
This chapter focuses on a few key topics that can help you design high-performance applications that consume data in SQL Azure and SQL Server databases. The approach used in this chapter builds a simple but effective WinForms application that consumes data from both on-premises and cloud data. You first explore a few general concepts and then quickly go into the design and development of a shard library that reads data from multiple databases. Finally you see how to add multithreading to the shard library using the Task Parallel Library (TPL) and caching using the Enterprise Library (formally known as application blocks).
Before diving into the details, let's discuss a few concepts related to performance. The first thing you should know is that achieving high performance is difficult. Although making sure applications perform to acceptable levels is important, advanced performance tuning requires careful planning and should be included as a design goal only if requirements drive you to believe that high performance is necessary. For example, if you expect your application to be used by thousands of concurrent users, then you may need to use caching and even multithreading. On the other hand, certain high-performance techniques can make code difficult to read and maintain, and in such cases knowledge transfer may be difficult.
The encrypted network connection to SQL Azure yields slower applications and may impact your application design significantly. An application that opens a database connection for every database call and performs a roundtrip for every update (that is, a chatty application) performs slower than an application that loads data for multiple objects in a single call and sends changes in bulk (a chunky application). LINQ to SQL and the Entity Framework are data access layers that provide good control over the use of bulk operations (the SaveChanges method on the object context).
For example, if you design a data access layer that contains a lot of business rules, your code may perform many roundtrips to the database to load the data needed to execute the business rules. If this is the case, you can implement certain data-intensive business rules in stored procedures (close to the data) and/or use caching to avoid unnecessary roundtrips.
On the other hand, although it's good to have fewer roundtrips from a performance standpoint, you should load only the data you need, for two reasons: the more data you load, the more you pay for the SQL Azure service; and loading more data than necessary can slow down your applications. So, you may want to consider using a lazy loading mechanism by which certain properties of your objects are loaded only when necessary. LINQ to SQL and the Entity Framework 4.0 support lazy loading (through the use of the DeferredLoadingEnabled property).
Although lazy loading minimizes the amount of data loaded, it also creates a chattier application by design. It's important to strike the right balance between using bulk data transfers and minimizing the amount of data needed to run an application function.
Another important technique used to minimize roundtrips is caching. Your application (or service) may use caching to avoid unnecessary roundtrips if some of your data doesn't change often. This may also impact your database design choices. For example, if you have a table that stores a list of states, the table will probably remain unchanged for a long time, which makes it a great candidate for caching.
Caching can be performed in memory or on disk (in a local database, for example). You have a few options:
ASP.NET caching. ASP.NET offers a cache object that provides good caching capabilities. However, ASP.NET caching is tied to IIS. Restarting IIS clears the ASP.NET cache unless you've taken the necessary steps to persist the cache.
Windows Server AppFabric. The AppFabric offers a next-generation distributed cache (previously known as Velocity). This cache can run on multiple computers and is made available through a .NET API.
Enterprise Library. The Enterprise Library offers a collection of application blocks that Microsoft makes available under public license. The Enterprise Library contains a cache mechanism that doesn't depend on ASP.NET. This caching mechanism is provided natively in .NET 4.0 and can be found under the
System.Runtime.Cachingnamespace.
Ultimately, performance is a measure that impacts the user experience and can be controlled to a certain degree by offering highly responsive user interfaces. A Windows application that becomes unresponsive while loading data, or a web page that doesn't load until all the data has been retrieved, is perceived as slow. As a result, developing with multithreading techniques may become more important to provide a better experience to your users.
For web development, you should consider using asynchronous controls (such as AJAX) that give you more control over partial page loading. For Windows development, you may need to use a multithreaded user interface development approach.
To implement a highly responsive application in WinForms, use the Invoke method, shown on line 3 of the following example, to refresh your user interface on the UI thread:
1) void OnPassCompleted()
2) {
3) this.Invoke(new EventHandler(UpdateProgressBar), null);
4) }
5)
6) private void UpdateProgressBar(object o, System.EventArgs e)
7) {
8) if (progressBarTest.Value < progressBarTest.Maximum)9) {
10) progressBarTest.Value++;
11) }
12) }In this example, OnPassCompleted is a custom event received by the main form, which then calls the Invoke method to refresh a progress bar. The call to Invoke forces the execution of the progress bar refresh on the UI thread, which is different than the thread on which the OnPassCompleted event was raised.
In addition to asynchronous user interfaces, your code may need to execute on multiple processors. Two primary scenarios can lead you to choose parallel processing for your application:
Many calculations. Your application is CPU intensive, especially if computations can be independent from each other. Advanced graphics or complex mathematical computations are examples of CPU-intensive operations.
Many waits. Your application needs to wait between each call, and the cost of creating parallel threads and aggregating results is insignificant. Database shards are an example: calling five databases in parallel is roughly five times faster than calling five databases serially.
