
11
Routing in Wireless Sensor Networks
11.1 Basics of Wireless Sensor Networks
Wireless sensor networks (WSNs) are being adopted in various applications that require deployment for continuous operations in inhospitable terrains, constrained space, or challenging environments. The features that make the WSN the preferred choice for such applications are its low cost, ad hoc deployment, rapid installation, low power consumption, ease of use, distributed operation, and small sensor size [1]. The number of devices deployed in a typical WSN for any particular application may vary from a few hundred to thousands. The advancements in wireless technology have been a boon for advancement in the field of sensor networks. The mesh of wires required to connect a few thousand devices, if not operational in wireless but in wired mode of communication, can well be imagined in terms of deployment time, space requirement, number of interconnections, essentiality of manual deployment, and finally the inability to conceal operation. Advancements in the area of application‐specific integrated circuits (ASICs), microelectromechanical systems (MEMSs), and nanotechnology has led to the design of compact and energy‐efficient sensor devices. The research in the area of battery technology is also at a pace to catch up with the advancement in computing technology and miniaturization of devices, and this has led to prolonged life of WSN devices. The algorithms being used for WSNs are getting optimized, power aware, distributed, and secured, enhancing the performance of WSNs from the available underlying device hardware.
The size and deployment pattern of nodes of the WSN lead to typical characteristics of resource constraint, limited processing capability, limited power availability, and limited view of its environment. This calls for distributed sensing, coordinated processing, and routing of information to achieve its goal over an unreliable network, as well as to prolong the lifetime of the WSN. Depending on the criticality of the network, one of the requirements – such as power saving, QoS, performance, bandwidth, reliability, or security – may get preference over others. With the use of proper routing protocols, the life of a WSN can be extended much beyond the life of any of its individual nodes by putting the nodes in sleep mode when not in use and activating a single node at a time in a particular coverage area with multiple node deployment. Effective bandwidth as well as data redundancy can also be increased by using multiple paths.
The characteristics of a WSN generally necessitate deployment of a number of sensor nodes to monitor an object, environment, or event. This is due to the fact that the range of event detection and message transmission of the nodes is limited and requires a collaborative effort to forward information. Being tiny and power constrained, all the nodes may not be operational at all times, which adds to the unreliability of a single node. The terrain of deployment may not permit line‐of‐sight communication between far‐off nodes. The dense deployment of nodes not only leads to robustness and fault tolerance but also gives highly accurate information about the geographic point of action, also known as localization. The nodes may be uniformly deployed over an area or randomly spread.
The applications of WSNs are varied, and some of the common areas where these are being used include healthcare and patient monitoring, industrial applications and plant safety, structural monitoring and catastrophe warning, environmental and wildlife monitoring, traffic regulation and vehicle monitoring, manufacturing and inventory tracking, and smart and automated home appliances. The variety of defense applications is huge, and the deployments, applications, spread, and topology are unknown, as WSNs provides a high degree of concealment. It is also possible to deploy sensors inside concrete structures, under the skin of animals, or inside medical implants, which opens up another area for sensor network applications.
In defense parlance and a few other specific fields of application, the size of the sensor may typically not be of the order of a few millimeters or centimeters – surveillance aircraft, submarines, autonomous underwater or surface vehicles, UAVs, aerostats, or communication and detection systems such as radars are also referred to as sensors. The evolution of sensor networks can be traced to the era of the Cold War, when the USA deployed a network of interconnected radars for aerial surveillance and acoustic sensors in the seabed to detect Soviet submarines. These sensors had wired deployment, relieving them from the bandwidth and power constraints faced by wireless sensors. DARPA started the distributed sensor network program in the 1980s to interconnect for collaborative activity low‐cost independent sensing nodes spread over an area. Under this project, the Massachusetts Institute of Technology (MIT) realized a sensor network for tracking aircraft. It was based on acoustic sensors that captured and analyzed the sound of aircraft, processed it, and transmitted the data using microwave radio. Subsequent research in this area led to low‐cost, energy‐efficient, and miniaturized hardware. In the present day, a typical sensor node consumes about 10 μW power and has a life of about 10 years.
A sensing and communicating device connected to a wireless sensor network is generally referred to as a ‘node’. There might also be devices in the WSN that do not have sensing capability but participate only in the routing. The area where the sensor nodes are deployed is known as the ‘sensor field’. The wireless sensor network consists of a number of sensor nodes that may be connected to a gateway or a sink node. The gateway or the sink node is generally assumed to have sufficient computational capability, memory, and power. This gateway sensor node receives data from all the nodes, stores it, and processes the data to derive a decision about an event from the sensed data. The sink or the gateway is also commonly referred to as an ‘aggregation point’. The sink node is connected to the Internet or to any other reliable wired network. The connectivity between the sink node and the wired network can either be wired or through a high‐bandwidth reliable wireless link. There may be more than one gateway or sink node in a wireless sensor network.
11.1.1 Hardware Architecture of Sensor Node
The major components of a sensor node are the sensing system, processing unit, communication system, power supply, and optionally an actuator. The architecture of a typical wireless sensor node is depicted in Figure 11.1.

Figure 11.1 Block diagram of a typical wireless sensor node.
The sensing system gives the input to the sensor nodes in terms of parameters sensed from the external environment. The sensors may vary in size, the sensing technology used, and the parameters being sensed. The sensor can be for the detection of sound, temperature, weight, vibration, humidity, motion, chemical contents, biological agents, explosive vapors, electromagnetic signals, or any other parameter for which the WSN has been deployed. The sensors may be continuously ON, detecting the environment, or may be activated at regular time intervals.
The processing unit comprises the microprocessor and memory. It has interfaces to connect to the sensing system, communication system, power source, and actuators. An analog‐to‐digital converter may be used between the processing unit and the sensing system if the output of the sensing system is in analog form. The processor unit runs an operating system and the routing algorithm. A real‐time operating system configured for a given application is generally deployed in the sensor nodes. A few examples of operating systems used in sensor networks are TinyOS, MANTIS OS, and Smart Card OS. The processing system controls the communication system as well as the sensors and actuators for power saving and maintaining electromagnetic silence. Depending on the application, the processing unit may have a GPS attached to it. The entire processing unit is designed as a system on chip (SoC).
The communication system comprises a short‐range radio receiver and transmitter. There may be nodes without receivers but only transmitters to support one‐way communication. The transmitter has various modes of operation, namely active, idle, or sleep. The wireless radio circuits may be proprietary or standard based. The standard‐based radios help in interoperability. Although 802.11.x has a high data transfer rate and transmission range, it is not suitable for use in WSNs owing to the high power requirements. Bluetooth, IEEE 802.15.4, Zigbee, and IEEE 1451.5 are the preferred interfaces for communication in WSNs.
The power source should essentially feed energy to the processing unit and communication system. The power requirement of the sensing system varies with the design and technology used in the sensor. While electronic sensors essentially require power, the mechanical sensors may work without power. The power requirement of the radio can be controlled not only by switching off the radio at frequent intervals but also by a number of other power‐saving strategies. Some of the strategies that can reduce the power consumption of radios are data compression to reduce the amount of transmitted data, activation of radio only on event detection, reduction in packet overhead, avoidance of collisions and retransmission, optimization of the time interval for exchange of control signals, and lowering of the frequency of data transmission.
11.1.2 Network Topology
Although there are a number of available topologies for wireless networks, radio networks, or ad hoc networks, the topologies for a WSN [2] are very limited and are as follows:
- Star network. This can be viewed as a point‐to‐multipoint communication, where a number of nodes can send or receive data from a single node, which may be termed the coordinator, base station, leader node, or central node. The nodes communicating with the coordinator cannot communicate directly among themselves. The advantages of such a topology are the simplicity of the architecture, the avoidance of duplicate data packets, the reduction in processing at the nodes, the reduction in flow of data, lower latency, and power saving. The disadvantages of the topology are that there is a single point of failure, the power of the coordinator is depleted faster than other nodes, and all other nodes must be in the reception range of the coordinator node. This type of topology is used in hierarchical routing.
- Mesh network. In a mesh topology, any node of the WSN can communicate with any other node in its range. Flat routing uses this topology, as it supports multihop communication. Participation from all intermediate nodes helps in passing the data packet from one node to another and enables the packet to reach the destination, which may be out of communication range of the source. The topology has no single point of failure and can have multiple data paths, leading to redundancy. Any number of new nodes can be added to the network as the topology is highly scalable. The spread of the network can also be huge, limited by the distance between the two extreme nodes under the condition that there are intermediate nodes between these extreme nodes to participate in multihop routing. The disadvantage of the network is that there are duplicate data packets flowing in the network, leading to congestion. As there are a number of hops between the source and destination, the latency for message delivery increases. A node has to check every data packet it receives so as to forward it to other nodes as well as to avoid forwarding duplicate packets. This requires all the nodes to keep the radio on and process the data packets. Both these activities consume battery. As all the nodes are active and operating at the same pace, the power of all the nodes is consumed almost at the same pace. All the nodes fail almost at the same time, which first partitions the network and thereafter makes the complete network fail.
- Hybrid network. Topology that is a hybrid of the star network and the mesh network takes the advantages from both to provide an underlying design for a robust and energy‐efficient routing. The power‐constrained nodes communicate only with their coordinators, forming a star topology, while the coordinators can communicate with each other in a mesh pattern. Thus, the data packet from a low‐power node reaches the coordinator in a single hop over star topology and thereafter reaches its destination using multihops across various coordinators in a mesh topology. Cluster‐based routing generally relies on this topology.
Figures 11.2 to 11.4 present typical star, mesh, and hybrid network topologies in a WSN.

Figure 11.2 Star network topology in a WSN.


