
Chapter 6. Site Topology and Active Directory Replication
This chapter introduces a major feature of Active Directory: multimaster replication. Active Directory was one of the first LDAP-based directories to offer multimaster replication. Most directories replicate data from a single master server to subordinate servers. This is how replication worked in Windows NT 4.0, for example. Obviously, there are several potential problems with a single-master replication scheme, including the single point of failure for updates, geographic distance from the master to clients performing the updates, and less efficient replication due to updates having a single originating location. Active Directory replication addresses these issues, but with a price. To get the benefit of multimaster replication, you must first create a site topology that describes the network and helps define how domain controllers should replicate with each other. In large environments, building and maintaining a site topology can require a significant amount of work.
This chapter looks at the basics of how sites and replication work in Active Directory. In Chapter 14, we’ll describe the physical infrastructure of a network layout using sites. We’ll also discuss in that chapter how the Knowledge Consistency Checker (KCC) sets up and manages the replication connections and provide details on how to effectively design and tailor sites, site links, and replication in Active Directory.
6.1. Site Topology
The Active Directory site topology is the map that describes the network connectivity, Active Directory replication guidelines, and locations for resources as they relate to the Active Directory forest. The major components of this topology are sites, subnets, site links, site link bridges, and connection objects. These are all Active Directory objects that are maintained in the forest’s Configuration container; this allows the information to be locally available on all domain controllers so the DCs can communicate properly.
Site and Replication Management Tools
Microsoft provides the Active Directory Sites and Services MMC snap-in (dssite.msc) to help you manage the replication topology. This snap-in allows you to drill down into the Sites container, which holds all the site topology objects and connection objects. The Sites container is physically located directly under the Configuration container in the Configuration naming context. With the Sites and Services snap-in, you can create new sites, subnets, links, bridges, and connections, as well as setting replication schedules, metrics for each link, and so on.
In addition to the Sites and Services snap-in, the repadmin command-line tool is an incredibly useful tool and one you should be familiar with. Windows Server 2012 adds a number of PowerShell cmdlets for managing replication as well. To see all of the replication cmdlets, run Get-Command *-adrep* from Windows PowerShell.
Note
If you are looking for repadmin on Windows 2000 or Windows Server 2003, you’ll find it in the Windows Support Tools download available from Microsoft.
Subnets
A subnet is a portion of the IP space of a network. Subnets are described by their IP network addresses combined with a subnet mask measured in bits. For instance, the subnet mask 255.255.255.0 is a 24-bit subnet mask. If you had a 24-bit mask for the 10.5.20.0 network, your subnet object would be described as 10.5.20.0/24. The subnet objects in Active Directory are a logical representation of the subnets in your environment; they may, but do not necessarily have to, reflect your actual physical subnet definitions. For example, you may have a building that has two 24-bit subnets of 10.5.20.0 and 10.5.21.0, which for the purposes of Active Directory could be included in a single AD subnet of 10.5.20.0/23, which specifies a 23-bit subnet mask.
Note
These examples all represent IP version 4 (IPv4) subnets. Windows Server 2008 introduced support for IP version 6 (IPv6) subnets and domain controllers in Active Directory. The same concepts for subnetting apply; however, the addresses and subnets are much larger. IPv4 uses 32-bit addressing whereas IPv6 uses 128-bit addressing.
You must define subnet information in the directory, because the only key available for determining relative locations on a network is the IP addresses of the machines. The subnets are, in turn, associated with sites. Without these definitions, there is no way for a machine to make an efficient determination of what distributed resources it should try to use. By default, no subnets are defined in Active Directory. For more information on defining subnets in Active Directory, see the sidebar , next.
It is very important to make sure that you have up-to-date subnet information stored in Active Directory any time you are working with a multisite environment. If subnet information is not accurate, unnecessary WAN traffic may be generated as domain members authenticate to domain controllers in other sites. Domain controllers will also log events warning you of missing subnet definitions.
One strategy for addressing missing subnet definitions is the use of supernets. Supernet is a term used to describe a single subnet that encompasses one or more smaller subnets. For example, you may define a subnet object of 10.0.0.0/8, as well as many subnets in the same space with larger subnet masks, such as 10.1.0.0/16, 10.1.2.0/24, or even 10.1.2.209/32. When Active Directory works out which subnet a machine is associated with, it chooses the most specific subnet defined. So, if the IP address were 10.1.2.209, the subnet 10.1.2.209/32 would be used; but if the IP address were 10.2.56.3, the 10.0.0.0/8 subnet would be used.
You may be wondering why someone would do this. The supernet objects can be assigned to any site just like any other subnet object. This means you can assign these “catchall” subnets to hub-based sites for machines that are running from subnets that are not otherwise defined. This causes the machines to use the hub resources rather than randomly finding and selecting resources to use.
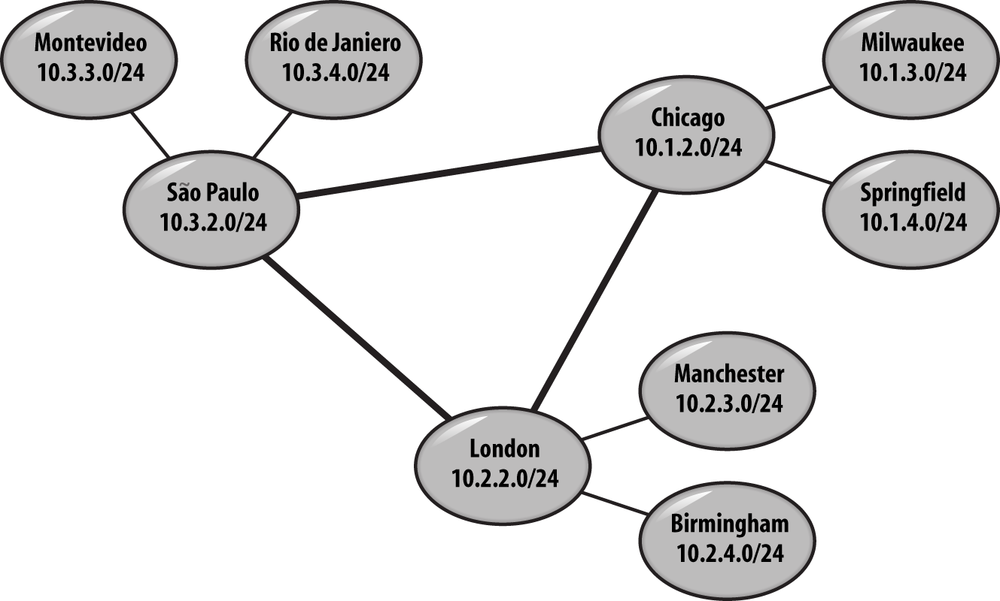
Figure 6-1 shows a perfect example of an organization whose subnet design lends itself well to the deployment of supernets in Active Directory. There are three hub sites in this topology—Chicago, São Paulo, and London. If you look closely, all of the subnets under Chicago can be summarized as 10.1.0.0/16, all of the subnets under London can be summarized as 10.2.0.0/16, and all of the subnets under São Paulo can be summarized as 10.3.0.0/16. By creating each of these subnets in Active Directory and associating them with their respective hub sites, you will create a safety net for new subnets that might come up at each of the locations.
Managing subnets
You can create subnets with Active Directory Sites and Services or with Windows PowerShell. To create a subnet with Active Directory Sites and Services, browse to the Subnets container under Sites. Right-click and click New Subnet. You can enter an IPv4 or IPv6 subnet address in the Prefix text box, as shown in Figure 6-2. You must also associate the subnet with a site. In Figure 6-2, we are associating the subnet 172.16.1.0/24 with the Chicago site.

To create the same subnet with Windows PowerShell, you will need to be using the Windows Server 2012 (or Windows 8) Remote Server Administration Tools (RSAT) or running the command directly on a Windows Server 2012 server. The command to use is:
New-ADReplicationSubnet-Name"172.16.1.0/24"-Site"Chicago"
If you need to change the site that a subnet is associated with, you can do that from the properties of the subnet, or with the Set-ADReplicationSubnet cmdlet.
Troubleshooting subnet data problems
When your forest doesn’t have up-to-date subnet information, there are a few things that happen on your domain controllers. First and foremost, clients start connecting to DCs that are not logically near them on the network. This leads to increased WAN traffic and poor client performance. Next, your DCs will start periodically logging events in the event log similar to the one following:
Event ID: 5807 Source: NETLOGON User: N/A Computer: DC01 Description: During the past %1 hours there have been %2 connections to this Domain Controller from client machines whose IP addresses don't map to any of the existing sites in the enterprise. Those clients, therefore, have undefined sites and may connect to any Domain Controller including those that are in far distant locations from the clients. A client's site is determined by the mapping of its subnet to one of the existing sites. To move the above clients to one of the sites, please consider creating sub- net object(s) covering the above IP addresses with mapping to one of the existing sites. The names and IP addresses of the clients in question have been logged on this computer in the following log file '%SystemRoot%debugNetlogon.log' and, poten- tially, in the log file '%SystemRoot%debug etlogon.bak' created if the former log becomes full. The log(s) may contain additional unrelated debugging information. To filter out the needed information, please search for lines which contain text 'NO_CLIENT_SITE:'. The first word after this string is the client name and the second word is the client IP address. The maximum size of the log(s) is controlled by the following registry DWORD value 'HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesNetlogonParameters LogFileMaxSize'; the default is %3 bytes. The current maximum size is %4 bytes. To set a different maximum size, create the above registry value and set the desired maximum size in bytes.
