
The next family of Python types we will be exploring are those whose items are ordered sequentially and accessible via index offsets into its set of elements. This group, known as sequences, includes the following types: strings (regular and unicode), lists, and tuples.
We call these sequences because they are made up of sequences of “items” making up the entire data structure. For example, a string consists of a sequence of characters (even though Python does not have an explicit character type), so the first character of a string “Hello” is ‘H’, the second character is ‘e’, and so on. Likewise, lists and tuples are sequences of various Python objects.
We will first introduce all operators and built-in functions (BIFs) that apply to all sequences, then cover each type individually. For each sequence type, we will detail the following:
• Introduction
• Operators
• Built-in functions
• Built-in methods (if applicable)
• Special features (if applicable)
• Related modules (if applicable)
We will conclude this chapter with a reference chart that summarizes all of the operators and functions applicable to all sequences. Let us begin by taking a high-level overview.
Sequence types all share the same access model: ordered set with sequentially indexed offsets to get to each element. Multiple elements may be selected by using the slice operators, which we will explore in this chapter. The numbering scheme used starts from zero (0) and ends with one less than the length of the sequence—the reason for this is because we began at 0. Figure 6-1 illustrates how sequence items are stored.

The standard type operators (see Section 4.5) generally work with all sequence types. Of course, one must comparisons with a grain of salt when dealing with objects of mixed types, but the remaining operations will work as advertised.
A list of all the operators applicable to all sequence types is given in Table 6.1. The operators appear in hierarchical order from highest to lowest with the levels alternating between shaded and not.

Membership test operators are used to determine whether an element is in or is a member of a sequence. For strings, this test is whether a character is in a string, and for lists and tuples, it is whether an object is an element of those sequences. The in and not in operators are Boolean in nature; they return True if the membership is confirmed and False otherwise.
The syntax for using the membership operators is as follows:
obj [not] in sequence
This operation allows us to take one sequence and join it with another sequence of the same type. The syntax for using the concatenation operator is as follows:
sequence1 + sequence2
The resulting expression is a new sequence that contains the combined contents of sequences sequence1 and sequence2. Note, however, that although this appears to be the simplest way conceptually to merge the contents of two sequences together, it is not the fastest or most efficient.
For strings, it is less memory-intensive to hold all of the substrings in a list or iterable and use one final join() string method call to merge them together. Similarly for lists, it is recommend that readers use the extend() list method instead of concatenating two or more lists together. Concatenation comes in handy when you need to merge two sequences together on the fly and cannot rely on mutable object built-in methods that do not have a return value (or more accurately, a return value of None). There is an example of this case in the section below on slicing.
The repetition operator is useful when consecutive copies of sequence elements are desired. The syntax for using the repetition operator is as follows:
sequence * copies_int
The number of copies, copies_int, must be an integer (prior to 1.6, long integers were not allowed). As with the concatenation operator, the object returned is newly allocated to hold the contents of the multiply replicated objects.
To put it simply: sequences are data structures that hold objects in an ordered manner. You can get access to individual elements with an index and pair of brackets, or a consecutive group of elements with the brackets and colons giving the indices of the elements you want starting from one index and going up to but not including the ending index.
Now we are going to explain exactly what we just said in full detail. Sequences are structured data types whose elements are placed sequentially in an ordered manner. This format allows for individual element access by index offset or by an index range of indices to select groups of sequential elements in a sequence. This type of access is called slicing, and the slicing operators allow us to perform such access.
The syntax for accessing an individual element is:
sequence[index]
sequence is the name of the sequence and index is the offset into the sequence where the desired element is located. Index values can be positive, ranging from 0 to the maximum index (which is length of the sequence less one). Using the len() function (which we will formally introduce in the next section), this gives an index with the range 0 <= index <= len(sequence)-1.
Alternatively, negative indexes can be used, ranging from -1 to the negative length of the sequence, -len(sequence), i.e., -len(sequence) <= index <= -1. The difference between the positive and negative indexes is that positive indexes start from the beginning of the sequences and negative indexes work backward from the end.
Attempting to retrieve a sequence element with an index outside of the length of the sequence results in an IndexError exception:

Because Python is object oriented, you can also directly access an element of a sequence (without first having to assign it to a variable) like this:
![]()
This comes in handy especially in cases where you have called a function and know that you are going to get back a sequence as a return value but are only interested in one or more elements and not the whole thing. So how do we select multiple elements?
Accessing a group of elements is similar to accessing just a single item. Starting and ending indexes may be given, separated by a colon ( : ). The syntax for accessing a group of elements is:
sequence[starting_index:ending_index]
Using this syntax, we can obtain a “slice” of elements in sequence from the starting_index up to but not including the element at the ending_index index. Both starting_index and ending_index are optional, and if not provided, or if None is used as an index, the slice will go from the beginning of the sequence or until the end of the sequence, respectively.
In Figures 6-2 to 6-6, we take an entire sequence (of soccer players) of length 5, and explore how to take various slices of such a sequence.





The final slice syntax for sequences, known as extended slicing, involves a third index known as a stride. You can think of a stride index like a “step” value as the third element of a call to the range() built-in function or a for loop in languages like C/C++, Perl, PHP, and Java.
Extended slice syntax with stride indices has actually been around for a long time, built into the Python virtual machine but accessible only via extensions. This syntax was even made available in Jython (and its predecessor JPython) long before version 2.3 of the C interpreter gave everyone else access to it. Here are a few examples:

The slice index syntax is more flexible than the single element index. The starting and ending indices can exceed the length of the string. In other words, the starting index can start off well left of 0, that is, an index of -100 does not exist, but does not produce an error. Similarly, an index of 100 as an ending index of a sequence with fewer than 100 elements is also okay, as shown here:
![]()
Here is another problem: we want to take a string and display it in a loop. Each time through we would like to chop off the last character. Here is a snippet of code that does what we want:

However, what if we wanted to display the entire string at the first iteration? Is there a way we can do it without adding an additional print s before our loop? What if we wanted to programmatically specify no index, meaning all the way to the end? There is no real way to do that with an index as we are using negative indices in our example, and -1 is the “smallest” index. We cannot use 0, as that would be interpreted as the first element and would not display anything:
>>> s[:0]
''
Our solution is another tip: using None as an index has the same effect as a missing index, so you can get the same functionality programmatically, i.e., when you are using a variable to index through a sequence but also want to be able to access the first or last elements:

So it works the way we want now. Before parting ways for now, we wanted to point out that this is one of the places where we could have created a list [None] and used the extend() method to add the range() output, or create a list with the range() elements and inserted None at the beginning, but we are (horribly) trying to save several lines of code here. Mutable object built-in methods like extend() do not have a return value, so we could not have used:

The reason for the error is that [None].extend(...) returns None, which is neither a sequence nor an iterable. The only way we could do it without adding extra lines of code is with the list concatenation above.
Before we look at sequence type BIFs, we wanted to let you know that you will be seeing the term iterable mixed in with sequence. The reason for this is that iterables are more generalized and include data types like sequences, iterators, or any object supporting iteration.
Because Python’s for loops can iterate over any iterable type, it will seem like iterating over a pure sequence, even if it isn’t one. Also, many of Python’s BIFs that previously only accepted sequences as arguments have been upgraded to take iterators and iterator-like objects as well, hence the basket term, “iterable.”
We will discuss in detail in this chapter BIFs that have a strong tie to sequences. We will discuss BIFs that apply more specifically to iteration in loops in Chapter 8, “Conditionals and Loops.”
The list(), str(), and tuple() BIFs are used to convert from any sequence type to another. You can also think of them as casting if coming over from another language, but there really is no conversion or casting going on. These “converters” are really factory functions (introduced in Chapter 4) that take an object and (shallow) copy its contents into a newly generated object of the desired type. Table 6.2 lists the sequence type conversion functions.

Again, we use the term “convert” loosely. But why doesn’t Python just convert our argument object into another type? Recall from Chapter 4 that once Python objects are created, we cannot change their identity or their type. If you pass a list to list(), a (shallow) copy of the list’s objects will be made and inserted into the new list. This is also similar to how the concatenation and repetition operators that we have seen previously do their work.
A shallow copy is where only references are copied...no new objects are made! If you also want copies of the objects (including recursively if you have container objects in containers), you will need to learn about deep copies. More information on shallow and deep copies is available toward the end of this chapter.
The str() function is most popular when converting an object into something printable and works with other types of objects, not just sequences. The same thing applies for the Unicode version of str(), unicode(). The list() and tuple() functions are useful to convert from one to another (lists to tuples and vice versa). However, although those functions are applicable for strings as well since strings are sequences, using tuple() and list() to turn strings into tuples or lists (of characters) is not common practice.
Python provides the following operational BIFs for sequence types (see Table 6.3 below). Note that len(), reversed(), and sum() can only accept sequences while the rest can take iterables. Alternatively, max() and min() can also take a list of arguments

We will provide some examples of using these functions with each sequence type in their respective sections.
Strings are among the most popular types in Python. We can create them simply by enclosing characters in quotes. Python treats single quotes the same as double quotes. This contrasts with most other shell-type scripting languages, which use single quotes for literal strings and double quotes to allow escaping of characters. Python uses the “raw string” operator to create literal quotes, so no differentiation is necessary. Other languages such as C use single quotes for characters and double quotes for strings. Python does not have a character type; this is probably another reason why single and double quotes are treated the same.
Nearly every Python application uses strings in one form or another. Strings are a literal or scalar type, meaning they are treated by the interpreter as a singular value and are not containers that hold other Python objects. Strings are immutable, meaning that changing an element of a string requires creating a new string. Strings are made up of individual characters, and such elements of strings may be accessed sequentially via slicing.
With the unification of types and classes in 2.2, there are now actually three types of strings in Python. Both regular string (str) and Unicode string (unicode) types are actually subclassed from an abstract class called basestring. This class cannot be instantiated, and if you try to use the factory function to make one, you get this:

Creating strings is as simple as using a scalar value or having the str() factory function make one and assigning it to a variable:

Python does not support a character type; these are treated as strings of length one, thus also considered a substring. To access substrings, use the square brackets for slicing along with the index or indices to obtain your substring:

You can “update” an existing string by (re)assigning a variable to another string. The new value can be related to its previous value or to a completely different string altogether.

