
5
Routing and MPLS Traffic Engineering
5.1 MPLS Fundamentals
Traffic Engineering (TE) is a set of methods that work on the actual interconnected network and optimize the network resource utilization for efficient flow of traffic through the physical network. It is achieved by minimizing the overutilization of network capacity and distributing the traffic load on costly network resources such as links, routers, switches, and gateways. In the context of routing, TE is of very useful because traditional routing techniques are based on greedy shortest‐path computation techniques that lead to overutilization of certain network resources, even when other resources remain underutilized.
Multiprotocol label switching (MPLS) is an IETF standard that merges the control protocols available at layer 3 and the speed of operations available at layer 2 of an IP network. MPLS creates an autonomous system wherein the data packet is tagged so as to ensure its faster processing in the path. These tags are called labels, and backbone switch is not required to see the IP header to calculate the path of the packet; rather the label is used for this, which increases the speed of packet forwarding by avoiding the need to read the packet header.
There are two types of router in an MPLS network. The routers at the periphery of the MPLS cloud are used to connect to the IP traffic coming into the MPLS cloud and going out of it. The MPLS routers at the periphery are called label edge routers (LERs), and the routers inside the MPLS cloud create the MPLS backbone and are known as label switched routers (LSRs). A packet enters an MPLS network from an ingress LER and is tagged with a fixed‐length label. It then moves through the LSRs until it moves out of the MPLS network through an egress LSR, which removes the label. The path traversed by a packet inside the MPLS network is termed the labeled switched path (LSP), and there is a Label Distribution Protocol (LDP) in the MPLS that monitors the exchange of labels and maps labels with destination. The LSPs are created by specifically adding one‐by‐one the LSRs in it, based on the assurance of service expected at each router to ensure the compliance of overall QoS from the ingress router to the egress router.
The traditional routing algorithms that forward packets based on the information about the destination address only are short sighted and are therefore constrained [1] by the following limitations:
- They do not take into consideration the current flows, or expected future flow demands in the network. These algorithms are greedy, in the sense that they would route a request through the default shortest path, the shortest‐widest path, or the widest‐shortest path, and would reject a demand when the precomputed routes using these algorithms are congested, even when other alternative routes are free to accept more requests.
- They do not take into consideration information about network infrastructure, network topologies, or traffic profiles to avoid loading bottleneck links in a network that might lead to rejection of future demands.
- The previous algorithms will perform negatively when they operate in an online routing situation, where the tunnel setup requests arrive one at a time and the future demand is unknown. These algorithms require knowledge of future demands to operate successfully.
- The previous algorithms are not adaptive to possible link failures. Therefore, in a situation where a link fails, these algorithms will not be able to route requests through alternative routes.
5.2 Traffic Engineering Routing Algorithms
Online routing using TE principles has drawn considerable attention. Of all the online TE algorithms [1–5], the one that has attracted most attention is the minimum interference routing algorithm (MIRA) designed by Kar et al. [2]. In addition to the MIRA algorithm, there are a few other TE routing algorithms that were proposed by other researchers, some of which are: (i) profile‐based routing (PBR) [1, 6], (ii) the dynamic online routing algorithm (DORA) [7], (iii) Iliadis and Bauer’s algorithm [5], (iv) Wang et al.’s algorithm [3], and (v) Subramanian and Muthukumar’s algorithm [8].
Some of the properties that a ‘practically useful’ TE algorithm (based on MPLS) should have are as follows [2]:
- The algorithm should be based on an online routing model, where LSP setup requests arrive one at a time (not all at once) and the future demand is unknown. On the other hand, in an offline model, all LSP setup requests are known a priori, and there are no demands for future LSP setup requests.
- It should be able to use knowledge about the physical locations of the ingress–egress router pairs through which an LSP is set up.
- The algorithm should be able to adapt to possible link failures in the network. In other words, a good TE algorithm should be able to reroute post‐failure requests through alternative routes.
- It should be able to route the requested bandwidth without splitting the demands as much as possible through multiple paths. This is necessary because it is often the case that the nature of the traffic does not allow a demand to be split. Splitting traffic is, however, a common practice in scenarios such as load balancing and network performance improvement.
- The algorithm should, if possible, support a distributed implementation, where instead of performing the route computation in a centralized server the computations of each LSP’s route request are distributed at the local ingress node.
- It is quite desirable for such an algorithm to be capable of using different policy constraints. For example, service level agreements might impose a restriction that LSPs with less than a threshold value of flow guarantees should not be accepted.
