
Chapter 2. Getting started with Tika
This chapter covers
Equipped with sufficient background on Apache Tika, you’re probably thinking to yourself: how do I start leveraging Tika in my own application? Tika is a modern Java application, and its development has undergone the natural evolution that most Java applications do: beginning as a set of Java classes exported as an API, followed by a basic command-line interface, and culminating with a graphical user interface (GUI) for the command-line neophyte (or those with a preference for visual interfaces).
Executing Tika at runtime is a separate step from building Tika from source code. Because Tika is an open source project at the Apache Software Foundation and provided under the Apache License version 2.0 (ALv2),[1] many of its users (you may be one of them) will be perfectly comfortable grabbing the Tika source code and building/integrating it into their applications. To do so, you’ll need some basic knowledge of the primary Tika build tool, Apache Maven, along with some basic knowledge of JUnit tests in order to make sure the Tika software will execute correctly in your environment.
1 The Apache Software Foundation is a community of open source projects characterized by a collaborative and consensus-based development process. The Apache License used by Apache projects is a permissive open source license that allows software with the license to be used and redistributed as a part of proprietary software. See the Apache website at http://www.apache.org/ for more details.
In this chapter, we’ll cover the basics of integrating Tika into your environment, whether you prefer executing Tika via command line, API, GUI form, or starting from the source code. We’ll start by introducing you to building Tika using Apache Maven or Apache Ant, a world you’ll need to familiarize yourself with (albeit briefly) to get working with the Tika source code.
2.1. Working with Tika source code
Before we get too deep into building Tika, we’ll briefly describe how to obtain the Tika source code, the starting point for building Tika and for integrating Tika into your Java application. You can skip this section if you’re only interested in using released Tika binaries, but as with any open source project, having access to and being able to modify and build the source code gives you a lot of extra opportunities.
2.1.1. Getting the source code
The first step in building Tika, obviously, is getting the source code. You download the source code of all Tika releases from the download section of the Tika website (http://tika.apache.org), but often the most interesting stuff is in the latest development tree that you can find in the version control system.
All Apache projects manage their source code in a big Subversion repository at http://svn.apache.org/, and Tika is no exception. Assuming you have a Subversion client installed, you can check out the latest Tika development tree with the following command:
svn checkout http://svn.apache.org/repos/asf/tika/trunk tika-trunk
Git Mirrors If you prefer the Git version control system over Subversion, you’ll want to check out the Git mirrors that Apache makes available at http://git.apache.org/. The Git clone URL for Tika is git://git.apache.org/tika.git and you can find Tika also on Github at http://github.com/apache/tika.
To keep up with the latest developments, run svn update (or git pull if you use Git) in the checked-out directory. This updates your copy with the latest changes committed to the Subversion repository. And if you want to submit a bug fix or a new feature to Tika, you can use svn diff to get a nicely formatted patch that includes all the changes you’ve made to your local copy of the source tree. But let’s not get ahead of ourselves—first we need to get the source code to build!
2.1.2. The Maven build
The Tika build is based on Apache Maven. If you don’t already have Maven installed on your computer, you can grab the latest version from the Maven website at http://maven.apache.org/. Once you’ve done that, you can start the Tika build by executing the following command in the project directory that you just checked out:
mvn clean install
That’s it. You can do a lot with Maven, but the preceding command will automatically clean up the build environment, download all the external dependencies, compile and package all the Tika source code, run the included unit and integration tests, and finally install the tested Tika libraries to your local Maven repository. You can, for example, find the freshly built standalone tika-app JAR file in the tika-app/target directory.
Maven Running Out of Memory? Running into memory issues when trying to compile Tika? Recent versions of Tika build several deliverable JAR files, some of which pull in many dependencies. If you’re getting Java or Maven OutOfMemory exceptions when running mvn install, try setting environment variable MAVEN_OPTS="-Xmx512m". This will allocate 512 megabytes of memory to Java and Maven; most times, this will get you through the build.
