
Chapter 7. Language detection
Imagine you’re in charge of developing a searchable document database for a multilingual organization like the European Union, an international corporation, or a local restaurant that wants to publish its menus in more than one language. Typically no single user of such a database knows all the languages used in the stored documents, so the system should be able to categorize and retrieve documents by language in order to present users with information that they can understand. And, to make things challenging, most of the documents added to the database don’t come with reliable metadata about the language they’re written in.
To implement such a multilingual document database, you need a language detection tool like the one shown in figure 7.1. This tool would act like a pipeline that takes incoming documents with no language metadata and automatically annotates them with the languages they’re written in. The annotation should take the form of a Metadata.LANGUAGE entry in the document metadata. Our task in this chapter is to find out how this can be done.
Figure 7.1. The language detection pipeline. Incoming documents with no language metadata are analyzed to determine the language they’re written in. The resulting language information is associated with the documents as an extra piece of metadata.

Identifying written languages is in principle like the file format detection we covered in chapter 4, so the structure of this chapter follows a similar approach. After a quick look at our sample document and a simple code example in section 7.1, we re-encounter taxonomies in section 7.2, which describes the ISO 639 standard of language codes. Then, in section 7.2.1 we’ll find out about different ways in which the language of a given text can be detected. Finally, section 7.3 shows how Tika implements language detection and how you can leverage this functionality in your applications. And as usual, we’ll end the chapter with a brief summary that wraps up all the key points.
7.1. The most translated document in the world
The Universal Declaration of Human Rights (UDHR) is our sample document in this chapter. This famous declaration was adopted by the United Nations General Assembly in 1948 and has since become one of the best-known documents in the world. It has been translated into almost 400 languages.[1] In fact the UDHR holds the Guinness World Record for being the most-translated text in the world! It’s the perfect example for studying language identification, especially since the United Nations makes all the translations easily available online at http://www.ohchr.org/. Figure 7.2 gives you an idea of the range of available translations by showing the UDHR opening sentence in the six official languages of the United Nations.
1 As of late 2010 the UDHR was available in 375 different languages and new translation efforts were ongoing.
Figure 7.2. The first sentence of the first article of the Universal Declaration of Human Rights, written in Arabic, Chinese, English, French, Russian, and Spanish—the six official languages of the United Nations.

Let’s see what Tika can tell us about these translations. The simplest way to do that is to use the Tika application’s --language command-line option. This option tells Tika to detect the languages of given documents. The detection results are printed out as ISO 639 language codes. The following example shows Tika correctly detecting the English, French, Russian, and Spanish versions of the UDHR. Tika doesn’t yet understand Arabic or Chinese, but it’s learning fast!