Like numbers, strings are not mutable, so you cannot change an existing string without creating a new one from scratch. That means that you cannot update individual characters or substrings in a string. However, as you can see above, there is nothing wrong with piecing together parts of your old string into a new string.
To repeat what we just said, strings are immutable, so you cannot remove individual characters from an existing string. What you can do, however, is to empty the string, or to put together another string that drops the pieces you were not interested in.
Let us say you want to remove one letter from “Hello World!”...the (lowercase) letter “l,” for example:

To clear or remove a string, you assign an empty string or use the del statement, respectively:

In most applications, strings do not need to be explicitly deleted. Rather, the code defining the string eventually terminates, and the string is eventually deallocated.
In Chapter 4, we introduced a number of operators that apply to most objects, including the standard types. We will take a look at how some of those apply to strings. For a brief introduction, here are a few examples using strings:

When using the value comparison operators, strings are compared lexicographically (ASCII value order).
Earlier in Section 6.1.1, we examined how we can access individual or a group of elements from a sequence. We will apply that knowledge to strings in this section. In particular, we will look at:
For the following examples, we use the single string ‘abcd’. Provided in the figure is a list of positive and negative indexes that indicate the position in which each character is located within the string itself.

Using the length operator, we can confirm that its length is 4:
![]()
When counting forward, indexes start at 0 to the left and end at one less than the length of the string (because we started from zero). In our example, the final index of our string is:
![]()
We can access any substring within this range. The slice operator with a single argument will give us a single character, and the slice operator with a range, i.e., using a colon ( : ), will give us multiple consecutive characters. Again, for any ranges [start:end], we will get all characters starting at offset start up to, but not including, the character at end. In other words, for all characters x in the range [start:end], start <= x < end.

Any index outside our valid index range (in our example, 0 to 3) results in an error. Above, our access of aString[2:4] was valid because that returns characters at indexes 2 and 3, i.e., ‘c’ and ‘d’, but a direct access to the character at index 4 was invalid.
When counting backward, we start at index -1 and move toward the beginning of the string, ending at negative value of the length of the string. The final index (the first character) is located at:

When either a starting or an ending index is missing, they default to the beginning or end of the string, respectively.

Notice how the omission of both indices gives us a copy of the entire string.
The membership question asks whether a (sub)string appears in a(nother) string. True is returned if that substring appears in the string and False otherwise. Note that the membership operation is not used to determine where substring is within a string. Such functionality can be accomplished by using the string methods or string module functions find() or index() (and their brethren rfind() and rindex()).
Below are a few more examples of strings and the membership operators. Note that prior to Python 2.3, the in (and not in) operators for strings only allowed a single character check, such as the second example below (is ‘n’ a substring of ‘abcd’). In 2.3, this was opened up to all strings, not just characters.

In Example 6.1, we will be using the following predefined strings found in the string module:

Example 6.1 is a small script called idcheck.py which checks for valid Python identifiers. As we now know, Python identifiers must start with an alphabetic character. Any succeeding characters may be alphanumeric. The
Example 6.1. ID Check (idcheck.py)
Tests for identifier validity. First symbol must be alphabetic and remaining symbols must be alphanumeric. This tester program only checks identifiers that are at least two characters in length.

example also shows use of the string concatenation operator ( + ) introduced later in this section.
Running this script several times produces the following output:

Let us take apart the application line by line.
Import the string module and use some of the predefined strings to put together valid alphabetic and numeric identifier strings that we will test against.
Print the salutation and prompt for user input. The if statement on line 12 filters out all identifiers or candidates shorter than two characters in length.
Check to see if the first symbol is alphabetic. If it is not, display the output indicating the result and perform no further processing.
Otherwise, loop to check the other characters, starting from the second symbol to the end of the string.
Check to see if each remaining symbol is alphanumeric. Note how we use the concatenation operator (see below) to create the set of valid characters. As soon as we find an invalid character, display the result and perform no further processing by exiting the loop with break.
Core Tip: Performance
In general, repeat performances of operations or functions as arguments in a loop are unproductive as far as performance is concerned.
![]()
The loop above wastes valuable time recalculating the length of string myString. This function call occurs for each loop iteration. If we simply save this value once, we can rewrite our loop so that it is more productive.
![]()
The same idea applies for this loop above in Example 6.1.
![]()
The for loop beginning on line 18 contains an if statement that concatenates a pair of strings. These strings do not change throughout the course of the application, yet this calculation must be performed for each loop iteration. If we save the new string first, we can then reference that string rather than make the same calculations over and over again:

It may be somewhat premature to show you a for-else loop statement, but we are going to give it a shot anyway. (For a full treatment, see Chapter 8). The else statement for a for loop is optional and, if provided, will execute if the loop finished in completion without being “broken” out of by break. In our application, if all remaining symbols check out okay, then we have a valid identifier name. The result is displayed to indicate as such, completing execution.
This application is not without its flaws, however. One problem is that the identifiers tested must have length greater than 1. Our application “as is” is not reflective of the true range of Python identifiers, which may be of length 1. Another problem with our application is that it does not take into consideration Python keywords, which are reserved names that cannot be used for identifiers. We leave these two tasks as exercises for the reader (see Exercise 6-2).
We can use the concatenation operator to create new strings from existing ones. We have already seen the concatenation operator in action above in Example 6-1. Here are a few more examples:

The last example illustrates using the concatenation operator to put together a pair of slices from string s, the “Spa” from “Spanish” and the “M” from “Made.” The extracted slices are concatenated and then sent to the string.upper() function to convert the new string to all uppercase letters. String methods were added to Python back in 1.6 so such examples can be replaced with a single call to the final string method (see example below). There is really no longer a need to import the string module unless you are trying to access some of the older string constants which that module defines.
Note: Although easier to learn for beginners, we recommend not using string concatenation when performance counts. The reason is that for every string that is part of a concatenation, Python has to allocate new memory for all strings involved, including the result. Instead, we recommend you either use the string format operator ( % ), as in the examples below, or put all of the substrings in a list, and using one join() call to put them all together:

The above syntax using the addition operator performs the string concatenation at runtime, and its use is the norm. There is a less frequently used syntax that is more of a programmer convenience feature. Python’s syntax allows you to create a single string from multiple string literals placed adjacent to each other in the body of your source code:
![]()
It is a convenient way to split up long strings without unnecessary backslash escapes. As you can see from the above, you can mix quotation types on the same line. Another good thing about this feature is that you can add comments too, like this example:

As you can imagine, here is what urlopen() really gets as input:
![]()

Python features a string format operator. This operator is unique to strings and makes up for the lack of having functions from C’s printf() family. In fact, it even uses the same symbol, the percent sign (%), and supports all the printf() formatting codes.
The syntax for using the format operator is as follows:
format_string % (arguments_to_convert)
The format_string on the left-hand side is what you would typically find as the first argument to printf(): the format string with any of the embedded % codes. The set of valid codes is given in Table 6.4. The arguments_to_convert parameter matches the remaining arguments you would send to printf(), namely the set of variables to convert and display.

Python supports two formats for the input arguments. The first is a tuple (introduced in Section 2.8, formally in 6.15), which is basically the set of arguments to convert, just like for C’s printf(). The second format that Python supports is a dictionary (Chapter 7). A dictionary is basically a set of hashed key-value pairs. The keys are requested in the format_string, and the corresponding values are provided when the string is formatted.
Converted strings can either be used in conjunction with the print statement to display out to the user or saved into a new string for future processing or displaying to a graphical user interface.
Other supported symbols and functionality are listed in Table 6.5.

