
The preceding chapters have described the core of software architecture, providing the notations, tools, and techniques that enable the designer to specify an architecture, implement, and deploy it. On the basis of those chapters one should be able to approach any design problem and successfully proceed. Such a simple declaration, however, belies the difficulties that arise when dealing with complex problems. Some problems just do not lend themselves to obvious solutions, or simple, uniform structures. One theme that characterized the chapter on designing architectures was benefiting from the lessons of experience. We continue that theme in this chapter, discussing how a wide variety of important and challenging architectural problems have been solved, thereby enhancing the repertoire of insights and styles that a designer possesses to bring to bear on his own problem.
Our motivation is the recognition that most new applications are complex, and must deal with a range of issues. Notably, many applications must deal with issues that arise from the application being on a computer network, wherein the application interacts with other software systems located remotely. Network-based applications may involve the Web, be focused on parallel computation, or focus on business-to-business interaction. We describe architectural styles for these and other applications.
In this chapter we also use the lens of software architecture to explicate a variety of design notions that are at least in part fundamentally architectural, but which have largely been described in idiosyncratic terms, such as "grid computing" and peer-to-peer (P2P) applications—terminology belonging to other computer science subcommunities, rather than software engineering. Such description enables a more direct comparison of their merits with alternative approaches to similar problems.
The goals of this chapter are thus to:
Describe how the concepts from the previous chapters can be used, sometimes in combination, to solve challenging design problems.
Highlight key issues in emerging application domains that have architectural implications, or where an architectural perspective is essential for system development within that domain.
Show how emerging architectures, such as P2P, can be characterized and understood through the lens of software architecture.
The sections of this chapter deal first with distribution and network-related issues; the increasingly important topic of decentralized architectures is then considered. The chapter concludes with a section on architectures from a few specific domains.
Outline of Chapter 11
11 Applied Architectures and Styles
11.1 Distributed and Networked Architectures
11.1.1 Limitations of the Distributed Systems Viewpoint
11.2 Architectures for Network-Based Applications
11.2.1 The REpresentational State Transfer Style (REST)
11.2.2 Commercial Internet-Scale Applications
11.3 Decentralized Architectures
11.3.1 Shared Resource Computation: the Grid World
11.3.2 Peer-to-Peer Styles
11.3.3 Summary Notes on Latency and Agency
11.4 Service-Oriented Architectures and Web Services
11.5 Architectures from Specific Domains
11.5.1 Robotics
11.5.2 Wireless Sensor Networks
11.6 End Matter
11.7 Review Questions
11.8 Exercises
11.9 Further Reading
The phrase "distributed application" is used to denote everything from an application that is simply distributed across multiple operating system processes all running on the same physical uniprocessor, to integrated applications that run on multiple computers connected by the Internet. Distributed applications have been in general use since at least the late 1970s when commercial networking technologies began to proliferate, and became increasingly common in the 1980s with the advent of efficient remote procedure calls and the availability of cheap computing power at the fringes of the network. Consequently we do not pretend to offer anything remotely close to a detailed treatment of such applications here. A variety of excellent texts are available that treat the subject in depth [see, for example, (Emmerich 2000; Tanenbaum and van Steen 2002)].
In Chapter 4 we discussed one popular approach to constructing distributed applications, CORBA, as representative of a variety of similar approaches, such as The Open Group's Distributed Computing Environment (DCE) (The Open Group 2005). That presentation omitted consideration of the broader issues associated with distributed applications, hence we begin with that discussion here.
One of the principal motivations for the development of the CORBA technology, and indeed of much distributed computing technology, was to enable use of the object-oriented development style in a distributed computing context. A particular design choice the designers made was to attempt to provide the illusion of "location transparency." That is, that a developer should not need to know where a particular object is located in order to interact with that object. (Several other forms of transparency are also supported, such as implementation transparency wherein the developer need not know or be concerned with the choice of programming language in which a particular object is implemented.) If such transparency is provided to the developer, all the concerns and issues associated with working across a network can be ignored, for those issues will be taken care of by the underlying CORBA support.
Unfortunately a quick look at the details of CORBA's API, that is, the interface that programmers have to work with, reveals that achieving such transparency has not proved to be fully possible. CORBA has a variety of special mechanisms, visible to the programmer, which reveal the presence of a network underneath, and the possibility of various networking issues impacting the programming model, such as network failure or response timeout.
The multiple difficulties of attempting to mask the presence of networks and their properties from application developers was recognized early and became canonized by Peter Deutsch in his short list "Fallacies of Distributed Computing" (Deutsch and Gosling 1994). As Deutsch and his colleague James Gosling say, "Essentially everyone, when they first build a distributed application, makes the following eight assumptions. All prove to be false in the long run and all cause big trouble and painful learning experiences." The fallacies are, as stated by Gosling:
The network is reliable.
Latency is zero.
Bandwidth is infinite.
The network is secure.
Topology doesn't change.
There is one administrator.
Transport cost is zero.
The network is homogeneous.
Directly addressing any one of these issues may lead to particular architectural choices and concerns. For instance, if the network is unreliable, then the architecture of a system may need to be dynamically adaptable. The presence of latency (delay in the receipt or delivery of a message) may require applications to be able to proceed based upon locally created estimated values of messages, based upon the value of previously received messages. Bandwidth limitations, and bandwidth variability, may require inclusion of adaptive strategies to accommodate local conditions. Existence of more than one administrative domain may demand that explicit trust mechanisms be incorporated. Accommodating network heterogeneity may involve imposition of abstraction layers or a focus on interchange standards.
Dealing explicitly with these issues that arise due to the presence of networking leads to our consideration of network-based and decentralized architectures. Rather than attempting to be comprehensive in our coverage, however, we select several deep examples that reveal how architectures can be designed to accommodate specific needs and goals.
We begin with an extended discussion of the REpresentational State Transfer (REST) style, which was first introduced in Chapter 1. REST was created as part of the effort to take the Web from its earliest form to the robust, pervasive system that we rely upon today. The derivation of REST is instructive, as the interplay between requirements from the application domain (namely, distributed decentralized hypertext) and the constituent parts of the style can be clearly shown.
Chapter 1 of this textbook began with a brief exposition of the REST architectural style, describing how it was used to design the post-1994 World Wide Web (which includes the HTTP/1.1 protocol, the Uniform Resource Identifier specification, and other elements). The goal of that presentation was to begin to indicate the power of software architecture, showing its impact on one of the world's most widespread technologies. That presentation also indicated how software architecture is not something you can necessarily derive by looking at a piece of source code (for example, the Apache Web server), for the Web's architecture represents a set of design decisions that transcends many independent programs. It is the way those programs must work together that the REST style dictates.
The presentation in Chapter 1 did not describe how the REST style was developed: what motivated its creation and what prior architectural influences were combined to yield this influential style. The presentation below addresses these topics. Beyond just understanding the "why" of the Web, the reader should see how selected simple styles can be combined in judicious ways to address a complex, and conflicting, set of needs.
The need for a next-generation Web arose from the outstanding success of the first generation—and the inability of that first generation's architecture to function adequately in the face of enormous growth in the extent and use of the Web. The characteristics of the Web as an application and the properties of its deployment and use provide the critical context for the development of REST.
The WWW is fundamentally a distributed hypermedia application. The conceptual notion is of a vast space of interrelated pieces of information. The navigation of that space is under the control of the user; when presented with one piece of information the user may choose to view another piece, where the reference to that second piece is contained in the first. The information is distributed across the Internet, hence one aspect of the application is that the information selected for viewing—which may be quite large—must be brought across the network to the user's machine for presentation. (Note that some current uses of the Web, such as for business-to-business transactions, do not fit this model, and are discussed later under Web services.)
Since the information must be brought to the user across the network, all of the network issues listed in the preceding section are of concern. Latency, for example, may determine user satisfaction with the navigation experience: Actions at the client/user agent (that is, the browser) must be kept fast. As large data sets are transferred it is preferable if some of the information can be presented to the user while the remainder of the data transfer takes place, so that the user is not left waiting. Since the Web is not only a distributed hypermedia application, but a multi-user application, provision must also be made for circumstances in which many users request the same information at the same time. The latency intrinsic in the transfer of the information is compounded by potential contention for access to the resource at its source.
