
Chapter 9. Trident
This chapter covers
- Trident and why it’s useful
- Trident operations and streams as a series of batched tuples
- Kafka, its design, and how it aligns with Trident
- Implementing a Trident topology
- Using Storm’s distributed remote procedure call (DRPC) functionality
- Mapping native Storm components to Trident operations via the Storm UI
- Scaling a Trident topology
We’ve come a long way in Storm Applied. Way back in chapter 2 we introduced Storm’s primitive abstractions: bolts, spouts, tuples, and streams. Over the course of the first six chapters, we dug into those primitives, covering higher-level topics such as guaranteed message processing, stream groupings, parallelism, and so much more. Chapter 7 provided a cookbook approach to identifying various types of resource contention, whereas chapter 8 took you to a level of abstraction below Storm’s primitive abstractions. Understanding all of these concepts is essential to mastering Storm.
In this chapter we’ll introduce Trident, the high-level abstraction that sits on top of Storm’s primitives, and discuss how it allows you to express a topology in terms of the “what” instead of the “how.” We’ll explain Trident within the context of a final use case: an internet radio application. But rather than start with the use case as we have in previous chapters, we’ll start by explaining Trident. Because Trident is a higher-level abstraction, we feel understanding that abstraction before designing a solution for the use case makes sense, as that understanding may influence the design for our internet radio topology.
This chapter will start with an explanation of Trident and its core operations. We’ll then talk about how Trident handles streams as a series of batches, which is different than native Storm topologies, and why Kafka is a perfect match for Trident topologies. At that point we’ll break out a design for our internet radio application followed by its associated implementation, which will include Storm’s DRPC functionality. Once we have the implementation, we’ll discuss scaling a Trident topology. After all, Trident is simply an abstraction that still results in a topology that must be tweaked and tuned for maximum performance.
Without further ado, we’ll introduce you to Trident, the abstraction that sits on top of Storm’s primitives.
9.1. What is Trident?
Trident is an abstraction on top of Storm primitives. It allows you to express a topology in terms of the “what” (declarative) as opposed to the “how” (imperative). To achieve this, Trident provides operations such as joins, aggregations, groupings, functions, and filters, along with providing primitives for doing stateful, incremental processing on top of any database or persistence store. If you’re familiar with high-level batch-processing tools like Pig or Cascading, the concepts of Trident will be familiar to you.
What does it mean to express computations using Storm in terms of what you want to accomplish rather than how? We’ll answer this question by taking a look at how we built the GitHub commit count topology in chapter 2 and comparing it to a Trident version of this same topology. As you may remember from chapter 2, the goal of the GitHub commit count topology was to read in a stream of commit messages, where each message contained an email, and keep track of the count of commits for each email.
Chapter 2 described the GitHub commit count topology in terms of how to count commit messages per email. It was a mechanical, imperative process. The following listing shows the code for building this topology.
Listing 9.1. Building a GitHub commit count Storm topology

Looking at how this topology is built, you can see that we ![]() assign a spout to the topology to listen for commit messages,
assign a spout to the topology to listen for commit messages, ![]() define our first bolt to extract emails from each commit message,
define our first bolt to extract emails from each commit message, ![]() tell Storm how tuples are sent between our spout and first bolt,
tell Storm how tuples are sent between our spout and first bolt, ![]() define our second bolt that keeps a running count of the number of emails, and end with
define our second bolt that keeps a running count of the number of emails, and end with ![]() , where we tell Storm how tuples are sent between our two bolts.
, where we tell Storm how tuples are sent between our two bolts.
Again, this is a mechanical process, one that’s specific to “how” we’re solving the commit count problem. The code in the listing is easy to follow because the topology itself isn’t complicated. But that may not be the case when looking at more complicated Storm topologies; understanding what’s being done at a higher level can become difficult.
This is where Trident helps. With its various concepts of “join,” “group,” “aggregate,” and so forth, we express computations at a higher level than bolts or spouts, making it easier to understand what’s being done. Let’s show what we mean by taking a look at a Trident version of the GitHub commit count topology. Notice how the code is expressed more in terms of the “what” we’re doing rather than “how” it’s being done in the following listing.
Listing 9.2. Building a GitHub commit count Trident topology

