
Few applications are designed, built, used, and ultimately discarded without undergoing change. Change is endemic to software: Both the perceived and actual malleability of the medium, coupled with the ease of altering code, induces everyone associated with an application to initiate changes. Users change their minds about what they want and hence what they require of an application. Designers seek to improve their designs with respect to performance, or appearance, or some other property. The application's usage environment can change. Whatever the reason, software developers are faced with the challenges of coping with the need to modify an application. We group all of these types of changes under the term adaptation : modification of a software system to satisfy new requirements and changing circumstances.
Adaptability was introduced in Chapter 12 as one of several non-functional properties for which architects must frequently design. Several basic architectural techniques supporting adaptation were presented. Just as Chapter 13 was devoted to in-depth exploration of the non-functional properties of security and trust, so this chapter delves further into adaptability. Nonetheless, this chapter does not aspire to present techniques for dealing with all possible types of adaptation at all levels of granularity and abstraction—to do so would require a book of its own. Consistent with the focus of the book, our discussion is centered on facilitating change in the context of software architectures: We focus on adaptation to a system's principal design decisions—its architecture—and on changes that proceed from a strong architectural foundation. We consider processes for effecting change that are conceptualized in terms of the system's architecture, and show the value and role of explicit architectural models in supporting and effecting adaptation. We also consider one of the more difficult types of change: modifying applications on-the-fly, showing how this can be achieved using an architecture- and connector-centric approach.
The goals of the chapter are to:
Characterize adaptation, showing what changes, why, and who the players are.
Characterize the central role software architecture plays in system adaptation.
Present techniques for effectively supporting adaptation, based on an architecture-centric perspective.
This chapter reveals the particular power of connectors in supporting adaptation, especially in those situations where the connectors remain first-class entities in the implementation and where communication is event-based. Highly dynamic applications are possible in such situations and offer the opportunity for creating novel, flexible, highly adaptable applications.
Outline of Chapter 14
14 Architectural Adaptation
14.1 Concepts of Architecture-centric Adaptation
14.1.1 Sources and Motivations for Change
14.1.2 Shearing Layers
14.1.3 Structural Elements Subject to Change
14.1.4 Change Agents and Context
14.1.5 Architecture: The Central Abstraction
14.2 A Conceptual Framework for Architectural Adaptation
14.3 Techniques for Supporting Architecture-centric Change
14.3.1 Basic Techniques Corresponding to Activities of the Conceptual Framework
14.3.2 Architectures/Styles that Support Adaptation
14.3.3 The Special Problems of On-the-Fly and Autonomous Adaptation
14.4 End Matter
14.5 Review Questions
14.6 Exercises
14.7 Further Reading
Several motivations for change are familiar to developers. Perhaps the most common is corrective change, where the application is adapted to conform to the existing requirements. Put in other words, corrective change means bringing the descriptive architecture into conformance with the prescriptive architecture. Put most simply, bug fixing. Whether bug fixing is easy or highly disruptive, however, may depend on the root cause of an error: Did the observed problem with the application stem from a small, localized error in the code, or result from a profound mistake made at the highest level of system structure? Understanding the root cause is essential for determining how to effect the fix; attempting to patch a deep problem with localized change usually is not effective.
A second common motivation for change is modification to the functional requirements for a system—new features are needed, existing ones modified, perhaps some must be removed. Rather than thinking that the existence of such needs for change reflect an inadequate system planning or analysis process, functional change requests often proceed from success with the existing application. Once applications are in use they inspire users to think of their task in new ways, leading to new ideas for what might be accomplished. Applications in use may change the usage context, or the usage context may change for extrinsic reasons. Whatever the source, feature change requests typically represent changes to the application's architecture.
A third motivation for change is the requirement to satisfy new or changed non-functional system properties. Such properties include security, performance, scale, and so on, as discussed in Chapters 12 and 13. New non-functional properties may induce profound changes to a system's architecture. One example is the World Wide Web. Prior to 1994 the Web's governing protocol was HTTP/1.0, a point-to-point protocol with no provision for proxies or caching. The change to HTTP/1.1 was accomplished by the adoption of a new architectural style for the Web (viz., REST), enabling the Web to scale from thousands of servers and tens of thousands of clients, to many millions of each. Similarly, as security attacks on Microsoft's IIS Web server increased, a significant redesign was required to meet the new threats. Another non-functional property that may cause significant architectural change is "better organization"—restructuring an application in anticipation of future change requests. For instance, a new middleware platform (that is, connector technology) may be put in place as a proactive step toward supporting potential future modifications.
A fourth common motivation for system adaptation is the need to conform to a changed operating environment. In this situation, neither the application's functions, nor its non-functional properties are altered, but the application's structure must be adapted to run, for example, on new hardware or to accommodate changes in interfaces to external systems.
More obviously germane to the software architect are motivations for change that arise from product-line forces. Strictly speaking, such changes can be classified under one of the preceding types of change, but such classification would obscure the insights.
The first of these product-line motivations is the desire to create a new variant within a product line. The notion here is that the architects have previously identified a branch point within a product-line architecture and at that branch point a new variant is identified. For example, in consumer electronics, a branch point within the design for integrated television systems is the interface to a high-capacity storage/replay subsystem—a hard disk, a DVD recorder/player, or a tape system perhaps. If it becomes desirable to interface with a different technology, perhaps Blu-ray, a new variant at that branch point is created. In our long-running example of the Lunar Lander video game, a new variant might be based upon the desire to utilize a new wireless joy-stick for controlling the lander or to incorporate a new three-dimensional graphics engine having improved performance.
Another of the product-line motivations is creation of a new branch point, thereby identifying a new opportunity for product marketplace segmentation. For instance, an electronics manufacturer may decide to adapt the design of its television products to enable them to work with home security systems, perhaps by using picture-in-picture technology to allow continuous display of surveillance camera data while watching broadcast TV. The existence of many types of external security systems implies many possible variants within this branch point; other variants are implied by the many ways of integrating surveillance information into the television display environment. New branch points in the Lunar Lander design might focus on multiplayer environments or on extensibility to allow missions to other solar system objects.
Yet another product-line motivation comes from the desire to merge product (sub-)lines, thereby rationalizing their architectures. A successful effort of this type will yield a common product-line architecture without requiring the complete creation of a new architecture. The goal, ostensibly, is to preserve as much as possible from the contributing architectures.
One type of adaptation that will be discussed later in this chapter is on-the-fly adaptation. The difficulty of supporting such change is typically greater than for non-real time adaptation, so a few words are needed here to prompt its consideration. A simple but perhaps extreme example motivating this type of change comes from planetary exploration. The Cassini/Huygens spacecraft were launched from Cape Canaveral in October 1997; they did not reach their intended destination, Saturn, until July 2004. During transit to Saturn the onboard software systems were upgraded several times. As the Cassini Web site (NASA Jet Propulsion Laboratory) puts it, "This development phase will never really be complete, since new command sequences are continually being created throughout Cassini's operation. New flight software will also be developed and loaded aboard the spacecraft periodically, to run in the Command Data Subsystem, Attitude and Articulation Control Subsystem, as well as in the physical science instruments onboard." As a system it is clear that Cassini could not be stopped and reloaded with the new software; rather the updates had to take place while the system was in continuous operation.
A more prosaic example is the extension of Web browser functionality. If when surfing the Web a resource is encountered that requires a novel type of display software (such as for a new type of audio encoding, perhaps), the browser must be extended. If the browser requires the user to download the new extension, perform some installation steps, and then restart the browser—or worse yet, the computer—before being able to continue, the user is inconvenienced. After restart the user will have to renavigate to the resource that demanded the extension in the first place. A more pleasant strategy, from the user's perspective, is to support the download and installation of the new software (that is, adaptation of the browser) dynamically, so that the user may continue usage in an uninterrupted manner.[18]
Motivations for supporting online (dynamic) change thus include:
Nonstop applications: Ones in which the software cannot be stopped because the application cannot be stopped—the services of the software are continually required or safety-critical.
Maintaining user or application state: Stopping the software would cause the user to lose mental context or because saving and/or re-creating the software's application state would be difficult or costly.
Re-installation difficulty: Applications with complex installation properties, such as software embedded in an automobile.
Finally, all software adaptation is motivated by observation and analysis. While perhaps this is an obvious point, the role of observation and analysis is critical in the process of supporting software adaptation, and will be discussed later in the chapter. The behavior and properties of the extant system are observed and compared with, for instance, goals and objectives for the system, and to the extent that analysis reveals a discrepancy, adaptation activities are initiated.
Before going further in consideration of the adaptation of software systems it is worth a moment to consider change in physical, building architecture. Stewart Brand's insightful book, How Buildings Learn—What Happens After They're Built (Brand 1994), examines how, and why, buildings change over time. We have all seen this process, of course: We rearrange the furniture in our offices and homes, we install new cabling in our homes to accommodate new audio systems, we install new windows to remove drafts and make a building more energy-efficient. On infrequent occasions we remodel our homes, adding new space or reconfiguring existing space. On very rare occasions we might even see a house physically moved—for instance, if it is of historical significance but is in the way of a new civic development.
