
6
Interior Gateway Protocols
6.1 Introduction
A network is termed an autonomous system (AS) [1‐3] if the administrative decisions related to the network, such as the network topology, addressing scheme, assignment of addresses to the hosts, and routing decisions, can be taken by the administrator of the network. The scope of an administrative domain may not be confined to a single network but can be over a combination of networks connected to each other and sharing common routing information. Still, these networks remain under the administrative control of only one administrator for the purpose of sharing the common routing table in a centralized, shared, or distributive mode. An AS is characterized as a network in which the nodes are connected to each other in such a fashion that any node can communicate with any other node unless there is some link or node failure in the network. The routers in an AS share routing information among each other, using a common routing protocol, and the network is managed by a single organization.
Generally, two different ASs are connected across a geographical distance over a wide area network, and the Internet service provider (ISP) provides the connectivity to these two ASs. The technique used by an ISP for routing the traffic cannot be controlled by the administrators of the ASs. The ISP is responsible for routing the traffic between the ASs and does it in a way that is generally transparent to the ASs. The ASs can only enter into an agreement with an ISP to provide a minimum guarantee of the level of service being provided. These guarantees can be based on a number of parameters such as number of hop counts, delay, bandwidth, and jitter. The assurance is mutually agreed based on a service level agreement (SLA) assuring quality of service (QoS). The routing protocols that work within an AS are called Interior Gateway Protocols (IGPs). An IGP is also used to route the traffic within each separate network of an AS. The Exterior Gateway Protocol (EGP) handles the routing among the ASs.
The autonomous system is also known as a routing domain, and Interior Gateway Protocol supports the distribution of routing information among the routers of the routing domain and then helps in computing the best routing path from one node to another. The ‘best’ path can be in terms of one or more parameters as defined by the administrator or the protocol. In an IGP, two types of message are generally exchanged between the nodes – the neighbor discovery messages and the network reachability messages. The neighbor discovery messages are used to detect the neighbors of the router, their status, the routing mechanism used by the router, and the condition of the connectivity to the neighboring router. The network reachability messages help the router to get an idea about the topology of as big a portion of the network in which it is operating as possible. The protocol attempts to seek the neighbor and the reachability information as well as try to incorporate mechanisms to authenticate it and keep it updated so as to take care of link failure or node failure or any other change in the network topology.
The term ‘gateway’ in the Interior Gateway Protocol refers to the router. The ‘gateway’ was used historically to define the functions performed by the present‐day router. The protocol guides how to reach from one router to another router within a network or a group of networks. There are two types of IGP: distance vector routing and link state routing. Distance Vector Routing Protocol gives each router in the network information about its neighbors and the cost of reaching any node through these neighbors. By exchanging information with the neighbors, a router can estimate the cost to reach a node and the neighbor to which it should forward the packet to enable it to construct the best path. In link state routing, each router has information about the topology of the network, by using which it calculates the best path to the destination and the outgoing (egress) link of the router to reach the destination using the shortest path.
The history of Interior Routing Protocol [4‐6] can be traced back to the NSFNet of the National Science Foundation (NSF), USA. NSFNet was a part of ARPANET and was running a software called ‘fuzzball’ on five DEC LSI‐11 computers across the network spread over five supercomputing centers at different academic institutes. The fuzzball software gave the hardware the capability to act as a modern‐day router and it helped in connecting various networks to ARPANET. These fuzzball computers in the NSFNet acted as an AS, and thus used an Interior Routing Protocol.
The Interior Routing Protocol used by NSFNet was a variation of the present‐day Distance Vector Protocol. The protocol used the network delay as the parameter for selecting the best path. The protocol was known as HELLO Protocol because the fuzzball routers on a regular basis sent hello packets to their neighbors and calculated the time required by the packet to reach the destination and then the acknowledgement to come back from the destination to them. This was done by time stamping the HELLO packets. A router knows that it can reach any other router that its neighbor can reach, but with an additional packet delay as calculated using the HELLO packet. However, using time delay as a route calculation metric led to spurious results in the protocol, as it was not directly related to the bandwidth owing to other parameters such as processing time and buffer. Even if there was no change in the network parameter, the link delay was not constant over a period of time, leading to flapping. HELLO Protocol was slowly replaced with RIP, and now HELLO Protocol is neither in use nor a part of TCP/IP.
6.2 Distance Vector Protocols
The Distance Vector Protocol gets its name from the two parameters that it uses – distance and vector. These two parameters are used to forward the packet from the source to the destination. The protocol has awareness about the distance between any two neighboring nodes as well as the distance from the source to the destination before it starts forwarding the packet. Vector indicates the direction in which the packet should move. Each intermediate routing node in the protocol is aware of the direction in which it should forward the packet so as to enable the packet to reach the destination using the shortest path.
The working of a distance vector routing protocol helps the routers to exchange their link information with immediate neighbors and update their routing table. When this routing table is shared recursively over time, each router gets to know the distance to every other router in the network and the direction towards each of the routers. In each level of recursion of sharing the routing table, information regarding one more level of router is added in terms of connectivity from the router separated by hops. At every step, as the levels of routers keep on increasing, the best path to the router is calculated and retained and the other paths to the router are ignored. Finally, when the recursion reaches the farthest level of router, the protocol stops and the final routing table is generated. However, there is frequent exchange of data between the neighboring nodes to incorporate topological changes. This exchange of data can be periodic or triggered by an event such as link failure or node failure [7, 8]. Some of the common terminologies used in distance vector routing are as follows.
Route convergence. A network is said to have achieved route convergence if all the routers in the AS contain in their routing tables the same information about the network. Route convergence continues if the routers do not have to change any information in their routing tables based on the regular exchange of routing information between the routers, i.e. no information of any topological changes is being received from their neighbors. If there are some topological changes or failure of a link or a node, changes in the routing table are triggered, disturbing the converged network. The neighboring node will transmit the information regarding the change in the form of a modified routing table. This will subsequently lead to changes in the routing table of all the routers, and the network again waits for all the routers to converge. The rate at which a network converges depends on two factors. Firstly, the rate at which the routing tables are exchanged between the routers, and secondly, the processing speed of the routing nodes to recalculate their routing tables based on the routing entries received from the neighbor. The faster a network converges, the faster it becomes operable.
Periodic updates. The routers send their routing tables to their neighbors at regular intervals of time for periodic update. A periodic update may be sent by a router to its neighbor even if there is no change in the routing table. However, this may lead to unnecessary transmission of data across the network and consumption of bandwidth by the data, which is not required. But at the same time, a periodic update from a neighbor informs the router that the neighboring router is active and the link to it is operational. The routing protocols may modify the form of the periodic updates and the router may just send ‘no change’ information to its neighbors instead of transmitting the entire routing table. Similarly, in the case of any change in the routing table, it may send only the changed parameters with proper sequencing to indicate the appropriate place where the changes are to be incorporated. This helps in reducing the amount of data required to be transmitted for a periodic update.