As with C’s printf(), the asterisk symbol ( * ) may be used to dynamically indicate the width and precision via a value in argument tuple. Before we get to our examples, one more word of caution: long integers are more than likely too large for conversion to standard integers, so we recommend using exponential notation to get them to fit.
Here are some examples using the string format operator:

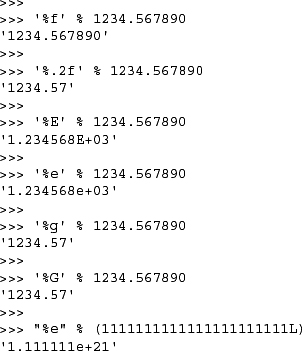

The previous examples all use tuple arguments for conversion. Below, we show how to use a dictionary argument for the format operator:
![]()
The string format operator is not only a cool, easy-to-use, and familiar feature, but a great and useful debugging tool as well. Practically all Python objects have a string presentation (either evaluatable from repr() or ‘‘, or printable from str()). The print statement automatically invokes the str() function for an object. This gets even better. When you are defining your own objects, there are hooks for you to create string representations of your object such that repr() and str() (and ‘‘ and print) return an appropriate string as output. And if worse comes to worst and neither repr() or str() is able to display an object, the Pythonic default is at least to give you something of the format:
<... something that is useful ...>.
The string format operator has been a mainstay of Python and will continue to be so. One of its drawbacks, however, is that it is not as intuitive to the new Python programmer not coming from a C/C++ background. Even for current developers using the dictionary form can accidentally leave off the type format symbol, i.e., %(lang) vs. the more correct %(lang)s. In addition to remembering to put in the correct formatting directive, the programmer must also know the type, i.e., is it a string, an integer, etc.
The justification of the new string templates is to do away with having to remember such details and use string substitution much like those in current shell-type scripting languages, the dollar sign ( $ ).
The string module is temporarily resurrected from the dead as the new Template class has been added to it. Template objects have two methods, substitute() and safe_substitute(). The former is more strict, throwing KeyError exceptions for missing keys while the latter will keep the substitution string intact when there is a missing key:

The new string templates were added to Python in version 2.4. More information about them can be found in the Python Library Reference Manual and PEP 292.
The purpose of raw strings, introduced back in version 1.5, is to counteract the behavior of the special escape characters that occur in strings (see the subsection below on what some of these characters are). In raw strings, all characters are taken verbatim with no translation to special or non-printed characters.
This feature makes raw strings absolutely convenient when such behavior is desired, such as when composing regular expressions (see the re module documentation). Regular expressions (REs) are strings that define advanced search patterns for strings and usually consist of special symbols to indicate characters, grouping and matching information, variable names, and character classes. The syntax for REs contains enough symbols already, but when you have to insert additional symbols to make special characters act like normal characters, you end up with a virtual “alphanumersymbolic” soup! Raw strings lend a helping hand by not requiring all the normal symbols needed when composing RE patterns.
The syntax for raw strings is exactly the same as for normal strings with the exception of the raw string operator, the letter “r,” which precedes the quotation marks. The “r” can be lowercase (r) or uppercase (R) and must be placed immediately preceding the first quote mark.
In the first of our three examples, we really want a backslash followed by an ‘n’ as opposed to a NEWLINE character:

Next, we cannot seem to open our README file. Why not? Because the and
are taken as special symbols which really are not part of our filename, but are four individual characters that are part of our file pathname.

Finally, we are (ironically) looking for a raw pair of characters
and not NEWLINE. In order to find it, we are attempting to use a simple regular expression that looks for backslash-character pairs that are normally single special whitespace characters:

The Unicode string operator, uppercase (U) and lowercase (u), introduced with Unicode string support in Python 1.6, takes standard strings or strings with Unicode characters in them and converts them to a full Unicode string object. More details on Unicode strings are available in Section 6.8. In addition, Unicode support is available via string methods (Section 6.6) and the regular expression engine. Here are some examples:

The Unicode operator can also accept raw Unicode strings if used in conjunction with the raw string operator discussed in the previous section. The Unicode operator must precede the raw string operator.
ur'Hello World!'



Although more useful with other sequence types, the max() and min() built-in functions do operate as advertised, returning the greatest and least characters (lexicographic order), respectively. Here are a few more examples:



The built-in raw_input() function prompts the user with a given string and accepts and returns a user-input string. Here is an example using raw_input():

Strings in Python do not have a terminating NUL character like C strings. We added in the extra call to len() to show you that what you see is what you get.
Both str() and unicode() are factory functions, meaning that they produce new objects of their type respectively. They will take any object and create a printable or Unicode string representation of the argument object. And, along with basestring, they can also be used as arguments along with objects in isinstance() calls to verify type:
chr() takes a single integer argument in range(256) (e.g., between 0 and 255) and returns the corresponding character. unichr() does the same thing but for Unicode characters. The range for unichr(), added in Python 2.0, is dependent on how your Python was compiled. If it was configured for UCS2 Unicode, then a valid value falls in range(65536) or 0x0000-0xFFFF; for UCS4, the value should be in range(1114112) or 0x000000-0x110000. If a value does not fall within the allowable range(s), a ValueError exception will be raised.
ord() is the inverse of chr() (for 8-bit ASCII strings) and unichr() (for Unicode objects)—it takes a single character (string of length 1) and returns the corresponding character with that ASCII code or Unicode code point, respectively. If the given Unicode character exceeds the size specified by your Python configuration, a TypeError exception will be thrown.

String methods were added to Python in the 1.6 to 2.0 timeframe—they also were added to Jython. These methods replace most of the functionality in the string module as well as to add new functionality. Table 6.6 shows all the current methods for strings. All string methods should fully support Unicode strings. Some are applicable only to Unicode strings.






Some examples of using string methods:

The most complex example shown above is the one with split() and join(). We first call split() on our string, which, without an argument, will break apart our string using spaces as the delimiter. We then take this list of words and call join() to merge our words again, but with a new delimiter, the colon. Notice that we used the split() method for our string to turn it into a list, and then, we used the join() method for ‘:’ to merge together the contents of the list.
Like most other high-level or scripting languages, a backslash paired with another single character indicates the presence of a “special” character, usually a nonprintable character, and that this pair of characters will be substituted by the special character. These are the special characters we discussed above that will not be interpreted if the raw string operator precedes a string containing these characters.
In addition to the well-known characters such as NEWLINE (
) and (horizontal) tab ( ), specific characters via their ASCII values may be used as well: OOO or xXX where OOO and XX are their respective octal and hexadecimal ASCII values. Here are the base 10, 8, and 16 representations of 0, 65, and 255:

Special characters, including the backslash-escaped ones, can be stored in Python strings just like regular characters.
Another way that strings in Python are different from those in C is that Python strings are not terminated by the NUL (�00) character (ASCII value 0). NUL characters are just like any of the other special backslash-escaped characters. In fact, not only can NUL characters appear in Python strings, but there can be any number of them in a string, not to mention that they can occur anywhere within the string. They are no more special than any of the other control characters. Table 6.7 represents a summary of the escape characters supported by most versions of Python.
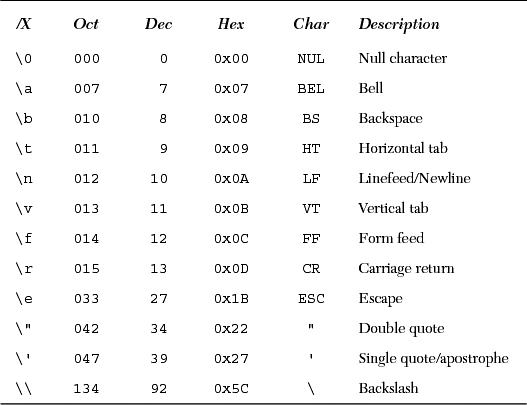
As mentioned before, explicit ASCII octal or hexadecimal values can be given, as well as escaping a NEWLINE to continue a statement to the next line. All valid ASCII character values are between 0 and 255 (octal 0177, hexadecimal 0xFF).
One use of control characters in strings is to serve as delimiters. In database or Internet/Web processing, it is more than likely that most printable characters are allowed as data items, meaning that they would not make good delimiters.
It becomes difficult to ascertain whether or not a character is a delimiter or a data item, and by using a printable character such as a colon ( : ) as a delimiter, you are limiting the number of allowed characters in your data, which may not be desirable.
One popular solution is to employ seldomly used, nonprintable ASCII values as delimiters. These make the perfect delimiters, freeing up the colon and the other printable characters for more important uses.
Although strings can be represented by single or double quote delimitation, it is often difficult to manipulate strings containing special or nonprintable characters, especially the NEWLINE character. Python’s triple quotes comes to the rescue by allowing strings to span multiple lines, including verbatim NEWLINEs, tabs, and any other special characters.
The syntax for triple quotes consists of three consecutive single or double quotes (used in pairs, naturally):

Triple quotes lets the developer avoid playing quote and escape character games, all the while bringing at least a small chunk of text closer to WYSIWIG (what you see is what you get) format.
The most powerful use cases are when you have a large block of HTML or SQL that would be completely inconvenient to use by concanentation or wrapped with backslash escapes:

In Section 4.8.2, we’ll discussed how strings are immutable data types, meaning that their values cannot be changed or modified. This means that if you do want to update a string, either by taking a substring, concatenating another string on the end, or concatenating the string in question to the end of another string, etc., a new string object must be created for it.
This sounds more complicated than it really is. Since Python manages memory for you, you won’t really notice when this occurs. Any time you modify a string or perform any operation that is contrary to immutability, Python will allocate a new string for you. In the following example, Python allocates space for the strings, ‘abc’ and ‘def’. But when performing the addition operation to create the string ‘abcdef’, new space is allocated automatically for the new string.
>>> 'abc' + 'def'
'abcdef'
Assigning values to variables is no different:
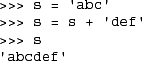
In the above example, it looks like we assigned the string ‘abc’ to string, then appended the string ‘def’ to string. To the naked eye, strings look mutable. What you cannot see, however, is the fact that a new string was created when the operation “s + ‘def’” was performed, and that the new object was then assigned back to s. The old string of ‘abc’was deallocated.
Once again, we can use the id() built-in function to help show us exactly what happened. If you recall, id() returns the “identity” of an object. This value is as close to a “memory address” as we can get in Python.