Brand categorizes the types of change that can be made to a building in terms of "shearing layers." Building upon earlier work by Frank Duffy, Brand cites six layers.
![Shearing layers of change [from Stewart Brand's How Buildings Learn (Brand 1994)]](http://imgdetail.ebookreading.net/software_development/33/9780470167748/9780470167748__software-architecture-foundations__9780470167748__figs__1401.png)
These six shearing layers are illustrated in Figure 14-1, with the arrangement of the layers in the diagram corresponding to where, approximately, the layers appear in a physical structure.[19]
Software is like this too. Though software is intrinsically more malleable, the constraints and dependencies that we impose during the process of design and implementation make it behave much like a building. As we have seen, any software system has an architecture, which determines its load-bearing elements. It has a site in its installation, that is, the usage context, whether it is a home business, a research laboratory, or a bank. Similarly, software has a "skin" with its user interfaces; further analogies can be found for the other layers. The difficult thing about software, however, is that we cannot examine a software system by looking at the source code and readily distinguish one of the system's load-bearing elements from a mere incidental—an item as incidental as the placement of a hairbrush in a house.
One value of Brand's observations is the categorization of types of change according to the nature and cost of making a change within those dimensions. Put another way, our understanding of building layers, either as sophisticated housing developers or simply as occupants, informs us regarding what can be changed, how quickly, and roughly for what cost. For instance, as Brand noted, changes to a load-bearing element of a building—such as a steel girder—are just not done; to do so would likely endanger the structural integrity of the building. If we could make a similar categorization for software, one that would allow us to dependably identify the load-bearing elements of an application, it would help us understand the necessary techniques to effect a given change, and allow us to effectively estimate the time and cost to achieve the goals. Our intuition as to understanding the costs, difficulty, and time to make changes in any of these aspects to a building is pretty good, due at least in part to our long experience with buildings and their visible, material nature. Unfortunately, we do not usually have that kind of intuition with software, for we often cannot associate a change request with a particular type of layer in the software.
One of Brand's objectives in identifying shearing layers with their different properties is that it provides design guidance. Recognizing that the layers change at different rates, change is facilitated by limiting the coupling between the parts of a building that correspond to different shearing layers. (A simple example admonition that comes from this is, "Don't inextricably associate the appearance of a building with its services"—an admonition famously contravened by Paris's Pompidou Center, as illustrated in Figure 14-2. By making the services—such as escalators—part of the skin, changing one requires changing the other. Maintenance costs for the services now must also include costs for maintaining their very public appearance.)
These layer notions can be applied to software. In particular, the observation of layers and the admonition to decouple them is consistent with David Parnas's dictum that software engineers should "design for change." The layer concept goes beyond that simple platitude, however, to suggest specific ways of assessing whether a proposed connection between two elements of a system is appropriate or not. Are the elements proposed for connection in separate layers? In layers that are widely separated? Is the proposed connection one that maintains the essential aspects of independence for those layers?

Figure 14-2. The Pompidou Center: A good lesson in why appearance should not be inextricably linked with services.
In Brand's analysis, structure plays a somewhat distinguished role. Its relative immutability in building architecture means that it must be understood well, for it provides the bounds to the types of changes that can be applied. In the case of software, with its relative mutability, we have the opportunity for accommodating a great range of change—but only under certain condition. We can achieve effective adaptation if we make the structure of software explicit (that is, the system's architectural configuration of components and connectors), and provide ways for manipulating that structure. At a minimum, understanding a software system's architecture enables us to assess the potential for future changes.
Finally, Brand makes a trenchant observation about building architectures that provides key insight into software adaptation: "Because of the different rates of change of its components, a building is always tearing itself apart." As introduced in Chapter 3, a concern with software change is architectural erosion, the regressive deviance of an application from its original intended architecture resulting from successive changes. If a programmer modifies an application based only upon local knowledge of the source code, it can be quite difficult to determine if the changes made cut across the software's shearing layers. Put another way, the changes to code may not respect the principal design decisions that govern the application. To the extent that the boundaries are ignored while making changes, the structure is degraded. The preventative strategy for avoiding architectural erosion of this type is to base change decisions not on local analysis of the code, but on the basis of understanding and modifying the architecture, and then flowing those changes down into the relevant code, a theme we explore below.
Any of a system's structural elements, its components, connectors, and their configuration, may be the focus of adaptation. The particular characteristics of these elements as found in a specific system will significantly determine the difficulty of accommodating change and the techniques useful for achieving it.
Some changes may be confined to a component's interior: Its interface to the outside world remains fixed, but, perhaps to achieve a particular non-functional property, the component's interior must be altered. A component's performance may be improved, for example, by a change to the algorithm that it uses internally. In many cases, however, adaptation to meet modified functional properties entails changing a component's interface.
Beyond this simple dichotomy a component may possess capabilities that facilitate its adaptation, or its role in the adaptation of the larger architecture within which it resides.
First among these capabilities is knowledge of self and exposure of this knowledge to external entities. A component may be built such that its own specifications are explicit and included within the component. A straightforward form and use of such specifications are as run time assertions that validate that incoming parameters satisfy the assumptions upon which the component's design depends. In a verified, static (that is, non-adaptive) world, such run time assertion checking may well be considered wasteful, but in an uncertain, adaptive world, such checking may be a useful adjunct in maintaining a robust application. A less obvious use of such assertions is in gathering information that may motivate adaptations. Assertions may repeatedly detect violation of input assumptions. If a component retains a history of such violations and exposes that history to a monitoring agent, that information may guide the architect in identifying ways in which the architecture needs to be changed. More generally, a component may make its full specifications available for inspection by external entities. Such a capability enables dynamic selection of components to achieve system goals and hence is strongly supportive of adaptation. While not supported in all programming languages, component reflection is supported in Java.
Second is (self-)knowledge of the component's role in the larger architecture. For instance, a component could be built to monitor the behavior of other components in an architecture and to change its behavior depending upon the failure of an external component. A component may be able to query whether other components exist in an architecture that could be used to obtain an equivalent service. Similarly, if a component monitors its own behavior and realizes, for example, that it is not performing fast enough to satisfy its client components, it could request an external agent to perform some load leveling or other remedial activity.
Third is the ability to proactively engage other elements of a system in order to adapt. Continuing the previous example, rather than asking an external agent to reduce the load, a component might query whether external (sub-) components are available that could be used within the component to enable it to improve its own performance. While such a scenario is currently pretty far-fetched, such a capability is only a natural progression from components that are not self-aware and not reflective, to components that are reflective but passive, to components that not only are reflective but (pro)active in supporting system adaptation.
The capabilities listed above prefigure the general adaptation techniques discussed later in this chapter. The common theme is explicit knowledge and representation of a component's specifications and knowledge of its role within the wider architecture.
Component Interfaces Changes to component interfaces are often inevitable when modifying functionality. Changing a component's interface, however, requires changes to the interface's clients as well: The input and output parameters must match at both ends of the interaction. Many client components may not be "interested" in the new functionality represented by the new interface, yet must be modified nonetheless.
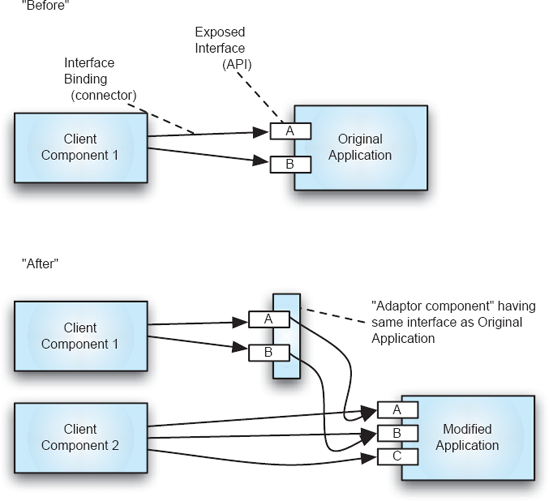
This undesirable ripple effect of change has motivated creation of techniques for mitigating such impacts. A popular technique is the creation of adaptors, whereby components wanting to use the original interface invoke an adaptor component, which then passes along the call to the new interface, as illustrated in Figure 14-3. A client needing the new interface calls the modified component directly.
Use of a technique such as this clearly has architectural implications: New components are introduced and tracing interactions to understand system functioning becomes more involved. Subsequent changes to one of the previously unmodified methods become even more complex: Should yet another adaptor be introduced? Should the method be changed in the root component and in all the previously created adaptors? Suffice it to say for now that "local fixes" that attempt to mitigate changes to component interfaces can have serious repercussions; the architect is wise to consider, in advance, a range of techniques for accommodating change, as discussed later in this chapter.