- Such an algorithm should operate under strict bounds of computational complexity. The algorithms should be very fast and execute within a fixed time constraint. The amount of computation involved with LSP setup requests should be minimized so that the algorithm can be implemented on a router or a route server.
5.3 Minimum Interference Routing Algorithm
The most influential online routing algorithm in TE is the MIRA algorithm [9]. MIRA [9–11] is online because it does not require a priori knowledge of the tunnel requests that have to be routed. The algorithm is targeted towards applications such as the setting up of LSPs in MPLS networks. The algorithm helps service providers set up bandwidth‐guaranteed tunnels with ease in their transport networks. The term ‘minimum interference’ used in the nomenclature of the algorithm indicates that the tunnel setup request is to be routed through a path (or a path segment) that must not interfere too much with future tunnel setup requests. The algorithm aims to protect the critical links in a network from being overloaded, thereby reducing the chances of rejection of future requests. The critical links are identified by the algorithm to be those that, if congested because of heavy loading, might lead to rejection of requests. One characteristic that is particularly attributable to MIRA is that it is the first algorithm to use information about ingress–egress pairs. Unlike its predecessors, MIRA uses any available information about ingress–egress nodes for potential future demands. MIRA is based on the core concepts of max‐flow and min‐cut computations.
Max‐flow. A flow [10–13] in a communication network can be defined as the rate at which information flows in the network. A max‐flow can be defined as the maximum rate at which information can be transmitted over a link in the network by satisfying the capacity constraints. Intuitively, in a max‐flow problem, we aim to design the network in such a way that the flow should not violate the capacity constraints, and the algorithm has to transmit the maximum possible flow from a source node to a sink node.
Critical links. If information has to pass through a minimum‐hop route, there would be interference at the bottleneck link. MIRA attempts to minimize this interference due to routing of requests through the bottleneck links. The bottleneck links are called critical links [2, 11] and are computed using the min‐cut concept described below. The set of critical edges between a pair of source and sink nodes is the minimum cut between that pair. MIRA defers the loading of critical links as much as possible.
Cut. The ‘cut’ in ‘flow networks’ indicates partitioning of the nodes in the network into two subsets [10]. If N is a set of nodes in a flow network, a cut involves partitioning [9] all the nodes of the network into two subsets, S and S′ = N − S, such that S ∪ S′ = N.
s–t cut and min‐cut. A cut is referred to as an s‐t cut [10] if s belongs to S (i.e. one subset of the nodes) and t belongs to S′ (i.e. the other subset of nodes N). The capacity of all the forward arcs in the cut is referred to as the capacity of the s–t cut. The minimum capacity among the capacities of all s‐t cuts is referred to as the min‐cut.
Max‐flow min‐cut theorem. This theorem states that: ‘The maximum value of the flow from a source node s to a sink node t equals the minimum capacity among all s–t cuts’ [10].
5.3.1 The Algorithm
Suppose we have a network represented by a set of N nodes, L links, and a set B representing the bandwidth between the links. Of all the N nodes, only a subset of them are ingress–egress nodes, of which, again, only a subset of all possible ingress–egress nodes will lead to the setting up of an LSP [2, 9]. A request for setting up an LSP is processed either directly by a route server or indirectly via an ingress node, both of which finally, through some interactions, know the explicit route from the ingress node to the egress node.
A request for setting up an LSP is denoted as the triple (oi, ti, bi), where oi represents the ingress router, ti represents the egress router, and the amount of bandwidth requested for LSP is bi. It is assumed that all the QoS requirements are converted into an effective bandwidth requirement, that all the requests for setting up an LSP come one at a time, and that the future demands are unknown. In such a model it is intended to devise an algorithm that will help to determine a path along which each demand for an LSP is routed along such a path so as to make optimum use of network resources.
Suppose there is a set of distinguished node pairs P, which can be perceived as potential ingress–egress router pairs. Suppose the pair (s,d) ∈ P. All LSP setup requests occur between these pairs. Now it is assumed that a request of D units of bandwidth arrives for the ingress–egress pair (a,b) ∈ P. Suppose now that the max‐flow problem is solved between the ingress–egress pair (s,d) with the link capacities reflecting the current residual capacities of those links. The max‐flow value determines the maximum amount of bandwidth that can be routed from s to d.