All of the major integrated development environment (IDE) tools such as Eclipse, IDEA, and NetBeans have good support for Maven builds, so you can easily import Tika to your IDE workspace for easy access to this functionality and more. See the relevant documentation of your favorite IDE for details on how to work with Maven projects.
2.1.3. Including Tika in Ant projects
Though Tika’s build is optimized for Maven, it’s fairly easy to use Tika with Apache Ant, another popular build tool. Ant is commonly included with many modern *nix distributions, but if you need to install Ant for any reason, you can grab it from the Ant website at http://ant.apache.org/. We’ll assume that you’ve created a build.xml file to begin working with Ant in your project. Including Tika in that Ant project is as simple as finding the existing <classpath> entry in your build.xml file (or adding a new <classpath> entry) and then including the Tika JARs in your <classpath> block.
It’s worth noting that version numbers could change by the time you read this, so to discern the actual dependencies, it’s better to use the mvn dependency:list or mvn dependency:tree commands to determine the latest versions of dependent libraries:
<classpath> ... <!-- your other classpath entries --> <pathelement location="path/to/tika-core-1.0.jar"/> <pathelement location="path/to/tika-parsers-1.0.jar"/> <pathelement location="path/to/slf4j-api-1.5.6.jar"/> <pathelement location="path/to/slf4j-log4j12-1.5.6.jar"/> <pathelement location="path/to/log4j-1.2.14.jar"/> <pathelement location="path/to/commons-logging-1.1.1.jar"/> <pathelement location="path/to/commons-codec-1.4.jar"/> <pathelement location="path/to/commons-compress-1.1.jar"/> <pathelement location="path/to/netcdf-4.2-min.jar"/> <pathelement location="path/to/pdfbox-1.5.0.jar"/> <pathelement location="path/to/fontbox-1.5.0.jar"/> <pathelement location="path/to/jempbox-1.5.0.jar"/> <pathelement location="path/to/poi-3.8-beta2.jar"/> <pathelement location="path/to/poi-scratchpad-3.8-beta2.jar"/> <pathelement location="path/to/poi-ooxml-3.8-beta2.jar"/> <pathelement location="path/to/poi-ooxml-schemas-3.8-beta2.jar"/> <pathelement location="path/to/xmlbeans-2.3.0.jar"/> <pathelement location="path/to/dom4j-1.6.1.jar"/> <pathelement location="path/to/geronimo-stax-api_1.0_spec-1.0.1.jar"/> <pathelement location="path/to/tagsoup-1.2.jar"/> <pathelement location="path/to/asm-3.1.jar"/> <pathelement location="path/to/metadata-extractor-2.4.0-beta-1.jar"/> <pathelement location="path/to/apache-mime4j-0.6.jar"/> <pathelement location="path/to/bcmail-jdk15-1.45.jar"/> <pathelement location="path/to/bcprov-jdk15-1.45.jar"/> <pathelement location="path/to/boilerpipe-1.1.0.jar"/> <pathelement location="path/to/rome-0.9.jar"/> <pathelement location="path/to/jdom-1.0.jar"/> </classpath>
Alternatively, you may include just the tika-app-1.0.jar file as a classpath element in your build.xml:
<classpath> ... <!-- your other classpath entries --> <pathelement location="path/to/tika-app-1.0.jar"/> </classpath>
Once you’ve integrated Tika into your classpath using one of these methods, to get going with your build, run
ant -f build.xml
... and you’re set!
Now that you’ve built Tika and learned how to integrate it into your Ant project, it’s time to learn how to interact with its two primary external interfaces: the command line and Tika’s graphical user interface (GUI).
2.2. The Tika application
The first step in revving up your new Babel Fish is deciding between two simple external interfaces that are part of the Tika application: a graphical user interface (GUI) that provides drag-and-drop functionality, and a command-line interface for folks comfortable with scripting environments. In this section we’ll first show you how to download Tika, and then walk you through each of these interfaces.