Finally, every client that connects to a DC from an IP address without a corresponding subnet in AD will get logged in the DC’s netlogon.log file, located at %windir%debug etlogon.log. Log entries for missing subnets will look like this:
11/12 05:45:29 BRIANLAB: NO_CLIENT_SITE: PC06 192.168.4.111 11/12 06:06:12 BRIANLAB: NO_CLIENT_SITE: PC03 192.168.4.113
In the preceding example, two machines, PC06 and PC03, have
connected from IP addresses (192.168.4.111 and 113) that don’t have a
corresponding subnet in Active Directory. The format of the log entry
is Date Time Domain: NO_CLIENT_SITE:
Machine-Name IP-Address.
Note
The IP address in the preceding log snippet could be an IPv4 or IPv6 address.
If you have IPv6 deployed and your clients have both IPv4 and IPv6 IPs (known as dual stack), you’ll need to make sure that AD contains subnet mappings for both the IPv4 and IPv6 subnets. If you only have one or the other configured for a client, you’ll start seeing this event periodically:
Event ID: 5810 Source: NETLOGON User: N/A Computer: DC01 Description: During the past %1 hours, this domain controller has received %2 connections from dual-stack IPv4/IPv6 clients with partial subnet-site mappings. A client has a partial subnet-site mapping if its IPv4 address is mapped to a site but its global IPv6 address is not mapped to a site, or vice versa. To ensure correct behavior for applications running on member computers and servers that rely on subnet-site mappings, dual-stack IPv4/IPv6 clients must have both IPv4 and global IPv6 addresses mapped to the same site. If a partially mapped client attempts to connect to this domain controller using its unmapped IP address, its mapped address is used for the client's site mapping. The log files %SystemRoot%debug etlogon.log or %SystemRoot%debug etlogon.bak contain the name, unmapped IP address and mapped IP address for each partially mapped client. The log files may also contain unrelated debugging information. To locate the information pertaining to partial-subnet mappings, search for lines that contain the text 'PARTIAL_CLIENT_SITE_MAPPING:'. The first word after this text is the client name. Following the client name is the client's unmapped IP address (the IP address that does not have a subnet-site mapping) and the client's mapped IP address, which was used to return site information. USER ACTION Use the Active Directory Sites and Services management console (MMC) snap-in to add the subnet mapping for the unmapped IP addresses to the same site being used by the mapped IP addresses. When adding site mappings for IPv6 addresses, you should use global IPv6 addresses and not for instance temporary, link-local or site-local IPv6 addresses. The default maximum size of the log files is %3 bytes. The current maximum size is %4 bytes. To set a different maximum size, create the following registry DWORD value to specify the maximum size in bytes: HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServices NetlogonParametersLogFileMaxSize
You’ll also start seeing entries in your
netlogon.log file that contain the term PARTIAL_CLIENT_SITE_MAPPING instead of NO_CLIENT_SITE. This entry will tell you the
IPv4 or IPv6 address that matched a subnet in Active Directory, and
the opposite address that did not. That is, if a client connected with
an IPv6 address but that client’s IPv4 address matches a subnet in
Active Directory, the log will advise you of the unmapped IPv6
address.
Note
Check out this website for a sample script to help you track down subnet mapping issues.
Sites
An Active Directory site is generally defined as a collection of well-connected AD subnets. You use sites to group subnets together into logical collections to help define replication flow and resource location boundaries. Active Directory uses sites directly to generate its replication topology, and also to help clients find the “nearest” distributed resources to use in the environment (such as DFS shares or domain controllers). The client’s IP address is used to determine which Active Directory subnet the client belongs to, and then that subnet information, in turn, is used to look up the AD site. The site information can then be used to perform DNS queries via the DC locator service to determine the closest domain controller or Global Catalog. For a discussion of the DC locator process, refer to Recipe 8.3.
Most members of a domain dynamically determine their site when they start up, and they continue to validate what site they are in in the background. This allows administrators to make modifications to the site topology and have them take effect properly in relatively short order with the least amount of manual work. Domain controllers, on the other hand, select their site when they are promoted and will not automatically change unless an administrator wants them to become part of another site. Moving a domain controller to another site is an administrative task that is most easily performed via the Active Directory Sites and Services tool.
By default, there is one site defined in Active Directory, the Default-First-Site-Name site. If there are no subnet objects defined, all members of the domain are “magically” assumed to be part of this initial site, or any other single defined site if you have replaced the default site with another site. Once there are multiple site objects, or after subnet objects are defined and assigned, the “magic” feature goes away and subnet objects must be defined for the subnets in which domain members reside. There is nothing special about this initial site other than that it is the first one created; you can rename it as you see fit. You can even delete it, as long as you have created at least one other site and moved any domain controllers located within the Default-First-Site-Name site to another site.
Multiple sites can be defined for a single physical location. This can allow you to better segregate which resources are used for which requestors. For instance, it is common practice in large companies to build a separate site just to harbor the Microsoft Exchange 2000 and 2003 servers and the global catalogs that are used to respond to Exchange and Outlook queries. This allows an administrator to easily control which GCs are used without having to hardcode preferred GC settings into Exchange. You can define the subnets as small as you need them, including down to a single IP address (32-bit subnet), to place servers in the proper site.
Warning
It is no longer a recommended best practice to place Exchange servers in a separate site, due to the changes in Exchange’s mail-routing behavior beginning with Exchange 2007. If you are deploying Exchange in your environment you will need to work closely with your Exchange administrators to ensure you have enough Global Catalog capacity in the sites that support Exchange.
Managing sites
Much like subnets, you can create sites with the aptly named Active Directory Sites and Services MMC snap-in, or with Windows PowerShell. When you create a site, as shown in Figure 6-3, you’ll be prompted to pick a site link that defines the path linking the site to the rest of the topology. When using the GUI, there is a bit of a Catch-22 because in order to create a site you need to pick a site link, but as you’ll see, when you’re ready to create a site link, you’ll need to pick the sites that are linked. Thus, when you create the site, it is fine to temporarily pick a site link (such as the default shown in Figure 6-3) and then make changes once you have the site links ready.

To create the same site with Windows PowerShell, you can run the following command:
New-ADReplicationSite-Name"Paris"
Note that when you use Windows PowerShell, you don’t have to specify a site link when you create a site. The circular dependency is a function of the MMC snap-in, not Active Directory.
If you want to see the list of subnets that are associated with a site, they are displayed on the properties of the site in the AD Sites and Services MMC snap-in.
Site Links
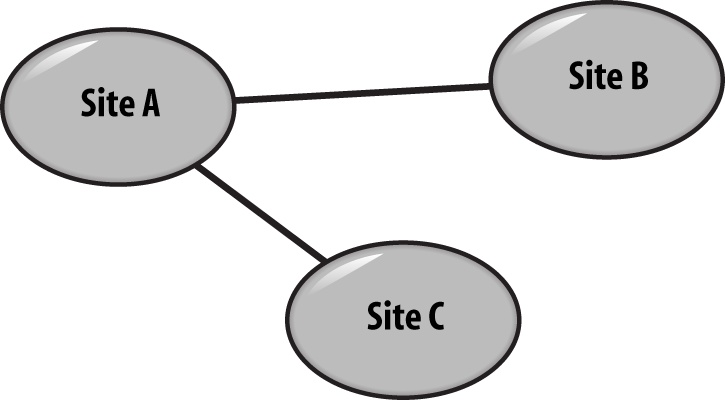
Site links allow you to define what sites are connected to each other and the relative cost of the connection. When you create a site link, you specify which sites are connected by this link and what the cost or metric of the connection is in a relative-costing model. For instance, three sites—A, B, and C—could be connected to each other, but because you understand the underlying physical network, you might feel all traffic should be routed through the A site. This would require you to configure to two site links: A to B and A to C, as shown in Figure 6-4.
If at a later time additional physical network connections were established between B and C, you could set up one more site link and connect B and C together. If you configure all three site links with an equal cost—say, 100—traffic could then flow across the B-to-C link instead of from B to A to C. This is because the total cost to use the B-to-C link would be 100 and the total cost to use the B-to-A-to-C route would be 200, which is more expensive. This scenario is demonstrated in Figure 6-5.

If you prefer that traffic to still flow through Site A, your total cost from B to A to C (and the reverse) should be lower than your cost from B to C. So, you would need to set the B-to-C link cost to something greater than 200—like 300, as shown in Figure 6-6. In this scenario, the B-to-C site link would only be used if the connection could not go through Site A for some reason.

Site links can come in two replication flavors: IP and SMTP. An IP site link actually represents a a remote procedure calls (RPC)-style replication connection. This is by far the most commonly used type of site link; in fact, the default site link created by Active Directory is an IP site link called DEFAULTIPSITELINK. The other site link type is an SMTP site link.
SMTP site links are a special SMTP-based (Simple Mail Transfer Protocol—think email) replication protocol. SMTP replication is used to communicate with sites that have very poor or unreliable network connections (such as extremely high latency or unpredictable availability) that cannot support an RPC replication connection. Due to security concerns, however, only certain naming contexts can be replicated across SMTP site links. Only the Configuration NC, Schema NC, and read-only Global Catalog NCs can be replicated via SMTP. This means that you must still replicate the domain NC via the more common IP replication protocol (with RPC).