The interference between a path in (a,b) and an ingress–egress pair (s,d) can be defined as the reduction in the max‐flow value in the ingress–egress pair owing to the routing of bandwidth on that path. As they do not make any assumptions about the knowledge of future demands, the demand of D units between a and b should be routed in such a way as maximally to utilize the smallest max‐flow value for the ingress–egress pairs in P(a,b).
To solve the problem, one approach is to compute the weights for the links in the network and route a demand along the weighted shortest path. The problem is to estimate the weights for all those links so that the current flow does not interfere too much with future demands. Without delving much into the procedure about how the link weights are estimated, the final equation that computes these weights for the links is as follows:

where αsd represents the weight for the ingress–egress pair (s,d), θsd represents the max‐flow value for the ingress–egress pair, and ∂θsd/∂R(l) represents the rate of change of the value of maximum flow between (s,d) with change in the residual link capacity R(l).
Equation (5.1) can be further simplified by considering the notion of critical links. For an ingress–egress pair, a critical arc belongs to any min‐cut for that ingress–egress pair. The min‐cut is always computed with the present value of the residual capacities on those links. If Csd represents the set of critical links for an ingress–egress pair (s,d), by the max‐flow min‐cut theorem it can be shown that

which implies that

Equation (5.3) can be used to compute the set of critical arcs for all ingress–egress pairs, which is essentially the problem of determining the weights of the arcs as described by equation (5.1). The set of critical links for a predetermined set of ingress–egress pairs of nodes can be determined by a single execution of the max‐flow algorithm between the ingress–egress pair.
For practical implementations [9], the value of αsd can be chosen to signify the importance of an ingress–egress pair (s,d). The weights can be chosen to be inversely proportional to the max‐flow values, i.e. αsd = 1/θsd. In other words, critical arcs that have lower max‐flow values are assigned more weights than those with higher max‐flow values.
MIRA prevents loading of the critical links and routes requests along non‐critical links, even if such a path is not a minimum‐hop shortest distance path.
5.3.2 Limitations of MIRA
Although MIRA is quite influential to the TE community because it proposes an online algorithm for routing bandwidth‐guaranteed tunnels using the idea of minimum interference, it is not ‘robust’. The limitations of MIRA [1] are as follows:
- MIRA fails to identify the effect of interference on a cluster of ingress–egress nodes. It just computes the effect of interference on single pairs of ingress–egress nodes.
- MIRA does not keep track of the expected bandwidth requests between a pair of nodes, thereby rejecting requests even when there might be sufficient residual capacity available to route the request between the affected pair.
- MIRA is computationally expensive in complex networks where thousands of max‐flow/min‐cut computations have to be performed for every request.
5.4 Profile‐Based Routing Algorithm
The PBR algorithm was designed to work on a group of ingress–egress nodes. The PBR algorithm, however, uses the traffic profile of a network in a preprocessing step roughly to predict the future traffic distribution. PBR has two main phases of processing: (i) the offline preprocessing phase; (ii) the online routing phase.
Offline preprocessing phase. This phase is based on the solution to the multicommodity flow computation problem [10] on a set of traffic profiles. The traffic profiles can, typically, be obtained from a number of sources, e.g. the service level agreements (SLAs) between the customers and network service providers, historical trend statistics, or by suitably monitoring the network for a predetermined period of time.
Using the same notations that were used by the original authors, i.e. Suri et al. [1, 6], let us assume that there is a capacitated network, G = (V, E), with the function cap(e) denoting the capacity of a link e ∈ E, and the set of links in the network with V vertices. It is also assumed that there is a table of traffic profiles obtained by using one of the methods mentioned in the last paragraph. Let us denote these traffic profiles by (classID, si, di, Bi), where classID denotes the traffic class to which an ingress–egress node belongs, si and di denote the ingress–egress pairs, and Bi is the aggregated bandwidth between the above ingress–egress pairs for that class. The term ‘class’ can typically be perceived as, for example, having requests between an ingress–egress pair to belong to one class, or as having all requests that have the same ingress or egress node to belong to one class [11]. In multicommodity flow preprocessing, each of these classes is classified as a distinct commodity. The requested bandwidth is treated as an aggregated bandwidth between a pair of ingress–egress nodes of the identified class as mentioned, and not as a single flow. Therefore, each profile (and not each flow) can be split, and consequently several flows belonging to a traffic profile can be routed on distinct paths.