Two choices are available to write parallel processes. If you can, you should use the Task Parallel Library (TPL), because it's easier:
Task Parallel Library. The TPL is a newer library that Microsoft is providing as part of .NET 4.0. It allows you to take advantage of multiple CPUs quickly and easily. You can find the TPL under
System.Threading.Tasks.Threads. Managing threads the old-fashioned way using the
System.Threadingnamespace gives you the most flexibility.
Shards offer another mechanism by which your code can read and write data against any number of databases almost transparently. Later in this chapter, you create a horizontal partition shard (HPS) using the read-write shard (RWS) design pattern as described in Chapter 2, with the round-robin access method. A horizontal partition implies that all the databases have identical schema and that a given record can written in any database that belongs to the shard. From a performance standpoint, reading from multiple databases in parallel to search for records yields greater performance; however, your code must keep breadcrumbs if you need to perform updates back to the correct database. Finally, using a shard requires parallel processing for optimum performance.
Table 2-1 provides a summary of the concepts discussed so far regarding some of the coding strategies available to you when you develop against a SQL Azure database with performance in mind.
Table 10.1. Coding Strategies to Design for Performance
Comments | |
|---|---|
Bulk data loading/changing | Minimizes roundtrips by using a data access library that supports loading data in bulk, such as the Entity Framework. |
Lazy loading | Allows you to create objects for which certain properties are loaded only when first called, to minimize loading unnecessary data (and improve performance). The Entity Framework 4.0 supports this. |
Lets you to keep in memory certain objects that don't change frequently. The caching application blocks provided by Microsoft offer this capability as well as expiration and scavenging configuration settings. | |
Asynchronous user interface | Not technically a performance-improvement technique, but allows users to use the application while your code is performing a long-running transaction and thus provides a better user experience. |
Parallel processing | Allows you to run code on multiple processors for optimum performance. Although complex, this technique can provide significant performance advantages. |
Shards | Lets you to store data in multiple databases to optimize reads and spread the load of queries over multiple database servers. |
Because shards are considered a newer technology, the remainder of this chapter focuses on building a HPS using caching and parallel processing in order to improve performance and scalability.
Let's build a shard library that can be used by applications that need to load and update data against multiple SQL Azure databases as quickly and transparently as possible. For the purpose of building an efficient shard library, you stipulate the following requirements for the shard:
Adding new databases should be simple and transparent to the client code.
Adding new databases shouldn't affect performance negatively.
The library should function with SQL Server, SQL Azure, or both.
The library should optionally cache results for fast retrieval.
The library should support mass or selective reads and writes.
Data returned by the library should be accepted as a data source for controls.
These requirements have very specific implications from a technology standpoint. Table 2-2 outlines which requirements are met by which technology.
Table 10.2. Technologies Used to Build the Shard
Technology | Requirement | Comment |
|---|---|---|
Configuration file | 1 | The configuration file stores the list of databases that make up the shard. |
Multithreading | 2 | Using the TPL lets the library to spawn multiple threads to use computers with multiple CPUs, allowing parallel execution of SQL statements. |
| 3 | Using |
Caching | 4 | Caching lets the library store results temporarily to avoid unnecessary roundtrips. |
Breadcrumbs | 5 | The library creates a virtual column for each record returned that stores a breadcrumb identifying the database a record it came from. |
| 6 | The library returns a |
The library accepts requests directly from client applications and can be viewed as an API. Note that you're using extension methods to make this API blend in with the existing SqlCommand class; this in turn minimizes the amount of code on the client and makes the application easier to read.
Figure 10-1 shows where the library fits in a typical application design. It also shows how the library hides the complexity of parallel processing and caching from the client application. Finally, the shard library abstracts the client code from dealing directly with multiple databases.

A sample application is provided to demonstrate how to use the shard library. Although the application is very simple, it uses all the features of the shard for reference.
Note
Check http://EnzoSqlShard.Codeplex.com for the latest shard library. This shard library is made available as an open source project.
This section walks through a few coding decisions that are necessary when creating this shard. Because the shard library needs to be able to connect to multiple databases, the client has two options to provide this list: it can provide the list of connections to use whenever it makes a call to the library, or it can preload the library with a list of connection objects that are then kept in memory for all future calls.
The shard library declares the following property to hold the list of preloaded connection objects. The ShardConnections property is declared as static so it can be used across multiple calls easily; the client application only needs to set this property once:
public static List<SqlConnection> ShardConnections {get;set;}In addition, an extension method is added to SqlConnection to provide a GUID value that uniquely identifies a connection string. The connection GUID is critical for the shard; it provides a breadcrumb for every record returned by the shard. This breadcrumb is later used by the shard to determine, for example, which database to use when performing an update statement.
