
In order to use cloud computing with the Azure platform beyond simple hosting, you must explore the vast array of options available to you when it comes to designing solutions. In addition to the design options presented in this chapter, you need a strong grasp of cloud computing's current shortcomings, which may affect your design choices.
Before reviewing various design patterns, let's start with some opportunities and limitations that impact your design choices. Keep in mind that although this book focuses primarily on SQL Azure, many of the concepts in this chapter apply to Azure development in general.
The Azure platform offers four distinct storage models, which were previously discussed in Chapter 1, "Blob, Table, Queue, and SQL Azure." Storing data in SQL Azure is similar to storing data in SQL Server. All you need to do is issue T-SQL statements and review some of the limitations of the syntax specific to SQL Azure, and off you go!
The ability to store data in SQL Azure using T-SQL offers unique opportunities. In many cases, you can easily extend or port certain types of applications in SQL Azure with no (or limited) modifications. This portability allows you either to implement solutions that directly depend on SQL Azure for storage, or to use a local database while using SQL Azure transparently for additional storage requirements (such as reporting).
However, keep in mind that you're limited to the amount of data you can store in a single SQL Azure database. At the moment, SQL Azure supports two editions: Web Edition (1GB or 5GB) and Business Edition (from 10GB to 50GB in 10GB increments). So, if your application needs to store more than 50GB of data, or if your database can benefit from a multithreaded data access layer, you need to consider splitting your data across multiple databases through a form of partitioning called a shard. You learn about shards later in this chapter and in more detail throughout this book.
When designing applications, software developers and architects are usually concerned about high-availability requirements. SQL Azure uses a very elaborate topology that maximizes workload redistribution, transparency, and recovery. Figure 2-1 shows a high-level implementation of SQL Azure that gives a hint about how advanced the backend infrastructure must be.

Figure 2-1 illustrates that connections are made through a load balancer that determines which gateway should process the connection request. The gateway acts as a firewall by inspecting the request, performing authentication and authorization services, and forwarding the packets to an actual SQL Azure database. Because databases can be moved dynamically to ensure fair resource allocation, the gateway may alter the destination endpoint. The process is mostly transparent.
In addition, each SQL Azure database is replicated twice on different servers for redundancy. Behind the scenes, a replication topology ensures that a SQL Azure database exists on two other physical servers at all times. These two additional copies are totally transparent to consumers and can't be accessed.
Note
SQL Azure offers 99.9% availability.
Performance of applications you write can be affected by two things: throttling and how you design the application. Microsoft has put performance throttling in place to prevent one client's applications from impacting another. (It's a good feature, not nearly so bad as it may sound.) Application design is something you control.
SQL Azure runs in a multitenant environment, which implies that your databases share server resources with databases from other companies. As a result, the SQL Azure platform has implemented a throttling algorithm that prevents large queries from affecting other users from a performance standpoint. If your application issues a large query that could potentially affect other databases, your database connection is terminated.
In addition, to preserve valuable resources and control availability, SQL Azure disconnects idle sessions automatically. The session timeout is set to 30 minutes. When you're designing for SQL Azure, your application should account for automatic session recovery. This also means that performance testing in your development phase becomes more critical.
Note
In the context of SQL Azure, throttling means terminating the database connection. Whatever the reason for being throttled is, the outcome is the same: loss of database connection.
When considering how to design your application to best take advantage of SQL Azure, you need to evaluate the following items:
Database roundtrips. How many roundtrips are necessary to perform a specific function in your application? More database roundtrips mean a slower application, especially when the connection is made over an Internet link and is SSL encrypted.
Caching. You can improve response time by caching resources on the client machine or storing temporary data closer to the consumer.
Property lazy loading. In addition to reducing roundtrips, it's critical to load only the data that's absolutely necessary to perform the required functions. Lazy loading can help significantly in this area.
Asynchronous user interfaces. When waiting is unavoidable, providing a responsive user interface can help. Multithreading can assist in providing more responsive applications.
Shards. A shard is a way of splitting your data across multiple databases in a manner that is as transparent as possible to your application code, thus improving performance.