The Web is also a heterogeneous, multi-owner application. One goal for the Web was to enable many parties to contribute to the distributed information space by allowing locally administered information spaces to be linked to that of the broader community, and to do so easily. This implies that the information space is not under a single authority—it is a decentralized application. The openness of the Web implies that neither the uniformity of supporting implementations nor the qualities of those implementations can be assumed. Moreover, the information so linked may not be reliably available. Previously available information may become unavailable, necessitating provision for dealing with broken links.
The heterogeneity of the Web also has a prospective view: Various contributors to the information space may identify new types of information to link (such as a new type of media) or new types of processing to perform in response to an information retrieval request. Provision for extension must therefore be made.
Lastly, the matter of scale dominates the concerns. Any proposed architectural style must be capable of maintaining the Web's services in the face of continuing rapid growth in both users and information providers. Keep in mind that REST was developed during a period when the number of Web sites was doubling every three to six months! The scale of the application today—in terms of users and sites—is far beyond what was imagined in 1994: 50 million active Web sites/100 million hostnames.
The REST style was created to directly address these application needs and design challenges. REST, as a set of design choices, drew from a rich heritage of architectural principles and styles, such as those presented in Chapter 4. Figure 11-1 summarizes the architectural heritage of REST. Key choices in this derivation, explained in detail below, include:
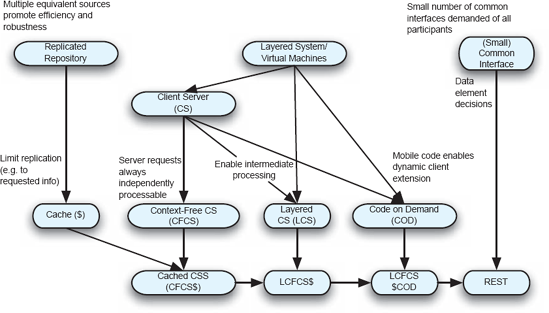
Layered separation (a theme in the middle portion of diagram), to increase efficiencies, enable independent evolution of elements of the system, and provide robustness.
Replication (left side of the diagram), to address latency and contention by allowing the reuse of information.
Limited commonality (right side) to address the competing needs for universally understood operations with extensibility.
Also critical in the derivation was the decision to require requests on the server to be independently serviceable or "context-free"; that is, the server can understand and process any request received based solely on the information in the request. This supports scalability and robustness. Finally, dynamic extension through mobile code addresses independent extensibility. The following paragraphs elaborate these issues and choices. More detailed expositions can be found in (Fielding 2000; Fielding and Taylor 2002).
Layered Separation. The core design decision for REST was the use of layered systems. As described in Chapter 4 layered systems can take many forms, including client-server and virtual machines. The separations based upon layering principles can be found several places in REST.
The use of a client-server (CS) architecture was intrinsic to the original Web. Browsers running on a user's machine have responsibility for presentation of information to the user and are the locus of determining the user's next interactions with the information space.
Servers have responsibility for maintaining the information that constitutes the Web, and delivering representations of that information to the clients. Software that addresses the user interface can hence evolve independently from the software that must manage large amounts of data and respond to requests from many sources. This separation of responsibilities simplifies both components and enables their optimization.
The client-server style is then further refined through imposition of the requirement that requests to a server be independently processable; that is, the server is able to understand and process any request based solely on the information in that one request. This design constraint is often referred to as a "stateless server," and the corresponding HTTP/1.1 protocol is often referred to as a "stateless protocol." This terminology is unfortunate, as it suggests that the server does not maintain any state. The server certainly may maintain state of various kinds: Previous client requests may have caused new information to be stored in a database maintained by the server, for instance. Rather, the focus here is that the server does not keep a record of any session of interactions with a client. With this requirement the server is free to deallocate any resources it used in responding to a client's request, including memory, after the request has been handled. In absence of this requirement the server could be obliged to maintain those resources until the client indicated that it would not be issuing any further requests in that session. In the diagram we have labeled this specialization of the CS style as "context-free" since a server request can be understood and processed independently of any surrounding context of requests.
Imposition of this requirement on interactions between clients and servers strongly supports scalability, as servers may efficiently manage their own resources—not leaving them tied up in expectation of a next request. Moreover, all servers with access to the same back-end databases become equal—any one of a number of servers may be used to handle a client request, allowing load sharing among the servers.
The possibility of cheap load balancing is a result of another application of layering in the design of REST. Intermediaries may be imposed in the path of processing a client request. An intermediary (such as a proxy) provides the required interface for a requested service. What happens behind that interface is hidden to the requestor. An intermediary, therefore, may determine which of several equivalent servers can be used to provide the best system performance, and direct calls accordingly. Intermediaries may also perform partial processing of requests, and can do so because all requests are self-contained. Finally, they may address some security concerns, such as enforcing boundaries past which specified information should not be allowed to flow.
Replication. The replication of information across a set of servers provides the opportunity for increased system performance and robustness. The existence of replication is hidden from clients, of course, as a result of intermediate layers.
One particular form of replication is caching information. Rather than duplicating information sources irrespective of the particular information actually requested of them, caches may maintain copies of information that has already been requested or that is anticipated to be requested. Caches may be located near clients (where they may be termed "proxies"), or near servers (where they may be termed "gateways"). The critical feature is that since requests are always self-contained, a single cache may be utilized by many different clients. If the cache determines, on the basis of inspecting the request message, that it has the required information, that information may be sent to the requestor without involving any processing on the part of a server. System performance is thus improved since the user obtains the desired information without incurring all the costs that would normally be expected. For this to work, responses from servers must be determined to be cacheable or not. For instance, if a request is for "the current temperature in Denver," the response is not cacheable since the temperature is continually varying. If the request, however, is for "the temperature in Denver at 24:00 on 01/01/2001," that value is cacheable since it is constant.
Limited Commonality. The parts of a distributed application can be made to work together either by demanding that a common body of code be used for managing all communications, or through imposition of standards governing that communication. In the latter case multiple, independent implementations are possible; communication is enabled because there is agreement upon how to talk. Clearly the use of standards to govern communication is superior to common code in an open, heterogeneous application. Innovation is fostered, local specializations may be supported, different hardware platforms used, and so on. The question, though, is what kind of communication standards should be imposed?
One option is the feature-rich style. In this approach, every possible type of interaction is anticipated and supported directly in the standard. This approach has the disadvantage that whenever any change to any part of the protocol is required, all implementations must be updated to conform. Another option, the one taken in REST, is essentially two-level: The first level (a) specifies how information is named and represented as meta-data, and (b) specifies a very few key services that every implementation must support. The second level focuses on the packaging of arbitrary data (including any type of request or operation encoded as data), in a standardized form for transmission. This is designed to be efficient for large-grain hypermedia data transfer, thus optimizing for the target application of the Web, but resulting in an interface that is not optimal for other forms of interaction.
Dynamic Extension. Allowing clients to receive arbitrary data, described by meta-data, in response to a request to a server allows client functionality to be extended dynamically. Data obtained by a client may be, for example, a script or an applet that the client could choose to execute. With such execution, the client is able to perform new functions and essentially be customized to that client's user's particular needs. REST thus incorporates the code-on-demand variant-style of mobile code.
REST is an exemplar of an architectural style driven by deep understanding of both the particular application domain supported (open network-distributed hypermedia) and the benefits that can be obtained from several simple architectural styles. Constraints from several styles are judiciously combined to yield a coherent architectural approach which is summarized in the box below. The success of the Web is due to this careful engineering.[13]
The REST style is certainly a powerful tool to use in network-based applications where issues of latency and agency (authority boundaries)[14] are prominent. It is also instructive in guiding architects in the creation of other specialized styles. The trade-offs made in developing REST, such as how many operations to include in the limited interface specification, highlight that creation of such a style is not straightforward. Nonetheless combination of constraints from a variety of simpler styles can yield a powerful, customized tool.
