
Chapter 1. Introducing Storm
This chapter covers
- What Storm is
- The definition of big data
- Big data tools
- How Storm fits into the big data picture
- Reasons for using Storm
Apache Storm is a distributed, real-time computational framework that makes processing unbounded streams of data easy. Storm can be integrated with your existing queuing and persistence technologies, consuming streams of data and processing/transforming these streams in many ways.
Still following us? Some of you are probably feeling smart because you know what that means. Others are searching for the proper animated GIF to express your level of frustration. There’s a lot in that description, so if you don’t grasp what all of it means right now, don’t worry. We’ve devoted the remainder of this chapter to clarifying exactly what we mean.
To appreciate what Storm is and when it should be used, you need to understand where Storm falls within the big data landscape. What technologies can it be used with? What technologies can it replace? Being able to answer questions like these requires some context.
1.1. What is big data?
To talk about big data and where Storm fits within the big data landscape, we need to have a shared understanding of what “big data” means. There are a lot of definitions of big data floating around. Each has its own unique take. Here’s ours.
1.1.1. The four Vs of big data
Big data is best understood by considering four different properties: volume, velocity, variety, and veracity.[1]
Volume
Volume is the most obvious property of big data—and the first that comes to most people’s minds when they hear the term. Data is constantly being generated every day from a multitude of sources: data generated by people via social media, data generated by software itself (website tracking, application logs, and so on), and user-generated data, such as Wikipedia, only scratch the surface of sources of data.
When people think volume, companies such as Google, Facebook, and Twitter come to mind. Sure, all deal with enormous amounts of data, and we’re certain you can name others, but what about companies that don’t have that volume of data? There are many other companies that, by definition of volume alone, don’t have big data, yet these companies use Storm. Why? This is where the second V, velocity, comes into play.
Velocity
Velocity deals with the pace at which data flows into a system, both in terms of the amount of data and the fact that it’s a continuous flow of data. The amount of data (maybe just a series of links on your website that a visitor is clicking on) might be relatively small, but the rate at which it’s flowing into your system could be rather high. Velocity matters. It doesn’t matter how much data you have if you aren’t processing it fast enough to provide value. It could be a couple terabytes; it could be 5 million URLs making up a much smaller volume of data. All that matters is whether you can extract meaning from this data before it goes stale.
So far we have volume and velocity, which deal with the amount of data and the pace at which it flows into a system. In many cases, data will also come from multiple sources, which leads us to the next V: variety.
Variety
For variety, let’s step back and look at extracting meaning from data. Often, that can involve taking data from several sources and putting them together into something that tells a story. When you start, though, you might have some data in Google Analytics, maybe some in an append-only log, and perhaps some more in a relational database. You need to bring all of these together and shape them into something you can work with to drill down and extract meaningful answers from questions such as the following:
- Q: Who are my best customers?
- A: Coyotes in New Mexico.
- Q: What do they usually purchase?
- A: Some paint but mostly large heavy items.
- Q: Can I look at each of these customers individually and find items others have liked and market those items to them?
- A: That depends on how quickly you can turn your variety of data into something you can use and operate on.
As if we didn’t have enough to worry about with large volumes of data entering our system at a quick pace from a variety of sources, we also have to worry about how accurate that data entering our system is. The final V deals with this: veracity.
Veracity
Veracity involves the accuracy of incoming and outgoing data. Sometimes, we need our data to be extremely accurate. Other times, a “close enough” estimate is all we need. Many algorithms that allow for high fidelity estimates while maintaining low computational demands (like hyperloglog) are often used with big data. For example, determining the exact mean page view time for a hugely successful website is probably not required; a close-enough estimate will do. These trade-offs between accuracy and resources are common features of big data systems.
With the properties of volume, velocity, variety, and veracity defined, we’ve established some general boundaries around what big data is. Our next step is to explore the various types of tools available for processing data within these boundaries.