Designing an application for performance becomes much more important for cloud computing solutions that depend on remote storage. For more information on these topics and more, see Chapter 10.
The SQL Data Sync framework offers bidirectional data-synchronization capabilities between multiple data stores, including databases. SQL Data Sync uses the Microsoft Sync Framework, which isn't limited to database synchronization; you can use the framework to synchronize files over different platforms and networks.
Specifically as it relates to SQL Azure, you can use the Sync framework to provide an offline mode for your applications by keeping a local database synchronized with a SQL Azure database. And because the framework can synchronize data with multiple endpoints, you can design a shard, described later, in which all databases keep their data in sync transparently.
You may also consider developing Azure services to keep the database connection to a local network, and send the data back to the client using SOAP or REST messages. If your Azure services are deployed in the same region as your SQL Azure databases, the database connection is made from the same datacenter and performs much faster. However, sending data back to the consumer using SOAP or REST may not necessarily improve performance; you're now sending back XML instead of raw data packets, which implies a larger bandwidth footprint. Finally, you may consider writing stored procedures to keep some of the business logic as close to the data as possible.
Figure 2-2 shows the two different ways an application can retrieve data stored in a SQL Azure database. A direct connection can be established to the database from the application, in which case the application issues T-SQL statements to retrieve data. A serviced connection can be made by creating and deploying custom SOAP or REST services on Windows Azure, which in turn communicate to the database. In this case, the application requests data through web services deployed in Azure.

Keep in mind that you can design an application to use both connection methods. You may determine that your application needs to connect directly when archiving data, while using services to perform more complex functions.
Note
Most of this chapter provides direct connection diagrams; however, many of the patterns presented would work just as well using a serviced connection to a Windows Azure service first.
Pricing of a hosted environment isn't usually considered a factor when it comes to standard application design. However, in the case of cloud computing, including Azure, you need to keep in mind that your application's performance and overall design have a direct impact on your monthly costs.
For example, you incur network and processing fees whenever you deploy and use Azure services. Although this is true, at the time of this writing the data traffic between a Windows Azure application or service and a SQL Azure database is free within the same geographic location.
Pricing may affect your short-term application design choices, but you should keep in mind that Microsoft may change its pricing strategy at any time. As a result, although pricing is an important consideration especially for projects on limited budget, long-term viability of a design should be more important than short-term financial gains.
If you're designing an application to live in the Azure world and you depend on this application to generate revenue, you must ensure that your pricing model covers the resulting operational costs. For example, your application should be designed from the ground up with billing capabilities in mind if you intend to charge for its use.
Another factor related to pricing is that your SQL Azure database cost consists of a monthly fee and a usage fee. The monthly fee is prorated, so if you create a database at 1pm and drop it at 2pm the same day, you're charged a fraction of the monthly fee, plus the usage fee. The usage fee is strictly limited to bandwidth consumption: CPU utilization, I/O consumption, and your database's memory footprint aren't factors in the usage fee (see Figure 2-3). However, your database connection may be throttled if your CPU, I/O, and/or memory consumption reaches specific thresholds.
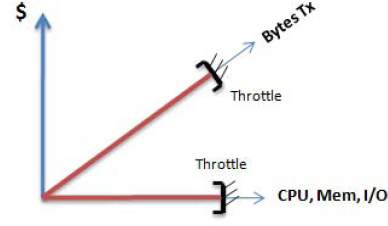
In summary, you can consider moving certain CPU-intensive activities (within reason) on the SQL Azure database without being charged. You may, for instance, perform complex joins that use large datasets in a stored procedure and return a few summary rows to the consumer as a way to minimize your usage fee.
It goes without saying that security may be a concern for certain types of applications; however, these concerns are similar to those that companies face when using traditional hosting facilities. The question that comes to mind when considering security is related to the lack of control over data privacy. In addition, certain limitations may prevent certain kinds of monitoring, which automatically rules out the use of SQL Azure for highly sensitive applications unless the sensitive data is fully encrypted on the client side.