The REST architecture has been successful in enabling the Web to scale through a time period when use of the Web was growing exponentially. One of the key features of REST that enabled that scaling was caching. While caching may potentially be performed by any component in a REST architecture, a key aspect of REST's support for caching is enabling the presence of intermediaries between a user agent and an origin server, in particular proxies. Proxies can store the results of HTTP GET requests; if the information so stored stays current for a time, further requests for that information that pass through that proxy may be satisfied by that proxy, without further routing the request on to the origin server. In dynamic, high-demand situations, however, proxies may not be able to prevent problems. Consider, for example, when a popular sporting event is being covered by a news company, maintaining a record of the event's progress on its Web site. As the event progresses many thousands of fans may attempt to access the information. Proxies throughout the Web will not be of much help because the information is being updated frequently—the contention will be for access to the origin server. These flash crowd demands for access to the origin server may induce it to fail or, at least, will induce unacceptable latency while each request is processed in turn.
Akamai's solution to the problem, in essence, is to replicate the origin server at many locations throughout the network, and direct a user agent's requests to the "replicant" origin server, called an edge server, closest to that user. This redirection, referred to as mapping, is performed when the Internet address (IP address) for the requested resource (such as www.example.com/bicycle-race/) is determined by the Internet Domain Name Server (DNS)—one of the first steps in processing an HTTP GET request. Akamai has located many thousands of its edge servers throughout the Internet, such as at the places where Internet Service Providers (ISPs) join their networks to the Internet. One of Akamai's strengths is in the way in which the closest edge server is identified. This calculation may involve the results of monitoring the status of parts of the Internet and computing locations whose access will be least impeded by demand elsewhere in the network. The edge servers, of course, will have to access the origin server to update their content, but by directing end user agent requests to the edge servers, demand on the origin server is kept manageable.
Viewed architecturally, Akamai further exploits the notion of replicated repositories. REST's separation of resources from representations enables many edge servers to provide representations of the resource located at the origin server. Further, REST's context-free interaction protocol enables many requests from a single user agent to be satisfied by several different edge servers. Akamai's redirection scheme succeeds because of the strong separations of concerns present in the Internet protocols.
Google as a company has grown from offering one product—a search engine—to a wide range of applications. Since the search engine and so many of Google's products are so closely tied to the Web one might expect the system architecture(s) to be REST-based. They are not. Google's systems are architecturally interesting, however, because they address matters of scale similar to the Web, but the nature of the applications and the business strategy of the company demands a very different architecture. Google is interesting as well because of the number of different products that share common elements.
The fundamental characteristic of many of Google's applications is that they rest upon the ability to manipulate very large quantities of information. Terabytes of data from the Web and other sources are stored, studied, and manipulated in various ways to yield the company's information products. The company's business strategy has been to support this storage and manipulation using many tens of thousands of commodity hardware platforms. In short, inexpensive PCs running Linux. The key notion is that by supporting effective replication of processing and data storage, a fault-tolerant computing platform can be built that is capable of scaling to enormous size. The design choice is to buy cheap and plan that failure, of all types, will occur and must be effectively accommodated. The alternative design would be to buy, for example, a high-capacity, high-reliability database system, and replicate it as required. Whether this would be as cost-effective is debatable (it most probably would not), but another key insight from Google's design process is that their applications do not require all the features of a full relational database system. A simpler storage system, offering fewer features, but running atop a highly fault-tolerant platform meets the needs in a cost-effective manner. This system, know as the Google File System, or GFS, is the substrate that manages Google's highly distributed network of storage systems. It is optimized in several ways differently from prior distributed file systems: The files are typically very large (several gigabytes), failure of storage components is expected and handled, files are typically appended to (rather than randomly modified), and consistency rules for managing concurrent access are relaxed.
Running atop GFS are other applications, notable of which is MapReduce. It offers a programming model in which users focus their attention on specifying data selection and reduction operations. The supporting MapReduce implementation is responsible for executing these functions across the huge data sets in the GFS. Critically, the MapReduce library is responsible for all aspects of parallelizing the operation, so that the thousands of processors available can be effectively brought to bear on the problem without the developer having to deal explicitly with those matters. Once again, the system is designed to gracefully accommodate the expected failure of processors involved in the parallel execution.
The architectural lessons from Google are several:
Abstraction layers abound: GFS hides details of data distribution and failure, for instance; MapReduce hides the intricacies of parallelizing operations.
Designing, from the outset, for living with failure of processing, storage, and network elements, allows a highly robust system to be created.
Scale is everything. Google's business demands that everything be built with scaling issues in mind.
Specializing the design to the problem domain, rather than taking the generic "industry standard" approach, allows high-performance and very cost effective solutions to be developed.
Developing a general approach (MapReduce) to the data extraction/reduction problem allowed a highly reusable service to be created.
The contrast between the last two points is instructive: On the one hand, a less general solution strategy was adopted (a specialized file system rather than a general database), and on the other hand, a general programming model and implementation was created (abstracting across the needs of many of Google's applications). Both decisions, while superficially at odds, arise from deep knowledge of what Google's applications are—what they demand and what key aspects of commonality are present.
In the preceding discussion of REST we referred to the World Wide Web as being a distributed, decentralized, hypermedia application. Decentralization refers to the multiple authority, or agency, domains participating in an application. The sense is that the various parts of an application are owned and controlled by various parties, and those parts communicate over a network (hence decentralization essentially implies distribution as well) to achieve the goals of the application. The Web is a good example of this cooperation between independent agencies. The millions of Web sites around the world are owned and controlled by as many individuals and organizations. By agreeing to the basic standards of the Web, such as HTTP, any user may traverse the Web to obtain information, and in so doing may cross many agency boundaries.
Designing decentralized software architectures poses challenges beyond the design of distributed systems. Designing decentralized applications is not, however, a new idea: Everyday society is filled with designed decentralized applications. International postal mail is one large-scale example; individual countries issue their own postage stamps and control local collection and delivery of mail. International post, however, involves cooperation at several levels between the parties involved, including standards to govern how mail is addressed, how postage is marked, and the agreements that are in place to govern the physical routing and hand off of mail. International commerce is an even more extensive and rich example.
Decentralized architectures are created whenever the parties desiring to participate in an application want to retain autonomous control over aspects of their participation. Web site owners, for instance, typically want to retain the ability to take their sites offline at arbitrary times, to add new content, or to add new servers. Such autonomy can be the source of many design challenges. Since there is no single authority, there is no guarantee, for example, that a participant in a system will always be participating with the best of intentions. Decentralized systems are also distributed, so coping with the new challenges of multiple agencies comes on top of the challenges of dealing with latency and the other issues of distribution.
Computer application developers have worked so long in a world where applications were fundamentally centralized in terms of authority (even if under the banner of "distributed systems") that as we begin to build new applications we have to call those assumptions into question and adapt to new realities. This section explores several systems and approaches that have been designed to both exploit the advantages of open, decentralized systems, while mitigating some of the problems encountered. We begin the discussion by briefly discussing grid computing, then focus on several peer-to-peer systems, as they simply and clearly illustrate some of the challenges and design solutions possible. Discussion then turns to Web services, a design approach targeted to supporting business-to-business interactions.
Grid computing is coordinated resource sharing and computation in a decentralized environment. The notion is to allow, for example, a team of researchers to temporarily bring numerous diverse hardware and software resources to bear on a computational problem. The resources may be under the authority of various owners, but for the time when the grid is logically in place the system behaves as though it is a distributed application under a single authority.
The supporting grid technology is designed to make transparent all the details of managing the diverse and distributed resources. Included in this goal of transparency is management of the details of crossing authority boundaries. A single sign-on is thus a particular goal. Grid applications have been used to support visualization of earthquake simulation data, simulate the flow of blood, support physics simulations, and so on.
