
CHAPTER 22
Protecting Data Moving Through the Internet
As previously discussed, most users and organizations want to use the Internet to interact with different types of people. These interactions can involve activities such as exchanging information through email, social media, FTP transmissions, and other transport mechanisms. They can also involve activities that include sending sensitive personal information, conducting financial activities, or transferring medical information that typically CALLS for heightened security measures. In this chapter, you will learn to:
- Describe typical Internet access control strategies, including authentication methods and protocols
- Define basic cryptography implementations used to secure data in motion, including encryption, digital signatures, certificate management, PKI, public versus private keys, hashing, and key management
- Describe the two major components involved in creating a virtual private network (VPN)
Securing Data in Motion
Because the Internet is public and based on TCP/IP, strangers and bad people can potentially examine these interactions. So, transmission-specific security features must be added to these messages to protect the data while it is in motion between the secure environment of the sender and the secure environment of the intended receiver.
The NIST Cybersecurity Framework standards specifically call for establishing security for data in motion (as opposed to data at rest, which is stored in some device that may be more protected). The following sections of this chapter deal with devices, tools, protocols, and policies involved in securing data as it moves across the Internet.
Often, security is implemented as we initially configure services. Sometimes we really don’t even think of it as security per se but rather simple configuration. It is important to be thinking about security throughout the configuration process because this is typically where many security features are enabled. To properly implement security concepts, it is important that you have a basic understanding of authentication and encryption.
Authentication
As illustrated in all of the previous chapters, security at all levels always involves some type of authentication process. Recall that authentication is simply a way to know the identity of a user through some means. You will certainly want to authenticate outside users who want to access your network, and you will generally also want to authenticate internal users as they venture out to locations unknown on the Internet.
Users can be authenticated by asking them to provide a username and password, examining their MAC address, or by their network address if they are assigned a static IP address. A combination of factors may be used, and it is becoming more common to involve other factors unrelated to the network in the authentication scheme. If unauthenticated users are allowed on the network, you will have no way of tracking their activities.
After a user is authenticated, you will generally want to determine their authorization, which essentially involves the resources that the authenticated user has permission to access, and what actions they can perform. Often, these credentials and permissions are stored in some sort of database, but sometimes authentications are stored in simple text files. The security of these files and databases are critical aspects of network security.
After a user has been authenticated and authorized, their activities need to be accounted for by means of some type of logging process. This is an often-overlooked concept related to authentication. However, logging is a key component of the security process, as security is never a purely preventative activity. Administrators must wade through logs from time to time to evaluate what events have happened, might have happened, or may yet happen in their networks, as well as to whom it happened.
Single-Factor Authentication
From the previous three chapters, you should be aware that the most well-known authentication method is certainly password authentication. It can be as simple as prompting the user for a password and nothing else. This is commonly seen when wireless users connect to an access point. The user is able to browse available access points around them and then only needs to provide a password or authentication key to connect. This is single-factor authentication and represents the lowest level of security available.
Single-factor authentication may be fine for restricting access to resources but can make it more challenging to verify the identity of the actual user. It may also be sufficient for guest access in a residential network, but this conveys a certain amount of trust in those users because they can now access the network and its Internet connection with much the same access as the owner.
You can configure restrictions, but at some point users will have access capabilities that increase your liability. When that liability is too great, you must find another way to authenticate. If passwords are a part of your security plan, you also must consider policies related to those passwords. A poor password may be enough for home networks, but every business should have strict policies relating to password quality and perhaps even password history.
Multifactor Authentication
Two-factor authentication involves asking for authentication using a second, different method. For example, one factor is something physical or in the user’s possession such as:
- An RFID key
- A USB key dongle
- A card swiped
Another factor is some physical characteristic, such as:
- A fingerprint or iris scanned
- A spoken phrase, analyzing the user’s voice
The different factors used can be set apart as one of the following:
- Something you know (a password or PIN)
- Something you have (a physical token or card)
- Something you are (physical characteristic like fingerprint)
Having a bank card and knowing your PIN code is an example of two-factor authentication. If authentication using some physical attribute cannot be implemented, an identifier that is not easily guessable could be used as a second factor. If both components are difficult to guess, the likelihood of a brute-force attack being successful is dramatically less than with single-factor authentication or with an email-password pair.