Just as components may be required to change, so may connectors, and depending on the type of change, the architectural implications may be profound or may be negligible, similarly for the resulting changes in the implementation. Typically, the motivation for changes to connectors is the desire to achieve altered non-functional properties, such as distribution of components, heightened independence of subarchitectures in the face of potential failures, increased performance, and so on.
Changes to connectors may be along any of the dimensions of connector design discussed in detail in Chapter 5. As the latter part of this chapter will show, choice of connector type is a major determinant of the effort involved in supporting architectural evolution. Roughly speaking, the more powerful the connector, the easier the architectural change. Connectors that remain explicit in the implementation code and that support very strong decoupling between components (such as those connectors supporting event-based communication) are superior for supporting adaptation.
Changes to the configuration of components and connectors—that is, how they are arranged and linked to one another—represent fundamental changes to a system's architecture. Such changes may occur at any level of design abstraction, and may be motivated by the need to meet new functional requirements or to achieve new non-functional properties. For instance, a common, large-scale configuration change is to move from an integrated business-to-business application model to an open, service-oriented architecture. The custom application may enable two businesses to communicate and transact business very efficiently, but a move to an open, service-oriented architecture may allow each party to more easily add new functionality, or support interactions with other business partners. Many of the core components may remain unchanged, but the way the components interact with each other and the connectors through which they communicate may be profoundly altered.
Effectively supporting such a modification requires working from an explicit model of the architecture. Many dependencies between components will exist, and the architectural model is the basis for managing and preserving such relationships. Most importantly, the constraints that governed creation of the initial architecture must be maintained if the architecture is to retain the same style. If maintaining the governing style constraints is not possible, then deliberative analysis should take place to determine an appropriate style for the new application. The move from custom, tightly integrated business-to-business applications to service-oriented architectures is precisely such a change: The fundamental architectural style of the application is altered.
The architectural model will need to manage deployment characteristics too, as basic component-connector relationships, in keeping with the discussion of Chapter 10.
Techniques for effecting change are determined not only by what is ultimately changed, but also by the context for the change and the character of the agent(s) performing the change. Important aspects of the context for change include:
The factors behind the change motivation: how a system is observed and what analysis can be performed on those observations.
The timing of the change: when in the development/deployment/use time line the change occurs.
The agents for achieving change include both people and software. Important attributes of the change agents include:
The location of the agent with respect to the system being changed.
The knowledge possessed by the change agent about the system, whether complete or partial.
The degree of freedom possessed by the change agent.
Each of the above items is considered in the following paragraphs.
Several types of motivation for change were discussed earlier. Depending on the particular motivation that is at work, different problems and opportunities for dealing with the change arise. All motivations spring from a combination of observations about a system and analysis of those observations. For example, a system may not perform some newly desired function (as determined by comparing its current behavior to the newly sought behavior), or it may need to be fixed (as determined by comparing its current behavior to the original specification). The key issue is where the observations about a system originate.
Some observations may be drawn from the engineer's review of the system's architecture. More likely is the situation where a user, or some external agent, observes the run-time behavior of the application. To the extent that these observations are tied or related to information about the architecture of the application, the adaptation task is eased. If the only observations are those that come from seeing an application's external functional behavior, then determining the related structure is a task akin to debugging: The offending behavior has to be (possibly laboriously) examined to see what parts of the application are responsible. If the application has, or can have, probes included within it that are designed to assist the analyst determine which internal elements are relevant, the adaptation can proceed more quickly. Every beginning programmer is familiar with this technique in its simplest form: the inclusion of dozens of println functions, to repeatedly indicate where the program is executing and the values that particular variables have.
As architectures become more complex the beginning programmer's print line technique becomes inadequate. The concept, though, is still valuable. Monitors of the architecture can be included in a system (typically in the connectors) to enable high-quality monitoring of the behavior. The more precise the information and the analysis based on that information, the better the change can be planned and managed. In extreme cases, the absence of a good technique for identifying the components responsible for a particular behavior may cause an engineer to replace an entire subsystem. With good information, however, a much more localized change may suffice. We return to the topic of embedded probes in Section 14.3.1 below.
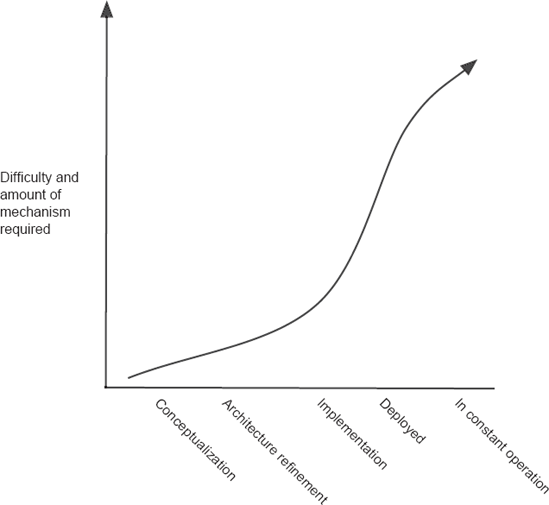
The positioning of change within a project's time line greatly affects the techniques available for accommodating the change. In short, the earlier the better. Rather than just repeating the old maxim that fixing problems in requirements is substantially cheaper than fixing them in code, we expand the time line to include system deployment and system use, for indeed some applications may need to be changed in situ, on the fly. A notional graph showing the relationship between cost and timing is found in Figure 14-4.
In Figure 14-4, the steep rise in cost is associated with accommodating change once a system is deployed; the costs top out when a deployed system must be changed on the fly. Deployment adds the costs of dealing with each individual installation of a system—possibly behind firewalls and customized at time of installation. On-the-fly adaptation requires special mechanisms and circumstances, a topic we treat on its own in Section 14.3.3.
Accommodating change early in a project's life is not the same, however, as fixing problems in the requirements. Identification, early in a system's design, of types of potential changes enables insertion of mechanisms specifically intended to facilitate those changes when they happen later. Far beyond a banal "design interfaces to be resilient in the face of potential, identifiable changes to the internals of a module," numerous sophisticated techniques designed to enable broad adaptation have been created. These include plug-in architectures, scripting languages, and event interfaces. These and others will be described in Section 14.3.2.
The processes that carry out adaptation may be performed by human or automated agents, or a combination thereof. Some trade-offs between these two types of agents are obvious, such as noting that humans can deal with a much wider range of problems and types of change or that automated agents can act with greater speed. Other issues may not be so obvious. One particular value of automated change agents is in the domain of deployed and continuously operating systems. If an adaptation change agent is part of a deployed application from the outset, the potential is present for an effective adaptation process: Getting to the deployed application is not a question. Moreover, the agent may have access to contextual information, whereby details of any local modifications and customizations are available. This potentially enables the change agent to act differently in every individual deployment. Users of modern desktop operating systems are familiar with such agents: Periodically a user is notified when an OS or application upgrade is available. If the agent is at all sophisticated, the advice given regarding the updates to be performed will be based upon knowledge of any local optimizations. (Often the downloaded update will perform a repeat or supplementary analysis, presenting messages such as "Locating installed components.")
In the case of dynamic adaptation the local presence of an automated change agent is essential. Managing the state of the application during the update can be a complicated matter, and is specifically discussed later in this chapter.
The knowledge possessed—or not—by the change agent can be a major determinant of the adaptation strategy followed. For example, there may be uncertainty surrounding the new behavior or concerning the new properties that are believed to be required. In such a case, an adaptation approach that deliberately works to mitigate risk is needed. This might involve processes that allow the engineer to easily retreat from a change if the change is not satisfactory. Prototypes or storyboards of potential changes are other strategies that could be employed when there is uncertainty.
Another key aspect of knowledge that governs adaptation strategy is knowing the constraints that must be retained in the modified system. More specifically, an adaptation should be performed with full knowledge of the architectural style of the application. Since the style is (typically) an intangible attribute of a system's structural architecture, knowing it and ensuring that any changes made are consistent with it requires extra work on the part of the adaptation team. The penalty for failing to know and respect the style is architectural degradation. That penalty may not have immediate repercussions, but through the course of successive changes the system's qualities will degrade and the difficulty of performing new changes will increase, sometimes reaching the point where further changes cannot be made at all.
Other important aspects of system knowledge include some obvious things. If the system's architecture has not been retained, then architectural recovery will be required. If a system component is a purchased binary, for which no information is available concerning its adaptation properties (if any), then large granularity changes will be needed ("component transplants"). If no analysis tools are available to help assess properties of a proposed change, then perhaps a more iterative approach to the adaptation should be followed. When it comes to adaptation, the more knowledge of the system and the change, the better.
