
Chapter 4. Creating robust topologies
- Guaranteed message processing
- Fault tolerance
- Replay semantics
So far, we’ve defined many of Storm’s core concepts. Along the way, we’ve implemented two separate topologies, each of which runs in a local cluster. This chapter is no different in that we’ll be designing and implementing another topology for a new scenario. But the problem we’re solving has stricter requirements for guaranteeing tuples are processed and fault tolerance is maintained. To help us meet these requirements, we’ll introduce some new concepts related to reliability and failure. You’ll learn about the tools Storm gives us to handle failure, and we’ll also dive into the various types of guarantees we can make about processing data. Armed with this knowledge, we’ll be ready to venture out into the world and create production-quality topologies.
4.1. Requirements for reliability
In the previous chapter, our heat map application needed to quickly process a large amount of time-sensitive data. Further, merely sampling a portion of that data could provide us with what we needed: an approximation of the popularity of establishments within a given geographic area right now. If we failed to process a given tuple within a short time window, it lost its value. The heat map was all about right now. We didn’t need to guarantee that each message was processed—most was good enough.
But there are domains where this is strictly unacceptable; each tuple is sacred. In these scenarios, we need to guarantee that each and every one is processed. Reliability is more important than timeliness here. If we have to keep retrying a tuple for 30 seconds or 10 minutes or an hour (or up to some threshold that makes sense), it has just as much value in our system as it did when we first tried. There’s a need for reliability.
Storm provides the ability to guarantee that each tuple is processed. This serves as a reliability measure we can count on to ensure accurate implementation of functionality. On a high level, Storm provides reliability by keeping track of which tuples are successfully processed and which ones aren’t and then replaying the ones that have failed until they succeed.
4.1.1. Pieces of the puzzle for supporting reliability
Storm has many moving parts that need to come together in order to deliver reliability:
- A reliable data source with a correspondingly reliable spout
- An anchored tuple stream
- A topology that acknowledges each tuple as it’s processed or notifies you of the failure
- A fault-tolerant Storm cluster infrastructure
In this chapter, we’ll look at how the first three of these components fall into place to enable reliability. Then chapter 5 introduces you to the Storm cluster and talks about how it provides fault tolerance.
4.2. Problem definition: a credit card authorization system
When you think about using Storm to solve a problem within your domain, take time to think about what guarantees you need to have around processing; it’s an important part of “thinking in Storm.” Let’s dive into a problem that has a reliability requirement.
Imagine that we run a large e-commerce site that deals with shipping physical goods to people. We know that the vast majority of orders placed on our site are authorized for payment successfully and only a small percentage are declined. Traditionally in e-commerce, the more steps our user needs to take to place an order, the higher the risk of losing the sale. When we’re billing at the time an order is placed, we’re losing business. Handling billing as a separate, “offline” operation improves conversions and directly affects our bottom line. We also need this offline billing process to scale well to support peak seasons such as the holidays (think Amazon) or even flash sales (think Gilt).
This is a scenario that requires reliability. Each order has to be authorized before it’s shipped. If we encounter a problem during our attempts to authorize, we should retry. In short, we need guaranteed message processing. Let’s take a look at what such a system may look like, keeping in mind how we can incorporate retry characteristics.
4.2.1. A conceptual solution with retry characteristics
This system deals solely with authorizing credit cards related to orders that have already been placed. Our system doesn’t deal with customers placing orders; that happens earlier in the pipeline.
Assumptions on upstream and downstream systems
Distributed systems are defined by the interactions amongst different systems. For our use case we can assume the following:
- The same order will never be sent to our system more than once. This is guaranteed by an upstream system that handles the placing of customer orders.
- The upstream system that places orders will put the order on a queue and our system will pull the order off the queue so it can be authorized.
- A separate downstream system will handle a processed order, either fulfilling the order if the credit card was authorized or notifying the customer of a denied credit card.
With these assumptions in hand, we can move forward with a design that’s limited in scope but maps well to the Storm concepts we want to cover.
Formation of a conceptual solution
Let’s begin with how orders flow through our system. The following steps are taken when the credit card for an order must be authorized:
- Pull the order off the message queue.
- Attempt to authorize the credit card by calling an external credit card authorization service.
- If the service call succeeds, update the order status in the database.
- If it fails, we can try again later.
- Notify a separate downstream system that the order has been processed.
These steps are illustrated in figure 4.1.
Figure 4.1. Conceptual solution of the e-commerce credit card authorization flow

