
Chapter 9. The big picture
This chapter covers
It’s time to start thinking big. After looking at the details of how Tika works, you’re probably already thinking of how to integrate it with your applications. The purpose of this chapter is to give you ideas about where and how Tika best fits with different kinds of applications, architectures, and requirements.
We’ll do this in two parts. First we’ll focus on functionality and look at common information-processing systems. We’ll start with search engines and then look at document management and text mining as examples of other information-processing systems where Tika comes in handy. The question is about what such systems can achieve with Tika and where Tika fits in the system architecture. Then in the latter part of this chapter we’ll turn to nonfunctional features such as modularity and scalability. The question there is how to use Tika to best meet such requirements.
9.1. Tika in search engines
Throughout this book we’ve mentioned search engines as common places where Tika is used, so let’s take a closer look at what a search engine does and where Tika fits in. If you already know search engines, you can probably skip this section. If not, we’ll start with a quick reminder of what a search engine does before a more detailed discussion of the components in a search engine.
9.1.1. The search use case
As outlined in figure 9.1, a search engine is broadly speaking an information-processing system that makes it possible to efficiently search for documents by maintaining an index of a document collection. Users look for information within a possibly unbounded collection of documents. They express what they’re looking for as a search query that can consist of keywords, phrases, or more complex constraints.
Figure 9.1. Overview of a search engine. The arrows indicate flows of information.
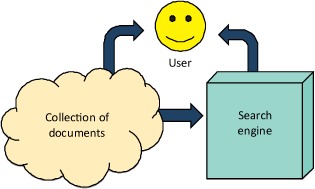
A classic example is a web search engine such as Google Search or Microsoft’s Bing, where the document collection is the entire web, the documents are web pages and other web resources, and the index is maintained by constantly “crawling” the web for new or updated documents.
The search engine works by indexing documents in the specified collection. A user then issues queries to the search engine and receives results through some addressing mechanism such as URLs for web resources or ISBN codes for printed books. The user can then find and access the matching document from the source collection.
9.1.2. The anatomy of a search index
What does a search engine look like internally, and where does Tika fit in there? The architectural diagram in figure 9.2 answers these questions by showing the key components of a typical search engine.
Figure 9.2. Architecture of a search engine. Blocks identify key components and the arrows show how data flows between them. Tika is typically used in the starred extraction component.

If we follow the flow of data within such a search engine, we first encounter the crawler component, whose task is to fetch documents to be indexed. There are many strategies for finding and fetching documents, but typically a crawler will either traverse a structured collection like a file system or follow document links in an unstructured collection like the public web. Often a crawler also has an update strategy by which it refetches already-indexed documents to check whether they’ve been modified. In the next chapter we’ll look at the Apache Nutch project, which contains a highly versatile and scalable crawler. The Apache ManifoldCF project (that we will cover later in chapter 10) provides another crawler example, optimized for ingestion into Apache Solr (also covered in chapter 10).
After a document has been fetched by the crawler, it’s handed to the extraction component whose task is to extract text and other data from the document. As discussed in chapters 5 and 6, the extracted text content and metadata of a document are much more useful to a search engine than raw bytes. In some search engines, the extraction component is also used to feed interdocument links back to the crawler component for use in traversing the document collection. These tasks are exactly what Tika does, so the extraction component of a search engine can easily consist of nothing but Tika and a bit of related glue code.
The next component in line is the indexer that converts the extracted document information into records stored in the search index. A typical search engine uses an inverse index that consists of a mapping from individual words or other search terms to the documents that contain them. The index is called “inverse” because instead of mapping a document identifier to the contents of the document, the mapping is from the content of a document to its identifier. Often the indexer uses a special analyzer tool to preprocess the previously extracted text; for example, to normalize words and other tokens into their base forms and to exclude common words such as the or and from being indexed. The Apache Lucene project discussed in the next chapter contains everything you’d need to build an indexer like this.
Finally, after the document has been indexed, there needs to be some way for the user to query the search index. The query component takes queries expressed by the user and translates them into the index access operations needed to find all the matching documents. The query component is normally tightly related to the indexer component, because they both contain information about the structure and organization of the inverse index and typically need to use the same analyzer configuration to map both documents and queries to the same underlying index terms. Because of this interdependence, you’ll normally use the same library or framework for both of these components.
Search is useful as a standalone service, but elements of search engines are often found also in other types of information-processing systems. This is natural, both because search is such an important feature and because the crawling and extraction components of a search engine are useful also in other applications. In the next section we’ll look at two broad categories of such applications.
9.2. Managing and mining information
A classic search engine as described in the previous section deals with documents that are stored and managed elsewhere and produces results that typically point to those external resources. What if your application is in charge of managing all those documents or needs to produce high-level reports that summarize or combine the contained information in some intelligent manner? These are the two categories of information-processing systems that we’ll cover next.
The first category is document management systems, of which there are quite a few different types, ranging from personal information management systems to huge record archives. The second is the emerging field of text mining, which has experienced some nice advances in recent years. Let’s start with document management.
9.2.1. Document management systems
Understood broadly, a document management system combines a document collection and search engine into a single service. Such a system takes care of storing, classifying, archiving, and tracking documents or other sorts of digital assets, and provides support for accessing the documents in various different ways, including searching and reporting. Often a document management system also includes things such as workflow support and integration with various other systems, for example, Documentum, SharePoint, and so on.
Common examples of document management are content, asset, and records management systems used by many companies. Even tools such as customer relationship management systems have similar features or contain an embedded document database, because they need to efficiently track and access documents such as sales quotes, customer requests, and other related correspondence.
Figure 9.3 shows a high-level overview of the typical architecture of a document management system. The system consists of a document database and a search index for locating documents within the database.
Figure 9.3. Overview of a document management system