Triggered updates. Triggered updates are sent by a router to its neighboring nodes if any new activity or change is detected in the network, which the router should immediately report to its neighbors instead of waiting to transmit it along with the regular update. A triggered update may be sent by a router when it detects any one of the following:
- a node failure or a link failure making one of its neighbors unreachable,
- the introduction of a new link into the network, one end of which is connected to this router,
- a new node that has joined the network and is directly connected to the router,
- changes in the link parameter,
- a change in state of any interface of the router from active to inactive/failed, or vice versa.
Synchronized updates. These occur when all the routers in the network or a network segment exchange routing table updates at the same instance in time. A synchronized update causes an abrupt increase in bandwidth utilization and can cause collisions in the network.
Routing loops. A routing loop is created when a packet is forwarded between a set of routers without ever reaching the destination. In a routing loop, the packet continuously traverses through the same set of routers in a unidirectional manner. A routing loop is generally created if there is some flaw in the route configuration by the routing algorithm. It may occur in the case of user‐defined routes using a static routing protocol in a huge network that is prone to configuration errors by the network administrator owing to its complexity. A routing loop is also created in the case of a slowly converging network, as the route forwarded to the routers may keep changing while the packet is in transit when the network has not converged. A packet in the routing loop may finally get lost. It unnecessarily consumes network bandwidth as well as processing capacity, processing time, and buffer space of the intermediate routers.
Count to infinity. In a count to infinity, packets are routed infinitely within the network. The packet may finally be delivered to the destination after a relatively huge amount of delay or it may continue being routed within the network. It is different from the routing loop as in this case the packet may not enter a loop and may be moving in a random path inside the network without any uniform pattern or routing loop. It creates the same set of problems in a network that is created by a packet in a routing loop.
Split horizon. Split horizon is a technique to prevent routing loops in a network. Split horizon states that when a router receives a route from its neighbor, the router should not propagate the route back to the neighbor from which it has received the route. Split horizon is achieved by a technique called route poisoning. In route poisoning the parameter value for the interface through which the update was received is set to an infinitely large or infinitely small value so as to make it the last choice in the best route selection or indicate the unavailability of the poisoned route.
6.2.1 Routing Information Protocol
Routing Information Protocol (RIP) [9] is a true distance vector protocol that exclusively works on metrics based on hop count. It is an intradomain routing protocol that, though not the best routing protocol, is the protocol with least overhead for a small to moderate‐sized network. The router transmits its routing table along all its interfaces to the neighboring routers every 30 s. However, a router may be configured not to broadcast the routing information along one or more of its interfaces, but to continue to receive updates along the same interfaces. An RIP host is said to be in active mode when it receives routing updates from its neighbors as well as transmitting its routing table to its neighbors. A RIP host is defined as operative in passive mode if it receives routing information from its neighbors but does not transmit its routing table to its neighbors. The terminal routers are generally configured in passive mode.
The RIP works well in a small autonomous system. It is not an effective protocol for huge networks with plenty of routers or in networks with slow connectivity links. The protocol is ineffective in these operating scenarios owing to parameters such as a maximum hop count of 15, the transmission of routing table updates after every 30 s, and maintenance of timers such as route invalid timer, hold‐down timer, and route flush timer. The default values and performance of these timers suit only a small network with optimum bandwidth links. A hop count of 15 is considered to be sufficient for RIP, as it is an Interior Gateway Protocol (IGP), and a network packet is not expected to cross the hop count in general operating conditions in a moderate‐sized network.
Routing table. The routing table in RIP primarily has three columns: the destination network, the next node, and the metrics. The destination column has entries for the various destination network addresses available in the AS. The next node column contains information regarding the interface on which the traffic should be routed to reach the destination. Metrics are based on minimum hop counts required to reach the destination. Hop count is the number of links that have to be covered to reach the destination node. By default, the maximum reachable router in RIP requires a hop count of 15; a hop count of 16 is treated as unreachable. A packet is dropped as soon as it crosses a hop count of 15, and the router dropping the packet sends an ICMP message to the source of the packet indicating ‘destination unreachable’. This is done to prevent infinite loops and endless travelling of a packet on the Internet owing to faulty routing. If a router is configured for a few more metrics, a network packet may be dropped even before reaching a hop count of 15.
Protocol timers. RIP involves regular transmission of route updates to its neighbors and rebuilding its routing table based on the route information received from its neighbors. It has to maintain a few timers to indicate the time between forwarding updates, awaiting updates, declaring a link unreachable, or flushing the entries from the routing table.
The route update timer is used by every router to determine the time when it should transmit its entire routing table to its neighbors. The default value of the route update timer is 30 s, i.e. the route update information is sent out by each router along its exit interfaces to the neighbor routers every 30 s.
The route invalid timer is maintained to determine the validity of an entry for a link in the routing table of a router. If a router does not receive information about a link from the route updates of any of the neighbors for six consecutive updates, i.e. 180 s, then it classifies the route as invalid and broadcasts this information to its neighbors during the next route update.
A route flush timer determines the time between declaration of a route as invalid and its removal from the routing table. The entry for this invalid route is not immediately removed from the routing table of the router that has declared it invalid as the router may receive an update about the link from any of its neighbors after it has declared the link as invalid. The router also takes some time to propagate the information about the invalid link to its neighbors. This type of implementation generally happens in the case of unstable links.
The hold‐down timer defines the period for hold‐down. Hold‐down is used to prevent any change in the routing table owing to routine update messages, which may wrongly reinstate a link that has gone down. As a link goes down, it is detected by the routers connected to it. The routers in turn recalculate the routing table and forward it to their neighbors in the form of triggered updates. The triggered updates are further transmitted by the neighbors that have just received them, and this initiates a wave of triggered updating. However, a router that has recently modified its routing table from a triggered update may receive a routine routing table update from a router that is not aware of the particular link failure. This routing update may lead to reinstating the metrics for the unavailable link. Hold‐down tells the routers to hold down any further changes until the hold‐down period is over.
Types of packet
In RIP, a router may send a routing table update to its neighbor in response to a message received from it or it may send a routing table update that does not correspond to any routing update request. Therefore, RIP packets are of the following two types:
- Request packets. The request packet is sent to a neighbor router requesting its complete or partial routing table.
- Response packets. The response packet is sent by a router in response to a request packet received from any of the neighboring routers. The response packet may contain the entire routing table or a partial routing table. In addition to transmission of the response packet on receipt of the request packet, the response packet is also sent every 30 s to all the neighbors to share its routing table.
