
Chapter 18
Decision Support
This chapter explains the economic advantages and the investments that come with Model-Driven Software Development (MDSD) in general and architecture-centric MDSD in particular. It also attempts to answer both typical and critical questions.
You can find an overview of the motivation for, and basic principles of, MDSD in Chapter 2, Sections 2.1 to 2.3. We recommend you read those sections before this chapter.
18.1 Business Potential
MDSD combines the scalable aspects of agile approaches with other techniques to prevent quality and maintainability problems in large systems, as well as with techniques for the automation of recurring development steps in software development.
The potential of MDSD is based on a few basic principles:
- Formalization and condensation of software designs via the creation of modeling languages that are oriented more towards the problem space than the solution space.
- Abstraction from the level of expressiveness of today’s programming languages and platforms.
- Use of generators to automate repetitive activities.
- Separation of concerns, which to a large extent enables separate processing and evolution of functional and technical code.
- Reusability across project boundaries through the formation of software system families and product lines (see Section 4.1.4).
Based on these basic principles, a considerable number of features of the software systems developed in this manner can be derived and mapped to economic benefits as the following table demonstrates.
Table 18-1 The economic benefits of MDSD
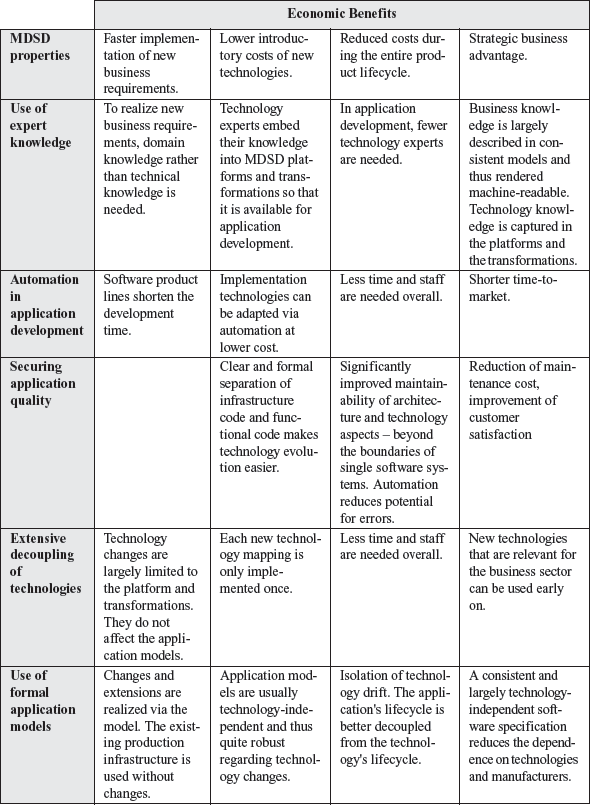
We now take a detailed look at the positive effects that MDSD can have on software projects.
18.2 Automation and Reuse
In a classical OO development process [JBR99] a design model is created incrementally and iteratively via a step-wise refinement of a part of the model that is established by projection to a few use cases. This model is refined to the point that it can more or less be transformed directly into an implementation.
Such a model can also be extracted automatically from an implementation by reverse engineering. We call this abstraction level an implementation model, because it contains all signature details of the implementation (but usually no more than this).
The diagram in Figure 18.1 shows the idealized development process of a development increment1 from its analysis to its implementation. Over time, both the level of understanding and the level of detail of the increment increase. At the start, more understanding is gained: towards the end, more details are worked out. A GUI design in the form of a sketch or a slide contains almost the same information as a completed implementation of the GUI using a JSP page or something similar. This means that the process of implementing the increment is primarily a task that requires tedious work and increases the increment’s level of detail, yet it hardly improves the level of understanding. Nevertheless, the work is necessary in order to convert the essential information into a computer-readable form.
Figure 18.1 The effort required in traditional software development.

Whether this happens iteratively or not is of little relevance in this context. The overall effort basically consists of the progress in both previously-mentioned dimensions – that is, it corresponds to the area underneath the curve.
The disadvantages of an implementation model can be summarized as follows:
- The implementation model provides a poor overview, because essential information gets lost among the wealth of details.
- Such a model is relatively poorly suited when new team members need to be trained.
- The route from the results of the analysis to the implementation model is very long and there are no defined waypoints. Intermediate results yielded by different developers tend to be diverse. In their entirety, they hardly ever constitute a usable, complete model.
