
Part of the motivation for generative models, be they GANs or VAEs, was always that they would allow us to generate data and therefore require less data. As data is inherently sparse, especially in finance, and we never have enough of it, generative models seem as though they are the free lunch that economists warn us about. Yet even the best GAN works with no data. In this section, we will have a look at the different methods used to bootstrap models with as little data as possible. This method is also called active learning or semi-supervised learning.
Unsupervised learning uses unlabeled data to cluster data in different ways. An example is autoencoders, where images can be transformed into learned and latent vectors, which can then be clustered without the need for labels that describe the image.
Supervised learning uses data with labels. An example is the image classifier we built in Chapter 3, Utilizing Computer Vision, or most of the other models that we've built in this book.
Semi-supervised learning aims to perform tasks usually done by supervised models, but with less data at hand and using either unsupervised or generative methods. There are three ways this can work: firstly, by making smarter use of humans; secondly, by making better use of unlabeled data, and thirdly, by using generative models.
For all the talk about AI replacing humans, an awful lot of humans are required to train AI systems. Although the numbers are not clear, it's a safe bet that there are between 500,000 and 750,000 registered "Mechanical Turkers" on Amazon's MTurk service.
MTurk is an Amazon website that offers, according to its own site, "Human intelligence through an API." In practice, this means that companies and researchers post simple jobs such as filling out a survey or classifying an image and people all over the world perform these tasks for a few cents per task. For an AI to learn, humans need to provide labeled data. If the task is large scale, then many companies will hire MTurk users in order to let humans do the labeling. If it is a small task, you will often find the company's own staff labeling the data.
Surprisingly little thought goes into what these humans label. Not all labels are equally useful. The following diagram shows a linear classifier. As you can see, the frontier point, which is close to the frontier between the two classes, determines where the decision boundary is, while the points further in the back are not as relevant:
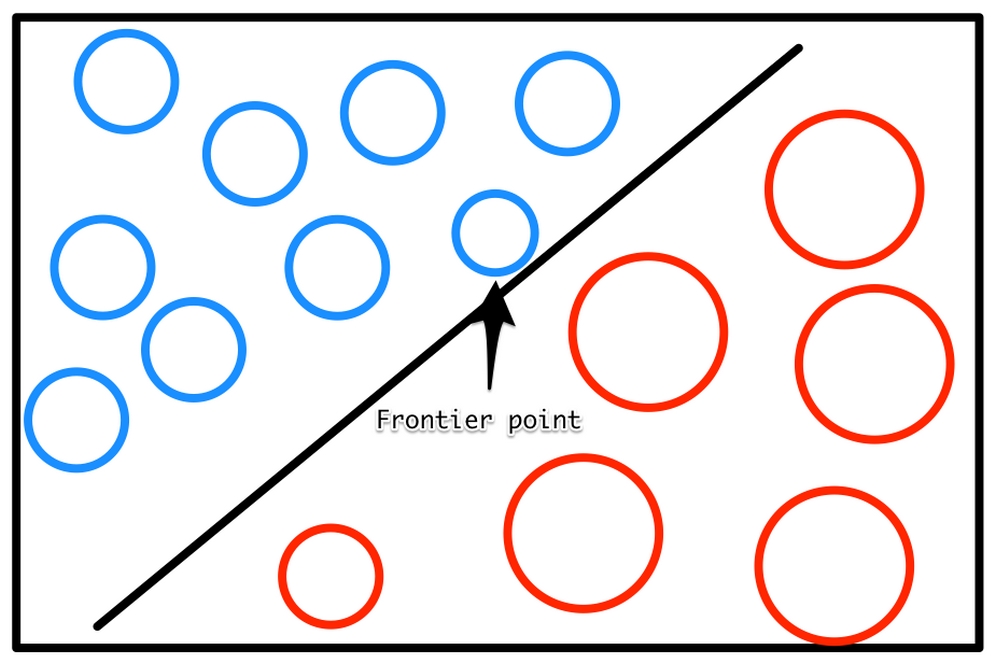
Frontier points are more valuable
As such, the frontier points are more valuable than points further away from the decision boundary. You can train on less data by doing the following:
- Labeling only a few images
- Training a weak model
- Letting that weak model make predictions for some unlabeled images
- Labeling the images that the model is least confident about and adding them to your training set
- Repeating the process
This process of labeling data is much more efficient than just randomly labeling data and can accelerate your efforts quite drastically.
In labeling, many companies rely on Microsoft Excel. They have human labelers look at something to label, such as an image or a text, and then that person will type the label into an Excel spreadsheet. While this is incredibly inefficient and error prone, it's a common practice. Some slightly more advanced labeling operations include building some simple web applications that let the user see the item to label and directly click on the label or press a hotkey. This can accelerate the labeling process quite substantially. However, it's still not optimal if there are a large number of label categories.
Another way is to once again label a few images and pretrain a weak model. At the point where the labeling takes place, the computer shows the labeler the data as well as a label. The labeler only has to decide whether this label is correct. This can be done easily with hotkeys and the time it takes to label a single item goes down dramatically. If the label was wrong, the label interface can either bring up a list of possible options, sorted by the probability the model assigned to them, or just put the item back on the stack and display the next most likely label the next time.
A great implementation of this technique is "Prodigy," a labeling tool by the company that makes spaCy, which we learned about in Chapter 5, Parsing Textual Data with Natural Language Processing, we can see an example of the Prodigy tool in the following screenshot:

Screenshot of the Prodigy labeling tool
Prodigy is a labeling tool that leverages machines, you can find more out about it by reading its official documentation here: https://prodi.gy/.
Often there is plenty of unlabeled data available, but only a small amount of data that has been labeled. That unlabeled data can still be used. First, you train a model on the labeled data that you have. Then you let that model make predictions on your corpus of unlabeled data. You treat those predictions as if they were true labels and train your model on the full pseudo-labeled dataset. However, actual true labels should be used more often than pseudo labels.
The exact sampling rate for pseudo labels can vary for different circumstances. This works under the condition that errors are random. If they are biased, your model will be biased as well. This simple method is surprisingly effective and can greatly reduce labeling efforts.
As it turns out, GANs extend quite naturally to semi-supervised training. By giving the discriminator two outputs, we can train it to be a classifier as well.
The first output of the discriminator only classifies data as real or fake, just as it did for the GAN previously. The second output classifies the data by its class, for example, the digit an image represents, or an extra "is fake" class. In the MNIST example, the classifying output would have 11 classes, 10 digits plus the "is fake" class. The trick is that the generator is one model and only the output, that is, the last layer, is different. This forces the "real or not" classification to share weights with the "which digit" classifier.
The idea is that to determine whether an image is real or fake, the classifier would have to figure out whether it can classify this image into one class. If it can, the image is probably real. This approach, called semi-supervised generative adversarial network (SGAN), has been shown to generate more realistic data and deliver better results on limited data than standard supervised learning. Of course, GANs can be applied to more than just images.
In the next section, we will apply them to our fraud detection task.