Note how the identities are different for the string before and after the update. Another test of mutability is to try to modify individual characters or substrings of a string. We will now show how any update of a single character or a slice is not allowed:

Both operations result in an error. In order to perform the actions that we want, we will have to create new strings using substrings of the existing string, then assign those new strings back to string:

So for immutable objects like strings, we make the observation that only valid expressions on the left-hand side of an assignment (to the left of the equals sign [ = ]) must be the variable representation of an entire object such as a string, not single characters or substrings. There is no such restriction for the expression on the right-hand side.
Unicode string support, introduced to Python in version 1.6, is used to convert between multiple double-byte character formats and encodings, and includes as much functionality as possible to manage these strings. With the addition of string methods (see Section 6.6), Python strings and regular expressions are fully featured to handle a wide variety of applications requiring Unicode string storage, access, and manipulation. We will do our best here to give an overview of Unicode support in Python. But first, let us take a look at some basic terminology and then ask ourselves, just what is Unicode?

Unicode is the miracle and the mystery that makes it possible for computers to support virtually any language on the planet. Before Unicode, there was ASCII, and ASCII was simple. Every English character was stored in the computer as a seven bit number between 32 and 126. When a user entered the letter A into a text file, the computer would write the letter A to disk as the number 65. Then when the computer opened that file it would translate that number 65 back into an A when it displayed the file contents on the screen.
ASCII files were compact and easy to read. A program could just read in each byte from a file and convert the numeric value of the byte into the corresponding letter. But ASCII only had enough numbers to represent 95 printable characters. Later software manufacturers extended ASCII to 8 bits, which provided an additional 128 characters, but 223 characters still fell far short of the thousands required to support all non-European languages.
Unicode overcomes the limitations of ASCII by using one or more bytes to represent each character. Using this system, Unicode can currently represent over 90,000 characters.
In the early days, Python could only handle 8-bit ASCII. Strings were simple data types. To manipulate a string, a user had to create a string and then pass it to one of the functions in the string module. Then in 2000, we saw the releases of Python 1.6 (and 2.0), the first time Unicode was supported in Python.
In order to make Unicode strings and ASCII strings look as similar as possible, Python strings were changed from being simple data types to real objects. ASCII strings became StringTypes and Unicode strings became UnicodeTypes. Both behave similarly. Due to many issues users are having with regards to moving between Unicode and ASCII strings, Python 3.0 will adopt a new standard where all strings are Unicode. A new bytes type will be added for those needing to manipulate binary data and encoded text.
Handling Unicode strings in Python is not that different from handling ordinary ASCII strings. Python calls hard-coded strings string literals. By default all string literals are treated as ASCII. This can be changed by adding the prefix u to a string literal. This tells Python that the text inside of the string should be treated as Unicode.
![]()
The built-in functions str() and chr() were not updated to handle Unicode. They only work with regular ASCII strings. If a Unicode string is passed to str() it will silently convert the Unicode string to ASCII. If the Unicode string contains any characters that are not supported by ASCII, str() will raise an exception. Likewise, chr() can only work with numbers 0 to 255. If you pass it a numeric value (of a Unicode character, for example) outside of that range, it will raise an exception.
New BIFs unicode() and unichr() were added that act just like str() and chr() but work with Unicode strings. The function unicode() can convert any Python data type to a Unicode string and any object to a Unicode representation if that object has an __unicode__() method. For a review of these functions, see Sections 6.1.3 and 6.5.3.
The acronym codec stands for COder/DECoder. It is a specification for encoding text as byte values and decoding those byte values into text. Unlike ASCII, which used only one byte to encode a character into a number, Unicode uses multiple bytes. Plus Unicode supports several different ways of encoding characters into bytes. Four of the best-known encodings that these codecs can convert are: ASCII, ISO 8859-1/Latin-1, UTF-8, and UTF-16.
The most popular is UTF-8, which uses one byte to encode all the characters in ASCII. This makes it easier for a programmer who has to deal with both ASCII and Unicode text since the numeric values of the ASCII characters are identical in Unicode.
For other characters, UTF-8 may use one or two bytes to represent a letter, three (mainly) for CJK/East Asian characters, and four for some rare, special use, or historic characters. This makes it more difficult for programmers who have to read and write the raw Unicode data since they cannot just read in a fixed number of bytes for each character. Luckily for us, Python hides all of the details of reading and writing the raw Unicode data for us, so we don’t have to worry about the complexities of reading multibyte characters in text streams. All the other codecs are much less popular than UTF-8. In fact, I would say most Python programmers will never have to deal with them, save perhaps UTF-16.
UTF-16 is probably the next most popular codec. It is simpler to read and write its raw data since it encodes every character as a single 16-bit word represented by two bytes. Because of this, the ordering of the two bytes matters. The regular UTF-16 code requires a Byte Order Mark (BOM), or you have to specifically use UTF-16-LE or UTF-16-BE to denote explicit little endian and big endian ordering.
UTF-16 is technically also variable-length like UTF-8 is, but this is uncommon usage. (People generally do not know this or simply do not even care about the rarely used code points in other planes outside the Basic Multilingual Plane (BMP). However, its format is not a superset of ASCII and makes it backward-incompatible with ASCII. Therefore, few programs implement it since most need to support legacy ASCII text.
Unicode support for multiple codecs means additional hassle for the developer. Each time you write a string to a file, you have to specify the codec (also called an “encoding”) that should be used to translate its Unicode characters to bytes. Python minimizes this hassle for us by providing a Unicode string method called encode() that reads the characters in the string and outputs the right bytes for the codec we specify.
So every time we write a Unicode string to disk we have to “encode” its characters as a series of bytes using a particular codec. Then the next time we read the bytes from that file, we have to “decode” the bytes into a series of Unicode characters that are stored in a Unicode string object.
The script below creates a Unicode string, encodes it as some bytes using the UTF-8 codec, and saves it to a file. Then it reads the bytes back in from disk and decodes them into a Unicode string. Finally, it prints the Unicode string so we can see that the program worked correctly.
The usual setup plus a doc string and some constants for the codec we are using and the name of the file we are going to store the string in.
Here we create a Unicode string literal, encode it with our codec, and write it out to disk (lines 9-13). Next, we read the data back in from the file, decode it, and display it to the screen, suppressing the print statement’s NEWLINE because we are using the one saved with the string (lines 15-19).
Example 6.2. Simple Unicode String Example (uniFile.py)
This simple script writes a Unicode string to disk and reads it back in for display. It encodes it into UTF-8 for writing to disk, which it must then decode in to display it.
When we run the program we get the following output:
$ unicode_example.py
Hello World
We also find a file called unicode.txt on the file system that contains the same string the program printed out.
$ cat unicode.txt
Hello World!
We show a similar and simple example of using Unicode with CGI in the Web Programming chapter (Chapter 20).
Examples like this make it look deceptively easy to handle Unicode in your code, and it is pretty easy, as long as you follow these simple rules:
• Always prefix your string literals with u.
• Never use str()... always use unicode() instead.
• Never use the outdated string module—it blows up when you pass it any non-ASCII characters.
• Avoid unnecessary encoding and decoding of Unicode strings in your program. Only call the encode() method right before you write your text to a file, database, or the network, and only call the decode() method when you are reading it back in.
These rules will prevent 90 percent of the bugs that can occur when handling Unicode text. The problem is that the other 10 percent of the bugs are beyond your control. The greatest strength of Python is the huge library of modules that exist for it. They allow Python programmers to write a program in ten lines of code that might require a hundred lines of code in another language. But the quality of Unicode support within these modules varies widely from module to module.
Most of the modules in the standard Python library are Unicode compliant. The biggest exception is the pickle module. Pickling only works with ASCII strings. If you pass it a Unicode string to unpickle, it will raise an exception. You have to convert your string to ASCII first. It is best to avoid using text-based pickles. Fortunately, the binary format is now the default and it is better to stick with it. This is especially true if you are storing your pickles in a database. It is much better to save them as a BLOB than to save them as a TEXT or VARCHAR field and then have your pickles get corrupted when someone changes your column type to Unicode.
If your program uses a bunch of third-party modules, then you will probably run into a number of frustrations as you try to get all of the programs to speak Unicode to each other. Unicode tends to be an all-or-nothing proposition. Each module in your system (and all systems your program interfaces with) has to use Unicode and the same Unicode codec. If any one of these systems does not speak Unicode, you may not be able to read and save strings properly.
As an example, suppose you are building a database-enabled Web application that reads and writes Unicode. In order to support Unicode you need the following pieces to all support Unicode:
• Database server (MySQL, PostgreSQL, SQL Server, etc.)
• Database adapter (MySQLdb, etc.)
• Web framework (mod_python, cgi, Zope, Plone, Django, etc.)
The database server is often the easiest part. You just have to make sure that all of your tables use the UTF-8 encoding.
The database adapter can be trickier. Some database adapters support Unicode, some do not. MySQLdb, for instance, does not default to Unicode mode. You have to use a special keyword argument use_unicode in the connect() method to get Unicode strings in the result sets of your queries.
Enabling Unicode is very simple to do in mod_python. Just set the text-encoding field to “utf-8” on the request object and mod_python handles the rest. Zope and other more complex systems may require more work.
Mistake #1: You have a large application to write under significant time pressure. Foreign language support was a requirement, but no specifics are made available by the product manager. You put off Unicode-compliance until the project is mostly complete ... it is not going to be that much effort to add Unicode support anyway, right?
Result #1: Failure to anticipate the foreign-language needs of end-users as well as integration of Unicode support with the other foreign language-oriented applications that they used. The retrofit of the entire system would be extremely tedious and time-consuming.
Mistake #2: Using the string module everywhere including calling str() and chr() in many places throughout the code.
Result #2: Convert to string methods followed by global search-and-replace of str() and chr() with unicode() and unichr(). The latter breaks all pickling. The pickling format has to be changed to binary. This in turn breaks the database schema, which needs to be completely redone.
Mistake #3: Not confirming that all auxiliary systems support Unicode fully.
Result #3: Having to patch those other systems, some of which may not be under your source control. Fixing Unicode bugs everywhere leads to code instability and the distinct possibility of introducing new bugs.
Summary: Enabling full Unicode and foreign-language compliance of your application is a project on its own. It needs to be well thought out and planned carefully. All software and systems involved must be “checked off,” including the list of Python standard library and/or third-party external modules that are to be used. You may even have to bring onboard an entire team with internationalization (or “I18N”) experience.
The Unicode factory function should operate in a manner similar to that of the Unicode string operator ( u / U ). It takes a string and returns a Unicode string.
The decode() and encode() built-in methods take a string and return an equivalent decoded/encoded string. decode() and encode() work for both regular and Unicode strings. decode() was added to Python in 2.2.
A Unicode string object is subclassed from basestring and an instance is created by using the unicode() factory function, or by placing a u or U in front of the quotes of a string. Raw strings are also supported. Prepend a ur or UR to your string literal.
The standard ord() built-in function should work the same way. It was enhanced recently to support Unicode objects. The unichr() built-in function returns a Unicode object for a character (provided it is a 32-bit value); otherwise, a ValueError exception is raised.
UnicodeError is defined in the exceptions module as a subclass of ValueError. All exceptions related to Unicode encoding/decoding should be subclasses of UnicodeError. See also the string encode() method.
Table 6.9 presents an extremely short list of the more common encodings used in Python. For a more complete listing, please see the Python Documentation. Here is an online link:
The regular expression engine is Unicode aware. See the re Core Module sidebar in Section 6.9.
For Python format strings: %s performs str(u) for Unicode objects embedded in Python strings, so the output will be u.encode(<default encoding>). If the format string is a Unicode object, all parameters are coerced to Unicode first and then put together and formatted according to the format string. Numbers are first converted to strings and then to Unicode. Here is an example:
![]()
Python is adopting Unicode as its standard string type beginning in 3.0. To help cope with this significant change, beginning with 2.6, you can “activate” Unicode strings as well as the new bytes literal type (see PEPs 358, 3112, 3137) which replaces Python’s original string type. To change to Unicode strings and add the new bytes type functionality along with its b'' notation and the new bytes() factory function, enter the following:
from __future__ import unicode_literals
Table 6.10 lists the key related modules for strings that are part of the Python standard library.

