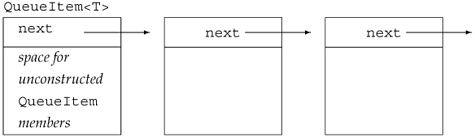
The operator new function next checks whether there are any objects on the freelist. If not, it asks the allocator member to allocate chunk new, unconstructed objects. It then iterates through the newly allocated objects, setting the next pointer. After the call to add_to_freelist, each object on the freelist will be unconstructed, except for its next pointer, which will hold the address of the next available object. The freelist looks something like the picture in Figure 18.3.
Figure 18.3. Illustration CachedObj Freelist
Having ensured that there are available objects to allocate, operator new returns the address of the first object on the freelist, resetting the freeStore pointer to address the next element on the freelist. The object returned is unconstructed. Because operator new is called from a new expression, the new expression will take care of constructing the object.
Defining operator delete
The member operator delete is responsible only for managing the memory. The object itself was already cleaned up in the destructor, which the delete expression calls before calling operator delete. The operator delete member is trivial:

It calls add_to_freelist to put the deleted object back onto the freelist.
The interesting part is the cast (Section 5.12.4, p. 183). operator delete is called when a dynamically allocated object of the class type is deleted. The compiler passes the address of that object to operator delete. However, the parameter type for the pointer must be void*. Before calling add_to_freelist, we have to cast the pointer from void* back to its actual type. In this case, that type is pointer to T, which in turn is a pointer to an object of a type derived from CachedObj.
The add_to_freelist Member
The job of this member is to set the next pointer and update the freeStore pointer when an object is added to the freelist:

The only tricky part is the use of the next member. Recall that CachedObj is intended to be used as a base class. The objects that are allocated aren’t of type CachedObj. Instead, those objects are of a type derived from CachedObj. The type of T, therefore, will be the derived type. The pointer p is a pointer to T, not a pointer to CachedObj. If the derived class has its own member named next, then writing
p->next
would fetch the next member of the derived class! But we want to set the next in the base, CachedObj class.
To avoid any possible collision with a member defined in the derived class, we explicitly specify that we are assigning to the base class member next.
Defining the Static Data Members
What remains is to define the static data members:
template <class T> allocator< T > CachedObj< T >::alloc_mem;
template <class T> T *CachedObj< T >::freeStore = 0;
template <class T> const size_t CachedObj< T >::chunk = 24;
As usual, with static members of a class template there is a different static member for each type used to instantiate CachedObj. We initialize chunk to an arbitrary value—in this case, 24. We initialize the freeStore pointer to 0, indicating that the freelist starts out empty. There is no initialization required for the alloc_mem member, but we do have to remember to define it.
Exercises Section 18.1.7
Exercise 18.10: Explain each of the following initializations. Indicate if any are errors, and if so, why.

Exercise 18.11: Explain what happens in the following new and delete expressions:

Exercise 18.12: Implement a class-specific memory allocator for Queue or another class of your choice. Measure the change in performace to see how much it helps, if at all.
18.2 Run-Time Type Identification
Run-time Type Identification (RTTI) allows programs that use pointers or references to base classes to retrieve the actual derived types of the objects to which these pointers or references refer.
RTTI is provided through two operators:
- The
typeidoperator, which returns the actual type of the object referred to by a pointer or a reference - The
dynamic_castoperator, which safely converts from a pointer or reference to a base type to a pointer or reference to a derived type
These operators return dynamic type information only for classes with one or more virtual functions. For all other types, information for the static (i.e., compile-time) type is returned.
The RTTI operators execute at run time for classes with virtual functions, but are evaluated at compile time for all other types.
Dynamic casts are needed when we have a reference or pointer to a base class but need to perform operations from the derived class that are not part of the base class. Ordinarily, the best way to get derived behavior from a pointer to base is to do so through a virtual function. When we use virtual functions, the compiler automatically selects the right function according to the actual type of the object.
In some situations however, the use of virtual functions is not possible. In these cases, RTTI offers an alternate mechanism. However, this mechanism is more error-prone than using virtual member functions: The programmer must know to which type the object should be cast and must check that the cast was performed successfully.
Dynamic casts should be used with caution. Whenever possible, it is much better to define and use a virtual function rather than to take over managing the types directly.
18.2.1 The dynamic_cast Operator
The dynamic_cast operator can be used to convert a reference or pointer to an object of base type to a reference or pointer to another type in the same hierarchy. The pointer used with a dynamic_cast must be valid—it must either be 0 or point to an object.
Unlike other casts, a dynamic_cast involves a run-time type check. If the object bound to the reference or pointer is not an object of the target type, then the dynamic_cast fails. If a dynamic_cast to a pointer type fails, the result of the dynamic_cast is the value 0. If a dynamic_cast to a reference type fails, then an exception of type bad_cast is thrown.
The dynamic_cast operator therefore performs two operations at once. It begins by verifying that the requested cast is valid. Only if the cast is valid does the operator actually do the cast. In general, the type of the object to which the reference or pointer is bound isn’t known at compile-time. A pointer to base can be assigned to point to a derived object. Similarly, a reference to base can be initialized by a derived object. As a result, the verification that the dynamic_cast operator performs must be done at run time.
Using the dynamic_cast Operator
As a simple example, assume that Base is a class with at least one virtual function and that class Derived is derived from Base. If we have a pointer to Base named basePtr, we can cast it at run time to a pointer to Derived as follows:

At run time, if basePtr actually points to a Derived object, then the cast will be successful, and derivedPtr will be initialized to point to the Derived object to which basePtr points. Otherwise, the result of the cast is 0, meaning that derivedPtr is set to 0, and the condition in the if fails.
By checking the value of derivedPtr, the code inside the if knows that it is operating on a Derived object. It is safe for that code to use Derived operations. If the dynamic_cast fails because basePtr refers to a Base object, then the else clause does processing appropriate to Base instead. The other advantage of doing the check inside the if condition is that it is not possible to insert code between the dynamic_cast and testing the result of the cast. It is, therefore, not possible to use the derivedPtr inadvertently before testing that the cast was successful. A third advantage is that the pointer is not accessible outside the if. If the cast fails, then the unbound pointer is not available for use in later cases where the test might be forgotten.
Performing a dynamic_cast in a condition ensures that the cast and test of its result are done in a single expression.
Using a dynamic_cast and Reference Types
In the previous example, we used a dynamic_cast to convert a pointer to base to a pointer to derived. A dynamic_cast can also be used to convert a reference to base to a reference to derived. The form for this a dynamic_cast operation is the following,
dynamic_cast< Type& >(val)
where Type is the target type of the conversion, and val is an object of base class type.
The dynamic_cast operation converts the operand val to the desired type Type& only if val actually refers to an object of the type Type or is an object of a type derived from Type.
Because there is no such thing as a null reference, it is not possible to use the same checking strategy for references that is used for pointer casts. Instead, when a cast fails, it throws a std::bad_cast exception. This exception is defined in the typeinfo library header.
We might rewrite the previous example to use references as follows:

Exercises Section 18.2.1
Exercise 18.13: Given the following class hierarchy in which each class defines a public default constructor and virtual destructor,
class A { /* ... */ };
class B : public A { /* ... */ };
class C : public B { /* ... */ };
class D : public B, public A { /* ... */ };
which, if any, of the following dynamic_casts fail?
(a) A *pa = new C;
B *pb = dynamic_cast< B* >(pa);
(b) B *pb = new B;
C *pc = dynamic_cast< C* >(pb);
(c) A *pa = new D;
B *pb = dynamic_cast< B* >(pa);
Exercise 18.14: What would happen in the last conversion in the previous exercise if both D and B inherited from A as a virtual base class?
Exercise 18.15: Using the class hierarchy defined in the previous exercise, rewrite the following piece of code to perform a reference dynamic_cast to convert the expression *pa to the type C&:
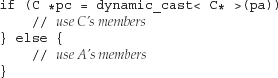
Exercise 18.16: Explain when you would use dynamic_cast instead of a virtual function.
18.2.2 The typeid Operator
The second operator provided for RTTI is the typeid operator. The typeid operator allows a program to ask of an expression: What type are you?
A typeid expression has the form
typeid(e)
where e is any expression or a type name.
If the type of the expression is a class type and that class contains one or more virtual functions, then the dynamic type of the expression may differ from its static compile-time type. For example, if the expression dereferences a pointer to a base class, then the static compile-time type of that expression is the base type. However, if the pointer actually addresses a derived object, then the typeid operator will say that the type of the expression is the derived type.
The typeid operator can be used with expressions of any type. Expressions of built-in type as well as constants can be used as operands for the typeid operator. When the operand is not of class type or is a class without virtual functions, then the typeid operator indicates the static type of the operand. When the operand has a class-type that defines at least one virtual function, then the type is evaluated at run time.
The result of a typeid operation is a reference to an object of a library type named type_info. Section 18.2.4 (p. 779) covers this type in more detail. To use the type_info class, the library header typeinfo must be included.
Using the typeid Operator
The most common use of typeid is to compare the types of two expressions or to compare the type of an expression to a specified type:

In the first if, we compare the actual types of the objects to which bp and dp point. If they both point to the same type, then the test succeeds. Similarly, the second if succeeds if bp currently points to a Derived object.
Note that the operands to the typeid are expressions that are objects—we tested *bp, not bp:
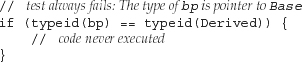
This test compares the type Base* to type Derived. These types are unequal, so this test will always fail regardless of the type of the object to which bp points.
Dynamic type information is returned only if the operand to typeid is an object of a class type with virtual functions. Testing a pointer (as opposed to the object to which the pointer points) returns the static, compile-time type of the pointer.
If the value of a pointer p is 0, then typeid(*p) throws a bad_typeid exception if the type of p is a type with virtual functions. If the type of p does not define any virtuals, then the value of p is irrelevant. As when evaluating a sizeof expression (Section 5.8, p. 167) the compiler does not evaluate *p. It uses the static type of p, which does not require that p itself be a valid pointer.
18.2.3 Using RTTI
As an example of when RTTI might be useful, consider a class hierarchy for which we’d like to implement the equality operator. Two objects are equal if they have the same value for a given set of their data members. Each derived type may add its own data, which we will want to include when testing for equality.
Because the values considered in determining equality for a derived type might differ from those considered for the base type, we’ll (potentially) need a different equality operator for each pair of types in the hierarchy. Moreover, we’d like to be able to use a given type as either the left-hand or right-hand operand, so we’ll actually need two operators for each pair of types.
If our hierarchy has only two types, we need four functions:
bool operator==(const Base&, const Base&)
bool operator==(const Derived&, const Derived&)
bool operator==(const Derived&, const Base&);
bool operator==(const Base&, const Derived&);
But if our hierarchy has several types, the number of operators we must define expands rapidly—for only 3 types we’d need 9 operators. If the hierarchy has 4 types, we’d need 16, and so on.
We might think we could solve this problem by defining a set of virtual functions that would perform the equality test at each level in the hierarchy. Given those virtuals, we could define a single equality operator that operates on references to the base type. That operator could delegate its work to a virtual equal operation that would do the real work.
Unfortunately, virtual functions are not a good match to this problem. The trouble is deciding on the type for the parameter to the equal operation. Virtual functions must have the same parameter type(s) in both the base and derived classes. That implies that a virtual equal operation must have a parameter that is a reference to the base class.
However, when we compare two derived objects, we want to compare data members that might be particular to that derived class. If the parameter is a reference to base, we can use only members that are present in the base class. We cannot access members that are in the derived class but not in the base.
Thinking about the problem in this detail, we see that we want to return false if we attempt to compare objects of different types. Given this observation, we can now use RTTI to solve our problem.
We’ll define a single equality operator. Each class will define a virtual equal function that first casts its operand to the right type. If the cast succeeds, then the real comparison will be performed. If the cast fails, then the equal operation will return false.
The Class Hierarchy
To make the concept a bit more concrete, let’s assume that our classes look something like:

A Type-Sensitive Equality Operator
Next let’s look at how we might define the overall equality operator:

This operator returns false if the operands are different types. If they are the same type, then it delegates the real work of comparing the operands to the appropriate virtual equal function. If the operands are Base objects, then Base::equal will be called. If they are Derived objects, Derived::equal is called.
The Virtual equal Functions
Each class in the hierarchy must define its own version of equal. The functions in the derived classes will all start the same way: They’ll cast their argument to the type of the class itself:

The cast should always succeed—after all, the function is called from the equality operator only after testing that the two operands are the same type. However, the cast is necessary so that the function can access the derived members of the right-hand operand. The operand is a Base&, so if we want to access members of the Derived, we must first do the cast.
The Base-Class equal Function
This operation is a bit simpler than the others:

There is no need to cast the parameter before using it. Both *this and the parameter are Base objects, so all the operations available for this object are also defined for the parameter type.
18.2.4 The type_info Class
The exact definition of the type_info class varies by compiler, but the standard guarantees that all implementations will provide at least the operations listed in Table 18.2
Table 18.2. Operations on type_info

The class also provides a public virtual destructor, because it is intended to serve as a base class. If the compiler wants to provide additional type information, it should do so in a class derived from type_info.
The default and copy constructors and the assignment operator are all defined as private, so we cannot define or copy objects of type type_info. The only way to create type_info objects in a program is to use the typeid operator.
The name function returns a C-style character string for the name of the type represented by the type_info object. The value used for a given type depends on the compiler and in particular is not required to match the type names as used in a program. The only guarantee we have about the return from name is that it returns a unique string for each type. Nonetheless, the name member can be used to print the name of a type_info object:

The format and value returned by name varies by compiler. This program, when executed on our machine, generates the following output:
i
d
Ss
4Base
7Derived
The type_info class varies by compiler. Some compilers provide additional member functions that provide additional information about types used in a program. You should consult the reference manual for your compiler to understand the exact type_info support provided.
18.3 Pointer to Class Member
We know that, given a pointer to an object, we can fetch a given member from that object using the arrow (->) operator. Sometimes it is useful to start from the member. That is, we may want to obtain a pointer to a specific member and then fetch that member from one or another object.
We can do so by using a special kind of pointer known as a pointer to member. A pointer to member embodies the type of the class as well as the type of the member. This fact impacts how pointers to member are defined, how they are bound to a function or data member, and how they are used.
Pointers to member apply only to nonstatic members of a class. static class members are not part of any object, so no special syntax is needed to point to a static member. Pointers to static members are ordinary pointers.
18.3.1 Declaring a Pointer to Member
In exploring pointers to members, we’ll use a simplified version of the Screen class from Chapter 12.

Defining a Pointer to Data Member
The contents member of Screen has type std::string. The complete type of contents is “member of class Screen, whose type is std::string.” Consequently, the complete type of a pointer that could point to contents is “pointer to member of class Screen of type std::string.” This type is written as
string Screen::*
We can define a pointer to a string member of class Screen as
string Screen::*ps_Screen;
ps_Screen could be initialized with the address of contents by writing
string Screen::*ps_Screen = &Screen::contents;
We could also define a pointer that might address the height, width, or cursor members as
Screen::index Screen::*pindex;
which says that pindex is a pointer to a member of class Screen with type Screen::index. We could assign the address of width to this pointer as follows:
pindex = &Screen::width;
The pointer pindex can be set to any of width, height, or cursor because all three are Screen class data members of type index.
Defining a Pointer to Member Function
A pointer to a member function must match the type of the function to which it points, in three ways:
- The type and number of the function parameters, including whether the member is
const - The return type
- The class type of which it is a member
A pointer to member function is defined by specifying the function return type, parameter list, and a class. For example, a pointer to a Screen member function capable of referring to the version of get that takes no parameters has the following type:
char (Screen::*)() const
This type specifies a pointer to a const member function of class Screen, taking no parameters and returning a value of type char. A pointer to this version of get can be defined and initialized as follows:
![]()
We might also define a pointer to the two-parameter version of get as
char (Screen::*pmf2)(Screen::index, Screen::index) const;
pmf2 = &Screen::get;
The precedence of the call operator is higher than that of the pointer-to-member operators. Therefore, the parentheses around Screen::* are essential. Without them, the compiler treats the following as an (invalid) function declaration:
// error: non-member function p cannot have const qualifier char Screen::*p() const;
Using Typedefs for Member Pointers
Typedefs can make pointers to members easier to read. For example, the following typedef defines Action to be an alternative name for the type of the two-parameter version of get:
![]()
Action is the name of the type “pointer to a const member function of class Screen taking two parameters of type index and returning char.” Using the typedef, we can simplify the definition of a pointer to get as follows:
Action get = &Screen::get;
A pointer-to-member function type may be used to declare function parameters and function return types:
![]()
This function is declared as taking two parameters: a reference to a Screen object and a pointer to a member function of class Screen taking two index parameters and returning a char. We could call action either by passing it a pointer or the address of an appropriate member function in Screen:

18.3.2 Using a Pointer to Class Member
Analogous to the member access operators, operators . and ->, are two new operators, .* and ->*, that let us bind a pointer to member to an actual object. The left-hand operand of these operators must be an object of or pointer to the class type, respectively. The right-hand operand is a pointer to a member of that type:
• The pointer-to-member dereference operator (.*) fetches the member from an object or reference.
• The pointer-to-member arrow operator (->*) fetches the member through a pointer to an object.
Using a Pointer to Member Function
Using a pointer to member, we could call the version of get that takes no parameters as follows:

The calls (myScreen.*pmf)() and (pScreen->*pmf)() require the parentheses because the precedence of the call operator—()— is higher than the precedence of the pointer to member operators.
Without the parentheses,
myScreen.*pmf()
would be interpreted to mean
myScreen.*(pmf())
This code says to call the function named pmf and bind its return value to the pointer to member object operator (.*). Of course, the type of pmf does not support such a use, and a compile-time error would be generated.
As with any other function call, we can also pass arguments in a call made through a pointer to member function:

Using a Pointer to Data Member
The same pointer-to-member operators are used to access data members:

Pointer-to-Member Function Tables
One common use for function pointers and for pointers to member functions is to store them in a function table. A function table is a collection of function pointers from which a given call is selected at run time.
For a class that has several members of the same type, such a table can be used to select one from the set of these members. Let’s assume that our Screen class is extended to contain several member functions, each of which moves the cursor in a particular direction:

Each of these new functions takes no parameters and returns a reference to the Screen on which it was invoked.
Using the Function-Pointer Table
We might want to define a move function that could call any one of these functions and perform the indicated action. To support this new function, we’ll add a static member to Screen that will be an array of pointers to the cursor movement functions:

The array named Menu will hold pointers to each of the cursor movement functions. Those functions will be stored at the offsets corresponding to the enumerators in Directions. The move function takes an enumerator and calls the appropriate function:

The call inside move is evaluated as follows: The Menu element indexed by cm is fetched. That element is a pointer to a member function of the Screen class. We call the member function to which that element points on behalf of the object to which this points.
When we call move, we pass it an enumerator that indicates which direction to move the cursor:
![]()
Defining a Table of Member Function Pointers
What’s left is to define and initialize the table itself:

18.4 Nested Classes
A class can be defined within another class. Such a class is a nested class, also referred to as a nested type. Nested classes are most often used to define implementation classes, such as the QueueItem class from Chapter 16.
Nested classes are independent classes and are largely unrelated to their enclosing class. Objects of the enclosing and nested classes are, therefore, independent from one another. An object of the nested type does not have members defined by the enclosing class. Similarly, an object of the enclosing class does not have members defined by the nested class.
The name of a nested class is visible in its enclosing class scope but not in other class scopes or in the scope in which the enclosing class is defined. The name of a nested class will not collide with the same name declared in another scope.
A nested class can have the same kinds of members as a nonnested class. Just like any other class, a nested class controls access to its own members using access labels. Members may be declared public, private, or protected. The enclosing class has no special access to the members of a nested class and the nested class has no special access to members of its enclosing class.
A nested class defines a type member in its enclosing class. As with any other member, the enclosing class determines access to this type. A nested class defined in the public part of the enclosing class defines a type that may be used anywhere. A nested class defined in the protected section defines a type that is accessible only by the enclosing class, its friends, or its derived classes. A private nested class defines a type that is accessible only to the members of the enclosing class or its friends.
18.4.1 A Nested-Class Implementation
The Queue class that we implemented in Chapter 16 defined a companion implementation class named QueueItem. That class was a private class—it had only private members—but it was defined at the global scope. General user code cannot use objects of class QueueItem: All its members, including constructors, are private. However, the name QueueItem is visible globally. We cannot define our own type or other entity named QueueItem.
A better design would be to make the QueueItem class a private member of class Queue. That way, the Queue class (and its friends) could use QueueItem, but the QueueItem class type would not be visible to general user code. Once the class itself is private, we can make its members public—only Queue or the friends of Queue can access the QueueItem type, so there is no need to protect its members from general program access. We make the members public by defining QueueItem using the keyword struct.
Our new design looks like:

Because the class is a private member, only members and friends of the Queue class can use the QueueItem type. Having made the class a private member, we can make the QueueItem members public. Doing so lets us eliminate the friend declarations in QueueItem.
Classes Nested Inside a Class Template Are Templates
Because Queue is a template, its members are implicitly templates as well. In particular, the nested class QueueItem is implicitly a class template. Again, like any other member in Queue, the template parameter for QueueItem is the same as the template parameter of its enclosing class: class Queue.
Each instantiation of Queue generates its own QueueItem class with the appropriate template argument for Type. The mapping between an instantiation for the QueueItem class template and an instantiation of the enclosing Queue class template is one to one.
Defining the Members of a Nested Class
In this version of QueueItem, we chose not to define the QueueItem constructor inside the class. Instead, we’ll define it separately. The only trick is where to define it and how to name it.
A nested-class member defined outside its own class must be defined in the same scope as the scope in which the enclosing class is defined. A member of a nested class defined outside its own class may not be defined inside the enclosing class itself. A member of a nested class is not a member of the enclosing class.
The constructor for QueueItem is not a member of class Queue. Therefore, it cannot be defined elsewhere in the body of class Queue. It must be defined at the same scope as the Queue class but outside that class. To define a member outside the nested-class body, we must remember that its name is not visible outside the class. To define the constructor, we must indicate that QueueItem is a nested class within the scope of class Queue. We do so by qualifying the class name QueueItem with the name of its enclosing class Queue:

Of course, both Queue and QueueItem are class templates. The constructor, therefore, is also a template.
This code defines a function template, parameterized by a single type parameter named Type. Reading the name of the function from right to left, this function is the constructor for class QueueItem, which is a nested in the scope of class Queue<Type>.
Defining the Nested Class Outside the Enclosing Class
Nested classes often support implementation details for the enclosing class. We might want to prevent users of the enclosing class from seeing the code that implements the nested class.
For example, we might want to put the definition of class QueueItem in its own file, which we would include in those files containing the implementation of the Queue class and its members. Just as we can define the members of a nested class outside the class body, we can define the entire class outside the body of the enclosing class:

To define the class body outside its enclosing class, we must qualify the name of the nested class by the name of its enclosing class. Note that we must still declare QueueItem in the body of class Queue.
A nested class also can be declared and then later defined in the body of the enclosing class. As with other forward declarations, a forward declaration of a nested class allows for nested classes that have members that refer to one another.
Until the actual definition of a nested class that is defined outside the class body is seen, that class is an incomplete type (Section 12.1.4, p. 437). All the normal retrictions on using an incomplete type apply.
Nested-Class Static Member Definitions
If QueueItem had declared a static member, its definition would also need to be defined in the outer scope. Assuming QueueItem had a static member, its definition would look somthing like:

Using Members of the Enclosing Class
Nonstatic functions in the nested class have an implicit this pointer that points to an object of the nested type. A nested-type object contains only the members of the nested type. The this pointer may not be used to fetch members of the enclosing class. Similarly, the nonstatic member functions in the enclosing class have a this pointer that points to an object of the enclosing type. That object has only the members defined in the enclosing class.
Any use of a nonstatic data or function member of the enclosing class requires that it be done through a pointer, reference, or object of the enclosing class. The pop function in class Queue may not use item or next directly:

Objects of type Queue do not have members named item or next. Function members of Queue can use the head and tail members, which are pointers to QueueItem objects, to fetch those QueueItem members.
Using Static or Other Type Members
A nested class may refer to the static members, type names, and enumerators (Section 2.7, p. 62) of the enclosing class directly. Of course, referring to a type name or static member outside the scope of the enclosing class requires the scope-resolution operator.
Instantiation for Nested Templates
A nested class of a class template is not instantiated automatically when the enclosing class template is instantiated. Like any member function, the nested class is instantiated only if it is itself used in a context that requires a complete class type. For example, a definition such as
Queue<int> qi; // instantiates Queue<int> but not QueueItem<int>
instantiates the template Queue with type int but does not yet instantiate the type QueueItem<int>. The Queue members head and tail are pointers to QueueItem<int>. There is no need to instantiate QueueItem<int> to define pointers to that class.
Making QueueItem a nested class of the class template Queue does not change the instantiation of QueueItem. The QueueItem<int> class will be instantiated only when QueueItem is used—in this case, only when head or tail is dereferenced from a member function of class Queue<int>.
18.4.2 Name Lookup in Nested Class Scope
Name lookup (Section 12.3.1, p. 447) for names used in a nested class proceeds in the same manner as for a normal class, the only difference being that now there may be one or more enclosing class scopes to search.
When processing the declarations of the class members, any name used must appear prior to its use. When processing definitions, the entire nested and enclosing class(es) are in scope.
As an example of name lookup in a nested class, consider the following class declarations:

The compiler first processes the declarations of the members of classes Outer, Outer::Inner, and Outer::Inner2.
The use of the name Outer as a parameter to Inner::process is bound to the enclosing class. That class is still incomplete when the declaration of process is seen, but the parameter is a reference, so this usage is okay.
The declaration of the data member Inner::val is an error. The type Inner2 has not yet been seen.
The declarations in Inner2 pose no problems—mostly they just use the built-in type int. The only exception is the process member function. Its parameter resolves to the incomplete type Outer. Because the parameter is a reference, the fact that Outer is an incomplete type doesn’t matter.
The definitions of the constructor and process member are not processed by the compiler until the remaining declarations in the enclosing class have been seen. Completing the declarations of class Outer puts the declaration of the function handle in scope.
When the compiler looks up the names used in the definitions in class Inner2, all the names in class Inner2 and class Outer are in scope. The use of val, which appears before the declaration of val, is okay: That reference is bound to the data member in class Inner2. Similarly, the use of handle from class Outer in the body of the Inner2::process member is okay. The entire Outer class is in scope when the members of class Inner2 are compiled.
Using the Scope Operator to Control Name Lookup
The global version of handle can be accessed using the scope operator:

18.5 Union: A Space-Saving Class
A union is a special kind of class. A union may have multiple data members, but at any point in time, only one of the members may have a value. When a value is assigned to one member of the union, all other members become undefined.
The amount of storage allocated for a union is at least as much as the amount necessary to contain its largest data member. Like any class, a union defines a new type.
Defining a Union
Unions offer a convenient way to represent a set of mutually exclusive values that may have different types. As an example, we might have a process that handles different kinds of numeric or character data. That process might define a union to hold these values:

A union is defined starting with the keyword union, followed by an (optional) name for the union and a set of member declarations enclosed in curly braces. This code defines a union named TokenValue that can hold a value that is either a char, an int, or a double. Section 18.5 (p. 795) will look at what it means to omit the union name.
Like any class, a union type defines how much storage is associated with objects of its type. The size of each union object is fixed at compile time: It is at least as large as the size of the union’s largest data member.
No Static, Reference, or Class Data Members
Some, but not all, class features apply equally to unions. For example, like any class, a union can specify protection labels to make members public, private, or protected. By default, unions behave like structs: Unless otherwise specified, the members of a union are public.
A union may also define member functions, including constructors and destructors. However, a union may not serve as a base class, so a member function may not be virtual.
A union cannot have a static data member or a member that is a reference. Moreover, unions cannot have a member of a class type that defines a constructor, destructor, or assignment operator:

This restriction includes classes with members that have a constructor, destructor, or assignment operator.
Using a Union Type
The name of a union is a type name:
![]()
Like other built-in types, by default unions are uninitialized. We can explicitly initialize a union in the same way that we can explicitly initialize (Section 12.4.5, p. 464) simple classes. However, we can provide an initializer only for the first member. The initializer must be enclosed in a pair of curly braces. The initialization of first_token gives a value to its cval member.
Using Members of a Union
The members of an object of union type are accessed using the normal member access operators (. and ->):
last_token.cval = 'z';
pt->ival = 42;
Giving a value to a data member of a union object makes the other data members undefined. When using a union, we must always know what type of value is currently stored in the union. Retrieving the value stored in the union through the wrong data member can lead to a crash or other incorrect program behavior.
The best way to avoid accessing the union value through the wrong member is to define a separate object that keeps track of what value is stored in the union. This additional object is referred to as the discriminant of the union.
Nested Unions
Most often unions are used as nested types, where the discriminant is a member of the enclosing class:

In this class, the enumeration object tok serves to indicate which kind of value is stored in the val member. That member is an (unnamed) union that holds either a char, int, or double.
We often use a switch statement (Section 6.6, p. 199) to test the discriminant and then do processing dependent on which value is currently stored in the union:

Anonymous Unions
An unnamed union that is not used to define an object is referred to as an anonymous union. The names of the members of an anonymous union appear in the enclosing scope. For example, here is our Token class rewritten to use an anonymous union:

Because an anonymous union provides no way to access its members, the members are directly accessible as part of the scope where the anonymous union is defined. Rewriting our previous switch to use the anonymous-union version of our class would look like:

An anonymous union cannot have private or protected members, nor can an anonymous union define member functions.
18.6 Local Classes
A class can be defined inside a function body. Such a class is called a local class. A local class defines a type that is visible only in the local scope in which it is defined. Unlike nested classes, the members of a local class are severely restricted.
All members, including functions, of a local class must be completely defined inside the class body. As a result, local classes are much less useful than nested classes.
In practice, the requirement that members be fully defined within the class limits the complexity of the member functions of a local class. Functions in local classes are rarely more than a few lines of code. Beyond that, the code becomes difficult for the reader to understand.
Similarly, a local class is not permitted to declare static data members, there being no way to define them.
Local Classes May Not Use Variables from the Function’s Scope
The names from the enclosing scope that a local class can access are limited. A local class can access only type names, static variables (Section 7.5.2, p. 255), and enumerators defined within the enclosing local scopes. A local class may not use the ordinary local variables of the function in which the class is defined:

Normal Protection Rules Apply to Local Classes
The enclosing function has no special access privileges to the private members of the local class. Of course, the local class could make the enclosing function a friend.
In practice, private members are hardly ever necessary in a local class. Often all members of a local class are public.
The portion of a program that can access a local class is very limited. A local class is encapsulated within its local scope. Further encapsulation through information hiding is often overkill.
Name Lookup within a Local Class
Name lookup within the body of a local class happens in the same manner as for other classes. Names used in the declarations of the members of the class must be in scope before the use of the name. Names used in definitions of the members can appear anywhere in the scope of the local class. Names not resolved to class members are searched first in the enclosing local scope and then out to the scope enclosing the function itself.
Nested Local Classes
It is possible to nest a class inside a local class. In this case, the nested class definition can appear outside the local-class body. However, the nested class must be defined in the same local scope as that in which the local class is defined. As usual, the name of the nested class must be qualified by the name of the enclosing class and a declaration of the nested class must appear in the definition of the local class:

A class nested in a local class is itself a local class, with all the attendant restrictions. All members of the nested class must be defined inside the body of the nested class itself.
18.7 Inherently Nonportable Features
One of the hallmarks of the C programming language is the ability to write low-level programs that can be readily moved from one machine to another. The process of moving a program to a new machine is referred to as “porting,” so C programs are said to be portable.
To support low-level programming, C defines some features that are inherently nonportable. The fact that the size of the arithmetic types vary across machines (Section 2.1, p. 34) is one such nonportable feature that we have already encountered. In this section we’ll cover two additional nonportable features that C++ inherits from C: bit-fields and the volatile qualifier. These features make it easier to interface directly to hardware.
C++ adds another nonportable feature to those that it inherits from C: linkage directives, which make it possible to link to programs written in other languages.
18.7.1 Bit-fields
A special class data member, referred to as a bit-field, can be declared to hold a specified number of bits. Bit-fields are normally used when a program needs to pass binary data to another program or hardware device.
A bit-field must be an integral data type. It can be either signed or unsigned. We indicate that a member is a bit-field by following the member name with a colon and a constant expression specifying the number of bits:
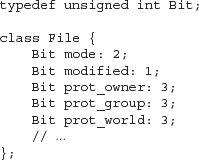
The mode bit-field has two bits, modified only one, and the other members each have three bits. Bit-fields defined in consecutive order within the class body are, if possible, packed within adjacent bits of the same integer, thereby providing for storage compaction. For example, in the preceding declaration, the five bit-fields will be stored in the single unsigned int first associated with the bit-field mode. Whether and how the bits are packed into the integer is machine-dependent.
Ordinarily it is best to make a bit-field an unsigned type. The behavior of bit-fields stored in a signed type is implementation-defined.
Using Bit-fields
A bit-field is accessed in much the same manner as the other data members of a class. For example, a bit-field that is a private member of its class can be accessed only from within the definitions of the member functions and friends of its class:

Bit-fields with more than one bit are usually manipulated using the built-in bitwise operators (Section 5.3, p. 154):

Classes that define bit-field members also usually define a set of inline member functions to test and set the value of the bit-field. For example, the class File might define the members isRead and isWrite:
inline int File::isRead() { return mode & READ; }
inline int File::isWrite() { return mode & WRITE; }
if (myFile.isRead()) /* ... */
With these member functions, the bit-fields can now be declared as private members of class File.
The address-of operator (&) cannot be applied to a bit-field, so there can be no pointers referring to class bit-fields. Nor can a bit-field be a static member of its class.
18.7.2 volatile Qualifier
The precise meaning of volatile is inherently machine-dependent and can be understood only by reading the compiler documentation. Programs that use volatile usually must be changed when they are moved to new machines or compilers.
Programs that deal directly with hardware often have data elements whose value is controlled by processes outside the direct control of the program itself. For example, a program might contain a variable updated by the system clock. An object should be declared volatile when its value might be changed in ways outside either the control or detection of the compiler. The volatile keyword is a directive to the compiler that it should not perform optimizations on such objects.
The volatile qualifier is used in much the same way as is the const qualifier. It is an additional modifier to a type:
volatile int display_register;
volatile Task *curr_task;
volatile int ixa[max_size];
volatile Screen bitmap_buf;
display_register is a volatile object of type int. curr_task is a pointer to a volatile Task object. ixa is a volatile array of integers. Each element of the array is considered to be volatile. bitmap_buf is a volatile Screen object. Each of its data members is considered to be volatile.
In the same way that a class may define const member functions, it can also define member functions as volatile. Only volatile member functions may be called on volatile objects.
Section 4.2.5 (p. 126) described the interactions between the const qualifier and pointers. The same interactions exist between the volatile qualifier and pointers. We can declare pointers that are volatile, pointers to volatile objects, and pointers that are volatile that point to volatile objects:

As with const, we may assign the address of a volatile object (or copy a pointer to a volatile type) only to a pointer to volatile. We may use a volatile object to initialize a reference only if the reference is volatile.
Synthesized Copy Control Does Not Apply to Volatile Objects
One important difference between the treatment of const and volatile is that the synthesized copy and assignment operators cannot be used to initialize or assign from a volatile object. The synthesized copy-control members take parameters that are const references to the class type. However, a volatile object cannot be passed to a plain or const reference.
If a class wants to allow volatile objects to be copied or to allow assignment from or to a volatile operand, it must define its own versions of the copy constructor and/or assignment operator:

By defining the parameter to the copy-control members as a const volatile reference, we can copy or assign from any kind of Foo: a plain Foo, a const Foo, a volatile Foo, or a const volatile Foo.
Although we can define the copy-control members to handle volatile objects, a deeper question is whether it makes any sense to copy a volatile object. The answer to that question depends intimately on the reason for using volatile in any particular program.
18.7.3 Linkage Directives: extern "C"
C++ programs sometimes need to call functions written in another programming language. Most often, that other language is C. Like any name, the name of a function written in another language must be declared. That declaration must specify the return type and parameter list. The compiler checks calls to external-language functions in the same way that it handles ordinary C++ functions. However, the compiler typically must generate different code to call functions written in other languages. C++ uses linkage directives to indicate the language used for any non-C++ function.
Declaring a Non-C++ Function
A linkage directive can have one of two forms: single or compound. Linkage directives may not appear inside a class or function definition. The linkage directive must appear on the first declaration of a function.
As an example, let’s look at some of the C functions declared in the cstdlib header. Declarations in that header might look something like

The first form consists of the extern keyword followed by a string literal, followed by an “ordinary” function declaration. The string literal indicates the language in which the function is written.
We can give the same linkage to several functions at once by enclosing their declarations inside curly braces following the linkage directive. These braces serve to group the declarations to which the linkage directive applies. The braces are otherwise ignored, and the names of functions declared within the braces are visible as if the functions were declared outside the braces.
Linkage Directives and Header Files
The multiple-declaration form can be applied to an entire header file. For example, the C++ cstring header might look like
When a #include directive is enclosed in the braces of a compound linkage directive, all ordinary function declarations in the header file are assumed to be functions written in the language of the linkage directive. Linkage directives can be nested, so if the header contained a function with a linkage directive the linkage of that function is unaffected.
The functions that C++ inherits from the C library are permitted to be defined as C functions but are not required to be C functions—it’s up to each C++ implementation to decide whether to implement the C library functions in C or C++.
Exporting Our C++ Functions to Other Langauges
By using the linkage directive on a function definition, we can make a C++ function available to a program written in another language:
// the calc function can be called from C programs
extern "C" double calc(double dparm) { /* ... */ }
When the compiler generates code for this function, it will generate code appropriate to the indicated language.
Every declaration of a function defined with a linkage directive must use the same linkage directive.
Languages Supported by Linkage Directives
A compiler is required to support linkage directives for C. A compiler may provide linkage specifications for other languages. For example, extern "Ada", extern "FORTRAN", and so on.
What languages are supported varies by compiler. You must consult the user’s guide for further information on any non-C linkage specifications it may provide.
Overloaded Functions and Linkage Directives
The interaction between linkage directives and function overloading depends on the target language. If the language supports overloaded functions, then it is likely that a compiler that implements linkage directives for that language would also support overloading of these functions from C++.
The only language guaranteed to be supported by C++ is C. The C language does not support function overloading, so it should not be a surprise that a linkage directive can be specified only for one C function in a set of overloaded functions. It is an error to declare more than one function with C linakage with a given name:
// error: two extern "C" functions in set of overloaded functions
extern "C" void print(const char*);
extern "C" void print(int);
In C++ programs, it is fairly common to overload C functions. However, the other functions in the overload set must all be C++ functions:

The C version of calc can be called from C programs and from C++ programs. The additional functions are C++ functions with class parameters that can be called only from C++ programs. The order of the declarations is not significant.
Pointers to extern "C" Functions
The language in which a function is written is part of its type. To declare a pointer to a function written in another programming language, we must use a linkage directive:
// pf points to a C function returning void taking an int
extern "C" void (*pf)(int);
When pf is used to call a function, the function call is compiled assuming that the call is to a C function.
A pointer to a C function does not have the same type as a pointer to a C++ function. A pointer to a C function cannot be initialized or be assigned to point to a C++ function (and vice versa).
When there is such a mismatch, a compile-time error message is issued:
![]()
Some C++ compilers may accept the preceding assignment as a language extension, even though, strictly speaking, it is illegal.
Linkage Directives Apply to the Entire Declaration
When we use a linkage directive, it applies to the function and any function point-ers used as the return type or as a parameter type:
// f1 is a C function; its parameter is a pointer to a C function
extern "C" void f1(void(*)(int));
This declaration says that f1 is a C function that doesn’t return a value. It has one parameter, which is a pointer to a function that returns nothing and takes a single int parameter. The linkage directive applies to the function pointer as well as to f1. When we call f1, we must pass it the name of a C function or a pointer to a C function.
Because a linkage directive applies to all the functions in a declaration, we must use a typedef to pass a pointer to a C function to a C++ function:

Chapter Summary
C++ provides several specialized facilities that are tailored to particular kinds of problems.
Customized memory management is used by classes in two ways: A class may need to define its own internal memory allocation that allows it to streamline allocation of its own data members. A class might want to define its own, class-specific operator new and operator delete functions that will be used whenever new objects of the class type are allocated.
Some programs need to directly interrogate the dynamic type of an object at run time. Run-time type identification (RTTI) provides language level support for this kind of programming. RTTI applies only to classes that define virtual functions; type information for types that do not define virtual functions is available but reflects the static type.
Pointers to ordinary objects are typed. When we define a pointer to a class member, the pointer type must also encapsulate the type of the class to which the pointer points. A pointer to member may be bound to any member of the class that has the same type. When we dereference a pointer to member, an object from which to fetch the member must be specified.
C++ defines several additional aggregate types:
• Nested classes, which are classes defined in the scope of another class. Such classes are often defined as implementation classes of its enclosing class.
• Unions are a special kind of class that may contain only simple data members. An object of a union type may define a value for only one of its data members at any one time. Unions are most often nested inside another class type.
• Local classes, which are very simple classes defined local to a function. All members of a local class must be defined in the class body. There are no static data members of a local class.
C++ also supports several inherently nonportable features including bit-fields and volatile, which make it easier to interface to hardware, and linkage directives, which make it easier to interface to programs written in other langauges.
Defined Terms
Standard library class that supports type-specific allocation of raw, unconstructed memory. The allocator class is a class template that defines member functions to allocate, deallocate, construct, and destroy objects of the allocator’s template parameter type.
Unnamed union that is not used to define an object. Members of the anonymous union are referred to directly. These unions may not have member functions and may not have private or protected members.
Class member with an signed or unsigned integral type that specifies the number of bits to allocate to the member. Bit-fields defined in consecutive order in the class are, if possible, compacted into a common integral value.
A delete expression destroys a dynamically allocated object of a specified type and frees the memory used by that object. A delete[] expression destroys the elements of a dynamically allocated array of a specified type and frees the memory used by the array. These expressions use the corresponding version of the library or class-specific operator delete functions to free raw memory that held the object or array.
Programming technique that uses an object to determine which actual type is held in a union at any given time.
Operator that performs a checked cast from a base type to a derived type. The base type must define at least one virtual function. The operator checks the dynamic type of the object to which the reference or pointer is bound. If the object type is the same as the type of the cast (or a type derived from that type), then the cast is done. Otherwise, a zero pointer is returned for a pointer cast, or an exception is thrown for a cast of a reference.
Memory management technique that involves preallocating unconstructed memory to hold objects that will be created as needed. When objects are freed, their memory is put back on the free list rather than being returned to the system.
Mechanism used to allow functions written in a different language to be called from a C++ program. All compilers must support calling C and C++ functions. It is compiler-dependent whether any other languages are supported.
Class defined inside a function. A local class is visible only inside the function in which it is defined. All members of the class must be defined inside the class body. There can be no static members of a local class. Local class members may not access the local variables defined in the enclosing function. They may use type names, static variables, or enumerators defined in the enclosing function.
member operators new and delete
Class member functions that override the default memory allocation performed by the global library operator new and operator delete functions. Both object (new) and array (new[]) forms of these functions may be defined. The member new and delete functions are implicitly declared as static. These operators allocate (deal-locate) memory. They are used automatically by new (delete) expressions, which handle object initialization and destruction.
Class defined inside another class. A nested class is defined inside its enclosing scope: Nested-class names must be unique within the class scope in which they are defined but can be reused in scopes outside the enclosing class. Access to the nested class outside the enclosing class requires use of the scope operator to specify the scope(s) in which the class is nested.
Synonym for nested class.
A new expression allocates and constructs an object of a specified type. A new[] expression allocates and constructs an array of objects. These expressions use the corresponding version of the library operator new functions to allocate raw memory in which the expression constructs an object or array of the specified type.
A library function that frees untyped, unconstructed memory allocated by operator new. The library operator delete[] frees memory used to hold an array that was allocated by operator new[].
A library function that allocates untyped, unconstructed memory of a given size. The library function operator new[] allocates raw memory for arrays. These library functions provide a more primitive allocation mechanism than the library allocator class. Modern C++ programs should use the allocator classes rather than these library functions.
The form of new that constructs its object in specified memory. It does no allocation; instead, it takes an argument that specifies where the object should be constructed. It is a lower-level analog of the behavior provided by the construct member of the allocator class.
Pointer that encapsulates the class type as well as the member type to which the pointer points. The definition of a pointer to member must specify the class name as well as the type of the member(s) to which the pointer may point:
TC::*pmem = &C::member;
This statement defines pmem as a pointer that can point to members of the class named C that have type T and initializes it to point to the member in C named member. When the pointer is dereferenced, it must be bound to an object of or pointer to type C:
classobj.*pmem;
classptr->*pmem;
fetches member from the object classobj of the object pointed to by classptr.
Term used to describe a program that can be moved to a new machine with relatively little effort.
Term used to describe the language and library facilities that allow the dynamic type of a reference or pointer to be obtained at run time. The RTTI operators, typeid and dynamic_cast, provide the dynamic type only for references or pointers to class types with virtual functions. When applied to other types, the type returned is the static type of the reference or pointer.
Unary operator that takes an expression and returns a reference to an object of the library type named type_info that describes the type of the expression. When the expression is an object of a type that has virtual functions, then the dynamic type of the expression is returned. If the type is a reference, pointer, or other type that does not define virtual functions, then the type returned is the static type of the reference, pointer, or object.
Library type that describes a type. The type_info class is inherently machine-dependent, but any library must define type_info with members listed in Table 18.2 (p. 779). type_info objects may not be copied.
Classlike aggregate type that may define multiple data members, only one of which can have a value at any one point. Members of a union must be simple types: They can be a built-in or compound type or a class type that does not define a constructor, destructor, or the assignment operator. Unions may have member functions, including constructors and destructors. A union may not serve as a base class.
Type qualifier that signifies to the compiler that a variable might be changed outside the direct control of the program. It is a signal to the compiler that it may not perform certain optimizations.