A document management system can use Tika not only as a part of the embedded search index, but also as a tool for helping automatically classify documents and report document characteristics. The metadata extraction (see chapter 6) and language detection (see chapter 7) capabilities of Tika are often highly useful, as they allow the system to better understand and categorize a document that might otherwise look like a bunch of bits that a user would need to explicitly classify. Even the basic type detection feature discussed in chapter 4 can be important for such a system.
Downloads Done Right A web-based document management system normally needs to provide a way for users to download documents for local review and editing. An important part of such a feature is annotating the download with a Content-Type header that contains the correct media type of the document, because without that information it’s difficult for the browser to determine how to best handle the document. With Tika’s automatic type detection there’s no excuse not to provide that information.
Search engines and different kinds of document management systems are probably the most important environments where Tika is being used, but there’s also an exciting new category of tools that’s quickly becoming mature. Read on to learn more about text mining and how to use Tika in that context!
9.2.2. Text mining
Traditional search engines or document management systems mostly just organize or manage information and are typically judged in quantitative terms such as how many documents they cover. Text mining applications are different in that they take existing documents but produce qualitatively different information, for example, in the form of relationships or key concepts.
Consider a task where you’re given an archive of all the email messages and other documents from your company over the last three years, and asked to provide a summary of all information related to a particular product or event. How would you go about achieving such a task? The sheer magnitude of raw data even in a small company rules out any manual approaches. You’ll need a computer (or a whole set of them) to mine through the data and report back with the information you’re looking for.
This is one example of the large class of information-processing tasks that are nowadays being performed using text mining tools. The key elements of such tasks are their large scale and the unstructured nature of the information being processed. A more traditional data mining task would typically consist of correlating and summarizing individual data points stored as structured rows in a relational database. With text mining, we don’t have the luxury of predefined structure. The relevant data is usually stored within the ambiguity of natural language and scattered around among multiple kinds of documents, messages, and databases.
Figure 9.4 shows a high-level overview of a typical data mining system. The system consumes documents from a large collection, processes the information contained in the documents, and outputs the mining results in the form of reports, databases, or other high-level summaries that users can often use directly without having to reach back to any individual source document.
Figure 9.4. Overview of a text mining system

Text mining systems like these are normally designed to work on plain text, from which they then extract structure and meaning through natural language processing or other text processing methods. But the source data to be mined is usually stored in formats such as email messages, web pages, or office documents. A text extraction step is needed to make such data useful to a text mining system, and this is where Tika comes in handy.
Many text mining systems use an internal processing pipeline to convert the incoming data from raw bytes or characters to increasingly meaningful units of information such as grammar trees or word occurrence vectors. Tika can usually be plugged into an early part of such a pipeline in order to convert incoming documents from bytes to text that can then be used as input to later stages of the pipeline.
That’s where Tika fits within text mining. Together with earlier points about search engines and document management systems, you should now have a good picture of the most common kinds of applications where Tika is being used. Next we’ll turn our attention to some key nonfunctional features that are relevant to all these and other kinds of applications.
9.3. Buzzword compliance
When talking about software components and applications, modularity or scalability come up often. Such features are so desirable that they’ve become buzzwords. If you trust marketing materials, virtually all software is highly scalable and modular. But what do these features mean in practice, and how does Tika scale on this buzzword-meter? Read on to find out!
9.3.1. Modularity, Spring, and OSGi
Most information-processing systems are complex applications composed of many smaller libraries and components. Being able to incrementally upgrade, customize, or fix individual components without breaking the rest of the system is therefore very useful. Complex deployment requirements (cloud, mobile, and so on) and the increasingly distributed organization of software development teams also benefit from good component architectures. Modularity has been a goal of software architects for decades, but it’s never been as important as today!
How does Tika fit within a modular component architecture? As discussed in previous chapters, Tika’s internal architecture is designed to be as pluggable and modular as possible. Most notably, one of the key design criteria for the Parser API covered in chapter 5 was to support easy integration with external parser libraries and components. Thus a Tika deployment with parser components from multiple different sources could easily look like the one featured in figure 9.5. In chapter 11 we’ll go into more detail on how and why to implement such custom or third-party parser plugins.
Figure 9.5. Tika deployment with parser implementations from multiple different sources