Additional authentication factors can be added to the login sequence to increase security by making it less and less likely that an attack will be successful. However, with more challenging login sequences, users will become dissatisfied and resort to scribbling credentials on sticky notes and desktop calendars, or just simply not using the service. This is a huge challenge for any website designer or security engineer where user satisfaction is an issue. When users are inconvenienced enough, they will find a way to bypass security.
Password Management
Passwords are a huge nuisance to users. The majority of users can remember only one or two passwords, and if each login requires a unique scheme or authentication factor, they might just give up and not participate.
Administrators must balance their need for security against the user’s willingness to comply with strong password requirements. There will almost always be grumbling, but this balance must be established and enforced—there will be much more grumbling if the user’s account is compromised.
Password manager applications can be employed to ease user’s password woes. These applications run on computers and mobile devices and will remember user authentication parameters so users don’t have to remember them. While using such applications places all of the user’s passwords behind one authentication scheme, that scheme is stored on a more personal device to which the user can control access.
This single-credential system can be made more secure by using a challenging password; fortunately, most users can learn a single secure password. Password managers generally suggest long and secure passwords that you can use that you couldn’t possibly remember. This can be a great solution so long as the password manager always works, although not every application or gateway will work with these systems conveniently.
IP and MAC Authentication
Access control lists are commonly used by servers and routers to grant a certain amount of access. When all that’s required is to ensure that access to a system is granted only to users from a particular network (or through a particular piece of hardware), IP address authentication or MAC address authentication can be effective.
However, be aware of IP address spoofing, where IP packets are created with a header containing a forged source IP address. Generally, this is done to conceal the source of a denial-of-service or other attack, but this can also be a way of defeating IP address authentication.
IP spoofing won’t work in all authentication schemes, as often something must be sent back to the user and that information is sent to the spoofed IP and not the actual source of the connection. Only in the case where the “spoofer” is on the same broadcast network can the spoofer eavesdrop for the reply.
IP authentication should be used only in combination with other authentication methods or to allow a connection to merely have the opportunity to communicate with a protocol or device and not for any specific access privileges whenever possible. This is generally best used in a LAN environment where spoofing should be less of a concern.
As you learned in Part I, a MAC address can also be spoofed. While this address is embedded in the hardware device network controller, a computer can mask this address to impersonate a different device. This can be far more effective than IP spoofing because it happens before the IP connection is established. MAC address authentication may be used in combination with other authentication schemes but should not be used for any serious authentication alone.
Authentication Protocols
A number of protocols are used on the Internet for validating access and facilitating secure communications between clients and a server-based system. These schemes are based on the use of authentication protocols. The following section discusses a few of the more common authentication protocols in use.
Password Authentication Protocol (PAP) is a standard username and password combination scheme that operates with or without an encrypted password. With both parameters set and rarely, if ever, changed, this leaves the system subject to simple guessing, especially if the username is easily obtainable as is the case with email addresses and sequential ID usernames.
Challenge-Handshake Authentication Protocol (CHAP) creates a random string, a challenge phrase, or a secret. It then combines that with something else, such as the username or host name, and sends the combined information to the requesting system. The requestor, in turn, hashes the string and returns the result. The server then checks to see that the hashed result is correct and authenticates or denies the requestor.
With CHAP, the server might make this request periodically and use different challenge phrases to revalidate the connection. Because the secret must be known to both sides and is never sent over the connection, this method is much more secure. Every possible secret must be maintained in plaintext at each end, so this protocol does have its limitations.
Kerberos authentication gets its name from a mythological three-headed dog. Kerberos involves relying on a trusted third-party Ticket Granting Server (TGS) to authenticate client/server interaction. The exact process varies with implementation, but essentially the client exchanges cleartext information with the Authentication Server (AS), which then uses keys shared with the client to encrypt messages that include keys shared between the AS and the TGS, as illustrated in Figure 22.1.