We have our basic flow. The next step in defining our problem is to look at the data points being worked with in our topology; with this knowledge, we can determine what’s being passed along in our tuples.
4.2.2. Defining the data points
With the flow of transactions defined, we can take a look at the data involved. The flow of data starts with incoming orders being pulled off a queue as JSON (see the following listing).
Listing 4.1. Order JSON
{
"id":1234,
"customerId":5678,
"creditCardNumber":1111222233334444,
"creditCardExpiration":"012014",
"creditCardCode":123,
"chargeAmount":42.23
}
This JSON will be converted into Java objects and our system will deal internally with these serialized Java objects. The next listing defines the class for this.
Listing 4.2. Order.java
public class Order implements Serializable {
private long id;
private long customerId;
private long creditCardNumber;
private String creditCardExpiration;
private int creditCardCode;
private double chargeAmount;
public Order(long id,
long customerId,
long creditCardNumber,
String creditCardExpiration,
int creditCardCode,
double chargeAmount) {
this.id = id;
this.customerId = customerId;
this.creditCardNumber = creditCardNumber;
this.creditCardExpiration = creditCardExpiration;
this.creditCardCode = creditCardCode;
this.chargeAmount = chargeAmount;
}
...
}
This approach of defining a problem in terms of data points and components that act on them should be familiar to you; it’s exactly how we broke down the problems in chapters 2 and 3 when creating our topologies. We now need to map this solution to components Storm can use to build our topology.
4.2.3. Mapping the solution to Storm with retry characteristics
Now that we have a basic design and have identified the data that will flow through our system, we can map both our data and our components to Storm concepts. Our topology will have three main components, one spout, and two bolts:
- RabbitMQSpout— Our spout will consume messages from the queue, where each message is JSON representing an order, and emit a tuple containing a serialized Order object. We’ll use RabbitMQ for our queue implementation—hence the name. We’ll delve into the details of this spout when we discuss guaranteed message processing later in this chapter.
- AuthorizeCreditCard— If the credit card was authorized, this bolt will update the status of the order to “ready-to-ship.” If the credit card was denied, this bolt will update the status of the order to “denied.” Regardless of the status, this bolt will emit a tuple containing the Order to the next bolt in the stream.
- ProcessedOrderNotification— A bolt that notifies a separate system that an order has been processed.
In addition to the spout, bolts, and tuples, we must define stream groupings for how tuples are emitted between each of the components. The following stream groupings will be used:
- Shuffle grouping between the RabbitMQSpout and AuthorizeCreditCard bolt
- Shuffle grouping between AuthorizeCreditCard bolt and the ProcessedOrder-Notification bolt
In chapter 2 we used a fields grouping to ensure the same GitHub committer email was routed to the same bolt instance. In chapter 3 we used a fields grouping to ensure the same grouping of geocoordinates by time interval was routed to the same bolt instance. We don’t need the same assurances; any given bolt instance can process any given tuple, so a shuffle grouping will suffice.
All of the Storm concepts we just discussed are shown in figure 4.2.
Figure 4.2. E-commerce credit card authorization mapped to Storm concepts
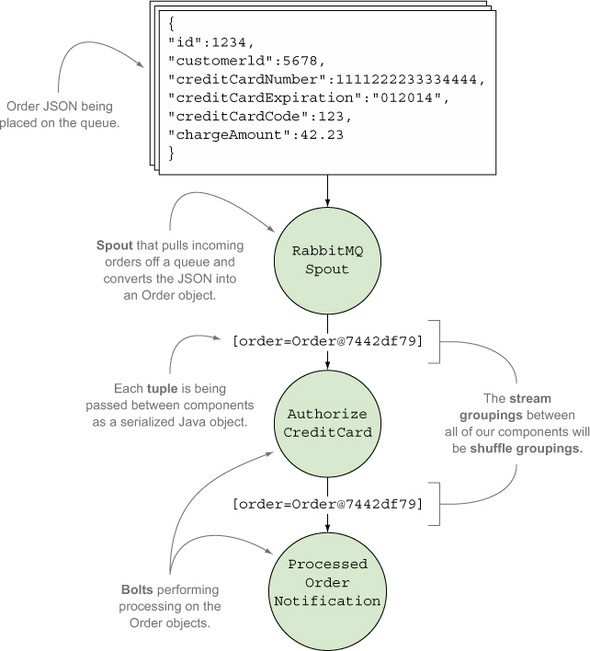
With an idea of what our topology looks like, we’ll next cover the code for our two bolts before getting into guaranteed message processing and what’s required to achieve it. We’ll discuss the code for the spout a bit later.
4.3. Basic implementation of the bolts
This section will cover the code for our two bolts: AuthorizeCreditCard and ProcessedOrderNotification. Understanding what’s happening within each of the bolts will provide some context when we discuss guaranteed message processing in section 4.4.
We’re leaving the implementation of the RabbitMQSpout for the end of the guaranteed message processing section because much of the code in the spout is geared toward retrying failed tuples. A complete understanding of guaranteed message processing will help you focus on the relevant parts of the spout code.
Let’s begin with a look at the first bolt in our topology: AuthorizeCreditCard.
4.3.1. The AuthorizeCreditCard implementation
The AuthorizeCreditCard bolt accepts an Order object from the RabbitMQSpout. This bolt then attempts to authorize the credit card by talking to an external service. The status of the order will be updated in our database based on the results of the authorization attempt. After that, this bolt will emit a tuple containing the Order object it received. Figure 4.3 illustrates where we are in the topology.
Figure 4.3. The AuthorizeCreditCard bolt accepts an incoming tuple from the RabbitMQSpout and emits a tuple regardless of whether or not the credit card was authorized.