Figure 11.4 Hybrid network topology in a WSN.
11.1.3 Design Factors
The designs, applications, and devices used in a WSN are varied. Still, the design factors that are considered equally important across all types of WSN are almost the same because all WSNs have similar constraints and similar underlying technologies. The major design factors in a WSN [3] are as follows:
- Reliability. Some of the factors that lead to failed nodes or dropped packets are deployment in a harsh environment, heavy interference due to high node density as well as noise, frequently being out of transmission range, and energy depletion. The routing protocol should be reliable enough to handle such failures.
- Scalability. The number of nodes deployed in a WSN may vary according to the application, coverage area, and redundancy. The routing protocol should be able to support a few hundred nodes to a few million nodes. New nodes may be added when the WSN is already operational, and the routing protocol should be able seamlessly to integrate the new nodes. The protocol should also be able to handle situations of nodes going to sleep and coming back to active state after sleep.
- Hardware cost. As the WSN nodes are one‐off deployed in their thousands without being collected back, the hardware cost per node should be very low.
- Hardware design. A sensor node comprises a processing unit, a sensing unit, a power source, and a communication system. It might also optionally have actuators, a positioning system, and a mobilizer to support node movement. All these systems should be fitted in a small space, preferably on a single chip.
- Network topology. The WSN protocol should be able to discover the topology at the time of deployment and support topological changes post‐deployment. At the time of deployment, the nodes may be introduced in the network one at a time, allowing the WSN to keep discovering each newly introduced node and its nearest neighbors. Alternatively, all the nodes might be deployed en masse by spraying, aerial dropping, or exploding a container of sensors in proximity to the site. In such a scenario, all the nodes start discovering their neighbors simultaneously, leading to the formation of a WSN. Post‐deployment, the nodes may be mobile all by themselves, or their motion can be dictated by the environment. This leads to topological changes, which the WSN should be capable to handle. Topological changes may also occur owing to deployment of additional nodes or nodes becoming inactive.
- Operating environment. The nodes can be deployed in extreme and varied environments. The extremity of the environment can be in terms of height, temperature, pressure, humidity, wind speed, or electromagnetic interference. They can be deployed on land, on the seabed, floating in the sea, and even in space. The deployment environment can be a home, office, hospital, industry, forest, or battlefield. Thus, the WSN should be designed to cater for such controlled as well as harsh operating environments.
- Mode of communication. The nodes in a WSN communicate with each other using wireless transmission. The wireless transmission can be on radio frequency, infrared, electromagnetic, or light waves at any frequency. Use of optical media is also being explored. The transmission media in use should preferably not be proprietary, to enable interoperability and global operations.
- Energy requirements. The nodes have a non‐replaceable, non‐chargeable, and limited power battery. This should be used judiciously to power all the components of the node to participate in sensing, processing, and communicating. The life of the node depends on its own power requirements and consumption pattern. The nodes consume energy not only in sensing their own environment and in processing and forwarding their data but also in rerouting data for other nodes. It may be preferable for the energy of all the nodes in the WSN not to be depleted almost at the same time, but only a few nodes keep failing with time owing to energy depletion. This will lead to graceful degradation in the performance of the WSN, but at the same time enhance the life of the WSN by rerouting the packets through paths across available nodes.
11.1.4 Classification of Routing Protocol
The routing protocols may be classified on the basis of various parameters [3‐5]. Based on the network topology in which the WSN routing takes place, the routing protocol can be classified as flat, hierarchical, location based, or direct. On the basis of the time when the path is determined between the source and destination, i.e. prior to the need to route the packet or after the need arises to route between the pair, the routing protocols are classified as proactive, reactive, or hybrid. For determination of the route between the source–destination pair, the communication can be initiated either from the source or the destination, leading to these two categories based on the initiator of communication. On the basis of protocol operation, the routing has been classified into negotiation‐based routing, multipath routing, query‐based routing, QoS‐based routing, and coherent routing.
In proactive WSN routing protocols, the routes between all source–destination pairs are computed even before any particular route is required to be discovered for actual transmission of a data packet. Any change in the network topology is also incorporated to keep the routing table updated, even if no data packet might be routed through these changed routes. As a WSN generally has thousands of sensor nodes, discovering such a huge number of routes and storing them in the memory of each sensor node is not feasible, and hence proactive routing protocols are generally not suitable for WSNs. In reactive routing protocols, the routes are discovered on a requirement basis from the source to the destination whenever a packet reaches an intermediate node for transmission. Hybrid routing protocols are a combination of reactive and proactive routing whereby the routes to neighbors or other nearby nodes may be known proactively and the complete end‐to‐end path is discovered reactively.
The communication in a WSN can be initiated by the source or the destination. A source initiates communication when it wants to transmit data to the sink, gateway, or any other destination about an interesting event or some other data. The source may initiate the communication at regular time intervals, at predefined times, or only on detection of some event of interest or on measuring a parameter above the threshold level. The communications that are originated by the destination are generally query driven. When the sink node or any other destination wants some information from the source, it sends a request/query to a node for data. The source‐initiated communication is generally a one‐lap communication from source to destination, while the destination‐initiated communication is a two‐lap communication in the form of a query from destination to source and the data as a reply from the source to the destination.
The network topology of a WSN can be hierarchical (star) or flat (mesh). In a flat structure, all the nodes are equivalent and any node can communicate with any other node, while in the hierarchical structure there are a few special nodes known as coordinators or cluster heads, and the other normal nodes can communicate only with their coordinators and not with each other. These two network structures lead to two different classes of routing protocols – flat and hierarchical. In a hierarchical routing protocol, the nodes are separated into zones called clusters, and there is a cluster head in each zone. The nodes in a cluster can communicate only with their cluster head and not with the other nodes in the same or different clusters. In a flat routing protocol, generally multihop routing is in practice, where any node can communicate with any other node in the WSN.
Two other routing protocols that are also based on network topology are direct routing and location‐based routing. In direct routing, the source should be able to send the data packet directly to the destination, i.e. the source and destination should be connected over a single hop. In a typical WSN implementation, this indicates that all the sensor nodes are a single hop distance away from the sink, which generally is a rare architecture and may be in use only in some specific applications. In location‐based routing, each node is aware of its location. The location can be in terms of a common frame of reference for the entire WSN, the relative position to each other, or based on a GPS fitted with each node. The broad classification of the routing protocols in a WSN is indicated in Figure 11.5.

Figure 11.5 Classification of WSN routing protocols.
11.2 Routing Challenges in Wireless Sensor Networks
Although a WSN appears to be very similar to a wireless ad hoc network in its characteristics and working paradigm, it greatly differs from a wireless ad hoc network. Some of the major differences [3, 6] between a wireless sensor network and a wireless ad hoc network are depicted in Table 11.1.
Table 11.1 Difference between a wireless ad hoc network and a wireless sensor network.
| Characteristic | Wireless ad hoc network | Wireless sensor network |
| Number of nodes in the network | It varies from a few nodes to a few hundred nodes | It varies from a few hundred nodes to thousands of nodes |
| Transmission standard | Wireless LAN (802.11.x), Bluetooth | Bluetooth, 802.15.4, ZigBee, Wireless HART, ISA SP100 |
| Devices involved | Laptops, notebooks, palmtops, cellular phones, smart phones, etc. | Sensor nodes, motes, etc. |
| Density of deployed nodes | Low | High |
| Rate of failure of nodes | Low | High |
| Retractable (taking back) nodes | Possible | Not possible/not economical |
| Change/recharge battery | Possible | Not possible/not economical |
| Frequency of topology change | Low, of the order of minutes | High (owing to node failures, addition of nodes, nodes going into sleep mode or coming into active mode from sleep mode), of the order of milliseconds to seconds |
| Resource (bandwidth, memory, processing, power) limitation | Less constrained | Constrained |
| Transmission | Point‐to‐point or broadcast | Broadcast |
| Unique node identification | Yes. Generally through the IP address | In deployments with a large number, global unique identification may not be possible |
The node of a WSN is not generally deployed manually or preplanned. This leads to a random distribution of nodes over an area. Once deployed, the nodes cannot be upgraded or configured from outside. All this further adds to the pre‐existing challenges of wireless communication. The major constraints challenging the development of a robust, optimized, and common routing protocol for a WSN are as follows:
- Deployment pattern. The sensor nodes are randomly deployed with no predefined layout. The separation between the nodes has wide variations. The deployment of nodes by aerial dropping is a common scenario in the field of WSN. This not only requires the nodes to be environmentally hardened but also requires the routing algorithms to support a wide variety of network topologies.
- Autoconfiguration. The WSN nodes, once deployed, have to be self‐configurable as there is no external configuration mechanism available individually to configure each node by intimating about the neighboring nodes, routing pattern, and path to be selected. The routing algorithm should be robust and intelligent enough regularly to detect all the available nodes and create a network out of these available nodes for data communication.
- Mobility. Some of the nodes may be mobile by themselves, or the location of the nodes may keep changing owing to the mobility of the deployment environment or platform, such as sand dumes, wildlife, glaciers, cultivable land, or vehicles. The routing algorithm should support change in network topologies to cater for such scenarios.
- Energy constraint. Owing to deployment in inhospitable, unreachable terrains, the WSN nodes once deployed may not be retractable for repairs or change of battery. Intractability may also be due to their small size. Furthermore, the devices are so small and cheap that it may not be economical to retrieve them. Hence, the battery of a WSN node decides the life of the node. Radio transmission is an activity that consumes huge energy. This cannot be done away with in the WSN nodes, as radio transmission is generally the only way of communication in a typical WSN. Thus, the transmitter has to be used optimally so as to use it for the minimum possible time and range. The other parts of a sensor node that consume power are the onboard processing, the sensing activity, and the actuators, if any. Thus, the routing protocol has to be designed to use all the resources in the node to an optimum level of energy conservation.
11.2.1 Self‐Healing Networks
Wireless sensor networks are infrastructureless and comprise a huge number of nodes, which may be homogeneous or heterogeneous. This leads to an increase in the probability of failure of nodes or links within the network as a result of malfunctioning, routing strategy, energy saving, misbehavior of a node, or an external attack. In order to ensure seamless operation of the wireless sensor network, it is imperative to have a scheme to detect and self‐heal such failures. With the advancement of technology, new areas and technologies such as nanotechnology, microelectromechanical systems (MEMSs), smart dust, and microsensors have evolved, which are highly complex systems with reduced physical dimensions. The complexity of the system increases its points of failure, and the size of the systems prohibits the recovery or repair of the system, leading to further strengthening of the requirement for healing capabilities of the sensor network.
A self‐healing network is able to detect by itself any failure in the network. The detection capability of the sensor network is further linked with the process of fault modeling and identification of the cause of the fault so as to decide on suitable intervention. For example, it should be able to detect whether a node has failed, a link has failed, a bidirectional link has become unidirectional (owing to failure of a particular receiver or transmitter), a node has gone into energy‐saving mode, or an attack has been launched on the network. Another advantage of fault modeling is that it helps in damage mitigation studies as well as degradation modeling in the case of failures. After detection of the cause of the failure, a self‐healing network is capable of launching a corrective action to bring the network or bring that particular portion of the network back into action. Generally, it is assumed that a network is self‐healing if it can autoconfigure itself to retain network connectivity and recover the point or zone of failure. However, self‐healing should actually ensure that, after the healing process, the network is equally reliable, with at least the same degree of connectivity and quality of service as in the network prior to the failure. This is to ensure that the recovered points are not the weakest links in the network. Certain systems ensure that the post‐healing strength is greater than the design strength.
The self‐healing of a network can be based on network realignment so that operational network components take over the load of the failed nodes and failed links. Alternatively, there can be redundant nodes, which can either move locally or throughout the network to replace the points of failure. There can also be reinforcement nodes, which act a priori on the basis of fault modeling. These nodes move to a network section detected with a high probability of failure and so reinforce that network section. Redundant nodes can be detected using sensor optimization, and these redundant nodes can be used as healing nodes. Sensor network health monitoring and damage algorithms can also be used to gain an insight into the extent of harm caused, its effects, and the remaining time for which the network can keep operating with graceful degradation.
Wireless sensor networks with memory about the shape of the deployed sensor network are a promising development in improving the damage resistance property of a sensor network in a highly turbulent deployment environment or in an area under surveillance of the sensor network and being attacked.
11.2.2 Security Threats
The nodes of the WSN transmit data omnidirectionally and in open medium, leading to an imminent security threat. Authentication, integrity, confidentiality, and availability are the major security concerns in WSNs as well. Denial of service (DoS) attack is the most common threat in a WSN, wherein an attacking node can place itself in the sensor field and create interference in the communication medium by continuously generating noise. If the attacking node is strategically placed in a dense part of the network, it can lead to disruption of multiple routes. The attack can be made more severe if this attacking node continuously sends request messages to the neighboring nodes. This would initiate a continuous conversation with the nodes and engage the communication channel as well as draining the power source of the neighboring nodes. Packet sniffing is an inherent characteristic of a wireless sensor network as the nodes generally accept all the packets, analyze them, process them, and retransmit the packets, leading to a major concern related to confidentiality.
Selfish nodes, inactive nodes, dumb nodes, and sleeping nodes add to the difficulty in distinguishing these nodes from a node planted by an adversary in the sensor field or any node of the WSN captured by an adversary. It is difficult to distinguish between the failure of a node as a result of malicious action and natural death due to hardware malfunction or power exhaustion. As the sensor nodes communicate in wireless mode, they are also prone to jamming, spoofing, tampering, and replaying. Some common attacks on a WSN are sybil attack, black hole attack, wormhole attack, and hello flood attack.
A wireless network in general, and a WSN in particular, is exposed to all the threats and attacks that a wired network faces. However, a WSN, being infrastructureless, cannot have specific security nodes performing the activities of a firewall, intrusion detection system, intrusion prevention system, information security gateway, and gateway encryptor device. Hence, the traditional intrusion detection and prevention techniques used in a wired network cannot be implemented in a WSN.
Secure routing protocols used in WSNs are Security Protocols for Sensor Network (SPINS), Authentication Confidentiality (AC), cluster‐based secure routing protocol, etc.
11.3 Flat Routing Protocols
In a flat routing protocol [7], all the sensor nodes are considered to be equivalent in terms of transmission and reception capabilities. Any node can communicate with any other node in the WSN, thus giving the name ‘flat’ to this category of protocols for the unstructured network topology where there are no hierarchies within nodes. The level and the amount of information possessed by all the nodes are similar. All the nodes are equally responsible for sensing the sensor field, processing data, forwarding and routing data, as well as ensuring the security of the network. As all the nodes are considered to be at an equal level, it is not necessary to have a unique identifier for each sensor node. Moreover, by doing away with a unique ID for each sensor node, the scalability of the WSN is also enhanced. Flat routing saves the resources and time involved in leader election, which is done in hierarchical routing. Most of the communication in flat routing is based on broadcast mode or by using wave propagation algorithms. In a flat‐routing‐based WSN, selective sensor nodes that lie in the path from the source to the sink are involved in forwarding the packet to the sink. The frequency of traffic flow and the traffic pattern dictate the power consumption across nodes.
One disadvantage of flat routing is the asymmetric energy consumption across nodes. The nodes participating in flat routing protocol communicate with the base station by direct communication or multihop communication. Depending on the distribution of the nodes with respect to the sink node and the location of the transmitting sensor node in the WSN, direct communication may be more efficient than multihop communication, or vice versa. Consider a WSN with nodes N1 to Nn (where n = 2 to 5), as shown in Figure 11.6. In a multihop communication, when Nn wants to send data to the sink, it will move over Nn − 1, …, N2, and N1. When Nn − 1 wants to send data to the sink, it will move over Nn − 2, …, N2, and N1, and so on. Thus, all the data intended for the sink will hop over N1, with maximum energy depletion of the sink’s nearest node. The distant nodes from the sink have minimum energy depletion. Alternatively, if the nodes were involved in direct communication with the sink, the node farthest from the sink would have to use the highest‐strength signal, while the nodes nearer to the sink would use the minimum‐strength signal. This would lead to minimum energy depletion in the nearby nodes and to maximum energy depletion in the farthest nodes.