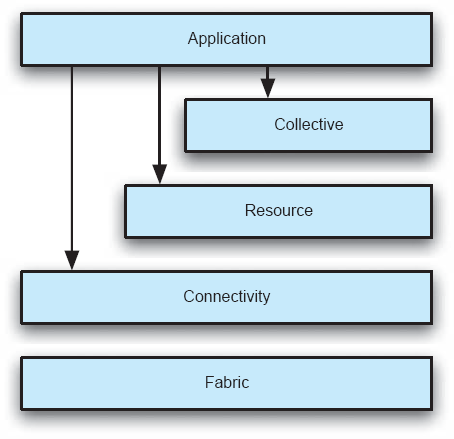
While many different grid systems have been built, a common architecture for them has been put forth (Foster, Kesselman, and Tuecke 2001), as shown in Figure 11-2. The architecture is layered, with the ability of components within any layer to build upon services provided by any lower layer. The Application layer contains the components that implement the user's particular system. The Collective layer is responsible for coordinating the use of multiple resources. The Resource layer is responsible for managing the sharing of a single resource. The Connectivity layer is responsible for communication and authentication. The Fabric layer manages the details of the low-level resources that ultimately comprise the grid; the upper layers provide a convenient set of abstractions to this set of resources. The diagram particularly calls out the notion of the application layer calling upon the first three layers below it, but not the Fabric layer. Presumably this is to indicate that management of the lowest-level resources is best left to the grid infrastructure.
Unfortunately the elegance and clean design of this architecture is not fully maintained by several popular and well-known grid technologies. By performing architectural recovery based upon the source code of grid systems, an as-built architecture can be compared to the prescriptive architecture of Figure 11-2. For example, Figure 11-3 portrays the recovered architecture of the Globus grid system (Mattmann, Medvidović et al. 2005). In this case, for example, several up-calls in the architecture are present, violating the layered systems principle. Similar architectural violations have been discovered in other grid technologies as well.

Chapter 4 introduced the idea of peer-to-peer architectures. Discussion there centered on the fundamental characteristics of P2P architectures, but did not present many details or rationale for when the style is appropriate. The examples below, Napster, Gnutella, and Skype, provide some of this detail.
P2P systems became part of the popular technical parlance due in large measure to the popularity of the original Napster system that appeared in 1999. Napster was designed to facilitate the sharing of digital recordings in the form of MP3 files. Napster was not, however, a true P2P system. Its design choices, however, are instructive.
Figure 11-4 illustrates the key entities and activities of Napster. Each of the peers shown is an independent program residing on the computers of end users. Operation begins with the various peers registering themselves with the Napster central server, labeled in the figure as the Peer and Content Directory. When registering, or later logging in, a peer informs the server of the peer's Internet address and the music files resident at that peer that the peer is willing to "share." The server maintains a record of the music that is available, and on which peers. Later, a peer may query the server as to where on the Internet a given song can be obtained. The server responds with available locations; the peer then chooses one of those locations, makes a call directly to that peer, and downloads the music.

Figure 11-4. Notional view of the operation of Napster. In steps 1 and 2, Peers A and B log in with the server. In step 3, Peer A queries the server where it can find Rondo Veneziano's "Masquerade." The location of Peer B is returned to A (step 4). In step 5, A asks B for the song, which is then transferred to A (step 6).
Architecturally, this system can be seen as a hybrid of client-server and pure P2P. The peers act as clients when registering with the Peer and Content Directory and querying it. Once a peer knows where to ask for a song, a P2P exchange is initiated; any peer may thus sometimes act as a client (asking others for a song) or as a server (delivering a song it has to another peer in response to a request). Napster chose to use a propriety protocol for interactions between the peers and the content directory; HTTP was used for fetching the content from a peer. (The decision to use a proprietary protocol offered dubious benefits, including limiting file sharing to MP3 files.)
The architectural cleanness of this design is also its downfall. If, for example, a highly desired song becomes available, the server will be swamped with requests seeking its location(s). And of course, should the server go down, or be taken down by court order, all peers lose the ability to find other peers.
Alleviating the design limitations of Napster was one of the design goals of Gnutella (Kan 2001). Gnutella's earliest version was a pure P2P system; there is no central server—all peers are equal in capability and responsibility. Figure 11-5 helps to illustrate the basic protocol. Similar to Napster, each of the peers is a user running software that implements the Gnutella protocol on an independent computer on the Internet. If Peer A, for instance, is seeking a particular song (or recipe) to download, he issues a query to the Gnutella peers on the network that he knows about, Peers B and H, in step 1. Assuming they do not have the song, they pass the query along further, to the peers they know about: each other, and Peers C and G, in step 2. Propagation of the query proceeds to spread throughout the network either until some retransmission threshold is exceeded (called the "hop count") or until a peer is reached that has the desired song. If we assume that Peer F has the song, it responds to the peer that asked it (Peer C in step 3), telling Peer C that it has the song. Peer C then relays that information, including the network address of Peer F, to the peers that requested the information from it.

Eventually, Peer A will obtain the address of Peer F and can then initiate a direct request to F in step 4 to download the song. The song is downloaded in step 5. As with Napster, the Gnutella protocol was custom designed, but the direct download of the music was accomplished using an HTTP GET request.
Several issues facing P2P systems are apparent in this example. When a new peer comes on to the network, how does it find any other peers to which its queries can be sent? When a query is issued, how many peers will end up being asked for the requested resource after some other peer has already responded and provided the information? Keep in mind that all the peers know only of the requests that they have received, and the requests that they have issued or passed along; they do not have global knowledge. How long should the requesting peer wait to obtain a response? How efficient is the whole process?
Perhaps most interesting, when a peer responds that it has the requested resource, and the requestor downloads it, what assurance does the requestor have that the information downloaded is that which was sought? Experience with Gnutella reveals what might be expected: Frequently the majority of responses to a resource request were viruses or other malware, packaged to superficially appear as the requested resource.
These significant weaknesses aside, a critical observation of Gnutella is that it is highly robust. Removal of any one peer from the network, or any set of peers, does not diminish the ability of the remaining peers to continue to perform. Removal of a peer may make a specific resource unavailable if that peer was the unique source for that resource, but if a resource was available from several sources it could conceivably still be found and obtained even if many peers were removed from the network. In this regard, Gnutella reflects the basic design of the Internet: Intermediate routers and subnetworks may come and go, yet the Internet protocol provides highly robust delivery of packets from sources to destinations.
Despite the benefit of being highly robust, the intrinsic limitations of the Gnutella approach have led to the search for improved mechanisms. Recent versions of Gnutella have adopted some of the Napsterish use of "special peers" for improvement of, for instance, the peer location process.
Napster and Gnutella are interesting mostly for their historical role and for ease in explaining the benefits and limitations of P2P architectures. A mature, commercial use of P2P is found in Skype, which we consider next.
Skype is a popular Internet communication application built on a P2P architecture.[15] To use Skype, a user must download the Skype application from Skype (only). In contrast to Gnutella, there are no open-source implementations, and the Skype protocol is proprietary and secret. When the application is run, the user must first register with the Skype login server. Subsequent to that interaction the system operates in a P2P manner.
Figure 11-6 illustrates how the application functions in more detail. The figure shows Peer 1 logging into the Skype server. That server then tells the Skype peer the address of Supernode A which the peer then contacts. When Peer 1 wants to see if any of his buddies are online, the query is issued to the supernode. When the user makes a Skype call (that is, a voice call over the Internet), the interaction will proceed from the calling peer to the supernode, and then either to the receiving peer directly (such as to Peer 2) or to another supernode and then to the receiving peer. If both peers are on public networks, not behind firewalls, then the interaction between the peers may be set up directly, as is shown in the figure between Peer 2 and Peer 3.
