
CHAPTER 7
Genetic Algorithms
7.1 Introduction
Computer simulations of evolution started in the mid-1950s, when a Norwegian-Italian mathematician, Nils Aall Barricelli (1912–1993), who had been working at the Institute for Advanced Study in Princeton, published his first paper on the subject. This was followed by a series of works that were published in the 1960s–1970s.
Genetic algorithms (GAs) became especially popular through the work of John Holland (see Box) in the early 1970s, and particularly because of his book Adaptation in Natural and Artificial Systems (1975).

Holland wrote: “A Genetic Algorithm is a method of problem analysis based on Darwin's theory of natural selection. It starts with an initial population of individual nodes, each with randomly generated characteristics. Each is evaluated by some method to see which ones are more successful. These successful ones are then merged into one ‘child’ that has a combination of traits of the parents' characteristics.”
In recent years, many studies on reliability optimization use a universal optimization approach based on metaheuristics. Genetic algorithms are considered as a particular class of evolutionary algorithms that use techniques inspired by Darwin's evolution theory in biology and include such components as inheritance, mutation, selection, and crossover (recombination).
These metaheuristics hardly depend on the specific nature of the problem that is being solved and, therefore, can be easily applied to solve a wide range of optimization problems. The metaheuristics are based on artificial reasoning rather than on classical mathematical programming. An important advantage of these methods is that they do not require any prior information and are based on collection of current data obtained during the randomized search process. These data are substantially used for directing the search.
Genetic algorithms are implemented as a computer simulation in which a population of abstract items (called “chromosomes” or “the genotype of the genome”) represent “candidate solutions” (called individuals, creatures, or phenotypes) systematically lead toward better solutions.
GAs have the following advantages in comparison with traditional methods:
A GA requires strong definition of two things:
The fitness function is defined over the genetic representation and measures the quality of the presented solution. The fitness function always depends on the problem's nature. In some problems, it is impossible to define the fitness expression, so one needs to use interactive procedures based on expert's opinion.
As soon as we have the genetic representation and the properly defined fitness function, a GA proceeds to initialize a population of solutions randomly.
A genetic algorithm includes the following main phases.
7.1.1 Initialization
A number of individual solutions are generated at random to form an initial population. The population size depends on the nature of the problem, but typically contains hundreds or thousands of possible solutions. The population is generated to be able to cover the entire range of possible solutions (the search space). Occasionally, some solutions may be “seeded” in areas where actual optimal solution is located.
This initial population of solutions is undertaken to improve the procedure through repetitive application of selection, reproduction, mutation, and crossover operators.
7.1.2 Selection
Obtained individual solutions are selected through a special process using a fitness function that allows ordering the solutions by specified quality measure. These selection methods rate the fitness of each solution and preferentially select the best solutions.
7.1.3 Reproduction
The next step is generating the next generation of solutions from those selected through genetic operators: crossover (recombination) and mutation.
Each new solution is produced by a pair of “parent” solutions selected for “breeding.” By producing a “child” solution using the above methods of crossover and mutation, a new solution is created that typically shares many of the characteristics of its “parents.” New parents are selected for each child, and the process continues until a new population of solutions of appropriate size is generated.
7.1.4 Termination
The reproduction process is repeated until a termination condition has been reached. Common terminating conditions are:
7.2 Structure of Steady-State Genetic Algorithms
The steady-state GA (see Fig. 7.1) proceeds as follows: an initial population of solutions is generated randomly or heuristically.1 Within this population, new solutions are obtained during the genetic cycle by using the crossover operator. This operator produces an offspring from a randomly selected pair of parent solutions that are selected with a probability proportional to their relative fitness. The newly obtained offspring undergoes mutation with the probability pmut.
FIGURE 7.1 Structure of a steady-state GA.
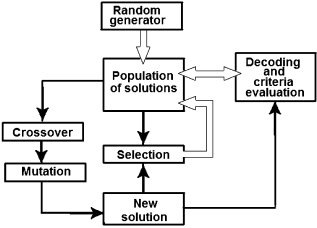
Each new solution is decoded and its fitness function value is estimated. These values are used for a selection procedure that determines what is better: the newly obtained solution or the worst solution in the population. The better solution joins the population, while the current one is discarded. If the solution population contains a pair of equivalent items, then either of them is eliminated and the population size decreases.
The stopping rule is when the number of new solutions reaches some level Nrep, or when the number of remaining solutions in the population after excluding reaches a specified level. After this, the new genetic cycle begins: a new population of randomly constructed solutions are generated and the process continues. The whole optimization process terminates when its specified termination condition is satisfied. This condition can be specified in the same way as in a generational GA.
The steady-state GA can be presented in the following pseudo-code format.
begin STEADY STATE GA
Initialize population П
Evaluate population П {compute fitness values}
while GA termination criterion is not satisfied do
{GENETIC CYCLE}
while genetic cycle termination criterion is not satisfied do
Select at random Parent Solutions S1, S2 from П
Crossover: (S1, S2) → SO {offspring}
Mutate offspring SO → S*O with probability pmut
Evaluate S*O
Replace SW {the worst solution in П with S*O } if S*O is
better than SW
Eliminate identical solutions in П
end while
Replenish П with new randomly generated solutions
end while
end GA7.3 Related Techniques
Here is a list (in alphabetic order) of a number of techniques “genetically” close to genetic algorithm.2
Notes
1 Material for this section is presented by G. Levitin.
2 This section is based partly on http://en.wikipedia.org/wiki/Genetic_algorithm.
Chronological Bibliography
Coit, D. W., and Smith, A. E. 1966. “Reliability optimization of series-parallel systems using a genetic algorithm.” IEEE Transactions on Reliability, no. 45
Coit, D. W., Smith, A. E. and Tate, D. M. 1966. “Adaptive penalty methods for genetic optimization of constrained combinatorial problems.” INFORMS Journal of Computing, no. 8.