Figure 11.6 Multihop transmission in an indicative WSN.
The flat routing protocols vary from very simple techniques such as flooding and gossiping to various application‐specific and resource optimization protocols, including energy‐aware routing. Some of the commonly used flat routing protocols and their brief description are as follows:
- Flooding. Flooding is the simplest routing protocol and needs neither topological information nor a routing algorithm. It can easily accommodate mobility, topological changes, and scalability. However, with increase in the number of nodes, the number of packets, including the redundant packets, increases manifold in the network. In flooding, as indicated in Figure 11.7, a sensor that receives a packet broadcasts the packet to all its neighbors. Thereafter, all the neighbors that receive this packet broadcast it further, and the process continues. Only a node that has already transmitted the packet does not broadcast it again when it receives the same packet from its neighbor’s broadcast. The process continues until the packet reaches the destination or has completed the predefined number of hops [8]. The disadvantages of the flooding technique are as follows:
- It leads to ‘data implosion’, as a sensor receives the same packet from a number of its neighbors.
- An interesting event might be covered by two or more sensors, as indicated in Figure 11.8 and all these might transmit the same data to their neighbors. Thus, two or more sensor nodes might sense a region independently, but send the same sensed data from the ‘overlap’ region to a common intermediate node.
- The technique does not try to optimize resource utilization in terms of processing, power, and buffer memory. This is termed ‘resource blindness’.
- Gossiping. This is an optimized version of flooding to reduce data implosion, whereby each sensor node sends the packet to one or a selected few neighbors instead of to all its neighbors. The neighbors receiving the data packet send it further, again only to one or a selected few of its neighbors. The process continues until the data packet reaches the destination or exceeds the maximum number of hops. This type of routing may lead to propagation delay, as the selected sensor nodes in the neighbor may not be in the optimum path.
- Direct diffusion. This is a destination‐initiated reactive routing protocol and operates in three stages: diffusion of interest, gradient setup, and data delivery along a reinforced path [9].

Figure 11.7 Data implosion during flooding.

Figure 11.8 Interesting event covered by two sensors in the overlap region and flooded through the neighbors by both sensors.
During diffusion of interest, depicted in Figure 11.9 (a), the sink node floods the query in the WSN. The query contains the attribute the sink is interested in, the particular value or a range of values that the sink desires to receive, and the frequency at which it intends to receive the sensor data. The geographical region of interest may also be transmitted. For example, the sink of a battlefield sensor network may send a query that it is interested in weight data and the value should be more than 50 000 kg (to enable it to detect a tank or launchers). This keeps the sink away from receiving data from all those sensor nodes that are not sensing the attribute of interest and even those sensors measuring the attribute of interest but that are presently not sensing data within the range of interest. The frequency of transmission requested at this stage is generally low, to prevent flooding of the network by the eligible sensing nodes. All the nodes maintain an ‘interest cache’, where they record the attributes of interest, as they might have to participate in the multihop routing of the data from the qualifying sensors to the sink, and during that stage will use this attribute in their interest cache for data aggregation.

Figure 11.9 (a) Diffusion of interest from the sink node in the WSN.
In the gradient setup stage, shown in Figure 11.9 (b), the qualifying sensors start sending the values of the attributes of interest (which are in the specified range) at specified intervals by flooding their neighbors with the data of interest. All the intermediate nodes that receive this data of interest perform data aggregation by checking whether the received data matches the entries in the ‘interest cache’ of the sensor nodes. If the data exists in the ‘interest cache’, it is flooded to neighbors and an entry is made in ‘data cache’. If the same data is received again, the data cache is used to verify that it has already been forwarded and hence the packet is dropped. When the data packet reaches the sink, the sink may decide to search for more paths from certain nodes. It sends another query for the same attribute of interest and range for one or more specific destination nodes. This initiates the generation of paths to the sink from these nodes also.

Figure 11.9 (b) Gradient setup from source node to sink node.
In the final stage, as shown in Figure 11.9 (c), the qualified sensors start sending data at the specified rate towards the sink using the discovered paths. Once the path is established, the sink may resend the original query to the destination with a change in the frequency at which it intends to receive the sensor data. The frequency is generally increased so as to receive the data of interest more frequently.

Figure 11.9 (c) Data delivery from source to sink through the discovered path.
The protocol supports topological changes and path repairs by selecting from the other paths that have sent data at a slower rate from the sensor to the sink in the gradient setup stage. It also does not require an addressing scheme or unique identifier for each node, as the communication process is neighbor to neighbor. The disadvantage of this routing is that there is flooding of data, which has associated resource utilization during the first two stages – diffusion of interest and gradient setup. The memory requirement is also high for each sensor, as it has to maintain an ‘interest cache’ and a ‘data cache’.
Rumor routing. A diffused routing has a major overhead if there are a very few sensors sensing data of interest. Rumor routing [10] is a variation of diffused routing where the data query is not sent across the entire network but to specific sensor nodes that have indicated that they have captured the event of interest. When a sensor node detects an event of interest, it adds it to its event table and creates a packet called an ‘agent’, which contains the event table and floods it in the network with certain hops‐to‐live. All the nodes receiving the agent use the event table being carried by the agent to update the sensor nodes’ own event table. New events can be added in the event table of the agent, and it is propagated to the nodes. The agent also maintains a list of visited nodes so as to ensure visiting a new node on every hop and reduces its hop‐to‐live count by 1. When a sink is interested in an event, it sends a request in a random path until it reaches a node that has information about the sensor node that has recorded the event of interest and the path to that sensor node.
The disadvantage of the protocol is that the size of the agent may become large, as it maintains the event table as well as the list of visited nodes. As the agent gives only one route to the sensor that has recorded the event of interest, a request from the sink to the sensor for data at frequent intervals may deplete the energy of the nodes in the path.
Gradient‐based routing. This is a destination‐initiated routing protocol, a variation of directed diffusion, where the distance in terms of hop count to the node capturing the event of interest is used as a gradient [11]. The minimum number of hops between any node and sink is termed the height of the node here. When a node has more than one neighbor at the same height, one of the neighbors is selected randomly. The protocol has an energy‐saving scheme incorporated in it, where any node with decreasing energy levels can increase its height parameter, thereby refraining its neighbors from forwarding packets through it.
Sensor Protocol for Information via Negotiation (SPIN). The protocol uses data descriptors or metadata to send information about the data to neighbors before sending the actual data to the sensor nodes interested in it. Those neighbors that do not have the data will be interested in it, and hence, on receiving metadata related to unreceived data from a neighbor, the sensor node sends a request for the actual data. On receiving the request, the actual data is sent to the interested node by the sensor node that had initially sent the metadata. This does away with the requirement of data aggregation and sensing of events by overlapped sensors, and prevents flooding. The format of the data descriptor is application specific. The protocol has to use three types of message, each of which is used during the process, depicted in Figures 11.10 (a)–(c) respectively: (1) ‘advertisement’ of metadata, (2) a ‘request’ message for actual data, and (3) transmission of actual ‘data’. However, SPIN does not guarantee delivery of data between any two nodes because, if the intermediate nodes are not interested in the data, the data cannot cross over the region of uninterested nodes and reach the destination that is interested in the data [12].
Figure 11.10 (a) SPIN – advertisement of metadata to all neighbors.

