
In the last chapter, we briefly mentioned one-hot encoding, which transforms categorical features to numerical features in order to be used in the tree-based algorithms in scikit-learn. It will not limit our choice to tree-based algorithms if we can adopt this technique to other algorithms that only take in numerical features.
The simplest solution we can think of to transform a categorical feature with k possible values is to map it to a numerical feature with values from 1 to k. For example, [Tech, Fashion, Fashion, Sports, Tech, Tech, Sports] becomes [1, 2, 2, 3, 1, 1, 3]. However, this will impose an ordinal characteristic, such as Sports is greater than Tech, and a distance property, such as Sports, is closer to Fashion than to Tech.
Instead, one-hot encoding converts the categorical feature to k binary features. Each binary feature indicates presence or not of a corresponding possible value. So the preceding example becomes as follows:
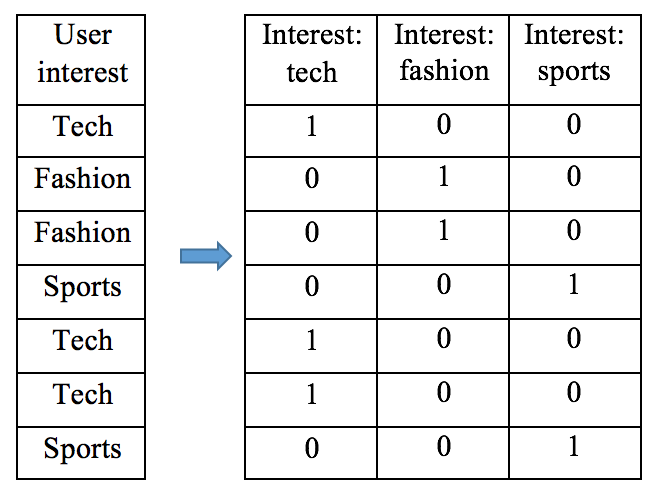
We have seen that DictVectorizer from scikit-learn provides an efficient solution in the last chapter. It transforms dictionary objects (categorical feature: value) into one-hot encoded vectors. For example:
>>> from sklearn.feature_extraction import DictVectorizer
>>> X_dict = [{'interest': 'tech', 'occupation': 'professional'},
... {'interest': 'fashion', 'occupation': 'student'},
... {'interest': 'fashion','occupation':'professional'},
... {'interest': 'sports', 'occupation': 'student'},
... {'interest': 'tech', 'occupation': 'student'},
... {'interest': 'tech', 'occupation': 'retired'},
... {'interest': 'sports','occupation': 'professional'}]
>>> dict_one_hot_encoder = DictVectorizer(sparse=False)
>>> X_encoded = dict_one_hot_encoder.fit_transform(X_dict)
>>> print(X_encoded
[[ 0. 0. 1. 1. 0. 0.]
[ 1. 0. 0. 0. 0. 1.]
[ 1. 0. 0. 1. 0. 0.]
[ 0. 1. 0. 0. 0. 1.]
[ 0. 0. 1. 0. 0. 1.]
[ 0. 0. 1. 0. 1. 0.]
[ 0. 1. 0. 1. 0. 0.]]
We can also see the mapping by using the following:
>>> print(dict_one_hot_encoder.vocabulary_)
{'interest=fashion': 0, 'interest=sports': 1,
'occupation=professional': 3, 'interest=tech': 2,
'occupation=retired': 4, 'occupation=student': 5}
When it comes to new data, we can transform it by using the following code:
>>> new_dict = [{'interest': 'sports', 'occupation': 'retired'}]
>>> new_encoded = dict_one_hot_encoder.transform(new_dict)
>>> print(new_encoded)
[[ 0. 1. 0. 0. 1. 0.]]
And we can inversely transform the encoded features back to the original features as follows:
>>> print(dict_one_hot_encoder.inverse_transform(new_encoded))
[{'interest=sports': 1.0, 'occupation=retired': 1.0}]
As for features in the format of string objects, we can use LabelEncoder from scikit-learn to convert a categorical feature to an integer feature with values from 1 to k first, and then convert the integer feature to k binary encoded features. Use the same sample:
>>> import numpy as np
>>> X_str = np.array([['tech', 'professional'],
... ['fashion', 'student'],
... ['fashion', 'professional'],
... ['sports', 'student'],
... ['tech', 'student'],
... ['tech', 'retired'],
... ['sports', 'professional']])
>>> from sklearn.preprocessing import LabelEncoder, OneHotEncoder
>>> label_encoder = LabelEncoder()
>>> X_int =
label_encoder.fit_transform(X_str.ravel()).reshape(*X_str.shape)
>>> print(X_int)
[[5 1]
[0 4]
[0 1]
[3 4]
[5 4]
[5 2]
[3 1]]
>>> one_hot_encoder = OneHotEncoder()
>>> X_encoded = one_hot_encoder.fit_transform(X_int).toarray()
>>> print(X_encoded)
[[ 0. 0. 1. 1. 0. 0.]
[ 1. 0. 0. 0. 0. 1.]
[ 1. 0. 0. 1. 0. 0.]
[ 0. 1. 0. 0. 0. 1.]
[ 0. 0. 1. 0. 0. 1.]
[ 0. 0. 1. 0. 1. 0.]
[ 0. 1. 0. 1. 0. 0.]]
One last thing to note is that if a new (not seen in training data) category is encountered in new data, it should be ignored. DictVectorizer handles this silently:
>>> new_dict = [{'interest': 'unknown_interest',
'occupation': 'retired'},
... {'interest': 'tech', 'occupation':
'unseen_occupation'}]
>>> new_encoded = dict_one_hot_encoder.transform(new_dict)
>>> print(new_encoded)
[[ 0. 0. 0. 0. 1. 0.]
[ 0. 0. 1. 0. 0. 0.]]
Unlike DictVectorizer, however, LabelEncoder does not handle unseen category implicitly. The easiest way to work around this is to convert string data into a dictionary object so as to apply DictVectorizer. We first define the transformation function:
>>> def string_to_dict(columns, data_str):
... columns = ['interest', 'occupation']
... data_dict = []
... for sample_str in data_str:
... data_dict.append({column: value
for column, value in zip(columns, sample_str)})
... return data_dict
Convert the new data and employ DictVectorizer:
>>> new_str = np.array([['unknown_interest', 'retired'],
... ['tech', 'unseen_occupation'],
... ['unknown_interest', 'unseen_occupation']])
>>> columns = ['interest', 'occupation']
>>> new_encoded = dict_one_hot_encoder.transform(
string_to_dict(columns, new_str))
>>> print(new_encoded)
[[ 0. 0. 0. 0. 1. 0.]
[ 0. 0. 1. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]]