Besides defining which replication protocols should be used and which sites should be replicating with what other sites, site links control domain controller and Global Catalog coverage of sites that do not have local DCs or GCs. This behavior is called auto site coverage.
Consider the diagram in Figure 6-7 showing Sites A, B, and C. Site A has domain controllers for Dom1 and Dom2, but Site B only has a DC for Dom1 and Site C for Dom2. How does a client decide which DC it should use for a domain that doesn’t have a domain controller in the local site? Logically, you can look at it and say, “If someone needs to log on to Dom1 while in Site C, the client should talk to Site A.” But Active Directory cannot make this intuitive leap; it needs to work with cold hard numbers, and that is what the site link metrics do: give the directory the information needed to make the calculations to determine which sites a given domain controller should cover in addition to its own site.
Active Directory will automatically register the necessary covering DNS records for sites that do not have domain controllers, based on the site link topology. The relationship between Active Directory and DNS is covered in detail in Chapter 8. For information on disabling auto site coverage, see this website.
Managing site links
The place to create site links in the AD Sites and Services MMC snap-in is a bit hard to find: the option is buried under SitesInter-Site TransportsIP, as shown in Figure 6-8.
Note
If you are using SMTP replication and you need to create an SMTP site link, you will need to instead create the site link from inside the SMTP folder pictured in Figure 6-8.

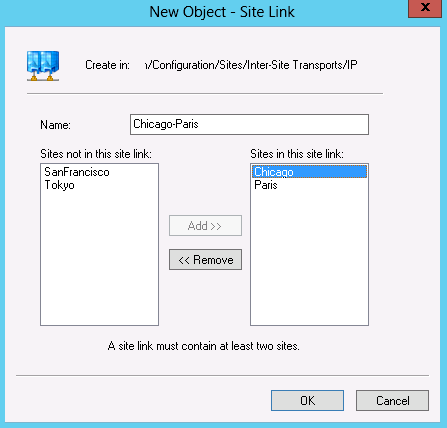
Once you’ve found the correct location, you can right-click and click New Site Links.... You’ll need to provide a name for the site link and select two or more sites to include in the site link. While AD supports more than two sites in a link, we generally recommend that you stick with two sites per link to make troubleshooting and understanding the expected topology easier.
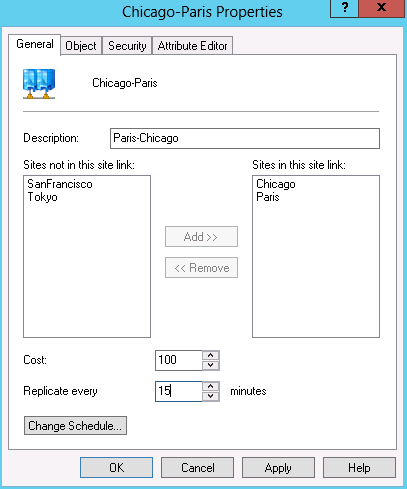
In Figure 6-9, we create a site link between Chicago and Paris. Once you create the site link, consider adding a description ordered in the opposite order of the name. For example, in Figure 6-9, we created a site link called Chicago-Paris. If you set the description to Paris-Chicago, you’ll be able to sort on either side of a site link by sorting on either the Name or Description the columns (shown in Figure 6-8).
To create the same site link with Windows PowerShell, run this command:
New-ADReplicationSiteLink-Name"Chicago-Paris"-Description"Paris-Chicago"`-SitesIncluded@("Chicago","Paris")-Cost100-ReplicationFrequencyInMinutes15
There is one piece of syntax here that may be new to you. In the SitesIncluded parameter, we have to provide PowerShell with an array. Arrays enable you to pass a list to a particular argument. PowerShell provides a shortcut to creating an array in the form of wrapping the list inside of the @() syntax shown in this example.
After you create a site link, chances are you’ll want to set some properties of the site link, such as the cost, replication frequency, or possibly the schedule. Figure 6-10 shows the properties of the Chicago-Paris site link. In this scenario, we are setting the cost to 100 and the replication interval to 15 minutes. You can manage the schedule with the Change Schedule button shown in Figure 6-10. Keep in mind that the site link’s schedule defines when replication can begin. Once replication has begun, it will continue until it has finished.
Site Link Bridges
By default, Active Directory assumes that the network paths between all of your sites are transitive. In other words, if you reference Figure 6-4, Active Directory assumes that domain controllers in Site C can talk directly to domain controllers in Site A. In some networks, this behavior is undesirable since the network does not permit this transitivity. Sometimes in the context of a networking discussion, people will refer to this scenario as the network not being fully routed. When you find yourself in this scenario, you may need to disable the “Bridge all site links” option for your forest. This option is accessible by right-clicking the SitesInter-Site TransportsIP folder in Active Directory Sites and Services, and going to Properties. The same setting is independently available for the SMTP replication transport.
If you have disabled “Bridge all site links,” you may need to define site link bridges in your directory. A site link bridge contains a set of site links that can be considered transitive. In other words, any of the sites contained in the list of site links that you are bridging can communicate directly. Referring to Figure 6-4 again, if the site links from A to C and A to B are bridged, we are telling Active Directory that direct communication between a domain controller in Site C and a domain controller in Site B is permissible.
We will discuss site link bridges in more detail in Chapter 14. You can create site link bridges from the same location as site links. Windows PowerShell offers the New-ADReplicationSiteLinkBridge cmdlet to script the creation of site link bridges.
Connection Objects
The final piece of the topology puzzle is the connection object. A connection object specifies which domain controllers replicate with which other domain controllers, how often, and which naming contexts are involved. Unlike sites, subnets, and site links, which you generally need to manually configure, connection objects are generally managed by the domain controllers themselves. The idea is that you should logically construct the site topology with good definitions for sites, subnets, and site links, and Active Directory will be able to figure out the best way to interconnect the actual domain controllers within and between the sites.
It is occasionally not possible to allow AD to manage all of these connections, but it is a very good goal to work toward, and you should endeavor not to modify or supplement connection objects unless you have no other choice. Earlier versions of Active Directory were not able to properly load balance replication connections between domain controllers, so a domain controller in a hub site could become overwhelmed with replication traffic from spoke domain controllers. This scenario often caused administrators to opt to attempt to manage replication connections manually or with the Active Directory Load Balancing (ADLB) tool. Fortunately, beginning with Windows Server 2008, Active Directory gained the ability to automatically load balance replication connection to read-only domain controllers (RODCs). Windows Server 2008 R2 extended this capability to load balancing of replication connections with all types of domain controllers.
You can view connection objects with AD Sites and Services as well as the Get-ADReplicationConnection cmdlet. Both the MMC snap-in and Windows PowerShell enable you to make changes to connection objects, and AD Sites and Services allows you to create new connection objects. When you manually create or modify a connection object, Active Directory will no longer automatically manage that connection object. With this in mind, you should endeavor not to manually edit or create connection objects and instead maintain an accurate site topology that the KCC can use to build and maintain the correct connection object topology. If the name of the connection object in the MMC doesn’t display as “<automatically generated>,” that means that Active Directory is not managing the connection object.
Knowledge Consistency Checker
In all but the smallest deployments, such as small business server (SBS) or other single-site environments, administrators should create a site topology in Active Directory that maps closely to the physical network. Unfortunately, Active Directory is not intelligent enough to look at the network and build its own complex topologies to optimize replication and resource location for every company installing Active Directory—it needs your help. Creating a site topology is discussed in Chapter 14.
Once you have set up your sites, subnets, and site link objects, an Active Directory process called the Knowledge Consistency Checker (KCC) takes that information and automatically generates and maintains the connection objects that describe which naming contexts should be replicated between which domain controllers, as well as how and when. The KCC has two separate algorithms it uses to determine what connection objects are needed: intrasite and intersite.
The intrasite algorithm is designed to create a minimal latency ring topology for each naming context that guarantees no more than three hops between any two domain controllers in the site. As DCs, GCs, and domains are added and removed within a site, the KCC adds and removes connections between the domain controllers as necessary to maintain this minimal-hop topology. It is quite simple to visualize when dealing with a single domain and a small number of domain controllers, but gets extremely difficult to visualize as you add many domain controllers and additional domains.
The intersite algorithm, on the other hand, is not a minimum-hop algorithm; it tries to keep the sites connected via a spanning-tree algorithm so that replication can occur, and then simply follows the site link metrics for making those connections. It is quite possible for the KCC to generate a replication topology that forces a change to replicate through eight sites to get from one end of the topology to the other. If you are unhappy with the site connections made by the KCC for the intersite topology because they don’t align with your network connections, the problem is almost certainly related to how the site links are configured. A well-designed site topology will help the KCC generate an intelligent and efficient collection of connection objects for replication.
We cover the KCC in greater depth in Chapter 14.
6.2. How Replication Works
Microsoft has introduced a number of new terms for Active Directory replication, and most of them will be completely unfamiliar to anyone new to Active Directory. To properly design your replication topology, you should understand the basics of how replication works, but you also need to understand how replication works using these new terms, which are used throughout both Microsoft’s documentation and its management tools. As you read the rest of this chapter, refer back as needed to the definitions of the terms that are presented. Do not be disappointed if it doesn’t all sink into your brain comfortably on your first or even fifth read of the material. Even experienced administrators have been known to debate how this all works, as well as what the proper terms are for the various structures and processes.