1.1.2. Big data tools
Many tools exist that address the various characteristics of big data (volume, velocity, variety, and veracity). Within a given big data ecosystem, different tools can be used in isolation or together for different purposes:
- Data processing— These tools are used to perform some form of calculation and extract intelligence out of a data set.
- Data transfer— These tools are used to gather and ingest data into the data processing systems (or transfer data in between different components of the system). They come in many forms but most common is a message bus (or a queue). Examples include Kafka, Flume, Scribe, and Scoop.
- Data storage— These tools are used to store the data sets during various stages of processing. They may include distributed filesystems such as Hadoop Distributed File System (HDFS) or GlusterFS as well as NoSQL data stores such as Cassandra.
We’re going to focus on data processing tools because Storm is a data-processing tool. To understand Storm, you need to understand a variety of data-processing tools. They fall into two primary classes: batch processing and stream processing. More recently, a hybrid between the two has emerged: micro-batch processing within a stream.
Batch processing
Consider for a moment a single datum: a unique click on a website. Now imagine hundreds of thousands of other clicks that are happening over the same time period. All of those clicks together form a batch—a collection of data points to be processed together. Figure 1.1 provides an overview of how data flows into a batch-oriented tool.
Figure 1.1. A batch processor and how data flows into it

Processing a website’s log files to extract information about the behavior of visitors is an excellent example of a batch-processing problem. We have a fixed pool of data that we will process to get a result. What’s important to note here is that the tool acts on a batch of data. That batch could be a small segment of data, or it could be the entire data set. When working on a batch of data, you have the ability to derive a big picture overview of that entire batch instead of a single data point. The earlier example of learning about visitor behavior can’t be done on a single data point basis; you need to have some context based on the other data points (that is, other URLs visited). In other words, batch processing allows you to join, merge, or aggregate different data points together. This is why batch processing is quite often used for machine learning algorithms.
Another characteristic of a batch process is that its results are usually not available until the entire batch has completed processing. The results for earlier data points don’t become available until the entire process is done. The larger your batch, the more merging, aggregating, and joining you can do, but this comes at a cost. The larger your batch, the longer you have to wait to get useful information from it. If immediacy of answers is important, stream processing might be a better solution.
Stream processing
A stream processor acts on an unbounded stream of data instead of a batch of data points. Figure 1.2 illustrates how data flows into a stream-processing system.
Figure 1.2. A stream processor and how data flows into it
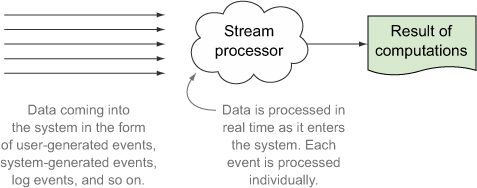
A stream processor is continually ingesting new data (a “stream”). The need for stream processing usually follows a need for immediacy in the availability of results. This isn’t always the case and is definitely not a mandate for stream processing. That’s why we have an unbounded stream of data being fed into the stream processor. This stream of data is usually directed from its origin by way of a message bus into the stream processor so that results can be obtained while the data is still hot, so to speak. Unlike a batch process, there’s no well-defined beginning or end to the data points flowing through this stream; it’s continuous.
These systems achieve that immediacy by working on a single data point at a time. Numerous data points are flowing through the stream, and when you work on one data point at a time and you’re doing it in parallel, it’s quite easy to achieve sub-second-level latency in between the data being created and the results being available. Think of doing sentiment analysis on a stream of tweets. To achieve that, you don’t need to join or relate any incoming tweet with other tweets occurring at the same time, so you can work on a single tweet at a time. Sure, you may need some contextual data by way of a training set that’s created using historical tweets. But because this training set doesn’t need to be made up of current tweets as they’re happening, expensive aggregations with current data can be avoided and you can continue operating on a single tweet at a time. So in a stream-processing application, unlike a batch system, you’ll have results available per data point as each completes processing.