The code for this bolt is presented in the next listing.
Listing 4.3. AuthorizeCreditCard.java

Once the billing has been approved or denied, we’re ready to notify the downstream system of the processed order; the code for this is seen next in ProcessedOrder-Notification.
4.3.2. The ProcessedOrderNotification implementation
The second and final bolt in our stream, ProcessedOrderNotification, accepts an Order from the AuthorizeCreditCard bolt and notifies an external system the order has been processed. This bolt doesn’t emit any tuples. Figure 4.4 shows this final bolt in the topology.
Figure 4.4. The ProcessedOrderNotification bolt accepts an incoming tuple from the AuthorizeCreditCard bolt and notifies an external system without emitting a tuple.

The following listing shows the code for this bolt.
Listing 4.4. ProcessedOrderNotification.java

After the downstream system has been notified of the processed order, there’s nothing left for our topology to do, so this is where the implementation of our bolts comes to an end. We have a well-defined solution at this point (minus the spout, which we’ll discuss next). The steps we took to come up with a design/implementation in this chapter match the same steps we took in chapters 2 and 3.
Where this implementation will differ from those chapters is the requirement to ensure all tuples are processed by all the bolts in the topology. Dealing with financial transactions is much different than GitHub commit counts or heat maps for social media check-ins. Remember the pieces of the puzzle needed for supporting reliability mentioned earlier in section 4.1.1?
- A reliable data source with a corresponding reliable spout
- An anchored tuple stream
- A topology that acknowledges each tuple as it’s processed or notifies us of the failure
- A fault-tolerant Storm cluster infrastructure
We are at a point where we can start addressing the first three pieces. So how will our implementation change in order to provide these pieces? Surprisingly, it won’t! The code for our bolts is already set up to support guaranteed message processing in Storm. Let’s examine in detail how Storm is doing this as well as take a look at our reliable RabbitMQSpout next.
4.4. Guaranteed message processing
What’s a message and how does Storm guarantee it gets processed? A message is synonymous with a tuple, and Storm has the ability to ensure a tuple being emitted from a spout gets fully processed by the topology. So if a tuple fails at some point in the stream, Storm knows a failure occurred and can replay the tuple, thus making sure it gets processed. The Storm documentation commonly uses the phrase guaranteed message processing, as will we throughout the book.
Understanding guaranteed message processing is essential if you want to develop reliable topologies. The first step in gaining this understanding is to know what it means for a tuple to be either fully processed or failed.
4.4.1. Tuple states: fully processed vs. failed
A tuple that’s emitted from a spout can result in many additional tuples being emitted by the downstream bolts. This creates a tuple tree, with the tuple emitted by the spout acting as the root. Storm creates and tracks a tuple tree for every tuple emitted by the spout. Storm will consider a tuple emitted by a spout to be fully processed when all the leaves in the tree for that tuple have been marked as processed. Here are two things you need to do with the Storm API to make sure Storm can create and track the tuple tree:
- Make sure you anchor to input tuples when emitting new tuples from a bolt. It’s a bolt’s way of saying, “Okay, I’m emitting a new tuple and here’s the initial input tuple as well so you can make a connection between the two.”
- Make sure your bolts tell Storm when they’ve finished processing an input tuple. This is called acking and it’s a bolt’s way of saying, “Hey Storm, I’m done processing this tuple so feel free to mark it as processed in the tuple tree.”
Storm will then have all it needs to create and track a tuple tree.
Though we call it a tuple tree, it’s actually a directed acyclic graph (DAG). A directed graph is a set of nodes connected by edges, where the edges have a direction to them. A DAG is a directed graph such that you can’t start at one node and follow a sequence of edges to eventually get back to that same node. Early versions of Storm only worked with trees; even though Storm now supports DAGs, the term “tuple tree” has stuck.
In an ideal world, you could stop here and tuples emitted by the spout would always be fully processed without any problems. Unfortunately, the world of software isn’t always ideal; you should expect failures. Our tuples are no different and will be considered failed in one of two scenarios:
- All of the leaves in a tuple tree aren’t marked as processed (acked) within a certain time frame. This time frame is configurable
at the topology level via the TOPOLOGY_MESSAGE_TIMEOUT_SECS setting, which defaults to 30 seconds. Here’s how you’d override this default when building your topology:
Config config = new Config(); config.setMessageTimeoutSecs(60);.
- A tuple is manually failed in a bolt, which triggers an immediate failure of the tuple tree.
We keep mentioning the phrase tuple tree, so let’s walk through the life of a tuple tree in our topology to show you how this works.
Going down the rabbit hole with Alice...or a tuple
Figure 4.5 starts things off by showing the initial state of the tuple tree after our spout emits a tuple. We have a tree with a single root node.
Figure 4.5. Initial state of the tuple tree
The first bolt in the stream is the AuthorizeCreditCard bolt. This bolt will perform the authorization and then emit a new tuple. Figure 4.6 shows the tuple tree after emitting.
Figure 4.6. Tuple tree after the AuthorizeCreditCard bolt emits a tuple