As a result, encryption may become an important part of your design decision. And if you decide to encrypt your data, where will the encryption take place? Although the connection link is encrypted between your application code and SQL Azure, the data itself isn't encrypted when it's stored in SQL Azure. You may need to encrypt your data in your application code before sending it over the public Internet so that it's stored encrypted.
Encryption is good for data privacy, but it comes with a couple of downsides: slower performance and difficulty in searching for data. Heavy encryption can slow down an application, and it's notoriously difficult to search for data that is encrypted in a database.
So far, you're seen a few considerations that can impact your design choices. Table 2-1 provides a summary. Some of the considerations are related to opportunities that you may be able to take advantage of; others are limitations imposed by the nature of cloud computing or specifically by the Azure platform.
As you design applications, make sure you evaluate whether specific Azure limitations discussed in this book still apply—the Azure platform is likely to change quickly in order to respond to customer demands.
Let's review the important design patterns that use SQL Azure. Before designing your first cloud application, you should read this section to become familiar with a few design options. Some of the advanced design patterns explained in this chapter can also provide significant business value, although they're more difficult to implement.
Note that for simplicity, the diagrams in this section show only a direct connection to SQL Azure. However, virtually all the patterns can be implemented using a serviced connection through Azure services.
The direct connection pattern, shown in Figure 2-4, is perhaps the simplest form of connectivity to a SQL Azure database. The consumer can be either an application located in a corporation's network or a Windows Azure service connecting directly to the SQL Azure database.
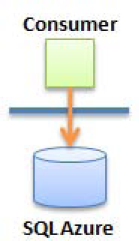
As simple as it is, this may be one of the most widely used patterns, because it requires no special configuration or advanced integration technique. For example, a software as a service (SaaS) application may use this pattern; in this case, the consumer is the web site hosted in Azure (or on any other hosting provider). Alternatively, the consumer may be a smart device or a phone accessing records in SQL Azure.
The smart branching pattern (see Figure 2-5) describes an application that contains sufficient logic to determine whether the data it needs to load is located in the cloud or in a local database. The logic to make this determination is either hardcoded in the application or driven from a configuration file. It may also be provided by a data access layer (DAL) engine that contains logic that fetches data either a local or a cloud database.
One of the uses for smart branching is to implement a form of caching in which the consumer caches parts of its data locally or fetches it from a cloud database whenever necessary. You can also use this pattern to implement a disconnected mode to your application, in case Internet connectivity becomes unavailable.

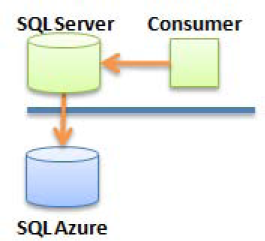
Whereas smart branching depends on the consumer (or one of its components) to determine whether data is local or in the cloud, transparent branching (see Figure 2-6) removes this concern from the consumer. The consuming application no longer depends on routing logic and becomes oblivious to the ultimate location of the data.
This pattern is best implemented by applications that are difficult to modify or for which the cost of implementation is prohibitive. It can effectively be implemented in the form of extended stored procedures that have the knowledge to fetch data from a cloud data source. In essence, this pattern implements a DAL at the database layer.
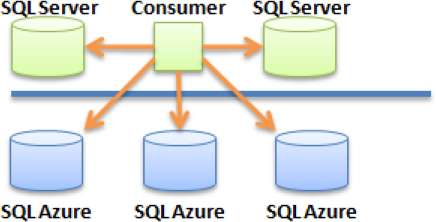
So far, you've seen patterns that implement a single connection at a time. In a shard (see Figure 2-7), multiple databases can be accessed simultaneously in a read and/or write fashion and can be located in a mixed environment (local and cloud). However, keep in mind that the total availability of your shard depends partially on the availability of your local databases.
Shards are typically implemented when performance requirements are such that data access needs to be spread over multiple databases in a scale-out approach.
Before visiting the shard patterns, let's analyze the various aspects of shard design. Some important concepts are explained here:
Decision rules. Logic that determines without a doubt which database contains the interesting record(s). For example, if Country = US, then connect to SQL Azure Database #1. Rules can be static (hardcoded in C#, for example) or dynamic (stored in XML configuration files). Static rules tend to limit the ability to grow the shard easily, because adding a new database is likely to change the rules. Dynamic rules, on the other hand, may require the creation of a rule engine. Not all shard libraries use decision rules.