What’s the magic behind the --language option, and how can you use it in your applications? Let’s find out!
7.2. Sounds Greek to me—theory of language detection
As discussed in chapter 4, the ability to consistently name and classify things is essential for fully understanding them. There are thousands of languages in the world, many with multiple dialects or regional variants. Some of the languages are extinct and some are artificial. Some don’t even have names in English! Others, like Chinese, have names whose specific meaning is highly context-sensitive.[2] A standard taxonomy that can name and classify all languages is needed to allow information systems to reliably store and process information about languages.
2 The Chinese language people normally refer to is Standard Mandarin, the official language of China and Taiwan. But Chinese is a complex family of related languages that span vast demographic, geographic, and historic spaces, though most of them share at least variations of the same written form. For example, the Chinese you hear in Hong Kong, Guangzhou, and Macau is Cantonese, a dialect that’s about as far from Mandarin as German or French is from English.
There are a number of different increasingly detailed systems for categorizing and naming languages, their dialects, and other variants. For example, according to the RFC 5646: Tags for Identifying Languages standard, you could use de-CH-1996 to identify the form of German used in Switzerland after the spelling reform of 1996. Luckily there aren’t many practical applications where such detail is necessary or even desirable, so we’ll focus on just the de part of this identifier.
The RFC 5646 standard leverages ISO 639 just like most of the other formal language taxonomies. ISO 639 is a set of standards defined by the International Organization for Standardization (ISO). The ISO 639 standards define a set of two- and three-letter language codes like the de code for German we encountered earlier. The two-letter codes that are most commonly used are defined in the ISO 639-1 standard. There are currently 184 registered two-letter language codes, and they represent most of the major languages in the world. The three-letter codes defined in the other ISO 639 standards are used mostly for more detailed representation of language variants and also for minor or even extinct languages.
The full list of ISO 639-1 codes is available from http://www.loc.gov/standards/iso639-2/ along with the larger lists of ISO 639-2 codes. Tika can detect 18 of the 184 currently registered ISO 639-1 languages. Here are the codes of these supported languages:
- da—Danish
- de—German
- et—Estonian
- el—Greek
- en—English
- es—Spanish
- fi—Finnish
- fr—French
- hu—Hungarian
- is—Icelandic
- it—Italian
- nl—Dutch
- no—Norwegian
- pl—Polish
- pt—Portuguese
- ru—Russian
- sv—Swedish
- th—Thai
After detecting the language of a document, Tika will use these ISO 639-1 codes to identify the detected language. But how do we get to that point? Let’s find out!
7.2.1. Language profiles
Detecting the language of a document typically involves constructing a language profile of the document text and comparing that profile with those of known languages. The structure and contents of the language profile depend heavily on the detection algorithm being used, but usually consist of some statistic compilation of relevant features of the text. In this section you’ll learn about the profiling process and different profiling algorithms.
Usually the profile of a known language is constructed in the same way as that of the text whose language is being detected. The only difference is that the language of this text set, called a corpus, is known in advance. For example, you could use the combined works of Shakespeare to create a profile for detecting his plays, those of his contemporaries, or modern works that mimic the Shakespearean style. Should you come across and old-looking book like the one shown in figure 7.3 you could use the Shakespearean profile to test whether the contents of the book match its looks. Of course, such a profile would be less efficient at accurately matching the English language as it’s used today.
Figure 7.3. Title page of a 16th century printing of Romeo and Juliet by William Shakespeare