Supernodes provide, at least, directory services and call routing. Their locations are chosen based upon network characteristics and the processing capacity of the machine they run on, as well as the load on that machine. While the login server is under the authority of Skype.com, the supernode machines are not. In particular, any Skype peer has the potential of becoming a supernode. Skype peers get "promoted" to supernode status based upon their history of network and machine performance. The user who downloaded and installed the peer does not have the ability to disallow the peer from becoming a supernode. Note the potential consequences of this for some users. Suppose a machine's owner installs a Skype peer, and that the owner pays for network connectivity based upon the amount of traffic that flows in and out of the machine on which the peer is installed. If that peer becomes a supernode, the owner then will bear the real cost of routing a potentially large number of calls—calls the owner does not participate in and does not even know are occurring.
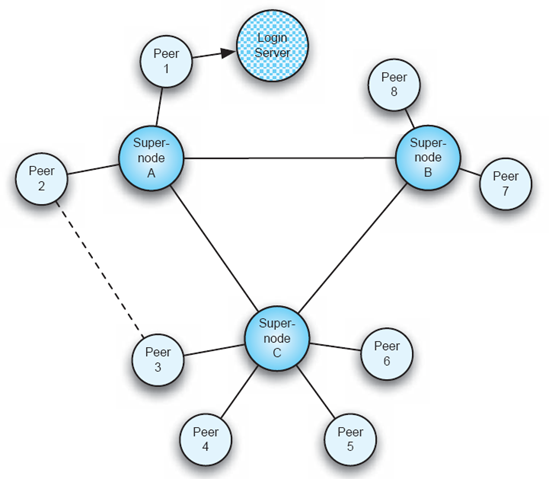
Several aspects of this architecture are noteworthy:
A mixed client-server and peer-to-peer architecture addresses the discovery problem. The network is not flooded with requests in attempts to locate a buddy, such as would happen with the original Gnutella.
Replication and distribution of the directories, in the form of supernodes, addresses the scalability and robustness problems encountered in Napster.
Promotion of ordinary peers to supernodes based upon network and processing capabilities addresses another aspect of system performance: "Not just any peer" is relied upon for important services. Moreover, as many nodes as are dynamically required can become supernodes.
A proprietary protocol employing encryption provides privacy for calls that are relayed through supernode intermediaries.
Restriction of participants to clients issued only by Skype, and making those clients highly resistant to inspection or modification, prevents malicious clients from entering the network, avoiding the Gnutella problem.
This last point prevents us from too strongly asserting how Skype works. The details provided here have resulted from extensive study of Skype by third-party scientists, citations for which are provided at the end of the chapter. The accompanying sidebar description of Skype is from material provided on the Skype.com Web site.
BitTorrent is another peer-to-peer application whose architecture has been specialized to meet particular goals. The primary goal is to support the speedy replication of large files on individual peers, upon demand. The distinctive approach of BitTorrent is to attempt to maximize use of all available resources in the network of interested peers to minimize the burden on any one participant, thus promoting scalability.
The problem that BitTorrent solves can be seen by considering what happens in either Napster or Gnutella, as described above, when one peer in the network has a popular item. Any peer who announces availability of a resource (either by registering the resource with the Napster server, or responding to a network query in the case of Gnutella) can quickly become the recipient of a very large number of requests for that resource—possibly more than the machine can support. These flash crowds burden the peer-server possessing the resource and can hence dissuade the server's owner from participating further in the P2P network.
BitTorrent's approach is to distribute parts of a file to many peers and to hence distribute both the processing and networking loads over many parts of the peer network. A peer does not obtain the requested large file from a single resource; rather the pieces of the file are obtained from many peers and then reassembled. Moreover, the requesting peer does not only download the pieces, but is also responsible for uploading the portions of the file that it has to other interested peers—keep in mind the operating context is one in which many peers are simultaneously interested in obtaining a copy of the file.
Architecturally, BitTorrent has made the following key decisions:
Responsibility for the discovery of content is outside the scope of BitTorrent. Potential users use other means, such as Web searches, to locate content on the Web.
A designated (centralized) machine called the tracker is used to oversee the process by which a file is distributed to an interested set of peers, but the tracker does not perform any of the file transfer. Peers use interaction with this machine to identify the other peers with which they communicate to effect the download.
Meta-data is associated with the file, and is used throughout the download process. The meta-data describes how the large file is "pieced," the attributes of those pieces, and the location of the tracker.
Each peer participating in a file's replication runs a BitTorrent application that determines (a) what piece of the file to download next, and (b) which peer to obtain that piece from. All the participating peers maintain knowledge of which peers have which pieces. The algorithms are designed to achieve the goals of quick distribution through maximizing use of the resources available at all peers. (If a peer is manipulated so that it does not participate in uploading pieces, but only downloading, it is penalized by the other peers through deprioritization of access to the pieces that it needs.)
As with all well-designed P2P applications, BitTorrent accounts for the possibility of any given peer dropping out of the process at any time.
The preceding sections have covered applications and architectures that have substantial complexity resulting from the need to deal with two primary issues in decentralized systems: latency and agency. Latency has been understood as an issue for a long time, and strategies for dealing with it are well known. Caching of results, intelligent searching strategies, and judicious use of centralized servers can all play roles in reducing latency.
Agency is a richer issue, and of more recent concern. Agency implies concerns with heterogeneity (such as of programming language platforms), unreliability, uncertainty, trust, and security. Effectively coping with all the concerns induced by multiple agencies requires careful thought. The REST style, and styles derived from it, offer proven guidance for dealing with several aspects of both agency and latency. Other issues remain, though, such as trust and security, as discussed in Chapter 13.
Service-oriented architectures (SOA) are directed at supporting business enterprises on the Internet. The notion is that business A could obtain some processing service b from vendor B, service c from vendor C, service d from vendor C, and so on. The service that A obtains from C might be based upon the result obtained from B in a preceding interaction. As a more specific example, a company might obtain bids from multiple travel agencies for a requested travel itinerary, select one of the travel agencies, then have that agency interact directly with subcontractors to contract the various specific services. Such services might include ticketing airline flights, obtaining a credit check, and issuing electronic payments to a vendor. All these interactions would be supported by SOA mechanisms.
Independence of the various interacting organizations, or at least of the services comprising a SOA, is fundamental to the SOA vision. Accordingly service-oriented architectures are conceptually part of the decentralized design space. SOAs must deal with all the network issues of distributed systems, plus the trust, discovery, and dynamism issues present in open, decentralized systems. Indeed, service-oriented architectures are the computer-based equivalents of the decentralized systems we see active in ordinary person-to-person commerce: Businesses and customers interact with each other in myriad, complex ways. Customers have to find businesses that offer the services they require, must determine if a business proffering a service is trustworthy, engage subcontractors, handle defaults, and so on.
From an architectural perspective, participating organizations on the Internet present a virtual machine layer of services of which users (client programs) may avail themselves. This view is portrayed in Figure 11-7, where a client has an objective (such as obtaining all the reservations, tickets, and travel advances associated with an itinerary) and calls upon various services throughout the Internet to meet this objective. Various of these services may themselves call upon other services on the network to achieve their subgoals. The virtual machine of the service-network is rather unlike the virtual machine architectures discussed in Chapter 4, however. The various SOA services, corresponding to functions in a classical virtual machine architecture, are offered by different controlling agencies; they may be implemented in widely varying ways, pose varying risks (such as being impersonated by a malicious agency), may come and go over time, and so on. The challenge, thus, is to provide the necessary support to a client who wants to use the service-network to achieve its goals. Web services, a particular way of providing an SOA, responds to this challenge by offering up a plethora of approaches, standards, and technologies.

The core problem is, how, architecturally, should the notion of business applications created using the virtual machine of the service network be realized? The answer, not surprisingly, entails:
Describing the components—that is, the services.
Determining the types of connectors to use—how the services will communicate and interact.
Describing the application as a whole—how the various services are orchestrated to achieve the business goals.
Additionally one might also consider how new services are discovered, since the context is one in which independent agencies may create new services that enterprises may want to weave into their current processes.
The services of SOAs are simply independent components, as we have discussed and illustrated throughout the text. They have an interface describing what operations they provide. They have their own thread of control. Services can be described in the Web services world using WSDL—the Web Services Description Language. WSDL describes services using XML as a collection of operations that may be performed on typed data sent to/from the service. In a more general SOA context, their interfaces may be described by APIs written in some particular programming language, such as Java or Ruby.