The quick-and-easy way to get started with Tika is to use the Tika application, a standalone JAR archive that contains everything you need to access the key Tika features. The application is available for download from the Tika website at http://tika.apache.org/. The current version of Tika is 1.0 at the time of writing this book, so we’ll use that in our examples, but any recent Tika version should work equally well if not better. It’s worth noting that you’ll need Java 5 or higher to run the standalone JAR archive, called tika-app-1.0.jar. The archive is available after you compile Tika inside of the tika-app/target directory.
To start up the standalone JAR, use the java command’s -jar option: java -jar tika-app-1.0.jar. The --help option displays a summary of the available command-line options and a brief description of the application, as shown next.
Listing 2.1. Built-in documentation of the Tika application
$ java -jar tika-app-1.0.jar --help
usage: java -jar tika-app.jar [option...] [file|port...]
Options:
-? or --help Print this usage message
-v or --verbose Print debug level messages
-g or --gui Start the Apache Tika GUI
-s or --server Start the Apache Tika server
-x or --xml Output XHTML content (default)
-h or --html Output HTML content
-j or --json Output JSON content
-t or --text Output plain text content
-T or --text-main Output plain text content (main content only)
-m or --metadata Output only metadata
-l or --language Output only language
-d or --detect Detect document type
-eX or --encoding=X Use output encoding X
-z or --extract Extract all attachments into current directory
--list-parsers
List the available document parsers
--list-parser-details
List the available document parsers, and their supported mime types
--list-met-models
List the available metadata models, and their supported keys
--list-supported-types
List all known media types and related information
Description:
Apache Tika will parse the file(s) specified on the
command line and output the extracted text content
or metadata to standard output.
Instead of a file name you can also specify the URL
of a document to be parsed.
If no file name or URL is specified (or the special
name "-" is used), then the standard input stream
is parsed. If no arguments were given and no input
data is available, the GUI is started instead.
- GUI mode
Use the "--gui" (or "-g") option to start the
Apache Tika GUI. You can drag and drop files from
a normal file explorer to the GUI window to extract
text content and metadata from the files.
- Server mode
Use the "-server" (or "-s") option to start the
Apache Tika server. The server will listen to the
ports you specify as one or more arguments.
As you can see, the graphical user interface (GUI) mode is invoked with the --gui option or if you run tika-app.jar without any arguments. The GUI provides a visual means of navigating Tika’s features, along with a simple drag-and-drop interface for exploring a document’s extracted textual content and metadata, as well as for determining whether the document was parsed correctly. Let’s take a look at the GUI first before discussing the other methods of interacting with Tika.
2.2.1. Drag-and-drop text extraction: the Tika GUI
The Tika GUI mode is especially useful when you’re sitting in front of your computer interactively trying to figure out how well Tika understands some specific documents. By “how well,” we mean the information that Tika is able to identify about the document, such as its MIME type, its language, the structured text, and the extracted metadata. In particular, it’s important to interactively explore Tika’s understanding of your document types, as you may be dealing with files that Tika has never seen before, or that contain content for which Tika needs tuning to better understand. In this regard, first interactively exploring the document using the Tika GUI is a viable solution before turning your deployed Tika app into a lights-out solution that you can run in batch mode automatically (we’ll see more of that in the command-line section).
At its core, the Tika GUI is a simple tool that allows you to try out the canonical Tika features (text extraction, metadata extraction, and so on) on all sorts of files. To start the GUI, use the --gui option like this: java -jar tika-app-1.0.jar --gui. This starts up a simple Apache Tika GUI window as shown in figure 2.1.
Figure 2.1. Tika GUI window

You can drag and drop files or URL links from a file explorer or a web browser into this window, and Tika will automatically extract all the content and metadata it can from the given document. The various forms of extracted information are shown in separate views as described in table 2.1. Any parsing errors or other problems are reported in a separate window that shows the relevant error message and related stack trace.