The following code shows how a connection GUID is calculated. It uses the SqlConnectionStringBuilder helper class and another extension method on strings called GetHash() (on line 8). This extension method returns a SHA-256 hash value. Note that if the connection string doesn't specify a default database (Initial Catalog), you assume the user is connected to the master database. This assumption is correct for SQL Azure, but it may not hold true for SQL Server:
1) public static string ConnectionGuid(this SqlConnection connection)
2) {
3) SqlConnectionStringBuilder cb = new
SqlConnectionStringBuilder(connection.ConnectionString);
4) string connUID =
5) ((cb.UserID != null) ? cb.UserID : "SSPI") + "#" +
6) cb.DataSource + "#" +
7) ((cb.InitialCatalog != null) ? cb.InitialCatalog : "master");
8) string connHash = connUID.GetHash().ToString();
9) return connHash;
10) }For reference, here is the extension method that returns a hash value for a string. Technically, you could use the string's native GetHashCode() method. However, the built-in GetHashCode method varies based on the operating system used (32-bit versus 64-bit) and the version of .NET. In this case, you create a simple GetHash() method that consistently return sthe same value for a given input. The string value is first turned into an array of bytes using UTF-8 (on line 3). The hash value is then computed on line 4. Line 5 returns the hash as a string value:
1) public static string GetHash(this string val)
2) {
3) byte[] buf = System.Text.UTF8Encoding.UTF8.GetBytes(val);
4) byte[] res =
System.Security.Cryptography.SHA256.Create().ComputeHash(buf);
5) return BitConverter.ToString(res).Replace("-", "");
6) }By default, the application code loads the initial set of connections using the application configuration file. In the current design, it's the application's responsibility to load the connections. This sample application reads the configuration file on startup and adds every entry in the ConfigurationStrings of the configuration file that contains the word SHARD:
1) foreach (System.Configuration.ConnectionStringSettings connStr in System.Configuration.ConfigurationManager.ConnectionStrings)
2) if (connStr.Name.ToUpper().StartsWith("SHARD"))
3) Shard.ShardConnections.Add(
new SqlConnection(connStr.ConnectionString));The application can also add connections based on user input. The following code shows how the application adds a new connection to the shard:
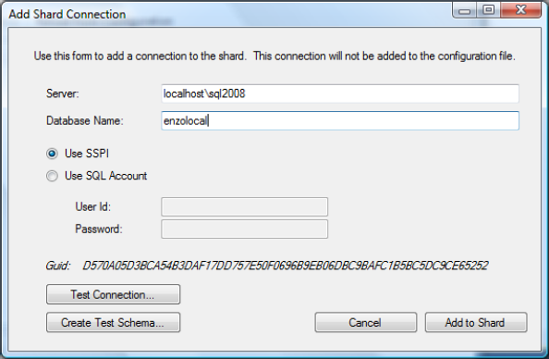
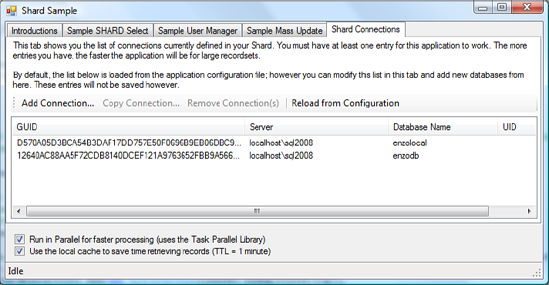
Shard.ShardConnections.Add(new SqlConnection("connection string here"));When running the test application, you can add a connection to the shard by clicking Add Connection on the Shard Connections tab. The GUID value for this connection is calculated automatically and displayed. Figure 10-2 shows the screen that allows you to add a connection manually, and Figure 10-3 displays all the connections defined in the shard.
Now that you've reviewed how connections strings are handled in the application and the library, you need to know how the shard handles a SELECT operation against multiple databases. In its simplest form, the library executes the SELECT operation against the list of connections defined previously.
The client application calls ExecuteShardQuery, which in turn loops over the list of SqlConnection objects (see Figure 10-4). If you look at the code, you see that a copy of each connection object is made first; this is to avoid any potential collisions if the client code makes a call to this method multiple times (a connection can only make one call at a time). Then, for each connection, the code calls ExecuteSingleQuery, which is the method in the shard library that makes the call to the database.

The ExecuteShardQuery method is designed to call the ExecuteSingleQuery method multiple times in parallel using the TPL. The TPL provides many useful methods to easily handle parallel processing without having to manage threads. The shard library uses Parallel.ForEach, which is a construct that allows the code to execute an inline method concurrently, and automatically adjusts the number of threads depending on your computer's hardware configuration. So, the more CPUs you have, the faster the following code executes, if you have enough connections to loop through. Note, however, that you need to lock the data object (line 5), which is a DataTable, because it could be accessed by other executing threads. Finally, the Merge method on the DataTable object concatenates resultsets from the various connections. After the loop has executed, the resulting data object has the list of records retrieved from the shard, in no guaranteed order:
1) Parallel.ForEach(connections, 2) delegate(SqlConnection c)
3) {
4) DataTable dt = ExecuteSingleQuery(command, c, exceptions);
5) lock (data)
6) data.Merge(dt, true, MissingSchemaAction.Add);
7) }
8) );The following code is a simplified version of the actual sample application. (For clarity, some code that calculates execution time and performs exception handling has been removed.) Line 4 sets the command text to be executed, such as a SELECT statement, and line 5 executes it against the shard. Instead of calling ExecuteReader, the code calls ExecuteShardQuery to use the shard. Line 7 binds the resulting DataTable and displays the records returned by the shard:
1) SqlCommand cmd = new SqlCommand(); 2) DataTable dataRes = new DataTable(); 3) 4) cmd.CommandText = this.textBox1.Text; 5) dataRes = cmd.ExecuteShardQuery(); 6) 7) dataGridView2.DataSource = dataRes;
Figure 10-5 shows the outcome of this code. The SELECT statement is designed to return database object names and types. Executing the statement against the shard performs as expected. However, notice that an extra column has been added to the display: __guidDB__. This is the name of the GUID column introduced previously. This column doesn't help much for reading, but it enables updates and deletes, as you see later.