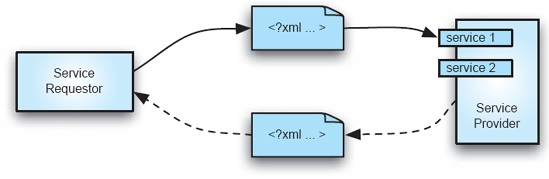
Connectors are the more interesting part of SOAs. The simplest mechanism used by SOA is asynchronous event notification. The top half of Figure 11-8 illustrates this. The basic model in this example is that a service requestor sends an XML document to a service provider across the network by any of a variety of protocols, anything from e-mail to HTTP. The obligation on both parties is that the XML document be structured so that both understand it. In this simplest model, the service provider may take some action upon receiving and reading the document, but there is no obligation for the provider to return anything to the requestor. Naturally, there are many situations where the desired interaction is indeed for the provider to return information to the requestor; that is supported too, and is shown in the dotted lines in the bottom half of Figure 11-8. Note that in this second example, the connection model has shifted from one-way, asynchronous events to an asynchronous request-response model, resembling a remote procedure call or perhaps a distributed object method invocation.
One key point here, of course, is that such interactions do not have the same semantics as a remote procedure call or the semantics of a distributed object invocation. The presence of agency issues, interaction based upon XML document exchange, and absence of various programming semantics, such as object persistence, are the bases for the differences.
With regard to the application as a whole, in essence what is required is an architecture description language, such as considered at length in Chapter 6. SOAs demand, however, that the ADL used must be executable; formality and complete semantics are thus required. Essentially, an SOA application could be described in a generic scripting language, but so doing would likely obscure important relationships between the services. The more natural choice is to use a language that allows effective expression of business workflows/processes. One language used is WS-BPEL, the Web Services Business Process Execution Language. BPEL is a scripting language that is compositional; that is, a BPEL program can appear as a service (component) in another workflow. The language is statically typed and expressed in XML, though proprietary graphical editors are available.
Other architectural styles and concepts appear throughout SOAs. Notable is the use of publish-subscribe mechanisms for discovery of newly available services or service providers. Other developers have created declarative models for utilizing Web services, akin to the interpreter style discussed in Chapter 4. Most—if not all—of the styles discussed in Chapter 4 have been used somewhere in the Web services world. (Note however that though the Web services literature sometimes speaks of a "layered set of protocols" this does not imply a layered architecture, as protocol descriptions often do not correspond to components.)
Despite the simple core model of SOA, in practice there is a great deal of complexity. This complexity arises from attempting to simultaneously satisfy many goals, such as interoperability across heterogeneous platforms, while coping with the difficulties inherent in open, decentralized systems. All this complexity does not necessarily yield an effective approach. For instance, the decision to make service providers announce and support specific services that others can "invoke"—the virtual machines decision—induces a particular kind of fragility and rigidity. Should a service provider ever change the interface to a service then all users of that service must become aware of the change and modify their requests accordingly. This is directly analogous to the problems of programming in a language such as Java and having a public method signature be modified—all of the code that is dependent on that interface must change. For this and other reasons, many decentralized enterprise application developers have chosen to base their designs on REST (thus focusing on the exchange of representations/data), rather than SOAP/Web services (thus focusing on the invocation of functions with arguments).[16] Amazon.com, for example, offers its Web services to developers either in REST form or as SOAP/Web Services interfaces. In practice, the REST-based interfaces have proven popular with developers.
This SOA design decision to focus on invocation of functional interfaces was not the only option. Just as not all programs depend on calls to public interfaces, an SOA could have been defined wherein service requestors pose descriptions of computations that they want performed, and leave it to service providers to determine if they are able to perform that computation and, if so, how.
This section examines the architectures of applications from a few specific domains. Through this examination we show, by example, how various architectural styles and patterns have been refined and exploited to provide the foundational core of effective solutions. While the architectures are drawn from specific application domains, the techniques used in developing the solution architectures, the analyses that accompanied the design, and even the resulting styles themselves are widely useful, extending beyond the confines of these source domains.
The field of robotics consists of a class of systems that reveals a great deal of diversity based on differences in the degree of autonomy and mobility the various robotic systems exhibit. Exemplars of this variety are:
Mobile tele-operated systems, such as bomb disposal robots, where full or partial control of the robot system's movement and actions is in the hands of a human operator who may be located hundreds of miles away.
Industrial automation systems, such as automotive assembly robotic arms, which autonomously perform predefined tasks without the need to move or adjust to their environment, as it is assumed that the environment, by design, conforms to the robot's task and movements.
Mobile autonomous robots, such as DARPA Grand Challenge vehicles, which are not only responsible for their own autonomous control without human intervention but have to also traverse through and deal with unpredictable environments.
From an architectural and general software engineering perspective, two factors are primarily responsible for making software development challenging in the robotics domain: the physical platforms and devices comprising the robots and the unpredictable nature of the environments in which they operate.
Robotic platforms are integrations of a large number of sensitive devices prone to malfunctions, such as wireless radio communications and vision sensors, complicating the need to coherently integrate the devices. The software systems operating robotic platforms must be capable of continued operation in the face of diminished hardware capacity and the loss of essential functions. The information provided by hardware devices such as sensors may also exhibit a high degree of unreliability and intermittent spikes of erroneous sensor readings, necessitating the capacity to not only continue operating but also to compensate seamlessly for such errors.
The second challenging element is the need to operate within environments that can be dynamic and unpredictable. Developing a mobile robot that can traverse unknown terrain through varying weather conditions and with potentially moving obstacles, for example, greatly increases the difficulty of designing its software control systems in a way that can account for and continue operating under conditions not fully predicted during the system's design and development.
Given these challenges and the nature of the domain, several software qualities are of special interest in robotic architectures: robustness, performance, reusability, and adaptability. The unreliability of many robotic environments motivates the need for robustness; the often stringent demands of working within a real-time environment (the world in which the robot operates) induces specific performance requirements. The need for reuse of developed software components across a variety of robotic systems is driven by the high cost of developing the high-performance and reliable modules necessary for the domain. Moreover, many robotic platforms use the same or very similar hardware components and therefore share a common need for drivers and interfaces for those devices. Finally, adaptability is particularly important given that the same hardware platform can be used with a modified software control system in order to perform a different task with unchanged devices.
Robotic architectures have their origins in artificial intelligence techniques for knowledge representation and reasoning. They have been subsequently improved in response to shortcomings in the application of these concepts, as well as general advances in the field. The following sections present a brief overview of this progression, discussed in the context of specific architectural examples, the trends they embody, and their key architectural decisions and goals.
Sense-Plan-Act. Recognizing the inability of building robotic systems solely using artificial intelligence search algorithms over a world model, the sense-plan-act (SPA) architecture (Nilsson 1980) identifies the necessity of using continuous feedback from the environment of a robot as an explicit input to the planning of actions. SPA architectures contain three coarse-grained components with a unidirectional flow of communication between them, as illustrated in Figure 11-9: The sense component is responsible for gathering sensor information from the environment and is the primary interface and driver of a robot's sensors. This sensor information is provided as an input to the plan component, which uses this input to determine which actions the robot should perform, which are then communicated to the act component—the interface and driver for the robot's motors and actuators—for execution. To this level of detail the architecture resembles the sense-compute-control (SCC) pattern of Chapter 4. A closer look reveals an important distinction, however.

Figure 11-9. An illustration of SPA architectures. The emphasis is on planning actions based on its internal world model subarchitecture.
The plan component is the primary driver of robot behavior in SPA architectures. Borrowing from artificial intelligence techniques, planning involves the use of sensory data to reconcile the robot's actual state—as deduced by this sensory data—with an internal model of the robot's state in the environment. This internal model is then used in conjunction with a task specification to determine which actions should be performed next by the act component in order to complete the robot's intended activity. The internal model is repeatedly updated in response to newly acquired sensory inputs, indicating what progress the robot is making (if any), with the objective of keeping the model consistent with the actual environmental conditions. The SCC pattern, in contrast, does not maintain such a model or perform sophisticated planning.