We’ll need to ack the input tuple in the AuthorizeCreditCard bolt so Storm can mark that tuple as processed. Figure 4.7 shows the tuple tree after this ack has been performed.
Figure 4.7. Tuple tree after the AuthorizeCreditCard bolt acks its input tuple

Once a tuple has been emitted by the AuthorizeCreditCard bolt, it makes its way to the ProcessedOrderNotification bolt. This bolt doesn’t emit a tuple, so no tuples will be added to the tuple tree. But we do need to ack the input tuple and thus tell Storm this bolt has completed processing. Figure 4.8 shows the tuple tree after this ack has been performed. At this point the tuple is considered fully processed.
Figure 4.8. Tuple tree after the ProcessedOrderNotification bolt acks its input tuple

With a clear definition of a tuple tree in mind, let’s move on to the code that’s needed in our bolts for anchoring and acking. We’ll also discuss failing tuples and the various types of errors we need to watch out for.
4.4.2. Anchoring, acking, and failing tuples in our bolts
There are two ways to implement anchoring, acking, and failing of tuples in our bolts: implicit and explicit. We mentioned earlier that our bolt implementations are already set up for guaranteed message processing. This is done via implicit anchoring, acking, and failing, which we’ll discuss next.
Implicit anchoring, acking, and failing
In our implementation, all of our bolts extended the BaseBasicBolt abstract class. The beauty of using BaseBasicBolt as our base class is that it automatically provides anchoring and acking for us. The following list examines how Storm does this:
- Anchoring— Within the execute() method of the BaseBasicBolt implementation, we’ll be emitting a tuple to be passed on to the next bolt. At this point of emitting, the provided BasicOutputCollector will take on the responsibility of anchoring the output tuple to the input tuple. In the AuthorizeCreditCard bolt, we emit the order. This outgoing order tuple will be automatically anchored to the incoming order tuple:
outputCollector.emit(new Values(order));
- Acking— When the execute() method of the BaseBasicBolt implementation completes, the tuple that was sent to it will be automatically acked.
- Failing— If there’s a failure within the execute() method, the way to handle that is to notify BaseBasicBolt by throwing a FailedException or ReportedFailed-Exception. Then BaseBasicBolt will take care of marking that tuple as failed.
Using BaseBasicBolt to keep track of tuple states through implicit anchoring, acking, and failing is easy. But BaseBasicBolt isn’t suitable for every use case. It’s generally helpful only in use cases where a single tuple enters the bolt and a single corresponding tuple is emitted from that bolt immediately. That is the case with our credit card authorization topology, so it works here. But for more complex examples, it’s not sufficient. This is where explicit anchoring, acking, and failing come into play.
Explicit anchoring, acking, and failing
When we have bolts that perform more complex tasks such as these
- Aggregating on multiple input tuples (collapsing)
- Joining multiple incoming streams (we won’t cover multiple streams in this chapter, but we did have two streams going through a bolt in the heat map chapter, chapter 3, when we had a tick tuple stream in addition to the default stream)
then we’ll have to move beyond the functionality provided by BaseBasicBolt. BaseBasicBolt is suitable when behavior is predictable. When you need to programmatically decide when a tuple batch is complete (when aggregating, for example) or at runtime decide when two or more streams should be joined, then you need to programmatically decide when to anchor, ack, or fail. In these cases, you need to use BaseRichBolt as a base class instead of BaseBasicBolt. The following list shows what needs to be done inside an implementation of a bolt extending BaseRichBolt:
- Anchoring— To explicitly anchor, we need to pass the input tuple into the emit() method on the outputCollector within the bolt’s execute method: outputCollector.emit(new Values(order)) becomes outputCollector.emit(tuple, new Values(order)).
- Acking— To explicitly ack, we need to call the ack method on the outputCollector within the bolt’s execute method: outputCollector.ack(tuple).
- Failing— This is achieved by calling the fail method on the outputCollector within the bolt’s execute method: throw new FailedException() becomes outputCollector.fail(tuple);
Although we can’t use BaseBasicBolt for all use cases, we can use BaseRichBolt for everything that the former can do and more because it provides more fine-grained control over when and how you anchor, ack, or fail. Our credit card authorization topology can be expressed in terms of BaseBasicBolt with desired reliability, but it can be written with BaseRichBolt just as easily. The following listing rewrites one of the bolts from our credit card authorization topology using BaseRichBolt.
Listing 4.5. Explicit anchoring and acking in AuthorizeCreditCard.java