- Design changes are preferably carried out in the source code. Afterwards, the static implementation model is made consistent using reverse engineering. More abstract intermediate results are seldom maintained, particularly because it often unclear which effects a change of the implementation model may or should have on an intermediate result. The consequence is that only the static implementation model is up-to-date – at best. The dynamic aspects are neglected or even removed from the model because they are no longer up-to-date. In most cases no consistent documentation exists at the end of the project that is any more abstract than the source code itself.
Figure 18.1 can be transferred to agile processes if a sufficiently abstract viewpoint is taken. The implementation model exists typically only in a virtual form – that is, in the form of source code. This avoids some disadvantages, of course, partly because specific artifacts are intentionally omitted. However, as in a heavyweight process, the necessary level of understanding must be gained during development. The same is true for the functional requirements (analysis results) that are contained in the software or an increment. In other words: depending on the process, the milestones in the diagram may have other names or may not exist explicitly, yet the shape of the curve is basically the same.
For the sake of this discussion, we reduce the overall effort of software development to the factors of information gain and level of detail, and consciously ignore setbacks in the level of understanding that are brought about by changing requirements or new insights. We don’t do this because these effects are irrelevant, but because they can be examined separately and independently of the issues described here.
We now introduce the essential potentials of MDSD, automation and reuse, to this discussion.
Here we clearly see the effects of abstraction, the modeling language’s shift towards the problem space (see Figure 18.2):
Figure 18.2 The effort in MDSD with partial manual coding.

- Very compact models are created with a unified and formally-defined abstraction level that is much higher than that of an implementation model. For example, point A’ is clearly to the left of the implementation model A, meaning that it is less cluttered with details.
- Those formal MDSD models described here (at point A’) contain significantly more information than the corresponding implementation models, due to the formalized semantics, particularly since not only signatures, but also partial implementations, are defined. For example, point A’ is above implementation model A, meaning that its information content is greater.
- This is exactly where the potential for automation lies: a generator cannot obtain any information, but it can easily improve the level of detail. Thus the effect of automation in the diagram is strictly horizontal and leads to point B without further effort2. Depending on the domain and the concrete approach (see Chapter 4), point B is closer to, or further from, the target, determining the effort for the remaining (manual) coding.
In an extreme case, the model specifies the complete semantics of the (partial) application, so that no manual coding is necessary at all (see Figure 18.3). The circumstances in which this is possible or useful are discussed later, in Section 18.6.2.
Figure 18.3 The effort in MDSD without any manual coding.

A generator cannot help in increasing the level of understanding. All information must therefore already be present in the model, expressed using the domain-specific modeling language (DSL) – see Sections 2.3 and 4.1.1. Referring to Figure 18.2, the curve rises more steeply close to point A’ than to point A. This means you have to put more work into understanding the domain - which has the positive side effect that it forces you to actually think about the domain.
Here, too, we are confronted with an extreme case: if the modeling language is very close to the problem space, the analysis result can be cast directly into a formal model – that is, point A’ moves closer to the analysis result while containing the same amount of information, or it assumes the same position, thus proportionally increasing the automation potential. On the other hand, this also means that the analysis will have to be more formal (see Figure 18.3).
Taking an automotive engineering metaphor as an example: at your local car dealership, you fill in an order form that lists the vehicle type and any special features you want. The characteristics on the order form constitute the domain-specific language. You don’t have to worry about implementation details, such as engine construction, when you order your car. The factory produces the desired product (your car) based on the domain model (your order form), using prefabricated components. Obviously, the engineering achievement lies in the effort of building the production line and the mapping of your functional order onto this production line. The production of the item itself is automated.
The second important aspect about increased efficiency is reusability in the form of a domain-specific platform consisting of components, frameworks and so on. Here the effort is simply shifted from application development to the creation of the platform (see Figures 18.2 and 18.3), which is reusable. Such reusable artifacts can be used beneficially in almost all other development processes. However, their creation is usually not explicitly included in the methodology: in MDSD the platform complements both the generator and the DSL.
Now we can clearly see the potential for savings that is gained by automation in combination with a domain-specific platform. Figure 18.3 shows the extreme case. From the application development perspective it obviously offers maximum efficiency, but on the other hand a powerful domain-specific software production infrastructure must be established. However, to be able to leverage the advantages of MDSD to the full, some investments are necessary that must be weighed against the advantages. We discuss this topic later.
In general the following advantages are gained compared to a standard development process:
- The modeling (design) phase ends much earlier.
- Only a fraction of the effort needed for creating an implementation model is required: the key to this is the domain-specific modeling language.