The final aspect of the context of change is the degree of freedom that the engineer has in designing the changes. One might think that greater freedom is always better. Unfortunately, greater freedom comes at a significant cost: The search space for solutions is larger, there is less immediate guidance for the engineer on how to proceed, and assessing all of the consequences and properties of a possible change will take more effort. The assumption of this statement, of course, is that the engineer is attempting to do a high-quality job; the cost can always be kept down in the short term by simply adopting whatever adaptation scheme first comes to mind, and doing the work in the same manner or style as the engineer always does. The price is paid in the future, when, for example, it is discovered that the change inhibits further growth or otherwise degrades the system's architectural quality. The alternate approach is to know or learn the constraints of the application and work within those constraints to satisfy the needs. With this approach, coherency is retained and the engineer's energies are directed toward solutions within the current architectural style.
The final concept of architecture-centric adaptation is the central one: the architectural model. An explicit architecture is assumed in much of the preceding discussion. In the absence of an explicit architecture, the engineer is left to reason about adaptation from memory and from source code—neither of which has proven very effective in managing change. The presence of an explicit architecture provides a sufficient basis for the planning and execution of system adaptation. Since the architecture is the set of principal design decisions governing the system, adaptation based on the architecture proceeds from knowledge of those things that are most intrinsic to the system's design.
The critical need, of course, is to maintain the integrity of the architecture and its explicit representation throughout the whole course of adaptation. As discussed earlier, in Chapters 2 and 9, the most important and most difficult aspect of this task is maintaining consistency between the architecture and the implementation. As long as the implementation is faithful to the architecture, the architecture can serve as the primary focus of reasoning about potential adaptations. As soon as the architectural model fails to be a reliable guide to the code it loses its value for guiding changes; the engineer is left with just the code—the "software engineering" of the 1970s.
Note that apropos of the discussion above regarding the location of change agents, if the agent is an automated part of a deployed system, then for architecture to be the central abstraction governing adaptation, the architectural model must either be deployed with the application or communication with an outside reference must be possible. If the model is not available, the agent does not have any basis for architecture-based adaptation.
The next section places all the concepts discussed above into a comprehensive framework for architecture-based adaptation.
The first comprehensive conceptual framework for architecture-based adaptation was presented in 1999 (Oreizy et al. 1999). The framework, shown in Figure 14-5, shows the principal activities and entities and the key relationships among them. The diagram is simple enough to explain how a very static, requirements-based adaptation process proceeds, but sophisticated enough to indicate how a highly dynamic, automated adaptation process can work. Quoting from Peyman Oreizy and his colleagues' article,
The upper half of the diagram, labeled "adaptation management," describes the lifecycle of adaptive software systems. The lifecycle can have humans in the loop or be fully autonomous. "Evaluate and monitor observations" refers to all forms of evaluating and observing an application's execution, including, at a minimum, performance monitoring, safety inspections, and constraint verification. "Plan changes" refers to the task of accepting the evaluations, defining an appropriate adaptation, and constructing a blueprint for executing that adaptation. "Deploy change descriptions" is the coordinated conveyance of change descriptions, components, and possibly new observers or evaluators to the implementation platform in the field. Conversely, deployment might also extract data, and possibly components, from the running application and convey them to some other point for analysis and optimization.
Adaptation management and consistency maintenance play key roles in our approach. Although mechanisms for runtime software change are available in operating systems (for example, dynamic-link libraries in Unix and Microsoft Windows), component object models, and programming languages, these facilities all share a major shortcoming: they do not ensure the consistency, correctness, or other desired properties of runtime change. Change management is a critical aspect of runtime-system evolution that identifies what must be changed; provides the context for reasoning about, specifying, and implementing change; and controls change to preserve system integrity. Without change management, the risks engendered by runtime modifications might outweigh those associated with shutting down and restarting a system. ...
The lower half of [the diagram], labeled "evolution management," focuses on the mechanisms employed to change the application software. Our approach is architecture-based: changes are formulated in, and reasoned over, an explicit architectural model residing on the implementation platform. Changes to the architectural model are reflected in modifications to the application's implementation, while ensuring that the model and the implementation are consistent with one another. Monitoring and evaluation services observe the application and its operating environment and feed information back to the diagram's upper half.

Figure 14-6 presents a further refined framework. Rather than the somewhat arbitrarily labeled "adaptation management" and "evolution management" of Figure 14-5, this figure separates the activities into three types and shows the entities and agents involved in carrying out the activities. The essential insights of the earlier framework are present, but now with additional detail and precision.

The three activities are characterized as strategic, tactical, and operational. Strategy refers to determining what to do, tactics to developing detailed plans for achieving the strategic goals, and operations to the nuts-and-bolts of carrying out the detailed plans.
Within the Strategy activity layer are agents for analyzing information about the system and the architecture, then planning adaptations based on that analysis. These agents may simply be tasks that a human user performs, or may be automated programs that carry out such tasks.
Within the Tactics activity layer are agents for making specific architectural modifications based upon the plans received from the strategy layer and deployment agents for seeing that those modifications are conveyed to all deployed instances of the architecture to be modified. Also found here are agents for determining how to correlate raw monitoring information received from deployed instances of the system such that the collected data is suitable for analysis at the strategy level.
Within the Operations activity layer are the specific mechanisms for modifying the architecture models (such as may reside on deployed instances) and modifying the implementation, maintaining consistency between them, and mechanisms for gathering data from an executing instance.
Keep in mind that one purpose of a framework such as this is to provide the engineer with a checklist of issues. Not all parts of the framework will be equally useful in all adaptation contexts. Similarly, the location of the various entities involved (both the agents performing the changes and the entities being analyzed or being changed) may vary. The architectural model is a good example: Any agent that needs to analyze or modify the architecture must have access to it. If the application is embedded in an isolated, autonomous system, then all the agents required, and the model, must be present on that system. If, on the other hand, the system can be stopped, reloaded, and restarted, all the adaptation agents and models may be found (only) on the development engineer's workstation. The deployment activity might only involve the object code.
In this section, we first present a selection of techniques that can be used to support the activities of the conceptual framework presented above, such as observing the application state and modifying the architecture. Since not all architectures or architectural styles are equally adept at supporting adaptation, we then present an overview of styles—some more architectural than others—that facilitate change. The section concludes with discussion of the special problems of autonomous change.
Adaptation is triggered when someone—user, developer, auditor—determines that the current behavior of a system is not what is desired. That determination is based upon observation, the cornerstone activity.
Determining the techniques that are most useful for observing and collecting state information presupposes knowing what "state" is. In its most obvious form, state consists of the run time values of a program's objects. Since values are continually changing, state is relative to time, and since only a small subset of a program's state is likely to be of use in adaptation, the observed state is usefully a time-stamped sequence of a subset of the run time values of the program's objects.
Other information beyond the values of a program's variables may also be important parts of state used for adaptation purposes. For instance, properties of the program's environment that are not represented in the program may be essential in determining how an application should be adapted. It may be, for example, that the behavior of a system should be a function of some currently unrepresented attribute of the external environment. An automated teller machine, for instance, should perhaps enter a safe mode and wirelessly signal an alarm whenever the ATM is subjected to G-forces in any direction (such as might be caused by an earthquake—or by someone attempting to abscond with the machine). Gathering this enhanced notion of a program's state would entail monitoring more than just the program.
A more prosaic example of external information that may be critical in determining an adaptation strategy is deployment information. The behavior of a system may be impacted by the presence of certain platform-specific options—the presence of certain device drivers, the amount of memory available, or the version of the operating system, for instance. Such information is usually easy to gather (for instance, from "registries" such as MS Windows registry database or Mac OS X's library files) and may be essential in the analysis phase.
System specifications and the system's architectural model may also be aspects of state that need to be observed on the target system and brought to the analysis context. One might expect this information to be static and already known to the adaptation analyst/planner, but in some contexts that may not be true. For example, if an application is highly configurable, each running instance of the application may be unique—perhaps because of customization to reflect installed hardware options. This information is thus akin to the deployment information mentioned above: In that case, the site-specific information concerns properties external to the application to be adapted; in this case, the information is about the application itself. The observed architecture, therefore, is the architecture of the application as it exists in its fielded state. Its set of components, connectors, and their current configuration may be unique. In some more esoteric situations, such as autonomous adaptation, the fielded system may also contain explicit and dynamically changing goal specifications for the application. These would also constitute part of the state subject to observation and reporting to the adaptation analyst.
Gathering the State Numerous techniques exist for gathering the state of a program's objects; the numerous techniques developed to support program debugging all apply. Most primitively, the analyst may manually observe the program's user interface. More usefully, observation code may be part of a special run time system that enables monitoring of a program without requiring any modification to it. In some contexts, such as specialized embedded systems, "bolt-on" hardware analyzers may allow inspection of program state without any disturbance to the run time software environment.