Once you understand Trident’s concepts, it’s much easier to understand our computation than if we expressed it in terms of
spouts and bolts. Even without a great deal of understanding of Trident, we can see that we ![]() create a stream coming from a spout, and for each entry in the stream
create a stream coming from a spout, and for each entry in the stream ![]() , we split the field commit into a number of email field entries, group like emails together
, we split the field commit into a number of email field entries, group like emails together ![]() , and persist a count of the emails
, and persist a count of the emails ![]() .
.
If we were to come across the code in this listing, we’d have a much easier time understanding what was going on compared to the equivalent code using the Storm primitives we have so far. We’re expressing our computation at much closer to a pure “what” level with far less “how” mixed in.
The code in this listing touches on a few of Trident’s abstractions that help you write code that expresses the “what” instead of the “how.” Let’s take a look at the full range of the operations Trident provides.
9.1.1. The different types of Trident operations
We have a vague idea of what it means to use Trident to express our code in terms of the “what” instead of the “how.” In the code in the previous section, we had a Trident spout emit a stream to be transformed by a series of Trident operations. The combination of these operations adds up to form a Trident topology.
This sounds similar to a Storm topology built on top of Storm’s primitives (spouts and bolts), except that we’ve replaced a Storm spout with a Trident spout and Storm bolts with Trident operations. This intuition isn’t true. It’s important to understand that Trident operations don’t directly map to Storm primitives. In a native Storm topology, you write your code within a bolt that performs your operation(s). You’re given a unit of execution that’s a bolt and you’re afforded the freedom to do whatever you see fit within that. But with Trident, you don’t have that flexibility. You’re provided with a series of stock operations and need to figure out how to map your problem onto one or more of these stock operations, most likely chaining them together.
Many different Trident operations are available that you can use to implement your functionality. From a high level, they can be listed as follows:
- Functions— Operate on an incoming tuple and emit one or more corresponding tuples.
- Filters— Decide to keep or filter out an incoming tuple from the stream.
- Splits— Splitting a stream will result in multiple streams with the same data and fields.
- Merges— Streams can be merged only if they have the same fields (same field names and same number of fields).
- Joins— Joining is for different streams with mostly different fields, except for one or more common field(s) to join on (similar to a SQL join).
- Grouping— Group by specific field(s) within a partition (more on partitions later).
- Aggregation— Perform calculations for aggregating sets of tuples.
- State updater— Persist tuples or calculated values to a datastore.
- State querying— Query a datastore.
- Repartitioning— Repartition the stream by hashing on specific field(s) (similar to a fields grouping) or in a random manner (similar to a shuffle grouping). Repartitioning by hashing on some specific field(s) is different from grouping in that repartitioning happens across all partitions whereas grouping happens within a single partition.
Representing your problem as a series of these operations allows you to think and reason at a much higher level than what the native Storm primitives allow. It also makes the Trident API for wiring in these different operations together feel much like a domain-specific language (DSL). For example, let’s say you have a step where you need to save your calculated results to a datastore. At that step, you’d wire in a state updater operation. Whether that state updater operation is writing to Cassandra, Elasticsearch, or Redis is completely irrelevant. In fact, you can have a state updater operation that writes to Redis and share that among different Trident topologies.
Hopefully you’re starting to gain an understanding of the types of abstractions Trident provides. Don’t worry about how these various operations are implemented right now. We’ll cover that soon when we dig into the design and implementation of our internet radio topology. But before we get into designing that topology, we need to cover one more topic: how Trident handles streams. This is fundamentally different from how a native Storm topology handles streams and will influence the design of our internet radio topology.
9.1.2. Trident streams as a series of batches
One fundamental difference between a Trident topology and a native Storm topology is that within a Trident topology, streams are handled as batches of tuples, whereas in a native Storm topology, streams are handled as a series of individual tuples. This means that each Trident operation processes a batch of tuples whereas each native Storm bolt executes on a single tuple. Figure 9.1 provides an illustration of this.
Figure 9.1. Trident topologies operate on streams of batches of tuples whereas native Storm topologies operate on streams of individual tuples.

Because Trident handles streams as batches of tuples, it falls under the category of micro-batching tools discussed in chapter 1. As you’ll recall from that chapter, micro-batching is a hybrid between batch processing and stream processing.
This fundamental difference in how Trident treats streams as a series of batches is why there are operations and not bolts in Trident. We think in terms of the stream and the series of operations we can apply to that stream. The operations discussed in section 9.1.1 will modify either the tuples that flow within the stream or the stream itself. In order to understand Trident, you must understand both streams and operations within Trident.
Next we’ll discuss a message queue implementation that’s well suited for use with Trident. It matches Trident’s needs so closely that it’s bundled with Storm to be used with Trident topologies.
9.2. Kafka and its role with Trident
Storm maintains a unique relationship with Apache Kafka when it comes to message queues that serve as a source of input. That’s not to say that other message queue technologies can’t be used. We’ve been careful throughout the book to point out how Storm can be used with a number of different technologies, such as RabbitMQ and Kestrel. What sets Kafka apart from other message broker implementations? It boils down to the core architectural decisions made during the creation of Kafka. To help you understand what makes Kafka such a good fit with Trident, we’re going to briefly discuss Kafka’s design and then talk about what characteristics of this design align well with Trident.
9.2.1. Breaking down Kafka’s design
This section will briefly dive into Kafka’s design, but only as far as is necessary for you to understand why it’s relevant to Storm and Trident.
Note
We use some standard Kafka terminology throughout this chapter. Two of the terms more commonly used are 1) topic, which is a feed of messages for a particular category and 2) broker, which is a server/node that’s usually one of many running in a Kafka cluster.
The Kafka website describes itself in two ways, both of which serve as clues to why the design fits well with Trident:
- It’s a publish-subscribe message broker, rethought as a distributed commit log.
- It’s a distributed, partitioned, replicated commit log service that provides the functionality of a messaging system, but with a unique design.
Let’s talk about each of these, because understanding these basic design decisions will help you see how Kafka aligns with Trident.
Partitioning for distributing a Kafka topic
When a message producer writes to a Kafka topic, it writes a given message to a particular partition of that topic. A partition is an ordered, immutable sequence of messages that’s continually being appended to. A topic can have multiple partitions, and these partitions can be distributed across multiple Kafka brokers. A message consumer will read from each partition in order to see the entire topic. Figure 9.2 illustrates a single topic distributed across multiple partitions.
Figure 9.2. Distribution of a Kafka topic as group of partitions on many Kafka brokers

By partitioning a topic, Kafka gains the ability to scale a single topic beyond a single broker (node) for both reads and writes. Each of the partitions can additionally be replicated to provide resiliency. This means that if you have n replicas for a partition, you can lose up to n – 1 replicas without suffering any data loss.
Having multiple partitions and being able to scale those partitions are important concepts to grasp when it comes to Trident. As you’ll see later in this chapter, this maps well with how a Trident topology reads data from a stream. But before we get ahead of ourselves, we should elaborate a bit more on how Kafka stores messages.
Modeling storage as a commit log
The storage model Kafka uses for messages within a topic yields many advantages—in both terms of performance and functional characteristics. We know from the previous section that a partition is an ordered, immutable sequence of messages on the filesystem. This represents a commit log. Each message within the partition is assigned a sequential identifier, called an offset, which marks where in the commit log each message is stored.
Kafka also maintains an ordering of messages within a partition, so strong ordering is guaranteed when a single consumer is reading from the partition. A message consumer reading from a particular partition will then maintain its own reference to its current position, known as that consumer’s offset into the commit log. Figure 9.3 illustrates offsets for multiple partitions.
Figure 9.3. A partition contains an immutable, ordered sequence of messages, where the consumers reading these messages maintain offsets for their read positions.