FIGURE 22.1 Kerberos Authentication
The client then validates these messages and decrypts them using the shared key and encrypts messages that include the TGS keys with keys shared between the client and the TGS. The TGS then decrypts the messages with those shared keys, which then allow the TGS access to the message from the AS, which it can decrypt using the keys shared between the TGS and the AS.
Then a similar process happens in reverse where encrypted authentication information is sent back to the client where it is partially decrypted and sent back to the AS for final authentication.
This has been oversimplified, but you can see the role the TGS or Kerberos server has in the process. Since this Kerberos server would represent a single point of failure, it is also possible to have multiple Kerberos servers. Each of these messages is time-stamped and given a strict expiration time and can be problematic on congested networks. This type of authentication also requires a lot of key management and can be a nightmare for administrators.
Remote Authentication Dial-In User Service (RADIUS) was a common protocol used in the dial-up modem days of the Internet, but it is also used as a simple method of user authentication and accounting on Wi-Fi and other modern networks. RADIUS uses the AAA protocol (Authentication, Authorization, and Accounting), which can use different link layer protocols but usually uses PPP and authenticates using PAP or CHAP, but the RADIUS server can use Kerberos or other protocols.
Password-Authenticated Key Agreement (PAKE) is essentially encrypted authentication using shared keys. Keys can be shared by multiple servers to allow a user to visit other servers using the same authentication.
Secure Remote Password (SRP) protocol is an augmented form of PAKE that uses a large, private shared key derived from a random number. The random number is partially generated by the client and partially generated by the server, which makes the number unique to each login attempt. This prevents attackers from simply brute-force-guessing passwords, even if the server is hacked.
Some email authentication schemes use a Challenge Response Authentication Mechanism (CRAM) based upon the MD5 message-digest algorithm. MD5 uses a 128-bit hash value expressed as a 32-digit hexadecimal number. CRAM-MD5 has largely fallen into disfavor because the passwords are stored on the server in plaintext, making them vulnerable to dictionary and birthday attacks.
The Lightweight Directory Access Protocol (LDAP) is a popular protocol often used for authentication in enterprise networks. LDAP offers a single login system that can lead to access to many services. A nonstandard Secure LDAP version is available that offers LDAP over SSL.
Encryption
Encryption is nothing more than the conversion of electronic data into a form called ciphertext. This involves applying a secret code, called a cipher, to the data to produce a scrambled message that cannot be understood without the knowledge of the cipher that was used to create it. It won’t matter how secure the password is if a third party can easily capture it electronically.
On the Internet, data passes across many systems and lines that you do not control. As such, any credentials passing through external networks in the form of cleartext may end up in the wrong hands if the bad guys are examining the data packets as they pass through specific nodes. This practice is known as packet sniffing, as shown in Figure 22.2. Adding encryption to the credential system is critical in any network security scheme.
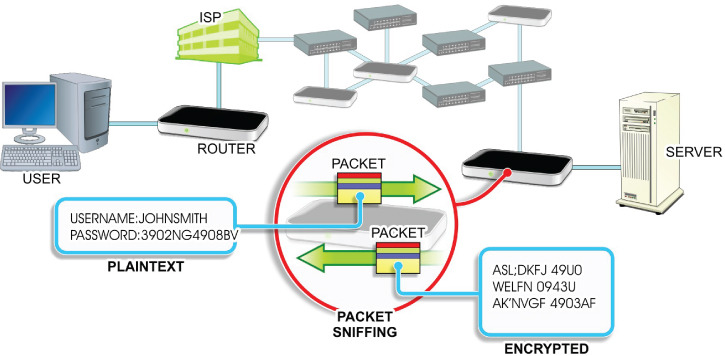
FIGURE 22.2 Viewing Credentials
Any password mechanism can employ good security techniques. If the following three conditions exist, then that system can be considered somewhat secure:
- At least some of the credentials are never stored anywhere without encryption,
- The encryption keys or secrets are not stored anywhere.
- The connection between the client and server is secure and encrypted.
That same system can be made more secure by including more factors and by adding physical factors, such as fingerprint scanning or another biometric authentication system, as described in Chapters 1 and 2. However, while the industry has been producing device solutions for years, mainstream acceptance by users takes a much longer time.