Round-robin. A method that changes the database endpoint for every new connection (or other condition) in a consistent manner. For example, when accessing a group of five databases in a round-robin manner, the first connection is made to database 1, the second to database 2, and so on. Then, the sixth connection is made to database 1 again, and so forth. Round-robin methods avoid the creation of decision engines and attempt to spread the data and the load evenly across all databases involved in a shard.
Horizontal partition. A collection of tables with similar schemas that represent an entire dataset when concatenated. For example, sales records can be split by country, where each country is stored in a separate table. You can create a horizontal partition by applying decision rules or using a round-robin method. When using a round-robin method, no logic helps identify which database contains the record of interest; so all databases must be searched.
Vertical partition. A table schema split across multiple databases. As a result, a single record's columns are stored on multiple databases. Although this is considered a valid technique, vertical partitioning isn't explored in this book.
Mirrors. An exact replica of a primary database (or a large portion of the primary database that is of interest). Databases in a mirror configuration obtain their data at roughly the same time using a synchronization mechanism like SQL Data Sync. For example, a mirror shard made of two databases, each of which has the Sales table, has the same number of records in each table at all times. Read operations are then simplified (no rules needed) because it doesn't matter which database you connect to; the Sales table contains the data you need in all the databases.
Shard definition. A list of SQL Azure databases created in a server in Azure. The consumer application can automatically detect which databases are part of the shard by connecting to the master database. If all databases created are part of the shard, enumerating the records in
sys.databasesgives you all the databases in the shard.Breadcrumbs. A technique that leaves a small trace that can be used downstream for improved decisions. In this context, breadcrumbs can be added to datasets to indicate which database a record came from. This helps in determining which database to connect to in order to update a record and avoids spreading requests to all databases.
When using a shard, a consumer typically issues CRUD (create, read, update, and delete) operations. Each operation has unique properties depending on the approach chosen. Table 2-2 outlines some possible combinations of techniques to help you decide which sharding method is best for you. The left column describes the connection mechanism used by the shard, and the top row identifies the shard's storage mechanism.
Table 2.2. Shard access techniques
Shards can be very difficult to implement. Make sure you test thoroughly when implementing shards. You can also look at some of the shard libraries that have been developed. The shard library found on CodePlex and explained further in this book (in Chapter 10) uses .NET 4.0; you can find it with its source code at http://enzosqlshard.codeplex.com. It uses round-robin as its access method. You can also look at another implementation of a shard library that uses SQLAzureHelper; this shard library uses decision rules as its access method and is provided by the SQL Azure Team (http://blogs.msdn.com/b/sqlazure/).
Shards can be implemented in multiple ways. For example, you can create a read-only shard (ROS). Although the shard is fed from a database that accepts read/write operations, its records are read-only for consumers.
Figure 2-8 shows an example of a shard topology that consists of a local SQL Server to store its data with read and write access. The data is then replicated using the SQL Data Sync framework (or other method) to the actual shards, which are additional SQL Azure databases in the cloud. The consuming application then connects to the shard (in SQL Azure) to read the information as needed.

In one scenario, the SQL Azure databases each contain the exact same copy of the data (mirror shard), so the consumer can connect to one of the SQL Azure databases (using a round-robin mechanism to spread the load, for example). This is perhaps the simpler implementation because all the records are copied to all the databases in the shard blindly. However, keep in mind that SQL Azure doesn't support distributed transactions; you may need to have a compensating mechanism in case some transactions commit and others don't.
Another implementation of the ROS consists of synchronizing the data using horizontal partitioning. In a horizontal partition, rules are applied to determine which database contains which data. For example, the SQL Data Synch service can be implemented to partition the data for US sales to one SQL Azure database and European sales to another. In this implementation, either the consumer knows about the horizontal partition and knows which database to connect to (by applying decision rules based on customer input), or it connects to all databases in the cloud by applying a WHERE clause on the country if necessary, avoiding the cost of running the decision engine that selects the correct database based on the established rules.