Kafka doesn’t discard messages after a consumer advances its offset; they’re kept in the log for a configured time period (such as 24 hours or 7 days). Once that time interval elapses, Kafka will compact the log and purge any older entries.
You should now have a general idea of how Kafka’s design works. A topic serves as a feed of messages for a particular category. This topic can then be broken into multiple partitions, which are immutable, ordered sequences of messages. These partitions can each be distributed across different brokers in the Kafka cluster. We’ll now elaborate on some of the advantages of this design in terms of both functionality and performance.
The functional and performance advantages of Kafka’s design
The functional advantages of this design include the following:
- Because messages aren’t discarded immediately and the consumer decides when or when not to advance its offset into the commit log, it’s easy to replay any messages from Kafka.
- Similarly, if your consumers fall behind for a long time and it no longer makes sense to consume those queued messages due to some consume-by-deadline requirements, it makes it easy to advance the offset by a large number into a new read position to skip all the expired messages.
- If your consumer acts on messages in batches and needs to complete the batch all at once or not at all, this can be accomplished by advancing the offset for a batch of sequential messages from a partition in one go.
- If you have different applications that need to subscribe to the same messages from a topic, consumers can easily read these different applications from that topic’s same set of partitions. This is facilitated because a message isn’t discarded after one consumer is done with it but rather the consumer controls its own offset into the commit log.
- On the other hand, if you want to ensure that only a single consumer consumes each message, you can do so by pinning a single consumer instance to a particular partition of a topic.
The performance advantages include the following:
- Whether your message bus ends up being bottlenecked by the message producer or the message consumer, that bottleneck can be easily addressed by increasing the number of partitions.
- The sequential and immutable nature of the commit log along with the sequential nature of the consumer’s offset advancement
pattern (in most cases) buys us many performance advancements:
- Disk access is often expensive but in most cases this is due to the random access nature that’s common among most applications. Because Kafka is designed from the ground up to make use of sequential access to data in the filesystem, modern operating systems will make efficient use of that by way of read-ahead caches and write-behind caching to give you large strides in performance improvements.
- Kafka makes excellent use of the OS disk cache. This allows Kafka to sidestep maintaining expensive caches in-process and not subject itself to garbage collection pressure.
We have a decent picture of Kafka’s general design along with the advantages, both functional and performance-related, that this design provides. It’s time to identify how Kafka aligns with Trident, making it such a great choice for Trident that it now comes bundled with Storm.
9.2.2. Kafka’s alignment with Trident
You’re probably able to imagine how wonderfully Storm would benefit from both the functional and performance advantages of Kafka. Kafka provides a performance advantage that’s an order of magnitude over its competition. For that reason alone, Kafka is the message bus of choice for native Storm. But when used with Trident, it’s clear why it’s such a good choice as the messaging implementation:
- Because Trident performs micro-batching within a stream, it relies on being able to manage a batch of tuples atomically. By allowing Trident to advance its consumer offset, Kafka supports this functionality.
- Messages aren’t discarded, so by rewinding the offset, you can replay messages from any point in time (up to Kafka’s log expiry time interval). This allows Kafka to behave as a reliable data source on which you can build a reliable spout, both for Trident and native Storm.
- As we’ll see later, Trident can use Kafka partitions to serve as a primary means of parallelism within a Trident topology.
- A Storm spout implemented for Kafka can maintain its consumer offsets for the different partitions in Zookeeper, so when your Storm or Trident topology is restarted or redeployed, you can continue processing from the place where you left off.
Let’s pause for a moment and see what we’ve covered so far. By now, you should understand the following:
- Trident provides an abstraction on top of Storm’s primitives, allowing you to write code that expresses “what” is being done rather than “how” to do it.
- Trident streams are handled as a series of batches of tuples rather than individual tuples, one at a time.
- Trident has operations, instead of bolts, that you apply to streams. These operations include functions, filters, splits, merges, joins, grouping, aggregation, state updater, state querying, and repartitioning.
- Kafka is the ideal queuing implementation for Trident topologies.
We’re finally ready to dive into our use case and apply all of these Trident principles to our design and implementation. As we go through the use case, try to keep in mind Trident’s operations and how it handles streams, because this will help steer our design.
9.3. Problem definition: Internet radio
Let’s say we want to start an internet radio company. We want to be conscientious about paying fair royalties to artists for their music that gets streamed through our internet radio platform. To do this, we decide to keep track of play counts for individual songs by artist. These counts can later be queried for use within reporting and for assigning royalties. In addition to paying royalties, we’re fairly ambitious and want to be able to query/report on the types of music our users prefer in order to provide them with the best possible experience when using our application.
Our users will be listening to our internet radio on various devices and on the web. These applications will collect “play logs” and send that information to us to be streamed into our topology from our Trident spout.
With this problem definition in hand, let’s take a look at the starting and ending data points, much like we’ve done in previous chapters.
9.3.1. Defining the data points
For our scenario, each play log will be streamed into our topology as JSON containing the artist, the title of the song, and a list of tags relevant to the song. The next listing provides an example of a single play log.
Listing 9.3. Sample play log entry for the stream of play logs
{
"artist": "The Clash",
"title": "Clampdown",
"tags": ["Punk","1979"]
}
The play log JSON gives us a starting point for our data. We want to persist three different types of counts: counts by artist, by title, and by tag. Trident provides a TridentState class that we’ll use for this. We’ll get more into TridentState later—what’s important now is that you understand the data we start with and where we want to end up.
With the data defined, the next step is to define the series of steps we need to go from a feed of play logs to the counts stored in TridentState instances.
9.3.2. Breaking down the problem into a series of steps
We’ve established that we’ll start with a play log and end with counts for artist, title, and tag. In forming a conceptual solution, we need to identify all the steps between our start and end.
Remember earlier when we said to keep in mind the various Trident operations when discussing the design for our use case? This is where we’ll look at those operations and see which make sense in our scenario. We end up with the following:
- A spout that emits a Trident stream. Remember that a Trident stream consists of batches of tuples as opposed to individual tuples.
- A function that deserializes (splits) incoming play logs into tuple batches for artist, title, and tag.
- Separate functions to count each of the artists, titles, and tags respectively.
- Trident state to persist the counts by artist, title, and tag, respectively.
These steps are illustrated in figure 9.4, which illustrates our design goal. Next we need to implement the code for the Trident operations that we’ll apply to the stream of tuple batches containing play logs.
Figure 9.4. Trident topology for internet radio application

9.4. Implementing the internet radio design as a Trident topology
At this point, we’re ready to implement a Trident topology that meets our design goal established in figure 9.4. You’ll notice as we start to go through the implementation that much of the code for our topology is handled within the topology builder class (TopologyBuilder). Although we do implement some functions for the operations used, the TopologyBuilder is where you’ll see the code expressed in terms of the “what” rather than the “how.”
Let’s start with the spout for our topology. Fortunately for us, Storm comes with a built-in spout implementation that we can use, saving ourselves some time.
9.4.1. Implementing the spout with a Trident Kafka spout
We’ll use the Trident Kafka spout that comes with the official Storm distribution. Figure 9.5 shows where this Trident Kafka spout will be used in the topology.
Figure 9.5. The Trident Kafka spout will be used for handling incoming play logs.