RIP versions
RIP version 1, defined in RFC 1058, supports only classful routing, while RIP version 2, defined in RFC 2453, supports classless routing [2, 10]. Thus, in RIP version 1, the subnet information is not transmitted during routing table updates and the default subnet has to be used as per the defined class. The first three bits of the IP address are used to determine the class of the network address, and thereafter the subnet mask corresponding to that class is used. RIP version 1 uses classful routing because it was introduced before the concept of subnet was introduced or before classless interdomain routing (CIDR) was implemented. RIP version 2 is also known as prefix routing as it sends the subnet information during route updates. RIP version 1 and RIP version 2 are fully interoperable, with forward compatibility as well as backward compatibility.
RIP uses UDP for exchange of update information among routers. The format of the RIP message is different in version 1 and version 2. One RIP datagram can carry information of up to 25 entries of the routing table. As shown in Figure 6.1, the size of a UDP datagram is 512 bytes, eight bytes of which are used by the UDP header and the remaining 504 bytes can be used by the RIP. Followed by the UDP header is a 1 byte ‘Command’ field and a 1 byte ‘Version’ field followed by two reserved bytes generally padded with ‘0’ as indicated in Figure 6.2. These four bytes are known as the RIP header, which is followed by the RIP message. The RIP header is common in version 1 and version 2. The RIP message starts with two bytes for the ‘Address Family Identifier’. This field is common in version 1 as well as version 2. The ‘Command’ field, which is of 1 byte, can have values ranging from 1 to 5. The details of the values are:
- 1‐ indicates that it is a request message asking the recipient to send partial or full routing table to the sender of the message.
- 2‐ indicates that it is a response message to a request and contains the entire or partial routing table of the sender in response to the request received from the receiver. A value of 2 in the command field is also transmitted when the sender sends an update message without any specific request message.
- 3‐ indicates Trace On. This is obsolete and not in use.
- 4‐ indicates Trace Off. This is obsolete and not in use.
- 5‐ is reserved for use by Sun Microsystems for its use.

Figure 6.1 UDP datagram for RIP message.

Figure 6.2 RIP header.
The values of 6, 7, and 8 were defined in RFC 1582 and are used to indicate triggered request, triggered response, and triggered acknowledgement respectively. The values of 9, 10, and 11 were defined in RFC 2091 and are used to indicate update request, update response, and update acknowledgement respectively.
The ‘Version’ field indicates the RIP version and generally has a value of 1 or 2 to indicate the version of the RIP. The 4 bytes ‘Address Family Identifier’ stores the information regarding the type of network address in use. As the IP address scheme is used in general, the ‘Address Family Identifier’ field should have a value of 2 as defined in RFC.
In RIP version 1, the ‘Address Family Identifier’ is followed by two reserved bytes generally with ‘0’ padding, and thereafter it has four bytes for the IP address of the host or network, eight bytes for ‘0’ padded reserved fields, and four bytes of ‘Metric’. As shown in Figure 6.3, this entire RIP message comprising the ‘Address Family Identifier’, ‘IP Address’ and ‘Metric’ can be repeated 25 times with a common RIP header in an RIP datagram.

Figure 6.3 RIP version 1 message format.
The format of the RIP header remains the same in RIP version 2. In RIP version 2, the RIP message comprises two bytes of ‘Address Family Identifier’ followed by two bytes of ‘Route Tag’ followed by four bytes each for ‘IP Address’, ‘Subnet Mask’, ‘Next Hop’, and ‘Metric’. The RIP version 2 message format is shown in Figure 6.4. The ‘Route Tag’ field is used to support multiple routing protocols and to distinguish between the RIP‐based routes and other protocol‐based routes. The ‘Subnet Mask’ introduces the classless addressing.

Figure 6.4 RIP version 2 message format.
Limitations of RIP. A few limitations of RIP [3] are as follows.
The protocol is not dependent on the bandwidth of the link in deciding a route to destination. As shown in Figure 6.5, if router A is directly connected to router B on an 8 kbps public switched telephone network (PSTN) link and router A is connected to router B through router C with a 155 Mbps link across both hops, RIP would route the packet on the direct link of 8 kbps between router A and router B rather than on a much faster link of 155 mbps between router A and router B through router C. This directly affects the quality of transmission in the case of real‐time traffic carrying voice and video packets, which calls for QoS parameters. However, a network administrator can deceive the RIP by manipulating the hop count entry in the routing table and increasing the value of the hop count for the slower link to a value greater that the hop count for the faster link.

Figure 6.5 A sample network of routers.
The protocol supports only equal‐cost load balancing and does not provide for a mechanism to balance the traffic load across links with different costs. The protocol sends all the packets through the cheapest path in terms of hop count. In the case of a lower‐bandwidth link, this may lead to congestion, but that does not change the routing strategy for RIP by selecting a less congested path as it will keep trying to send all the packets through the least hop count path only. The traffic is also not distributed across alternative routes to reach the destination as the routing table does not contain any information to support the load balancing. In the case of Figure 6.5, the entire traffic will be forwarded directly from router A to router B and will never be shared across both routers, i.e. directly from router A to router B as well as from router A to router B via router C.
As the routers broadcast their routing tables to all their neighbors every 30 s, this leads to network congestion and consumption of bandwidth. Owing to the delay of 30 s in transmitting the routing updates, it takes time for the network to converge. If the network has a few unstable links, convergence becomes very difficult. Moreover, it also leads to the forwarding of packets to unavailable links, information about which has not yet been received by the router on account of the slow convergence.
The protocol has a mechanism for loop detection by using hop count and dropping a packet completing 15 link hops, but it does not have any mechanism for avoidance of routing loops.
6.2.2 Interior Gateway Routing Protocol
Interior Gateway Routing Protocol (IGRP) is a distance vector routing protocol that was invented by Cisco Systems Inc. in the mid‐1980s and is proprietary to it. IGRP can be used in a network that comprises all Cisco routers. The protocol was introduced to overcome the drawbacks of RIP and introduce a protocol that overcomes the limitations of RIP to an optimum extent. The protocol supports a maximum hop count of 255 with a default value of 100 hops. This makes the routing protocol highly scalable, and it can be implemented in huge networks.
The metrics to determine the most suitable path are not simply based on a single parameter, but can be calculated based on a number of parameters, commonly referred to as ‘composite metrics’. The default parameters used for calculation of metrics are based on the bandwidth of the path and the cumulative interface delay, which is the delay in the network. The bandwidth of the path is based on the minimum bandwidth link on the path. In addition to these default parameters, a few more parameters such as channel occupancy of the link (load), reliability of the link based on current error rate, hop count, and maximum transmission unit (MTU) can be used for metric calculation. MTU indicates the maximum packet size that can be transmitted through the path without fragmentation. These parameters have different permissible ranges of values. The value of bandwidth can range between 1200 bps and 10 gbps; the value of delay can range between 1 and 224, and the values of load and reliability can range between 1 and 255. Cisco has predefined links and associated bandwidth for token ring, ethernet, and T1. A reliability scale of 255 indicates a 100% reliable link or 100% load. In addition to these metrics, IGRP permits the configuration of a few user‐defined constants to add to the computational algorithm for composite metrics. All these parameters are combined by an algorithm [2] that is tuned by assigning specific weights to each parameter finally to arrive at the resultant metrics. The composite metrics are calculated as follows:

where

Based on the above calculation, the smaller the value of the metrics, the better the path.