We will use the sample replication topology in Figure 6-11 for the discussion in this section.

A Background to Metadata
Replication metadata is the data that governs the replication process. Active Directory replication enables data transfer between naming contexts on different domain controllers without ending up in a continuous replication loop or missing any data. To make this process work, each NC holds a number of pieces of information that specifically relate to replication within that particular NC. That means that the replication data for the Schema NC is held in the Schema NC and is separate from the replication data for the Configuration NC, which is held in the Configuration NC, and so forth. This is done this way because all replication is naming context-based. When a domain controller is pulling changes from another domain controller, it does so one naming context at a time in a serial fashion.
Warning
Although time isn’t used as the basis for replication in Active Directory, it is still incredibly important. All authentication between domain controllers for replication is Kerberos-based, and Kerberos has a maximum time-skew requirement between hosts. In a domain with the default settings, if a domain controller deviates from the common time of all of the other domain controllers by more than five minutes, that domain controller will no longer be able to replicate with other domain controllers.
Update sequence numbers (USNs) and highestCommittedUSN
Each domain controller maintains its own separate update sequence number (USN). Each time a change (new objects, updates, deletes, etc.) is made to an object in Active Directory, a transaction occurs. A USN is a 64-bit value that is assigned to each atomic update transaction, and it is meaningful only in relation to the domain controller on which the update was performed. Each separate update transaction will generate an incrementing USN value. A single USN could represent the change of every attribute on an object or a single attribute on a single object. If we examined a domain controller’s highest committed USN and discovered it was 1,000 and then came back 10 minutes later and discovered the highest committed USN was now 1,056, we would know that 56 transactions had occurred in the past 20 minutes on this domain controller.
While some directory systems use timestamps to control
replication and what needs to be propagated from server to server,
Microsoft chose to use USN values. The fact that these values
increment sequentially completely avoids the issues of the domain
controllers having their clocks set backward or being out of sync with
their replication partners. While the USN is independent of the clock
on the domain controller, it is critical that the USN only move
forward. When the USN on a domain controller gets decremented (usually
through reverting a virtual machine snapshot), you will find yourself
in a situation commonly referred to as USN
rollback. Each domain controller maintains its highest
combined USN for every naming context in the highestCommittedUSN value of the RootDSE. See the sidebar Querying RootDSE with LDP in Chapter 4 for the steps to
view the highestCommittedUSN
value.
USNs are used to uniquely identify each update that has taken place in a naming context on a particular domain controller, regardless of the update type. It is highly improbable that the same USNs will ever represent the same change on two different domain controllers. This means that you can request individual changes based on particular USNs from a specific domain controller, but it does not allow for direct comparison between DCs based on similar USN values. The change of the description on a computer account named Cerberus to “joe’s computer” may be USN 23865 on one domain controller, but USN 4078 on another and USN 673459234 on yet another.
Originating updates versus replicated updates
Replication distinguishes between two types of update:
- Originating update (write)
This term defines the point of origin for a particular update—i.e., on which domain controller the change initially occurred.
- Replicated update (write)
This term defines the opposite of an originating update—i.e., the change in question did not begin here; it was replicated from another domain controller.
If you use the Active Directory Users and Computers snap-in to create five users on DC A, DC A’s USN will be incremented five times, once for each originating update. These changes will then be replicated to DC B, incrementing its USN by five. Similarly, if DC A receives a change from DC B, DC A’s USN is incremented once. This behavior is outlined in Table 6-1.
Note
If an Active Directory database transaction is aborted—i.e., fails to complete—the associated USN value is not assigned to any object or reused in any way. The USN continues incrementing as changes occur.
Action | Naming context | Originating domain controller | Domain controller | USN |
Initial USN value | Domain NC | N/A | DC A | 1000 |
Initial USN value | Domain NC | N/A | DC B | 2500 |
Create 5 new users (originating update) | Domain NC | DC A | DC A | 1005 |
Receive 5 new users (replicated update) | Domain NC | DC A | DC B | 2505 |
Modify user description attribute (originating update) | Domain NC | DC B | DC B | 2506 |
Receive modified user description attribute (replicated update) | Domain NC | DC B | DC A | 1006 |
DSA GUIDs and invocation IDs
Each domain controller has a GUID called the Directory Service
Agent (DSA) GUID. This DSA GUID is used to
uniquely identify a domain controller and is the objectGUID of the NTDS Settings object
viewable under the domain controller in Active Directory Sites and
Services. This GUID does not change unless the domain controller is
demoted and re-promoted.
The Active Directory database (ntds.dit) also has a GUID. This latter GUID
is used to identify the server’s Active Directory database in
replication calls and is called the invocation
ID; it is stored in the invocationId attribute of the NTDS Settings
object for the domain controller. The invocation ID is changed any
time Active Directory is restored on that DC or any time the DSA GUID
is changed. Windows Server 2012 DCs will also reset their invocation
IDs any time they detect a change in their virtual machine generation
IDs. For more information on the virtual machine generation ID (VM gen
ID) change process, refer to Chapter 9.
Note
This change of GUID ensures that the other domain controllers on the network realize that this is a new database instance and that they create new high-watermark vector and up-to-dateness vector entries in their respective tables for it.
This allows changes that occurred after the backup to be replicated back to the newly restored database to bring it properly up to date. Without this step, any changes that originated on the restored DC after the backup completed and that had replicated out to the rest of the directory would never replicate back to this DC once it was restored. This is because the replication partners would assume the DC already had those changes, since it was the master of the changes in the first place.
Table 6-2 summarizes the DSA GUID and invocation ID values.
Object | Attribute | Description |
NTDS Settings |
| Uniquely identifies the domain controller for its entire lifetime. This attribute value is referred to as the DSA GUID. |
NTDS Settings |
| Uniquely identifies the Active Directory database on the domain controller. This attribute value is referred to as the invocation ID. The invocation ID is reset when a domain controller is restored from a backup or when a change in VM gen ID is detected. |
High-watermark vector (direct up-to-dateness vector)
The high-watermark vector (HWMV) is a table maintained independently by every domain controller to assist in efficient replication of a naming context. Specifically, it is used to help the domain controller determine where it last left off when replicating the naming context with a specific replication partner.
There is one table for every naming context the domain controller maintains a replica of, so at a minimum every domain controller will have at least three HWMV tables: one each for the Schema, the Configuration, and Domain NCs. Each table stores the highest USN of the updates the domain controller has received from each direct partner it replicates with for the given naming context. These USN values are used to determine where replication should begin with each partner on the next replication cycle. This allows the domain controller to request the most recent updates from a given replication partner for each naming context.
When the local domain controller initiates replication for a naming context with one of its partners, the highest USN for that partner from the domain controller’s high-watermark vector for the naming context is one of the pieces of information sent to the replication partner. The replication partner compares that value with its current highest USN for the naming context to help determine what changes should be sent to the domain controller. This logic is further refined by the up-to-dateness vector, as described in the next section.
Continuing with our previous example, the HWMV tables of DC A and DC B are outlined in Table 6-3 and Table 6-4.
Up-to-dateness vector
The up-to-dateness vector (UTDV) is a table maintained independently by every domain controller to assist in efficient replication of a naming context. Specifically, it is used for replication dampening to reduce needless replication traffic and endless replication loops.
There is one table for every naming context the domain controller maintains a replica of, so again, at a minimum, every domain controller will have at least three of these tables. Each table stores the highest originating update USN the domain controller has received from every other domain controller that has ever existed in the forest, as well as the date/time at which the domain controller last successfully completed a replication cycle with the given replication partner and naming context.
The up-to-dateness vector is used in conjunction with the high-watermark vector to reduce replication traffic. When the replication request for a naming context is passed to the replication partner, the destination domain controller’s up-to-dateness vector for the naming context is also in the request. The source partner can then zero in on changes that it hasn’t previously sent and then further filter out any changes that the destination may have already received from other replication partners. In this way, it guarantees that a single change is not replicated to the same domain controller multiple times; this is called propagation dampening.
Let’s examine our sample replication scenario again; however, this time we will include DC C in the scenario. Table 6-5 shows the USN values as a result of each step.
Action | Naming context | Originating domain controller | Domain controller | USN |
Initial USN value | Domain NC | N/A | DC A | 1000 |
Initial USN value | Domain NC | N/A | DC B | 2500 |
Initial USN value | Domain NC | N/A | DC C | 3750 |
Create 5 new users (originating update) | Domain NC | DC A | DC A | 1005 |
Receive 5 new users (replicated update) | Domain NC | DC A | DC B | 2505 |
Receive 5 new users (replicated update) | Domain NC | DC A | DC C | 3755 |
Modify user description attribute (originating update) | Domain NC | DC B | DC B | 2506 |
Receive modified user description attribute (replicated update) | Domain NC | DC B | DC A | 1006 |
Receive modified user description attribute (replicated update) | Domain NC | DC B | DC C | 3756 |
Once DC C receives the updates originated by DC A, it will attempt to replicate them to DC B; however, DC B has already received these updates from DC A directly. To prevent an endless replication loop, DC C checks the up-to-dateness vector tables for DC B, and it then knows not to send those updates.