If you use a credential-based access system that does not use good security techniques, then you must understand the risk associated with that activity. If very little is at risk, then just using good password policy might provide enough security.
Cryptography
Cryptography is the term used to describe the concepts and methods for securing information. Many researchers have built their careers on a single cryptographic algorithm. Some of these methods are interesting historically and can be fascinating to read about, but we will deal with only a few of the modern areas of cryptography.
Many cryptographic techniques involved the use of keys. A key is merely a data string used to encrypt or decrypt information. How the key is used in this way and how large the string is does impact the strength of the encryption. Encryption keys can be based on a “secret” string that is known only to the software that encrypts and decrypts the data, or it may be randomly generated. It could also be a combination of known and random factors.
The algorithm that performs this encryption or decryption is known as a cipher. A cipher might be a stream cipher dealing with one character at a time or a block cipher that deals with multiple blocks of an input string at one time.
If the same key is used for both encryption and decryption, then it is a symmetric key. If a different key is used for encryption than decryption, then these are known as asymmetric keys even if the keys are based on one another. The difference is shown in Figure 22.3.

FIGURE 22.3 Symmetric vs. Asymmetric Keys
Public-key cryptography uses asymmetric keys incorporating a public key and a private key (or secret key). Public and private keys are different. A person’s public key is widely shared, while their private key must be kept secret to them only. Asymmetric key cryptography when used correctly offers two services: encryption and authentication (proving someone is who they say they are).
The strength of this type of cryptography obviously is related to how impossible this calculation is to reverse engineer. The initial authentication process typically involves processing some credential with the private key to produce a digital signature. Subsequent verification is then done by processing the public key against this signature to validate the original credential or message.
Public-key cryptography is used in a number of different encryption protocols and systems including:
- Transport Layer Security and Secure Sockets Layer (TLS and SSL)
- Secure Shell (SSH)
- PGP (Pretty Good Privacy)
- GNU Privacy Guard (GPG)
- Secure/Multipurpose Internet Mail Extensions (S/MIME)
- Digital Signature Standard (DSS)
- RSA encryption algorithm
Symmetric-key cryptography uses the same or easily transformed key for both encryption and decryption. These keys are known as a shared secret between the two sides of the transaction. Symmetric-key encryption is used in Advanced Encryption Standard (AES) encryption, Blowfish, RC4, 3DES, and many other schemes.
Simple stream ciphers are less secure, so most use 64-bit or better block ciphers. Some schemes will tout their strength by mentioning the block size of their encryption (such as 256-bit encryption). The original plaintext input must be padded so that it is an even multiple of the block size.
Symmetric-key ciphers are mostly vulnerable to brute-force attacks where the attacker systematically guesses the key based on a known list or a predictive mathematical scheme, so the authentication scheme should try to identify these activities and automatically employ appropriate measures to thwart them. This typically means limiting the number of authentication attempts in a period of time, which can be an inconvenience to users but a necessary feature nonetheless.
Another component of the strength of a key-based security scheme is the degree of randomness used in key generation. Randomized keys may be generated algorithmically using applications called pseudorandom key generators. Randomizers employ some source of entropy (or a degree of uncertainty) as a seed for randomization. The degree of entropy can be measured, generally in bits, and is sometimes mentioned in the strength analysis of an encryption scheme.
Ideally, the entropy is the same size as the key. The source of this entropy is typically a combination of data readily available to the system, possibly transformed by some multiplier or algebraic equation. For example, a randomizer might combine the milliseconds of time since some time in the past divided by the process ID padded to length.
If the time is somewhat randomly calculated (say, randomly chosen between 1,001 and 4,017 seconds ago) and the process ID would be difficult for anyone to predict, you would have an easily generated random key. Some key generation algorithms use wild math to transform keys, but at the heart of entropy is some source of pseudorandom data.
Ultimately, it is desirable to work with asymmetric keys using 256-bit block ciphers where the keys are generated by high entropy randomizers. Today you are unlikely to see this frequently. For large scale systems, processing such calculations can be processor intensive and the management of such schemes can be arduous.
