
Understanding Fault Tolerance
Identify the purpose and characteristics of fault tolerance.
In networking, fault tolerance refers to the ability for a device or system to continue operating in the event of a failure. Fault tolerance should not be confused with disaster recovery, which is the ability to respond to and recover from catastrophic events with no loss of data and no loss of data availability.
In practical terms, fault tolerance involves ensuring that when network hardware or software fails, users on the network can still access the data and continue working with little or no disruption of service. Developing a strong fault-tolerant system that ensures continual access to data is not an easy task, and it involves attention to many details. The following sections explore fault tolerance, establishing a fault-tolerant network design, and the impact failure can have on the network.
Today's business world relies heavily on networks and network servers. If these networks and servers were to fail, many businesses would be unable to function. Thus every minute a network is not available costs money. The exact amount of money it costs depends on the size of the organization and can range from a mild economic inconvenience to a crippling financial blow. The potential impact of a network failure often dictates the fault tolerance measures an organization implements.
Unfortunately, no fault-tolerance measures can guarantee 100% availability to network data or services, and fault-tolerance solutions that strive to meet this goal can be very expensive. But the costs associated with any fault-tolerance solution must be compared to the costs of losing access to network services and the reconstruction of network data.
Some hardware components are more likely than others to fail. Implementing a strong fault-tolerance strategy involves identifying the weakest links and employing strategies that can compensate when those weak links fail. Figure 10.1 provides a quick look at the failure rates of server hardware components.
Figure 10.1. Server hardware failure rates.

As shown in Figure 10.1, 50% of all server failures can be attributed to hard disks. The hard disk is 50 times more likely to fail than the motherboard and 12 times more likely to fail than memory. It should come as no surprise that when configuring a fault-tolerant system, hard drives receive special attention; after all, they do hold all the data. (Of course, it would be unwise not to consider fault-tolerance measures for other hardware devices as well.) The following sections identify common fault tolerance measures, beginning with the best known: Redundant Array of Inexpensive Disks (RAID).
RAID
RAID is a strategy for implementing fault-tolerance solutions that prevent hard disk failure. RAID combines multiple hard disks together in such a way that more than one disk is responsible for holding data. Instead of using a single large disk, information is written to several smaller disks.
Such a design offers two key advantages. First, the failure of one disk does not, in fault-tolerant RAID configurations, compromise the availability of data. Second, reading (and sometimes writing) to multiple smaller disks is simply faster with multiple hard disks than when using one large disk, thus offering a performance boost.
The goals of a RAID solution are clear: Decrease the costs associated with downtime, secure network data, minimize network disruption, and (selfishly) reduce the stress on the network administrator(s). Because a well-designed RAID system can accomplish all these goals, RAID is widely implemented and found in organizations of all sizes.
Several RAID strategies are available, and each has advantages and disadvantages. It is important to know what you are protecting and why before you implement any RAID solution; the particular RAID strategy used will depend on many factors, including associated costs, the server's role, and the level of fault tolerance required. The following sections discuss the characteristics of the various RAID strategies.
RAID 0
Although it is classified as a RAID level, RAID 0 is in fact not fault tolerant. As such, RAID 0 is not recommended for servers that maintain mission-critical data. RAID 0 works by writing to multiple hard drives simultaneously, allowing for faster data throughput. RAID 0 offers a significant performance increase over a single disk—but, as with a single disk, all data is lost if any disk in the RAID set fails. With RAID 0 you actually increase your chances of losing data compared to using a single disk because RAID 0 uses multiple hard disks, creating multiple failure points. Essentially, the more disks you use in the RAID 0 array, the more at risk the data is. A minimum of two disks is required to implement a RAID 0 solution.
RAID 0 writes data to the disks in the array by using a system called striping. Striping works by partitioning the hard disks into stripes and writing the data across the stripes, as shown in Figure 10.2. This strategy is also used by RAID 2, RAID 3, RAID 4, and RAID 5.

Advantages of RAID 0
Despite the fact that it is not fault tolerant, RAID 0 is well suited for some environments. The following are some of the advantages of RAID 0:
Ease of implementation— RAID 0 offers easy setup and configuration.