Let’s also look at the high-watermark vector tables again, now that DC C is included. Tables 6-6, 6-7, and 6-8 show the HWMV and UTDV tables for DC A, DC B, and DC C.
Naming context | Replication partner | High-watermark vector (USN of last update) | Up-to-dateness vector |
Domain NC | DC B invocation ID | 2506 | 2506 |
Domain NC | DC C invocation ID | 3756 | 3756 |
Naming context | Replication partner | High-watermark vector (USN of last update) | Up-to-dateness vector |
Domain NC | DC A invocation ID | 1006 | 1006 |
Domain NC | DC C invocation ID | 3756 | 3756 |
Naming context | Replication partner | High-watermark vector (USN of last update) | Up-to-dateness vector |
Domain NC | DC A invocation ID | 1006 | 1006 |
Domain NC | DC B invocation ID | 2506 | 2506 |
Notice that now each domain controller has an up-to-dateness vector for each domain controller that it replicates. When DC B goes to pull changes from DC C, it includes its up-to-dateness vector table in the request. DC C will then check this table and discover that DC B has already received the change from DC A. This functionality prevents the endless loop that would otherwise occur and also eliminates unnecessary replication traffic on the network.
Recap
The following list summarizes the important points of this section:
Active Directory is split into separate naming contexts, each of which replicates independently.
Within each naming context, a variety of metadata is held.
For each naming context on a given domain controller, a high-watermark vector is maintained that contains one entry for each of its replication partners. The values in this table for the replication partners are updated only during a replication cycle.
For each naming context on a given domain controller, an up-to-dateness vector is maintained that contains one entry for every domain controller that has ever made an originating write within this NC. Each entry consists of three values:
The originating server’s DSA GUID
The orginating server’s USN
A timestamp indicating the date and time of the last successful replication with the originating domain controller
These values are updated only during a replication cycle.
How an Object’s Metadata Is Modified During Replication
Note
To minimize the use of abbreviations, the terms DC and server are used interchangeably in this section. The terms property and attribute are also used interchangeably here.
To see how the actual data is modified during replication, consider a four-step example:
An object (a user) is created on DC A.
That object is replicated to DC B.
That object is subsequently modified on DC B.
The new changes to that object are replicated back to DC A.
This four-step process is shown in Figure 6-12. The diagram depicts the status of the user object on both DC A and DC B during the four time periods that represent each of the steps.
Now use Figure 6-12 to follow a discussion of each of the steps.
Step 1: Initial creation of a user on Server A
When you create a user on DC A, DC A is the originating server.
During the Active Directory database transaction representing the
creation of the new user on DC A, a USN (1000) is assigned to the
transaction. The user’s uSNCreated
and uSNChanged attributes are
automatically set to 1000 (the USN of the
transaction corresponding to the user creation). All of the user’s
attributes are also initialized with a set of data, as follows:
The attribute’s value(s) is/are set according to system defaults or parameters given during user creation.
The attribute’s USN is set to 1000 (the USN of this transaction).
The attribute’s version number is set to 1.
The attribute’s timestamp is set to the time of the object creation.
The attribute’s originating-server GUID is set to the GUID of DC A.
The attribute’s originating-server USN is set to 1000 (the USN of this transaction).
This information tells you several things about the user:
The user was created during transaction 1000 on this domain controller (
uSNCreated= 1000).The user was last changed during transaction 1000 (
uSNChanged= 1000).The attributes for the user have never been modified from their original values (property version numbers = 1), and these values were set during transaction 1000 (attributes’ USNs = 1000).
Each attribute was last set by the originating server, DC A, during transaction 1000 (originating-server GUID and originating-server USN).
The preceding discussion showed two per-object values and five
per-attribute values being changed. While uSNChanged and uSNCreated are real attributes on each
object in Active Directory, attributes of an object can only have
values and cannot hold other attributes, such as a version
number.
In reality, all of the per-attribute replication metadata
(Property Version Number, Time-Changed, Originating-DC-GUID,
Originating-USN, Property-USN) for every attribute of any given object
is encoded together as a single byte string and stored as replPropertyMetaData, a nonreplicated
attribute of the object.
Note
Use PowerShell, repadmin, adfind, ADSI Edit, or LDP to see a property’s metadata. For an example of how to view replication metadata, see the sidebar Viewing Replication Metadata.
Step 2: Replication of the originating write to DC B
Later, when this object is replicated to DC B, DC B adds the
user to its copy of Active Directory as a replicated write. During
this transaction, USN 2500 is allocated, and the user’s uSNCreated and uSNChanged attributes are modified to
correspond to DC B’s transaction USN (2500).
From this we can learn several key points:
The user was created during transaction 2500 on this server (
uSNCreated= 2500).The user was last changed during transaction 2500 (
uSNChanged= 2500).The attributes for the user have never been modified from their original values (property version numbers = 1), and these values were set during transaction 2500 (attributes’ USNs = 2500).
Each attribute was last set by the originating server, DC A, during transaction 1000 (originating-server GUID and originating-server USN).
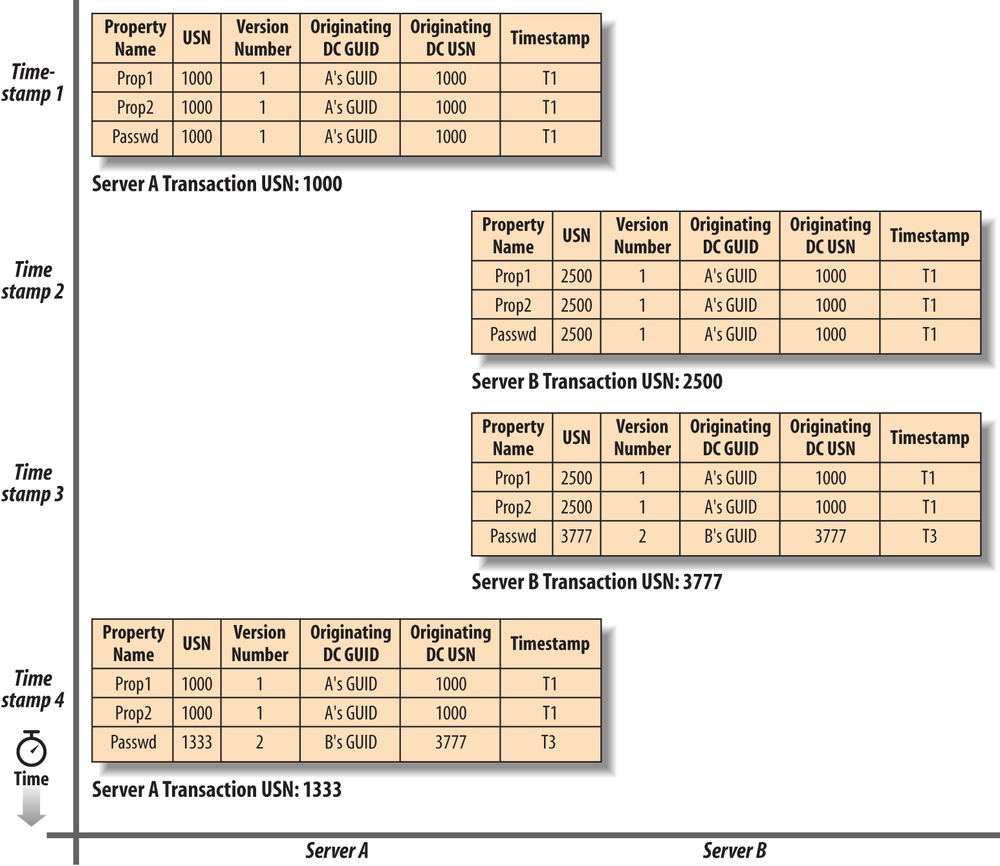
Step 3: Password change for the user on DC B
Now an originating write (a password change) occurs on DC B’s
replicated-write user. Some time has passed since the user was
originally created, so the USN assigned to the password-change
transaction is 3777. When the password is changed, the user’s uSNChanged property is modified to become
3777. In addition, the password attribute (and only
the password attribute) is modified in the following way:
The password value is set.
The attribute’s USN is set to 3777 (the USN of this transaction).
The attribute’s version number is set to 2.
The attribute’s timestamp is set to the date/time at which transaction 3777 occurred.
The attribute’s originating-server GUID is set to the GUID of Server B.
The attribute’s originating-server USN is set to 3777 (the USN of this transaction).
Looking at the user object, you can now see that the object was last changed during transaction 3777 and that the transaction represented a password change that originated on DC B.
Step 4: Password-change replication to DC A
This step is similar to step 2. When DC A receives the password update during replication, it allocates the change transaction a USN of 1333.
Note
Remember that updates occur at the attribute level and not the object level, so only the password is sent and not the entire user object.
During transaction 1333, the user’s uSNChanged attribute is modified to
correspond to Server A’s transaction USN.
Note
If you are duplicating this step-by-step walkthrough on real domain controllers, you will have noticed two discrepancies.
The first is that after the replication from DC A to DC B, the
cn attribute will actually show
that the originating write came from DC B. This is a backend
implementation detail impacting the RDN attribute for any given
object, and it is the only case where this type of discrepancy
occurs.
The second is that a password change actually updates several
attributes, not just one. The attributes involved are dBCSPwd, unicodePwd, pwdLastSet, ntPwdHistory, and lmPwdHistory. This is another backend
implementation detail. For most attributes, when you specifically
update a single attribute, only that attribute gets modified and
replicated; passwords are handled as a special case.