Digital Certificates
Digital certificates, also known as public key certificates, are digital verifications that the sender of an encrypted message is who they claim to be. To obtain a digital certificate, you must apply to a trusted Certificate Authority (CA). The applicant must create a private key and provide a Certificate Signing Request (CSR) to the CA.
Depending on the type of certificate involved, the CA will verify your identity in some manner, which might be as simple as verifying an email account on that domain but could involve the verification of public company documents or even a personal interview.
The CA then issues an encrypted digital certificate containing a public key for the applicant, along with their digital signature and an expiration date. When the applicant receives the encrypted message, they must use the CA’s public key to decrypt the digital certificate attached to the message and verify that it was issued by the CA.
Next, the applicant uses the CA’s public key and identification to encrypt a reply indicating their trust of this encryption. Finally, the server uses its private key to decrypt the response in order to obtain the symmetric public key that will be used for the data exchange. This process is illustrated in Figure 22.4.

FIGURE 22.4 Digital Certificates
Public Key Infrastructure (PKI) supports the distribution of these public keys and certificates to enable trusted connections and secure data exchange based on the information from the CA signer. CAs must obtain their own certificates from a higher ranking CA. At the top of this hierarchy there must be a root certificate or self-signed certificate identifying the Root Certificate Authority.
Software such as web browsers may contain CA keys to facilitate the handling of certificates. However, they should also reference a Certificate Revocation List (CRL) or use the Online Certificate Status Protocol (OCSP) to query for revoked certificates. Increasingly, browsers are employing OCSP, but there are still those providers that simply include a CRL with each update of their browser software.
A certificate chain is the list of certificates starting with the root certificate followed by every other certificate where the issuer or signer of one certificate is the subject of the next. While a certificate can have only one issuing CA signature, different certificate chains may exist for some certificates because more than one certificate can be created using the same public key.
Secure certificates should be obtained only from known and respected CAs, or you risk having the certificates revoked. CAs are increasingly pushing Extended Validation (EV) certificates where the identity of the entity is verified much more extensively. EV certificates are no stronger or structurally different than other certificate types, but they imply a greater trust because the site being visited is owned by the certificate holder.
Web browsers typically have some visual indication that the SSL/TLS connection is using an EV certificate. This usually involves displaying information using a green color. EV certificates are typically used only on sites that accept credit cards or other private data (rather than those that handle email or other services).
It is possible to generate and use a self-signed certificate for encryption. This can be useful for testing. However, client software will inform the user that this certificate is not trusted.
Secure Sockets Layer (SSL)
Secure Sockets Layer (SSL) is a protocol for managing both authentication and communication between clients and servers using both a public key and a private key. SSL uses the sockets method to exchange data between client and server program. A socket is bound to a specific port number and once created will listen for a connection request. Web requests using SSL use the HTTPS protocol designation rather than HTTP.
In 2014, SSL version 3.0 was considered vulnerable due to a repeatable, man-in-the-middle attack method called Padding Oracle on Downgraded Legacy Encryption (POODLE). Therefore, SSL v3.0 is now considered obsolete.
Transport Layer Security (TLS)
Transport Layer Security (TLS) is the successor to SSL even though the two are often referred to interchangeably or even together as SSL/TLS. They are not, however, interoperable. The TLS Handshake Protocol allows the client and server to exchange keys and handle an encryption algorithm prior to any exchange of data.
Hash Tables
A hash table is simply a lookup table that maps keys to values using a hash function that converts the keys into hash values. Rather than sequentially searching a table of data looking for a particular value, a hash function can be performed on the lookup key, which will return the index to the hash value being searched for. This can save a tremendous amount of time searching for data.
A distributed hash table (DHT) is a similar type of function, but the mapping from keys to values is distributed among the different nodes across the network. The node that stores this map can be found by hashing that key.
Cookies
Cookies are a bit of text stored on a system after visiting a particular website. Because web protocol is largely “stateless,” the saved cookie text allows some information to remain, such as a password or preference, about the website for future visit.
In many cases, users hear about privacy concerns and decide that cookies are a bad thing and simply block them in their browser. This will likely cause a number of issues with some sites, including the inability to log in to private areas or even the creation of a requirement to constantly reenter simple identity data. Most cookies aren’t malicious and should be accepted.