One thing to note is that with BaseBasicBolt, we were given a BasicOutputCollector with each call of the execute() method. But with BaseRichBolt, we are responsible for maintaining tuple state by using an OutputCollector that will be provided via the prepare() method at the time of bolt initialization. BasicOutputCollector is a stripped-down version of OutputCollector; it encapsulates an OutputCollector but hides the more fine-grained functionality with a simpler interface.
Another thing to be mindful of is that when using BaseRichBolt, if we don’t anchor our outgoing tuple(s) to the incoming tuple, we’ll no longer have any reliability downstream from that point on. BaseBasicBolt did the anchoring on your behalf:
- Anchored—outputCollector.emit(tuple, new Values(order));
- Unanchored—outputCollector.emit(new Values(order));
Having covered anchoring and acking, let’s move on to something that isn’t as straightforward: handling errors. The act of failing a tuple itself is easy; it’s knowing when an error can be retried that requires some thought.
Handling failures and knowing when to retry
We’ve covered a lot of concepts related to guaranteed message processing. We have anchoring and acking down pat. But we have yet to address how we want to handle failures. We know that we can fail a tuple by either throwing a FailedException/ReportedFailedException (when using BaseBasicBolt) or calling fail on the OutputCollector (when using BaseRichBolt). Let’s look at this in the context of our AuthorizeCreditCard bolt, shown in the next listing. We’re showing only the changes to the execute() method that incorporate explicit failing.
Listing 4.6. Anchoring, acking, and failing in AuthorizeCreditCard.execute()

Failing a tuple in this way will cause the entire tuple tree to be replayed starting at the spout. This is the key to guaranteed message processing, because this is the main trigger for the retry mechanism. It’s important to know when a tuple should be failed. This seems obvious, but tuples should be failed when they’re retriable (can be retried). The question then becomes what can/should be retried. The following list discusses the various types of errors:
- Known errors— These can be broken down into two groups:
- Retriable— For known specific, retriable errors (say, a socket timeout exception while connecting to a service), we’ll want to fail the tuple so it gets replayed and retried.
- Nonretriable— For known errors that can’t be safely retried (like a POST to REST API) or when it doesn’t make sense for something to be retried (like a ParseException while handling JSON or XML), you shouldn’t fail the tuple. When you have one of these nonretriable errors, instead of failing the tuple you’ll need to ack the tuple (without emitting a new one), because you don’t want to engage the replay mechanism for it. We recommend some sort of logging or reporting here so you’ll know there was an error in your topology.
- Unknown errors— Generally, unknown or unexpected errors will be a small percentage of errors observed, so it’s customary to fail them and retry them. After you’ve seen them once, they become a known error (assuming logging is in place), and you can take action on them as either a retriable or nonretriable known error.
Note
Having data on errors within a Storm topology can be useful, as you’ll see in chapter 6 when we discuss metrics.
This brings our discussion of anchoring, acking, and failing in our bolts to a close. Now it’s time to shift gears and move to the spout. We mentioned that when the replay mechanism gets engaged, the replaying starts at the spout and works its way down. Let’s see how that works.
4.4.3. A spout’s role in guaranteed message processing
So far our focus has been centered on what we need to do in our bolts to achieve guaranteed message processing. This section will complete the sequence and discuss the role a spout plays in guaranteeing a tuple it emits gets fully processed or replayed on failure. The next listing shows the spout interface from chapter 2.
Listing 4.7. ISpout.java interface