The implementation effort can be reduced considerably by using a generator that ‘understands’ the domain-specific modeling language. In the case of an architecture-centric approach (Section 2.5), a considerable amount of ‘classical’ programming remains, yet developers can focus on coding the functional requirements. The architectural infrastructure code is generated (Chapter 3) and also serves as an implementation guideline. A formalized, generative software architecture that includes a well-defined programming model emerges.
18.3 Quality
Until now we have focused entirely on how to increase efficiency in software development, but quality plays an equally important role, particularly because of its long-term effect. This section examines some of the factors that affect software quality and their connection with MDSD.
18.3.1 Well-defined Architecture
Code generation can only be used sensibly if the mapping of specific concepts in the model to the implementation code is defined in a systematic manner –that is, based on clearly-defined rules. It is mandatory to define these rules first. To reduce the demand for code generation, we recommend working with a set of rules that is as small and well-defined as possible. A small set of well-defined concepts and implementation idioms are the hallmark of a good architecture. We conclude that – in the context of MDSD – both the platform architecture and the realization of the application functionality on the platform must be well planned. MDSD demands a concise, well-defined architecture. This results in permanent consistency between model and implementation in spite of the model’s high abstraction level. Suitable generation techniques guarantee this consistency in strongly iterative development (see Chapter 3).
18.3.2 Preserved Expert Knowledge
Modeling language, generator, and platform constitute a reusable software production infrastructure for a specific domain. Today’s technical platforms, such as J2EE, .NET, or CORBA, offer a large number of basic services for their respective application fields – J2EE, for example, for big enterprise applications. Yet using these services – and hence the platform itself – efficiently is not easy. One must adhere to specific patterns or idioms to exploit the full potential of the platform: the platform must be used ‘correctly’. All the patterns and idioms are documented and well-known in principle, of course, yet it is a big problem in larger projects to ensure that the team members, whose qualifications typically vary considerably, consequently apply the right patterns. MDSD can help here, because defined domain concepts are automatically implemented on the platform in always the same manner. Ergo, the transformations are design knowledge that has been rendered machine-processable. They constitute an inherent value, as they preserve the knowledge of how to use the platform effectively in the context of the respective domain.
18.3.3 A Stringent Programming Model
In today’s practice it is not reasonable to generate 100% of the application code. As a rule, a skeleton is generated into which the developer adds manually written application code. The platform architecture as well as the generated application skeleton determine where and how manually-created code has to be integrated and the manner in which this code is structured. This equips developers with a safeguard that makes it unlikely that they will create ‘big ball of mud’ systems.
18.3.4 Up-to-date and Usable Documentation
In the context of ‘classical’ software development, the application logic, mixed with technical code, is typically programmed against a specific platform in a 3GL language. This is also done, although to a lesser extent, when dealing with technologies such as EJB, where the application server takes over specific technical services such as transactions or security. Since many concepts are not visible at this abstraction level, the software must be documented using various means. In time-critical projects it is often impossible to keep this documentation synchronized with the code, and it is therefore usually the first victim if time runs short.
In the context of MDSD, the situation is altogether different: the various artifacts constitute a formal documentation of specific aspects of the system:
- The domain-specific model offers a superb overview, because recurring implementation schemas and details are factored from the model. It is therefore much more compact than an implementation model.
- The DSL and the transformations document the use of the platform and the models’ semantics.
- The models document the application structure and logic in a form that can be understood by domain experts. Besides the model itself, user manuals and other documentation can be generated from the application models and their descriptions. Generative creation guarantees that the documentation stays consistent with the code base beyond the first release.
These artifacts are always synchronized with the actual application, because they serve as the source for the application’s generation.
Of course MDSD also has a need for informal documentation. The DSL and its semantics must be documented to allow its efficient use in projects. However, this kind of documentation is only required once for each DSL, not for each application (see Section 18.4.).
18.3.5 The Quality of Generated Code
In general, generated code has a rather dubious reputation: barely readable, not documented, and with poor performance. However, this is an unfounded prejudice in the context of MDSD, because the quality of the generated code depends directly on the transformations (for example the templates). The latter are typically derived from a reference implementation (see Section 13.2.2). This means that the properties mentioned above, such as readability and performance, are propagated from the reference implementation into the generated applications.
This is also the reason why the reference implementation specifically should be developed and maintained with care. As long as transformations are created with sufficient care, the generated code’s quality will be no worse than that of manually-created code. On the contrary, generated code is usually more systematic and consistent than manually-created code, because repetitive aspects are always generated by the same generator, so they always look and work the same way.
For example, with today’s generators it is no problem to indent the code sensibly. Comments can also be generated easily. One should pay attention to these things – the developers will be grateful.