Core Module: re
Regular expressions (REs) provide advanced pattern matching scheme for strings. Using a separate syntax that describes these patterns, you can effectively use them as “filters” when passing in the text to perform the searches on. These filters allow you to extract the matched patterns as well as perform find-and-replace or divide up strings based on the patterns that you describe.
The re module, introduced in Python 1.5, obsoletes the original regex and regsub modules from earlier releases. It represented a major upgrade in terms of Python’s support for regular expressions, adopting the complete Perl syntax for REs. In Python 1.6, a completely new engine was written (SRE), which added support for Unicode strings as well as significant performance improvements. SRE replaces the old PCRE engine, which had been under the covers of the regular expression modules.
Some of the key functions in the re module include: compile()— compiles an RE expression into a reusable RE object; match()— attempts to match a pattern from the beginning of a string; search()— searches for any matching pattern in the string; and sub()— performs a search-and-replace of matches. Some of these functions return match objects with which you can access saved group matches (if any were found). All of Chapter 15 is dedicated to regular expressions.
You can think of a string as a Python data type that you can consider as an array or contiguous set of characters between any pair of Python quotation symbols, or quotes. The two most common quote symbols for Python are the single quote, a single forward apostrophe ( ’ ), and the double quotation mark ( ” ). The actual string itself consists entirely of those characters in between and not the quote marks themselves.
Having the choice between two different quotation marks is advantageous because it allows one type of quote to serve as a string delimiter while the other can be used as characters within the string without the need for special escape characters. Strings enclosed in single quotes may contain double quotes as characters and vice versa.
Strings are the only literal sequence type, a sequence of characters. However, characters are not a type, so strings are the lowest-level primitive for character storage and manipulation. Characters are simply strings of length one.
The string format operator (see Section 6.4.1) provides a flexible way to create a custom string based on variable input types. It also serves as a familiar interface to formatting data for those coming from the C/C++ world.
In Section 6.7.2, we introduced the notion of triple quotes, which are strings that can have special embedded characters like NEWLINEs and tabs. Triple-quoted strings are delimited by pairs of three single (’ ’ ’) or double (” ” ”) quotation marks.
In Section 6.4.2, we introduced raw strings and discussed how they do not interpret special characters escaped with the backslash. This makes raw strings ideal for situations where strings must be taken verbatim, for example, when describing regular expressions.
One major problem in C is running off the end of a string into memory that does not belong to you. This occurs when strings in C are not properly terminated with the NUL or ‘�’ character (ASCII value of zero). Along with managing memory for you, Python also removes this little burden or annoyance. Strings in Python do not terminate with NUL, and you do not have to worry about adding them on. Strings consist entirely of the characters that were designated and nothing more.
Like strings, lists provide sequential storage through an index offset and access to single or consecutive elements through slices. However, the comparisons usually end there. Strings consist only of characters and are immutable (cannot change individual elements), while lists are flexible container objects that hold an arbitrary number of Python objects. Creating lists is simple; adding to lists is easy, too, as we see in the following examples.
The objects that you can place in a list can include standard types and objects as well as user-defined ones. Lists can contain different types of objects and are more flexible than an array of C structs or Python arrays (available through the external array module) because arrays are restricted to containing objects of a single type. Lists can be populated, empty, sorted, and reversed. Lists can be grown and shrunk. They can be taken apart and put together with other lists. Individual or multiple items can be inserted, updated, or removed at will.
Tuples share many of the same characteristics of lists and although we have a separate section on tuples, many of the examples and list functions are applicable to tuples as well. The key difference is that tuples are immutable, i.e., read-only, so any operators or functions that allow updating lists, such as using the slice operator on the left-hand side of an assignment, will not be valid for tuples.
Creating lists is as simple as assigning a value to a variable. You handcraft a list (empty or with elements) and perform the assignment. Lists are delimited by surrounding square brackets ( [ ] ). You can also use the factory function.

Slicing works similar to strings; use the square bracket slice operator ( [ ] ) along with the index or indices.

You can update single or multiple elements of lists by giving the slice on the left-hand side of the assignment operator, and you can add to elements in a list with the append() method:

To remove a list element, you can use either the del statement if you know exactly which element(s) you are deleting or the remove() method if you do not know.

You can also use the pop() method to remove and return a specific object from a list.
Normally, removing an entire list is not something application programmers do. Rather, they tend to let it go out of scope (i.e., program termination, function call completion, etc.) and be deallocated, but if they do want to explicitly remove an entire list, they use the del statement:
del aList
In Chapter 4, we introduced a number of operators that apply to most objects, including the standard types. We will take a look at how some of those apply to lists.

When using the value comparison operators, comparing numbers and strings is straightforward, but not so much for lists, however. List comparisons are somewhat tricky, but logical. The comparison operators use the same algorithm as the cmp() built-in function. The algorithm basically works like this: the elements of both lists are compared until there is a determination of a winner. For example, in our example above, the output of ‘abc’ versus ‘xyz’ is determined immediately, with ‘abc’ < ‘xyz’, resulting in list1 < list2 and list2 >= list3. Tuple comparisons are performed in the same manner as lists.
Slicing with lists is very similar to strings, but rather than using individual characters or substrings, slices of lists pull out an object or a group of objects that are elements of the list operated on. Focusing specifically on lists, we make the following definitions:

Slicing operators obey the same rules regarding positive and negative indexes, starting and ending indexes, as well as missing indexes, which default to the beginning or to the end of a sequence.
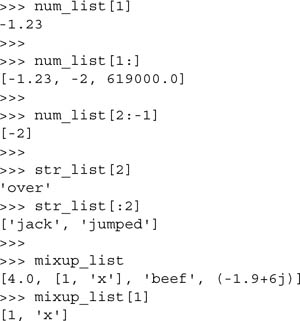
Unlike strings, an element of a list might also be a sequence, implying that you can perform all the sequence operations or execute any sequence built-in functions on that element. In the example below, we show that not only can we take a slice of a slice, but we can also change it, and even to an object of a different type. You will also notice the similarity to multidimensional arrays.