Browsers offer the ability to block cookies from sites that the user isn’t visiting. While this partially solves the tracking cookie issue, older browsers may still allow some scripting that can circumvent this privacy feature.
Often, some compelling offer on a particular site will bring up a pop-up window from a different domain (which you are now visiting) and load the cookie in that way. While blocking popups can help, educating users about the pitfalls of aggressive clicking before thinking is a more effective way to prevent these issues.
More recently, super cookies have emerged as another privacy nuisance. Super cookies are simply third-party cookies that are harder to remove than other types of cookies. Many of them do not use the traditional cookie storage methodology, but rather use local browser HTML5 database storage or even Adobe Flash data storage.
These Flash cookies and super cookies heighten the already bad reputation of cookies, but browser vendors have responded well and modern browsers now control these storage options. Conceptually, this is done in the same manner as traditional cookies offering a way to block cookies from third party sites.
CAPTCHAs
Everyone should be aware of the reality that almost anything available publicly can be exploited in some manner. While this exploration might come from actual humans, a larger threat comes from automated tools that can be used to carry out the exploitation. Often, the purpose of the exploitation is simply to inject unsolicited commercial advertisements into a message through a form.
However, this can also be a way to carry out brute-force password attacks where an automated device might repeatedly try different credentials to obtain access. This is frequently seen on many web forms where the site owner is merely trying to minimize spam. However, a similar concept can be used on authentication forms to thwart automated attacks.
CAPTCHA is an acronym for Completely Automated Public Turing test to tell Computers and Humans Apart. These are generally a form input request for a word or phrase or maybe even random characters and numbers but can also be a simple request to perform a simple test that cannot easily be automated, such as identifying colors by name. Often, these CAPTCHAs feature obscured text, making it hard for automated tools to interpret them, as illustrated in Figure 22.5.

FIGURE 22.5 CAPTCHA Examples
Adding a CAPTCHA to a traditional authentication scheme can potentially eliminate any kind of automated password attack. While these tests tend to annoy users, they are generally very effective. However, they are also a barrier to some users with certain disabilities, unless alternative mechanisms are included that target those users.
Authentication is a key part of any security conversation and can be done in many different ways. Network administrators must find the proper balance of security for access for their particular network or application, and the ease of use for users. The more at risk, the more security that should be deployed. At a minimum, it is best to find multiple ways to authenticate users.
Virtual Private Networks
An important networking concept is that of the Virtual Private Network (VPN). A remote user can connect to a private network over a public network, such as the Internet, and then authenticate and perform tasks on the private network as if they were connected directly, as illustrated in Figure 22.6.

FIGURE 22.6 VPN Connections
Basically, a virtual private network consists of two components: a communication point-to-point tunnel established between the sender and the recipient and an encryption scheme for encoding the data so that it cannot be understood even if it is intercepted. For this reason, VPNs often involve the use of two different protocols: a tunneling protocol and an encryption protocol.
VPNs may be established using a variety of protocols and encryption, and can be one of the more complex things with which a network administrator has to deal. Many VPNs are simply point-to-point connections over IP or MPLS and do not support Layer 2 protocols such as Ethernet. Therefore, most networking is limited to TCP/IP, but newer VPN variants like Virtual Private LAN Service (VPLS) or Layer 2 Tunneling Protocol (L2TP) can provide Ethernet-based communication.
VPNs may be either trusted VPNs or secure VPNs. Trusted VPNs do not use cryptographic tunneling but rather trust the underlying network to handle security beyond authentication. Secure VPNs handle the encryption of the connection.
Many different types of VPNs are available, but the most widely used protocol is the Point-to-Point Tunneling Protocol (PPTP). PPTP does not provide any encryption and uses the simple password authentication taken from the Point-to-Point Protocol (PPP).
Layer 2 Tunneling Protocol (L2TP) also uses PPP and is unencrypted but can pass another encryption protocol in the tunnel. Often, the underlying protocol will be combined with L2TP as with L2TP/IPsec.