Table 2.1. Information included in views of the Tika GUI window
|
View |
Description |
|---|---|
| Formatted text | Extracted text content as formatted XHTML. You can use this view to see how well Tika understands the structure of the document that was parsed. Ideally you should see all content in correct order with details such as links and headings in place. |
| Plain text | Extracted text content as plain text. This view is most useful for understanding how (for example) a simple search index that doesn’t care about text structure sees your document. |
| Structured text | Extracted text content as raw XHTML. Shows the exact XHTML output produced by the Tika parser. See chapter 5 for more details on this and the other two text views. |
| Metadata | Extracted document metadata. This view will tell you the exact document type and any other information, such as title or author of the document, that Tika was able to extract. See chapter 6 for more details about document metadata. |
The Tika GUI is great for interaction-driven exploration of your files and documents, but what if you want to automatically process large batches of documents or to integrate Tika with other (existing) applications automatically, without human intervention? This is where the other command-line options come in.
2.2.2. Tika on the command line
When you don’t specify the --gui option, the standalone JAR will act as any normal command-line application would. It reads a document from standard input and writes the extracted content to standard output. The default command-line behavior is highly relevant, especially after exploring your Tika deployment and its understanding of your document types interactively via the GUI. In most cases, once you’re comfortable parsing your documents via the GUI, you’ll move into a mode of batch processing the documents with Tika, leveraging that default command-line behavior.
You can customize the command-line behavior with various command-line options, but by default the output consists of the extracted text in XHTML format. In the following example, we first call Tika and provide (via a Unix input pipe, the < symbol) the contents of the document.doc file, then take the output results of the Tika command (extracted XHTML text) and write that output (via the Unix output pipe, the > symbol) to the file extracted-text.xhtml:
java -jar tika-app-1.0.jar < document.doc > extracted-text.xhtml
You can use this command-line mode to integrate Tika with non-Java environments, such as shell scripts or other scripting languages. For example, it’s easy to use Tika as a part of a Unix pipeline either directly on the command line, or as part of a more complex script. In the following example, a document is printed to Unix standard output (via cat), then piped into a call to Tika (the java -jar.. command), and then specific text is identified in the extracted text output using the Unix grep command:
cat document.doc | java -jar tika-app-1.0.jar | grep some-text
Save Some Typing If you’re using the bash shell on a Unix-like computer, you can avoid some extra typing by defining the following alias: alias tika="java -jar /path/to/tika-app-1.0.jar". Then you can run the Tika application by typing just tika on the command line. The syntax of the alias command may differ slightly if you use another shell such as tcsh. See the relevant man page for details.
If the input document is available as a normal file or can be downloaded from a URL, then you can pass the filename or the URL as a command-line argument. Tika will read the document from the given file or URL instead of from the standard input, and will also use the filename or a possible content type setting returned by a web server as additional information when processing the document:
java -jar tika-app-1.0.jar http://www.example.com/document.doc
Instead of XHTML output, you can also request traditional HTML or plain text by specifying the --html or --text command-line option:
java -jar tika-app-1.0.jar --text document.doc
Note that Tika will by default output text using the normal character encoding used on your computer. This is great if you’re using Tika with tools such as your command-line console window that expect this default character encoding, but may cause trouble otherwise. To avoid unexpected encoding problems, you can explicitly set the output encoding with the --encoding option:
java -jar tika-app-1.0.jar --encoding=UTF-8 --text document.doc
If you’re more interested in the document metadata than in the contents of the document, you can ask for a metadata printout with the --metadata option. This will output the extracted document metadata in the Java properties file format:
java -jar tika-app-1.0.jar --metadata document.doc
The GUI and command-line modes are useful tools, but as Java developers likely already understand, leveraging Tika as an embedded library within Java is where the full power of Tika really lies. Tika’s GUI and command-line interface are powered under the hood by a set of Java classes and APIs that the GUI and command-line interface expose to Tika’s users. From a GUI perspective, interaction with visual aids and via clicks and drag-and-drop actions are a means to codify user intent—to turn that intent into a series of method calls to Tika’s Java API, grab the results from Tika, and present those findings to the user. The same goes for the command-line API. It grabs user interaction in the form of command-line arguments and switches, then sends that information to the Tika Java classes. It gets the results and finally presents those results to the user by printing the results to the terminal output. Because both the GUI and command-line interface ultimately restrict interaction to their mode of choice and simplify the underlying complexity of the Tika library (which is a good thing because it lowers the entry barrier to using Tika), a lot of “advanced user” expressiveness and flexibility are limited to what’s provided in those interaction modes. Using Tika in native Java affords you all of the necessary language-level and build-level tools to overcome those interaction limitations and unlock the power and features of Tika.