Although the implementation details of this spout are outside the scope of this chapter, we’ll show you the code for wiring up this spout in the TopologyBuilder class in the next listing.
Listing 9.4. Wiring up a TransactionalTridentKafkaSpout in the TopologyBuilder

We now have a spout implementation that will emit batches of play logs. The next step is to implement our first operation that will take the JSON for each tuple in the batch and transform that JSON into separate tuple batches for artist, title, and tags.
9.4.2. Deserializing the play log and creating separate streams for each of the fields
The next step to implement in the design is to take the batches of incoming play-log tuples and emit batches of tuples for each of the fields we’re interested in counting: artist, title, and tag. Figure 9.6 illustrates the batches of input tuples, our operation, and batches of output tuples, with each batch being emitted on a separate stream.
Figure 9.6. Operation for deserializing JSON into Trident tuples for each of the artist, title, and tags fields

Looking at the figure, you can see we need to do two things: 1) convert the JSON into separate tuples for the artist, title, and tags fields, and 2) create a separate stream for each of those fields. For the first task, we’re going to take a look at the each operation.
Trident provides an each operation that can be applied to each tuple, one at a time. The each operation can be used with a function or a filter. In our scenario, an each function seems like the appropriate choice, because we’re transforming the JSON into Trident tuples for artist, title, and tag. If we needed to filter out any data for some reason, then a filter would be a more appropriate choice.
Implementing an each function
A function takes in a set of input fields and emits zero or more tuples. If it doesn’t emit anything, the original tuple is filtered out. When using an each function, the fields of the output tuple are appended to the input tuple. The following listing provides the code for implementing an each function for our topology.
Listing 9.5. TopologyBuilder.java with an each function for deserializing the play logs

The new stream will contain the fields play-log, artist, title, and tags. The each function LogDeserializer is built by providing an implementation for the Base-Function abstract class, and will deserialize the input tuple with a JSON string into the required output. Implementing a BaseFunction is similar to implementing a Base-BasicBolt in native Storm. The following listing shows the implementation.
Listing 9.6. LogDeserializer.java


When you define an each function as stream.each(inputFields, function, output-Fields), only a subset of fields (represented by inputFields) from the original stream is sent into the function (the rest become inaccessible within the function). This is called projection. Projections make it extremely easy to avoid issues that people commonly encounter with having sent unnecessary fields into a function.
You can also use the project(..) method on the stream to remove any unnecessary fields that are hanging around after an operation. In our case we have the play-log field as part of the stream after the LogDeserializer operation and we don’t need the original JSON anymore. It’s better to get rid of it; keeping unnecessary data in memory will affect efficiency (particularly in Trident because we’re treating a stream as a series of batches and that involves keeping more data in memory within a JVM than a regular Storm topology):
playStream = playStream.project(new Fields("artist", "title", "tags"));
As we mentioned earlier, we must do two things: 1) convert the JSON into separate tuples, which we’ve now done, and 2) create a separate stream for each of those fields. Let’s take a look at that second task next.
Splitting a stream and grouping the fields
If we were to end our implementation right now, we’d have a single stream containing batches of tuples with four values. This is because of the following in LogDeserializer:
collector.emit(new Values(logEntry.getArtist(),
logEntry.getTitle(),
logEntry.getTags()));
Figure 9.7 illustrates where we currently are versus where we want to be.
Figure 9.7. We want to move from a stream with tuples containing multiple values to multiple streams with tuples containing single values.

Fortunately for us, splitting a stream is easy. We hold multiple references for the stream from the split origination point and then continue to apply different Trident operations to those references, as shown in the next listing.
Listing 9.7. Splitting the stream originating from LogDeserializer into three separate streams

We have code for creating separate streams, but there isn’t anything to those streams. They’re just references to the originating playStream. We need to associate each of those streams with the fields we’re interested in splitting on. This is where grouping the tuples by field name comes into play.
Grouping tuples by field name
Trident provides a groupBy operation we can use for grouping together tuples with the same field name. A groupBy operation first repartitions the stream so that tuples with the same selected field values fall within the same partition. Within each partition, it then groups the tuples together whose group fields are equal. The code for performing these groupBy operations is in the next listing.
Listing 9.8. Grouping by artist, title, and tag in the three split streams

ListSplitter is an each function implemented in a similar manner to LogDeserializer. The difference is that ListSplitter splits the tags list into individual tag tuples.
Now that we’ve split the streams and performed a grouping on each of the artist, title, and tag fields, we’re ready to calculate the counts for each of these fields.
9.4.3. Calculating and persisting the counts for artist, title, and tag
The next step is to aggregate the artist, title, and tag tuples in order to calculate the counts for each. Figure 9.8 provides a reminder of where we are in the topology design.
Figure 9.8. Counting each of the artist, title, and tag values and persisting those values to a store