Good input/output (I/O) performance— RAID 0 offers a significant increase in performance over a single disk and other RAID solutions by spreading data across multiple disks.
Minimal hardware requirements— RAID 0 can be implemented with as few as two hard drives, making it a cost-effective solution for some network environments.
Disadvantages of RAID 0
You cannot have the good without the bad. For a number of reasons, a RAID 0 solution may not be appropriate:
No fault tolerance— Employing a RAID solution that does not offer data protection is a major drawback. This factor alone limits a RAID 0 solution to only a few network environments.
Increased failure points— A RAID 0 solution has as many failure points as there are hard drives. For instance, if your RAID 0 configuration has five disks and any one of those drives fails, the data on all drives will be lost.
Limited application— Because of the lack of fault tolerance, a RAID 0 solution is practical for few applications. Quite simply, it's limited to environments where the performance of I/O outweighs the importance of data availability.
Despite its drawbacks, you might encounter RAID 0.
Recovering from a Failed RAID 0 Array
Anyone relying on a RAID 0 configuration to hold sensitive data is bold. The bottom line is, there is no way to recover from a failed RAID 0 array, short of restoring the data from backups. Both the server and the services it provides to the network are unavailable while you rebuild the drives and the data.
RAID 1
RAID 1 is a fault-tolerant configuration known as disk mirroring. A RAID 1 solution uses two physical disk drives. Whenever a file is saved to the hard disk, a copy of the file is automatically written to the second disk. The second disk is always an exact mirrored copy of the first one. Figure 10.3 illustrates a RAID 1 array.
Figure 10.3. A RAID 1 array.

RAID 1 writes the same data to the hard drives simultaneously. The benefits of having a duplicate copy of all saved data are clear, and on the surface, RAID 1 may seem like a very fault-tolerant solution. However, it has a couple drawbacks. First, RAID 1 has very high overhead because an entire disk must be used to provide the mirrored copy. Second, a RAID 1 solution is limited to two hard drives, which limits the available storage capacity.
Another RAID strategy that falls under the category of RAID 1 is disk duplexing. Disk duplexing is a mirrored solution that incorporates a second level of fault tolerance by using a separate hard disk controller for each hard drive. Putting the hard disks on separate controllers eliminates the controller as a single point of failure. The likelihood of a failed disk controller is not nearly as high as the likelihood of a failed hard disk, but the more failure points covered, the better. Figure 10.4 shows a disk duplexing configuration.

Advantages of RAID 1
Although it is far from perfect, RAID 1 is widely implemented in many different network environments. The following are a few of the advantages of RAID 1:
Fault tolerance— RAID 1 is a fault-tolerance solution that maintains a mirrored image of data on a second hard drive in case of failure. Disk duplexing adds extra fault tolerance by using dual hard drive controllers.
Reduced cost— RAID 1 provides fault tolerance by using only two hard disks, thereby providing a cost-effective method of implementing a fault-tolerance solution.
Ease of implementation— Implementing a RAID 1 solution is not difficult; it can be set up quite easily. The procedures and methods for implementing the hardware and software are well documented.
NOTE
Sizing the Mirror Because mirroring involves making a duplicate copy of the data, the volumes used on each disk are the same size. If you set up the mirrored environment with a 500MB volume and a 700MB volume, the result will be only a 500MB volume. The system will use the lowest common amount of free space to construct the mirrored volume.
Disadvantages of RAID 1
Several factors exclude RAID 1 from being used in many network environments. The following are some of the disadvantages associated with RAID 1:
Limited disk capacity— Because RAID 1 uses only two hard disks, limited disk space is available for use. Even if you purchased two 80GB drives, your network would have only 80GB of storage space. The applications and data storage needs of many of today's businesses would exceed this limitation quickly.
High disk space overhead— RAID 1 has 50% overhead—that is, half of the hard disk space needs to be used for RAID. So for every megabyte used for other purposes, another is needed for RAID.