Figure 11.10 (b) SPIN – after checking of metadata, a request for actual data by nodes not having the data.

Figure 11.10 (c) SPIN – transmission of actual data to the interested nodes.
Some of the other flat routing protocols are as follows:
- energy‐aware routing [13],
- Constrained Anisotropic Diffusion Routing (CADR) [14],
- cougar approach [15],
- Active Query Forwarding in Sensor Networks (ACQUIRE) [16],
- Minimum‐Cost Forwarding Algorithm (MCFA) [17],
- Minimum‐Energy Communication Network (MECN) [18].
11.4 Hierarchical Routing Protocols
The hierarchical routing protocols preferably use faster and better sensor nodes as we move up in the hierarchy of the sensor nodes. These nodes may have higher power and better resources. Alternatively, if all the nodes in the WSN are of similar capabilities, the nodes that operate at higher levels of hierarchy are replaced regularly, and some other nodes are selected to perform the task of the cluster head or coordinator, as these roles demand more processing requirements and drain the power of the sensor node very rapidly. Hence, the responsibility is generally rotated across all the available nodes to avoid any particular node being exhausted of power.
Hierarchical routing keeps the flow of data packets restricted within the WSN by avoiding duplicate packets as well as broadcast of packets to all the nodes. Data broadcasts and communication between sensors are generally confined within small regions of the sensor field, and these regions are generally termed ‘clusters’. Only selective traffic moves up in the hierarchy. Data communication between two far‐off sensor nodes is through the nodes at a higher level of the hierarchy forming a high‐reliability and minimum‐congestion ‘backbone’ of communication in the WSN. In a hierarchical routing protocol, the role of sensing an event of interest is generally assumed to be performed by the sensors at the lowest level of the hierarchy, which can be the low‐energy, low‐processing‐capability, and reduced‐communication‐capability (only transmission is required) sensor devices. The nodes at the higher level perform the tasks of data processing, aggregation, and forwarding and are generally high‐energy nodes. This enhances the life of the WSN by saving energy requirements, and avoids resource blindness. The energy dissipation is very similar in all the nodes at the same hierarchical level, and the energy dissipation cannot be controlled on the basis of traffic pattern because all the nodes at the higher hierarchical levels have to exchange data even if a single sensor node forwards data of interest.
Cluster routing is the most common hierarchical routing in a WSN, with two layers of hierarchy. The WSN is divided into regions called clusters, comprising low‐end devices at the lower level, and each cluster can have one or more cluster heads at the upper level. The nodes in the cluster can communicate only with their cluster head, and the cluster heads can communicate with all other cluster heads in the WSN.
The major disadvantage of hierarchical routing is the resource overhead in selection of the cluster heads. Furthermore, there might be regions in the WSN where no data of interest is being generated, but still these regions have to utilize resources in creating and maintaining the cluster structure. This involves creating cluster heads and coordinating with sensor nodes in the cluster to inform them about the cluster heads or the discovery of cluster heads by the lowest‐level sensor nodes. Resources are also used by the sensors in deciding their association with any particular cluster and thereafter change of cluster owing to mobility, signal strengths, and QoS issues.
Routing is generally very simple in a hierarchical routing – the sensor node sends the data to the cluster head. In the case of a two‐level hierarchy, the cluster heads communicate with each other, similarly to a flat routing protocol. In the case of a multilevel hierarchy, the data moves up to the highest level in the hierarchy and then comes down in the hierarchy up to the destination node. Most of the hierarchical routing protocols therefore handle the following two problems in hierarchical routing:
- selection of a cluster head,
- selection of a cluster by a sensor node to get associated with.
Low‐Energy Adaptive Clustering Hierarchy (LEACH). In LEACH [19], the cluster head is selected randomly based on election. The nodes can send data only to their cluster head, and the cluster head in turn sends the data to the sink after processing and aggregating the data. Although the scheme reduces the power requirement of an individual sensor node, it enhances the power consumption of the cluster heads by a huge amount. As the cluster heads also do not have a fixed power source, the protocol rotates the role of the cluster head among the sensor nodes based on two factors – the energy left in the node and the number of times the node has performed the role of cluster head. A node elects itself as a cluster head based on random number selection between 0 and 1. If the selected number is below a threshold value, it elects itself as the cluster head. The threshold value is determined on the basis of an equation with the parameters: desired percentage of cluster heads, current round, and set of nodes that have not been cluster heads in certain previous rounds. One disadvantage of this technique of cluster head election is that the elected cluster heads may be concentrated in a certain region of the WSN instead of being equally distributed across the WSN.
The membership of a node in a cluster is based on the signal strength of the cluster head being received by the node. A node is a member of the cluster from which it receives the strongest cluster‐head signal strength. Proximity to the cluster head and signal‐to‐noise ratio may also be used as criteria for selection of cluster membership. The protocol operates in rounds, with a different cluster setup and cluster head in each round. The following are the operations in each round:
- A node elects itself as the cluster head with a certain probability and advertises its election.
- The other nodes select their clusters based on the received signal strength of the cluster head. The cluster head is informed about their membership.
- The cluster head manages transmission from the nodes in its cluster by using TDMA, where each node is informed about its slot so as to enable it to go into sleep mode while it does not have a transmission slot.
- A node sends data to the cluster head in its allocated time slot.
- Once the cluster head receives the data from all the nodes, it performs data processing and analysis and data aggregation and compression, and then sends it to the sink.
Collision between the nodes in a cluster is avoided by using TDMA, and contention between cluster heads for transmitting data to the sink is avoided by CDMA.
PEGASIS is a hierarchical routing protocol that works on ‘chaining’ [20] instead of clusters as in LEACH. It is more energy efficient than LEACH, as it saves on processing for cluster formation, election of cluster heads, and processing of data from all the sensors at the cluster head. PEGASIS forms a chain of sensor nodes, and one of the nodes from the chain is selected for transmission of processed data to the sink. As the data moves in the chain, it keeps being aggregated along with the data of the node that is forwarding it in the chain. A token passing technique is used in the chain to avoid collisions, as only the node possessing the token is capable of transmitting data in the chain. The working of the routing algorithm can be explained using the deployment example shown in the Figure 11.11. Nodes N1 to N5 are the sensor nodes in a small region within the sensor field. These nodes form a chain, and the data moves along the chain. Initially, node N1 has the token and sends the data to N2. N2 aggregates the data received from N1 along with its own data and sends it to N3. N3 passes on the token to N5, which on receiving the token sends its data to N4. Like N2, N4 also aggregates its data along with the data from N5 and sends it to N3. N3 aggregates the data received from N2 and N4 to the sink, which effectively is the aggregated data of the complete chain.

Figure 11.11 Creation of a chain in a WSN running PEGASIS.
The disadvantage of PEGASIS is that the central node in the chain, which sends the data to the sink, becomes the point of delay and energy consumption. Furthermore, as the size of the chain increases, the process of data aggregation and transmission is delayed, as it requires time for the data from the farthest link in the chain to move towards the center of the chain.
TEEN is based on clustering with three levels in the cluster hierarchy [21]. As depicted in Figure 11.12, the nodes transmit to the first‐level cluster heads. The first‐level cluster heads communicate with the second‐level cluster heads, and finally the second‐level cluster heads communicate with the sink. This is a reactive routing protocol that is used to detect sudden change in the value of the sensed parameter. The routing algorithm defines two parameters: the hard threshold and the soft threshold. The hard threshold is that level beyond which, if the data is sensed by the sensor, it should be transmitted to the sink. If the value has crossed the hard threshold, this does not mean that the data will now be continuously transmitted to the sink. It also does not now necessitate data transmission at regular intervals. The data will be transmitted again only when it is beyond the hard threshold and fluctuates beyond the soft threshold limits. Thus, the soft threshold further reduces the data transmission, and only interesting and significant changes in the values of the sensed parameters are sent to the sink. The protocol does not suit those applications that require regular transmission of sensed parameters to the sink.