If modification of the subject software system is feasible, a variety of more specialized and targeted approaches are possible. Again, at the most primitive level, the beginning programmer's technique of seeding a program with print statements may be sufficient. As program and problem complexity increase, more powerful and thoughtful approaches are required. Customized monitors may be inserted in the application code and function similarly to assertions. Such assertions can check for specified condition and, if satisfied, record some value or otherwise emit an observation of the program's state. Whether a given programming language's assert statement is appropriate for this use depends on the language semantics: If satisfaction of the assert's condition necessarily interrupts the program's flow of control following the assertion, then use of that language feature would not be appropriate. Monitoring should allow execution to proceed unimpeded.
To the extent that creation of custom monitors is a manual process, it is an expensive process. Moreover, the use of custom monitors such as described above is only feasible when the source code is available and the application can be recompiled. One alternative is to focus on capturing information only at component boundaries, and to do so by capturing information that passes through an application's connectors. This technique can be based upon commercial middleware when used for connectors, or may take other forms. If the information gathering is automatic and does not filter "uninteresting" data, then it must be coupled with other tools to support filtering after the raw data has been gathered.
The concept is illustrated by the MTAT system (Hendrickson, Dashofy, and Taylor 2005), which creates a log of all messages sent between components in an architecture during its execution. This log is created by automatically implanting trace connectors in an architecture (see Figure 14-7). Trace connectors intercept all messages passing through them, make a copy of each message, and send each copy to a distinguished component that logs the messages in a relational database. The original messages are passed on unmodified. The trace connectors are first-class connectors. Figure 14-8 shows an architecture before modification as well as the architecture after inserting trace connectors.
The MTAT analysis system includes a tool that examines an xADL description of a system's structure and inserts trace connectors into that description automatically. The system's structure is modified so that each link in the original architecture is split into two links, with a trace connector between. Because the infrastructure provided by xADL and its supporting ArchStudio tool set instantiates architectures directly from their descriptions, no recoding of components is needed for instrumentation. Consequently, components in the application remain unaware of any architectural changes or the presence of the trace connectors once the architecture is modified. The approach works in both single-process and distributed systems. In distributed systems, connectors that bridge process boundaries are broken into two halves—one in each process they connect. In terms of instrumentation, distributed connectors are treated the same way single-process connectors are; a trace connector is placed on every link in every process.


Finally, depending on the adaptation context, the technique used for gathering the observations may also need to be responsible for transmitting them from the platform where the target application is running to the host where the adaptation analysis will take place. To the extent that the target is an embedded system this off-board transmission is likely to be a necessity.
Analyzing the Data Analyzing the data gathered from observing a system and consequently determining the adaptations to perform is a wide-open problem. The range of types of changes that may be required precludes the prescription of a small set of standard techniques. Indeed, the problem is essentially the same as program understanding and program debugging. For some situations, a simple, canonical technique may suffice; for most situations, ample human thought will be required.
To the extent that kinds of change may be anticipated while a system is being designed, techniques may be put into place to monitor for specific situations, triggering preplanned strategies for coping with the change when the monitors detect the key values. The data analysis is simply comparing a value to a reference. Consider the example of an electronic commerce application. As the number of customer transactions increases the back-end servers must perform more work. As a maximum threshold is approached, additional servers must be brought online to avoid degradation of the user experience. Since much of the transaction processing in such e-commerce applications can be performed by independent servers, a simple load-sharing design can be used wherein additional servers are brought online automatically, becoming part of the "server farm" as the result of monitoring a threshold value and triggering the preplanned response.
An easy step up from this situation is using a set of rules to monitor a set of observed values. The guarding condition in the rules may be complex; so, too, may be the corresponding actions. In essence, though, the approach is the same: The system's design has explicit provision for accommodating anticipated change, including the specific approach for monitoring and analysis. One use of this technique might be in comparing observed behavior of a system with behavior predicted by an analysis of the architecture before its implementation. For example, a simulation may show that a system correctly aborts a transaction if any one of its subtransactions fails; but monitoring of the implementation may show that the transaction was (inappropriately) completed in such a case, requiring correction.
Beyond these simple approaches there are few general techniques focused on analyzing observational data to guide adaptation. One example is illustrative, however. The MTAT system is targeted at helping engineers understand the behavior of applications having an event-based architecture. (The Rapide system of Chapter 6 is similar.) The trace connectors shown in Figure 14-7 feed copies of all messages sent in the architecture to a relational database. This database can then be examined in various ways to determine, for instance, communication patterns in the application or causality chains. Causality chains are particularly useful: When an engineer understands that message a from component A causes message b to be sent from component B and so on, changes can be made that reflect a deep understanding of the interrelationships between elements of a system's architecture. Note that, in essence, this approach is similar to techniques employed in debugging source code; the difference is in bringing the analytic approach to bear at the level of architectural concepts, and focusing on the particular kind of communication used at the architectural level.
Analyzing the Architecture and Proposing a Change. Assuming that observations of a system have been obtained and analyzed, it remains to develop a modification to the architecture to meet the needs with which the architect is concerned. Again, the challenge may be very simple or very complex.
If the architecture was originally designed to accommodate certain types of change, and analysis of the data shows that the needed change is within the expected scope, then proposing a responsive change is straightforward. For instance, if a component is shown to be a performance bottleneck, and a faster replacement component having the same interfaces can be produced (that is, the change is confined to the component's internal "secrets"), then simply swapping the original component for the improved one is all that is required. If a system's architecture is in the client-server style and a new client is needed, modification is simple. If a system's architecture is in the publish-subscribe style and a new publisher is available, then again the path to change is straightforward. The pattern here is clear: If the needed change fits within the type of change anticipated and accommodated by the application's architectural style, then the approach to take is clear.
If analysis shows that the needed change does not fall within an anticipated pattern, then the architect has to revert to the general analysis and design techniques discussed earlier in Chapters 4 and 8.
Analyzing the Proposed Change. After a proposed change to an architecture has been developed it should be checked to determine if it is complete and appropriate for deployment to its target platforms. Checking a proposed change seems so obvious that it should go without saying, but consider some of the possible items that may need to be checked:
Are there any unattached ("broken") links in the new architecture?
Have all interface links been type-checked for consistency?
Are all components properly licensed for use in the target environments? (For example, if the target environment is a commercial product, do any of the new components have GPL licenses attached?)
Are communications between the components performed consistently with the application's security requirements? (For example, if two components communicate over an open network, are the messages encrypted?)
Is every component and connector in the revised architecture mapped to an implementation?
Is everything in the deployment package that the change agent on the target platform requires? (For example, license keys and configuration parameters.)
The number of issues that may need to be checked is large, and hence an explicit process step to verify them is usually warranted.
One situation that calls for special attention is when each target system to which the revised architecture is to be deployed may be unique. That is, due to the possibility of local modifications, each target needs, in essence, to be individually checked. If the number of targets is at all significant, the analysis will have to be automated.
Describing Changes to an Architecture To effect a repair on a running software system, the changes to the system that will occur because of the repair must be specified and machine-readable. There are three primary ways that concrete architectural changes can be expressed, as follows.
Change scripts: Change scripts are executable programs that operate on a system to make changes. In general, these scripts leverage underlying adaptation APIs provided by the implemented system (or its architecture implementation framework or its middleware). Adaptation APIs provide high-level functions, for instance, for instantiating and removing components and connectors, creating and destroying links, exposing or withdrawing provided services, and so on. Sometimes, change scripts will be accompanied by implementation artifacts (for example, new source or binary files) that are merged with the implemented system.
Architectural differences: Rather than executable programs or scripts, architectural changes can be expressed as a set of differences between one architecture and another. In general, these differences, also known as "diffs," contain a list of additions, removals, and (optionally) modifications to architectural elements. For example, a diff might indicate the addition of two components, new interfaces on those components, and new architectural links to hook those components into the architecture, as well as the removal of links that are no longer needed. Given two concrete architectural models of the system—as it is and the system as it should be—tools can create a diff automatically.
New architectural models: In some cases, especially cases where the current state of the system to be adapted is unknown, a complete architectural model is used to describe the target adaptation architecture. In this case, an architectural difference is generally created by examining the elements in the current system as well as those in the new model and determining what to add and what to remove to bring the current system in line with the new architecture. Whether or not this architectural difference is expressed as a new artifact or is simply a side effect of determining the changes depends on the approach.
Applying Changes to an Architecture In any of these three cases, two worlds are involved—the world of architecture and the world of implementation. In general, for any of these change artifacts to be effective in adapting a real, implemented system there must be a tight correspondence between elements in the architectural model and elements in the implementation. The use of architecture implementation frameworks or flexible middleware (see Chapter 9) can be used to facilitate this.
In the absence of tight bindings between architecture and implementation, it is conceivable to employ a human as the change agent on the target system. That is, the change artifact is reviewed by a person, and that person is responsible for making the corresponding changes to the system. Certain software systems [for example, enterprise resource planning (ERP) systems] are so complex to deploy, install, and configure that customers simply cannot do it themselves. In general, an organization that purchases such software also hires a team of consultants or product experts to deploy, install, and configure the software for their own organization. In this case, architectural changes might be deployed from the vendor to the consulting team, which could then make the configuration changes to the system manually.