According to figure 9.8, there are basically two steps here: 1) aggregate the tuples by value for each stream to perform the counts, and 2) persist the counts. Let’s start by looking at three different ways to aggregate tuples and identify the one that’s best for our scenario.
Choosing an aggregator implementation for performing the counts
There are three ways to aggregate tuples, each with its own interface for defining how it should be implemented:
-
A CombinerAggregator calls the init
 method for each tuple, and then uses the combine
method for each tuple, and then uses the combine  method to combine each tuple’s init value and returns a result. If there are no tuples to aggregate, it returns the zero
method to combine each tuple’s init value and returns a result. If there are no tuples to aggregate, it returns the zero  value.
value.
-
A ReducerAggregator calls the init method just once for the aggregation, and then calls reduce with each tuple and current value.
just once for the aggregation, and then calls reduce with each tuple and current value.
-
Aggregator public interface Aggregator<T> extends Operation { T init(Object batchId, TridentCollector collector); void aggregate(T state, TridentTuple tuple, TridentCollector collector); void complete(T state, TridentCollector collector); }An Aggregator is a more low-level abstraction interface for implementing more complex aggregations. Please refer to the Storm documentation for more information.
The majority of the time, you’ll use CombinerAggregator or ReducerAggregator. If the initial value for the entire aggregation isn’t dependent on any single tuple, then you’ll have to use ReducerAggregator. Otherwise, we suggest CombinerAggregator because it’s more performant.
When you’re running an aggregate operation with a ReducerAggregator- or an Aggregator-based implementation, a repartitioning of the stream takes place so that all partitions are collapsed into one and the aggregation takes place on that one partition. But if you use a CombinerAggregator-based implementation (as we do with Count), Trident will perform partial aggregations on the current partitions and then repartition the stream into one stream and complete aggregation by further aggregating the partially aggregated tuples. This is far more efficient because fewer tuples have to cross the wire during the repartition. CombinerAggregator should always be preferred because of this reason; the only time you’ll have to resort to ReducerAggregator is when you need to seed an aggregation with an initial value independent of the tuples.
For our scenario, let’s use a built-in aggregator called Count that implements Combiner-Aggregator. This is a simple implementation that will allow us to count artists, titles, and tags within our groupings. The next listing shows the implementation for Count.
Listing 9.9. Built-in Count.java that implements CombinerAggregator.java

We know that we’ll be using the Count class to perform the actual counts, but we still need to wire up Count instances somewhere in our TopologyBuilder. Let’s look at various ways to do this next.
Choosing an aggregate operation to work with our aggregator implementation
Trident provides three ways to use an aggregator with a stream:
- partitionAggregate— This operation takes on the single responsibility of aggregating tuples and works only within a single partition. This operation
results in a Stream containing the aggregate result tuple(s). The code for setting up partition-Aggregate is as follows:
Stream aggregated = stream.partitionAggregate(new Count(), new Fields("output")); - aggregate— This operation takes on the single responsibility of aggregating tuples and works across all partitions within a single batch
of tuples. The operation results in a Stream containing the aggregate result tuple(s). The code for setting up aggregate is as follows:
Stream aggregated = stream.aggregate(new Count(), new Fields("output")); - persistentAggregate— This operation applies across multiple batches and takes on the dual responsibility of aggregating the tuples and persisting
the results. It will persist the aggregated results to a datastore managed by a <state-factory>. A state factory is Trident’s abstraction for working with a datastore. Because it works with state, persistentAggregate can work across batches. It does this by aggregating the current batch from the stream and then aggregating that value with
the current value in the datastore. This operation results in a TridentState that can be queried against. The code for setting up persistentAggregate is as follows:
TridentState aggregated = stream.persistentAggregate(<state-factory>, new Count(), new Fields("output"));
In this list, the Count aggregator could be replaced with any CombinerAggregator, ReducerAggregator, or Aggregator implementation.
Which of these aggregation operations best suits our needs? Let’s start with partition-Aggregate. We know that partitionAggregate works within a single partition, so we must figure out if we need to aggregate within a single partition. We’ve already applied a groupBy operation to group tuples by a field (artist, title, and tag) and then count the number of tuples within that group across the entire batch. This means we’re going across partitions, making partitionAggregate not the choice for us.
Next up is aggregate. The aggregate operation works across all partitions within a batch of tuples, which is what we need. But if we decide to use aggregate, we’ll need to apply another operation to persist the aggregated results. So aggregate can work if we decide to take on additional work and build more that allows us to aggregate across batches and persist the results.
We have a feeling there’s a better choice for our scenario, which brings us to persistent-Aggregate. The name alone gives us the feeling that it might be the operation we need. We need to both aggregate counts and then persist those aggregated results. Because persistentAggregate works with state and thus works across batches, it feels like the perfect choice for our scenario. In addition, persistentAggregate leaves us with a TridentState object that can be queried against, making it easy for us to build the various reports we discussed earlier in the problem definition.
We’ve settled on persistentAggregate for our solution, but there’s one last piece we need to define before we’re done. Let’s look at the code for persistent-Aggregate again:
TridentState aggregated = stream.persistentAggregate(<state-factory>,
new Count(),
new Fields("output"));
We still need a <state-factory>, which we’ll discuss next.
Working with state
We need an implementation of StateFactory when dealing with state in Trident. This StateFactory serves as an abstraction that knows both how to query and update a datastore. For our scenario, we’re going to choose MemoryMapState.Factory, which is bundled with Trident. MemoryMapState.Factory works with an in-memory Map and will serve our needs fine for now. The code for wiring up this factory can be seen in the following listing.
Listing 9.10. Using a persistentAggregate operation to update/persist counts in TopologyBuilder.java