But stream processing isn’t limited to working on one data point at a time. One of the most well-known examples of this is Twitter’s “trending topics.” Trending topics are calculated over a sliding window of time by considering the tweets within each window of time. Trends can be observed by comparing the top subjects of tweets from the current window to the previous windows. Obviously, this adds a level of latency over working on a single data point at a time due to working over a batch of tweets within a time frame (because each tweet can’t be considered as completed processing until the time window it falls into elapses). Similarly, other forms of buffering, joins, merges, or aggregations may add latency during stream processing. There’s always a trade-off between the introduced latency and the achievable accuracy in this kind of aggregation. A larger time window (or more data in a join, merge, or aggregate operation) may determine the accuracy of the results in certain algorithms—at the cost of latency. Usually in streaming systems, we stay within processing latencies of milliseconds, seconds, or a matter of minutes at most. Use cases that go beyond that are more suitable for batch processing.
We just considered two use cases for tweets with streaming systems. The amount of data in the form of tweets flowing through Twitter’s system is immense, and Twitter needs to be able to tell users what everyone in their area is talking about right now. Think about that for a moment. Not only does Twitter have the requirement of operating at high volume, but it also needs to operate with high velocity (that is, low latency). Twitter has a massive, never-ending stream of tweets coming in and it must be able to extract, in real time, what people are talking about. That’s a serious feat of engineering. In fact, chapter 3 is built around a use case that’s similar to this idea of trending topics.
Micro-batch processing within a stream
Tools have emerged in the last couple of years built just for use with examples like trending topics. These micro-batching tools are similar to stream-processing tools in that they both work with an unbounded stream of data. But unlike a stream processor that allows you access to every data point within it, a micro-batch processor groups the incoming data into batches in some fashion and gives you a batch at a time. This approach makes micro-batching frameworks unsuitable for working on single-data-point-at-a-time kinds of problems. You’re also giving up the associated super-low latency in processing one data point at a time. But they make working with batches of data within a stream a bit easier.
1.2. How Storm fits into the big data picture
So where does Storm fit within all of this? Going back to our original definition, we said this:
Storm is a distributed, real-time computational framework that makes processing unbounded streams of data easy.
Storm is a stream-processing tool, plain and simple. It’ll run indefinitely, listening to a stream of data and doing “something” any time it receives data from the stream. Storm is also a distributed system; it allows machines to be easily added in order to process as much data in real-time as we can. In addition, Storm comes with a framework called Trident that lets you perform micro-batching within a stream.
When we use the term real-time throughout this book, what exactly do we mean? Well, technically speaking, near real-time is more accurate. In software systems, real-time constraints are defined to set operational deadlines for how long it takes a system to respond to a particular event. Normally, this latency is along the order of milliseconds (or at least sub-second level), with no perceivable delay to the end user. Within the context of Storm, both real-time (sub-second level) and near real-time (a matter of seconds or few minutes depending on the use case) latencies are possible.
And what about the second sentence in our initial definition?
Storm can be integrated with your existing queuing and persistence technologies, consuming streams of data and processing/transforming these streams in many ways.
As we’ll show you throughout the book, Storm is extremely flexible in that the source of a stream can be anything—usually this means a queuing system, but Storm doesn’t put limits on where your stream comes from (we’ll use Kafka and RabbitMQ for several of our use cases). The same thing goes for the result of a stream transformation produced by Storm. We’ve seen many cases where the result is persisted to a database somewhere for later access. But the result may also be pushed onto a separate queue for another system (maybe even another Storm topology) to process.
The point is that you can plug Storm into your existing architecture, and this book will provide use cases illustrating how you can do so. Figure 1.3 shows a hypothetical scenario for analyzing a stream of tweets.
Figure 1.3. Example of how Storm may be used within a system

This high-level hypothetical solution is exactly that: hypothetical. We wanted to show you where Storm could fall within a system and how the coexistence of batch-and stream-processing tools is possible.
What about the different technologies that can be used with Storm? Figure 1.4 sheds some light on this question. The figure shows a small sampling of some of the technologies that can be used in this architecture. It illustrates how flexible Storm is in terms of the technologies it can work with as well as where it can be plugged into a system.