So, now that we’ve covered most of Tika’s GUI and command-line functionality, we’ll switch gears and start writing some Java code to help you unlock Tika’s true flexibility and expressiveness!
2.3. Tika as an embedded library
Though GUIs and command-line integration are rapid ways of exploring what Tika has to offer, the real power of Tika is unveiled when you leverage Tika Java classes and APIs in your application. We’ll start with the simplest and most direct way of calling Tika from Java: the Tika facade. After the facade discussion, you’ll be introduced to Tika’s modules and source code organization, a necessary primer for building and running Tika code and ultimately for integrating Tika into your Java project.
2.3.1. Using the Tika facade
As we’ll see in later chapters, Tika provides powerful and detailed APIs for many content detection and analysis tasks. This power comes with a price of some complexity, which is why Tika also contains a facade class that implements many basic use cases while hiding most of the underlying complexity. This facade class, org.apache.tika.Tika, is what we’ll be using in this section.
Think of the facade as you would a financial broker that manages your investments. You provide your broker investment capital and that broker works behind the scenes to invest your money in different bonds and stocks that meet your desired level of risk. To do so, the broker must understand what companies suit your risk profile and are a sound investment; where to find those companies; how to purchase stock in your name; what’s been going on in the market—navigating the complex financial landscape on your behalf. Your interface to this broker is the simple exchange of money, along with some high-level specifications for your investment strategy.
In the same vein, the Tika facade is an honest broker of the information landscape. Its goal is to simplify the complexity behind all of the unique aspects of the underlying Tika library: its MIME detection mechanism, used to quickly and accurately identify files; its parsing interface, used to quickly summarize a document by extracting its text and metadata; its language detection mechanism; and so on. As we’ll see in later chapters, the use of each one of these features within Tika deserves a chapter’s worth of material in its own right. But the Tika facade’s job is to obfuscate this complexity for you (just like the financial broker) and to provide simple, clear methods for making document file analysis and understanding a snap.
The SimpleTextExtractor class shown next uses the Tika facade for basic text extraction. A Tika object is first created with the default configuration and then used to extract the text content of all files listed on the command line.
Listing 2.2. Simple text extractor example
import java.io.File;
import org.apache.tika.Tika;
public class SimpleTextExtractor {
public static void main(String[] args) throws Exception {
// Create a Tika instance with the default configuration
Tika tika = new Tika();
// Parse all given files and print out the extracted text content
for (String file : args) {
String text = tika.parseToString(new File(file));
System.out.print(text);
}
}
}
The standalone JAR archive discussed earlier contains everything that this SimpleTextExtractor class needs, so you can compile and run it with the javac and java commands included in the standard Java Development Kit (JDK):
$ javac -cp tika-app-1.0.jar SimpleTextExtractor.java $ java -cp tika-app-1.0.jar:. SimpleTextExtractor document.doc
Or, if you’re a Maven guru, you can compile and run the SimpleTextExtractor from the book’s source code using your favorite document.doc file by issuing the below command:
$ mvn exec:java -
Dexec.mainClass="tikainaction.chapter2.SimpleTextExtractor"
-Dexec.args="document.doc"
As you can see from this simple text extractor example, the Tika facade is a powerful tool. In a few lines of code, we’ve created an application that can understand and process dozens of different file formats. Let’s see what else you can do with the facade. The class diagram in figure 2.2 summarizes the key features.