That brings the basic implementation of our Trident topology to a close. We’re now at a place where we have in-memory counts for all of the fields we’re interested in: artist, title, and tag. We’re done now; ready to move on, right? Well, not quite. We’d hate to leave you hanging with these in-memory counts that you have no way of accessing. Let’s look at a way to implement access to these counts. It will come in the form of Storm’s DRPC functionality.
9.5. Accessing the persisted counts through DRPC
Now that we have TridentState objects with counts by artist, title, and tag, we can query these state objects to build the reports we need. We want our reporting application to be external to Storm, so this reporting application needs to be able to query this topology to get the data it needs. We’ll make use of distributed remote procedure calls (DRPC) for this purpose.
In Storm DRPC, the client will invoke a DRPC request with a Storm DRPC server, which will coordinate the request by sending it to the corresponding Storm topology and wait for the response from that topology. Once it receives the response, it will communicate that back to the calling client. This in effect acts as a distributed query by querying for multiple artists or tags in parallel and summing up the results.
This section covers the three parts of Storm DRPC required to implement our solution for querying the counts:
- Creating a DRPC stream
- Applying a DRPC state query to the stream
- Using the DRPC client to make DRPC calls via Storm
We’ll start our explanation with the DRPC stream.
9.5.1. Creating a DRPC stream
When the Storm DRPC server receives a request, it needs to route it to our topology. For our topology to be able handle this incoming request, it needs a DRPC stream. The Storm DRPC server will route any incoming requests to this stream. The DRPC stream is given a name that’s intended to be the name of this distributed query we want to execute. The DRPC server will identify which topology (and which stream within that topology) to route incoming requests based on this name. The next listing shows how to create a DRPC stream.
Listing 9.11. Creating a DRPC stream
topology.newDRPCStream("count-request-by-tag")
The DRPC server accepts arguments for a DRPC function as text and forwards it along with the request to this DRPC stream. We need to parse the textual arguments into a form that we can make use of within the DRPC stream. The following listing defines the contract for the arguments for our count-request-by-tag DRPC stream to be a comma-delimited list of tags we want to query by.
Listing 9.12. Defining the contract for the arguments for the DRPC stream
topology.newDRPCStream("count-request-by-tag")
.each(new Fields("args"),
new SplitOnDelimiter(","),
new Fields("tag"));
Listing 9.12 references an each function called SplitOnDelimiter, so let’s take a look at that class’s implementation, as shown in the following listing.
Listing 9.13. SplitOnDelimiter.java

This gives us a basic DRPC stream to work with. The next step is to apply a state query to this stream.
9.5.2. Applying a DRPC state query to a stream
The state query we want to execute in response to this DRPC request is to count the number of play logs by given tag arguments. Let’s refresh our memory of how we calculated TridentState for the tags before we continue, as shown in the next listing.
Listing 9.14. Creating the counts-by-tag stream resulting in TridentState
TridentState countsByTag = playStream
.each(new Fields("tags"),
new ListSplitter(),
new Fields("tag"))
.project(new Fields("tag"))
.groupBy(new Fields("tag"))
.persistentAggregate(new MemoryMapState.Factory(),
new Count(),
new Fields("tag-count"));
We stored the counts by a given tag in an in-memory map with the tag as the key and count as the value. Now all we need to do is look up the counts for the tags we received as arguments for the DRPC query. This is achieved through the stateQuery operation on the DRPC stream. An explanation of the stateQuery operation can be seen in figure 9.9.
Figure 9.9. Breaking down the stateQuery operation

As the figure illustrates, the QueryFunction we choose needs to know how to access the data through the TridentState object. Fortunately for us, Storm comes with a built-in MapGet query function that can work with our MemoryMapState implementation.
But implementing this state query isn’t as simple as adding the stateQuery operation to the end of our DRPC stream. The reason for that is in our original play stream, we repartitioned the stream using a groupBy operation on the tag field. In order to send count-request-by-tag requests from the DRPC stream into the same partition that contains the needed tag in the TridentState, we need to apply a groupBy operation on the DRPC stream as well, on the same tag field. The next listing provides the code for this.
Listing 9.15. Looking up counts-by-tag by querying a source of state

Now we have the results of the count for each tag that we wanted. We can stop here in the DRPC stream and be done. Optionally, we can append an additional each operation to filter out null counts (that is, tags that haven’t yet been encountered on the play stream), but we’ll leave the nulls as something to be handled by the DRPC caller.
This brings us to our final step: being able to communicate with Storm via a DRPC client.
9.5.3. Making DRPC calls with a DRPC client
Making a DRPC request to this topology can be done by including Storm as a dependency in your client application and using the DRPC client built into Storm. Once you’ve done this, you can use something similar to the code in the next listing for making the actual DRPC request.
Listing 9.16. Performing a DRPC request

DRPC requests are made over the Thrift protocol, so you’ll need to handle the Thrift-related errors (usually connectivity-related) as well as DRPCExecutionException errors (usually feature-related). And that’s it. We haven’t left you hanging. You now have a topology that maintains state with the counts for various fields of artist, title, and tag, and you’re able to query that state. We’ve built a fully functional topology using Trident and Storm DRPC.
Or is that it? If you’ve learned anything from earlier chapters, it’s that once you’ve deployed your topology, your job as a developer hasn’t ended. The same holds true here. Section 9.6 discusses how Trident operations map to Storm primitives using the Storm UI to identify the spouts and bolts that are created under the covers. Section 9.7 will then touch upon scaling a Trident topology.
9.6. Mapping Trident operations to Storm primitives
Recall that in the beginning of the chapter we discussed how Trident topologies are built on top of the Storm primitives that we’ve become comfortable with over the course of this book. With our use case complete, let’s take a look at how Storm turns our Trident topology into bolts and spouts. We’ll start by looking at how our topology, sans our DRPC spout, is mapped down to Storm primitives. Why not just look at everything at once? We feel it will be easier to understand what exactly is going on by addressing the core Trident streams first and then tacking on the DRPC stream.
Without our DRPC spout, our TopologyBuilder code can be seen in the following listing.
Listing 9.17. TopologyBuilder.java without the DRPC stream
public TopologyBuilder {
public StormTopology build() {
TridentTopology topology = new TridentTopology();
Stream playStream = topology
.newStream("play-spout", buildSpout())
.each(new Fields("play-log"),
new LogDeserializer(),
new Fields("artist", "title", "tags"))
.each(new Fields("artist", "title"),
new Sanitizer(new Fields("artist", "title")));
TridentState countByArtist = playStream
.project(new Fields("artist"))
.groupBy(new Fields("artist"))
.persistentAggregate(new MemoryMapState.Factory(),
new Count(),
new Fields("artist-count"));
TridentState countsByTitle = playStream
.project(new Fields("title"))
.groupBy(new Fields("title"))
.persistentAggregate(new MemoryMapState.Factory(),
new Count(),
new Fields("title-count"));
TridentState countsByTag = playStream
.each(new Fields("tags"),
new ListSplitter(),
new Fields("tag"))
.project(new Fields("tag"))
.groupBy(new Fields("tag"))
.persistentAggregate(new MemoryMapState.Factory(),
new Count(),
new Fields("tag-count"));
return topology.build();
}
...
}
When our Trident topology is being turned into a Storm topology, Storm takes our Trident operations and packages them into bolts in a way that’s efficient. Some operations will be grouped together into the same bolts whereas others will be separate. The Storm UI provides a view into how that mapping is being done (figure 9.10).
Figure 9.10. Our Trident topology broken down into spouts and bolts in the Storm UI