IGRP is a classful network protocol and so does not transmit any subnet‐related information as it deals with the default subnet based on network class. RIP as well as IGRP, being classful, waste a lot of IP address space, and this is a major disadvantage of these protocols. All the routers in an autonomous system use a common AS number to identify and exchange routing information among them. The value of the AS number ranges between 1 and 65 535. Identification of the network by an AS supports convergence of various networks and flexibility to run different routings in the same network.
The protocol can load balance [11] among six unequal links. The bandwidth as well as the other parameters can be used to decide on the load balancing across variable metric links ranging from the best link to the worst link. However, the traffic will be routed through the worst link only if it is above the predefined range of metrics acceptable for transmission along the link. The range of metrics by which a load can be balanced across unequal cost paths can be defined by the network administrator and is known as variance. The amount of traffic routed across these links with different metrics is in the same ratio as the metrics of the link, i.e. the better the metrics, the more traffic is routed through it as compared with a link with poorer metrics. Although RIP can also support load balancing, it is based on a single parameter, which is hop count, and can share data across links with the same number of hops to the destination. IGRP also supports sharing of a single stream of traffic across two equi‐bandwidth links in a round robin order. If one of these eqi‐bandwidth links fails, the entire traffic is automatically switched over to the other link. IGRP also uses a few techniques such as hold‐downs and split horizons to enhance the stability of the protocol.
Protocol timers. IGRP uses the same set of protocol timers as defined in RIP, but with a difference in their values. The use of these timers, however, remains the same as that in RIP. The route update timer has a default value of 90 s, as against a default value of 30 s in RIP. This leads to lesser exchange of routing tables between the routers, leading to more effective utilization of bandwidth for actual data than for exchange of routing tables between the routers. This leads to reduced flooding of the network by the routers themselves.
The value of the route invalid timer is 270 s, which is calculated as 3 times the route update timer. The value of the flush timer is 630 s, which is calculated as 7 times the value of the update timer. The value of the hold‐down timer is 3 times the route update timer with an additional buffer of 10 s.
Key improvements over RIP. IGRP was developed as an attempt at improvement over RIP. The key advantages of IGRP over RIP are as follows:
- It can be used for larger networks.
- The routing table is updated every 90 s to reduce flooding, link congestion and bandwidth utilization.
- It uses bandwidth and cumulative interface delay as minimum composite metrics.
- It can load balance between six different links.
- It uses the AS number as a unique identifier to identify all the routers in an autonomous system.
- It shares a single stream of traffic across two equi‐bandwidth links in a round robin fashion, with switchover to one of the links in the case of failure of the other.
6.3 Link State Protocols
In a link state protocol, the router exchanges its network topology information in terms of its links and interfaces with its neighbors. The neighboring nodes further transmit this information to its other neighboring nodes, and the process continues to enable the topological information about each node to reach across the network to all the routing nodes. Each router in the autonomous system has complete information about the topology of the network, which it uses to determine the best path to any other node in the network. In link state routing, the router decides the next hop router or the egress interface link from it on the basis of the best end‐to‐end path to the destination.
As the routers in the link state protocol have an entire topological view of the network, it is the protocol most suited to traffic engineering and implementation of QoS. As the router is aware of the end‐to‐end links, various parametric constraints can be imposed on the links to cater for the assured level of service agreed in the SLA. But knowledge of the entire network requires memory and processing capability at each routing node. As the size of the network increases, the requirement of memory for storage of the topology and processing capacity to calculate the entire network topology increases. The size of topological data exchanged between the neighbors also increases, leading to traffic congestion. Considering these requirements, the link state protocols are not highly scalable and are confined within the AS for intradomain routing.
Each router participating in link state routing creates a packet called a link state PDU (LSP). An LSP contains information about the neighbors of the router, the type of link, and the distance or cost of reaching the neighbor. The router discovers its neighbor after booting by using a reachability protocol that uses a ‘hello’ packet. LSPs contain a serial number to help in sequencing and timeout by unique identification because LSPs are frequently generated by each router. An LSP is generated when the router boots up and whenever changes are detected in its interfaces or in its links. LSP packets are flooded in the entire network. The flooding of the packet is through the neighbors. Each routing node sends its LSPs to its neighbors. Each neighbor checks the sequence number of the LSP and, if it detects it to be a new LSP that the node has not transmitted earlier, it transmits it to all its neighbors except the one from which the LSP was received. In this way, the neighbors generate a wave of LSP transmission across the network, covering all their neighbors in one wave, these neighbors cover all their other neighbors, and the process continues until the LSP reaches the entire network. Therefore, each router receives the PDUs of all other routers in the network. These LSPs are stored in the link state database of each router.
All the routers compute the entire network topology using these PDUs stored in the link state database and creates the shortest path tree and the routing table. Thus, the link state database should be the same across all the routers, as it is built by collecting the LSPs of all the routing nodes. However, the routing table generated by each router would be different as the routing table will contain entries related to the shortest path from the routing node to every other node in the network by forming the shortest path tree in which the routing node is at the root.
The modern link state routing protocols resolve the scalability issue of the link state protocol by dividing the AS into smaller areas and running the link state routing protocols within smaller areas with the provision of communication among these areas. Splitting the AS into smaller areas also reduces the memory and processing requirement of the routing protocol.
The major advantage of link state routing over distance vector routing are as follows:
- All the routers in the network have an entire topological view of the network.
- Each router in the network builds its own complete network map based on the LSPs received from all the routing nodes.
- As the LSPs are flooded, they immediately spread across the network and thus help in quick convergence of the network owing to their faster receipt at the routing nodes.
- The LSPs are not sent at regular intervals, but only on detection of change in the link or interface of the router, and once when the router boots up.
- Scalability issues of implementing link state routing in a huge AS can be resolved by using the hierarchical or the layered approach of separating the network into smaller areas.
6.3.1 Open Shortest Path First Protocol
Open Shortest Path First (OSPF) [2, 9] routing protocol version 2 is defined in RFC 2328. OSPF is an open standard routing protocol that supports only IP routing and converges fast even in a large network. The protocol supports classless IP addressing, VLSM, and multicasting. It can select multiple equal‐cost paths between the source and the destination and hence can perform load balancing by distributing the traffic across the equal‐cost paths. The metrics of the route refer to the cost of the path and can be based on a single parameter or a combination of parameters such as delay and throughput. A router can have multiple routing tables in it, each based on a different metric. The default metric used by the protocol is bandwidth. The metric formula is
where the numerator value is configurable.