Figure 2.2. Overview of the Tika facade

Each of these three key methods takes an input document as an argument and returns information extracted from it. The document can be passed in as a generic java.io.InputStream instance or a more specific java.io.File or java.net.URL instance. The key methods are described in more detail in table 2.2.
Table 2.2. Key methods of the Tika facade
|
Method name |
Description |
|---|---|
| parseToString() | The parseToString() method used in the preceding example parses the given input document and returns the extracted plain-text content as a simple string. The length of the returned string is limited by default, so you don’t need to worry about running out of memory even when parsing huge documents. You can set a custom string length limit with the setMaxStringLength() method. |
| parse() | To conserve memory or to avoid the size limit, you can use the parse() method that returns a java.io.Reader instance for incrementally reading the text content of the input document. This method starts a background thread that parses the given document on demand as your application consumes the returned reader. |
| detect() | You can use the detect() method to detect the internet media type of a document. As discussed in more detail in chapter 4, Tika uses heuristics like known file extensions and magic byte patterns to detect file types. This method hides the details of all those mechanisms and returns the media type that most likely matches the given document. |
Despite its simplicity, the Tika facade covers many of the basic text extraction and detection use cases. For example, the “program that understands everything” that we set out to create in section 1.1 can easily be implemented using the functionality of the Tika facade.
We’ve spent most of the chapter thus far discussing various means of interacting with Tika: calling it from the command line or via a GUI, and ultimately integrating Tika’s classes and APIs into Java code for maximum flexibility. Now, we’re going to open up the hood and learn about how Tika’s modules and code are organized. This should help you understand how to extend Tika, compile its sources, and begin to integrate Tika into your existing Java applications as an external dependency.
2.3.2. Managing dependencies
Tika’s facade interface exposes functionality provided by Tika’s canonical Java classes, relationships, and APIs. As you begin to use the facade, or even the other aspects of Tika’s API that will be discussed in later chapters, you’ll probably wonder why certain class imports (such as org.apache.tika.Tika) are organized in particular packages, and why those packages are part of separate projects, such as tika-core versus tika-parsers. In short, you’ll need to understand the organization of the Tika code, shown in figure 2.3.
Figure 2.3. The Tika component stack. The bottom layer, tika-core, provides the canonical building blocks of Tika: its Parser interface, MIME detection layer, language detector, and the plumbing to tie it all together. tika-parsers insulates the rest of Tika from the complexity and dependencies of the third-party parser libraries that Tika integrates. tika-app exposes tika-parsers graphically, and from the command line to external users for rapid exploration of content using Tika. Finally, tika-bundle provides an Open Services Gateway Initiative (OGSI)-compatible bundle of tika-core and tika-parsers for using Tika in an OGSI environment.
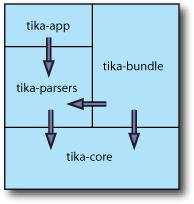
Tika is separated into four concrete components—tika-core, tika-parsers, tikaapp, and tika-bundle—as shown in the bottom, middle left, top left, and top right of figure 2.3, respectively. Each of the four components is organized as a Maven project, all referencing a tika-parent Maven project which stores project defaults such as common dependencies, mailing lists, developer contact, information, and other goodies that are fairly independent of the source code and the four aforementioned components.
Tika-Core
The tika-core component is the base component on which the other three package components are built. The component provides the Tika facade, the classes for MIME type detection (the org.apache.tika.mime package); the core parser interface (the org.apache.tika.parser package that Parsers in tika-parsers extend and implement the interface from); the language identifier interface (the org.apache.tika.language package); the core metadata structure (from the org.apache.tika.metadata package) output from Tika; and the methods for outputting structured text (the org.apache.tika.sax package). The tika-core component is also home to the Tika configuration (which configures the overall framework with properties, sets defaults, allows for extensibility, and so forth) and other utilities useful for other Tika components to leverage.