As you can see, we have one spout and six bolts. Two of the bolts have the name “spout” in them and four others are labeled b-0 to b-3. We can see some components there but we have no idea how they’re related to our Trident operations.
Rather than try to figure out the mystery behind the names, we’ll show you a way to make it easier to identify the components. Trident has a name operation that assigns a name we specify to an operation. If we name each collection of operations in our topology, our code ends up like that in the next listing.
Listing 9.18. TopologyBuilder.java with named operations
public TopologyBuilder {
public StormTopology build() {
TridentTopology topology = new TridentTopology();
Stream playStream = topology
.newStream("play-spout", buildSpout())
.each(new Fields("play-log"),
new LogDeserializer(),
new Fields("artist", "title", "tags"))
.each(new Fields("artist", "title"),
new Sanitizer(new Fields("artist", "title")))
.name("LogDeserializerSanitizer");
TridentState countByArtist = playStream
.project(new Fields("artist"))
.groupBy(new Fields("artist"))
.name("ArtistCounts")
.persistentAggregate(new MemoryMapState.Factory(),
new Count(),
new Fields("artist-count"));
TridentState countsByTitle = playStream
.project(new Fields("title"))
.groupBy(new Fields("title"))
.name("TitleCounts")
.persistentAggregate(new MemoryMapState.Factory(),
new Count(),
new Fields("title-count"));
TridentState countsByTag = playStream
.each(new Fields("tags"),
new ListSplitter(),
new Fields("tag"))
.project(new Fields("tag"))
.groupBy(new Fields("tag"))
.name("TagCounts")
.persistentAggregate(new MemoryMapState.Factory(),
new Count(),
new Fields("tag-count"));
return topology.build();
}
...
}
If we take a look at our Storm UI, what’s going on becomes much more apparent (figure 9.11).
Figure 9.11. Our Trident topology displayed on the Storm UI after naming each of the operations

We can see that our b-3 bolt was log deserialization and sanitation. And our b-0, b-1, and b-2 bolt our title, tag, and artist counting, respectively. Given the amount of clarity that using names provides, we recommend you always name your partitions.
What’s up with the name of the log deserialization bolt? LogDeserializer-Sanitizer-ArtistCounts-LogDeserializerSanitizer-TitleCounts-Log-Deserializer-Sanitizer-TagCounts—what a mouthful! But it does provide us with a great deal of information. The name indicates that we’re getting our data from the log deserializer and sanitizer and feeding into artist counts, title counts, and tag counts. It’s not the most elegant of discovery mechanisms but it beats just b-0 and so on.
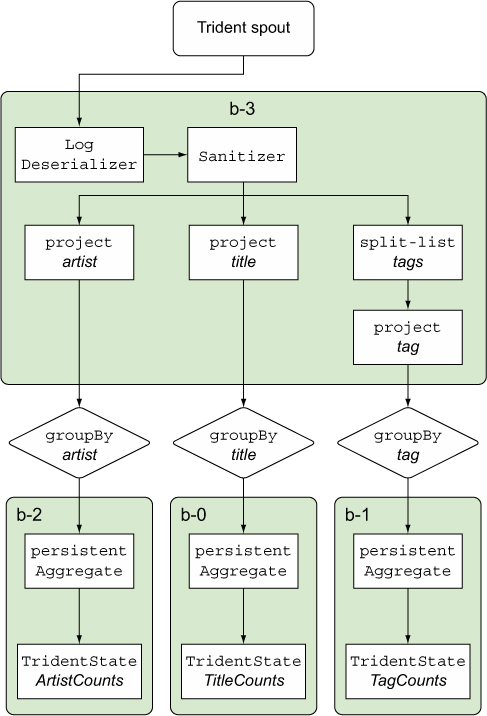
With this additional clarity, take a look at figure 9.12, which illustrates how our Trident operations are mapped down into bolts. Now let’s add back the DRPC stream with relevant names as well. The code for this appears in the next listing.
Figure 9.12. How our Trident operations are mapped down into bolts
Listing 9.19. The DRPC stream with named operations
topology.newDRPCStream("count-request-by-tag")
.name("RequestForTagCounts")
.each(new Fields("args"),
new SplitOnDelimiter(","),
new Fields("tag"))
.groupBy(new Fields("tag"))
.name("QueryForRequest")
.stateQuery(countsByTag,
new Fields("tag"),
new MapGet(),
new Fields("count"));
Adding the DRPC stream with named operations results in the Storm UI seen in figure 9.13.
Figure 9.13. The Storm UI with named operations for both the Trident topology and DRPC stream

What has changed? Well...
Our log sanitizer bolt is now b-2 rather than b-3. This is very important. You can’t rely on the autogenerated bolt names remaining the same when you make changes to the number of bolts in the topology.
The number of named bolts has increased from 4 to 5 and the names of those bolts have changed.
We have some unnamed bolts. What’s going on with the bolt name changes? The addition of our DRPC spout has changed the mapping onto Storm primitives and names have changed accordingly. Figure 9.14 shows the final mapping of Trident/DRPC operations into bolts.
Figure 9.14. How the Trident and DRPC streams and operations are being mapped down into bolts