Satisfying all bandwidth route requests may not always be possible. Thus, additional edges, called excess edges, are added to the network. This is done to avoid the situation where there is no feasible solution to the multicommodity flow problem. The excess edges are assigned an infinite capacity, so as to discourage routing of flows through these routes as much as possible. The rest of the network edges are assigned a cost of unity. Thus, the cost function [1] can be expressed as

If there are k commodities, the multicommodity problem to be solved for the transformed network [1] from the last step can be expressed as

subject to the following constraints:
- All edges satisfy the capacity constraints. In other words, if e is not an excess edge, then the following inequality holds true:
 .
. - All nodes conserve the flow for each node, except at the ingress–egress nodes corresponding to that flow.
- Bi is the amount of commodity i reaching its destination di.
The xi(e) values that can be obtained from the multicommodity flow computation are used for preallocating the capacity of the edges of the network. The incoming requests in the online phase of the algorithm, will use these capacities as thresholds so as to route flows belonging to traffic class i.
Online routing phase. The online phase of the PBR algorithm is much simpler than the offline phase. The terminologies of the original authors [6] are used to explain the online phase of this algorithm. The reduced graph, with residual capacities from the offline preprocessing phase, is used as the input to this phase. Let this residual capacity of an edge e of class j be denoted by rj(e). The online routing phase takes this residual graph to process an online sequence of incoming LSP setup requests (id, si, di, bi), where id, si, di, and bi are respectively the ID of the request to be routed, the ingress and egress node pairs between which the request is to be routed, and the bandwidth that is to be routed. While routing the requests, given a choice, the requests are routed through the minimum‐hop shortest paths between the ingress–egress pairs of nodes.
PBR was identified to have the following limitations [11]:
- PBR is based on the assumption of the splitting of a group of flows, even if it is not a single flow. This will still remain problematic when an individual flow has a very high demand.
- The performance of the algorithm will be limited by the accuracy of information provided in the traffic profiles in the preprocessing phase of the algorithm.
5.5 Dynamic Online Routing Algorithm
DORA is another TE routing algorithm, proposed by Boutaba et al. [7], for the routing of bandwidth‐guaranteed tunnels. DORA attempts to accommodate more future path setup requests by evenly distributing reserved bandwidth paths across all possible paths in the entire network, thereby balancing the load in an efficient manner. It does so by avoiding, as much as possible, routing over links that have a greater potential to coincide with the link segments of any other path, and those that have a low running estimate of the residual bandwidth.
DORA is designed to operate in two phases [7]. In the first phase, DORA computes, for every source–destination pair, the path potential value (PPV), which stores in an array the potential of a link to be more likely to be included in a path than other links. In other words, the algorithm tries to preprocess a set of links that are more likely to be included among the different paths that packets could travel between any pair of source–destination nodes. The PPV for any pair of nodes (S,D) is denoted as PPV(S,D). If a path can be constructed over a link L for any pair of source–destination nodes, PPV(S,D) is reduced by unity, whereas if different paths can be constructed over the same link L for different source–destination pairs, the value of PPV(S,D) is increased by unity.
In the second phase, DORA first preprocesses and removes those links that have a required bandwidth exceeding the residual bandwidth. It then provides weights to the different links in the network by taking into consideration the PPV arrays and the current residual bandwidths. As there are two parameters that may influence the weights that can be assigned to the links, namely the PPV and the current residual bandwidth, it introduces a new parameter called bandwidth proportion (BWP), which determines the proportion of influence either of these two parameters could have on the weight of the link.
5.6 Wang et al.’s Algorithm
Wang et al. [3] also proposed an algorithm for setting up bandwidth‐guaranteed paths for MPLS TE, which is based on the concept of critical links, the degree of their importance, and their contribution in routing future path setup requests. Thus, like MIRA, the algorithm essentially belongs to the class of minimum interference algorithms. The algorithm takes into account the position of source–destination nodes in the network. Specifically, for any path setup request, the algorithm first considers the impact of routing this request on future path setup requests between the same pair of source–destination nodes. To do this, the algorithm assigns weights to the links that may be used by future demands between that pair of source–destination nodes. For any source‐destination pair of nodes (s,d), it computes the maximum network flow, θs,d, between s and d, and ![]() , which represents the amount of flow passing through link l. Then, for all links in the paths between s and d, they compute the bandwidth contribution of each of those links,
, which represents the amount of flow passing through link l. Then, for all links in the paths between s and d, they compute the bandwidth contribution of each of those links, ![]() , to the max‐flow between s and d [3].