How does a spout tie into guaranteeing messages are processed? Here’s a hint: The ack ![]() and fail
and fail ![]() methods have something to do with it. The following steps give a more complete picture in terms of what happens before a
spout emits a tuple and after that tuple is either fully processed or failed:
methods have something to do with it. The following steps give a more complete picture in terms of what happens before a
spout emits a tuple and after that tuple is either fully processed or failed:
- Storm requests a tuple by calling nextTuple
 on the spout.
on the spout.
- The spout uses the SpoutOutputCollector to emit a tuple to one of its streams.
- When emitting the tuple, the spout provides a messageId that’s used to identify that particular tuple. This may look something like this:
spoutOutputCollector.emit(tuple, messageId);.
- The tuple gets sent to the bolts downstream and Storm tracks the tuple tree of messages that are created. Remember, this is done via anchoring and acking within the bolts so Storm can build up the tree and mark leaves as processed.
- If Storm detects that a tuple is fully processed, it will call the ack
 method on the originating spout task with the message ID the spout provided to Storm.
method on the originating spout task with the message ID the spout provided to Storm.
- If the tuple timed out or one of the consuming bolts explicitly failed the tuple (such as in our AuthorizeCreditCard bolt), Storm will call the fail
 method on the originating spout task with the message ID the spout provided to Storm.
method on the originating spout task with the message ID the spout provided to Storm.
Steps 3, 5, and 6 are the keys to guaranteed message processing from a spout’s perspective. Everything starts with providing a messageId when emitting a tuple. Not doing this means Storm can’t track the tuple tree. You should add code to the ack method to perform any required cleanup for a fully processed tuple, if necessary. You should also add code to the fail method to replay the tuple.
Storm uses special “acker” tasks to keep track of tuple trees in order to determine whether a spout tuple has been fully processed. If an acker task sees a tuple tree is complete, it’ll send a message to the spout that originally emitted the tuple, resulting in that spout’s ack method being called.
It looks like we need to write an implementation of a spout that supports all these criteria. In the previous chapter, we introduced the concept of an unreliable data source. An unreliable data source won’t be able to support acking or failing. Once that data source hands your spout a message, it assumes you’ve taken responsibility for that message. A reliable data source, on the other hand, will pass messages to the spout but won’t assume you’ve taken responsibility for them until you’ve provided an acknowledgment of some sort. In addition, a reliable data source will allow you to fail any given tuple with the guarantee that it will later be able to replay it. In short, a reliable data source will support steps 3, 5, and 6.
The best way to demonstrate how a reliable data source’s capabilities tie into a spout API is to implement a solution with a commonly used data source. Kafka, RabbitMQ, and Kestrel are all commonly used with Storm. Kafka is a valuable tool in your arsenal of infrastructure that works great with Storm, which we’ll cover in detail in chapter 9. For now we’re going with RabbitMQ, which is an excellent match for our use case.
A reliable spout implementation
Let’s go over a RabbitMQ-based spout implementation that’ll provide all the reliability we need for this use case.[1] Keep in mind our main point of interest isn’t RabbitMQ, but rather how a well-implemented spout together with a reliable data source provide guaranteed message processing. If you don’t follow the underpinnings of the RabbitMQ client API, don’t worry; we’ve emphasized the important parts that you need to follow in the next listing.
1 You can find a more robust, configurable, and performant implementation of the spout implementation for RabbitMQ on GitHub at https://github.com/ppat/storm-rabbitmq.
Listing 4.8. RabbitMQSpout.java


