
Earlier in this chapter, we introduced the three models that we will be using to detect fraud, now it's time to explore each of them in more detail. We're going to start with the heuristic approach.
Let's start by defining a simple heuristic model and measuring how well it does at measuring fraud rates.
We will be making our predictions using the heuristic approach over the entire training data set in order to get an idea of how well this heuristic model does at predicting fraudulent transactions.
The following code will create a new column, Fraud_Heuristic, and in turn assigns a value of 1 in rows where the type is TRANSFER, and the amount is more than $200,000:
df['Fraud_Heuristic '] = np.where(((df['type'] == 'TRANSFER') &(df['amount'] > 200000)),1,0)
With just two lines of code, it's easy to see how such a simple metric can be easy to write, and quick to deploy.
One important thing we must consider is the need for a common metric on which we can evaluate all of our models on. In Chapter 1, Neural Networks and Gradient-Based Optimization, we used accuracy as our emulation tool. However, as we've seen, there are far fewer fraudulent transactions than there are genuine ones. Therefore a model that classifies all the transactions as genuine can have a very high level of accuracy.
One such metric that is designed to deal with such a skewed distribution is the F1 score, which considers true and false positives and negatives, as you can see in this chart:
|
Predicted Negative |
Predicted Positive | |
|---|---|---|
|
Actual Negative |
True Negative (TN) |
False Positive (FP) |
|
Actual Positive |
False Negative (FN) |
True Positive (TP) |
We can first compute the precision of our model, which specifies the share of predicted positives that were positives, using the following formula:
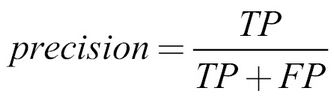
Recall measures the share of predicted positives over the actual number of positives, as seen in this formula:

The F1 score is then calculated from the harmonic mean, an average, of the two measures, which can be seen in the following formula:

To compute this metric in Python, we can use the metrics module of scikit-learn, or sklearn for short:
from sklearn.metrics import f1_score
Given the predictions we've made, we can now easily compute the F1 score using the following command:
f1_score(y_pred=df['Fraud_Heuristic '],y_true=df['isFraud'])
out: 0.013131315551742895
You'll see that the preceding command outputs a number–starting 0.013131315…-What this number means exactly is that our heuristic model is not doing too well, as the best possible F1 score is 1, and the worst is 0. In our case, this number represents the harmonic mean of the share of correctly caught frauds over everything labeled as fraud and the share of correctly caught frauds over all frauds.
A more qualitative and interpretable way of evaluating a model is with a confusion matrix. As the name suggests, the matrix shows how our classifier confuses classes.
Firstly, let's study the code appendix for the plot_confusion_matrix function:
from sklearn.metrics import confusion_matrix cm = confusion_matrix(
y_pred=df['Fraud_Heuristic '],y_true=df['isFraud'])
plot_confusion_matrix(cm,['Genuine','Fraud'])Which, when we run, produces the following graphic:

A confusion matrix for a heuristic model
So, just how accurate was that model? As you can see in our confusion matrix, from our dataset of 2,770,409 examples, 2,355,826 were correctly classified as genuine, while 406,370 were falsely classified as fraud. In fact, only 2,740 examples were correctly classified as fraud.
When our heuristic model classified a transaction as fraudulent, it was genuine in 99.3% of those cases. Only 34.2% of the total frauds got caught. All this information is incorporated into the F1 score we formulated. However, as we saw, it is easier to read this from the generated confusion matrix graphic. The reason we used both the heuristic model and the F1 score is that it is good practice to have a single number that tells us which model is better, and also a more graphical insight into how that model is better.
To put it frankly, our heuristic model has performed quite poorly, detecting only 34.2% of fraud, which is not good enough. So, using the other two methods in the following sections, we're going to see whether we can do better.