Limited hot-swap support— Because RAID 1 is often implemented through software rather than hardware, RAID 1 configurations often don't support the ability to hot swap drives, meaning that you might have to shut down the server to replace a damaged hard disk. In some environments, powering down a server is a major consideration that is avoided at all costs. In such environments, a software RAID 1 solution is not practical.
Although disk mirroring is a reliable fault-tolerance method, it provides for only a single disk failure.
Recovering from a Failed RAID 1 Array
RAID 1 can handle the failure of a single drive; if one fails, a complete copy of the data exists on an alternate hard drive. Recovering from a failed RAID 1 array typically involves breaking the mirror set, replacing the failed drive with a working one, and reestablishing the mirror. The data will be automatically rebuilt on the new drive.
The recovery process may cause network disruption while a new hard drive is installed. The server can continue to function with a single drive, but there is no fault tolerance until the RAID 1 array is rebuilt.
It is possible—however unlikely—for multiple drives to fail, and RAID 1 cannot handle such a situation.
RAID 2
A few RAID levels have fallen into obscurity, and it is unlikely that you will see them in modern network environments. RAID 2 falls into this category. RAID 2 is described here to provide a complete look at the RAID picture.
RAID 2 is a fault-tolerant RAID level that writes error-correction data across several disks and uses this code to re-create data in case of failure. RAID 2 offered an error-detection method that used hamming code. Hamming code was designed to be used with drives with no built-in error detection. SCSI hard disks today all have built-in error-detection, making this feature useless. RAID 2 no longer has any real-world practical applications.
RAID 3
RAID 3 is another obsolete RAID level. RAID 3 stripes data across several hard disks, like RAID 0 does, but it also uses an additional disk for parity information. If a hard drive fails, the separate parity disk can be used to re-create the missing data, and business can continue without disruption to network service. Using a dedicated disk as a parity disk puts undue stress on a single disk because the parity information is constantly being written to the disk. The increased workload placed on a single disk can slow performance and cause the disk to fail more quickly than the other disks in the array.
RAID 4
RAID 4, like RAID 3, stripes information across all hard drives and uses a single dedicated disk for parity information. The main difference between the two is that RAID 4 uses block-level striping. However, due to the use of a single parity disk, RAID 4 suffers from the same shortcomings as RAID 3, and you are unlikely to encounter it today.
NOTE
Long Shots The chances of encountering RAID levels 2, 3, and 4 in a modern network environment are similar to the odds of being struck by lightning and winning the lottery on the same day.
RAID 5
RAID 5 is the preferred hard disk fault-tolerance strategy for most environments; it is trusted to protect the most sensitive data. RAID 5 stripes the data across all the hard drives in the array.
NOTE
Drive Failures The key advantage of RAID 5 is that a single drive can fail and the server can continue operation.
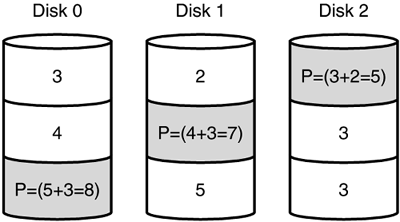
Instead of reserving a single disk for parity information as RAID 3 and 4 do, RAID 5 spreads parity information across all the disks in the array. Known as distributed parity, this approach allows the server to continue to function in the event of disk failure. The system can calculate the information that is missing from the failed drive by using the parity information on the disks. A minimum of three hard drives is required to implement RAID 5, but more drives are recommended, up to 32. When calculating how many drives you will be using in a RAID 5 array, remember that the parity distributed across the drives is equivalent to one disk. Thus if you have four 10GB hard disks, you will have 30GB of storage space.
You can expect to work with and maintain a RAID 5 array in your network travels. Figure 10.5 shows a RAID 5 array.
Figure 10.5. A RAID 5 array.
Advantages of RAID 5
There are several reasons RAID 5 has become a widely implemented fault-tolerance strategy. The following are some of the key advantages of RAID 5:
Minimal network disruption— When a hard disk crashes in a RAID 5 array, the rest of the drives will continue to function with no disruption in data availability. Network users can keep working, and costs associated with network downtime are minimized. Although there is no disruption to data access, the performance of the system decreases until the drive has been replaced.