Kumar, A., Pathak, R., Gupta, and Parsaei, H. 1995. “A genetic algorithm for distributed system topology design.” Computers and Industrial Engineering, no 3.
Kumar, A., Pathak, R., and Gupta, Y. 1995. “Genetic algorithm-based reliability optimization for computer network expansion.” IEEE Transactions on Reliability, no. 1.
Painton, L., and Campbell, J. 1995. “Genetic algorithm in optimization of system reliability.” IEEE Transactions on Reliability, no. 2.
Coit, D. W., and Smith, A. E. 1996. “Penalty guided genetic search for reliability design optimization.” Computers and Industrial Engineering, no. 30.
Coit, D. W., and Smith, A. E. 1996. “Reliability optimization of series-parallel systems using genetic algorithm.” IEEE Transactions on Reliability, no. 2.
Coit, D. W., and Smith, A. E. 1996. “Solving the redundancy allocation problem using a combined neural network/genetic algorithm approach.” Computers and OR, no. 6.
Dengiz, B., Altiparmak, F., and Smith, A. 1997. “Efficient optimization of all-terminal reliable networks using an evolutionary approach.” IEEE Transactions on Reliability, vol. 46, no. 1.
Dengiz, B., Altiparmak, F., and Smith, A. 1997. “Local search genetic algorithm for optimal design of reliable networks.” IEEE Transactions on Evolutionary Computation, no. 3.
Gen, M., and Cheng, R. 1997. Genetic Algorithms and Engineering Design. John Wiley & Sons.
Gen, M., and Kim, J. 1997. “GA-based reliability design: state-of-the-art survey.” Computers and Industrial Engineering, no 1/2.
Ramachandran, V., Sivakumar, V., and Sathiyanarayanan, K. 1997. “Genetics based redundancy optimization.” Microelectronics and Reliability, no 4.
Shelokar, P. S., Jayaraman, V. K., and Kulkarni, B. D. 1997. “Ant algorithm for single and multi-objective reliability optimization problems.” Quality and Reliability Engineering International, no. 6
Coit, D. W., and Smith, A.E. 1998. “Redundancy allocation to maximize a lower percentile of the system time-to-failure distribution.” IEEE Transactions on Reliability, no. 1.
Hsieh, Y., Chen, T., and Bricker, D. 1998. “Genetic algorithms for reliability design problems.” Microelectronics and Reliability, no. 10.
Taguchi, T., Yokota, T., and Gen, M. 1998. “Reliability optimal design problem with interval coefficients using hybrid genetic algorithms.” Computers and Industrial Engineering, no. 1/2.
Yang, J., Hwang, M., Sung, T., and Jin, Y. 1999. “Application of genetic algorithm for reliability allocation in nuclear power plant.” Reliability Engineering and System Safety, no. 3.
Levitin, G., Kalyuzhny, A., Shenkman, A., and Chertkov, M. 2000. “Optimal capacitor allocation in distribution systems using a genetic algorithm and a fast energy loss computation technique.” IEEE Transactions on Power Delivery, no. 2.
Levitin G., Dai,Y., Xie, M., and Poh, K. L. 2003. “Optimizing survivability of multi-state systems with multi-level protection by multi-processor genetic algorithm.” Reliability Engineering and System Safety, no. 2.
Liang, Y., and Smith, A. 2004. “An ant colony optimization algorithm for the redundancy allocation problem.” IEEE Transactions on Reliability, no. 3.
Coit, D.W., and Baheranwala, F. 2005. “Solution of stochastic multi-objective system reliability design problems using genetic algorithms.” In Advances in Safety and Reliability, K. Kolowrocki, ed. Taylor & Francis Group.
Levitin, G. 2005. “Genetic algorithms in reliability engineering.” Reliability Engineering and System Safety, no. 2.
Marseguerra, M., Zio, E., and Podofillini, L. 2005. “Multi-objective spare part allocation by means of genetic algorithms and Monte Carlo simulation.” Reliability Engineering and System Safety, no. 87.
Gupta, R., and Agarwal, M. 2006. “Penalty guided genetic search for redundancy optimization in multi-state series-parallel power system.” Journal of Combinatorial Optimization, no. 3.
Levitin, G., ed. 2006. Computational Intelligence in Reliability Engineering: Evolutionary Techniques in Reliability Analysis and Optimization. Series: Studies in Computational Intelligence, vol. 39. Springer-Verlag.
Levitin, G., ed. 2006. Computational Intelligence in Reliability Engineering: New Metaheuristics, Neural and Fuzzy Techniques in Reliability. Series: Studies in Computational Intelligence, vol. 40. Springer-Verlag.
Levitin, G. 2006. “Genetic algorithms in reliability engineering.” Reliability Engineering and System Safety, vol. 91, no. 9.
Konak, A., Coit, D., and Smith, A. 2006. “Multi-objective optimization using genetic algorithms: a tutorial.” Reliability Engineering and System Safety, vol. 91, no. 9.
Parkinson, D. 2006. “Robust design employing a genetic algorithm.” Quality and Reliability Engineering International, no. 3.
Taboada, H. A., Espiritu, J. F., and Coit, D. W. 2008. “A multi-objective multi-state genetic algorithm for system reliability optimization design problems.” IEEE Transactions on Reliability, no. 1.