From this, we can learn a number of things:
The user was created during transaction 1000 on this server (
uSNCreated= 1000).The user was last changed during transaction 1333 (
uSNChanged= 1333).All but one of the attributes for the user have retained their original values (property version numbers = 1), and these values were set at transaction 1000 (properties’ USNs = 1000).
All but one of the attributes were last set by the originating server, DC A, during transaction 1000 (originating-server GUID and originating-server USN).
The password was modified for the first time since its creation (password version number = 2) during transaction 1333 (password’s USN = 1333), and it was modified on DC B during transaction 3777 (originating-server GUID and originating-server USN).
That’s how object and property metadata is modified during replication. Let’s now take a look at exactly how replication occurs.
The Replication of a Naming Context Between Two Servers
In the following examples, there are five servers in a domain: Server A, Server B, Server C, Server D, and Server E. It doesn’t matter what NC they are replicating or which servers replicate with which other servers (as they do not all have to replicate with one another directly), because the replication process for any two servers will be the same nonetheless. Replication is a five-step process:
Replication with a partner is initiated.
The partner works out what updates to send.
The partner sends the updates to the initiating server.
The initiating server processes the updates.
The initiating server checks whether it is up to date.
Step 1: Replication with a partner is initiated
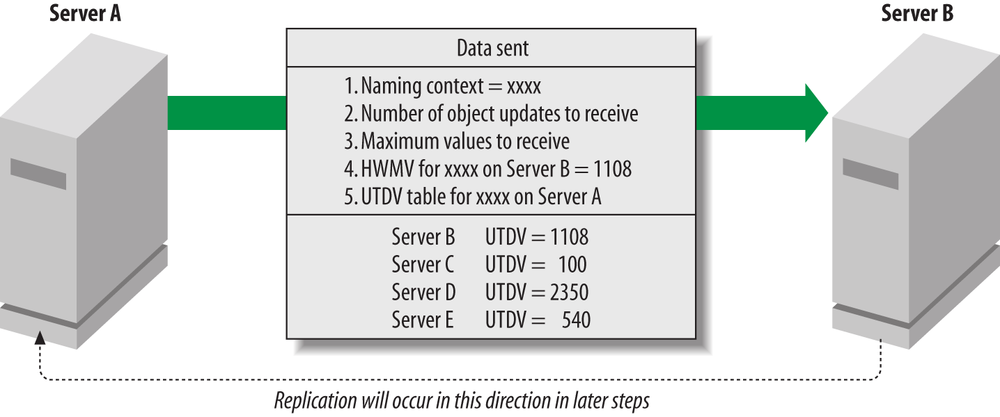
Replication occurs between only two servers at any time, so let’s consider Server A and Server B, which are replication partners. At a certain point in time indicated by the replication schedule on Server A, Server A initiates replication for a particular NC with Server B and requests any updates that it doesn’t have. This is a one-way update transfer from Server B to Server A. No new updates will be passed to Server B in this replication cycle, as this would require Server B to initiate the replication.
Server A initiates the replication by sending Server B a request to replicate along with five pieces of important replication metadata, (i.e., data relating to the replication process itself). The five pieces of metadata are:
The name of the NC for which Server A wishes to receive updates
The maximum number of object updates that Server A wishes to receive during this replication cycle
The maximum number of values that Server A wishes to receive during this replication cycle
The USN for Server B from Server A’s high-watermark vector for this NC
Server A’s up-to-dateness vector for this NC
Specifying the numbers of maximum object updates and property values is very important in limiting network bandwidth consumption. If one server has had a large volume of updates since the last replication cycle, limiting the number of objects replicated out in one replication packet means that network bandwidth is not inordinately taken up by replicating those objects in one huge packet. Instead, the replication is broken down into smaller packets over the course of the replication cycle. Once a replication cycle has started for a naming context, it will replicate all changes regardless of how many packets are needed or how long it will take, unless the connection between the domain controllers fails outright.
Warning
The wording in the previous paragraph with regard to the behavior of replication schedules is subtle but key. The schedule defines only when replication can begin. Once a replication cycle begins, it will not stop until it completes (or the connection is interrupted). This is true even if the schedule is overrun.
This step is illustrated in Figure 6-13, which shows that while the initiation of the replication occurs from an NC denoted as xxxx on Server A (where xxxx could represent the Schema NC, the Configuration NC, an application partition, or any domain NC), the actual replication will occur later from Server B to Server A.
Step 2: The partner works out what updates to send
Server B receives all this metadata and works out which updates it needs to send back for this NC. First, Server B determines its own highest committed USN for its copy of the NC and compares that to the USN Server A submitted from its high-watermark vector table. Assuming that there have been some updates, Server B instantly knows how many updates have occurred since Server A last replicated with Server B. This has to be true, as Server A’s HWMV will have been updated with Server B’s highest committed USN for the NC during the last replication cycle. Any difference between the two USNs must therefore represent changes on Server B since the last replication, and Server B knows which individual USNs Server A is missing. Assuming also for now that the number of updates does not exceed the maximums specified by Server A in its metadata, Server B can supply all of the missing updates to Server A.
However, this entire set of updates may not need to go to Server A if Server A has already had some of them replicated from other servers. Server B now needs some way of knowing which updates Server A has already seen, so that it can remove those items from the list of updates to send. That’s where the up-to-dateness vector comes in. For each update that could potentially be sent, Server B checks two pieces of data attached to the object that was updated: the DSA GUID of the server that originated the update (the Originating-DC-GUID) and the USN associated with that update (the Originating-USN) on the originating server. For example, a password change to a user may have been replicated to Server B and recorded as USN 1112, but it may in fact have originated on Server D as USN 2345. Server B cross-references the originating server’s GUID with Server A’s UTDV to find the highest originating write USN for the originating server. If the USN recorded in the UTTV for the originating server is equal to or higher than the USN attached to the update on Server D, Server A must have already seen the update. This has to be true, because Server A’s UTDV is used to indicate the highest originating writes that Server A has received.
Let’s say that Server B has four updates for Server A: one originating write (Server B USN 1111) and three replicated writes (Server B USNs 1109, 1110, and 1112). The reason there are four is that 1112 is the last update made on Server B in this example, and the USN in Server A’s HWMV for xxxx on Server B from Figure 6-13 is 1108. So, we look for updates starting at 1109 up to the last update on Server B, which is 1112. The first two replicated writes (Server B USNs 1109 and 1110) originated on Server E (Server E USNs 567 and 788), and one (Server B USN 1112) originated on Server D (Server D USN 2345). This is shown in Table 6-9.
Server B USN | Originating-DC-GUID | Originating-DC-USN |
1109 | Server E’s GUID | 567 |
1110 | Server E’s GUID | 788 |
1111 | Server B’s GUID | 1111 |
1112 | Server D’s GUID | 2345 |
According to Figure 6-13, Server A already has Server D’s 2345 update, because the USN in Server A’s UTDV for Server D is 2350. So, both Server A and Server B already have Server D’s 2345 update, and there is no need to waste bandwidth sending it over the network again. (As mentioned earlier, the act of filtering previously seen updates to keep them from being continually sent between the servers is known as “propagation dampening.”)
Now that you know how the high-watermark vector and up-to-dateness vector help Server B to work out what updates need to be sent, let’s look at the exact process that Server B uses to work out what data is required.
When Server B receives a request for updates from Server A, the following steps occur:
Server B makes a copy of its up-to-dateness vector for Server A.
Server B puts the table to one side, so to speak, and does a search of the entire naming context for all objects with a
uSNChangedvalue greater than the USN value from Server A’s high-watermark vector entry for Server B. This list is then sorted into ascendinguSNChangedorder.Server B initializes an empty output buffer to which it will add update entries for sending to Server A. It also initializes a value called Last-Object-USN-Changed. This will be used to represent the USN of the last object sent in this particular replication session. This value is not an attribute of any particular object, just a simple piece of replication metadata.
Server B enumerates the list of objects in ascending
uSNChangedorder and uses the following algorithm for each object:If the object has already been added to the output buffer, Server B sets Last-Object-USN-Changed to the
uSNChangedproperty of the current object. Enumeration continues with the next object.If the object has not already been added to the output buffer, Server B tests the object to see if it contains changes that need to be sent to the destination. For each property of the current object, Server B takes the Originating-DC-GUID of that property and locates the USN that corresponds to that GUID from Server A’s UTDV. From that entry, Server B looks at the Originating-USN. If the property’s Originating-USN on Server B is greater than Server A’s UTDV entry, the property needs to be sent.
If changes need to be sent, an update entry is added to the output buffer. Server B sets Last-Object-USN-Changed to the
uSNChangedproperty of the current object. Enumeration continues with the next object.If no changes need to be sent, Server B sets Last-Object-USN-Changed to the
uSNChangedof the current object. Enumeration continues with the next object.
Note
During the enumeration, if the requested limit on object
update entries or values is reached, the enumeration terminates
early and a flag known as More-Data is set to
True. If the enumeration finishes without either
limit being hit, More-Data is set to
False.
Step 3: The partner sends the updates to the initiating server
Server B identifies the list of updates that it should send back
based on those that Server A has not yet seen from other sources.