18.3.6 Test Effort and Possible Sources of Errors
When MDSD is used a number of aspects have positive effects on the error rate of the software produced. This can be seen as early as your first MDSD project, but you will feel the effects mostly in subsequent projects and during maintenance:
- MDSD helps to automate tests via the use of generative methods for test script and test data generation (see Chapter 14).
- The generalization of schematic code in the form of transformations (or templates) enables a new approach to validation of the application architecture for to scalability, performance, and coverage of unusual application constructs. With little effort, a test application can be generated that is much more versatile than the manually-developed reference implementation, and which covers the extreme cases of the architecture’s applicability. Thus weaknesses in the architecture can be detected early and can be cured by refining the reference implementation, followed by refining the templates. This positively affects the risk profile of projects and demonstrates that MDSD can sensibly be used in risky projects.
- Extensive tests with the generative test application eliminate an entire class of tests that would otherwise have needed to be tested with every single generated application.
- Since the code that can be generated typically makes up more than 50% of the whole code volume, potential error sources are significantly reduced through consequent automation. In the long run, the qualitative advantages of MDSD are as important as increased productivity.
- The generation of user manuals and other documentation based on descriptions and characteristics of application model elements is possible. Generative creation guarantees that the documentation stays consistent with the code base beyond the first release.
18.4 Reuse
Besides the potential for automation and quality improvement, a domain architecture also has a very high potential for reuse. Keep in mind that it is a software production infrastructure consisting of a domain-specific modeling language3 (the DSL), a domain-specific platform, as well as a set of transformations that enable the step from model to runnable software, either completely or partially automated (see Section 4.1.4).
Such a production infrastructure is then reusable in similar software systems (applications) with the same properties. The definition of ‘similarity’ and its related potential for reusability is derived from these decisions:
- Definition of the domain
- Definition of the domain’s implementation platform
This makes MDSD interesting primarily in the world of software system families. In this context, a software system family is a set of applications based on the same domain architecture. This means that:
- They run on the same platform.
- They use the same DSL for specification of the applications – that is, of the ‘family member’.
- A common set of transformations exists that transfers the models into executable code based on the platform.
As an example, our first case study (see Chapter 3) covers the domain of architecture for business software with the MDSD platform J2EE/Struts. The modeling language described there is reusable for all software systems that use the features provided by this language. The generative software architecture of the case study maps the modeling language to the platform. The transformations are therefore reusable for all software systems that have the same architectural features and will be implemented on the same platform.
Due to its level of abstraction, the reusability of DSLs typically is even greater than that of transformations and platforms. In the context of a business, it can for example be sensible to describe the business architecture via respective high-quality DSLs and map them to relevant platforms using transformations (generators).
In the case of a clearly-defined functional/professional domain such as software for insurance applications, a functional/professional DSL can be even more effective, for example to support the model-driven, software-technical realization of insurance products or tariffs.
A combination – or more precisely, a cascade – of functional/professional and technical MDSD domains is particularly effective: in most cases, the platform of a functional domain architecture can be very well realized with the help of an architecture-centric domain architecture (see Section 7.6). In this way the advantages of MDSD can be leveraged in both functional and technical dimensions.
Either way, the more applications or parts of applications are created in such software production lines, the faster one will profit from their creation, and the greater will be the benefit.
18.5 Portability, Changeability
Fan-out is an important benefit of MDSD. This term describes the fact that a number of less abstract artifacts can be generated from a single model. The fan-out has two dimensions:
- On one hand, several artifacts can be generated from a single model in the course of a project. For example, relational database schemas, XML schemas, as well as serializers, can all be generated from a UML-based data model. In projects in which all of these different artifacts must be kept mutually consistent, this is a considerable advantage.
- On the other hand, different implementations can be generated from a single application model over time, making migration to newer versions of the technical platform, or to a totally new platform, easier.
An MDSD approach generally allows fast modification of the developed application(s). Since many artifacts are automatically created from one specification, changes to the specification will of course affect the whole system. In this way, the agility of project management increases.
18.6 Investment and Possible Benefits
We have seen the potential and usefulness of MDSD. Unfortunately, even in IT, there is no such thing as free lunch: to be able to enjoy the advantages, one must invest in training and infrastructure – of a technical as well as an organizational nature, depending on the desired degree of sophistication. This section introduces some experiences and conveys some condensed information from real-life projects to give you a clearer idea of the costs, the usefulness, and the break-even points in MDSD.