In a read-write shard (RWS), all databases are considered read/write. In this case, you don't need to use a replication topology that uses the SQL Data Sync framework because there is a single copy of each record within the shard. Figure 2-9 shows a RWS topology.
Although a RWS removes the complexity of synchronizing data between databases, the consumer is responsible for directing all CRUD operations to the appropriate cloud database. This requires special considerations and advanced development techniques to accomplish, as previously discussed.
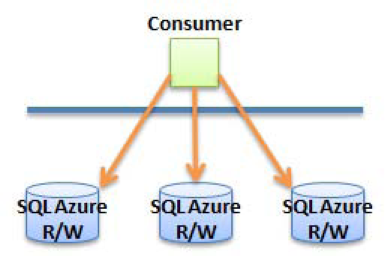
In the offloading pattern, the primary consumer represents an existing onsite application with its own database; but a subset of its data (or the entire database) is replicated to a cloud database using SQL Data Sync (or another mechanism). The offloaded data can then be used by secondary consumers even if the primary database isn't accessible.
You can implement the offloading pattern in two ways, as shown in Figure 2-10. The primary database can be either the local SQL Server database or the cloud database. For example, a legacy application can use a local SQL Server database for its core needs. SQL Data Sync is then used to copy relevant or summary data in a cloud database. Finally, secondary consumers such as portable devices and PDAs can display live summary data by connecting to the cloud for their data source.
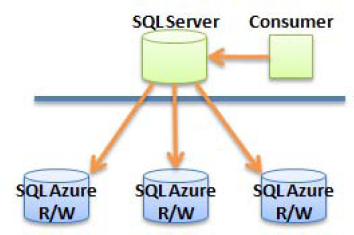
In its simplest form, the aggregation pattern provides a mechanism to collect data from multiple data providers into a SQL Azure database. The data providers can be geographically dispersed and not know about each other, but they must share a common knowledge of the schema so that, when aggregated, the data is still meaningful.
The aggregation patterns shown in Figure 2-11 use the direct connection pattern. You can use an aggregation pattern to provide a common repository of information, such as demographic information or global warming metrics collected from different countries. The key in this pattern is the ability to define a common schema that can be used by all providers and understood by the consumers. Because SQL Azure supports XML data types, you can also store certain columns in XML, which provides a mechanism to store slightly different information per customer.

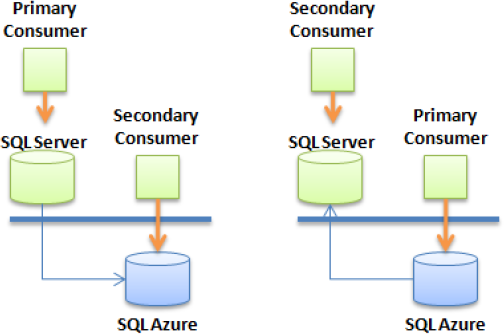
The mirror pattern, shown in Figure 2-12, is a variation of the offloading pattern where the secondary consumer can be an external entity. In addition, this pattern implies that a two-way replication topology exists, so that changes in either database are replicated back to the other database. This pattern allows a shared nothing integration in which neither consumer has the authority to connect to the other consumer directly.

The previous design patterns provide the necessary basis to build systems with SQL Azure. Some of these patterns can be used as is, but you're very likely to combine patterns to deliver improved solutions. This section describes some useful combinations.
Figure 2-13 shows the transparent branching and the read-write shard patterns combined. This pattern can be used to offload into the cloud storage of historical data that an existing Enterprise Resource Planning (ERP) application generates. In this example, the shard provides a way to ensure high throughput by using asynchronous round-robin calls into SQL Azure databases.
This pattern offers the following advantages:
Transparent data transfer. In this case, the transparent branching pattern copies an existing application's data into cloud databases without changing a single line of code in the existing application.
High performance. To ensure high performance and throughput, the round-robin shard pattern is used along with asynchronous calls into the cloud.