Performance— Because RAID 5 can access several drives simultaneously, the read performance over that of a single disk is greatly improved. Increased performance is not necessarily a reason to use a fault-tolerant solution, but it is an added bonus.
Distributed parity— By writing parity over several disks, RAID 5 avoids the bottleneck of writing parity to a single disk, which occurs with RAID 3 and 4.
Disadvantages of RAID 5
The disadvantages of RAID 5 are few, and the benefits certainly outweigh the costs. The following are the disadvantages of RAID 5:
Poor write performance— Because parity is distributed across several disks, multiple writes must be performed for every write operation The severity of this performance lag will depend on the application being used, but its impact is minimal enough to make it a factor in only a few environments.
Regeneration time— When a hard disk is replaced in a RAID 5 array, the data must be regenerated on it. This process is typically performed automatically and demands extensive system resources. However, this factor is unlikely to become a concern.
Data limitations— RAID 5 that is implemented using software (such as Windows NT) is unable to include the system or boot partitions in the stripe set, so you must use an alternative method to secure the system and boot partitions. For example, some organizations use RAID 5 for data and a mirrored set to provide fault tolerance for the system and boot partitions. This limitation does not include hardware RAID 5 solutions, which can stripe the system and boot partitions.
Recovering from a RAID 5 Array Failure
RAID 5 ensures data availability even in the event of failed hard disks. A RAID 5 system will still be able to service requests from clients in the event of a failure, by using the parity information from the other disks to identify the data that is now missing because it was on the failed drive.
At some point, you must replace the failed hard disks to rebuild the array. Some systems let you remove the failed hard drive (that is, they are hot swappable) and insert the new one without powering down the server. The new hard disk is configured automatically as part of the existing RAID 5 array, and the rebuilding of data on the new drive occurs automatically. Other systems may require you to power down the server to replace the drive. You must then manually perform the rebuild. Because RAID 5 continues to run after a disk failure, you can schedule a time to replace the damaged drive and minimize the impact on network users.
RAID 10
In some server environments, it makes sense to combine RAID levels. One such strategy is RAID 10, which combines RAID 1 and RAID 0. RAID 10 requires four hard disks—two for the data striping and two to provide a mirrored copy of the striped pair.
NOTE
Implementing RAID 10 There are various ways of implementing RAID 10, depending on how many drives you have available and what the system configuration is.
RAID 10 combines the performance benefits of RAID 0 with the fault-tolerant capability of RAID 1, without requiring the parity calculations. However, RAID 10 also combines the limitations of RAID 0 and RAID 1. Mirroring the drives somewhat reduces the performance capabilities of RAID 0, and the 50% overhead of a RAID 1 solution is still in effect. Even with these limitations, RAID 10 is well suited for many environments, and you might find yourself working with or implementing such a solution. Figure 10.6 shows a possible configuration for a RAID 10 solution.

NOTE
What's in a Name? RAID 10 has many names. It's sometimes referred to as RAID 1/0, RAID 0/1, or RAID 1+0.
REVIEW BREAK: Choosing a RAID Level
Deciding whether to use a fault-tolerant solution on a network is the first and most obvious step for you to take when you design a network. The next, less simple, decision is which RAID level to implement. Your first inclination might be to choose the best possible RAID solution, but your budget might dictate otherwise. You should consider the following when choosing a specific RAID level:
Data protection and availability— First and foremost, you must consider the effect of downtime on the organization. If minutes will cost the organization millions, you need a very strong fault-tolerant solution. On the other hand, if you are able to go offline for an hour or more and suffer nothing more than an inconvenience, a costly RAID solution might be overkill. Before choosing a RAID solution, be sure what impact data unavailability will have on you and your network.
Cost— We would all like the best RAID solution, but high-end RAID solutions are out of the price range of many organizations. You are left to choose the best solution for the price.
Capacity— Some organizations' data needs are measured in megabytes, and others organizations' needs are measured in gigabytes. Before choosing a RAID solution, you need to know the volume of data. RAID 1, for instance, provides far less space than RAID 5.