18.6.1 Architecture-centric MDSD
We recommend you first approach MDSD via architecture-centric MDSD, since this requires the smallest investment, while the effort of its introduction can pay off in the course of even a six-month project. Architecture-centric MDSD does not presuppose a functional/professional domain-specific platform, and is basically limited to the generation of repetitive code that is typically needed for use with commercial and Open Source frameworks or infrastructures.
The investment consists primarily of the training needed for handling an MDSD generator and its respective template language, as well as for the definition of a suitable DSL for modeling.
Effects on the Code Volume
To conduct a quantitative analysis, we collected sample data from a real-life MDSD project at the time of its acceptance. This project was a strategic, Web-based back-office application for a big financial service provider. Table 18-2 shows in rough numbers the effects of architecture-centric MDSD on the source code volume.
Table 18-2 Code-volume ratio in architecture-centric MDSD
| Amount of source code [kB] | Traditional development | MDSD |
| Source code reference implementation | 1.000 | 1.000 |
| handwritten code | 18.800 | 2.200 |
| Models | 3.400 | |
| Transformations | 200 | |
| ____ | ____ | |
| Total | 19.800 | 7.800 |
To represent the influence of models on code volume, we selected the number of kilobytes required to store the all required UML files. We also assumed that a manually-created reference implementation would be developed to validate the application architecture.
Our concrete example for architecture-centric MDSD shows that the volume of code that needs to be maintained manually is reduced to 34% of the code volume that would have to be maintained in non-model driven development scenarios, including transformation sources! This number may appear to be very low, but in our experience it has proven to be representative. Tool manufacturers quite often publish data reflecting the percentage of generated code. However, these numbers are meaningless if it is unclear whether the necessary model and transformation sources, as shown in Table 18-2, have been included in the calculation. In our example, model and transformation sources make up more than 50% of the source code that needs to be maintained. Figure 18.4 provides a graphical view of the data from our example.
Figure 18.4 Code-volume distribution.

Of course, other than in manual implementation, the volume of sources to be compiled remains unchanged if MDSD is used, as shown in Figure 18.5. The difference between traditional development and MDSD is that generated code doesn’t constitute a source, but an effort-neutral intermediate result.
Figure 18.5 Ratio of generated ‘sources’ and manually created sources.

If we ignore model and transformation sources, as well as the reference implementation, we get a ratio of 88% generated code and 12% manually-created code. In our view, however, such figures are ‘window dressing’. In MDSD, the models have the same value as normal source code, and the reference implementation should always be maintained in MDSD, because it is the basis of all refinements and extensions of the architecture.
Viewed from this perspective, the ratio of generated code and manually-created code is 72% to 28%. These figures are still impressive enough to make it clear that architecture-centric MDSD can pay off even if only a single application is developed with a given infrastructure – particularly if one takes into account medium-term maintenance requirements. To prove that our statement is true, we must consider the entire effort for the project’s realization, not just the programming effort.
Effects on Project Time and Effort
Besides implementation, the project time and effort consist of:
- Analysis and documentation of the requirements.
- Architecture and design work, definition of the modeling language (for example UML profile), if applicable.
- Test generation and execution.
- Project management.
In addition, business process analysis preceding the project, required project documentation (user manuals, help menu texts), as well as production costs must be considered. MDSD has a positive influence on some of these activities, yet it is difficult to document this influence in general numbers. We therefore only examine in which respects MDSD affects the implementation effort, and how this again affects the total core activity efforts.
The figures given in the previous section are not useful for an assessment of the total work effort, because they do not reflect how much time – and thus money – is spent on the creation of models and transformations, as well as for the manual programming of reference implementations and application-specific source code. Likewise, the brainwork involved in creating the DSL is not considered here.
In a little practical experiment [Bet02] we examined how much time the creation and maintenance of models takes, based on data entry and mouse clicks. We then converted this information into the equivalent of source code lines using an approximate formula:
- If we define the total programming effort as being equivalent to the sum of all remaining manually-created source code lines, we get an interesting picture. In our experiment, MDSD causes a reduction of the programming effort to 48% of that of completely manual programming.
- If MDSD is not used and typical UML tools are applied instead to generate skeleton source code from the models, the programming effort increases to between 105% and 149% of that of manual programming completely without UML, depending on how many interaction diagrams the models contain (other than class diagrams, which don’t contribute to skeleton generation).
These figures clearly demonstrate that MDSD is not the same as UML round-trip engineering. They also show why many software developers are skeptical regarding the use of UML tools.
In architecture-centric MDSD, the platform almost exclusively consists of external commercial and Open Source frameworks. The domain architecture that needs to be created consists primarily of a reference implementation and transformations derived from it (code generation templates).