Tika-Parsers
The tika-parsers component represents the Tika wrappers around different parsing libraries, providing implementations of the generic org.apache.tika.parser.Parser interface specified by the tika-core component. Each package within tika-parsers provides all the necessary classes and functionality to wrap the underlying parser library, and insulates the dependencies and uniqueness of those classes from the rest of the Tika core framework components. In this manner, users wanting to take advantage of MIME detection or language identification independent of actually parsing the extracted text and metadata can do so without pulling in the vast array of (downstream) dependencies induced by integrating many parsing libraries into a single framework.
Tika-App
The tika-app component provides the command line and graphical user interface aspects of Tika, and is built on top of tika-parsers. Ultimately, the GUI and command-line interface expose the underlying parsing functionality, and through this elements of MIME detection and language identification are eventually plumbed as metadata output from a Tika Parser after its execution. In providing these external interfaces through tika-app, users are given a single packaged solution containing all of Tika (it’s what we showed you earlier in terms of the command-line interface), without having to worry about the underlying APIs and classes used to provide that external interface. This package also ensures fairly automatic interaction with Tika, as opposed to manually building and constructing Tika core classes (say, via tika-core and/or tika-parsers), and then calling their functionality as a series of methods that we’ll see later in the book. The trade-off here is automatically serving and exposing functionality for higher-level batch processing use cases within Tika.
Tika-Bundle
The tika-bundle component rounds out the Tika stack: it’s used to provide an Open Services Gateway Initiative (OGSI) bundle so that Tika can be included in an OGSI environment. OGSI is essentially a software component model and middleware framework for allowing component-based software development in Java. This means that OGSI is highly similar to Java Beans, a model for describing and implementing Java classes that deal with data as plain old Java objects (POJOs), and for operating both computationally and in a data-intensive matter on those POJOs. The goal of Java Beans was to pave the way for a component marketplace, separation of concerns, and ultimately for modular software to be written in Java so that systems and components could be extended, ported to a number of platforms, and evolved with as little direct code modifications as possible. OGSI encourages this mode of development, and defines on top of it explicit lifecycle phases for bundles; a security mechanism for those bundles; a means for registering and discovering bundles; and finally a way to make use of those bundles (call them, deploy them, and so on). The tika-bundle package was created because of a need in recent Tika deployments to include the full Tika stack (ideally, tika-app), but without pulling in all of tika-app’s transitive dependencies.
We’ve covered some basic Tika code, its use in Java, as well as its organization, and you’re hopefully familiar enough with Tika to start leveraging it via the command line, Tika’s GUI, or including its classes in your application.
2.4. Summary
Our goal in this chapter was to highlight the power of Tika, be it from a command-line shell, GUI, or by integrating Tika into your existing Java code. Along the way we covered the ancillary steps (tips for using Tika from a command shell, downloading Maven or Subversion) as well, but didn’t spend much time since most of those topics are the subjects of books in their own right.
The simplest and most visual method of using Tika is via its GUI, a thin wrapper around the tika-parsers module which exposes the ability to extract structured text, metadata, and plain text from any type of content through drag and drop. A lot of power with little barrier to entry.
If you’re a command-line hacker, or are looking to run Tika in batch mode, the command-line interface is your tool of choice. We covered the basics of Tika’s command-line help system, inputting files into Tika via pipes, writing out extracted text from Tika to files, and piping data into or out of Tika into the next application.
Tika is written in Java, which is where it gets most of its flexibility and expressiveness. We covered Tika’s facade, an interface to the underlying MIME detector, parsing framework, and language detection framework, and showed how in a few lines of Java code you too can quickly extract text and metadata from all of your documents.
In the next chapter, we’ll take a step back and reflect on the information landscape. Where are documents and other forms of content housed, and how do we unlock that information so we can send it to Tika? What are some advanced technologies to simplify getting and analyzing information, and how can Tika work with those technologies to improve how computers automatically comprehend information? Read on, and you’ll find out!