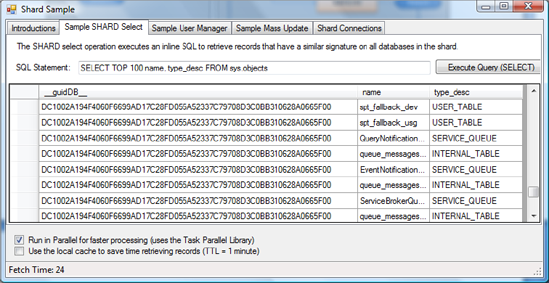
The GUID provided is unique for each database connection, as long as one of the key parameters is different in the connection string of each connection. It's added by the ExecuteSingleQuery method described previously. Within this method, a column is added in front of all the others, which carries the GUID. In the following code extract, line 3 creates the data column of type string, and line 4 sets its default value to the connection's GUID. Line 7 fills the data table with the query's result, along with the added GUID column. The following is the logic used to add this GUID:
1) // Add the connection GUID to this set of records 2) // This helps us identify which row came from which connection 3) DataColumn col = dt.Columns.Add(_GUID_, typeof(string)); 4) col.DefaultValue = connection.ConnectionGuid(); 5) 6) // Get the data 7) da.Fill(dt);
To minimize roundtrips to the source databases, the shard library provides an optional caching mechanism. The caching technique used in this library offers basic capabilities and can be extended to address more complex scenarios. The objective of this library is to cache the entire DataTable of each database backend whenever requested. Figure 10-6 shows the logical decision tree of the caching approach. It's important to note that this library calculates a cache key based on each parameter, the parameter value, each SQL statement, and the database's GUID.

The effect of the cache is visible when you connect to SQL Azure. Considering that connecting to a SQL Azure database takes up to 250 milliseconds the first time, memory access is significantly faster. The importance of the cache increases as the number of records increases and the number of databases increases in the shard.
The cache provided by this library also provides a time to live (TTL) mechanism that implements an absolute expiration or a sliding expiration scheme. An absolute expiration resets the cache automatically at a specific time in the future, whereas the sliding setting moves the expiration time if the cache items are used before expiring. The following code shows how the caching is implemented. Line 1 creates a CacheItemPolicy used to define the behavior of the cache. Line 3 implements the sliding window cache, and line 5 implements the absolute approach:
1) CacheItemPolicy cip = new CacheItemPolicy(); 2) if (UseSlidingWindow) 3) cip.SlidingExpiration = defaultTTL; 4) else 5) cip.AbsoluteExpiration = new DateTimeOffset(System.DateTime.Now.Add(defaultTTL)); 6) MemoryCache.Default.Add(cacheKey, dt, cip);
You can enhance this caching technique in multiple ways. For example, the DataTable object stored in the cache can be compressed when it contains many rows. Compression algorithms tend to increase latency, but the overall performance benefits may be worth a slight delay.
Another way to enhance this caching storage is to create different cache containers, so you can control at a more granular level which container holds which kind of data. Doing so lets you control a different setting per container, for example; or you may decide to always compress one cache container but not another.
Finally, the cache provided in this library isn't distributed; it's local to the machine running the library. If you need to develop a more robust cache, consider looking into the Windows Server AppFabric; its caching technology provides enterprise-level capabilities.
Note
For more information about the Windows Server AppFabric, visit http://msdn.microsoft.com/appfabric.
At this point, you're ready to see how updates and deletes take place through the shard. Updates and deletes against the databases in the shard can either be performed for records in a given database or against all databases. At a high level, here are some guidelines you can use to decide on an approach:
Update or delete records in a single database. You update or delete one or more records in a database when you already know the database GUID to use. This is the case when you use the shard to retrieve records, because the database GUID is provided for all records returned.
Update or delete records across databases. Generally speaking, you update or delete records across databases in the shard whenever you don't know which database a record is in, or when all records need to be evaluated.