Scalable. When using a shard, it's very simple to expand it by adding a new SQL Azure database into the cloud. If implemented correctly, the shard automatically detects the new database and storage capacity, and throughput automatically increases.
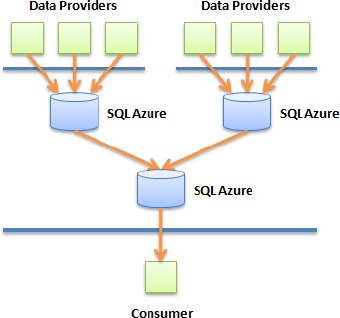
In cascading aggregation (see Figure 2-14), the aggregation pattern is applied serially to generate a summary database. The mechanism to copy (or move) data from one SQL Azure database to another must be accomplished using a high-level process, such as a worker process in Windows Azure.
For example, this pattern can be used to collect information from multiple SQL Azure databases into a single one used by a third party to monitor overall performance. A Windows Azure worker process can run a performance view provided by SQL Azure and store the data into another database. Although the SQL Azure databases being monitored for performance may have a totally different schema, the output of SQL Azure's performance data management view (DMV) is consistent. For example, the monitoring service can call sys.dm_exec_connections to monitor connection activity in various SQL Azure databases every 5 minutes and store the result in a separate SQL Azure database.
To put a few of the patterns in perspective, let's create a formal design around a system that monitors application performance service-level agreements (SLAs). In this design, a company already has a monitoring product that can audit activity in existing SQL Server databases at customer sites. Assume that the company that makes this monitoring product wants to extend its services by offering a SQL Azure storage mechanism so it can monitor customers' database SLAs centrally.
First, let's look at the existing application-monitoring product. It contains a module that monitors one or more SQL Servers in an enterprise and stores its results in another database located on the customer's network.
In this example, Company A has implemented the monitoring service against an existing ERP product to monitor access security and overall SLA. The monitoring application performs the auditing based on live activity on the internal SQL Server storing the ERP data. When certain statements take too long to execute, the monitoring service receives an alert and stores an audit record in the local auditing database, as shown in Figure 2-15.
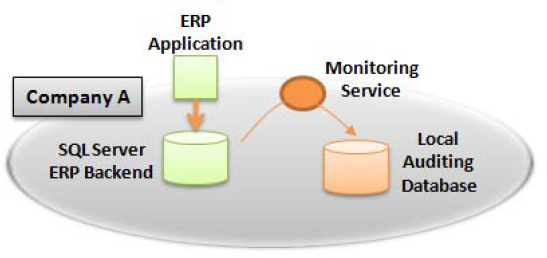
On a monthly basis, managers run reports to review the SLAs of the ERP system and can determine whether the ERP application is still performing according to predefined thresholds as specified in the ERP vendor contract. So far, the benefits of this implementation include the following:
Visibility. The customer has visibility into its internal database's performance.
SLA management. Measured SLAs can be used to negotiate contract terms with the ERP vendor.
However, the customer needs to store the auditing data internally and manage an extra SQL Server instance; this adds database management overhead, including making sure all security patches (operating system and database) are up to date. In addition, the local auditing database running on SQL Server isn't readily accessible to the ERP vendor, so the ERP vendor can't take proactive actions on any SLA issues and must wait to be informed by the customer about serious performance issues. Finally, the customer doesn't know how its internal SLA measures compare to other customers running the same ERP product.
The monitoring provider has created an enhanced version of its monitoring system and includes an optional cloud storage option, in which the monitoring service can forward performance events in a centrally located database in the cloud. The monitoring provider has decided to implement an asynchronous smart branching pattern so that events can be stored in a SQL Azure database.
Figure 2-16 shows the implementation architecture that lets the monitoring service store data in a cloud database. Each monitoring service can now store SLA metrics in the cloud in addition to the local auditing database. Finally, the local auditing database is an option that customers may choose not to install. To support this feature, the monitoring provider has decided to implement a queuing mechanism in case the link to SQL Azure becomes unavailable.