Here is another example using num_list:

Notice how, in the last example, we replaced only a single element of the list, but we replaced it with a list. So as you can tell, removing, adding, and replacing things in lists are pretty freeform. Keep in mind that in order to splice elements of a list into another list, you have to make sure that the left-hand side of the assignment operator ( = ) is a slice, not just a single element.
With lists (and tuples), we can check whether an object is a member of a list (or tuple).
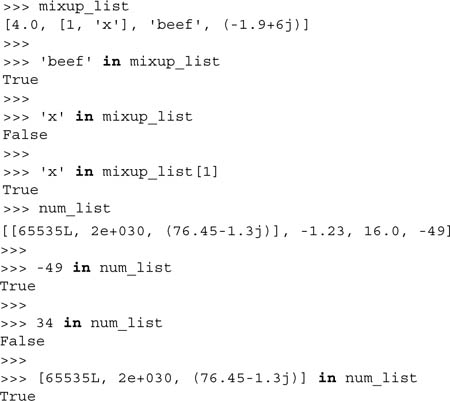
Note how ‘x’ is not a member of mixup_list. That is because ‘x’ itself is not actually a member of mixup_list. Rather, it is a member of mixup_uplist[1], which itself is a list. The membership operator is applicable in the same manner for tuples.
The concatenation operator allows us to join multiple lists together. Note in the examples below that there is a restriction of concatenating like objects. In other words, you can concatenate only objects of the same type. You cannot concatenate two different types even if both are sequences.

As we will discover in Section 6.14, starting in Python 1.5.2, you can use the extend() method in place of the concatenation operator to append the contents of a list to another. Using extend() is advantageous over concatenation because it actually appends the elements of the new list to the original, rather than creating a new list from scratch like + does. extend() is also the method used by the augmented assignment or in-place concatenation operator (+=), which debuted in Python 2.0.
We would also like to point out that the concatenation operator does not facilitate adding individual elements to a list. The upcoming example illustrates a case where attempting to add a new item to the list results in failure.

This example fails because we had different types to the left and right of the concatenation operator. A combination of (list + string) is not valid. Obviously, our intention was to add the 'new item' string to the list, but we did not go about it the proper way. Fortunately, we have a solution:
Use the append() list built-in method (we will formally introduce append() and all other built-in methods in Section 6.14):
>>> num_list.append('new item')


There are really no special list-only operators in Python. Lists can be used with most object and sequence operators. In addition, list objects have their own methods. One construct that lists do have however, are list comprehensions. These are a combination of using list square brackets and a for-loop inside, a piece of logic that dictates the contents of the list object to be created. We cover list comprehensions in Chapter 8, but we present a simple example here as well as a few more throughout the remainder of the the chapter:

In Section 4.6.1, we introduced the cmp() built-in function with examples of comparing numbers and strings. But how would cmp() work with other objects such as lists and tuples, which can contain not only numbers and strings, but other objects like lists, tuples, dictionaries, and even user-created objects?

Compares are straightforward if we are comparing two objects of the same type. For numbers and strings, the direct values are compared, which is trivial. For sequence types, comparisons are somewhat more complex, but similar in manner. Python tries its best to make a fair comparison when one cannot be made, i.e., when there is no relationship between the objects or when types do not even have compare functions, then all bets are off as far as obtaining a “logical” decision.
Before such a drastic state is arrived at, more safe-and-sane ways to determine an inequality are attempted. How does the algorithm start? As we mentioned briefly above, elements of lists are iterated over. If these elements are of the same type, the standard compare for that type is performed. As soon as an inequality is determined in an element compare, that result becomes the result of the list compare. Again, these element compares are for elements of the same type. As we explained earlier, when the objects are different, performing an accurate or true comparison becomes a risky proposition.
When we compare list1 with list2, both lists are iterated over. The first true comparison takes place between the first elements of both lists, i.e., 123 vs. 456. Since 123 < 456, list1 is deemed “smaller.”
If both values are the same, then iteration through the sequences continues until either a mismatch is found, or the end of the shorter sequence is reached. In the latter case, the sequence with more elements is deemed “greater.” That is the reason why we arrived above at list2 < list3. Tuples are compared using the same algorithm. We leave this section with a summary of the algorithm highlights:
- Compare elements of both lists.
- If elements are of the same type, perform the compare and return the result.
- If elements are different types, check to see if they are numbers.
a. If numbers, perform numeric coercion if necessary and compare.
b. If either element is a number, then the other element is “larger” (numbers are “smallest”).
c. Otherwise, types are sorted alphabetically by name.
- If we reach the end of one of the lists, the longer list is “larger.”
- If we exhaust both lists and share the same data, the result is a tie, meaning that 0 is returned.
For strings, len() gives the total length of the string, as in the number of characters. For lists (and tuples), it will not surprise you that len() returns the number of elements in the list (or tuple). Container objects found within count as a single item. Our examples below use some of the lists already defined above in previous sections.

max() and min() did not have a significant amount of usage for strings since all they did was to find the “largest” and “smallest” characters (lexicographically) in the string. For lists (and tuples), their functionality is more defined. Given a list of like objects, i.e., numbers or strings only, max() and min() could come in quite handy. Again, the quality of return values diminishes as mixed objects come into play. However, more often than not, you will be using these functions in a situation where they will provide the results you are seeking. We present a few examples using some of our earlier-defined lists.


For beginners using strings, notice how we are able to mix single and double quotes together in harmony with the contraction “they’re.” Also to those new to strings, this is a note reminding you that all string sorting is lexicographic and not alphabetic (the letter “T” comes before the letter “a” in the ASCII table.)


The list() and tuple() factory functions take iterables like other sequences and make new lists and tuples, respectively, out of the (just shallow-copied) data. Although strings are also sequence types, they are not commonly used with list() and tuple(). These built-in functions are used more often to convert from one type to the other, i.e., when you have a tuple that you need to make a list (so that you can modify its elements) and vice versa.

As we already discussed at the beginning of the chapter, neither list() nor tuple() performs true conversions (see also Section 6.1.2). In other words, the list you passed to tuple() does not turn into a tuple, and the tuple you give to list() does not really become a list. Although the data set for both (the original and new object) is the same (hence satisfying ==), neither variable points to the same object (thus failing is). Also notice that, even though their values are the same, a list cannot “equal” a tuple.
There are currently no special list-only built-in functions in Python unless you consider range() as one—its sole function is to take numeric input and generate a list that matches the criteria. range() is covered in Chapter 8. Lists can be used with most object and sequence built-in functions. In addition, list objects have their own methods.
Lists in Python have methods. We will go over methods more formally in an introduction to object-oriented programming in Chapter 13, but for now think of methods as functions or procedures that apply only to specific objects. So the methods described in this section behave just like built-in functions except that they operate only on lists. Since these functions involve the mutability (or updating) of lists, none of them is applicable for tuples.
You may recall our earlier discussion of accessing object attributes using the dotted attribute notation: object.attribute. List methods are no different, using list.method(). We use the dotted notation to access the attribute (here it is a function), then use the function operators ( ( ) ) in a functional notation to invoke the methods.
We can use dir() on a list object to get its attributes including its methods:

Table 6.11 shows all the methods currently available for lists. Some examples of using various list methods are shown later.


In the preceding example, we initiated a list with a single element, then checked the list as we either inserted elements within the list, or appended new items at the end. Let’s now determine if elements are in a list and how to find out the location of where items are in a list. We do this by using the in operator and index() method.

Oops! What happened in that last example? Well, it looks like using index() to check if items are in a list is not a good idea, because we get an error. It would be safer to check using the membership operator in (or not in) first, and then using index() to find the element’s location. We can put the last few calls to index() in a single for loop like this:

This solution helps us avoid the error we encountered above because index() is not called unless the object was found in the list. We will find out later how we can take charge if the error occurs, instead of bombing out as we did above.
We will now test drive sort() and reverse(), methods that will sort and reverse the elements of a list, respectively.

Core Note: Mutable object methods that alter the object have no return value!

One very obvious place where new Python programmers get caught is when using methods that you think should return a value. The most obvious one is sort():
![]()
The caveat about mutable object methods like sort(), extend(), and reverse() is that these will perform their operation on a list in place, meaning that the contents of the existing list will be changed, but return None! Yes, it does fly in the face of string methods that do return values:
![]()
Recall that strings are immutable—methods of immutable objects cannot modify them, so they do have to return a new object. If returning an object is a necessity for you, then we recommend that you look at the reversed() and sorted() built-in functions introduced in Python 2.4.
These work just like the list methods only they can be used in expressions because they do return objects. However, obviously the original list object is left as is, and you are getting a new object back.
Going back to the sort() method, the default sorting algorithm employed by the sort() method is a derivative of MergeSort (modestly named “timsort”), which is O(lg(n!)). We defer all other explanation to the build files where you can get all the details—source code: Objects/listobject.c and algorithm description: Objects/listsort.txt.
The extend() method will take the contents of one list and append its elements to another list:

The argument to extend() can be any iterable, starting with 2.2. Prior to that, it had to be a sequence object, and prior to 1.6, it had to be a list. With an iterable (instead of a sequence), you can do more interesting things like:

pop(), introduced in 1.5.2, will either return the last or requested item from a list and return it to the caller. We will see the pop() method in Section 6.15.1 as well as in the Exercises.
Because of their container and mutable features, lists are fairly flexible and it is not very difficult to build other kinds of data structures using lists. Two that we can come up with rather quickly are stacks and queues.
A stack is a last-in-first-out (LIFO) data structure that works similarly to a cafeteria dining plate spring-loading mechanism. Consider the plates as objects. The first object off the stack is the last one you put in. Every new object gets “stacked” on top of the newest objects. To “push” an item on a stack is the terminology used to mean you are adding onto a stack. Likewise, to remove an element, you “pop” it off the stack. Example 6.3 shows a menu-driven program that implements a simple stack used to store strings.
In addition to the Unix startup line, we take this opportunity to clear the stack (a list).