From an architectural perspective, the SPA architecture captures an iterative unidirectional data flow between the three components, similar to a pipe-and-filter architecture, with a subarchitecture for the plan component varying and depending on the kind of planning and robot state model used by a specific SPA architecture.
Systems following the SPA architecture suffer from a number of issues primarily relating to performance and scalability. The main drawback is that sensor information must be integrated—referred to as sensor fusion—and incorporated into the robot's planning models in order for actions to be determined at each step of the architecture's iteration: These operations are quite time-consuming and usually cannot keep up with the rate of environmental change. The performance of this iterative model-update-and-evaluation does not scale well as robotic system capabilities and goals expand. This poor performance is a handicap when the environment changes quickly or unpredictably, and is the primary driver for the development of alternative robotic architectures.
Subsumption. Attempting to address the drawbacks of SPA architectures, the subsumption architecture (Brooks 1986) makes a fundamental architectural decision: the abandonment of complete world models and plans as the central element of robotic systems. While the flow of information originates at sensors and eventually terminates at actuators that effect action (as in SPA and SCC architectures), there is no explicit planning step interposed between this flow. Subsumption architectures—as can be seen in Figure 11-10 —are composed of a number of independent components, each encapsulating a specific behavior or robot skill. These components are arranged into successively more complex layers that communicate through two operations: inhibition and suppression. These operations are used, respectively, to prevent input to a component and to replace the output of a component. In the figure, output from Skill C may cause the input from Skill A to Skill B to be delayed by time t; similarly output from Skill C may override the output of Skill B to Actuator 1 for time t.

Figure 11-10. An illustration of an example subsumption architecture, showing the inhibition and suppression operations between levels of components.
The fundamental architectural feature of subsumption architectures is the modularization of robot behavior and functionality: Rather than behavior being represented in a single model, independent components arranged in layers each capture one facet of the overall behavior without a single, overarching representation. Each of these components independently relies on sensory inputs in order to trigger the actions it is supposed to perform, and overall robot behavior emerges from the execution of those actions without a central plan coordinating this behavior. Subsumption architectures, therefore, are more reactive in nature. This characteristic explicitly addresses the performance shortcomings of SPA architectures, and subsumption architectures garnered popularity for their fast and nimble performance.
Architecturally, subsumption adopts a component-based approach to the basic data flow between sensors and actuators allowing for data flow cycles, although the interfaces of these components are simple and capture the value of a single signal. In contrast to SPA, the overall behavior of a subsumption robot depends on the overall topology of the system and how components are connected rather than a single abstract model.
Subsumption architectures are not without drawbacks, despite their better performance characteristics compared to SPA robots. The fundamental drawback of subsumption in practice is the lack of a coherent architectural plan for layering and consequential support. While the conceptualization of the subsumption architecture describes the use of layers in order to organize components of different complexities, there is no explicit guidance or support for such layering in the architecture. Components are inserted into the data flow depending on their specific task, without their position necessarily being related to the layer within which they are positioned, and without components belonging to the same layer being inserted in similar manners and positions.
Three-Layer. Following the development of subsumption, a number of alternatives were developed that attempted to bridge the gap between between SPA's plans and subsumption's reactive nature; these hybrid architectures can be grouped together under the rubric of three-layer (3L) architectures. [One of the earliest examples is found in (Firby 1989).] The widely adopted 3L architectures—illustrated in Figure 11-11 —are characterized by the separation of robot functionality into three layers (the names of which may differ from system to system): the reactive layer, which quickly reacts to events in the environment with quick action; the sequencing layer, which is responsible for linking functionalities present in the reactive layer into more complex behaviours; and the planning layer, which performs slower long-term planning.
With the adoption of three separate layers each concerned with a different aspect of a robot's operation, 3L architectures attempt to combine both reactive operation and long-term planning. The planning layer, then, performs tasks in a manner similar to SPA architectures by maintaining long-term state information and evaluating plans for action based on models of the robot's tasks and its environment. The reactive layer—in addition to containing the basic functions and skills of the robot such as grasping an object—captures reactive behavior that must execute quickly and immediately in response to environmental information. The sequencing layer that links the two is responsible for linking reactive layer behaviors together into chains of actions as well as translating high-level directions from the planning layer into these loencing layer of the architecture. The sequencing layer, then, often is simply a virtual machine that executes programs written in these swer-level actions. The majority of 3L architectures adopt some kind of special-purpose scripting language for the implementation of the sequcripting languages.
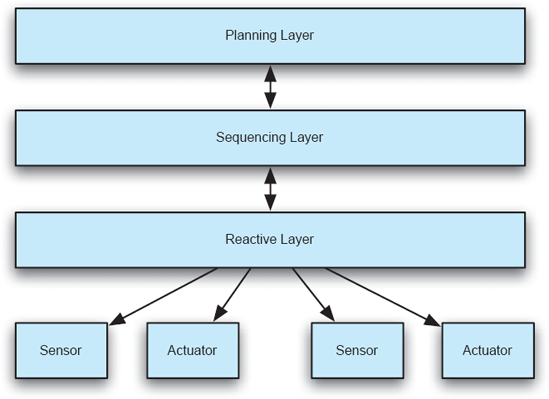
Figure 11-11. An illustration of 3L architectures, showing the relationship between each layer and the basic sensors and actuators.
From an architectural perspective, 3L is an example of a layered architecture with a bidirectional flow of information and action directives between the layers while using independent components to form each layer. The behavior of 3L architectures is dependent not only on the arrangement of their components, but also on the operation of the internal subarchitecture of the sequencing layer.
One challenge associated with the development of 3L architectures is understanding how to separate functionality into the three layers. This separation is dependent on the robot's specific tasks and goals and there is little architectural guidance to help in this task; the separation largely depends on the design expertise of the architect. Depending on the tasks the robot is intended to perform, there is also a tendency for one layer to drastically dominate others in importance and complexity, which clouds the hybrid nature of 3L architectures. The interposition of the sequencing layer in the middle of the architecture also results in difficulties when translating the higher-level planning directives into lower-level execution. This translation necessitates the maintenance and reconciliation of the potentially disparate world and behavior models maintained by the planning and sequencing layers, and may cause unnecessary performance overhead.
Reuse-Oriented. Following the development and widespread use of 3L hybrid architectures, the focus of recent robotic architecture efforts has shifted to the application of modern software engineering technologies with the primary goal of increasing the level of component reuse and therefore maximizing returns on the time and cost invested in their development. While many of these systems adopt ideas and principles from the previously discussed architectures and exhibit varying degrees of layering and subarchitectures based on planning or task modeling, their primary focus is a clear definition of interfaces and the promotion of reuse.
The primary techniques and technologies that these reuse-oriented architectures adopt are explicit object-oriented interface definitions for components and the use of middleware frameworks for the development of components that are reusable across projects. The architecture of the WITAS unmanned aerial vehicle project (Doherty et al. 2004), for example, adopts CORBA as the mechanism for information interchange and enforces clearly defined interfaces for each component using CORBA IDL. It also adopts a hybrid approach that uses a special-purpose task procedure specification language subarchitecture for decision making and planning. In addition to enabling reuse, this approach also enables the distributed operation of robot components for better resource utilization. Another example of this class of systems can be found in the CLARATy reusable robotic software architecture (Nesnas et al. 2006): This two-layer architecture adopts a goal-network approach for planning while focusing on defining generic device interfaces that clearly identify the primary functions of a class of devices in a way that is decoupled from the specific device used in any particular instance of a CLARATy architecture. By doing so, different devices of the same type (rangefinders, for example) can be seamlessly integrated into the architecture without the need to redefine this device's interface.