Once changes to a system's architecture are described concretely in one of the above forms, they must be actually applied to that system. In the case of change scripts, the change script is executed in some run time environment co-located with the target application. Software underlying the target application, usually the architecture implementation framework or middleware, is called upon to actually make the changes to the system. In the case of architectural diffs, a change agent running alongside the target application must interpret the diff and make the changes specified therein, a process known as merging. In the case of new architecture specifications, a change agent must determine the difference between the current and intended application configuration and make changes as needed.
Issues with Deployment. No matter what form of change artifact is used—change scripts, architectural diffs, or new architectural specifications—that artifact needs to be deployed to the target system (or its associated change agent). The issues involved with deploying these change artifacts are similar to those found in software deployment in general, and so most of the advice in Chapter 10 on deployment applies here as well. If the target system is running on a single remote host, deployment is generally straightforward: The change artifact can be sent over any number of network protocols such as HTTP or FTP to the change agent, which then executes the changes. Distributed and decentralized systems can use push-based or pull-based approaches to distribute change artifacts.
In any of these approaches, a change agent must be located on the target machine to actually effect the changes on the architecture—to execute the change script, to parse the architectural diff, and so on. This agent can be deployed with the original system, or it can be sent along with the change artifact. For example, a change script could be compiled into executable form (as an "installer" or "patcher") and then sent over the network to the target system, where it is executed by the operating system directly. This is convenient as it avoids the problem of having to update change agents themselves. This strategy carries some security risk—running arbitrary executables on target platforms is an easy way to spread malicious software if the code is not trusted. Code signing and other strategies can be used to mitigate this risk.
Issues with Applying Changes. Making on-the-fly architectural changes (see Section 14.3.3 below) is more difficult. All issues identified below with respect to ensuring that the application is in an appropriate quiescent state to be adapted apply with these strategies.
Making on-the-fly changes to a distributed system is even more difficult, since the change must first be deployed to all appropriate parts of a distributed system, and then the system as a whole must be put into a quiescent state for update. This involves additional risk, since network and host failures during the update process can make it difficult to get the system into a consistent state.
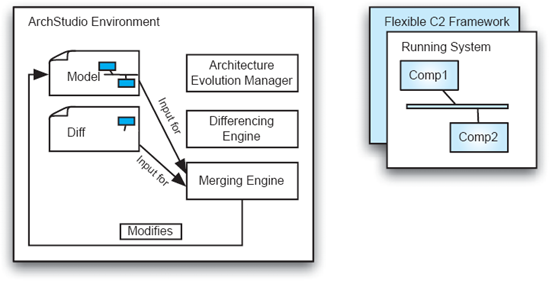
The ArchStudio environment supports architecture-based adaptation with a combination of techniques listed above. Specifically, it uses an architecture-implementation framework to ensure a mapping between architecture and implementation. Then, architectural diffs are used as change descriptions to evolve a system at run time. The process for evolving a system occurs in four steps.
Step 1 of the process is shown in Figure 14-9. An architecture description in xADL is provided to a tool in ArchStudio, the Architecture Evolution Manager (AEM). The AEM reads through the model and uses the Flexible C2 Framework, described in Chapter 9, to instantiate the system. Implementation bindings in the xADL model facilitate the mapping from architectural components and connectors to Java components.
Step 2 of the process is shown in Figure 10. A new architectural model is created in the environment, possibly by making a copy of and modifying the old model. Then, the old model and the new model are both provided as input to another ArchStudio tool, the Differencing Engine, "ArchDiff." ArchDiff creates a third document, an architectural diff, that describes the differences between the two.
Step 3 in the process is shown in Figure 11. Here, the new model is no longer needed. The original model, still describing the running system, and the diff are both provided as input to another ArchStudio tool, the Merging Engine, "ArchMerge." The merging engine, acting as a change agent, modifies the original model with the changes in the diff.
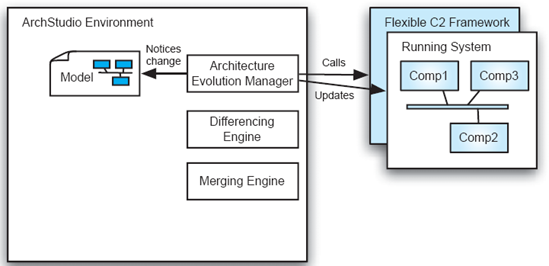
Step 4 in the process is shown in Figure 12. Here, the AEM notices that changes were made to the original model (by way of events emitted from the model repository within ArchStudio). AEM then makes the corresponding changes to the running architecture by making more calls to the underlying Flexible C2 Framework, instantiating new elements and changing the application as necessary. Although only additions are shown in these simple diagrams, ArchStudio supports additions, modifications, and removals of elements.


The preceding sections focused on generic techniques that support parts of the conceptual framework for architecture-based adaptation presented in Figure 14-6. The difficulty of making changes—even using these techniques—will vary enormously from one application to another, depending on the type of change required and the nature of the architecture to be changed. The discussion of shearing layers early in this chapter indicated, in generic terms, why some changes are more difficult to effect than others. The discussion of the many architectural styles in Chapter 4 showed in particular how some styles are more adept at handling particular types of change than others. Client-server architectures, for example, are designed to easily accommodate the addition or deletion of clients.
In the subsections below we revisit the topic of styles, introducing some specific interface-focused architectural approaches to facilitating change, and then briefly reconsider some concepts from Chapter 4 that are particularly effective in supporting change.
Since developers have been charged with changing software since the advent of computing, it is no surprise that a variety of techniques have emerged to help this process. The techniques presented here all reflect application of the dictum "design for change." We have categorized these techniques as interface-focused since they rest upon application-programming interfaces or interpreter interfaces presented by the original application.
These techniques do not purport to support all types of change. Indeed, the primary focus of these techniques is only in adding functionality in the form of a new module.
Application Programming Interfaces (APIs). APIs are perhaps the most common technique for enabling developers to adapt an application by extending it. With this technique, the application exposes an interface—a set of functions, types, and variables—to developers. The developers may create and bind in new modules that use these interface elements in any way the developers choose. (The interrelationships between the new modules themselves are unconstrained by the API.) The type of change to the original application that can be supported is limited to whatever functionality the API presents. Many operating systems and commercial packages use APIs.

This approach is illustrated in Figure 14-13, which presents a notional picture of an application to which one new component has been added. The added component can make use of any of the features of the original application that are exposed by the API, but it cannot access the interfaces of any of the components internal to the application, nor can it modify any of the connections internal to the application. The added component makes calls to the original application; nothing in the original application can make calls to the added component.
Plug-Ins. Plug-ins are sort of a mirror-image of APIs: Instead of the added component calling the original application, the application calls out to the added component. To achieve this, the original application predefines an interface that third-party add-ons or plug-ins must implement. The application uses and invokes the plug-in's interface, thereby altering its own behavior. To initiate the process, the original application must be made aware of the existence of the plug-ins; they must become registered with the application. Typically, the registration happens on application start-up, when the application inspects predefined file directories. Components found in those directories that meet the interface specification are registered and may then be called. The technique is illustrated in Figure 14-14.
Adobe Acrobat and Adobe Photoshop are applications that historically have made significant use of the plug-in mechanism. Direct interactions between multiple plug-ins are possible, but such interaction is not part of the plug-in architecture as such.
"Component/object Architectures". With this technique, the host application exposes its internal entities and their interfaces to third-party developers so that they can be used during the adaptation process. This is in contrast, for example, with the API and plug-in approaches that view the original application as a monolithic entity whose internal structure is opaque and immutable. Here, add-ons alter the behavior of the host application by adding new components that interact with existing components. Exposing the internal entities also allows a component to be replaced by one that exposes a compatible interface. This approach is illustrated in Figure 14-15.

This approach to adaptation is more powerful than either APIs or plug-ins, since more interfaces are exposed, and the approach seems architecture-centric because the key items in the vocabulary are a system's components. Typically missing in common application of this technique, however, is an explicit architectural model. The developer is (just) confronted with the system's source code; nothing at a higher level of granularity can be manipulated to achieve the desired changes.
CORBA-based systems, discussed in Chapter 4, are members of this category, as are systems built with Microsoft's Component Object Model (COM). Such systems can be very fluid, but management of them can be difficult because there is no explicit model capable of serving as the fundamental abstraction.