A key question for developers of language detection or other natural language processing tools is how to find a good corpus that accurately and fairly represents the different ways a language is used. It’s usually true that the bigger a corpus is, the better it is. Common sources of such sets of text are books, magazines, newspapers, official documents, and so forth. Some are also based on transcripts of spoken language from TV and radio programs. And the internet is quickly becoming an important source, even though much of the text there is poorly categorized or labeled.
Once you’ve profiled the corpus of a language, you can use that profile to detect other texts that exhibit similar features. The better your profiling algorithm is, the better those features match the features of the language in general instead of those of your corpus. The result of the profile comparison is typically a distance measure that indicates how close or how far the two profiles are from each other. The language whose profile is closest to that of the candidate text is also most likely the language in which that text is written. The distance can also be a percentage estimate of how likely it is that the text is written in a given language.
You’re probably already wondering what these profiling algorithms look like. It’s time to find out!
7.2.2. Profiling algorithms
The most obvious way to detect the language used in a piece of text is to look up the used words in dictionaries of different languages. If the majority of words in a given piece of text can be found in the dictionary of some language, it’s likely that the text is written in that language. Even a relatively small dictionary of the most commonly used words of a language is often good enough for such language detection. You could even get reasonably accurate results with just the word the for detecting English; the words le and la for French; and der, die, and das for German!
Such a list of common words is probably the simplest reasonably effective language profile. It could be further improved by associating each word with its relative frequency and calculating the distance of two profiles as the sum of differences between the frequencies of matching words.[3] Another advantage of this improvement is that it allows the same profiling algorithm to be used to easily generate a language profile from a selected corpus instead of needing to use a dictionary or other explicit list of common words.
3 The distance computation can more accurately be represented as calculating the difference of two n-dimensional vectors, where each dimension corresponds to a distinct word and the component along that dimension represents the relative frequency of that word in the profiled text.
Alas, the main problem with such an algorithm is that it’s not very efficient at matching short texts like single sentences or just a few words. It also depends on a way to detect word boundaries, which may be troublesome for languages like German with lots of compound words or Chinese and Japanese where no whitespace or other extra punctuation is used to separate words. Finally, it has big problems with agglutinative languages like Finnish or Korean where most words are formed by composing smaller units of meaning. For example, the Finnish words kotona and kotoa mean “at home” and “from home” respectively, which makes counting common words like at, from, or even home somewhat futile.
Given these difficulties, how about looking at individual characters or character groups instead?
7.2.3. The N-gram algorithm
The profiling algorithm based on word frequencies can just as easily be applied to individual characters. In fact this makes the algorithm simpler, because instead of a potentially infinite number of distinct words, you only need to track a finite number of characters. And it turns out that character frequencies really do depend on the language, as shown in figure 7.4.
Figure 7.4. Frequency of letters in many languages based on the Latin alphabet
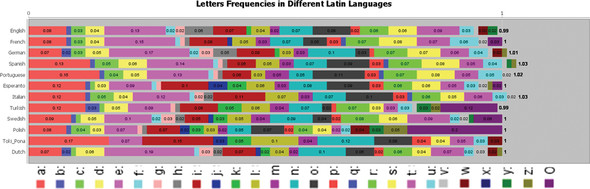
Obviously this algorithm works even better with many Asian languages that have characters which are used in only one or just a handful of languages. But this algorithm has the same problem as the word-based one in that it needs a lot of text for an accurate match. Interestingly enough, the problem here is opposite of that with words. Where a short sentence may not contain any of the most common words of a language, it’s practically guaranteed to contain plenty of the common characters. Instead the problem is that there isn’t enough material to differentiate between languages with similar character frequencies.
This detail hints at an interesting approach that turns out to be useful in language detection. Instead of looking at individual words or characters, we could look at character sequences of a given length. Such sequences are called 2-, 3-, and 4-grams or more generally N-grams based on the sequence length. For example, the 3-grams of a word like hello would be hel, ell, and llo, plus _he and lo_ when counting word boundaries as separate characters.
It turns out that N-grams[4] are highly effective for isolating the essential features of at least most European languages. They nicely avoid problems with compound words or the oddities of languages like Finnish. And they still provide statistically significant matches even for relatively short texts. Tika opts to use 3-grams, as that seems to offer the best trade-off of features in most practical cases.
4 There are many research papers on N-grams for language detection. A simple search on scholar.google.com for “N-gram language identification” will reveal many of most relevant ones.
7.2.4. Advanced profiling algorithms
Other more advanced language profiling algorithms are out there, but few match the simplicity and efficiency of the N-gram method just described. Typically such algorithms target specific features like maximum coverage of different kinds of languages, the ability to accurately detect the language of very short texts, or the ability to detect multiple languages within a multilingual document.
Tika tracks developments in this area and may incorporate some new algorithms in its language detection features in future releases, but for now N-grams are the main profiling algorithm used by Tika.
Now that we’ve learned the basics of language codes and profiling algorithms, let’s look at how to use them in practice. It’s coding time!
7.3. Language detection in Tika
The language detection support in Tika is designed to be as easy to use as possible. You already saw the --language command-line option in action in section 7.1, and the Java API is almost as easy to use. The class diagram in figure 7.5 summarizes the key parts of this API.
Figure 7.5. Class diagram of Tika’s language detection API
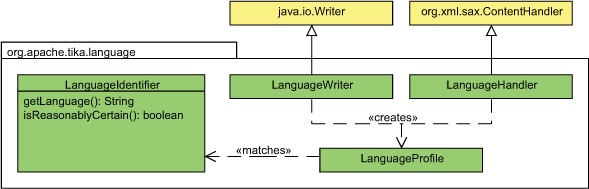
The keys to language detection in Tika are the LanguageProfile and Language-Identifier classes in the org.apache.tika.language package. A LanguageProfile instance represents the language profile of a given piece of text. The default implementation in Tika 1.0 uses 3-grams for the language profile. Once you’ve constructed the language profile of a document, you can use the LanguageIdentifier class to map the profile into a matching ISO 639 language code. The following code shows how to do this:

Sometimes there’s no clear match for a language profile, either because the language of the profiled text isn’t yet known by Tika or because the profiling algorithm doesn’t work optimally for that language or for that particular piece of text. You can use the isReasonablyCertain() predicate method of the LanguageIdentifier class to detect whether the language match is reliable. This method uses best-effort heuristics to estimate the accuracy of the language match, so even a positive result doesn’t guarantee a 100% accurate match, but helps filter out most of the false matches encountered in practice.
7.3.1. Incremental language detection
You may have noticed that the LanguageProfile constructor used in the preceding example takes the entire input document as a single string. But as discussed in chapter 5, a better approach is usually to use a character stream or a SAX event handler to process document content. This way we don’t need to keep the entire document in memory, and useful results can be obtained after accessing just part of the document. Tika supports such incremental language detection through the ProfilingWriter and ProfilingHandler classes.
The ProfilingWriter class is a java.io.Writer subclass that builds a language profile of the incoming character stream. The following example shows how this works:

You can call the ProfilingWriter instance’s getLanguage() method at any point, and it’ll return the profile of the text that has already been seen. In practice even a few hundred characters is usually more than enough to get a fairly accurate language profile. For example, the language profile of the preceding example starts to match Hungarian after the second append() call.
What if you want to profile the XHTML output of a Tika parser? The answer to that question is the ProfilingHandler class. A ProfilingHandler instance listens to SAX character events and profiles the contained text just like the ProfilingWriter. The following shows how to detect the language of a document parsed from the standard input stream:
ProfilingHandler handler = new ProfilingHandler();
new AutoDetectParser().parse(
System.in, handler,
new Metadata(), new ParseContext());
LanguageIdentifier identifier = handler.getLanguage();
System.out.println(identifier.getLanguage());
With these tools we’re now ready to address the task we set before ourselves at the beginning of this chapter!
7.3.2. Putting it all together
Remember the requirements of the multilingual document database described at the beginning of this chapter? It should be searchable and support categorization and filtering of documents based on the language they’re written in. Chapter 5 showed how to do the search part based on extracted text, and the metadata features described in chapter 6 are ideal for categorizing and filtering documents. We’ve just learned how to build the automatic language detector. Now we only need to combine these tools to achieve our goal.
Assuming you’ve already implemented full-text and metadata processing based on the previous chapters, the easiest way to add language detection functionality is to decorate your existing parser instance. We can do that easily by extending the DelegatingParser class that by default delegates all parsing tasks to the Parser instance found in the parsing context. Our extension is to inject a ProfilingHandler instance to the parsing process and add the identified language to the document metadata once the parsing process is completed. Here’s the complete source code for this solution.
Listing 7.1. Source code of a language-detecting parser decorator

So how does this example work? We start by customizing the parse() method so we can inject language detection functionality. We use the TeeContentHandler class to direct the extracted text both to the original content handler given by the client application and to the ProfilingHandler instance we’ve created for detecting the document language. You may remember the TeeContentHandler class from chapter 5. It’s perfect for our needs here, as it allows you to copy the parser output to multiple parallel handlers.
Once the setup is done, we invoke the original parse() method to parse the given document. Once the parsing is complete, we ask our profiler for the detected language identifier and use it to set the Metadata.LANGUAGE metadata entry if the language match was good enough to rely on.
You’d think that complex problems such as language detection would require lots of complicated code to achieve, but with the right tools it’s pretty simple! The preceding code is all you need to make your application tell the difference between documents written in French, Russian, English, or a dozen other languages. And the best part is that your application will grow brighter every time a new Tika release adds new language profiles or improves its profiling algorithms.
7.4. Summary
Let’s take a moment to look back at what we’ve learned in this chapter. Even though natural language processing is a fiendishly complex subject that has and probably will be a topic of scientific research for decades, certain areas are already useful in practical applications. Language detection is one of the simpler tasks of natural language processing, and can for the most part be implemented with relatively simple statistical tools. Tika’s N-gram–based language detection feature is one such implementation.
We described this feature through the examples of the UDHR document and a multilingual document database. After the introduction we covered standard ISO 639 language codes and proceeded to discuss commonly used language detection algorithms. Armed with this theoretical background, we looked at how Tika implements language detection. Finally, we combined the lessons of this chapter to a Parser decorator that can be used to integrate language detection to the full-text and metadata processing features from previous chapters.
If you’ve read this book from the beginning, you’ll by now have learned about type detection, text extraction, metadata processing, and, finally, language detection with Tika. These are the four main features of Tika, and the rest of this book will tell you more about how these features interact with the world around Tika. To begin, the next chapter takes you on a tour of the structure and quirks of many common file formats and the way Tika handles them.