The figures from Table 18-2’s example (reference implementation circa 1,000 kB source code, transformation source code circa 200 kB) support our thesis that the derivation of transformations from a reference implementation takes only between 20% and 25% of the effort required for creating the actual reference implementation – especially if you keep in mind that most of the mental work has already been done for the reference implementation.
The effort required to create a reference implementation is not influenced by MDSD. For further discussions, we assume that the programming effort for the reference implementation constitutes 15% of a project’s total programming effort. In the Table 18-2’s example, the size of the reference implementation was only 5% of the entire application (measured in kB), so that even if one takes into account that the reference implementation is more difficult to program, 15% is a fairly conservative estimate.
Table 18-3 shows that architecture-centric MDSD can lower the programming effort by 40%, given the conditions described above. This figure confirms our practical experience as well, and is a good reference for calculating the costs of introducing MDSD. It is best however to use metrics from your own team to calculate how much programming effort is needed compared to the total project time and effort, and thus to calculate the potential of MDSD.
Table 18-3 Comparison of modeling and programming effort
| Development effort [%] | Traditional development | MDSD |
| Transformations | – | 4 (0,15*25) |
| Reference Implementation | 15 | 15 |
| Application models and code | 85 | 41 (0,48*85) |
| Total | 100 | 60 |
- If we assume that programming makes up 40% of the project activities, the potential for saving money can be up to 16%.
- The effort for the reference implementation and transformation development is not necessary for subsequent projects, so that the programming effort is reduced by 59% and potentially up to 24% of the costs can be avoided.
- A mature domain architecture increases the maintainability and changeability of all projects using MDSD, so that maintenance costs are significantly reduced4.
In real life, of course, the team’s learning effort, as well as the hiring of an MDSD expert as a coach for the first project, must also be considered.
We can make an empirical assessment: if an MDSD pilot project runs for six months or longer and the team consists of more than five people, the introduction of MDSD can pay off as early as during this first project, even if the whole production infrastructure must be built from scratch. Chapter 20 describes the adaptation strategies and prerequisites that should be observed.
18.6.2 Functional/Professional MDSD Domains
As you may already have inferred from the previous section, architecture-centric MDSD offers a simple and low-risk adoption path for MDSD. As the figures in our examples show, roughly half of the sources to be maintained consist of models and transformations: the other half consist of ‘traditional’ source code for the reference implementation and handwritten application logic.
If a mature implementation of architecture-centric MDSD is available, the remaining traditional source code cannot be reduced any further. Efficiency can only be increased by applying the MDSD paradigm not just to the architectural/technical domain, but also to functional/professional domains. This allows us to uncover functional domain-specific commonalities and variabilities of applications via domain analysis or product-line engineering (Section 13.5) and to increase the abstraction level of the application models even further: the models then describe domain-related problems and configurations, instead of architectural aspects, effecting a further reduction of the modeling effort and particularly the effort for manual coding.
To exemplify this it helps to look at the code volume distribution during development of a number of applications in the same domain. Figure 18.6 sketches the reduction of code volume via introduction of a functional domain architecture during the development of three applications, while assuming that the application models and application-specific, handwritten source code can be reduced by 50%. Note that Figure 18.6 is of a purely illustrative nature: the real-life facts very much depend on the domain and its complexity. The more clearly the domain’s boundaries can be defined, the more functionality can be integrated into the functional MDSD platform in a reusable form.
Figure 18.6 Code-volume distribution during introduction of a functional domain architecture.

In practice, the development of a functional domain architecture is an incremental process based on architecture-centric MDSD.
The development effort for functional domain-specific languages (DSLs) and the corresponding frameworks should not be underestimated. The successful development of such languages requires significant experience in the respective domain and should not be attempted in your first MDSD project.
There are also scenarios in which functional frameworks already exist that can be used without the help of model-driven generators, of course. In this case, MDSD can build on them as in the architecture-centric case – that is, the existing frameworks are regarded as the MDSD platform that defines the target architecture (see Chapter 7). A DSL is then derived from the configuration options. As in the architecture-centric case, productivity can be improved remarkably with only a moderate investment.
18.7 Critical Questions
We have addressed some of the prejudices against MDSD in the preceding sections, as well as in Chapter 5. Some of these prejudices date back to the 1980s and 90s and stem from negative experiences with CASE tools, and are now projected onto model-driven approaches in general. Serious and important questions emerge: the answers to such questions are neither trivial nor easily found. Below we discuss answers to some of these questions:
- What is new about MDSD?