Internet Protocol Security (IPsec) is an open standard commonly used in VPNs that actually employs a suite of protocols for encrypting and authenticating IP communications. Protocols in this suite include:
- Authentication Headers (AH) provides data integrity and origin authentication to protect against replay attacks (attacks where a recorded transmission is replayed by an attacker to gain access).
- Encapsulating Security Payloads (ESP) offers origin authentication as well as encryption. ESP encrypts and encapsulates the entire TCP/UDP datagram within an ESP header that does not include any port information. This means that ESP won’t pass through any device using port address translation.
- Security Associations (SAs) offer a number of algorithms and frameworks for authentication and key exchange.
- Internet Key Exchange (IKE) is the protocol used to set up a security association in IPsec.
Hands-On Exercises
Objectives
The purpose of this lab is to implement file hashes, compare file hashes, describe the usage and importance of file hashing, and define file integrity.
Resources
- Customer-supplied desktop/laptop hardware system
- Windows 10 Professional installed
- MD5deep installed
MD5deep may be obtained from https://sourceforge.net/projects/md5deep/files/md5deep/md5deep-4.3/md5deep-4.3.zip/download.
Download, extract, and move the MD5deep folder to your desktop.
Discussion
Hashing is a basic type of cryptography. It employs a one-way algorithm that creates a unique hash (also known as a message digest). The purpose of a hash is not to create a cryptographic message to be decrypted later; instead, it is used to compare a file before and after a certain set of circumstances has arisen.
Hashing does not ensure confidentiality, rather it confirms file integrity. File integrity proves the file has not been altered in any way while the file or message was in transit.
A common use of file hashing is used with downloads from the Internet. Perhaps a freeware item is available, but you are worried that a malicious user has tampered with the file on the site. The owner of the site, however, has provided a hash of the original file in case you want to compare it once downloaded. Examining the string of characters on the site, you create a hash of the downloaded file and compare. If they are exactly the same, you have confirmed file integrity.
Procedures
In this procedure, you will create and compare hashes. You will also tamper with the file to witness the differences in hashing so you’ll better understand what ensuring file integrity really means.
Locating MD5deep
MD5deep is a command-line tool that supplies hashing algorithms that include MD5, Whirlpool, and Sha-1. The noticeable differences in the hashing algorithms occur in the padding and length (in bits) of the digest.
- Power on your machine.
- Log on to your computer using your administrative account.
- Double-click the
md5deep-4.3folder, located on the desktop.
To help navigate which files are which, you will change the view option to show the file extensions of each file.
- Click the View tab near the top left of the window and place a check in the box next to File Name Extensions; this will add the extensions to each file to help you navigate which files are which, as shown in Figure 22.7.

FIGURE 22.7 Show File Extensions
- Locate
md5deep.exe,sha1deep.exe, andwhirlpooldeep.exe, as depicted in Figure 22.8. These will be the hash algorithms you will test.
FIGURE 22.8 The Hash Algorithms
Creating a Test File
For ease of use, you will create a test file in the same folder as the hash algorithms. Using the command line can be difficult if you are not familiar with it, so keeping the file in the same folder will create an easier environment to navigate.
- Right-click any empty white space in the right pane.
- Navigate to and select New ➣ Text Document.
- You will be prompted to create a name for the new text document. Type HashTest as the name. Notice the file is given a
.txtextension, as depicted in Figure 22.9. Press Enter to confirm.
FIGURE 22.9 Creating the
HashTest.txtFile - Double-click the
HashTest.txtfile to open it in Notepad. - Type This is my Hash Test!, as shown in Figure 22.10.

FIGURE 22.10 Contents of HashTest File
- Click File, and then select Save to save the contents. Exit Notepad by clicking on the red X in the top-right corner of the window.
There are GUI-based hash outputs; however, you will use the command line to discover the digests for the file.
Creating Multiple Hashes
A hash is similar to a digital fingerprint. It is considered secure if it includes a fixed size, is unique, and cannot be reversed to reveal the original plaintext.
- Leave the
md5deep-4.3folder open. - To locate the command prompt, type cmd in the embedded search bar and press Enter. The Command Prompt window will be launched.
- You will need to change directories to be inside the
md5deep-4.3folder. Type cd C:usersyour account namedesktopmd5deep-4.3 and press Enter. You will be redirected to the folder, as shown in Figure 22.11.