Performance— Speed is an important consideration. With some of the RAID solutions the network suffers a performance hit, whereas with others performance can be increased over the performance using a single disk. Choosing the correct RAID solution might involve understanding the performance capabilities of each of the different RAID levels.
Table 10.1 summarizes the main characteristics of the various RAID levels.
Hardware and Software RAID
After you've decided to implement a RAID solution, you must also decide whether to use a software or hardware RAID solution. The decision is not easy, and your budget might again be the deciding factor.
Software RAID is managed by the network operating system or third-party software and as such requires server resources to operate. As a result, the overhead associated with software RAID can affect the performance of the server by taking resource time away from other applications. Some variations of RAID require more from the server than others; for example, RAID 1 is commonly implemented using software RAID because it requires less overhead than RAID 5.
Software RAID has one definite advantage: It's inexpensive. For instance, Linux and Windows NT/2000 have RAID capability built in, allowing RAID to be implemented at no extra cost, apart from the costs associated with buying multiple disks. These operating systems typically offer support for RAID levels 0, 1, and 5.
NOTE
Arrays and Volumes When discussing RAID, you'll often encounter the terms array and volume. An array is a group of disks that are part of a single RAID configuration. For instance, you would say, “There are two disks in a RAID 1 array.” A volume is a logical disk space within an array. Typically, a volume only refers to data storage and capacity.
Hardware RAID is the way to go if your budget allows. Hardware RAID uses its own specialized controller, which takes the RAID processing requirements away from the server. The server's resources can thus focus on other applications. Hardware RAID also provides the ability to use cache memory on the RAID controller, further adding to its performance capabilities over software RAID.
Other Fault-Tolerance Measures
Although hard drives represent the single largest failure point in a network, they are not the only failure points. Even the most costly RAID solution cannot save you from a faulty power supply or memory module. To fully address data availability, you must consider all hardware. This section provides a brief overview of some of the other common fault-tolerance measures you can take to further ensure data availability:
Preparing for faulty power supplies
Having spare memory
Preventing processor failures
Providing fault tolerance for network interface cards (NICs)
Using standby servers
Server clustering
Preparing for Faulty Power Supplies
If you work with servers or workstations, you know that from time to time a power supply will fail. When it fails in a workstation, you simply power down the system and replace the power supply. On a server, where downtime is often measured in dollars and cents, powering down to replace a faulty power supply can be a major issue.
You can prepare for a faulty power supply by using redundant, hot-swappable power supplies. As you might expect, such a strategy has associated costs that must be weighed against the importance of continual access to data.
Having Spare Memory
After memory is installed and confirmed to be working, it generally works for a long time. Sometimes, however, memory is at the root of server problems. Unfortunately, no fault-tolerance strategies will cope with failed memory; there is no hot swapping of memory, so you have to power down the server during the repair. The best you can do is minimize the impact of the failure.
Some environments have spare memory available at all times in case of failure. When memory does fail, a spare is ready to go. Such planning requires considerable forethought, but when you need such a solution, the preparation pays off.
Preventing Processor Failures
Processors are hardy, and processor failure is extremely uncommon. In fact, processor failure is so unusual that few organizations include processors in their fault-tolerance designs. Environments that consider processors may have a spare or, more likely, a standby server (discussed later in this chapter).
Some multiprocessor machines have a built-in safeguard against a single processor failure. In such a machine, the working processor maintains the server while a replacement for the nonfunctioning processor is found.
Providing Fault Tolerance for NICs
A faulty NIC can disable access to data quickly because a failed NIC effectively isolates the server. Several strategies are used to provide fault tolerance for NICs. Many systems employ a hot spare in the system that can be put to work as soon as the primary NIC fails.
NOTE
Warm Swaps Some systems support warm swaps. Warm swapping involves powering down an individual bus slot to change a NIC. Doing so prevents you from having to power down the entire system to replace an NIC.
Another strategy, called adapter teaming, uses multiple NICs configured to act as a single unit. Adapter teaming is a relatively new technology and as such is not widely implemented, but it's expected to become increasingly popular. In addition to providing fault tolerance, adapter teaming can increase bandwidth capability and let you manage network traffic more effectively.