Figure 1.4. How Storm can be used with other technologies

For our queuing system, we could choose from a number of technologies, including Kafka, Kestrel, and RabbitMQ. The same thing goes for our database choice: Redis, Cassandra, Riak, and MySQL only scratch the surface in terms of options. And look at that—we’ve even managed to include a Hadoop cluster in our solution for performing the required batch computation for our “Top Daily Topics” report.
Hopefully you’re starting to gain a clearer understanding of where Storm fits and what it can be used with. A wide range of technologies, including Hadoop, can work with Storm within a system. Wait, did we just tell you Storm can work with Hadoop?
1.2.1. Storm vs. the usual suspects
In many conversations between engineers, Storm and Hadoop often come up in the same sentence. Instead of starting with the tools, we’ll begin with the kind of problems you’ll likely encounter and show you the tools that fit best by considering each tool’s characteristics. Most likely you’ll end up picking more than one, because no single tool is appropriate for all problems. In fact, tools might even be used in conjunction given the right circumstances.
The following descriptions of the various big data tools and the comparison with Storm are intended to draw attention to some of the ways in which they’re uniquely different from Storm. But don’t use this information alone to pick one tool over another.
Apache Hadoop
Hadoop used to be synonymous with batch-processing systems. But with the release of Hadoop v2, it’s more than a batch-processing system—it’s a platform for big data applications. Its batch-processing component is called Hadoop MapReduce. It also comes with a job scheduler and cluster resource manager called YARN. The other main component is the Hadoop distributed filesystem, HDFS. Many other big data tools are being built that take advantage of YARN for managing the cluster and HDFS as a data storage back end. In the remainder of this book, whenever we refer to Hadoop we’re talking about its MapReduce component, and we’ll refer to YARN and HDFS explicitly.
Figure 1.5 shows how data is fed into Hadoop for batch processing. The data store is the distributed filesystem, HDFS. Once the batches of data related to the problem at hand are identified, the MapReduce process runs over each batch. When a Map-Reduce process runs, it moves the code over to the nodes where the data resides. This is usually a characteristic needed for batch jobs. Batch jobs are known to work on very large data sets (from terabytes to petabytes isn’t unheard of), and in those cases, it’s easier to move the code over to the data nodes within the distributed filesystem and execute the code on those nodes, and thus achieve substantial scale in efficiency thanks to that data locality.
Figure 1.5. Hadoop and how data flows into it

Storm
Storm, as a general framework for doing real-time computation, allows you to run incremental functions over data in a fashion that Hadoop can’t. Figure 1.6 shows how data is fed into Storm.
Figure 1.6. Storm and how data flows into it

Storm falls into the stream-processing tool category that we discussed earlier. It maintains all the characteristics of that category, including low latency and fast processing. In fact, it doesn’t get any speedier than this.
Whereas Hadoop moves the code to the data, Storm moves the data to the code. This behavior makes more sense in a stream-processing system, because the data set isn’t known beforehand, unlike in a batch job. Also, the data set is continuously flowing through the code.
Additionally, Storm provides invaluable, guaranteed message processing with a well-defined framework of what to do when failures occur. Storm comes with its own cluster resource management system, but there has been unofficial work by Yahoo to get Storm running on Hadoop v2’s YARN resource manager so that resources can be shared with a Hadoop cluster.
Apache Spark
Spark falls into the same line of batch-processing tools as Hadoop MapReduce. It also runs on Hadoop’s YARN resource manager. What’s interesting about Spark is that it allows caching of intermediate (or final) results in memory (with overflow to disk as needed). This ability can be highly useful for processes that run repeatedly over the same data sets and can make use of the previous calculations in an algorithmically meaningful manner.