Storm gives you the tools to guarantee the tuples being emitted by your spout are fully processed while they’re in transit within the Storm infrastructure. But for guaranteed message processing to take effect, you must use a reliable data source that has the capability of replaying a tuple. Additionally, the spout implementation has to make use of the replay mechanism provided by its data source. Understanding this is essential if you want to be successful with guaranteed message processing in your topologies.
The topologies we created in earlier chapters didn’t take advantage of guaranteed message processing or fault tolerance. We may have used BaseBasicBolt in those chapters and that may have bought us implicit anchoring and acking, but our tuples in those chapters didn’t originate from a reliable spout. Because of the unreliable nature of those data sources, when we emitted tuples at the spout, they were sent “unanchored” via outputCollector.emit(new Values(order)). When you don’t anchor to the input tuple starting from the spout, it can’t guarantee that they’ll be fully processed. This is because replaying always starts at the spout. So the decision to emit tuples unanchored should always be a conscious one, as we made in the heat map example.
We’re now ready to write a robust topology and introduce it to the world. We’ve covered three pieces of the puzzle needed for supporting reliability:
- A data source with a corresponding reliable spout
- An anchored tuple stream
- A topology that acknowledges each tuple as it gets processed or notifies of failure
But before moving on to chapter 5 to discuss the last piece of the puzzle—the Storm cluster—let’s talk about replay semantics and whether our current topology implementation is good enough for what we want.
4.5. Replay semantics
Each of the four pieces of the puzzle to reliability plays a key role and is necessary if we want to build a robust topology. But when you consider the replay characteristics of streams as they flow through your topology, you’ll begin to recognize that Storm provides varying guarantees of reliability when it comes to event processing. We can assign different semantics to reliability when we become aware of different requirements being met by our streams. Let’s take a look at these varying degrees of reliability.
4.5.1. Degrees of reliability in Storm
Much like we saw different kinds of scaling problems when we carefully examined data streams in chapter 3, we see varying degrees of reliability when we carefully examine our topology design. We identify three degrees of reliability here:
- At-most-once processing
- At-least-once processing
- Exactly-once processing
Let’s elaborate a little further what we mean by each of these.
At-most-once processing
You’d use at-most-once processing when you want to guarantee that no single tuple ever gets processed more than once. In this case, no replaying will ever happen. If it succeeds, great, but if it fails the tuple will be discarded. Regardless, this semantic provides no reliability that all operations will be processed, and it’s the simplest semantic you can choose. We used at-most-once processing in the preceding chapters, because those use cases didn’t dictate a need for reliability. We may have used BaseBasicBolt (with its automated anchoring and acking) in previous chapters, but we didn’t anchor the tuples when we first emitted them from the spout.
You don’t need to do anything special to achieve this type of reliability in Storm, which isn’t true for our next degree of reliability.
At-least-once processing
At-least-once processing can be used when you want to guarantee that every single tuple must be processed successfully at least once. If a single tuple is replayed several times, and for some reason it succeeds more than once, that’s okay under this replay semantic. Your primary concern is that it must succeed, even if that means doing redundant work.
To achieve at-least-once processing in Storm, you need a reliable spout with a reliable data source and an anchored stream with acked or failed tuples. This leads us to the strictest degree of reliability.
Exactly-once processing
Exactly-once processing is similar to at-least-once processing in that it can guarantee that every tuple is processed successfully. But exactly-once processing takes care to ensure that once a tuple is processed, it can’t be processed ever again.
As with at-least-once processing, you need a reliable spout with a reliable data source and an anchored stream with acked or failed tuples. But what sets this degree apart from at-least-once processing is that you also need logic in your bolt(s) to guarantee tuples are processed only once.
To understand what each type of processing requires of your system, it’s important to understand the subtleties and problems that arise from our most stringent of options: exactly once.
4.5.2. Examining exactly once processing in a Storm topology
There’s a lot of complexity hiding behind that simple phrase exactly once. This means that you have to be able to know whether you’ve already done a unit of work, which in turn means that you have to do the following:
- Do the unit of work.
- Record that you’ve done the unit of work.
Further, these two steps must be performed as an atomic operation—you can’t do the work and then fail to record the result. You need to be able to do the work and record that it was done in one step. If you can do the work but have a failure before recording that the work was done, then you don’t actually have exactly once—you have usually once. The vast majority of the time, the work will be done one time, but from time to time, it’ll be done more often. That’s an exceedingly rigorous qualification to meet.
At-least-once processing shares the same two steps, except that these operations aren’t required to occur atomically. If for some reason a failure occurs during or immediately after performing your unit of work, it is okay to redo the work and reat-tempt to record the result. If it isn’t okay to redo the work, then you need to add an important requirement: the end result of your unit of work must be idempotent. An action is idempotent when performed more than once, it has no additional effect on its subject after the first time it’s performed. For example:
- “Set x to 2” is an idempotent operation.
- “Add 2 to variable x” isn’t an idempotent operation.
Operations with external side effects such as sending an email are decidedly non-idempotent. Repeating that unit of work would send more than one email and is assuredly not what you want to do.
If your unit of work is non-idempotent, then you must fall back to at-most-once processing. You want to do the unit of work, but it’s more important that the result of this work not be duplicated than doing the actual work.
4.5.3. Examining the reliability guarantees in our topology
How can we provide a stricter degree of reliability in our topology? Do we even need to, or are we already in a good enough state? To answer these questions, it makes sense to identify what level of reliability our topology is currently at.
Identifying the current level of reliability
Which type of processing do we have with our topology? We have guaranteed message processing so that if we have a failure, we’ll retry the tuple. This rules out at-most-once as our semantics. That’s good. We certainly want to charge people for the goods we’re shipping them.
Do we have exactly-once semantics or at-least-once semantics? Let’s break this down. Our “unit of work” is charging a customer’s credit card along with updating the status of the order. This is seen in the following listing.
Listing 4.9. Examining the execute() method of AuthorizeCreditCard.java

The question is this: are the two steps a single atomic operation? The answer is no. It’s possible for us to charge a user’s
credit card and then not update the order status. Between charging the credit card ![]() and changing the order status (
and changing the order status (![]() ,
, ![]() ), a couple of things could happen:
), a couple of things could happen:
- Our process could crash.
- The database might be unavailable to record the result.
This means we don’t have exactly-once semantics; we have at-least-once. Looking at our topology as it currently stands, that’s problematic. Retrying a tuple can result in multiple charges to a customer’s card. What can we do to lessen this danger? We know that exactly-once is impossible for us, but we should be able to make at-least-once safer.
Providing better at-least-once processing when authorizing an order
The first question we want to ask ourselves in making our at-least-once processing safer is whether our operation can be made idempotent. The answer is probably not. We’d need the external credit card service’s assistance with that. If we could provide the order ID as a unique transaction identifier and the service would throw an error such as DuplicateTransactionException, then we could update our records to indicate the order is ready to ship and continue processing. Handling such an error is seen in the following listing.
Listing 4.10. Updating AuthorizeCreditCard.java to handle a DuplicateTransactionException