To update or delete records in a single database, you must provide a command parameter that contains the database GUID to use. Here's the code that updates a single record in the shard. On lines 1 through 7, the code creates a command object that calls a stored procedure that requires two parameters. On line 9, the code adds the database GUID to use. This extra parameter is removed by the shard library before making the call to the requested database:
1) cmd.CommandText = "sproc_update_user";
2) cmd.CommandType = CommandType.StoredProcedure;
3)
4) cmd.Parameters.Add(new SqlParameter("@id", SqlDbType.Int));
5) cmd.Parameters["@id"].Value = int.Parse(labelIDVal.Text);
6) cmd.Parameters.Add(new SqlParameter("@name", SqlDbType.NVarChar, 20));
7) cmd.Parameters["@name"].Value = textBoxUser.Text;
8)
9) cmd.Parameters.Add(new SqlParameter(
PYN.EnzoAzureLib.Shard._GUID_, labelGUID.Text));
10)
11) ExecuteShardNonQuery (cmd);Note that calling a stored procedure isn't required for this code to run. All that is required is that a SqlCommand object be used; the SQL code may very well be inline SQL.
Deleting a record from the shard is virtually identical. The command object is created with the required stored procedure parameters from lines 1 through 5. On line 7, the code adds the database GUID to use:
1) cmd.CommandText = "sproc_delete_user";
2) cmd.CommandType = CommandType.StoredProcedure;
3)
4) cmd.Parameters.Add(new SqlParameter("@id", SqlDbType.Int));
5) cmd.Parameters["@id"].Value = int.Parse(labelIDVal.Text);
6)
7) cmd.Parameters.Add(new SqlParameter(
PYN.EnzoAzureLib.Shard._GUID_, labelGUID.Text));
8)
9) ExecuteShardNonQuery (cmd);Note
The ExecuteShardNonQuery method behaves differently if it has no database GUID parameter (it executes the query against all databases), if it has a database GUID parameter with a value (it executes the query against the specified database), or if it contains a database GUID parameter with a NULL value (it executes the query against the next database in the shard using round-robin). You see how to use round-robin calls when adding records in the shard shortly.
Figure 10-7 shows the sample application updating a record from the shard. When you click Reload Grid, a SELECT statement is issued against the shard, which returns the database GUID for each record. Then, when you select a specific record, the record details are loaded in the right section of the screen, along with the record's database GUID. At this point, the record can be updated or deleted.

Because records are being updated or deleted, the client code clears the cache to force future SELECT statements to fetch records from the databases in the shard. The shard library exposes a ResetCache method that does just that. You can improve this logic by also performing the same update or delete operation of records in the cache.
Updating or deleting records across databases in the shard is even simpler. The following code executes an inline SQL statement using a SqlCommand object. Because no database GUID is provided, this statement executes the statement across all databases in the shard. When you perform updates or deletes across databases, it's important to set the parallel flag correctly, as shown on line 1:
1) PYN.EnzoAzureLib.Shard.UseParallel = checkBoxParallel.Checked; 2) cmd.CommandText = "UPDATE TestUsers2 SET LastUpdated = GETDATE()"; 3) cmd.CommandType = CommandType.Text; 4) ExecuteShardNonQuery (cmd);
You see how easy it is to add records to the shard databases. This shard works best from a performance standpoint when all databases in the shard have a roughly equal number of records; this is because parallel processing is performed without any deterministic logic. As a result, the more spread out your records are in the shard, the faster it is. You can add records in the shard in two ways:
In a single database. If you're loading the shard for the first time, you may decide to load certain records in specific databases. Or you may decide to load one database with more records than others, if the hardware is superior.
Across databases. Usually, you load records in the shard without specifying a database. The shard library uses a round-robin mechanism to load records.
Adding a record in a specific database is no different than updating or deleting a record in a database; all you need to do is create a SqlCommand object, set the INSERT statement, and add a SqlParameter indicating the database GUID to use.
Adding one or more records across databases requires a slightly different approach. The round-robin logic stores the last database used to insert records in the shard. The shard library exposes two methods to perform inserts:
ExecuteShardNonQuery. As you've seen previously, this method extends theSqlCommandobject and executes statements against the next database in the shard (round-robin) if the GUID parameter isNULL. This convention is used to let the shard library know that it should move its internal database pointer to the next database in the shard for the next round-robin call.ExecuteParallelRoundRobinLoad. This method extendsList<SqlCommand>and provides a mechanism to create a collection ofSqlCommandobjects. EachSqlCommandobject contains anINSERTstatement to execute. This method adds aNULLdatabase GUID and callsExecuteShardNonQueryto execute all the statements with round-robin support. This construct simplifies loading a shard quickly by spreadingINSERTstatements evenly across all databases.
The following code shows how the client prepares the call to ExecuteParallelRoundRobinLoad. Line 1 creates a collection of SqlCommand objects. Then, on line 3, an outer loop executes for each value found in the userName array (this is a list of names to add to the shard). From lines 5 to 16, a SqlCommand object is created for each name to INSERT and is added to the collection. Line 22 makes the actual call to ExecuteParallelRoundRobinLoad. Finally, on line 23, if all goes well, the library's cache is cleared:
1) List<SqlCommand> commands = new List<SqlCommand>();
2)
3) foreach (string name in userName)
4) {
5) if (name != null && name.Trim().Length > 0)
6) {
7) SqlCommand cmdToAdd = new SqlCommand();
8) cmdToAdd.CommandText = "sproc_add_user";
9) cmdToAdd.CommandType = CommandType.StoredProcedure;
10)
11) cmdToAdd.Parameters.Add(
12) new SqlParameter("name", SqlDbType.NVarChar, 20));
13) cmdToAdd.Parameters["name"].Value = name;
14)
15) commands.Add(cmdToAdd);
16) }
17) }
18)
19) // Make the call!