Scripting Languages. With this approach, the application provides its own programming language (the "scripting language") and run time environment that the architect uses to implement add-ons. In essence, this is a use of the interpreter style from Chapter 4. Add-ons, when executed by the interpreter, alter the behavior of the application. Scripting languages commonly provide domain-specific language constructs and built-in functions that facilitate the implementation of add-ons, especially for users who lack programming expertise. Spreadsheet formula languages, macro systems, and programming-by-demonstration systems are essentially scripting languages optimized for specialized needs. Microsoft Excel is a prime example of an application that provides this means of extension. The technique is illustrated in Figure 14-16.
Event Interfaces With this technique—a simple application of the event-based architectural style of Chapter 4—the original application exposes two distinct interfaces to third-party developers. The first is an incoming event interface, specifies the messages it can receive and act on; the second, an outgoing event interface, which specifies the messages it generates. Messages are exchanged via an event mechanism. Add-ons alter the behavior of the application by sending messages to it or by acting on the messages they receive from it. As discussed in Chapter 5, event mechanisms commonly provide a message broadcast facility, which sends a message to every add-on attached to the event mechanism. The event mechanism acts as an intermediary, encapsulating and localizing program binding and communication decisions. As a result, these decisions can be altered independently of the original application or add-on components. This is in sharp contrast to the other techniques, in which programs directly reference, bind to, and use each other's interfaces. The technique is illustrated in Figure 14-17.
Should changes to a system be required that involve more than just adding a new module, a richer approach to adaptation is needed than what the interface-focused solutions above offer. The core of any architecture-based solution, as we have discussed, is an explicit architectural model, faithful to the implementation, which can serve as the basis for reasoning about changes.

Simply having an explicit architecture is no panacea, of course. Complex dependencies between architectural elements and inflexible connectors may render difficult any adaptation problem. Consistent use of any of the architectural styles of Chapter 4 can remove some of the inherent difficulties. Ill-conceived custom styles that combine simpler styles in complex ways can vitiate those benefits, however.
The fundamental issue is bindings. To the extent that an architectural style enables easy attachment and detachment of components from one another, that style facilitates adaptation. The consistent emphasis of this text on the use of connectors stems from the benefits that explicit connectors can provide in supporting such attachments and detachments. The wide range of connector techniques discussed in Chapter 5 reveals that not all connectors are equally supportive of adaptation, however. Since a direct procedure call is one kind of connector it is obviously possible for the internals of one component to be strongly tied (via a procedure-call connector) to the details of an interface provided by another component. In the extreme (and hence rather useless) case of treating shared memory as a connector, arbitrary interdependencies between components may be achieved. These negative examples do serve to indicate what makes a good connector and what makes a style supportive of adaptation: independence between components. At a minimum, this means lack of dependency on interfaces. (As we shall see later, however, this is not a sufficient condition.) Use of particular types of connectors can achieve this independence, wherein one of the roles of the connector is to facilitate communication between two components while insulating them from dependence.
Perhaps the best example of this kind of connector and the independence provided is the event-based connector discussed in Chapter 4 in conjunction with the implicit invocation architectural styles. Components send events to connectors that route them to other components. The events are capsules of information; the sending component may not know which components receive the sent event; a receiving component may not fully understand all the information in the event, but still can process it such that its own objectives are satisfied. A network protocol (such as HTTP/1.1) can be used, for example, to support this type of communication. The protocol supports moving MIME-encapsulated data throughout a distributed application; how a receiving component interprets and processes the encapsulated payload is a decision local to that component. Ensuring that the collection of components and connectors cooperate to achieve the objectives for the application is the responsibility of the system architect. For detailed examples of this type of architecture, see Chapter 4, including the discussion of the C2 style.
Adapting a system while it remains in operation presents special challenges, complicating the adaptation process. Some example situations where that complication cannot be avoided were given at the beginning of the chapter, and include applications whose continuous operation is essential to the success of some larger system, such as control software in a continuously operating chemical refinery.
Autonomous adaptation means that human involvement in the adaptation process is absent, or at least greatly minimized. Autonomous adaptation can be a complicating addition to on-the-fly adaptation, such as when the continuously operating system is isolated from external control, as in robotic planetary exploration. Such extreme circumstances are not the only ones where autonomous adaptation may be required, however. It may be, for instance, that rapid response requirements to partial system failure dictates the use of autonomous adaptation techniques.
Some of the challenges of on-the-fly adaptation can be seen through analogies. Living in a house that is undergoing a major renovation is sometimes necessary, and is seldom pleasant. The unpleasantness comes from attempting to carry on daily life while portions of the service architecture that we depend upon—plumbing, electricity, heat, security, and so on—are only partially or intermittently available. Life goes on, but not in the regular rhythms or with the usual comforts.
A more vivid, and instructive, example is surgery. The patient corresponds to the system being "adapted." Clearly it is essential that while the adaptation is taking place—repair to a heart valve, for example—the patient must be kept alive. The various subsystems of the human (must) continue to function even though major disruptions take place. The various techniques and technologies of heart surgery, from anesthesia to cardiopulmonary bypass, are designed to maintain basic system performance while enabling major restructuring of a key component.
The key additional issues in on-the-fly adaptation are as follows:
Service strategy: While the adaptation is taking place, will the system continue with a temporary service to fully replace the one being changed? Will it continue with a reduced level of service? A missing service? Can some service errors be tolerated? System functioning during adaptation may be maintained through the use of auxiliary components (such as the heart-lung machine in the surgery analogy), or may be degraded to a lower level of functionality (such as using a bathroom sink to wash dishes while the kitchen is remodeled in the home remodeling analogy).
Timing: Identifying the occasions when the subject parts of the system can be altered. Depending on the service strategy adopted, the condition under which the adaptation may proceed can be identified. Replacement of a component may only be allowed, for example, when it has finished servicing all outstanding requests to it, and has not initiated any requests on other components in the application.
Restoration or transfer of state: If a component is replaced, does the replacement component need to know some or all of the state information that was held by its predecessor? The first calculations made by the new component may necessarily be functions of previous values computed and stored, in which case that state would have to be restored at the time the new component is started up.
An example may help make these concepts more clear. (Throughout this section we assume, consistent with the preceding parts of this chapter, that the smallest unit of change is a component and that component identity and boundaries are maintained in the implementation.)
Consider the case of a processor that controls the opening and closing of a valve in a chemical refinery based upon command inputs, temperature sensors, and flow meters. Such a processor may be designed in the sense-compute-control pattern discussed in Chapter 4. It may become necessary to replace one of the control components onboard, due to identification of an error in one of its algorithms. One plausible adaptation strategy is, at an arbitrary time, to cease processing of any incoming signals on its sensors, leave the valve's opening at whatever position it is in, swap out the offending component, swap in the new component, and then start the replaced component by first sampling all the input sensors, and then issuing new commands to the valve. Whether this strategy will work depends on, for example, whether any inputs missed during the swap were critical to the refinery's safety, or whether leaving the valve open in its last position could endanger the refinery before the new component was in place. For instance, if the valve was left in the "full on position" while the upgrade was taking place, and if the upgrade took very long to transpire, some downstream reaction in the refinery may be put at risk. A better strategy would likely entail buffering all inputs to the valve controller so that when the new component comes online it would ensure that every incoming value was processed, and instead of leaving the valve at its last setting, putting it into some safe position.
The appropriate service strategy for this example would likely be determined in consultation with the plant's chemical engineers. The amount of time the control processor could safely be preoccupied with the adaptation might well be determined by properties of the chemical processes in the refinery. If the valve is highly critical, a temporary controller may need to be put into place. Timing of the adaptation could be determined by properties of the plant, or perhaps by the state of the value itself (perhaps the adaptation would occur only when the valve is closed).
The determination of the precise condition under which it is appropriate to replace a component can be a function of the system as well as of the architecture. The system, as illustrated in the refinery example, may dictate that change happen only under certain external condition. Alternatively, system domain analysis may reveal that change can happen at any time—even if it means that some outputs produced are erroneous—simply because the system is so robust that it can tolerate some significant degree of error on the part of the software. For example, a satellite that gathers weather data, processes it, and sends the resulting information to the ground may be in this category. Weather data is continuous and is a phenomenon that changes slowly (relative to computer processing, at least), so simply losing some amount of the telemetry data is unlikely to matter.
Some applications will demand a much more conservative analysis, however. The principle is that it is safe to remove/replace a component only when such change will not adversely affect the functioning of the rest of the application. While precisely identifying all such condition may be quite difficult, it is easier to specify sufficient condition. Some sufficiency condition are captured in the notion of quiescence. The intuition is that it is safe to replace a component when that component is inactive. A simple understanding of quiescence is that the component is not engaged in sending or receiving information, and internally is idle (all of its threads are idle). Inactivity, however, needs to be understood more comprehensively, in terms of any transactions to which the component may be a party. That is, a component C may initiate a set of actions that are performed by other components, itself staying inactive until the other components complete their task and return control to C. In this case, C is not quiescent until all actions that are part of a (conceptual) transaction are complete. Various shades of quiescence are defined in the sidebar, drawing from the work of Professors Jeff Kramer and Jeff Magee, who pioneered this area.