The protocol separates a bigger network into smaller networks called areas, the routing is dealt with separately within each area, and all the areas are interconnected by a backbone. As OSPF is a hierarchical protocol, it is fast, scalable, and stable. OSPF prevents the corruption of routing tables as it can authenticate the node transmitting the route advertisement.
Areas. In OSPF, an area [2] is the grouping of routers, links, and the associated OSPF network. Each area is uniquely identified by its 32 bit area ID. An area ID ‘0’ represents the backbone area. The backbone area must be contiguous as there cannot be separated backbones in the AS with the same area ID. As a router can be a member of one or more areas, the area ID is associated with the particular interface of the router that belongs to the area. As the routers lie on the border of two separate areas, any link in OSPF will belong only to one of the areas. The non‐backbone area is also known as the secondary area, and the backbone area is known as the primary area. The non‐backbone area must be directly connected to the backbone area through one of its routers that is common to the non‐backbone area as well as the backbone area. The router inside an area should maintain the topological information of only the area to which it belongs. The information is stored in the form of a topological database. The topological database of all the routers within an area should be the same.
Routers. For unique identification of a router, it is given a 32 bit router ID (RID), which is different from its IP address. However, as the IP addresses of the routers are also unique, many implementations of OSPF use the IP address of one of the interfaces of the router, e.g. the lowest‐ or the highest‐number IP address, to generate the RID. Depending on the connectivity of the router in the area, which is also depicted in Figure 6.6, the following kinds of router have been defined in OSPF:
- Internal router. All the interfaces of this router are in the same area. Internal routers may be connected to each other or to the area border router. They maintain the topology database only of their area.
- Backbone router. This is a router with an interface in the backbone area, i.e area ID 0.
- Area border router (ABR). This router connects two or more areas. It has at least two different interfaces in two different areas. There is flooding of information in an area. The ABR gets the range of addresses in the area from the flooding and passes it on to the other areas. ABRs can also be backbone routers. They maintain the topology database of each of area to which they are attached and run a shortest path first algorithm for each area separately.
- Autonomous system border router (ASBR). These routers connect the AS to which they belong to some other AS. One of the interfaces of such routers is generally located in the backbone, i.e. area ‘0’, or these are also the ABR routers.

Figure 6.6 OSPF routers and their areas.
A multiaccess network has more than two routers attached to it. The network may allow broadcasts using a broadcast address recognized by all the routers, or the network may not possess the broadcast capabilities and each packet is addressed to only one destination router. In the case of a multiaccess router, a designated router (DR) and a backup designated router (BDR) are deployed to reduce the flooding of the network with exchange of link state advertisements (LSAs) between the routers [10]. The interface of each router in the network has a priority attached to it, depicting its ability to become a DR or BDR. The router with the highest priority is selected as a DR. Generally, the default priority attached to the router is 1, and a 0 priority attached to the router indicates its inability to serve as a DR.
- Designated router. In a multiaccess network, adjacencies are formed between the router and the DR to prevent bandwidth consumption of the network by the formation of adjacencies between every pair of routers. The DR has adjacencies with all the routers in the network and is the only source to forward LSAs.
- Backup designated router. The BDR assumes the role of a DR when the DR fails. As it is in active standby mode, it has adjacencies with all the routers in the network, as in the case of a DR.
Neighbor routers. Two or more routers can be neighbor routers [10] if they are in the same area and share a common network segment. As OSPF supports authentication, they may define a security passphrase among each other.
The neighbor discovery is done by regular exchange of ‘hello’ packets on each of the interfaces. The packet contains the RID of the routers whose ‘hello’ packet has been received by the router. When a router receives a hello packet with its RID in it, the two routers enter into neighbor relationship.
The multiaccess network should elect a DR and a BDR. In the case of such a network, the ‘hello’ packet will also contain the information required for electing a DR, i.e. router priority, DR identifier, and the BDR identifier. The router with the highest router priority in the segment becomes the DR. The tie in the priority, if any, due to the same router priority for DR is resolved by electing as the DR the router that has the higher RID. The same election process is thereafter followed for electing the BDR, but in this case the DR is not eligible to participate in the election of the BDR.
The neighbor routers form an adjacency relationship when they synchronize their topology database with each other. Synchronization is obtained by exchanging link state information, and it is done to ensure the same contents of the topology database in the neighbor routers. In the case of a multiaccess network, the router does not establish a direct adjacency relationship with all its neighbors, but it is done through DR and BDR as shown in Figure 6.7.

Figure 6.7 Neighbor relation in point‐to‐point network versus multiaccess network.
The process of topology database synchronization is done by exchange of database information as well as the exchange of database entries between the routers. The neighbors that desire to enter an adjacency relationship exchange database description packets with each other. The database description packet contains the listing of the LSAs available with the router. The router that receives the database description packets checks its topology databases to detect whether the neighbor has any more recent LSA or any LSA that is missing in the receiver’s topology database. The router then requests the updated information using a link state request. On receiving the link state request, the recipient of the request sends those specific LSAs to the router that has requested the LSAs. On receiving an LSA, the router sends an acknowledgement to the sender.
Links. A connection in a network is referred to as a link. It is the network or router interface assigned to a network through which a packet may be received by the network or forwarded by the network. Every interface of a router is associated with a link. However, a single link may have one or multiple IP addresses. A link is generally in one of two states: up or down. A link can sometimes be in a state that is neither up nor down, but has a varying degree of congestion. Four different types of link [9] are used in OSPF:
- Point‐to‐point link. This directly connects two routers without any other router, host, or network in‐between.
- Transient link. This is a network with multiple routers connected to it.
- Stub link. This is a network connected to a single router.
- Virtual link. This is a link created by the administrator between two routers when the actual link between the two routers goes down. The virtual link is created by connecting the two routers with a number of intermediate routers in‐between, thus forming a continuous, but longer path.
Operation. The protocol exchanges link state information every 30 min, and the changes occurring in the network during this time are communicated to other routers using link state advertisements (LSAs). The LSAs are exchanged only within their area. The routers maintain the topological database, which is known as the link state database (LSDB). The LSDB stores the LSAs received from all the other routers in the area. The LSDB of all the routers in the area should have the same contents. The RID is used to tag an LSA in the LSDB to recognize the router from which it was received. Owing to the hierarchical design of OSPF, the routers are not required to maintain the path for all the other routers in the AS.