20) if (commands.Count > 0)
21) {
22) commands.ExecuteParallelRoundRobinLoad();
23) Shard.ResetCache();
24) }Note
The call to ExecuteParallelRoundRobinLoad is different in two ways from all the other methods you've seen so far. First, there is no need to add the database GUID parameter; it creates this parameter automatically with a NULL value. Second, this method executes on a List<SqlCommand> object instead of SqlCommand.
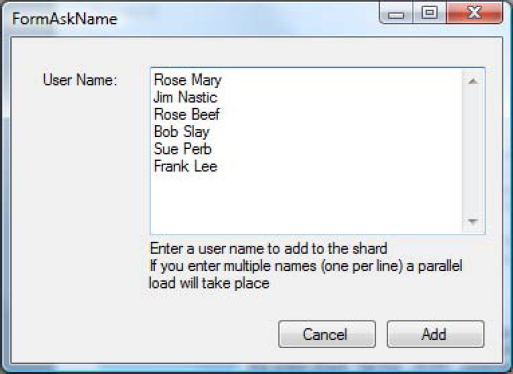
Figure 10-8 shows the sample application screen that creates the array of names to load in the shard. Six names are added in the shard using round-robin, as previously described.
Having created a shard and reached the point of being able to run queries and add data, you can begin to think about higher-level issues: how to handle exceptions, manage performance, control transactions, and more.
So far, you've learned the basic principles of the sample shard library. You saw how to select, insert, update, and delete records in various ways through the methods provided by the library. Let's discuss how you can manage exceptions that the shard may throw at you.
The current library doesn't handle rollbacks, but it may throw exceptions that your code needs to capture. In the previous example (Figure 10-8), all the records were inserted except Jim Nastic: that name was too long for the SqlParameter object (hence it threw a "Value Would Be Truncated" exception).
The library handles exceptions through the AggregateException class provided by the TPL; this class holds a collection of exceptions. This is necessary because the library executes database calls in parallel. As a result, more than one exception may be taking place at the same time. You need to aggregate these exceptions and return them to the client for further processing.
For example, the shard library's ExecuteSingleNonQuery method takes a ConcurrentQueue<Exception> parameter, which represents an object that stores exceptions. This object is thread-safe, meaning that all running threads can add new exceptions to it safely without running into concurrency issues. The following code shows that if an exception is detected in the ExecuteSingleNonQuery method, the code adds the exception to the queue on line 14. Also, as a convention, the exception is rethrown if the queue isn't provided (line 16):
1) private static long ExecuteSingleNonQuery(
2) SqlCommand command,
3) SqlConnection connectionToUse,
4) System.Collections.Concurrent.ConcurrentQueue<Exception> exceptions
5) )
6) {
7) try
8) {
9) // ...
10) }
11) catch (Exception ex)
12) {
13) if (exceptions != null)
14) exceptions.Enqueue(ex);
15) else
16) throw;
17) }
18) }The following code shows the ExecuteShardNonQuery method, which calls the ExecuteSingleNonQuery method just described. Line 1 creates the exception queue (ConcurrentQueue), which is passed as a variable to ExecuteSingleNonQuery. After the parallel execution of the database calls is complete, the code checks whether the exception queue is empty. If it isn't empty, an AggregateException is thrown, which contains the collection of exceptions stored in the exception queue (lines 13 and 14):
1) var exceptions = new System.Collections.Concurrent.ConcurrentQueue<Exception>();
2)
3) Parallel.ForEach(connections, delegate(SqlConnection c)
4) {
5) long rowsAffected = ExecuteSingleNonQuery(command, c, exceptions);
6)
7) lock (alock)
8) res += rowsAffected;
9)
10) }
11) );
12)
13) if (!exceptions.IsEmpty)
14) throw new AggregateException(exceptions);As you can see, managing exceptions can be a bit tricky. However, these exception helper classes provide a good mechanism to store exceptions and return a collection of exceptions that the client code can consume.
So far, you've seen how the shard library works and how you can use it in your code. But it's important to keep in mind why you go through all this trouble—after all, there is nothing trivial in creating a shard library. This shard library does something important: it allows a client application to grow parts (or all) of a database horizontally, with the intention of improving performance, scalability, or both.
What does this mean? It means the shard library can help an application keep its performance characteristics in a somewhat consistent manner as more users use the application (scalability), or it can help an application perform faster under a given load (performance). If you're lucky, the shard library may be able to achieve both. However, this won't happen without proper planning. The shard library by itself is only a splitter, in the sense that it spreads calls to multiple databases.