Without that external cooperation, what’s the best we can do? If our process crashes between charging a customer and recording that we charged, there isn’t anything we can do but accept that it’ll happen from time to time and be prepared to address it in a nontechnical fashion (such as customer service responding to a refund request). Realistically, if our system is stable, this should be a relatively rare occurrence.
For the “system of record being unavailable” scenario, we can add a partially preventive measure. We can verify the database for storing the updated order status is available before attempting to charge the credit card. This approach reduces the chance of a situation arising where we charge the credit card and then fail to update the order status because the database is down.
In general, this is good practice. If you’re computing a non-idempotent result within a topology and will then store “doneness,” verify at the time you begin your unit of work that you’ll be able record it. This check can be seen in the next listing.
Listing 4.11. Updating AuthorizeCreditCard.java to check for database availability before processing

So we’ve improved our reliability, but we have a feeling we can do better. Looking back at our steps, we have the following:
- Authorize the credit card.
- Update the order status.
- Notify an external system of the change.
Looks like there’s more work to do to address step 3.
Providing better at-least-once processing across all steps
What happens if we manage to do the first two steps but we experience a failure while doing the third? Perhaps our process crashes; perhaps our tuple times out before notifying the external system. However it happens, it has happened, and Storm is going to replay the tuple. So what can we do to address this scenario?
Before processing the credit card, we should assure that the system of record is available (as we did previously) and verify that the order status isn’t already “ready to ship.” If the order isn’t ready to ship, then we proceed as normal. It’s probably the first time we’re trying this order and the database is up and running. If the order is ready to ship, then we probably had a failure between our “update order status” and “notify external system” steps. In that case, we would want to skip charging the card again and move directly to notifying the external system of the change.
If we control this external system, then we can make a request to ship the same order more than once an idempotent operation where subsequent attempts are dropped. If not, the caveats we encountered earlier around lack of idempotence of credit card processing applies as well.
The steps in our conceptual framework have changed somewhat; step 2 is new:
- Pull the order off the message queue.
- Determine whether the order has been marked as “ready to ship” and do one of two things:
- If the order has been marked as “ready to ship,” skip to step 6.
- If the order hasn’t been marked as “ready to ship,” continue to step 3.
- Attempt to authorize the credit card by calling an external credit card authorization service.
- If the service call succeeded, update the order status.
- If it fails, we can try again later.
- Notify a separate downstream system that the order has been processed.
These updated steps are illustrated in figure 4.9, with the new steps highlighted.
Figure 4.9. Conceptual solution of the e-commerce credit card authorization flow with an extra step for providing better at-least-once processing

We could map this conceptual solution onto our topology in a couple ways:
- Add a new bolt that performs the status verification step. We could call this something like VerifyOrderStatus.
- Perform the status verification step in the AuthorizeCreditCard bolt.
We’ll choose option number two and update the AuthorizeCreditCard bolt to perform the verification step. We’ll leave adding a new VerifyOrderStatus bolt as an exercise for you. The following listing shows the updated code for AuthorizeCreditCard.
Listing 4.12. Updating AuthorizeCreditCard.java to check the order status before processing

And just like that, we’re done. Or are we? We missed something here. We still need to always notify the external system when we are done processing the order even if “done” just means that we checked that the order was ready to ship and did nothing. The updated code for this can be seen in the next code listing; we just need to emit a tuple with the order whenever we “process” it.
Listing 4.13. Updating AuthorizeCreditCard.java to emit a tuple whenever an order is “processed”

This brings us to a solution we feel comfortable with. And although we haven’t been able to achieve exactly-once processing, we have been able to achieve a better at-least-once processing by including some additional logic in our AuthorizeCreditCard bolt. Follow this process whenever you’re designing a topology with reliability requirements. You need to map out your basic conceptual problem and then figure out what your semantics are, at least once or at most once. If it’s at least once, start looking at all the ways it can fail and make sure you address them.
4.6. Summary
In this chapter, you learned that
- The varying degrees of reliability you can achieve in Storm are
- At-most-once processing
- At-least-once processing
- Exactly-once processing
- Different problems require varying levels of reliability, and it’s your job as a developer to understand the reliability requirements of your problem domain.
- Storm supports reliability with four main parts:
- A reliable data source with a corresponding reliable spout
- An anchored tuple stream
- A topology that acknowledges each tuple as it gets processed or notifies of failure
- A fault-tolerant Storm cluster infrastructure (to be addressed next)
- Storm is able to tell if a tuple emitted by a spout is fully processed by tracking a tuple tree for that tuple.
- In order for Storm to be able to track a tuple tree, you must anchor input tuples to output tuples and ack any input tuples.
- Failing a tuple either via a timeout or manually will trigger the retry mechanism in Storm.
- Tuples should be failed for known/retriable errors and unknown errors. Tuples should not be failed for known/non-retriable errors.
- A spout must be implemented to explicitly handle and retry failures while being hooked up to a reliable data source in order to truly achieve guaranteed message processing.