Robotic systems represent a very active type of application: The software must make a physical system perform some set of tasks. Sensor nets are, in a manner of speaking, a largely reactive application: Their first task is to monitor the environment and report on its state. Wireless sensor network (WSN) systems are now used in a variety of domains, including medical systems, navigation, industrial automation, and civil engineering for tasks such as monitoring and tracking. These systems enjoy the benefits of low installation cost, inexpensive maintenance, easy reconfiguration, and so on. Nonetheless WSNs can be very challenging to implement, for they may need to be integrated with legacy wired networks, other embedded devices, and mobile networks that include PDAs and cell phones for user notification. The wireless devices themselves are typically highly constrained with respect to power consumption, communication bandwidth and range, and processing capacity. Wireless sensor systems impose further constraints with regard to fault-tolerance, performance, availability, and scalability.
The Bosch Research and Technology Center, in conjunction with researchers at the University of Southern California, have explored how WSNs should be designed to meet the multitude of challenges present (Malek et al. 2007). The architecture–centric design that has emerged for Bosch's applications is interesting for it explicitly combines three separate architectural styles to achieve all the system's goals. The design is sketched in Figure 11-12.
As depicted, MIDAS's reference architecture applies three different architectural styles. The peer-to-peer portion of the architecture is shown in the bottom portion of the diagram. It is responsible for deployment activities, including the exchange of application-level components. The publish-subscribe portion of MIDAS corresponds to the communication backbone responsible for the routing and processing of sensor data among the various platforms. The service-oriented portion of MIDAS is depicted at the top of the diagram. These services represent generic, but less frequently used system monitoring and adaptation facilities. These services are distributed among the platforms.
The central theme of this chapter has been that architectures for complex applications result from deep understanding of the application domain, careful choice of constituent elements and styles based upon experience and their known properties, and hybridization of these elements into a coherent solution. REST is the example par excellence of this. The Web would not be the success it is today without this careful architecture.

Figure 11-12. The MIDAS wireless sensor network architecture. Diagram adapted from (Malek et al. 2007) © IEEE 2007.
More than just exemplifying how a complex style arises from the combination of elements from simpler styles, REST illustrates important means for coping with issues that arise due to the presence of network issues, notably latency and agency. REST thus serves as a model from which solutions to related problems can be derived.
Networking issues—especially latency and agency—have been emphasized in the chapter since an increasingly large proportion of applications are now network based. The discussion of peer-to-peer systems highlighted concerns with discovery of other peers, search for resources, and risks due to potential performance problems and malicious entities. The particular issues of security and trust will be covered in detail in Chapter 13.
Note that just because an application grows in scope the solution architecture does not necessarily become more complex. Insight into the essence of a problem coupled with effective exploitation of a few simple ideas can yield a highly effective application. This is clearly the case with, for example, Google, Akamai, and Skype. Great solutions to tough, commercial problems do not just happen: They result from great architectures that reflect experience, choice, and discriminating taste.
Concern for non-functional properties such as scale, performance, and security has dominated the designs considered in this chapter. In the next three chapters we examine specifically how to design to achieve such properties. The design techniques presented in each of these three chapters have emerged from experience in creating applications such as those considered above. Chapter 12 considers such properties as efficiency and dependability, while Chapter 13 is devoted to designing applications to achieve certain security and trust properties. The non-functional property of adaptability seen in the preceding discussion of, for instance, peer-to-peer systems is given additional in-depth treatment in Chapter 14.
The eight fallacies of distributed computing, as given in the chapter, are stated as lies. For instance, "The network is reliable." What are the consequences for a distributed application's architecture from realizing the network is not reliable?
What are the consequences for a distributed application's architecture from the other seven fallacies?
What are the three main stylistic elements from which REST was derived?
How do pure peer-to-peer systems, such as the original Gnutella, discover the presence of resources (such as an.mp3 file) in the network? How do hybrid P2P systems improve on that?
What are the main styles for robotics architectures, and what problems were observed with the early styles?
Any two architectural styles can be combined simply by fully encapsulating the use of one style inside of a single component that is present in the usage of the other style. REST however, shows how some styles can be compatibly used together, at the same level of abstraction. For all six pair combinations of the following styles, describe how the styles can be used together at the same level of abstraction, or explain why they cannot.
Layered/virtual machines
Event-based
Pipe-and-filter
Rule-based
Develop an architecture for a lunar lander video game example that shows the result of (effectively) using two or more architectural styles in combination.
Create a diagram like that of Figure 11-1 that indicates the intellectual heritage of the C2 style, as described in Chapter 5.
Search on the Web and identify other applications (than the Web itself) to which REST has been applied.
What is the architecture of AOL's Instant Messenger? How does it compare to the architecture of ICQ's chat features? How do they compare to the architecture of IRC (Internet Relay Chat)?
What are the trust assumptions of the Napster architecture? Develop a modification to the Napster architecture that would decrease the risk of downloading malicious content from another peer.
Are service-oriented architectures peer-to-peer systems? Describe why this is and why this is not a valid description.
Several software architecture styles take inspiration, and sometimes their name, from interactions in real, physical life. Peer-to-peer interactions is one example. This relationship can go the other direction too: Software architectures can also be used to describe interactions in everyday society. Describe the service architecture of a fast-food restaurant (such as In-N-Out Burger or McDonald's) using the styles of Chapter 4, in combination as necessary.
The grid style described in the chapter is very high level, and described to be broadly descriptive of many grid applications. Identify one actual grid application and describe its architecture. How does that architecture compare to the nominal architecture of Figure 11-2?
Koala has been used to develop architectures for consumer electronics, such as televisions. If a distributed media system were to be developed (with media sources located one place in the network, and various processing and display devices and software located elsewhere in the network), would Koala still be a good choice for describing the architecture? Why or why not? What would be essential in such a situation?
References for further study of distributed architectures and the REST style were provided in the text. Central are Tanenbaum's text on distributed systems (Tanenbaum and van Steen 2002), Fielding's dissertation (Fielding 2000), and subsequent journal publication (Fielding and Taylor 2002).
Google's architecture is becoming increasingly public, with many of its technologies described in papers available at labs.google.com/papers.html. The Google File System, for example, is explained in (Ghemawat, Gobioff, and Leung 2003) and MapReduce is presented in (Dean and Ghernwat 2004). Further information on Akamai is available in (Dilley et al. 2002); other resources are available at the company's Web site.
As the main chapter text mentioned, knowing Skype's architecture exactly is somewhat difficult to determine because the client software has been obscured using several sophisticated techniques. The architecture described in the text reflects a forensic analysis. One key publication in this regard is (Baset and Schulzrinne 2004), which reflects observation of the Skype client in action. Another project worked at analyzing the obscured client code. Results can be found at recon.cx/en/f/vskype-part1.pdf and recon.cx/en/f/vskype-part2.pdf.
Good references for Web services are somewhat hard to come by. Many publications and Web sites are shallow in their technical presentation, imprecise, or else focused on only a narrow facet. A good introduction, however, is found in (Vogels 2003). A technically richer paper is (Manolescu et al. 2005). WS-BPEL is described in (OASIS 2007).
A high-performance computing architecture that forms an interesting contrast to grid architectures is MeDICi (Gorton 2008; Gorton et al. 2008).
The architecture of Linux has been recovered and described (Bowman, Holt, and Brewster 1999), showing the differences between the application's prescriptive and descriptive architectures. As elsewhere mentioned in this text, the architecture of the Apache Web server has also been recovered and described (Gröne, Knöpfel, and Kugel 2002; Gröne et al. 2004). Both projects are interesting studies in architectural recovery; they also are useful for retrospectively seeing how multiple styles are combined to solve challenging problems.
[13] The Web as it exists today in the form of the union of the HTTP/1.1, URI, and other standards, along with various server implementations, should not be equated with REST. Several elements of the Web in current use are at odds with REST; origins of this architectural drift are explored in Fielding's dissertation, as cited earlier.
[14] An agency boundary denotes the set of components operating on behalf of a common (human) authority, with the power to establish agreement within that set (Khare and Taylor 2004).
[15] Skype is a trademark of Skype Limited or other related companies.
[16] See the feature, "Words about Words in Web Services," to learn about the term SOAP.