Using Standby Servers
In addition to instituting fault-tolerance measures for individual components, many larger organizations use server fault-tolerance measures. In this scenario, if one server fails, a second is fully configured and waiting to take over. The second server is sometimes located in a separate building, in case of fire or flood damage to the location where the first server is kept.
A second strategy used for complete server fault tolerance is server failover. A server failover configuration has two servers wired together, with one acting as the primary server and the other acting as the secondary server. The systems synchronize data between them, ensuring that they are always current with each other. If the secondary server detects that the primary is offline, it switches to failover mode and becomes the primary server for the network. The whole procedure is transparent to the network user, and very little downtime, if any, is experienced.
As you might imagine, the costs associated with having a redundant server are very high. For this reason, few organizations use the failover and hot-spare server measures.
Server Clustering
Continuing our journey into incredibly expensive fault-tolerance strategies, we come to server clustering. For companies that cannot afford even a second of downtime, the costs of server clustering are easily justified.
Server clustering involves grouping several computers into one logical unit. This strategy can, depending on the configuration, provide fault tolerance as well as increased performance and load balancing. Because the servers within the cluster are in constant contact with each other, they are able to detect and compensate for a failing server system. A well-configured server cluster will provide failover without any disruption to network users.
The advantages of clustering are obvious. Clustering affords the highest possible availability of data and network services. Clusters are the foundational configuration for the “five nines” level of service—that's 99.999% uptime, which translates to less than 10 minutes of downtime in a year.
The fundamental downside to server clustering is its cost. Clustering requires a separate network to be constructed between the servers, installation and configuration of additional software, additional hardware, and additional administrative support.
Using Uninterruptable Power Supplies
NOTE
Overloading UPSs One mistake often made by administrators is the overloading of UPSs. UPSs are designed for server systems, and connecting monitors, printers, or other peripheral devices to them reduces their effectiveness.
No discussion of fault tolerance can be complete without a look at power-related issues and the mechanisms used to combat them. When you're designing a fault-tolerant system, your planning should definitely include UPSs. A UPS serves many different functions and is a major part of server consideration and implementation.
On a basic level, a UPS is a box that holds a battery and a built-in charging circuit. During times of good power, the battery is recharged; when the UPS is needed, it's ready to provide power to the server. Most often, the UPS is required to provide enough power to give the administrator time to shut down the server in an orderly fashion, preventing any potential data loss from a dirty shutdown.
Why Use a UPS?
Organizations of all shapes and sizes need UPSs as part of their fault-tolerance strategies. A UPS is as important as any other fault-tolerance measure. Three key reasons make a UPS necessary:
Data availability— The goal of any fault-tolerance measure is data availability. A UPS ensures access to the server in the event of a power failure—or at least as long as it takes to save your file.
Data loss— Fluctuations in power or a sudden power down can damage the data on the server system. In addition, many servers take full advantage of caching, and a sudden loss of power could cause the loss of all information held in cache.
Hardware damage— Constant power fluctuations or sudden power downs can damage hardware components within a computer. Damaged hardware can lead to reduced data availability while the hardware is being repaired.
Power Threats
In addition to keeping a server functioning long enough to safely shut it down, a UPS also safeguards a server from inconsistent power. This inconsistent power can take many forms. A UPS protects a system from the following power-related threats:
Blackout— A totalfailure of the power supplied to the server.
Spike— A spike is a very short (usually less than a second) but very intense increase in voltage. Spikes can do irreparable damage to any kind of equipment, especially computers.
Surge— Compared to a spike, a surge is a considerably longer (sometimes many seconds) but usually less intense increase in power. Surges can also damage your computer equipment.
Sag— A sag is a short-term voltage drop (the opposite of a spike). This type of voltage drop can cause a server to reboot.
Brownout— A brownout is a drop in power supply that usually lasts more than a few minutes.
Many of these power-related threats can occur without your knowledge; if you don't have a UPS, you cannot prepare for them. For a few hundred dollars, it is worth buying a UPS, if for no other reason than to sleep better at night.