Naturally, its individual concepts, for example the generation of source code from higher-level descriptions/models, are nothing new. Nevertheless, the simple code generators that every developer uses or writes at some point in their career are not comparable with the highly flexible MDA/MDSD tools of the latest generation, which allow you to define modeling languages and modular transformations both freely and in a relatively simple manner. MDSD is more than just a technique – it is mainly about the engineering principle. - If the approach is that brilliant, why isn’t it more popular?
The required prerequisites, such as flexible tools and – most of all – a more comprehensive knowledge about the approach are not yet available. In the field of tools, the growing popularity of MDSD certainly plays a driving role. On the other hand, the integral architecture-centric MDSD view – and particularly its generative use – are already established among early adopters. The same is true for central, process-related MDSD concepts. - Does MDSD have negative effects on the performance or the readability of application source code?
In the model-driven approach, the necessary infrastructure and the corresponding design patterns are developed initially in the form of a small, manually-created reference implementation. This reference implementation may be small, but it is deep. It covers all the architecture’s layers and is established in the first phases of a project by experienced team members. In the course of the project, the reference implementation is refined and optimized, so that its properties and improvements can be transferred to the entire source code via generative techniques. On average, the model-driven approach leads to a performance that is at least as high as if a traditional development approach is used. The same is true for source code readability (see Section 8.2.4). - Aren’t today’s UML-based IDEs with round-trip support much more mature than MDA/MDSD tools?
This may be correct to a certain extent, yet it is irrelevant, because these tools constitute a different class of tools. Due to their missing abstraction level, they do not offer the advantages of MDSD described above (see Section 18.2 and Chapter 5). - Doesn’t MDSD create an unreasonably strong dependency on a specific tool or a certain technology combination?
Modular, automated transformations and the treatment of model transformations as first-class artifacts guarantee that tool dependencies remain local (see Section 11.2). Since MDA has not yet established a standard for transformation languages, one is bound to a specific transformation language by choosing an MDA/MDSD tool. However, MDSD tools can more and more be considered a commodity, especially if they are available as Open Source software. Since modern template-based generators have no restrictions with regards to target languages, there is no limit to specific technology combinations for the application to be created. - Doesn’t the model-driven approach imply a waterfall model, and doesn’t it particularly conflict with agility? What distinguishes it from CASE?
The iterative, dual-track process of MDSD (see Section 13.2), in which the infrastructure is developed in parallel to the application(s), must be clearly distinguished from traditional waterfall methods that are based on a ‘big design up-front’ philosophy. MDSD is based on domain-specific platforms and is in strong opposition to the classic CASE approach that tries to anticipate all situations by using a universal language. Agile methods are particularly well-suited for the creation of MDSD reference implementations. MDSD also helps to scale agile methods, because the experience and expert knowledge gained can be made available to all developers in software form. MDSD fosters test-driven approaches (see Chapter 14). - How can one ensure that model and code do not diverge at some point?
In MDSD generation is based on the model, and generated code is consequently separated from non-generated code. Handwritten code is not obsolete. On the contrary, MDSD considers developers and generators to be complementary partners that must work together efficiently. The rules for this collaboration between developers and generators are not rigid, but are defined based on the actual requirements. The same applies to the rules for the developers’ interaction in a team. However, the MDSD generator ensures that the developer does not cross the boundary set by the domain architecture, especially since manipulations of the generated code are undone during iterative regeneration. - How much time and effort is required for generator or transformation development? Is is worth the time and money?
Well-focused, yet mature generic tools are available, particularly in the Open Source field. These tools possess simple yet powerful template languages. Some also define powerful model-to-model transformation languages. One should build on these generators during transformation development.
Modern template languages allow a very intuitive generalization of complex, handwritten code. The effort for the generalization or ‘templating’ of the source code is only 20% to 25% of the effort needed to code manually the reference implementation from which the templates are extracted. From a certain project size upward, and especially when similar subsequent projects are to be expected, the MDSD approach is much more efficient than traditional software development (see Section 18.6). - Doesn’t it take longer to change an attribute type in the model, followed by regeneration, than to change the declaration in the code in a certain place manually?
If we have rich semantics, for example persistence of the attribute, changing one occurrence in the code is not enough; all dependent occurrences, e.g. in interfaces (getters/setters), serializers, and DDL scripts must be adapted consistently. - Isn’t it faster to adapt changes due to maintenance by adapting the generated code manually instead of adapting the MDSD transformations (the generation rules)?