In addition to being easy to implement, Tika parsers are also easy to use in a component environment. For example, all parser classes are expected to have a zero-argument constructor and be configurable dynamically through the parsing context mechanism discussed in chapter 5. The following Spring bean configuration snippet illustrates this by wiring up a simple composite parser that understands both plain text and PDF documents:
-->
<bean id="tika" class="org.apache.tika.parser.AutoDetectParser">
<constructor-arg>
<list>
<ref bean="txt"/>
<ref bean="pdf"/>
</list>
</constructor-arg>
</bean>
<bean id="txt" class="org.apache.tika.parser.txt.TXTParser"/>
<bean id="pdf" class="org.apache.tika.parser.pdf.PDFParser"/>
<!
A component configuration like the one shown here creates a static composition of parsers. Modifying the configuration requires restarting your application or at least reloading the configuration and all components that depend on it. But sometimes a more dynamic mechanism is needed. Imagine being able to replace the PDF parser with a commercially licensed alternative, upgrade the plain text parser for a version with the latest bug fixes, and add a new parser for a custom file format without having to restart or even reload any other components of the system! This is what the OSGi framework makes possible.
The OSGi framework is a modular service platform for the Java environment. Originally designed for embedded systems with complex deployment and management requirements, OSGi is also quickly becoming popular on the server side. Tika supports OSGi through the tika-bundle component, which combines Tika core classes and all the default parsers into a single package that can easily be deployed into an OSGi container. Once deployed, the Tika bundle will provide all the standard Tika classes and interfaces that we’ve already covered. And as an extra twist, the bundle will automatically look up and use possible parser services from other bundles.
9.3.2. Large-scale computing
What if your modules are entire computers instead of individual software components? Especially in large search and text mining applications, it’s becoming increasingly common to spread the processing load to hundreds or thousands of commodity servers. Cloud services like Amazon’s Elastic Computing Cloud (EC2) make such environments readily available at low cost and minimal overhead. But how do you run Tika on such systems?
Such large-scale deployments typically use sharding or map-reduce algorithms for controlling their workload. The basic idea is that the data to be processed is distributed over the computing cluster, and each individual computer is only responsible for handling a small subset of the data. This approach works well with Tika, which only really cares about a single document at a time.
For example, consider a case where you need to create a full-text index of millions of documents. In chapter 5 we outlined how to build a simple full-text indexer with Tika, but it may take months for such an application to index all the documents on a single computer. Now what if you’re given 1,000 computers to achieve this task? Figure 9.6 illustrates what a difference distributing such computations over multiple computers can make.
Figure 9.6. Distributing a large workload over multiple computers can dramatically improve system throughput.

The only requirements for such distribution of computing work is that the processing can be split into independent pieces that can be processed in parallel and that the results of these partial processes can be combined easily. Luckily, an inverse search index meets both these requirements in that documents can be indexed in parallel and it’s easy to merge two or more independent indexes into a single larger index. This suggests a straightforward map-reduce solution illustrated in figure 9.7.
Figure 9.7. Building an inverse index as a map-reduce operation

What happens here is that we split our collection of input documents into parts that each contain a few hundred documents. These parts are then sent to individual computers for producing an index that covers just those documents. This is the “map” part of our map-reduce solution. The resulting small indexes are then “reduced” into a big index by merging them together.
An important concern in such a solution is being able to properly handle computer failures. The more computers you’re using, the more likely it becomes that at least one of them will fail while it’s doing important work. The solution to such cases is to restart the failed computation on another computer.
There’s a fast-growing ecosystem of tools and communities focused on such large-scale information systems. A good place to start is the Apache Hadoop project which, together with related Apache projects, implements a comprehensive suite of cloud computing tools.
9.4. Summary
This completes our high-level overview of where and how you might find yourself using Tika. We started with a search engine walkthrough and a brief overview of document management and text mining as examples of related information-processing systems. Then we turned to modularity and scalability as key nonfunctional features. As we found out, Tika supports component systems such as Spring and OSGi, and it also fits in nicely with large-scale architectures such as map-reduce operations.
A single chapter is only enough to scratch the surface, but you’ll find a lot more information in books and other resources dedicated to these topics. Good starting points are other books in Manning’s In Action series, which covers pretty much all the projects and technologies mentioned in this chapter. Since Tika is such a new tool, it’s not yet widely referenced in existing literature, and the information from this chapter should help you fill in those blanks where appropriate.
The next chapter is dedicated to a sprawling collection of open source tools and projects that are often found in applications and systems described in this chapter. Read on to discover the Lucene search stack!