Figure 11.12 A WSN running TEEN protocol.
While the working of a few hierarchal routing protocols have been explained to indicate the variations in techniques, topologies, and the parameters optimized in the routing, there exist a huge number of hierarchical routing protocols, of which just a few are listed below:
- Adaptive Threshold‐Sensitive Energy‐Efficient Sensor Network Protocol (APTEEN) [22],
- Sequential Assignment Routing (SAR),
- Sensor Protocol for Energy‐Aware Routing (SPEAR),
- Small Minimum Energy Communication Network (MECN),
- Self‐Organizing Protocol (SOP) [23],
- Virtual Grid Architecture Routing (VGA),
- Hierarchical PEGASIS [24],
- Energy‐Aware Routing [25],
- Hierarchy‐Based Anycast Routing (HAR) [26],
- Hierarchy Energy‐Aware Routing for Sensor Networks [27],
- Balanced Aggregation Tree Routing (BATR) [28].
11.5 Location‐Based Routing Protocols
Location‐based routing protocols are highly adaptive to the dynamic nature of sensor networks. The routing overheads are low compared with the other routing protocols as location‐based routing protocols use the information about the geographic location of the sensor nodes to forward the packets. The location of a sensor node in a network can either be indicated in terms of its geographic location with a global frame of reference by using a GPS or with a local frame of reference with respect to some local‐infrastructure‐based positioning system. Apart from these, the location of nodes can also be indicated with reference to each other. Location‐based routing can be used for packet delivery with two different kinds of requirement. Firstly, it can be used to move a packet towards the destination node by using the location information of the destination node and make the packet move nearer to the destination with each hop. The protocol can change the route of packet forwarding dynamically if the destination node moves to a different position while the packet is already on the move through the sensor network towards the destination node. Secondly, location‐based routing can be used to deliver a data packet to one or more of the sensor nodes that are available in the predesignated location for which the packet has been forwarded. This kind of packet forwarding is also known as geocasting.
Location‐based routing has a low memory demand from the sensor nodes. An elaborative routing table is not required to be maintained in the nodes, as only the location information about the neighbors will suffice for routing. Location‐aware routing can lead to a single path from the source to the destination or can be used to discover multiple paths, depending on the application scenario. Single‐path forwarding results in energy savings, while multiple paths can increase the reliability of packet delivery and can also support load distribution. In the case of multiple paths, avoiding a common node or link among the multiple paths will further enhance the reliability and load‐sharing capability.
The most common routing strategy used in location‐aware routing is the greedy approach, whereby a node forwards the packet to one or more of its neighbors that are nearer to the destination than the node itself. If only a single path has to be selected, the greedy approach leads to forwarding of the packet to the neighbor that is nearest to the destination in terms of distance. Such a single‐path greedy‐based approach may lead the packet to a dead end when it reaches a node, which might be very near to the destination but cannot reach the destination in a single hop and there are no intermediate nodes available between the node and the destination to carry the packet forward. In such scenarios, the packet has to be backtracked. Hence, the intermediate nodes should maintain a record of which packet has been forwarded to which node so as to avoid forwarding it to the same neighbor during backtracking after reaching a dead end. Another approach to recover from a dead end in a greedy approach is to use flooding, partial flooding, or directional flooding to forward the packet to neighboring nodes, after which the nodes receiving the packet initiate the greedy approach to forward the packet towards the destination. The greedy approach with location information will also ensure by itself that the route is loop free.
The strategy of a location‐based routing changes if the packet is not meant for a particular location but for a specific node, the location of which has to be determined before delivering the packet. The scenario becomes more complex if the destination node is mobile. The awareness of the changing location of the destination has to be passed on to the intermediate node handling the packet to enable the intermediate node to forward the packet in the proper direction. The routing strategy should not only have a mechanism to maintain data about each node and its current location but also be able to make the data available to any node that requires it for routing. The simplest mechanism is that every node keeps transmitting its current location, which propagates throughout the network through intermediate nodes, and all the nodes store this information. If the intermediate node has some other location information stored about the node, the new location information overwrites the previous location information. Time stamping or sequence number may be used to distinguish between two pieces of location information received from a node and to judge which one is recent.
Another approach to get to the destination location can be query based, whereby the source node floods the network with a query seeking the location of the destination node. The intended destination node replies to the flooding by sending its location to the source node. This approach is generally suitable for small, low‐density, and low‐mobility sensor networks, otherwise the energy and bandwidth consumption will be too high and the destination node might change its location by the time a packet reaches near the destination. An alternative to these approaches is to use some predesignated intermediate nodes as server nodes to which all sensors in their zone send location information. The source node intending to send a packet to the destination node can get the location of the destination node from the server node of the destination zone. The intermediate nodes in the routing path of the packet can also keep checking for any change in the location of the destination node from the server node of the destination zone as the destination node will keep the server node of its zone updated about its changing locations. A zone may have one or more server nodes, and there is a proper handoff mechanism between the server nodes of two separate zones when a node moves from one zone to another zone.
Location‐based routing is also used in conjunction with some other static or dynamic routing protocol to create a hybrid routing protocol. The location‐based routing is used for long‐distance transmission, and the static or dynamic routing is used once the packet reaches the vicinity of the destination. This leads to energy savings and less memory requirement in the sensor nodes, as only the routing information of a small area comprising nodes up to a few hops from the sensor nodes has to be stored in them and not the entire network. Another scenario where a hybrid routing with location‐aware routing as one of the components is used is a network in which certain areas do not support location‐aware routing. There can be regions of non‐availability of location information owing to electromagnetic interference, jamming, the need for electromagnetic silence, or non‐availability of GPS information. Such portions of the network may be catered for by static or dynamic routing, while the remaining network can use location‐aware routing.
Location‐based routing has been of interest to researchers since early 2000, and a good number of such protocols were proposed even during these initial years, some of which are listed below:
- Location Aided Routing (LAR) [29],
- Geographic Adaptive Fidelity (GAF) [30],
- Geographical and Energy‐Aware Routing (GEAR) [31],
- Time‐Based Positioning Scheme (TPS) [32],
- Two‐Tier Data Dissemination (TTDD) [33],
- SPEED [34].
11.6 Multipath Routing Protocols
The multipath routing protocols discover multiple paths from source to destination as well as use these multiple paths to forward the data from the source to the destination. The protocols have three main stages: path discovery to locate more paths between any source–destination pair or from any sensor node to the sink node, distribution of traffic from the source across multiple paths to the destination, and path maintenance to cater for topological changes, scalability, and availability of new paths. All three stages are based on certain criteria, which might be based on the application supported, reliability, QoS, energy constraint, or any other parameters. The major advantages of multipath routing are fault tolerance, load balancing, bandwidth aggregation, and faster delivery.
To find the best possible paths from source to destination during path discovery, disjoint paths are discovered so as to avoid common points of failure. The paths can be link disjoint or node disjoint, as indicated in Figures 11.13 and 11.14 respectively. If the set of paths are link disjoint, no two paths can have a common link. This implies that, for a typical WSN topology, in link disjoint paths a few nodes can be common across various paths. However, in node disjoint paths, as no two paths can have a common node except the source and destination nodes, this in itself implies that there can be no two common links either in the disjoint paths. A link failure brings down one path in link disjoint paths, and a node failure brings down one path in node disjoint paths. However, a node failure can bring down multiple paths in the case of link disjoint paths. Thus, node disjoint paths ensure link disjoint paths, but the reverse may not be true. Node disjoint paths are most effective in fault tolerance and bandwidth aggregation as they do not have a common point of failure or congestion.