Server B then sends this data to Server A. In addition, if
More-Data is set to False, one
extra piece of metadata is sent back. The returned information from
Server B includes:
The output buffer updates from Server B
Server B’s Last-Object-USN-Changed value (i.e., the value for Server A to insert into the high-watermark vector for the NC for Server B)
The
More-DataflagServer B’s up-to-dateness vector for this NC (sent only when
More-Datais set toFalse)
This is shown in Figure 6-14.

If Server B calculates that Server A is already up to date and requires no updates, only the last two pieces of metadata are returned to Server A. This can occur if the highest committed USN for the NC on Server B is identical to the HWMV entry passed by Server A (i.e., no updates have occurred since the last replication cycle), or if Server B’s highest committed USN for the NC has changed, but Server A has already seen all of the originating updates through replication with other partners. In both cases, just the metadata is returned.
Step 4: The initiating server processes the updates
Server A receives the data. For each update entry it receives,
Server A allocates a USN and starts a database transaction to update
the relevant object in its own copy of the Active Directory database.
The object’s uSNChanged property is
set to the USN of this transaction. The database transaction is then
committed. This process continues for each update entry that was
received.
After all the update entries have been processed, the USN in Server A’s high-watermark vector for Server B is set to the Last-Object-USN-Changed received from Server B. In other words, Server A now knows that it is up to date with Server B, up to the last change just sent over.
The Last-Object-USN-Changed that Server A receives allows it to know the last update that Server B has made. This will be used in the next replication cycle. In the previous example, the highest update sent across to Server A is USN 1111. Server B’s USN 1112 update is not actually sent since Server A has already seen it. However, the Last-Object-USN-Changed returned by Server B with the data would still be 1112 and not 1111.
Step 5: The initiating server checks whether it is up to date
Server A now checks the More-Data flag. If
More-Data is set to True, Server
A goes back to step 1 to start replication with Server B again and
request more updates. If More-Data is set to
False, every update must have been received from
Server B, and finally Server A’s up-to-dateness vector is itself
updated.
The up-to-dateness vector allows Server A to identify which originating updates Server B has seen and thus, by replication, which originating updates it has now seen. Server A does not replace its up-to-dateness vector with the one it was sent. Instead, it checks each entry in the received table and does one of two things. If the entry for a server is not listed in its own UTDV, it adds that entry to the table. This allows Server A to know that it has now been updated to a certain level for a new server. If the entry for a server is listed in Server A’s UTDV and the value received is higher, it modifies its own copy of the table with the higher value. After all, it has now been updated to this new level by that server, so it had better record that fact.
Table 6-10 shows Server A’s up-to-dateness vector and high-watermark vector for the xxxx naming context before step 1 and after step 5.
Recap
The following points summarize replication between naming contexts:
The high-watermark vector is used to detect updates that need to be sent between replication partners.
The up-to-dateness vector is used in propagation dampening to filter the updates so that only updates that the initiating server has not seen are transmitted from a partner.
The
uSNChangedproperty on each object is used to identify which objects might need to be sent out as updates to the initiating server.
Note
You can force manual replication of a particular NC on a DC if you choose, using the AD Sites and Services snap-in. Browse to the connection object that you want to replicate over, right-click it, and select Replicate Now. This can also be done from the command line with the repadmin utility.
With Windows PowerShell, you can use the Sync-ADObject cmdlet to force replication of a specific object. There is not, however, a cmdlet to synchronize an entire partition at once.
How Replication Conflicts Are Reconciled
While the replication process is usually fine on its own, there are times when conflicts can occur because two servers perform irreconcilable operations between replication cycles. For example, say Server A creates an object with a particular name at roughly the same time that Server B creates an object with the same name under the same parent container. Both can’t exist at the same time in Active Directory, so what happens to the two objects? Does one object get deleted or renamed? Do both objects get deleted or renamed?
What about an administrator moving an object on Server D to an organizational unit while at the same time on Server B that organizational unit is being deleted? What happens to the soon-to-be orphaned object? Is it deleted along with the organizational unit or moved somewhere else entirely?
Consider a final example: if an admin on Server B changes a user’s password while the user himself changes his password on Server C, which password does the user get?
All of these conflicts need to be resolved within Active Directory during the next replication cycle. The exact reconciliation process and how the final decision is replicated back out depend on the exact conflict that occurred.
Conflict due to identical attribute change
This scenario occurs when an attribute on the same object is updated on two different domain controllers at around the same time. During replication, each domain controller follows the following process to resolve the conflict:
The server starts reconciliation by looking at the version numbers of the two attributes. Whichever attribute has the higher version number wins the conflict.
If the property version numbers are equal, the server checks the timestamps of both attributes. Whichever attribute was changed at the later time wins the conflict.
If the attribute timestamps are equal, the GUIDs from the two originating servers are checked. As GUIDs must be unique, these two values have to be unique, so the server takes the attribute change from the originating server with the mathematically higher GUID as the winner of the conflict.
Note
All replication metadata timestamps for Active Directory are stored in Universal Time Coordinated (UTC), which is more commonly known as Greenwich Mean Time (GMT) or Zulu time.
Conflict due to a move or creation of an object under a now-deleted parent
This scenario occurs when an object is created on one server under a particular OU or container—for example, an OU called People—and meanwhile, on another server at about the same time, that OU is deleted.
This is a fairly easy conflict to resolve. In this case, the parent (the People OU) remains deleted, but the object is moved to the naming context’s Lost and Found container, which was specially set up for this scenario. The distinguished name of the Lost and Found container for the mycorp.com domain is:
cn=LostAndFound,dc=mycorp,dc=com
In addition to the Lost and Found container for the domain, every forest has a Lost and Found container for the configuration partition. For the mycorp.com forest, this would be found at:
cn=LostAndFoundConfig,cn=Configuration,dc=mycorp,dc=com
Conflict due to creation of objects with names that conflict
Recall that the relative distinguished name (RDN) for an object must be unique within the context of its parent container. This particular conflict occurs when two objects are created on two different servers with the same RDN. During replication, domain controllers take the following steps to resolve this conflict:
The server starts reconciliation by looking at the version numbers of the two objects. Whichever object has the higher version number wins the conflict.
If the object version numbers are equal, the server checks the timestamps of both objects. Whichever object was changed at the later time wins the conflict.
If both object timestamps are equal, the GUIDs from the two originating servers are checked. The server once again takes the object change from the originating server with the higher GUID as the winner of the conflict.
In this case, however, the object that lost the conflict resolution is not lost or deleted; instead, the conflicting attribute is modified with a known unique value. That way, at the end of the resolution, both objects exist, with one having its conflicting name changed to a unique value. The unique name has the following format: <ObjectName><LineFeed>CNF:<ObjectGUID>.
Warning
This logic is only used for the RDN naming value of the object
(usually the cn attribute). It is
not used for cleaning up other values that are normally required to
be unique, such as the sAMAccountName attribute that represents a
user’s username or a computer’s name. For more information on how
duplicate sAMAccountName values
are handled, see the upcoming sidebar How Active Directory Handles Duplicate Account
Values.
In the following example, a computer called PC04 has been renamed due to a conflict. This probably occurred after an administrator encountered an error joining the machine to the domain, and then subsequently tried again. During the subsequent try, the administrator connected to another domain controller before replication had occurred:
CN=PC04�ACNF:41968ad2-717e-4ffc-a876-04798d288ede,CN=Computers,DC=contoso,DC=com
Replicating the conflict resolution
Let’s say that Server A starts a replication cycle. First, it requests changes from Server B and receives updates. Then Server A requests changes from Server C and receives updates. However, as Server A is applying Server C’s updates in order, it determines that a conflict has occurred between these updates and the updates recently applied by Server B. Server A resolves the conflict according to the preceding guidelines and finds in Server C’s favor. Now, while Server A and Server C are correct, Server B still needs to be updated with Server C’s value.
To do this, when Server B next requests updates from Server A, it receives (among others) the update that originated on Server C. Server B then applies the updates it receives in sequence, and when it gets to the update that originated on Server C, it detects the same conflict. Server B then goes through the same conflict resolution procedure that Server A did and comes to the same result. So, it modifies its own copy of the object to accommodate the change.
Additional problems can occur when changes are made on a server and it goes down prior to replicating the changes. If the server never comes back up to replicate changes, those changes are obviously lost.
Note
Alternatively, if the server comes back up much later and attempts to replicate those changes back to Active Directory, there is a much greater chance of conflict resolution (with that server failing the conflict, if many of the changes that were made on that server have subsequently been made in Active Directory more recently on other servers). This isn’t a problem, but is something you need to be aware of.
6.3. Common Replication Problems
There are a couple of issues that often crop up in the field or in discussions of Active Directory replication. Neither of these are issues that you will want to run into, but, it’s important to be aware of them so you can recognize the symptoms and be prepared to respond.
Lingering Objects
Lingering objects appear when a domain controller that has been offline for longer than the tombstone lifetime of your forest comes back online and begins replicating again. We’ll talk about the concept of tombstone lifetime in detail in Chapter 18, but in a nutshell, it’s how long a record of deleted objects is preserved in the Active Directory database to ensure deletions are replicated. Depending on when your forest was created, your tombstone lifetime will likely be either 60 days or 180 days, assuming it hasn’t been modified from the default.