The popit() function removes an element from the stack (the more recent one). An error occurs when trying to remove an element from an empty stack. In this case, a warning is sent back to the user. When an object is popped from the stack, the user sees which element was removed. We use single backquotes or backticks ( ’ ) to symbolize the repr() command, showing the string complete with quotes, not just the contents of the string.
Although we cover dictionaries formally in the next chapter, we wanted to give you a really small example of one here, a command vector (CMDs). The contents of the dictionary are the three “action” functions defined above, and they are accessed through the letter that the user must type to execute that command. For example, to push a string onto the stack, the user must enter 'u', so 'u' is how access the pushit() from the dictionary. The chosen function is then executed on line 43.
The entire menu-driven application is controlled from the showmenu() function. Here, the user is prompted with the menu options. Once the user makes a valid choice, the proper function is called. We have not covered exceptions and try-except statement in detail yet, but basically that section of the code allows a user to type ^D (EOF, which generates an EOFError) or ^C (interrupt to quit, which generates a KeyboardInterrupt error), both of which will be processed by our script in the same manner as if the user had typed the 'q' to quit the application. This is one place where the exception-handling feature of Python comes in extremely handy. The outer while loop lets the user continue to execute commands until they quit the application while the inner one prompts the user until they enter a valid command option.
This part of the code starts up the program if invoked directly. If this script were imported as a module, only the functions and variables would have been defined, but the menu would not show up. For more information regarding line 45 and the __name__ variable, see Section 3.4.1.
Here is a sample execution of our script:




A queue is a first-in-first-out (FIFO) data structure, which works like a single-file supermarket or bank teller line. The first person in line is the first one served (and hopefully the first one to exit). New elements join by being “enqueued” at the end of the line, and elements are removed from the front by being “dequeued.” The following code shows how, with a little modification from our stack script, we can implement a simple queue using lists.


Because of the similarities of this script with the stack.py script, we will describe in detail only the lines which have changed significantly:
The key difference between the two scripts lies here. The deQ() function, rather than taking the most recent item as popit() did, takes the oldest item on the list, the first element.



Tuples are another container type extremely similar in nature to lists. The only visible difference between tuples and lists is that tuples use parentheses and lists use square brackets. Functionally, there is a more significant difference, and that is the fact that tuples are immutable. Because of this, tuples can do something that lists cannot do . . . be a dictionary key. Tuples are also the default when dealing with a group of objects.
Our usual modus operandi is to present the operators and built-in functions for the more general objects, followed by those for sequences and conclude with those applicable only for tuples, but because tuples share so many characteristics with lists, we would be duplicating much of our description from the previous section. Rather than providing much repeated information, we will differentiate tuples from lists as they apply to each set of operators and functionality, then discuss immutability and other features unique to tuples.
Creating and assigning tuples are practically identical to creating and assigning lists, with the exception of tuples with only one element—these require a trailing comma ( , ) enclosed in the tuple delimiting parentheses ( ( ) ) to prevent them from being confused with the natural grouping operation of parentheses. Do not forget the factory function!

Slicing works similarly to lists. Use the square bracket slice operator ( [ ] ) along with the index or indices.

Like numbers and strings, tuples are immutable, which means you cannot update them or change values of tuple elements. In Sections 6.2 and 6.3.2, we were able to take portions of an existing string to create a new string. The same applies for tuples.

Removing individual tuple elements is not possible. There is, of course, nothing wrong with putting together another tuple with the undesired elements discarded.
To explicitly remove an entire tuple, just use the del statement to reduce an object’s reference count. It will be deallocated when that count is zero. Keep in mind that most of the time one will just let an object go out of scope rather than using del, a rare occurrence in everyday Python programming.
del aTuple
Object and sequence operators and built-in functions act the exact same way toward tuples as they do with lists. You can still take slices of tuples, concatenate and make multiple copies of tuples, validate membership, and compare tuples.




Like lists, tuples have no operators or built-in functions for themselves. All of the list methods described in the previous section were related to a list object’s mutability, i.e., sorting, replacing, appending, etc. Since tuples are immutable, those methods are rendered superfluous, thus unimplemented.
Okay, we have been throwing around this word “immutable” in many parts of the text. Aside from its computer science definition and implications, what is the bottom line as far as applications are concerned? What are all the consequences of an immutable data type?
Of the three standard types that are immutable—numbers, strings, and tuples—tuples are the most affected. A data type that is immutable simply means that once an object is defined, its value cannot be updated, unless, of course, a completely new object is allocated. The impact on numbers and strings is not as great since they are scalar types, and when the sole value they represent is changed, that is the intended effect, and access occurs as desired. The story is different with tuples, however.
Because tuples are a container type, it is often desired to change single or multiple elements of that container. Unfortunately, this is not possible. Slice operators cannot show up on the left-hand side of an assignment. Recall this is no different for strings, and that slice access is used for read access only.
Immutability does not necessarily mean bad news. One bright spot is that if we pass in data to an API with which we are not familiar, we can be certain that our data will not be changed by the function called. Also, if we receive a tuple as a return argument from a function that we would like to manipulate, we can use the list() built-in function to turn it into a mutable list.
Although tuples are defined as immutable, this does not take away from their flexibility. Tuples are not quite as immutable as we made them out to be. What do we mean by that? Tuples have certain behavioral characteristics that make them seem not as immutable as we had first advertised.
For example, we can join strings together to form a larger string. Similarly, there is nothing wrong with putting tuples together to form a larger tuple, so concatenation works. This process does not involve changing the smaller individual tuples in any way. All we are doing is joining their elements together. Some examples are presented here:

The same concept applies for repetition. Repetition is just concatenation of multiple copies of the same elements. In addition, we mentioned in the previous section that one can turn a tuple into a mutable list with a simple function call. Our final feature may surprise you the most. You can “modify” certain tuple elements. Whoa. What does that mean?
Although tuple objects themselves are immutable, this fact does not preclude tuples from containing mutable objects that can be changed.

In the above example, although t is a tuple, we managed to “change” it by replacing an item in the first tuple element (a list). We replaced t[0][1], formerly an integer, with a list [‘abc’, ‘def’]. Although we modified only a mutable object, in some ways, we also “modified” our tuple.
Any set of multiple objects, comma-separated, written without identifying symbols, i.e., brackets for lists, parentheses for tuples, etc., defaults to tuples, as indicated in these short examples:

Any function returning multiple objects (also no enclosing symbols) is a tuple. Note that enclosing symbols change a set of multiple objects returned to a single container object. For example:

In the above examples, foo1() calls for the return of three objects, which come back as a tuple of three objects, foo2() returns a single object, a list containing three objects, and foo3() returns the same thing as foo1(). The only difference is that the tuple grouping is explicit.
Explicit grouping of parentheses for expressions or tuple creation is always recommended to avoid unpleasant side effects:

In the first example, the less than ( < ) operator took precedence over the comma delimiter intended for the tuples on each side of the less than sign. The result of the evaluation of 2 < 3 became the second element of a tuple. Properly enclosing the tuples enables the desired result.
Ever try to create a tuple with a single element? You tried it with lists, and it worked, but then you tried and tried with tuples, but you cannot seem to do it.

It probably does not help your case that the parentheses are also overloaded as the expression grouping operator. Parentheses around a single element take on that binding role rather than serving as a delimiter for tuples. The workaround is to place a trailing comma (,) after the first element to indicate that this is a tuple and not a grouping.
>>> ('xyz',)
('xyz',)
Immutable objects have values that cannot be changed. That means that they will always hash to the same value. That is the requirement for an object being a valid dictionary key. As we will find out in the next chapter, keys must be hashable objects, and tuples meet that criteria. Lists are not eligible.
Core Note: Lists versus Tuples
One of the questions in the Python FAQ asks, “Why are there separate tuple and list data types?” That question can also be rephrased as, “Do we really need two similar sequence types?” One reason why having lists and tuples is a good thing occurs in situations where having one is more advantageous than having the other.
One case in favor of an immutable data type is if you were manipulating sensitive data and were passing a mutable object to an unknown function (perhaps an API that you didn’t even write!). As the engineer developing your piece of the software, you would definitely feel a lot more secure if you knew that the function you were calling could not alter the data.
An argument for a mutable data type is where you are managing dynamic data sets. You need to be able to create them on the fly, slowly or arbitrarily adding to them, or from time to time, deleting individual elements. This is definitely a case where the data type must be mutable. The good news is that with the list() and tuple() built-in conversion functions, you can convert from one type to the other relatively painlessly.
list() and tuple() are functions that allow you to create a tuple from a list and vice versa. When you have a tuple and want a list because you need to update its objects, the list() function suddenly becomes your best buddy. When you have a list and want to pass it into a function, perhaps an API, and you do not want anyone to mess with the data, the tuple() function comes in quite useful.
Table 6.12 lists the key related modules for sequence types. This list includes the array module to which we briefly alluded earlier. These are similar to lists except for the restriction that all elements must be of the same type. The copy module (see optional Section 6.20 below) performs shallow and deep copies of objects. The operator module, in addition to the functional equivalents to numeric operators, also contains the same for sequence types. The types module is a reference of type objects representing all types that Python supports, including sequence types. The re module is for regular expressions, the StringIO modules allow you to manipulate strings like files, textwrap is useful for wrapping/filling text fields, and collections has high-performance specialized containers.