FIGURE 22.11 The Md5deep Folder
- Now that the command prompt is located in the folder, you can view the contents by typing dir and pressing Enter. The contents of the folder will be displayed, as shown in Figure 22.12.

FIGURE 22.12 Md5deep Contents in the Command Prompt
Here you can see the same contents as within the Windows Explorer. Locate the hash algorithms you will be using, along with the HashTest.txt file. Understand that to use these command-line tools you will need to type the entire filename with its associated extension.
- To create your first hash, type md5deep.exe HashTest.txt. This tells the computer to use MD5 to create a hash of
HashTest.txt. Press Enter to create the hash, as shown in Figure 22.13.
FIGURE 22.13 MD5 Hash Output
You should see a string of characters, as illustrated in the figure. This represents your file with the MD5 hash algorithm applied to it.
FIGURE 22.14 64-bit MD5 Hash output
- Now type sha1deep.exe HashTest.txt and press Enter, as shown in Figure 22.15. The string of numbers and letters represents your file with the Sha-1 hash algorithm applied to it.
FIGURE 22.15 Sha-1 Hash Output
Notice that the hash output has more characters than the MD5 hash. The MD5 hash output is 128 bits, while the Sha-1 hash output is 160 bits. SHA (secure hash algorithm) is considered more secure.
- Finally, type whirlpooldeep.exe HashTest.txt and press Enter. This will use the Whirlpool hash algorithm on the text file, as shown in Figure 22.16.
FIGURE 22.16 Whirlpool Hash Output
The Whirlpool hash algorithm employs an astounding 512-bit digest to the file, much larger than the previous two hashing algorithms.
Tampering with a File
The purpose of the hash is verify file integrity. Now let’s tamper with the file in a minimal way so you can later attempt to discern the subtle difference.
- Leave the Command Prompt window open and return to the Windows Explorer window with the
md5deep-4.3folder open. - Double-click the
HashTest.txtfile to open it. Notepad will launch. - Delete the exclamation point and insert a period. The contents should now read, This is my Hash Test., as shown in Figure 22.17.

FIGURE 22.17 New Contents of HashTest File
- Click File and select Save to save the file. Exit Notepad by clicking on the red X in the top-right corner of the window.
- Exit the Windows Explorer window by clicking on the red X in the top-right corner of the window.
Comparing Hash Values
You might think with such a subtle change to the contents of the file that a hash output might be similar. You will now discover the importance of hash output by comparing the before and after of the file hashes.
- Return to the command prompt. You should be able to view the three previous hashes.
- At the prompt, type md5deep.exe HashTest.txt. This will create a hash of the newly tampered with HashTest file. Press Enter.
Is there a difference between your new hash and your previous hash?
As illustrated in Figure 22.18, comparing this hash to the first hash reveals a completely different set of characters. This verifies the file’s integrity.

FIGURE 22.18 Comparing the MD5 Hash Outputs
- Type sha1deep.exe HashTest.txt and press Enter. The resulting hash will be displayed and should be different from the earlier hash, as illustrated in Figure 22.19.
FIGURE 22.19 Comparing the Sha-1 Hash Outputs
When you compare your Sha-1 outputs, is there a difference?
- Finally, type whirlpooldeep.exe HashTest.txt and press Enter. As shown in Figure 22.20, there should be a difference between the previous hash and the new hash.
FIGURE 22.20 Comparing the Whirlpool Hash Outputs
Is there a difference between your hashes?
- Exit the command prompt by typing exit and pressing Enter.
- Shut down the computer.
It is important to remember that file hashing only verifies integrity. It does not provide confidentiality, availability, authenticity, or nonrepudiation. Therefore, it is only one part in the security scheme.
Lab Questions
- What is the purpose of a file hashing?
- Hashing provides confidentiality. True or False?
- Does a hash change only a little if the file is changed only a little?
- Of the three hash algorithms used, which has the longest digest?
Lab Answers
- The purpose of a hash is to be able to verify file integrity.
- False.
- No, it is completely changed even with a small change to the data in the file.
- The Whirlpool hash.