Figure 11.13 A WSN with link disjoint paths.
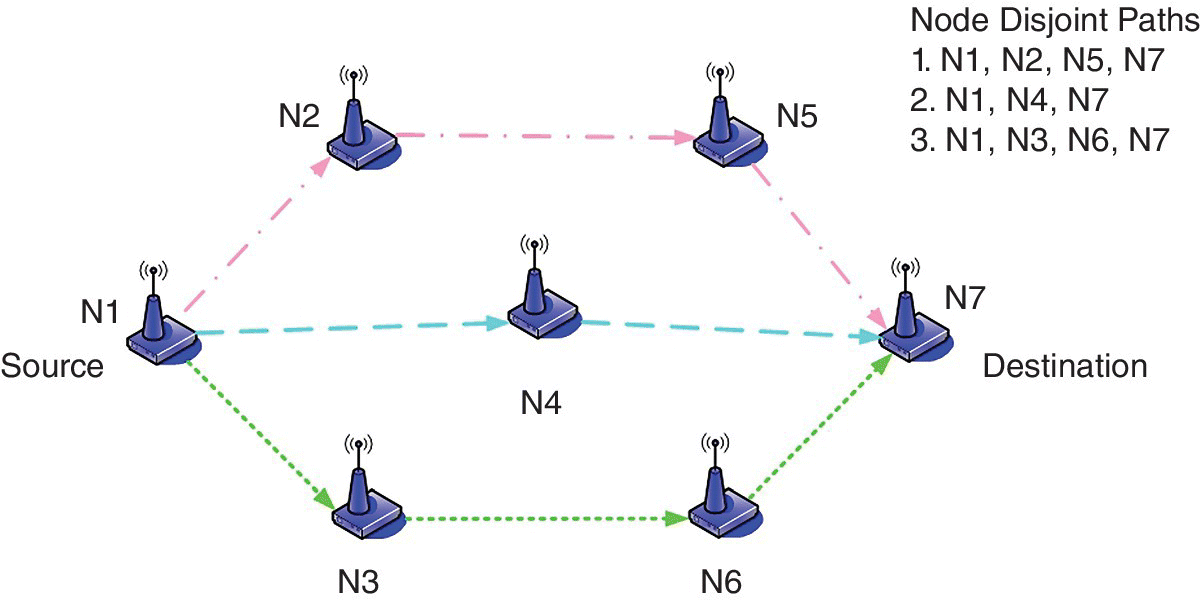
Figure 11.14 A WSN with node disjoint paths.
The traffic distribution over multiple paths can have various strategies. The entire traffic between a source–destination pair may be passed through a single path that is most efficient, reliable, or fault tolerant, and the other paths are kept as backup paths. Alternatively, the traffic may be distributed in the form of different data streams, each moving along a different path. The distribution of traffic over various paths is taken care of by the path selection algorithm, which uses different types of metric to select the paths. A process also has to be in place to reassemble the data streams received from various paths in a single data stream at the destination.
Fault tolerance is achieved by using multiple paths to send not only different data packets but also packets with a certain amount of redundancy along different paths to ensure fault tolerance in the case of path failure. To support load balancing, the multipath routing protocol can divert traffic to alternative paths if the path along which the data is presently being transferred has congestion, is facing latency, or is overutilized. A WSN may have multiple low‐bandwidth links, which can be aggregated to achieve higher bandwidth. The data is split into a number of streams, each passed through a different low‐bandwidth link to the destination, giving an effective high bandwidth at the destination. This reduces the delay in delivery of data packets from source to destination, as it also saves on the time of alternative route discovery in the case of a failed node or link.
Continuous research in the area of multipath routing has led to the development of a number of multipath routing algorithms, a few of which are named below:
- energy‐aware routing for low‐energy ad hoc sensor networks [13],
- highly resilient, energy‐efficient multipath routing [35],
- an energy‐efficient multipath routing protocol [36].
11.7 Query‐Based Routing Protocols
Query‐based routing protocols are the category of routing protocols where a query is sent to a wireless sensor network to obtain the data values sensed by the sensor node at a particular time or over a time interval. The query may also be sent to detect whether an event of interest is being detected by the sensor network. Query‐based routing is generally destination‐initiated reactive routing. The query can be generated by the sink node, any sensor node, or a system interfaced to the wireless sensor network. As query‐based routing is generally reactive, it adapts even in dynamic network topologies and can discover more than one route between the two nodes, leading to load sharing or recovery from a particular route disruption.
The querying node may be interested in getting information from a specific sensor node for specific data, or from a cluster of sensor nodes within a zone for event detection, or from all the sensor nodes in a wireless sensor network for the purpose of data aggregation and analysis. In a wireless sensor network running query‐based routing, when the network initializes or the querying node begins its operation, it may not be aware of the exact node or the specific zone from which the reply is of interest. Hence, initially the operation may be in classical broadcast mode. This fetches data from all the sensors, analysis of which may help in reducing the area of query, leading to identification of the zone of interest and reduction in zone size with time to avoid querying any unwanted node.
A query is generated by the querying node and sent in the wireless sensor network so as to reach the relevant sensor node for reply to the query. This query packet has to pass through a number of intermediate sensor nodes. Any intermediate node may be aware of the route to the intended target nodes for the query and forward the query through that route. Alternatively, the intermediate node may not be aware of the route to the target nodes for the query and hence may use any routing strategy such as flooding, gossip, or rumor routing. To ensure quick and assured discovery, flooding or selective flooding may be preferred to locate the target node for the query [37].
The route query moves from the querying source, which is the intended destination, towards the expected source of data, searching for the path and marking the path traversed so as to use it during return of the data packet from source to destination, subject to links being bidirectional. It should be ensured that the query packet does not enter into infinite loops among the nodes of the wireless sensor network. This will not only lead to delays in determination of the route, it will also lead to traffic congestion. The simplest way to avoid infinite loops in a query packet is to use a time‐to‐live (TTL) field in the query packet. The value of TTL is generally kept equal to the diameter of the network in the case of a static network, and a few hops extra in the case of a dynamic network. Restricting the value of TTL to these parameters helps in discovering the optimal routes in terms of number of hops, one among which will be the shortest route. However, if no restrictions are imposed on this scheme, all the intermediate nodes forward the route query to all their neighbors except the one from which they have received the query. The scheme can be better regulated in terms of reduction in network traffic if each intermediate node is constrained to forward the query packet only to one of its neighboring nodes. Although this will lead to a reduction in network traffic, it will not guarantee discovery of the shortest path, and the nodes will have to maintain data about all the query packets they have forwarded to avoid forwarding the same packet again if received from some other neighboring node [38].
Once a query reaches the destination node from the querying node, the reply has to go back from the destination node to the querying node. There are several techniques used to preserve the path information for traversal of the reply data. The simplest technique is that, while the query packet moves from the querying node to the destination node, it keeps appending to its data packet the addresses of all the nodes through which it has traversed so that the same can be used to send back the reply packet, and also be used by the nodes in the querying path to store the routing path to the destination node. If the size of the network is big or the optimum path has not been discovered by the query packet, the query packet and the reply packet can become too big in size, as they will contain the entire path information. Alternatively, each intermediate node forwarding the query packet in the sensor network can store the packet identifier along with the address of the previous hop node so that this information can be used to send back the reply data from the destination node to the query source. This reduces the packet size but leads to an overhead of each node maintaining details about every packet forwarded by it. Apart from these schemes, the route from destination node to query source can be discovered independently of the route discovered from delivery of query packet from querying node to the destination. This is essentially one of the techniques that the networks with unidirectional link connectivity have to rely on.
An example of query‐based routing protocol is Energy‐aware Query‐Based Routing Protocol for WSNs (EQR), which also aims to achieve energy balancing and energy saving.
11.8 Negotiation‐Based Routing Protocols
Sensor nodes are generally deployed in sufficient quantities to ensure coverage of interesting events with accuracy even in the case of failure of a few boundary or intermediate nodes. There may be critical deployment scenarios where a variety of sensors have been deployed collaboratively to detect an event with high reliability and avoid false alarms. For example, a fire may be detected by a smoke sensor, light sensor, heat sensor, and video sensor simultaneously, each reporting ‘Yes’ to fire detection in the case of a binary mode of operation for detection of fire in terms of ‘Yes’ and ‘No’. This leads to redundant event detection and duplicate data transmission among the nodes. Each extra or avoidable copy of the data being transmitted through the network consumes power in transmission and processing and occupies memory, both of which are in scarcity in a wireless sensor network. Negotiation‐based protocols [39, 40] are designed to address these issues of data implosion and detection of the same event by multiple sensors, which also leads to generation of similar data for transmission across the network. Furthermore, negotiation‐based protocols require a very limited view of the sensor network for their operation and can work well with awareness of single‐hop neighbors only. The Sensor Protocol for Information via Negotiation (SPIN) family of routing protocols [41], i.e. SPIN‐EC, SPIN‐RL, SPIN‐BC, SPIN‐PP, SPIN‐1, and SPIN‐2, are the most common examples of negotiation‐based routing protocols.
Negotiation‐based routing protocols conserve energy, reduce the amount of data being communicated, and hence also reduce the computational requirements. In this class of protocol, the nodes, which are generally in the neighborhood, negotiate with each other before transmission of the actual data to ensure that only useful data is transmitted. The two most common negotiations are for the following purposes:
- Negotiation ensuring requirement of data. Before sending the data, the transmitting node communicates with the receiving node in its neighborhood to check whether that neighboring node requires the data that is now ready for transmission with the transmitting node or this particular receiving node in the neighborhood is already possessing a copy of the data received from some other node.
- Negotiation enquiring of ability to forward data. The transmitting node checks whether the receiving node has sufficient energy and willingness to forward the data packet. This scenario is for those particular cases where the neighboring node has to act as an intermediate node to transfer the data further in the network to some other nodes so as to enable the data to reach the destination node or sink node. The neighboring nodes’ agreement to forward it and not drop the data because of energy constraint is negotiated before transmission of the data.
For the negotiation to occur across the nodes, the transmitting node should be able to share with the receiving node the basic information about the characteristics of the data in terms of the time of data creation, the location of generation of the data, intermediate nodes through which the data has traversed, or the type of data. One or more of these data descriptors help the receiver to take a decision as to whether it needs to receive the actual data from the sender. The data descriptor should be sufficiently small compared with the data itself to make the negotiation protocol efficient. Either the complete data descriptor or a predefined field in the data descriptor should be the same for the same data. The format of the data descriptor may be defined as per the application of the sensor network or based on the aggregation of heterogeneous sensors.
Negotiation occurs before the transmission of the actual data. A receiver does not agree to receive the data from the sender if it has already received a copy of it from some other node, and thus negotiation avoids data implosion. The receiver also prevents the transmitter from sending the data to it if it is of the same event or the same location and time that some other sensor in the area has already captured and has reached the receiving node prior to negotiation with the transmitting node. This helps to avoid redundant data transmission from sensors with overlapping sensing areas. The receiving node may not have sufficient energy left with it, and thus may now be interested only in receiving data of direct interest to it, but not willing or capable of participating in data forwarding to the destination node. Its non‐willingness to act as an intermediate node in data transmission can also be conveyed to the transmitting node during negotiation to stop the transmitting node from forwarding the data to this energy‐deficient node.
The number of steps involved in negotiation in terms of rounds of communication between the transmitting node and the receiving node should be few. The amount of data transmitted between the nodes during negotiation should also be optimally low so as to keep the negotiation overhead at the minimum. Furthermore, the process of negotiation should not be so intense and detailed that it consumes more power, computation, and bandwidth than the actual data transmission. Still, there may be instances when the data might be transmitted between any two nodes without negotiation as the transmitting node may judge it to be more cost effective if transmitted directly to the receiver without negotiation. These cases arise when the size of the data is either too small or the data is very critical and redundancy has to be maintained in the network for certain areas of the network or particular events.
11.9 QoS Routing Protocols
The applications of WSNs are on the rise, with an unimaginable diversity of requirements in the use of WSNs, deployment conditions, and desired output. Quality of Service (QoS) is interpreted as the measurement of the network parameters being delivered to the users as against the requirement of the user. There are certain applications where a real‐time output is desired from the WSN [42]. The real‐time output can be demanded from the network on a continuous basis or only during detection of an interesting event. For example, the output from a video sensor may not be required on a real‐time basis until any motion is detected in its area of visualization, and once the video sensor detects a motion, real‐time data from the video sensor is desired at the control station. Latency beyond a certain limit is not acceptable in this scenario. There are applications where latency can be tolerated to a certain extent, but reliability of the data cannot be compromised. An example of such a scenario is a sensor network to study the activity of a volcano when people are already away from it and no human life is at stake even if the data is received a few seconds late. However, reliability is important as the data will help to formulate the actual volcanic model and there is no other means to cross‐check the data. Use of sensor networks for tsunami prediction and ballistic missile defense are examples of applications where latency and reliability are of equal importance. Thus, the QoS requirement in a WSN is application dependent.
With advancement in sensor devices supported by technologies such as nanomaterials and MEMSs, the output of a sensor device is no longer limited to plain discrete text and numbers. Continuous data from sensors, including video, voice, and image, has posed new challenges, as these requirements cannot tolerate network latency, lower bandwidth, interference and packet drops, data loss, or out‐of‐order delivery. The fulfillment of these requirements calls for computational resources, memory, and accelerated operations, which all consume power. Over and above these, a QoS routing protocol is also required to route the packets for effective delivery across the network.
11.9.1 Challenges
QoS routing protocol is also responsible for balancing between energy consumption and assurance in terms of latency, throughput, reliability, or hop count. The QoS may not be dependent on a single metric, but a combination of two or more metrics. This further adds to the complexity of QoS routing, which now has to balance between multiple QoS metrics in a power‐saving routing algorithm.
Although energy is the primary constrained resource in a WSN, there are other constraints and challenges in providing QoS [43] in a WSN, some of which are as follows:
- Lower processing capability, limited queuing memory, small transmission range, dependence on other nodes for data forwarding.
- Compared with sensor nodes, there are fewer cluster coordinators, sink nodes, and gateways, and in the case of continuous sensing by sensor nodes, this leads to traffic congestion at these points.
- Multiple sink nodes may also call for variation in the QoS with respect to each sink node.
- There is a great amount of redundancy in detected data as well as data packets flowing in the network, which adds to reliability as well as energy consumption. Data fusion and aggregation techniques are used to reduce the undesirable redundancy, but these further add to energy consumption and processing delays.
- The sensor nodes as well as the sink nodes are mobile. A node may also keep toggling between active and sleep states to save power, adding to the problem of QoS implementation.
- QoS protocol should ensure that the energy consumption is nearly equal across all nodes so as to avoid power drain of a small set of sensor nodes.
- In a heterogeneous network there might be a variety of sensors with a different frequency of traffic generation, different bandwidth requirement, and different QoS requirement. Sensor clouds are a live example of such a network where there can be sensors related to temperature, humidity, wind flow, and video for a particular geographical area.
- The network topology is dynamic, the transmission medium in not reliable, and all the sensor nodes may not be uniquely identifiable.
11.9.2 Approach to QoS Routing