The border router advertises the range of addresses available in the area and not the individual address of each of the routers in the area. Thus, all the border routers maintain a database of the range of addresses corresponding to every border router and the shortest route to the border router in their area. This helps to prevent the processing of the entire address by the border router to detect the area to which the packet should be forwarded, as the same can be done by processing a portion of the address only. OSPF uses Dijkstra’s algorithm to create the shortest path tree for each router. Although the LSDB is the same in all the routers in the area, the shortest path tree will be different in all the routers, as it has the corresponding router in the root node of the tree and thereafter the tree is generated connecting all the other routers. The routing table is built from this tree by detecting the shortest path from the root node, i.e. the router itself, to every other router in the network [1]. This routing table is the final lookup table used by the router for forwarding the packets by selecting one of its interfaces based on the routing table entries.
6.3.2 Intermediate System to Intermediate System Protocol
Intermediate System to Intermediate System Protocol (IS‐IS) defines an intermediate system as ‘a device used to connect two networks and permit communication between end systems attached to a different network’. Intermediate system is ISO terminology for a router. IS‐IS is a link state protocol that is highly scalable and has fast convergence, and the complete topological view supports implementation of traffic engineering, which makes it a favorite protocol for the service providers. IS‐IS Protocol supports two different network layer protocols – IP and OSI connectionless network service (CLNS) [2, 3]. The IS‐IS Protocol can also be used in a dual‐network environment comprising IP as well as OSI. By supporting both IP and OSI, the protocol can interconnect dual routing domains with dual or pure (IP or OSI) routing domains delivering the packets to IP hosts, OSI end system, or a dual‐end system.
IS‐IS was designed in 1987 as a dynamic routing protocol for CLNP under the ISO 10589 standard and later adapted for IP as per RFC 1195 in 1990. In the year 2008, IPv6 support was added to IS‐IS by RFC 5308, and RFC 5120 permitted the multitopology (IPv4 as well as IPv6) concept. IS‐IS supports classless interdomain routing with variable subnet length masking.
Two‐level protocol. IS‐IS is a two‐level hierarchical routing protocol. The entire network is split into small areas, and the routing within an area is taken care of by level 1 routing and the routing outside the area is taken care of by level 2 routing [12]. Thus, the level 2 routers form the backbone of the network, and each area should have at least one level 2 router to connect to the backbone. Each node belongs to one area only, and there is no overlapping of the areas. However, the same router can be in level 1 as well as in level 2, or it may belong to any one of the levels only. The border between the areas is based on the links that connect routers belonging to separate areas. The formation of areas and the levels of the routers can be visualized from Figure 6.8. Level 1 routing is responsible for routing within the area. Level 2 routing is responsible for delivery of the packet to the area that has the destination host. When a packet is sent from a source to a destination, level 1 routing forwards the packet from the source that is contained in its area to the nearest level 2 intermediate system. Now the level 2 IS forwards the packet to the destination area where it is sent from the level 2 IS to the level 1 IS containing the destination. Then the level 1 IS routes the packet to the destination within the area.

Figure 6.8 Areas in IS‐IS depicting interconnections between level 1 and level 2 routers.
In link state routing, the routers are aware of the entire network topology. But as the network is divided into areas in IS‐IS, the level 1 router is aware only of the topology of its area, which comprises level 1 and level 2 routers in the area. As the level 1 router is responsible only for the intra‐area routing, the link state database of the level 1 router comprises information related only to the routers in its area. However, this information is not used to find the optimal path if a packet has to be sent outside the area because the level 1 router sends the packet to its nearest level 2 router if the packet has to be sent outside the network. Forwarding the packet to the nearest level 2 router and thereafter routing at level 2 may not lead to the shortest path. This can be well understood from the example of a sample network depicted in Figure 6.9, on the assumption that all link costs are the same. For example, node B has to send a packet to node H. Node B being a level 1 router will forward the packet to its nearest level 2 router, i.e. node D, and thereafter the route followed by the packet will be node D → node E → node F → node I → node C → node J → node H. Alternatively, if node B is not to forward the packet to the nearest level 2 router for interarea forwarding, the packet would follow the path node B → node A → node C → node J → node H, which is optimal by comparison with the previous route. IS‐IS specification mentions about four different types of metric: cost, delay, expense (monitory cost involved in using the link), and error (measured in terms of the probability of residual error associated with the link).
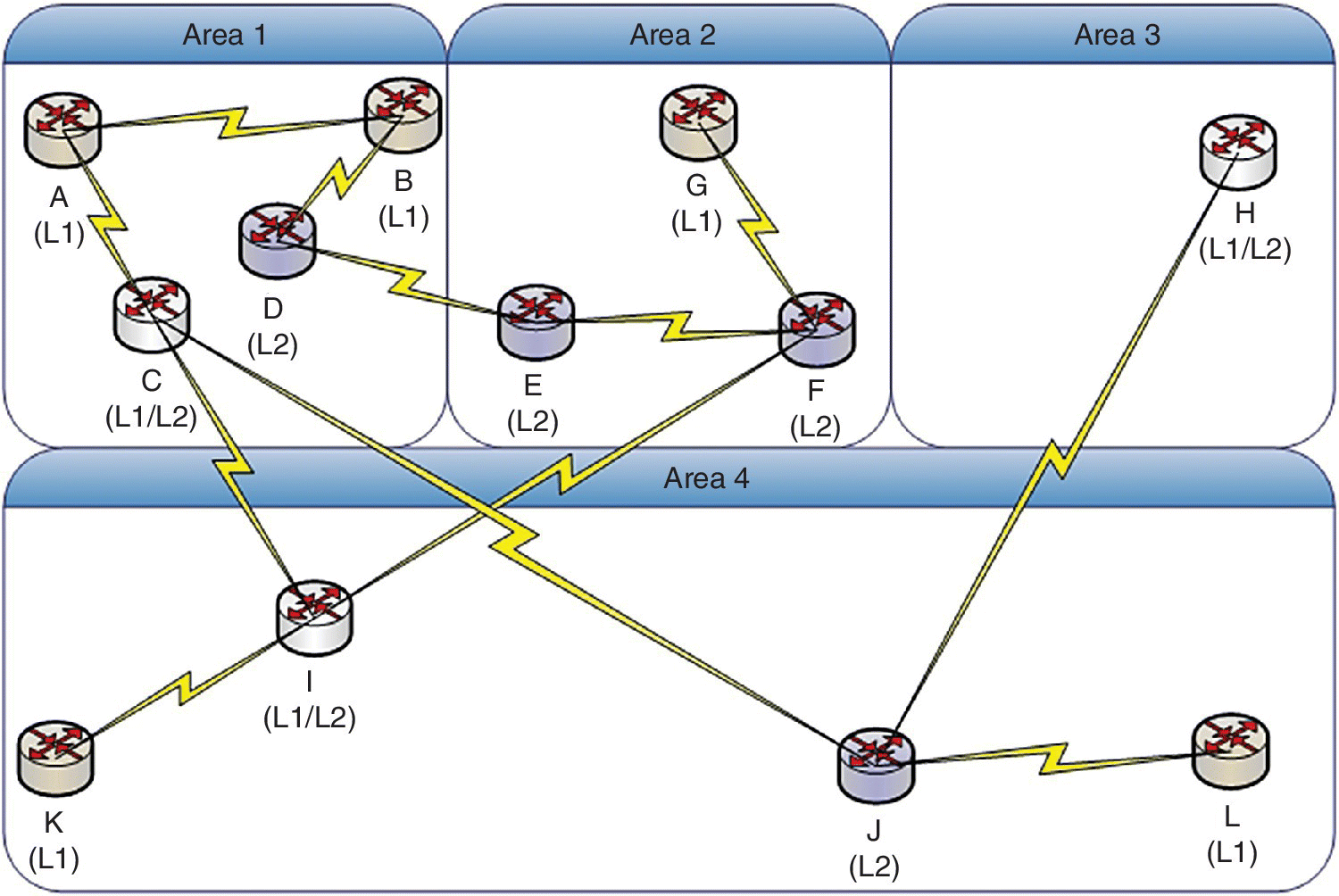
Figure 6.9 Level 1 (L1) and level 2 (L2) routers in the areas in IS‐IS routing to depict suboptimal routing from level 1 to level 2.