If the guidelines for MDSD are obeyed and generated code is kept strictly separate from non-generated code, changes to code templates are always faster than manual changes to numerous source files. - In time-critical phases of application development, one cannot always wait for the next release of the domain architecture. Manual interventions into the generated code are the consequence, and the MDSD approach fails because the generator can no longer be used. How can this be avoided?
For smaller patches it can make sense to create a specific, temporary branch of the domain architecture that is decommissioned during the domain architecture’s next release. Should severe insufficiencies of the domain architecture emerge, one must fall back on manual programming, either temporarily or permanently. This is not accomplished by manipulating the generated code, but by opening the domain architecture in the relevant place: the transformations are changed in such a way that they generate only a (modifiable) default implementation. The opening-up of the domain architecture can – if applicable – also be made available as a temporary, project-specific branch. - Isn’t it better to implement an object-oriented framework instead of using a generator? Do object-oriented generators and high-quality, object-oriented generated code exist?
Object-oriented frameworks and generators are an ideal match (see Chapter 3). The combination of both approaches is a real step forward.
In MDSD, frameworks and generators complement each other in a similar way to the dynamic and structural aspects of an object-oriented model. Modern generators are typically realized in object-oriented languages and are in no way comparable to the simple utilities that every programmer has written at some point. - Model-Driven Software Development in larger teams inevitably means distributed modeling. Aren’t the currently-available (UML) modeling tools a problem rather than a help?
Of course choosing the right modeling tool is essential to the success of MDSD in big projects. Yet there are also mature (UML) tools that support distributed modeling even in large teams. Independently of this approach, the simple partitioning of the application model into several loosely-coupled partial models can be helpful. Partitioning can take place either horizontally – aligned with the architectural layers – or vertically – alongside loosely-coupled use case implementations. Partitioning must be allowed and supported by the DSL and the generator (see Chapter 15). - Isn’t it much more time-consuming to work out an architecture explicitly?
Each application has an architecture, whether formally defined or not, but only if it is explicitly worked out (in whatever form) does it becomes a ‘good’ architecture. Quality attributes such as maintainability, scalability and so on can be created iteratively, but not accidentally. - Isn’t handwritten code more reliable than generated code? Can one trust a generator in all situations, or won’t there always be situations in which manual interventions are required?
It is wrong to assume that a couple of unpredictable exceptions of a design pattern render the use of generators impractical or uneconomic. It is not the goal of MDSD to eliminate the manual creation of source code altogether. On the contrary, MDSD offers pragmatic techniques for supplementing generated code with non-generated code in well-defined locations.
As proof of the higher efficiency and lower error rates of handwritten code, strange compiler or assembler errors are sometimes quoted. The fact is overlooked here that this supposed weakness of generator technology would have prevented the development and usage of today’s programming languages a long time ago. The opposite is true: practice shows that typically many errors are discovered during the derivation of templates from the reference implementation, due to the intense attention paid to implemented design patterns. Such errors would otherwise remain unnoticed and spread further via traditional copy and paste techniques.
We admit that the borderline between generated code and manual implementation must be drawn with great care. It is a balancing act between automation and necessary degrees of freedom. Often it is the limited number of solution alternatives that will let you achieve your goal (see Chapter 7).
18.8 Conclusion
MDSD enables productivity and quality gains as soon as during your first model-driven project. Specifically, the implementation effort can be reduced by half compared to traditional manual programming. Considering the necessary training effort for the introduction of MDSD, real savings are to be expected from the second project onwards once the team is familiar with the MDSD paradigm, a concrete set of tools, and the methodology. The use of MDSD with functional/professional MDSD platforms should be the second step (cascaded MDSD, see Section 8.2.8).
18.9 Recommended Reading
Unfortunately the amount of publicly-accessible data on the efficiency of Model-Driven Software Development and product line development is rather small. This is for several reasons: on one hand, no-one will come up with the idea of executing a real-life project twice in parallel just to collect comparative metrics – and even this would be only of limited value, due to the dissimilar boundary conditions. Furthermore, positive effects on time and quality are obvious to everyone involved in the project, while interesting metrics relate more to the incremental refinement of the approaches than to a comparison with completely manual approaches. Last but not least, not all companies mention the option of using generative techniques and the resulting savings if the customer is only interested in the delivered, traditional source code or the finished application.
The sources [PLP], [Bet02] and [Bet04c] contain further data and economically-relevant statements regarding the MDSD development process.
1 In the special case of a waterfall model, only one global ‘increment’ exists.
2 We don’t take the effort required for the development of a generator into account here.
3 Compare for example the architecture-centric UML profile in Chapter 3’s case study.
4 It is difficult to express this effect in figures.