The QoS in a WSN can either be application driven or network driven. As discussed earlier, the field of application where the WSN is in use may dictate the QoS parameters. The application‐driven QoS parameters generally are latency, data integrity, reliability of data fusion, complete coverage (overlapping of sensed areas), and power saving from redundant sensors by being in sleep mode. The most common application‐specific QoS requirements are latency and reliability. The network‐specific QoS ensures minimal usage of sensor resources to deliver application‐specific QoS. These network‐specific QoS parameters are generally common for all WSNs and are the underlying parameters for data delivery from the sensor to the sink. The data delivery model being used for the network QoS can be distinguished into three categories: event driven, query driven, and data driven. In the event‐driven model, the sensor transmits data to the sink on detection of an event or a parameter beyond threshold. In a query‐driven model, the sink node enquires about certain parameters from all the sensors or specific sensors in a selected region. In a data‐driven model, the sensor nodes keep sending data to the sink either continuously or at prespecified time intervals.
In QoS‐based routing protocol, the route from source to destination has to be computed on the basis not only of the various resources available in the network but also the QoS requirements of the application so as to ensure that the QoS service delivered by the WSN matches the QoS requirement of the user. The QoS routing protocol, working on changing topology and unreliable state information about the sensor nodes, has to ensure data flow through the network at a minimum assured bandwidth with less than specified latency. Energy consumption is a parameter that always has to be minimized, along with any other metrics being considered for QoS.
11.9.3 Protocols
Some of the common QoS‐based WSN protocols are listed below:
- Sequential Assignment Routing (SAR) [44],
- Multiconstrained QoS Multipath Routing (MCMP) [45],
- Energy Constrained Multipath (ECMP) Routing Protocol [46],
- SPEED [34],
- Multipath and Multispeed Routing (MMSPEED) [47],
- Message‐Initiated Constrained‐Based Routing (MCBR) [48],
- Energy‐Efficient and QoS‐Aware Multipath‐Based Routing (EQSR) [49],
- QoS‐Based Energy‐Efficient Sensor Routing (QuESt) Protocol [50],
- Reliable Information Forwarding Using Multipath (ReInForM) [51],
- Directed Alternative Spanning Tree (DAST) [52],
- Multiobjective QoS Routing (MQoSR) [53].
References
- 1 C. Chong and S.P. Kumar. Sensor networks: evolution, opportunities, and challenges. IEEE, 91(8):1247–1256, 2003.
- 2 C. Townsend and S. Arms. Wireless sensor networks: principles and applications. Sensor Technology Handbook, Volume 1, pp. 439–450, Elsevier, Burlington, 2005.
- 3 C. J. Leuschner. The design of a simple energy efficient routing protocol to improve wireless sensor network lifetime, University of Pretoria. http://upetd.up.ac.za/thesis/available/etd‐01242006‐091709/unrestricted/00dissertation.pdf, 2005.
- 4 Q. Jiang and D. Manivannam. Routing protocols for sensor networks. 1st IEEE Consumer Communications and Networking Conference, 2(3):93–98, 2004.
- 5 J. N. Al‐Karaki and A.E Kamal. Routing techniques in wireless sensor networks: a survey. IEEE Wireless Communications, 11(6):6–28, 2004.
- 6 I. F. Akyildiz, W. Su, Y. Sankarasubramaniam, and E. Cayirci. Wireless sensor networks: a survey. Computer Networks, 38(4):393–422, 2002.
- 7 K. Akkaya and M. F. Younis. A survey on routing protocols for wireless sensor networks. Ad Hoc Networks, 3(3):325–349, 2005.
- 8 S. Hedetniemi and A. Liestman. A survey of gossiping and broadcasting in communication networks. Networks, 18(4):319–349, 1988.
- 9 C. Intanagonwiwat, R. Govindan, and D. Estrin. Directed diffusion: a scalable and robust communication paradigm for sensor networks. 6th Annual International Conference on Mobile Computing and Networking, pp. 56–67, ACM, 2000.
- 10 D. Braginsky and D. Estrin. Rumor routing algorthim for sensor networks. 1st ACM International Workshop on Wireless Sensor Networks and Applications, pp. 22–31, ACM, 2002.
- 11 C. Schurgers and M.B. Srivastava. Energy efficient routing in wireless sensor networks. IEEE. Military Communications Conference (MILCOM) – Communications for Network‐Centric Operations: Creating the Information Force, Volume 1, 2001.
- 12 W. Heinzelman, J. Kulik, and H. Balakrishnan. Adaptive protocols for information dissemination in wireless sensor networks. 5th Annual ACM/IEEE International Conference on Mobile Computing and Networking, pp. 174–185, ACM, 1999.
- 13 R. Shah and J. Rabaey. Energy aware routing for low energy ad hoc sensor networks. IEEE Wireless Communications and Networking Conference (WCNC), Volume 1, pp. 350–355, 2002.
- 14 M. Chu, H. Haussecker, and F. Zhao. Scalable information‐driven sensor querying and routing for ad hoc heterogeneous sensor networks. International Journal of High Performance Computing Applications, 16(3):293–313, 2002.
- 15 Y. Yao and J. Gehrke. The cougar approach to in‐network query processing in sensor networks. SIGMOD Record, 31(3):9–18, 2002.
- 16 N. Sadagopan, B. Krishnamachari, and A. Helmy. The ACQUIRE mechanism for efficient querying in sensor networks. IEEE 1st International Workshop on Sensor Network Protocols and Applications, pp. 149–155, 2003.
- 17 F. Ye, A. Chen, S. Lu, and L. Zhang. A scalable solution to minimum cost forwarding in large sensor networks. IEEE 10th International Conference on Computer Communications and Networks, pp. 304–309, 2001.
- 18 V. Rodoplu and T. H. Meng. Minimum energy mobile wireless networks. IEEE Journal on Selected Areas in Communications, 17(8):1333–1344, 1999.
- 19 W. Heinzelman, A. Chandrakasan, and H. Balakrishnan. Energy‐efficient communication protocol for wireless microsensor networks. IEEE 33rd Annual Hawaii International Conference on System Sciences, Volume 2, p. 10, 2000.
- 20 S. Lindsey and C. S. Raghavendra. PEGASIS: power‐efficient gathering in sensor information systems. IEEE Aerospace Conference, Volume 3, pp. 3‐1125–3‐1130, 2002.
- 21 A. Manjeshwar and D. P. Agrawal. TEEN: a routing protocol for enhanced efficiency in wireless sensor networks. International Parallel and Distributed Processing Symposium, Volume 3, p. 30189a, 2001.
- 22 A. Manjeshwar and D. P. Agrawal. APTEEN: a hybrid protocol for efficient routing and comprehensive information retrieval in wireless sensor networks. IEEE Computer Society, International Parallel and Distributed Processing Symposium, Volume 2, pp. 195–202, 2002.
- 23 L. Subramanian and R. H. Katz. An architecture for building self‐configurable systems. 1st Annual Workshop on Mobile and Ad Hoc Networking and Computing (MobiHOC), pp. 63–73, 2000.
- 24 S. Lindsey, C. S. Raghavendra, and K. Sivalingam. Data gathering in sensor networks using the energy*delay metric. IEEE Computer Society, International Parallel and Distributed Processing Symposium, Volume 3, San Francisco, CA, 2001.
- 25 M. Younisa, M. Youssef, and K. Arisha. Energy‐aware routing in cluster‐based sensor networks. 10th IEEE/ACM International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems (MASCOTS 2002), pp. 129–136, 2002.
- 26 N. Thepvilojanapong, Y. Tobe, and K. Sezaki. HAR: hierarchy‐based anycast routing protocol for wireless sensor networks. 2005 Symposium on Applications and the Internet, pp. 204–212, 2005.
- 27 M. Hempel, H.Sharif, and P. Raviraj. HEAR‐SN: a new hierarchical energy‐aware routing protocol for sensor networks. 38th Annual Hawaii International Conference on System Sciences, Hawaii, USA, 2005.
- 28 H. S. Kim and K. J. Han. A power efficient routing protocol based on balanced tree in wireless sensor networks. 1st International Conference on Distributed Frameworks for Multimedia Applications, pp. 138–143, 2005.
- 29 Y. B. Ko and N. H. Vaidya. Location‐Aided Routing (LAR) in mobile ad hoc networks. Wireless Networks, 6(4):307–321, 2000.
- 30 X. Ya, J. Heidemann, and D. Estrin. Geography‐informed energy conservation for ad hoc routing. 7th Annual International Conference on Mobile Computing and Networking, MobiCom ’01, pp. 70–84, New York, NY, USA, ACM, 2001.
- 31 Y. Yu, R. Govindan, and D. Estrin. Geographical and energy aware routing: a recursive data dissemination protocol for wireless sensor networks. UCLA Computer Science Department Technical Report ucla/csd‐tr‐01‐0023, 2001.
- 32 X. Cheng, A. Thaeler, G. Xue, and D. Chen. TPS: a time‐based positioning scheme for outdoor wireless sensor networks. INFOCOM 2004, 23rd Annual Joint Conference of the IEEE Computer and Communications Societies, Volume 4, pp. 2685–2696, 2004.
- 33 F. Ye, H. Luo, J. Cheng, S. Lu, and L. Zhang. A two‐tier data dissemination model for large‐scale wireless sensor networks. 8th Annual International Conference on Mobile Computing and Networking, pp. 148–159, ACM, 2002.
- 34 T. He, J. Stankovic, C. Lu, and T. Abdelzaher. SPEED: a stateless protocol for real‐time communication in sensor networks. IEEE 23rd International Conference on Distributed Computing Systems, pp. 46–55, 2003.
- 35 D. Ganesan, R. Govindan, S. Shenker, and D. Estrin. Highly‐resilient, energy‐efficient multipath routing in wireless sensor networks, ACM SIGMOBILE. Mobile Computing and Communications Review, 5(4):11–25, 2001.
- 36 Y. M. Lu and V. W. S. Wong. An energy‐efficient multipath routing protocol for wireless sensor networks. International Journal of Communication Systems, 20(7):747–766, 2007.
- 37 E. Ahvar, R. Serral‐Gracià, E. Marín‐Tordera, X. Masip‐Bruin, and M. Yannuzzi. EQR: a new energy‐aware query‐based routing protocol for wireless sensor networks. Wired/Wireless Internet Communication, pp. 102–113, Springer, 2012.
- 38 M. R. Pearlman and Z. J. Haas. Improving the performance of query‐based routing protocols through diversity injection. Wireless Communications and Networking Conference (WCNC 1999), Volume 3, pp. 1548–1552, 1999.
- 39 J. Kulik, W. Heinzelman, and H. Balakrishnan. Negotiation‐based protocols for disseminating information in wireless sensor networks. Wireless Networks, 8(2/3):169–185, 2002.
- 40 A. Okunoye and O. B. Longe. Enhanced negotiation‐based routing in wireless sensor networks. Computing, Information Systems & Development Informatics, 3(4):66–78, 2012.
- 41 L. J. García Villalba, A. L. Sandoval Orozco, A. T. Cabrera, and C. J. Barenco Abbas. Routing protocols in wireless sensor networks. Sensors, 9(11):8399–8421, 2009.
- 42 R. Sumathi and M. G. Srinivas. A survey of QoS based routing protocols for wireless sensor networks. Journal of Information Processing Systems, 8(4):589–602, 2012.
- 43 B. Bhuyan, H. K. Deva Sarma, N. Sarma, A. Kar, and R. Mall. Quality of service (QoS) provisions in wireless sensor networks and related challenges. Wireless Sensor Network, 2(11):861–868, 2010.
- 44 K. Sohrab, J. Gao, V. Ailawadh, and G. J. Pottie. Protocols for self‐organization of a wireless sensor network. IEEE Personal Communications, 7(5):16–27, 2000.
- 45 X. Huang and Y. Fang. Multiconstrained QoS multipath routing in wireless sensor networks. Wireless Networks, 14(4):465–478, 2008.
- 46 A. B. Bagula and K. G. Mazandu. Energy constrained multipath routing in wireless sensor networks. Ubiquitous Intelligence and Computing, pp. 453–467, Springer, 2008.
- 47 E. Felemban, C. G. Lee, and E. Ekici. MMSPEED: Multipath Multi‐SPEED Protocol for QoS guarantee of reliability and timeliness in wireless sensor networks. IEEE Transactions on Mobile Computing, 5(6):738–754, 2006.
- 48 Y. Zhang and M. Fromherz. Message‐initiated constraint‐based routing for wireless ad‐hoc sensor networks. 1st IEEE Consumer Communications and Networking Conference, pp. 648–650, 2004.
- 49 J. Ben‐Othman and B. Yahya. Energy efficient and QoS based routing protocol for wireless sensor networks. Journal of Parallel and Distributed Computing, 70(8):849–857, 2010.
- 50 N. Saxena, A. Roy, and J. Shin. QuESt: a QoS‐based energy efficient sensor routing protocol. Wireless Communications and Mobile Computing, 9(3):417–426, 2009.
- 51 B. Deb, S. Bhatnagar, and B. Nath. ReInForM: reliable information forwarding using multiple paths in sensor networks. 28th Annual IEEE International Conference on Local Computer Networks LCN’03, pp. 406–415, 2003.
- 52 P. Ji, C. Wu, Y. Zhang, and Z. Jia. DAST: a QoS‐aware routing protocol for wireless sensor networks. IEEE International Conference on Embedded Software and Systems Symposia ICESS Symposia’08, pp. 259–264, 2008.
- 53 H. Alwan and A. Agarwal. MQoSR: a multiobjective QoS routing protocol for wireless sensor networks. ISRN Sensor Networks, 2013:1–12, 2013.
Abbreviations/Terminologies
- AC
- Authentication Confidentiality
- ACQUIRE
- Active Query Forwarding in Sensor Networks
- APTEEN
- Adaptive Threshold‐Sensitive Energy‐Efficient Sensor Network Protocol
- ASIC
- Application‐Specific Integrated Circuit
- BATR
- Balanced Aggregation Tree Routing
- CADR
- Constrained Anisotropic Diffusion Routing
- CDMA
- Code Division Multiple Access
- DARPA
- Defense Advanced Research Projects Agency
- DAST
- Directed Alternative Spanning Tree
- DoS
- Denial of Service
- ECMP
- Energy Constrained Multipath Routing Protocol
- EQR
- Energy‐Aware Query‐Based Routing
- EQSR
- Energy‐Efficient and QoS‐Aware Multipath‐Based Routing
- GAF
- Geographic Adaptive Fidelity
- GEAR
- Geographical and Energy‐Aware Routing
- GPS
- Global Positioning System
- HART
- Highway Addressable Remote Transducer Protocol
- HAR
- Hierarchy‐Based Anycast Routing
- ISA
- International Society of Automation
- LAN
- Local Area Network
- LAR
- Location‐Aided Routing
- LEACH
- Low‐Energy Adaptive Clustering Hierarchy
- MCBR
- Message‐Initiated Constrained‐Based Routing
- MCFA
- Minimum‐Cost Forwarding Algorithm
- MCMP
- Multiconstrained QoS Multipath Routing
- MECN
- Minimum‐Energy Communication Network
- MEMS
- Microelectromechanical System
- MIT
- Massachusetts Institute of Technology
- MMSPEED
- Multipath and Multispeed Routing
- MQoSR
- Multiobjective QoS Routing
- PEGASIS
- Power‐Efficient Gathering in Sensor Information Systems
- QoS
- Quality of Service
- QuESt
- QoS‐Based Energy‐Efficient Sensor routing
- ReInForM
- Reliable Information Forwarding Using Multipath
- SAR
- Sequential Assignment Routing
- SoC
- System on Chip
- SOP
- Self‐Organizing Protocol
- SPEAR
- Sensor Protocol for Energy‐Aware Routing
- SPIN
- Sensor Protocol for Information via Negotiation
- SPINS
- Security Protocol for Sensor Network
- TDMA
- Time Division Multiple Access
- TEEN
- Threshold‐Sensitive Energy‐Efficient Sensor Network Protocol
- TPS
- Time‐Based Positioning Scheme
- TTDD
- Two‐Tier Data Dissemination
- TTL
- Time‐to‐Live
- UAV
- Unmanned Aerial Vehicle
- VGA
- Virtual Grid Architecture Routing
- WSN
- Wireless Sensor Network
Questions
- Mention the typical characteristics of a WSN.
- Make a list of at least 20 applications of wireless sensor networks. Thereafter, group these applications into various fields such as medical, industrial, defense, vehicular, home, environmental, and any other application.
- Draw a block diagram of a wireless sensor node, clearly showing all the components. Explain the role of each component in the sensor node.
- Explain the various networking topologies in a WSN.
- Describe the various classes of protocols in a WSN.
- State the requirements and the characteristics of a self‐healing sensor network.
- Differentiate between flat routing and hierarchical routing, clearly mentioning their advantages and disadvantages.
- Differentiate between rumor routing and gossiping.
- Why is location‐based routing required? Mention its advantages.
- Explain the main stages in a multipath routing protocol.
- State the requirements of a negotiation‐based routing.
- Mention the names of any two routing protocols from each of the following classes of routing:
- flat routing,
- hierarchical routing,
- location‐based routing,
- multipath routing,
- query‐based routing,
- QoS routing.
- Explain in detail, with an example, the working of the following protocols:
- SPIN,
- LEACH,
- PEGASIS,
- flooding,
- direct diffusion.
- State whether the following statements are true or false and give reasons for the answer:
- The size of a sensor node should be less than 1 cm.
- A sensor node should essentially have a receiver and a transmitter.
- Event‐driven routing in a WSN is a source‐based routing.
- The parameters for QoS routing in a WSN are hop count and bandwidth.
- Even in negotiation‐based routing, some data may be sent directly to the neighbor without any negotiation.
- Query‐based routing can discover multiple paths between source and destination.
- A node disjoint path may not be link disjoint.
- Location‐based routing is completely dependent on a GPS to know the location of the nodes.
- TEEN is a hierarchical routing protocol.
- If a node has battery power but still is not receiving or transmitting data, this indicates that the node has either gone faulty or been captured by an adversary.
- For the following, mark all options which are true:
- SPIN does not use this type of message:
- advertisement,
- request,
- ack,
- data.
- In a typical hierarchical routing, a group of nodes at the lowest hierarchical level send their data to:
- cluster head,
- sink,
- gateway.
- neighboring nodes.
- Location‐based routing can use any of the following for location awareness:
- cluster head,
- GPS,
- local frame of reference,
- position with respect to each other.
- Which is not a stage in multipath routing:
- path discovery,
- leader election,
- distribution of traffic,
- path maintenance.
- Which is not a transmission standard in WSN:
- Bluetooth,
- ZigBee,
- Wireless HART,
- IEEE 802.11.x.
- SPIN does not use this type of message:
Exercises
- Consider a wireless sensor network as indicated in the figure below where the links indicate connectivity between the nodes. The routing in the WSN is based on flooding and a packet has to be transmitted (a) from node 11 to node 16, (b) from node 2 to node 1, (c) from node 8 to node 10, and (d) from node 4 to node 16. How many copies of the packet will be generated in the network for each of the above?