A router at level 2 is connected to other level 2 routers that may be in the same area or in a different area. As the level 2 router is responsible for interarea routing, the link state database of the level 2 router contains information about all other level 2 routers in the network. If a router is only in level 2, it does not contain any topological information about its area, as intra‐area routing is beyond its scope. However, a level 1/level 2 router should have topological information about its area as well as information about all other level 2 routers (backbone). The level 1/level 2 router can have its neighbors in the same area (level 1 routers, level 2 routers in the same area) as well as in other areas (level 2 routers in other areas). It has to maintain a link state database for intra‐area routing and another link state database for interarea routing, and run two separate shortest path first algorithms separately on each of these databases.
Packets. There are four different types of IS‐IS packet used in the protocol:
- IS‐IS hello (IIH) packet. This is used to discover neighbors and maintain adjacencies. The IIH packet is sent every 10 s. It is different on P2P links and LANs. In order to be of full MTU size, the IIH packets are padded.
- Link state packet (LSP). An LSP has a fixed header and LSP contents. The LSP header comprises the LSP ID, the sequence number, the remaining lifetime, the checksum, the type (level 1, level 2), the attached bit, and the overload bit. The LSP contents comprise all the information pertaining to a router, such as adjacencies, connected IP prefix, area address, and/or OSI end systems. There is not only one LSP per router, but there is only one LSP per LAN network. There is only one LSP per LAN because a virtual node is assumed for an LAN, and this virtual node is called the ‘pseudo node’, which imitates a router and generates an extra LSP.
- Partial sequence number packet (PSNP). This is used for requesting LSPs and confirming the receipt of the link state information and acts as acknowledgements on P2P links.
- Complete sequence number packet (CSNP). This is used while distributing the complete link state information over LANs. The CSNP contains all the LSPs from the link state database. As all the routers should have the same LSPs in their link state database, CSNP helps to synchronize the link state database of those routers that have outdated or missing LSPs.
IS‐IS operation. Being a link state protocol, IS‐IS follows the outlined procedure of a link state routing for packet forwarding. An IS on booting or joining a network in IS‐IS discovers its neighbors on all its interfaces by sending ‘hello’ packets. The two ISs across a data link become neighbors only in the case of matching authentication and IS level. Each IS generates its LSPs based on the connectivity at its interfaces, and these LSPs are flooded in the network. All the ISs in the network construct the link state database from the flooded LSPs. The link state database is identical in all the level 1 routers of an area or in all the level 2 routers because it depicts the topology of the network or the area and it should be the same all across. The LSP database is used to construct the shortest path tree, which helps to build the routing table of each IS. Multiple equal‐cost shortest paths to the destination can also be computed by the algorithm. The LSP in a link state database has a lifetime of 1200 s, and the generator of the LSP should usually refresh the LSP every 900 s to prevent it from expiry and deletion from the link state database.
The protocol recalculates the shortest path in the case of any topological change in the network. The two‐level routing in IS‐IS provides an additional layer of security. The packets are confined within the area for level 1 routing and the packets are confined only at the backbone for level 2 routing. The topological information of one area is not known to the other area or the backbone. Moreover, as the broadcast is confined to the level and the area, the amount of traffic generated by the protocol is reduced and confined to its broadcast domain (area) only.
Flooding. Flooding of an LSP on a P2P link is different from the flooding of an LSP on an LAN. In the case of a P2P, when link adjacency is established, the two neighboring ISs exchange CSNP. Thereafter, missing LSPs are sent if they are not present in the CSNP after a request has been received for the same using PSNP. An LSP is active for its 20 s lifetime, before which it is refreshed in 15 s. For flooding in an LAN, a designated router (DR) is elected for each LAN based on priority. DR creates a pseudo node representing the LAN, which is shown in Figure 6.10, and the pseudo node has its LSP. DR also performs flooding in the LAN and multicasts the CSNP every 10 s. The ISs in the LAN check their link state database with reference to the CSNP and request specific LSPs by requesting the DR using PSNP.

Figure 6.10 Creation of a pseudo node by DR.
References
- 1 S. Mueller. Upgrading and Repairing Networks. Techmedia Publishers, 4th edition, 2004.
- 2 T. Lammle. Cisco Certified Network Associate Study Guide. BPB Publishers, 4th edition, 2003.
- 3 W. Stallings. Data and Computer Communications. Prentice Hall of India Publication, 8th edition, 2007.
- 4 C. M. Kozierok. The TCP/IP Guide: A Comprehensive, Illustrated Internet Protocols Reference. No Starch Press, 2005.
- 5 National Science Foundation, the launch of NSFNET. http://www.nsf.gov/about/history/nsf0050/internet/launch.htm.
- 6 National Science Foundation, Fuzzball: the innovative router. http://www.nsf.gov/about/history/nsf0050/internet/fuzzball.htm.
- 7 R. Graziani and A. Johnson. Routing Protocols and Concepts: CCNA Exploration Companion Guide. Cisco Press, 1st edition, 2012.
- 8 A. Johnson. Routing Protocols and Concepts: CCNA Exploration Labs and Study Guide. Cisco Press, 2007.
- 9 B. A. Forouzan. Data Communications and Networking. Tata McGraw‐Hill Publication, 4th edition, 2006.
- 10 L. Parziale, D. T. Britt, C. Davis, J. Forrester, W. Liu, C. Matthews, and N. Rosselot. TCP/IP Tutorial and Technical Overview. IBM Redbook, IBM Corporation, International Technical Support Organization, 1998.