Spark Streaming
Spark Streaming works an unbounded stream of data like Storm does. But it’s different from Storm in the sense that Spark Streaming doesn’t belong in the stream-processing category of tools we discussed earlier; instead, it falls into the micro-batch-processing tools category. Spark Streaming is built on top of Spark, and it needs to represent the incoming flow of data within a stream as a batch in order to operate. In this sense, it’s comparable to Storm’s Trident framework rather than Storm itself. So Spark Streaming won’t be able to support the low latencies supported by the one-at-a-time semantics of Storm, but it should be comparable to Trident in terms of performance.
Spark’s caching mechanism is also available with Spark Streaming. If you need caching, you’ll have to maintain your own in-memory caches within your Storm components (which isn’t hard at all and is quite common), but Storm doesn’t provide any built-in support for doing so.
Apache Samza
Samza is a young stream-processing system from the team at LinkedIn that can be directly compared with Storm. Yet you’ll notice some differences. Whereas Storm and Spark/Spark Streaming can run under their own resource managers as well as under YARN, Samza is built to run on the YARN system specifically.
Samza has a parallelism model that’s simple and easy to reason about; Storm has a parallelism model that lets you fine-tune the parallelism at a much more granular level. In Samza, each step in the workflow of your job is an independent entity, and you connect each of those entities using Kafka. In Storm, all the steps are connected by an internal system (usually Netty or ZeroMQ), resulting in much lower latency. Samza has the advantage of having a Kafka queue in between that can act as a checkpoint as well as allow multiple independent consumers access to that queue.
As we alluded to earlier, it’s not just about making trade-offs between these various tools and choosing one. Most likely, you can use a batch-processing tool along with a stream-processing tool. In fact, using a batch-oriented system with a stream-oriented one is the subject of Big Data (Manning, 2015) by Nathan Marz, the original author of Storm.
1.3. Why you’d want to use Storm
Now that we’ve explained where Storm fits in the big data landscape, let’s discuss why you’d want to use Storm. As we’ll demonstrate throughout this book, Storm has fundamental properties that make it an attractive option:
- It can be applied to a wide variety of use cases.
- It works well with a multitude of technologies.
- It’s scalable. Storm makes it easy to break down work over a series of threads, over a series of JVMs, or over a series of machines—all this without having to change your code to scale in that fashion (you only change some configuration).
- It guarantees that it will process every piece of input you give it at least once.
- It’s very robust—you might even call it fault-tolerant. There are four major components within Storm, and at various times, we’ve had to kill off any of the four while continuing to process data.
- It’s programming-language agnostic. If you can run it on the JVM, you can run it easily on Storm. Even if you can’t run it on the JVM, if you can call it from a *nix command line, you can probably use it with Storm (although in this book, we’ll confine ourselves to the JVM and specifically to Java).
We think you’ll agree that sounds impressive. Storm has become our go-to toolkit not just for scaling, but also for fault tolerance and guaranteed message processing. We have a variety of Storm topologies (a chunk of Storm code that performs a given task) that could easily run as a Python script on a single machine. But if that script crashes, it doesn’t compare to Storm in terms of recoverability; Storm will restart and pick up work from our point of crash. No 3 a.m. pager-duty alerts, no 9 a.m. explanations to the VP of engineering why something died. One of the great things about Storm is you come for the fault tolerance and stay for the easy scaling.
Armed with this knowledge, you can now move on to the core concepts in Storm. A good grasp of these concepts will serve as the foundation for everything else we discuss in this book.
1.4. Summary
In this chapter, you learned that
- Storm is a stream-processing tool that runs indefinitely, listening to a stream of data and performing some type of processing on that stream of data. Storm can be integrated with many existing technologies, making it a viable solution for many stream-processing needs.
- Big data is best defined by thinking of it in terms of its four main properties: volume (amount of data), velocity (speed of data flowing into a system), variety (different types of data), and veracity (accuracy of the data).
- There are three main types of tools for processing big data: batch processing, stream processing, and micro-batch processing within a stream.
- Some of the benefits of Storm include its scalability, its ability to process each message at least once, its robustness, and its ability to be developed with any programming language.