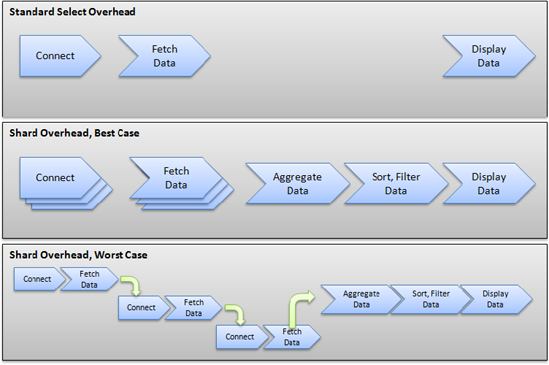
Shards don't necessarily help performance; in certain cases, a shard hurts both performance and scalability. The reason is that a shard imposes an overhead that wouldn't otherwise exist. Figure 10-9 shows the difference between a standard ADO.NET call selecting records and best case and worst case scenarios when fetching the same records from a shard. In the best case scenario, all records are assumed to be split in three distinct databases; the shard is able to concurrently access all three databases, aggregate the three resultsets, and filter and/or sort the data. The shard must then manage all of the following, which consumes processing time:
Loops for connecting to the underlying databases
Loops for fetching the data
Data aggregation, sorting and filtering
In the worst case scenario, all these operations can't be executed in parallel and require serial execution. This may be the case if the TPL detects that only a single processor is available. Finally, you may end up in a situation that mixes worst and best case scenarios, where some of the calls can be made in parallel, but not all.
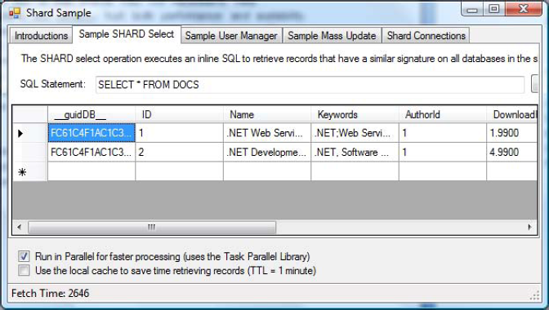
Now that all the warnings are laid out, let's look at a scenario for which a shard makes sense and probably improves both performance and scalability. Imagine a DOC table that contains only two records. The table contains a few fields that represent document metadata, such as Title and Author ID. However, this table also contains a large field: a varbinary column called Document that holds a PDF file. Each PDF file is a few megabytes in size. Figure 10-10 shows the output of the table. Because this database is loaded in SQL Azure, the SELECT * FROM DOCS statement returns a few megabytes of data on an SSL encrypted link. The execution of this statement takes about 2.5 seconds on average, or roughly 1.25 seconds per record.
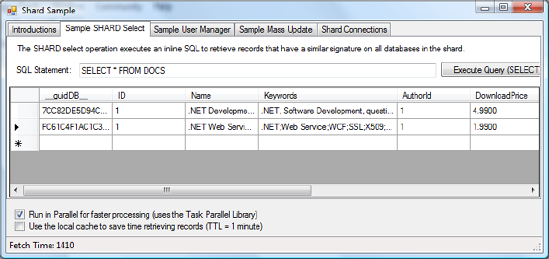
Both records come from the database; you can see this by looking at the database GUID, which is similar for both records. However, if you move the second record to another SQL Azure database, the average execution time drops to about 1.8 seconds. Figure 10-11 shows the result of the same statement that executed in 1.4 seconds (you can see that the database GUIDs are now different). This is half the execution time of the first result.
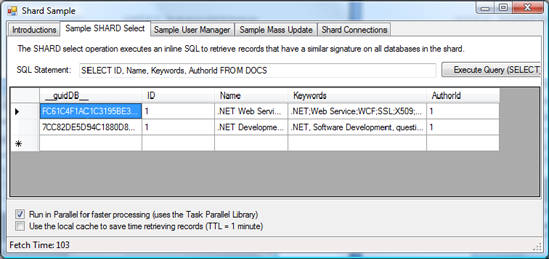
You can execute this statement much more quickly because almost the entire time is spent returning the Document field. Figure 10-12 tells you that returning all the fields against both databases without the Document field takes only 103 milliseconds. This shows that using a shard can provide performance benefits even if there is a processing overhead; however, this may not always be the case. Be sure to carefully evaluate your database design to determine which tables, if any, can take advantage of parallel execution.
Note that building a shard isn't an all-or-nothing approach. You can easily create a partial shard for a set of tables. Depending on how your code is structured, you may or may not need to build logic that uses the shard library, depending on which tables you need to access. This logic is best built in a data access layer (DAL), where the physical organization of tables is separated from the organization of business objects.
For example, you can design an application that consumes business objects directly. These business objects in turn consume command objects, which are specialized routines smart enough to load data in memory structures by calling execution objects. Figure 10-13 shows the Authors object calling two command objects that load data from two separate libraries: the standard ADO.NET library and the shard library. The complexity of determining which library to call is deferred to the lowest level possible, protecting the application and business objects from database structural changes.