- 11 Cisco system, interior gateway routing protocol, document ID‐26825. http://www.cisco.com/en/US/tech/tk365/technologies_white_paper09186a00800c8ae1.shtml.
- 12 Cisco system, intermediate system‐to‐intermediate system protocol. http://www.cisco.com/en/US/tech/tk365/technologies_white_paper09186a00800a3e6f.shtml.
Abbreviations/Terminologies
- ABR
- Area Border Router
- ARPANET
- Advanced Research Projects Agency Network
- AS
- Autonomous System
- ASBR
- Autonomous System Border Router
- BDR
- Backup Designated Router
- CIDR
- Classless Interdomain Routing
- CLNP
- Connectionless Network Protocol
- CLNS
- Connectionless Network Service
- CSNP
- Complete Sequence Number Packet
- DR
- Designated Router
- EGP
- Exterior Gateway Protocol
- ICMP
- Internet Control Message Protocol
- IGP
- Interior Gateway Protocol
- IGRP
- Interior Gateway Routing Protocol
- IIH
- IS‐IS Hello (Packet)
- IS‐IS
- Intermediate System to Intermediate System
- ISO
- International Organization for Standardization
- ISP
- Internet Service Provider
- LSA
- Link State Advertisement
- LSDB
- Link State Database
- LSP
- Link State Packet
- MTU
- Maximum Transmission Unit
- NSF
- National Science Foundation
- OSI
- Open Systems Interconnection
- OSPF
- Open Shortest Path First
- P2P
- Point to Point
- PDU
- Protocol Data Unit
- PSNP
- Partial Sequence Number Packet
- PSTN
- Public Switched Telephone Network
- QoS
- Quality of Service
- RFC
- Request for Comments
- RID
- Router ID
- RIP
- Routing Information Protocol
- UDP
- User Datagram Protocol
- VLSM
- Variable‐Length Subnet Mask
Questions
- Describe an autonomous system. Why is routing within an AS different from the routing between ASs?
- Differentiate between a neighbor discovery message and a neighbor reachability message.
- Explain the working of distance vector protocols.
- State the difference between the routing loop and count to infinity.
- Mention at least five factors that can trigger an update in a distance vector routing.
- How is the active mode of operation of an RIP node different from a passive mode of operation?
- Describe the format of a UDP datagram for an RIP version 2 message. It should include details about the UDP header, RIP header, and RIP message.
- State the advantages and limitations of RIP.
- Mention the improvements in IGRP over RIP.
- Explain the working of a link state protocol.
- Describe the various kinds of router in an OSPF along with their functionality.
- What are the different types of IS‐IS packet used in the protocol?
- What are the advantages of a two‐level protocol over a single‐level protocol?
- State whether the following statements are true or false and give reasons for the answer:
- Interior Gateway Protocol supports routing between ASs on the Internet.
- Synchronized updates lead to flooding.
- Split horizon is a technique used to prevent flapping.
- The frequency of exchange of routing tables between neighbors in RIP is 30 s.
- The edge/terminal routers in an RIP should necessarily be active routers.
- A route flush timer in RIP directly helps in routing loop avoidance.
- IGRP is a proprietary protocol.
- IGRP is a classless protocol.
- In IS‐IS, a level 1 router in one area can communicate with a level 1 router in another area only if there is a direct communication link between the two.
- IGRP and IS‐IS are distance vector protocols.
- For the following, mark all options that are true:
- Routing within an AS can be termed:
- intra‐AS routing,
- intradomain routing,
- neighbor discovery,
- route convergence.
- The maximum hop count implemented in RIP is:
- 8,
- 15,
- 100,
- 255.
- The following are Interior Gateway Protocols:
- OSPF,
- BGP,
- IS‐IS,
- EGP.
- A routing loop can be created by:
- flooding,
- faulty route configuration,
- split horizon,
- slow converging network.
- The following are types of link in OSPF:
- stub link,
- active link,
- virtual link,
- point‐to‐point link.
- Routing within an AS can be termed:
Exercises
- An RIP host is in active mode when it receives routing updates from its neighbors as well as transmitting its routing table to its neighbors. An RIP host is in passive mode if it receives routing information from its neighbors but does not transmit its routing table to its neighbors. The terminal routers are always in passive mode. Draw a state diagram for the RIP hosts.
- Assume that a network as indicated in Figure 6.6 (ignore the areas and consider only the routers) performs routing based on RIP with route poisoning implemented over it. In the network diagram, along with each of the routers, write down the routing tables exchanged between the routers in the first two rounds after booting. Necessary assumptions regarding IP addresses may be made.
- Assume that a network as indicated in Figure 6.9 (ignore the areas and consider only the routers) performs routing based on RIP. Select any three nodes and show the values of all the protocol timers every 10 s for the first 2 min. The network with all the nodes boot up and become operational at time t = 0. At time t = 15 s, node A fails; at time t = 30 s, node A becomes operational and node B fails; at time t = 45 s, node B becomes operational and node C fails; at time t = 60 s, node C becomes operational and node D fails; the sequence of failure of nodes and their subsequent coming up, involving node E, node F, node G, and node H, continues in the same manner for the first 2 min. Any other value, if required, may be assumed. What will be the values of the protocol timers in the same time period if the network is using IGRP?
- Assume the existence of a network running IGRP with node failure as explained in exercise 3. What will be the values of the protocol timers after every 10 s during the first 2 min? Now assume that the nodes fail and come up every 2 min in the same sequence as explained in exercise 3. Write down the values of the protocol times after every 1 min in a 15 min period for any three nodes.
- Consider the network given below, which uses RIP with load balancing. 100 MB data has to be transferred from node A to node B. What will be the amount of data that will flow over each of the links in the network? If the metrics are based linearly only on hop count, what will be the amount of data flowing over each link if the network has IGRP implemented with load balancing?

- Consider the network depicted in the figure below. It is planned to implement OSPF in the network. Divide the network into appropriate areas, including the backbone area, as depicted in Figure 6.6, and then identify the nodes as – internal routers, backbone routers, area border routers, and ASBR. Also, identify the point‐to‐point link, transient link, stub link, and virtual links (assumptions may be made to identify virtual links).

- In the solution network designed for exercise 6, identify the point‐to‐point link, transient link, stub link, and virtual links (assumptions may be made to identify virtual links).
- The network depicted in exercise 6 above has to implement IS‐IS routing, and so divide the network into suitable areas and identify the level 1 and level 2 routers.
- Consider the network given below. What would be the contents of the RIP message from each of the routers after bootup?

- Consider the network given in exercise 9. Assume that the network has stabilized and every node has its RIP routing table. Draw the RIP routing table of each node. Now the link between node 3 and node 5 goes down and the link between link 4 and link 9 also goes down. What would be the RIP message from node 3, node 4, node 5, and node 9 to its neighbor? What would be the contents of the RIP routing table of each node after the new topology stabilizes?