When a domain controller is offline for longer than the tombstone lifetime and is then reconnected, it will never receive notification of objects that were deleted while it was offline. As a result, those objects will not exist on any domain controller in the forest except the one that was brought back online. This can pose a problem in a number of ways. First, a user account that has been deleted (perhaps because the employee was terminated) will be available for use again if the specific domain controller is targeted. Next, old objects such as users and contacts that display in the global address list (GAL) if you’re using Exchange might start appearing again for certain users who get their view of the GAL from the domain controller in question. Printers published to Active Directory are another common example. Print queues are published and removed from the directory all the time as a matter of normal operation. End users searching AD for a printer in the site containing the domain controller with lingering objects may find themselves attempting to connect to printers that no longer exist.
In addition to these scenarios, you will often see replication-related event log entries on other domain controllers that make reference to the possibility of lingering objects in the forest. There are a couple of steps you can take to control the propagation of lingering objects, as well as to clean up a domain controller that has them.
First, enable strict replication consistency on all of your domain controllers. This setting causes a domain controller to quarantine a replication partner if it detects that an attempt has been made to replicate a lingering object. When a lingering object is replicated back into the forest, the deletion is essentially undone, and the object is restored to the state it is in on the domain controller that has the lingering object. This behavior is undesirable. To enable strict replication consistency, set this registry setting:
Path: HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesNTDSParameters Value Name: Strict Replication Consistency Value Type: REG_DWORD Value: 1
Note
You can use repadmin to enable strict replication consistency on every DC in your forest. To do this, run this command: repadmin /regkey * +strict.
To clean up lingering objects on a domain controller, the easiest solution is to simply demote the domain controller and then re-promote it. If you can’t do this, you can take advantage of the lingering object cleanup functionality in repadmin. You’ll need to choose a domain controller that will be the source of truth. Active Directory will check that each object on the domain controller you are cleaning up also exists on your “source of truth” DC.
To check DC17’s domain partition (contoso.com) for lingering objects against DC05, follow these steps:
Resolve the DSA GUID (boldfaced) of DC05 by running: repadmin /showrepl DC05. This produces output like the following:
SiteADC05 DSA Options: IS_GC Site Options: (none) DSA object GUID:
67c1ee19-4706-4c56-b1cb-3a299541376eDSA invocationID: 54770948-f0d3-44ed-ae26-291ab6200ed4Run the “remove lingering objects command” on DC17 in advisory mode to get a list of objects that will be removed:
repadmin /removelingeringobjects DC17 67c1ee19-4706-4c56-b1cb-3a299541376e dc=contoso,dc=com /advisory_mode
There are three arguments in the preceding command: the DC to check (DC17), the source DC’s DSA GUID (67c1...), and the DN of the partition to validate (dc=contoso,dc=com).
Review the events logged in DC17’s event log (events 1938, 1946, and 1942) for a list of objects that will be removed.
Run the remove lingering objects command again without the /advisory_mode switch to delete the lingering objects from DC17’s domain partition:
repadmin /removelingeringobjects DC17 67c1ee19-4706-4c56-b1cb-3a299541376e dc=contoso,dc=com
You will need to repeat these steps for each naming context that DC17 is hosting. This includes the Configuration NC, DNS NCs, and any Global Catalog partitions.
USN Rollback
As virtualization has become commonplace in IT, the concept of USN rollback has grown as a discussion topic and fear amongst many Active Directory administrators. USN rollback is a precarious situation that can lead to replication black holes and duplicate SIDs, amongst other issues. The most common avenues for running into USN rollback are rolling back virtual machine snapshots and the use of image-based disk backup programs. Microsoft has taken steps in every version of Active Directory to try to mitigate the impact of these operations, and Windows Server 2012 finally addresses many angles of this problem head-on. We’ll talk about the improvements Windows Server 2012 makes in Chapter 9, but for now we’ll focus on the impact on replication without consideration of those specific improvements.
As we discussed earlier, the USN should only ever move forward. Each time a domain controller starts a transaction, it increments the local USN counter so that the transaction can be identified. Another way to think of the USN is as a logical clock. If you think about a clock, the clock never moves backward. Consider a virtualized domain controller with its USN similar to Figure 6-15:
At USN 5, an administrator takes a snapshot of the virtual machine (VM).
A number of changes are made locally, and the USN advances to 9.
Next, the administrator rolls back the snapshot. The USN is now 5.
A number of changes are made once again, and they are assigned USNs 6 to 9.
Step 4 is the key here. The administrator has made changes that have the same USNs as previous changes. This leads to an inability for other DCs to keep track in their HWMV tables.
To put this into better perspective, recall how we discussed earlier that DCs keep track of the changes they’ve replicated from other DCs in their high-watermark vector tables. Let’s examine the previous scenario once more, factoring in the replication process as shown in Figure 6-16:
At T1, DC-A’s
highestCommittedUSNis100. DC-B’s HWMV reflects this and the two DCs are in sync.At T2, the administrator takes a snapshot of DC-A in the hypervisor.
At T3, the administrator creates 75 users on DC-A, incrementing DC-A’s
highestCommittedUSNto175. DC-B replicates these changes and updates its HWMV to reflect that it has replicated up to change 175 from DC-A.At T4, the administrator rolls DC-A back to its state prior to taking the snapshot. DC-A’s
highestCommittedUSNis now100once again.At T5, the administrator creates 15 users on DC-A, incrementing DC-A’s
highestCommittedUSNto 115. DC-B starts a replication cycle with DC-A by checking its HWMV and asking DC-A for any changes after USN 175. DC-A replies that it has no changes to send.
The net result here after T5 is that a set of objects exist on DC-A that will never replicate to DC-B. Until DC-A reaches USN 175, any changes made on DC-A will never replicate to DC-B. Since Windows Server 2003, Active Directory has attempted to detect when this scenario happens and quarantine replication so that the domain controller can be forcibly demoted and then re-promoted in order to get it back in sync with the rest of the forest. The good news is that, beginning with Windows Server 2012, virtualized DCs running on a hypervisor that provides a VM generation ID to the VM will not suffer from any rollback scenario that occurs within the state model of the hypervisor. Any “manual” snapshots that occur outside of the hypervisor’s knowledge can still produce a rollback scenario, though, such as reverting the underlying files in the disk subsystem.
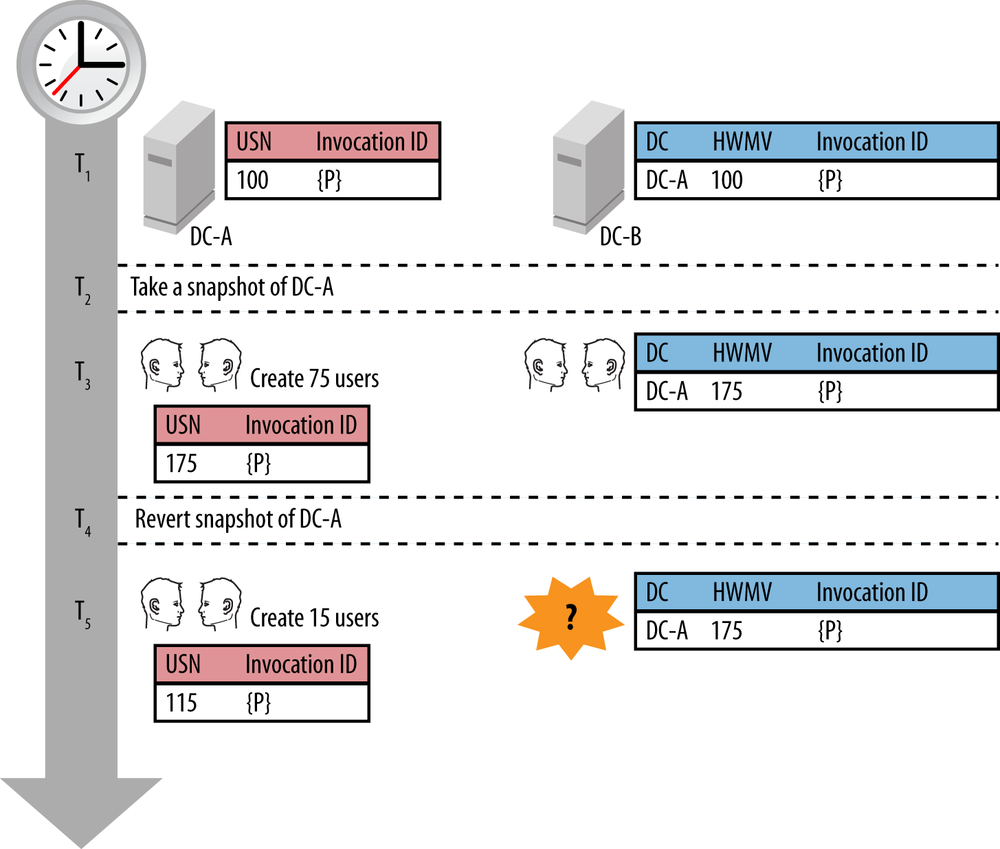
6.4. Summary
In this chapter, we looked at the importance of the site topology in Active Directory and how it relates to your physical network. We also considered the metadata that governs the replication process, how the system keeps track of changes to objects and properties automatically, how data is replicated among servers (including propagation dampening) and how conflicts are resolved.
In Chapter 14, we’ll take this knowledge further and show you how Active Directory manages and automatically generates the replication connections that exist both within and between sites. With that knowledge, we can move on to the design principles for sites and links in Active Directory.