, to the max‐flow between s and d [3].
In addition to the link’s bandwidth contribution, as it also considers the link’s residual bandwidth R(l), the algorithm proposes the parameter ![]() . It uses this normalized bandwidth contribution of any particular link l to compute the overall weight of a link l as
. It uses this normalized bandwidth contribution of any particular link l to compute the overall weight of a link l as

where w(l) represents the total weight contribution of all the links between a pair of source–destination nodes. Subsequently, it assigns the weights to the different links using the above formula, and then, in the latter phases of the algorithm, eliminates those links that have requested bandwidth for any request greater than the residual bandwidth in that link. It then runs Dijkstra’s algorithm on the reduced network (with the weights assigned using the formula above) to route a request through the shortest path between a pair of source–destination nodes in a network.
5.7 Random Races Algorithm
The RRATE algorithm [13] accepts certain packet transfer requests with an assured bandwidth and then efficiently uses the network to forward the packet at the committed bandwidth. The input to the algorithm comprises the routing bandwidth details, and the output of the algorithm is the path in the network to be followed as well as routing of the packets over that path. The algorithm is based on a reward function for each action. It also defines a value N that indicates the limit of reward an action can be granted. The algorithm is based on the theory of ‘random races (RR)’ [14].
The algorithm is divided into three phases: offline operations, online operations, and post‐convergence operations. In the offline operations, the shortest paths between the routers are determined and the RR corresponding to each router pair is maintained. The maximum bandwidth utilization permissible on the link in terms of its percentage utilization is also specified. During the online operations phase, a decision is taken regarding accepting or rejecting a request for a path. The request for a path is accepted if the prerouting path utilization approximation is less than the threshold bandwidth utilization specified for the path. Further, path selection is done in a sequential manner by sorting the k paths in increasing order of available threshold bandwidth, starting the selection from the path with least available bandwidth. The path that has just a little more than the required bandwidth is selected. This reduces the amount of unutilized bandwidth as well as providing sufficient bandwidth to the requested service. If all the paths have been checked and none of them could be selected, the request is rejected. In the post convergence phase, the packet is routed through the first path providing the assured bandwidth.
References
- 1 S. Suri, M. Waldvogel, D. Bauer, and P. R. Warkhede. Profile‐based routing and traffic engineering. Computer Communications, 26:351–365, 2003.
- 2 K. Kar, M. Kodialam, and T. V. Lakshman. Minimum interference routing of bandwidth guaranteed tunnels with MPLS traffic engineering applications. IEEE Journal of Selected Areas in Communications, 18(12):2566–2579, 2000.
- 3 B. Wang, X. Su, and P. Chen. Efficient bandwidth guaranteed routing algorithms. Journal of Parallel and Distributed Systems and Networks, 2002.
- 4 W. Szeto, R. Boutaba, and Y. Iraqi. Dynamic Online Routing Algorithm for MPLS Traffic Engineering. Lecture Notes in Computer Science 2345. Springer, 2002.
- 5 I. Iliadis and D. Bauer. A new class of online minimum‐interference routing algorithms, pp. 959–971, in Enrico Gregori, Marco Conti, Andrew T. Campbell, Guy Omidyar, and Moshe Zukerman (eds). NETWORKING 2002: Networking Technologies, Services, and Protocols; Performance of Computer and Communication Networks; Mobile and Wireless Communications. Lecture Notes in Computer Science 2345. Springer, 2002.
- 6 S. Suri, M. Waldvogel, D. Bauer, and P. R. Warkhede. Profile based routing: a new framework for MPLS traffic engineering, pp. 138–157, in Quality of Future Internet Services, Lecture Notes in Computer Science 2156. Springer, 2001.
- 7 R. Boutaba, W. Szeto, and Y. Iraqi. DORA: efficient routing for MPLS traffic engineering. Journal of Network and Systems Management, 10(3):309–325, 2002.
- 8 S. Subramanian and V. Muthukumar. Alternate Path Routing Algorithm for Traffic Engineering. ICSENG, 15th edition, 2002.
- 9 M. Kodialam and T. V. Lakshman. Minimum interference routing with applications to MPLS traffic engineering. IEEE, INFOCOM 2000. 19th Annual Joint Conference of the IEEE Computer and Communications Societies, Volume 2, pp. 884–893, 2000.
- 10 R. K. Ahuja, T. L. Magnanti, and J. B. Orlin. Network Flows: Theory Algorithms, and Applications. Prentice Hall, 1993.