Earlier in Section 3.5, we described how object assignments are simply object references. This means that when you create an object, then assign that object to another variable, Python does not copy the object. Instead, it copies only a reference to the object.
For example, let us say that you want to create a generic profile for a young couple; call it person. Then you copy this object for both of them. In the example below, we show two ways of copying an object, one uses slices and the other a factory function. To show we have three unrelated objects, we use the id() built-in function to show you each object’s identity. (We can also use the is operator to do the same thing.)

Individual savings accounts are created for them with initial $100 deposits. The names are changed to customize each person’s object. But when the husband withdraws $50.00, his actions affected his wife’s account even though separate copies were made. (Of course, this is assuming that we want them to have separate accounts and not a single, joint account.) Why is that?

The reason is that we have only made a shallow copy. A shallow copy of an object is defined to be a newly created object of the same type as the original object whose contents are references to the elements in the original object. In other words, the copied object itself is new, but the contents are not. Shallow copies of sequence objects are the default type of copy and can be made in any number of ways: (1) taking a complete slice [:], (2) using a factory function, e.g., list(), dict(), etc., or (3) using the copy() function of the copy module.
Your next question should be: When the wife’s name is assigned, how come it did not affect the husband’s name? Shouldn’t they both have the name ‘jane’ now? The reason why it worked and we don’t have duplicate names is because of the two objects in each of their lists, the first is immutable (a string) and the second is mutable (a list). Because of this, when shallow copies are made, the string is explicitly copied and a new (string) object created while the list only has its reference copied, not its members. So changing the names is not an issue but altering any part of their banking information is. Here, let us take a look at the object IDs for the elements of each list. Note that the banking object is exactly the same and the reason why changes to one affects the other. Note how, after we change their names, that the new name strings replace the original ‘name’ string:
BEFORE:

AFTER:
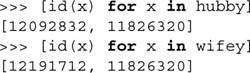
If the intention was to create a joint account for the couple, then we have a great solution, but if we want separate accounts, we need to change something. In order to obtain a full or deep copy of the object—creating a new container but containing references to completely new copies (references) of the element in the original object—we need to use the copy.deepcopy() function. Let us redo the entire example but using deep copies instead:

Now it is just the way we want it. For kickers, let us confirm that all four objects are different:
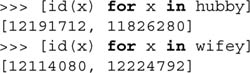
There are a few more caveats to object copying. The first is that non-container types (i.e., numbers, strings, and other “atomic” objects like code, type, and xrange objects) are not copied. Shallow copies of sequences are all done using complete slices. Finally, deep copies of tuples are not made if they contain only atomic objects. If we changed the banking information to a tuple, we would get only a shallow copy even though we asked for a deep copy:

Sequence types provide various mechanisms for ordered storage of data. Strings are a general medium for carrying data, whether it be displayed to a user, stored on a disk, transmitted across the network, or be a singular container for multiple sources of information. Lists and tuples provide container storage that allows for simple manipulation and access of multiple objects, whether they be Python data types or user-defined objects. Individual or groups of elements may be accessed as slices via sequentially ordered index offsets. Together, these data types provide flexible and easy-to-use storage tools in your Python development environment. We conclude this chapter with a summary of operators, built-in functions and methods (shaded in order of precedence) for sequence types given in Table 6.13.




6-1. Strings. Are there any string methods or functions in the string module that will help me determine if a string is part of a larger string?
6-2. String Identifiers. Modify the idcheck.py script in Example 6-1 such that it will determine the validity of identifiers of length 1 as well as be able to detect if an identifier is a keyword. For the latter part of the exercise, you may use the keyword module (specifically the keyword.kwlist list) to aid in your cause.
6-3. Sorting.
(a) Enter a list of numbers and sort the values in largest-to-smallest order.
(b) Do the same thing, but for strings and in reverse alphabetical (largest-to-smallest lexicographic) order.
6-4. Arithmetic. Update your solution to the test score exercise in the previous chapter such that the test scores are entered into a list. Your code should also be able to come up with an average score. See Exercises 2-9 and 5-3.
(a) Update your solution to Exercise 2-7 so that you display a string one character at a time forward and backward.
(b) Determine if two strings match (without using comparison operators or the cmp() built-in function) by scanning each string. Extra credit: Add case-insensitivity to your solution.
(c) Determine if a string is palindromic (the same backward as it is forward). Extra credit: Add code to suppress symbols and whitespace if you want to process anything other than strict palindromes.
(d) Take a string and append a backward copy of that string, making a palindrome.
6-6. Strings. Create the equivalent to string.strip(): Take a string and remove all leading and trailing whitespace. (Use of string.*strip() defeats the purpose of this exercise.)
6-7. Debugging. Take a look at the code we present in Example 6.5 (buggy.py).
(a) Study the code and describe what this program does. Add a comment to every place you see a comment sign ( # ). Run the program.
(b) This problem has a big bug in it. It fails on inputs of 6, 12, 20, 30, etc., not to mention any even number in general. What is wrong with this program?
(c) Fix the bug in (b).
6-8. Lists. Given an integer value, return a string with the equivalent English text of each digit. For example, an input of 89 results in “eight-nine” being returned. Extra credit: Return English text with proper usage, i.e., “eighty-nine.” For this part of the exercise, restrict values to be between 0 and 1,000.
6-9. Conversion. Create a sister function to your solution for Exercise 5-13 to take the total number of minutes and return the same time interval in hours and minutes, maximizing on the total number of hours.
6-10. Strings. Create a function that will return another string similar to the input string, but with its case inverted. For example, input of “Mr. Ed” will result in “mR. eD” as the output string.
Example 6.4. Buggy Program (buggy.py)
This is the program listing for Exercise 6-7. You will determine what this program does, add comments where you see "#"s, determine what is wrong with it, and provide a fix for it.

6-11. Conversion.
(a) Create a program that will convert from an integer to an Internet Protocol (IP) address in the four-octet format of WWW.XXX.YYY.ZZZ.
(b) Update your program to be able to do the vice versa of the above.
6-12. Strings.
(a) Create a function called findchr(), with the following declaration:
def findchr(string, char)
findchr() will look for character char in string and return the index of the first occurrence of char, or -1 if that char is not part of string. You cannot use string.*find() or string.*index() functions or methods.
(b) Create another function called rfindchr() that will find the last occurrence of a character in a string. Naturally this works similarly to findchr(), but it starts its search from the end of the input string.
(c) Create a third function called subchr() with the following declaration:
def subchr(string, origchar, newchar)
subchr() is similar to findchr() except that whenever origchar is found, it is replaced by newchar. The modified string is the return value.
6-13. Strings. The string module contains three functions, atoi(), atol(), and atof(), that convert strings to integers, long integers, and floating point numbers, respectively. As of Python 1.5, the Python built-in functions int(), long(), and float() can also perform the same tasks, in addition to complex(), which can turn a string into a complex number. (Prior to 1.5, however, those built-in functions converted only between numeric types.)
An atoc() was never implemented in the string module, so that is your task here. atoc() takes a single string as input, a string representation of a complex number, e.g., ‘-1.23e+4-5.67j’, and returns the equivalent complex number object with the given value. You cannot use eval(), but complex() is available. However, you can only use complex() with the following restricted syntax: complex(real, imag) where real and imag are floating point values.
6-14. *Random Numbers. Design a “rock, paper, scissors” game, sometimes called “Rochambeau,” a game you may have played as a kid. Here are the rules. At the same time, using specified hand motions, both you and your opponent have to pick from one of the following: rock, paper, or scissors. The winner is determined by these rules, which form somewhat of a fun paradox:
(a) the paper covers the rock,
(b) the rock breaks the scissors,
(c) the scissors cut the paper. In your computerized version, the user enters his/her guess, the computer randomly chooses, and your program should indicate a winner or draw/tie. Note: The most algorithmic solutions use the fewest number of if statements.
(a) Given a pair of dates in some recognizable standard format such as MM/DD/YY or DD/MM/YY, determine the total number of days that fall between both dates.
(b) Given a person’s birth date, determine the total number of days that person has been alive, including all leap days.
(c) Armed with the same information from (b) above, determine the number of days remaining until that person’s next birthday.
6-16. Matrices. Process the addition and multiplication of a pair of M by N matrices.
6-17. Methods. Implement a function called myPop(), which is similar to the list pop() method. Take a list as input, remove the last object from the list and return it.
6-18. zip() Built-in Function. In the zip() example of Section 6.13.2, what Python object does zip(fn, ln) return that can be iterated over by the for loop?
6-19. Multi-Column Output. Given any number of items in a sequence or other container, display them in equally-distributed number of columns. Let the caller provide the data and the output format. For example, if you pass in a list of 100 items destined for three columns, display the data in the requested format. In this case, two columns would have 33 items while the last would have 34. You can also let the user choose horizontal or vertical sorting.