Note how “Tag Counts” and “Query for Request” are mapped to the same bolt and the name has been adjusted accordingly. Okay, but what about those unnamed bolts? The reason why we saw some components named as spouts in the bolts section of the UI is because Storm runs Trident spouts wrapped in a bolt. Remember that Trident spouts aren’t the same as native Storm spouts. Additionally, Trident topologies have other coordinators that allow us to treat an incoming stream as a series of batches. Storm introduced them when we added the DRPC spout to our topology and changed how it was mapped to Storm.
Identifying how Storm maps Trident operations to native Storm components is easy with a few extra lines of code. Adding names is the key and will save you headaches. Now that you have an idea of how to map native Storm components to Trident operations via names and the Storm UI, let’s turn our attention to the final topic of this chapter: scaling a Trident topology.
9.7. Scaling a Trident topology
Let’s talk units of parallelism. When working with bolts and spouts, we trade in executors and tasks. They form our primary means of parallelism between components. When working with Trident, we still work with them but only tangentially as Trident operations are mapped down to those primitives. When working with Trident, our primary method to achieve parallelism is the partition.
9.7.1. Partitions for parallelism
With Trident, we take a stream of data and work with it across one or more worker processes by partitioning the stream and applying our operations in parallel across each of the partitions. If we had five partitions within our topology and three worker processes, our work would be distributed in a fashion similar to what’s shown in figure 9.15.
Figure 9.15. Partitions are distributed across storm worker process (JVMs) and operated on in parallel

Unlike Storm, where we imagine our parallelism as spreading executors across a series of worker processes, here we’re imagining our parallelism as a series of partitions being spread across a series of worker processes. The way we scale our Trident topology is by adjusting the number of partitions.
9.7.2. Partitions in Trident streams
Partitions start at the Trident spout. A Trident spout (a much different beast from a Storm spout) will emit a stream, which then has a set of Trident operations applied to it. This stream is partitioned to provide parallelism for the topology. Trident will break down this partitioned stream into a series of small batches containing thousands of tuples to perhaps millions of tuples, depending on your incoming throughput. Figure 9.16 shows the zoomed-in view of what a Trident stream looks like between two Trident operations or between the Trident spout and the first Trident operation.
Figure 9.16. Partitioned stream with a series of batches in between two operations

If parallelism starts at the spout, and we adjust the number of partitions to control parallelism, how do we adjust the number of partitions at the spout? We adjust the number of partitions for the Kafka topic we’re subscribed to. If we had one partition for our Kafka topic, then we’d start with one partition in our topology. If we increased our Kafka topic to having three partitions, the number of partitions in our Trident topology would change accordingly (figure 9.17).
Figure 9.17. Kafka topic partitions and how they relate to the partitions within a Trident stream

From here, our stream with three partitions can be partitioned further by various operations. Let’s step back from talking about having three partitions from the spout and go back to having just one; it will make everything else easier to reason about when learning more about parallelism within our Trident topology.
Within a Trident topology, natural points of partition will exist. Points where partitioning has to change are based on the operations being applied. At these points, you can adjust the parallelism of each of the resulting partitions. The groupBy operations that we use in our topology result in repartitioning. Each of our groupBy operations resulted in a repartitioning that we could supply a parallelism hint to, as shown in the following listing.
Listing 9.20. Specifying parallelism at the points of repartition
public static StormTopology build() {
TridentTopology topology = new TridentTopology();
Stream playStream =
topology.newStream("play-spout", buildSpout())
.each(new Fields("play-log"),
new LogDeserializer(),
new Fields("artist", "title", "tags"))
.each(new Fields("artist", "title"),
new Sanitizer(new Fields("artist", "title")))
.name("LogDeserializerSanitizer");
TridentState countByArtist = playStream
.project(new Fields("artist"))
.groupBy(new Fields("artist"))
.name("ArtistCounts")
.persistentAggregate(new MemoryMapState.Factory(),
new Count(),
new Fields("artist-count"))
.parallelismHint(4);
TridentState countsByTitle = playStream
.project(new Fields("title"))
.groupBy(new Fields("title"))
.name("TitleCounts")
.persistentAggregate(new MemoryMapState.Factory(),
new Count(),
new Fields("title-count"))
.parallelismHint(4);
TridentState countsByTag = playStream
.each(new Fields("tags"),
new ListSplitter(),
new Fields("tag"))
.project(new Fields("tag"))
.groupBy(new Fields("tag"))
.name("TagCounts")
.persistentAggregate(new MemoryMapState.Factory(),
new Count(),
new Fields("tag-count"))
.parallelismHint(4);
topology.newDRPCStream("count-request-by-tag")
.name("RequestForTagCounts")
.each(new Fields("args"),
new SplitOnDelimiter(","),
new Fields("tag"))
.groupBy(new Fields("tag"))
.name("QueryForRequest")
.stateQuery(countsByTag,
new Fields("tag"),
new MapGet(),
new Fields("count"));
return topology.build();
}
Here we’ve given each of our final three bolts a parallelism of four. That means they each operate with four partitions. We were able to specify a level of parallelism for those because there’s natural repartitioning happening between them and bolts that came before them due to groupBy and persistentAggregate operations. We didn’t specify any parallelism hint to our first two bolts because they don’t have any inherent repartitioning going on between them and the spouts that came before them. Therefore, they operate at the same number of partitions as the spouts. Figure 9.18 shows what this configuration looks like in the Storm UI.
Figure 9.18. Result of applying a parallelism hint of four to the groupBy operations in our Trident topology

In addition to natural changes in partitions that happen as a result of groupBy operations, we have the ability to force Trident to repartition operations. Such operations will cause tuples to be transferred across the network as the partitions are changed. This will have a negative impact on performance. You should avoid repartitioning solely for the sake of changing parallelism unless you can verify that your parallelism hints post repartitioning have caused an overall throughput increase.
This brings us to the close of Trident. You’ve learned quite a bit in this chapter, all of which was built on a foundation that was laid in the first eight chapters of this book. Hopefully this foundation is only the beginning of your adventure with Storm, and our goal is for you to continue to refine and tune these skills as you use Storm for any problem you may encounter.
9.8. Summary
In this chapter, you learned that
- Trident allows you to focus on the “what” of solving a problem rather than the “how.”
- Trident makes use of operations that operate on batches of tuples, which are different from native Storm bolts that operate on individual tuples.
- Kafka is a distributed message queue implementation that aligns perfectly with how Trident operates on batches of tuples across partitions.
- Trident operations don’t map one-to-one to spouts and bolts, so it’s important to always name your operations.
- Storm DRPC is a useful way to execute a distributed query against persistent state calculated by a Storm topology.
- Scaling a Trident topology is much different than scaling a native Storm topology and is done across partitions as opposed to setting exact instances of spouts and bolts.