- 11 S. W. H. Wong. The online and offline properties of routing algorithms in MPLS. Master’s thesis, Department of Computer Science, University of British Columbia, July 2002.
- 12 T. H. Cormen, C. E. Leiserson, and R. L Rivest. Introduction to Algorithms. MIT Press, 1990.
- 13 S. Misra, Network applications of learning automata. PhD dissertation, School of CS, Carleton University, Ottawa, Canada, 2005.
- 14 D. T. H. Ng, B. J. Oommen, and E. R. Hansen. Adaptive learning mechanisms for ordering actions using random races. IEEE Transactions on Systems, Man, and Cybernetics, 23(5):1450–1465, 1993.
Abbreviations/Terminologies
- BWP
- Bandwidth Proportion
- DORA
- Dynamic Online Routing Algorithm
- IETF
- Internet Engineering Task Force
- IP
- Internet Protocol
- LDP
- Label Distribution Protocol
- LER
- Label Edge Router
- LSP
- Labeled Switched Path
- LSR
- Label Switched Router
- MIRA
- Minimum Interference Routing Algorithm
- MPLS
- Multiprotocol Label Switching
- PBR
- Profile‐Based Routing
- PPV
- Path Potential Value
- QoS
- Quality of Service
- RR
- Random Races
- RRATE
- Random‐Races‐Based Algorithm for Traffic Engineering
- SLA
- Service Level Agreement
- TE
- Traffic Engineering
Questions
- What is traffic engineering and what is its usefulness?
- Name five different traffic engineering routing algorithms.
- Mention the properties that a traffic engineering algorithm should have.
- Explain the following: max‐flow, critical link, cut, and max‐flow min‐cut theorem.
- Draw a hypothetical network and, using it, explain the working of MIRA.
- Differentiate between the two main phases of processing in a PBR algorithm.
- State the two phases of operation of DORA and explain both phases.
Exercises
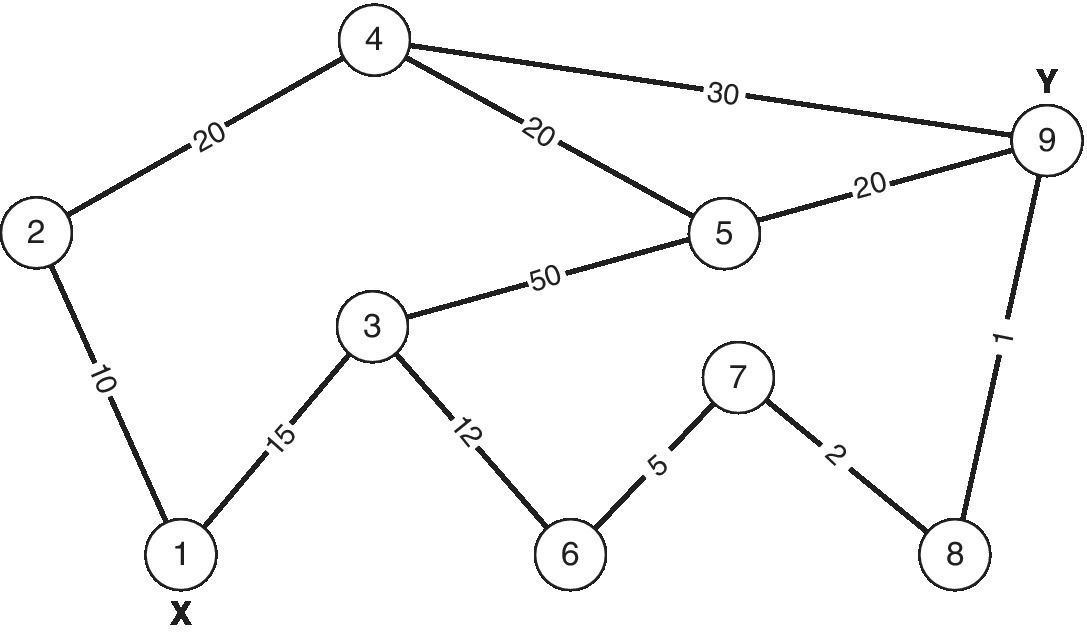
- Consider the network as indicated in the figure below. Calculate the min‐cut edge for source = X and destination = Y. What is the capacity of the s–t cut and the value min‐cut?
- Design a network and mention the traffic flow over it to bring out the disadvantages of MIRA.