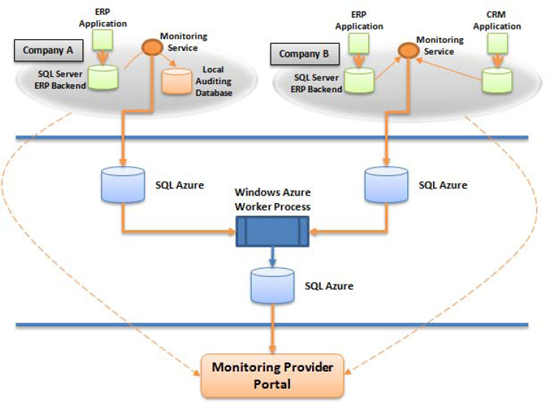
The monitoring provider has also built a portal on which customers can monitor their SLAs. Customer B, for example, can now use the portal to monitor both its CRM and ERP application database SLAs. The customer can prepare reports and make them available to the ERP and CRM vendors for review online, with complete drilldown access to the statements from the same portal.
In this implementation, additional benefits include the following:
Improved sharing. Sharing information with vendors becomes much easier because drilldown access to issues is provided through a cloud-enabled portal.
Local storage optional. With the improved solution, customers may decide to implement the cloud storage only if they're short staffed to handle the necessary internal database-management activities.
External monitoring. Customers A and B also have the ability to use the monitoring provider to proactively monitor their ERP products remotely with specific escalation procedures when the SLAs aren't met. The monitoring provider can, for example, manage performance issues directly with the ERP provider.
This chapter has introduced many important design factors to help you design a solution that uses SQL Azure. Are few more concepts are worth a glance, such as blob data stores, edge data caching, and data encryption.
Blobs are files that can be stored in Windows Azure. What is interesting about blobs is that they can be easily accessed through REST, there is no limit to the number of blobs that can be created, and each blob can contain as much as 50GB of data. As a result, blobs can be used as a backup and transfer mechanism between consumers.
A system can dump SQL Azure tables to files using the Bulk Copy Program (BCP), possibly compressing and/or encrypting the files beforehand, and store the blobs in Windows Azure.
The chapter briefly mentioned caching earlier, but you should remember that caching may yield the most important performance gains in your application design. You can cache relatively static tables in memory, save them as blobs (or a form of in-memory storage) so that other caching systems use the same cache, and create a mechanism to refresh your data cache using queues in Azure.
Figure 2-17 shows an example of a design that creates a shared cache updated by two ERP systems. Each ERP systems uses the transparent branching pattern to update shared records in a SQL Azure database. At this point, however, the edge caches aren't aware of the change in data. At a specific interval (every 10 minutes, for example) a worker process in Windows Azure picks up the changes and stores them in blobs. The worker may decide to apply logic to the data and resolve conflicts, if any. Blobs are then created (or replaced) with the latest cache information that should be loaded. The edge cache refreshes its internal data by loading the blobs at specific intervals (every 5 minutes, for example) and replaces its internal content with the latest cache. If all edge caches are configured to run against a public atomic clock, all the caches are updated virtually at the same time.

You can encrypt your data in two environments: onsite or in Windows Azure using a service. SQL Azure, as previously mentioned, doesn't support encryption at this time (although hashing is supported). If you need to encrypt Social Security numbers or phone numbers, you should consider where encryption makes sense.
Generally speaking, unless your application runs in a public environment where your private keys can be at risk, you should consider encrypting onsite before the data goes over the Internet. But if you need a way to decrypt in Windows Azure, or you need to encrypt and decrypt data across consumers that don't share keys, you probably need to encrypt your data in Windows Azure before storing it in SQL Azure.
This chapter reviewed many design concepts that are unique to distributed computing and for which cloud computing is a natural playground. Remember that designing cloud applications can be as simple as connecting to a SQL Azure database from your onsite applications or as complex as necessary (with distributed edge caches and shards) for enterprise-wide systems.
The chapter provided multiple parameters that you should consider when designing your application, each of which can significantly impact your final design, such as performance, billing, security, storage options, and throttling. You should consider creating two or more cloud-based designs and review them with other designers to discuss pros and cons before making your final selection. And if you have the time, build a proof-of-concept to validate your assumptions and measure how effective the solution will be.