- Sensor nodes have been fitted on deers in a forest. Each sensor node has a variety of sensors available in it that can detect position (GPS), acceleration/speed, humidity, body temperature, and atmospheric temperature. The sensor nodes form a part of a WSN that has rumor routing implemented in it. It is planned to locate the deer in the forest that have high body temperature owing to heavy rainfall. Make necessary assumptions and make a representative diagram of this WSN. Indicate the contents of any agent at three different nodes. Indicate the flow of packets, the contents of the event table, and the contents of the agent for the process to gain locations of the deers with high body temperature due to heavy rainfall.
- A drawback of SPIN is that it ‘does not guarantee delivery of data between any two nodes because, if the intermediate nodes are not interested in the data, the data cannot cross over the region of uninterested nodes and reach the destination that is interested in the data’. Draw an indicative WSN and mark a sink node and a node generating data of interest. Place the other sensor nodes accordingly to prove the correctness of the statement above and explain the process with ‘advertisement’, ‘request’, and ‘data’ packets moving in the WSN.
- A WSN has to implement hierarchical routing. There are 10 000 sensor nodes in the WSN. Each cluster head has resources to communicate with a maximum of ten nodes. Why does a multilevel hierarchy have to be implemented and why will it not be possible to establish a two‐level hierarchy? How many levels of hierarchy will have to be formed, and what will be the minimum number of cluster heads that have to be formed at each level? What will be the maximum number of hops required for transmission of a packet between any two sensor nodes?
- Formulate an equation to determine the threshold value for election as cluster head in LEACH. Necessary parameters may be taken as required. Prove that the value equated through this equation is not skewed.
- Assume that the network indicated in exercise 2 has TEEN implemented over it. The hard threshold for temperature has been set as 103 °F, and the soft threshold is 2 °F. The following temperatures in °F are being detected by the temperature sensor in this sequence – 99, 102, 100, 103, 100, 104, 105, 106, 103, 105, 106, 107, 108, 104, 102, 101. Please indicate the temperatures that will be transmitted by the WSN to the sink and in the same sequence in which they will be transmitted.
- Consider the WSN indicated in exercise 1. Mark two node disjoint paths between node 7 and node 12. Can two paths between any two nodes be detected that are node disjoint but not link disjoint?
- Assume a WSN as indicated in exercise 1 that uses TTL to avoid routing loops. This particular WSN is extremely dynamic. Bearing in mind the present arrangements of the nodes and the fact that the sensors have high mobility, what should be the minimum value of TTL?