If an application is implemented with powerful, explicit connectors, such as message buses, then determining whether a component is engaged in communication is easy—the connectors may be used to make this determination. Knowing whether a component is engaged in a multiparty transaction, however, requires deeper analysis and will have to consider the behavioral characteristics of the architecture as a whole. The stronger the notion of quiescence required, the more complex will be the determination of when it is achieved.
A component's state is the set of values that it maintains internally. When a component A is replaced with a component B, the question arises as to what B 's state should be initialized to upon its startup. The easiest situation is one where no transfer or re-creation of corresponding state is needed. For example, many Unix filters do not maintain state; the output they produce is solely a function of the most recently read input, unaffected by any preceding computation. Other applications may not be so designed. For instance, the user may have set a number of preferences; should the application be modified while the user is working with it, the preferences should be transferred. One effective strategy for dealing with transference of state is simply to externalize it: copy whatever state needs to be moved to a third party; when the replacement component comes online its first action is to initialize itself by drawing from the third party. This strategy, of course, presumes that the components were designed for replacement—a condition not often true.
While the principles and issues discussed above apply to architectures generally, there are some practices and approaches that definitely ease the practical problems of supporting on-the-fly adaptation. Foremost are use of explicit, discrete, first-class connectors in the implementation and use of stateless components. To see the success of this simple advice, consider the architecture of the Web. As described elsewhere in this text, the Web is based upon these principles—and manifestly the Web is an application that continuously is undergoing change. Proxies and caches can be added and deleted; new Web server technologies put into place, new browsers installed. It all works because the interactions between the various components are discrete messages and the core protocol (HTTP/1.1) requires interactions to be context-free ("stateless" in the Web jargon)—a server does not need to maintain a history of interactions with a client in order to know how to respond to a new request.
Autonomous change is adaptation undertaken without outside control. The distinctive character of autonomous change is not the challenge of working without connection to, say, the Internet, but rather effecting the change process without involving humans. The desire to avoid involving humans is readily motivated: A self-adaptive system can change much more quickly than one involving people; consequently, self-adaptive change is likely to be much cheaper. Other situations may similarly motivate autonomous change. For instance, if a large number of very similar systems must be changed, but each with minor variances, an autonomous approach may work not only faster, but more accurately, as such repetitive tasks are often poorly performed by people—the tasks are simply too boring to keep one's attention.
The difficulties entailed in achieving autonomous change are equally clear: All the activities discussed above must be completely realized as executable processes, from data observation, to analysis, to planning, to deployment, to run time system modification. Moreover, all these executable processes, and all the information involved in their execution, must reside on the autonomous system. Preeminent in this information is the architectural model of the system. Note that with this onboard, and kept faithful to the implementation, the system is continuously self-describing.
In practical terms, self-adaptive systems today are limited to rather simplistic situations for which a set of rule-based adaptation policies can be formulated. As previously discussed, this is appropriate for systems where the types of adaptation needs can be anticipated and encoded in simple terms. Expanding the range of systems and types of change for which autonomous solutions can be developed is an area of active research.
There is little question that applications will be adapted and changed over their lifetime. The real question is how expensive and how difficult will it be to effect those changes. While "designing for change" and the use of encapsulation is an important principle for assisting with change, much more powerful and capable mechanisms are required for meeting contemporary adaptation needs. This chapter has presented such mechanisms:
A conceptual framework for governing the entire adaptation process.
Architectural styles that assist with accommodating large-scale system change.
Specific techniques for assisting with the major tasks of adaptation: monitoring, analyzing, planning, and effecting.
If a system's descriptive architecture and its prescriptive architecture are consistent, then adaptation can be orchestrated around changes to the architectural model. This approach, besides providing the intellectual tools for managing ordinary adaptation, opens the door to novel types of application evolution, such as wherein the architectural model is deployed with the application and adaptation processes on the target machine utilize the model in determining and carrying out changes.
This chapter concludes a three-chapter sequence on designing systems for non-functional properties. Chapter 12 introduced the main concepts and covered a variety of NFPs. Chapter 13 delved into the NFPs of security and trust; this chapter has examined the NFP of adaptability. The next chapter returns to a subject introduced in the very first chapter of the text: program families. With all the various elements of architecture-based development laid out in the intervening chapters, we next explore in depth how cost-effective development of a related set of applications can be achieved.
What are the fundamental causes or motivations for software adaptation?
What are the major activities of software adaptation?
For each of the major activities of adaptation, describe a technique that assists in performing that activity.
How can architectures be designed to make the task of third-party extension easier?
How do plug-in architectures work?
Why may quiescence be needed for run time replacement of a component?
Consider the problem of modifying several of the lunar lander designs of Chapter 4 to serve as a Martian lander. Would the changes required be confined to components, or would connectors be involved?
Consider the problem of adapting the lunar lander designs of Chapter 4 to work by remote control. That is, instead of the Lander having a pilot on board, the craft is unmanned and a pilot on Earth must control the descent. What type of changes would be required to the components? To the connectors?
Consider the challenges faced in adapting a planetary exploration vehicle, such as the Cassini mission to Saturn. What would be a suitable architectural style for supporting in-flight system adaptation? Would you have a kernel that is nonupdatable? Why or why not?
What degree of quiescence would be required in your answer to question 3 when performing an update? To what extent does your answer depend on the type of update (that is, the degree of change involved)?
What are the differences (if any) between software architectures that support dynamic adaptation and fault-tolerant architectures? What circumstances are the approaches suited for?
Suppose you had optimized a connector in the implementation of a system for performance reasons and then need at some later date to modify the architecture. How would you approach adaptation of this system if the adaptation is performed offline? What if the adaptation must be performed dynamically?
Analyze the robotic architectures of Chapter 11 with respect to their ability to effectively accommodate changes such as requiring the robot to (a) perform a minor variation to an existing task, and (b) utilize a new tool, such as a new robotic arm, to perform an entirely new task.
Is preplanned change really an instance of dynamic architecture? Why or why not? What should the litmus test be?
(Research question) What is the role of dynamic adaptation (or just "adaptation") in the context of software product families? When should adaptation of a member of a family be considered creation of a new product?
(Research question) Does design of an application to support ease of adaptation conflict with the ability to ensure that any given instance of the application performs its intended task? In general, does ease of adaptation conflict with analyzability?
Since change has accompanied software development from the outset of the field there is no shortage of literature discussing how to adapt software. Indeed, the entire "Millennium Bug"/Y2K problem was one massive effort in software adaptation. In that case, of course, the change being effected was extremely narrowly focused. Sadly, for some Y2K systems, architecture changes were required since the two-digit fault was so implicitly part of those systems' design.
Stewart Brand's book on change in physical architectures (Brand 1994) is well worth an extensive read, for it has numerous insights on adaptation that have correspondences in software adaptation. If nothing else, you will discover why you love some buildings and hate others.
Some of the earliest work in architectural approaches to adaptation was performed at Imperial College by Jeff Kramer and Jeff Magee as part of the Regis (Magee, Dulay, and Kramer 1994; Ng, Kramer, and Magee 1996) and Conic projects (Kramer and Magee 1990). Successive work with Darwin continues this theme (Magee and Kramer 1996).
Peyman Oreizy and colleagues are responsible for many of the key insights presented in this chapter, including the original conceptual model for the management of self-adaptive systems (Oreizy, Medvidović, and Taylor 1998; Oreizy et al. 1999) and the characterization of the architectural styles promoting adaptability presented in Section 14.3.2. The first of these two papers received an award in 2008, when it was recognized as the most influential paper from the 1998 International Conference on Software Engineering. As part of the award, the authors were invited to present a new paper on the topic, retrospectively analyzing the past decade's work in software adaptation and prospectively offering challenges for work still to be done (Oriezy, Medvidović, and Taylor 2008). Additional recent work includes approaches based on knowledge-based systems (Georgas and Taylor 2004; Georgas, van der Hoek, and Taylor 2005). Gomaa has explored the use of patterns to facilitate reconfiguration in (Gomaa and Hussein 2004), and addresses the issue of quiescence.
Many more references are available from the proceedings of the leading workshops in the field, which include the Workshop on Software Engineering for Adaptive and Self-Managing Systems and the Workshop on Architecting Dependable Systems.
[18] Strictly speaking, any browser that supports JavaScript is dynamically adaptable. Whenever JavaScript is downloaded from a Web site and executed in the browser the user is taking advantage of dynamic extensibility. Most contemporary browsers are so good at this that the experience is completely transparent to the user.
[19] Layers, as used by Brand and shown in Figure 14-1 do not correspond exactly to layers as used in software. In particular, the relative juxtaposition of layers in a software system, such as found in the layered style of Chapter 4, differs from the ordering of the shearing layers. As shown in this diagram, for instance, the relatively immutable structure layer is adjacent to the relatively mutable skin.