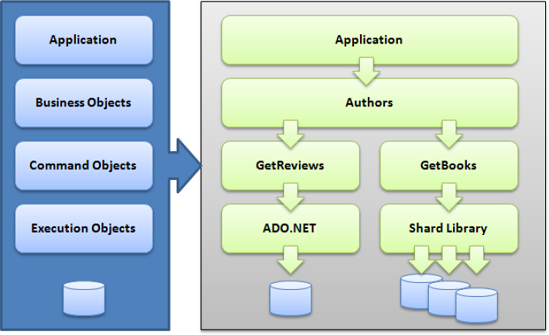
Because this library is meant for SQL Azure, and distributed transactions aren't supported in SQL Azure, the shard library doesn't offer transactional consistency by default. But you should look carefully at your transactional needs and what this means to your application design.
You can add transactional capabilities in the shard library fairly easily by changing the ExecuteShardNonQuery and ExecuteParallelRoundRobinLoad methods. To do so, you need to add a separate transaction context to all connection objects and commit them in a loop at the end of the last execution. If any exception occurs, you must roll back all the changes.
Note
As mentioned earlier, the shard library is an open-source project and is likely to evolve over time. Check for the latest release to see which features are supported.
Another interesting issue to consider in shard databases is related to foreign key constraints. Because the shard library proposed in this book splits tables horizontally, you may quickly realize that maintaining referential integrity can be challenging.
To maintain relational integrity, the following concerns apply:
Data duplication. Because you don't know which records are where in the shard, the parent tables needs to be duplicated in every database. For example, a table that contains the list of states (Florida, Illinois, and so on) may need to be replicated across all databases.
Identity values. Adding records in one database can't be easily replicated across to other databases. Thus, using an identity value as the primary key may be difficult because you aren't guaranteed to have the same value in all databases in the shard. For example, the StateID value for Florida may be 10 in one database and 11 in another.
When it comes to data duplication, you can either treat the parent tables as overhead and duplicate them across databases, allowing you to maintain strong referential integrity (RI), or sacrifice RI in the database by sharding the parent tables as well. If you decide to shard parent tables, you can no longer enforce RI in the database; but you may still be able to enforce RI in your code by adding RI constraints to your DataTable objects. You can do so by creating a DataRelation object in the DataTable's ParentRelations collection. For example, the following code adds RI to the DOCS and AUTHORS DataTable objects:
1) SqlCommand cmd1 = new SqlCommand("SELECT * FROM Authors");
2) SqlCommand cmd2 = new SqlCommand("SELECT * FROM Docs");
3) DataTable authors = ExecuteShardQuery(cmd1);
4) DataTable docs = ExecuteShardQuery(cmd2);
5) DataRelation dr = new DataRelation("RI",
6) authors.Columns["authorId"],
7) docs.Columns["authorId"]);
8) docs.ParentRelations.Add(dr);The issue with identity values lies in the fact that an automatic identity is created for each record. But because the tables are split across databases, you aren't guaranteed to have the same values over time. To solve this issue, you need to create RI rules that depend not on identity values, but on codes. In the case of the table that stores states, you create a StateCode column (that stores FL for Florida) and use that column as your primary key and in your RI rules. This ensures that all databases in the shard use the same values to maintain integrity.
The majority of this chapter discussed the HPS, but it's important to also be familiar with vertical partition shards (VPSs). A VPS stores an application database schema across multiple databases; in essence, the application database is split in such a way that no database in the shard holds the complete schema.
Let's consider a simple application database that is made of two tables: Users and Sales. The Users table contains a few thousand records, and the Sales table contains a few million records. You can design a VPS with two databases: the first contains the Users table, and the second contains the Sales table.
This type of shard makes it easy to isolate the processing power needs of certain tasks without affecting the other database. For example, you can use the Users table to process login requests from users while at the same time using the Sales table for a CPU-intensive calculation process or to run long reports.
You can also build a VPS by splitting a table across multiple databases. For example, the Sales table may store large binary fields (such as documents). In this case, you can split the Sales table such that common fields are stored in one database and the field containing documents is stored in another database.
A VPS does bring it own set of challenges, such as the difficulty of keeping strong RI between databases and, in the case of SQL Azure, ensuring transaction consistency. These considerations are only meant to bring certain design issues to the surface when you're thinking about a VPS. Depending on your database design, a VPS may work very well and may be simpler to implement than an HPS.
As you've seen, building databases with SQL Azure can be complex if you need to scale your database design or if you're looking to develop a high-performance system. This chapter introduced you to the design and implementation of a shard library that gives you the necessary building blocks to experiment with a flexible and scalable architecture.
You saw how to use caching in a data access layer and how parallel processing of SQL statements can increase performance of your applications. You also explored more advanced topics, such as referential integrity and exception management. This chapter provides you with the necessary background to create your own shard and create high-performing applications against SQL Azure databases.