
Appendix A
Matrix Analysis
A.1 Vector Spaces and Hilbert Space
Finite-dimensional random vectors are the basic building blocks of many applications. Halmos (1958) [1472] is the standard reference. We just take the most elementary material from him.
- addition is communicative, x + y = y + x,
- addition is associative, x + (y + z) = (x + y) + z,
- there exists in Ω a unique vector (called the origin) such that x + 0 = x, for every x, and
- to every vector in Ω there corresponds a unique vector −x such that x(− x) = 0.
These axioms are not claimed to be logically independent.
![]()
![]()
![]()
Recall that the basic building block in “Big Data” is a random vector which is defined in a finite-dimensional vector space. The dimension is high but still finite-dimensional. The high-dimensional data processing is critical to many modern applications.
![]()
![]()
If y1 and y2 are linear functions on Ω and α1 and α2 are scalars, let us define the function by
![]()
It is easy to check that y is also a linear functional; we denote it by α1y1 + α2y2. With these definitions of the linear concepts (zero, addition, scalar multiplication), the set Ω′ forms a vector space, the dual space of Ω.
A.2 Transformations
![]()
Linear transformations can be regarded as vectors.
![]()

A.3 Trace
The trace function, TrA = ∑iaii, satisfies the following properties [110] for matrices A, B, C, D, X and scalar α:
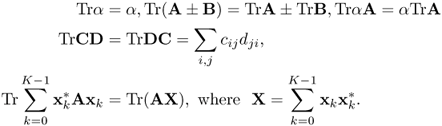
To prove the last property, note that since ![]() is a scalar, the left side of (A.1) is
is a scalar, the left side of (A.1) is

A.4 Basics of C*-Algebra
C*-algebras (pronounced “C-star”) are an important area of research in functional analysis. The prototypical example of a C*-algebra is a complex algebra ![]() of linear operators on a complex Hilbert space with two additional properties:
of linear operators on a complex Hilbert space with two additional properties:
C*-algebras [138, 1473] are now an important tool in the theory of unitary representations of locally compact groups, and are also used in algebraic formulations of quantum mechanics. Another active area of research is the program to obtain classification, or to determine the extent of which classification is possible. It is through the latter area that its connection with our interest in hypothesis detection is made.
A.5 Noncommunicative Matrix-Valued Random Variables
We mainly follow [11] this section, but with different notations that are convenient for our context. Random variables are functions defined on a measure space, and they are often identified by their distributions in probability theory [11]. In the simplest case when the random variables are real valued, the distribution is a probability measure on the real line. In this appendix probability distributions can be represented by means of linear Hilbert space operators, as well. (In this appendix an operator is an infinite-dimensional matrix.) This observation is as old as quantum mechanics; the standard probabilistic interpretation of the quantum mechanical formalism is related.
In an algebraic generalization, elements of a typically noncommutative algebra together with a linear functional on the algebra are regarded as noncommutative random variables. The linear functional evaluated on this element is the expectation value, its use to powers of this selected element leads to the moments of the noncommunicative random variables. One does not distinguish between two random variables, when they have the same moments. A very new feature of this theory occurs when these noncommunicative random variables are truly noncommuting with each other. Then, one cannot have a joint distribution in the sense of classical probability theory, but a functional of the algebra of polynomials of noncommuting indeterminates may work as an abstract concept of joint distribution [11]. Random matrices with respect to the expectation of their trace are natural “noncommuniting” noncommutative (matrix-valued) random variables.
Random variables over a probability space form an algebra. Indeed, they are measurable functions defined on a set Ω, and so are the product and sum of two of them, that is, A B and A + B. As mentioned before, the expectation value ![]() is a linear functional on this algebra. The algebraic approach to probability stresses this point. An algebra over a field is a vector space equipped with a bilinear vector product. That is to say, it is an algebraic structure consisting of a vector space together with an operation, usually called multiplication, that combines any two vectors to form a third vector; to qualify as an algebra, this multiplication must satisfy certain compatibility axioms with the given vector space structure, such as distributivity. In other words, an algebra over a field is a set together with operations of multiplication, addition, and scalar multiplication by elements of the field [1474].
is a linear functional on this algebra. The algebraic approach to probability stresses this point. An algebra over a field is a vector space equipped with a bilinear vector product. That is to say, it is an algebraic structure consisting of a vector space together with an operation, usually called multiplication, that combines any two vectors to form a third vector; to qualify as an algebra, this multiplication must satisfy certain compatibility axioms with the given vector space structure, such as distributivity. In other words, an algebra over a field is a set together with operations of multiplication, addition, and scalar multiplication by elements of the field [1474].
If ![]() is a unital algebra (a vector space defined above) over the complex numbers and ϕ is a linear functional of
is a unital algebra (a vector space defined above) over the complex numbers and ϕ is a linear functional of ![]() such that
such that
![]()
then ![]() will be called a noncommutative probability space and an element A of
will be called a noncommutative probability space and an element A of ![]() will be called a noncommunicative random variable. of course, a random matrix is such a noncommunitative random variable. The number ϕ(Ak) is called the n-th moment of a noncommutative random variable.
will be called a noncommunicative random variable. of course, a random matrix is such a noncommunitative random variable. The number ϕ(Ak) is called the n-th moment of a noncommutative random variable.
![]()
If ![]() is, further, self-adjoint (or Hermitian for the finite-dimensional case), then a probability measure is associated to A and φ, as mentioned above. The algebra used in the definition of a noncommunitative random variable is often replaced with a *-algebra. In fact,
is, further, self-adjoint (or Hermitian for the finite-dimensional case), then a probability measure is associated to A and φ, as mentioned above. The algebra used in the definition of a noncommunitative random variable is often replaced with a *-algebra. In fact, ![]() is a *-algebra, if the operation A* stands for the adjoint of A. The most familiar example of a *-algebra is the field of complex numbers C where * is just complex conjugation. Another example is the matrix algebra of n × n matrices over C with * given by the conjugate transpose. Its generalization, the Hermitian adjoint of a linear operator on a Hilbert space is also a *-algebra (or star-algebra).
is a *-algebra, if the operation A* stands for the adjoint of A. The most familiar example of a *-algebra is the field of complex numbers C where * is just complex conjugation. Another example is the matrix algebra of n × n matrices over C with * given by the conjugate transpose. Its generalization, the Hermitian adjoint of a linear operator on a Hilbert space is also a *-algebra (or star-algebra).
A *-algebra is a unital algebra over the complex numbers which is equipped with an involution*. The revolution recalls the adjoint operation of Hilbert space operators as follows:
When ![]() is a noncommunitative probability space over a *-algebra
is a noncommunitative probability space over a *-algebra ![]() ϕ is always assumed to be a state on
ϕ is always assumed to be a state on ![]() that is, a linear function such that
that is, a linear function such that
![]()
A matrix X whose entries are (classical) random variables on a (classical) probability space is called a random matrix, such as a sample covariance matrix XXH. Here H stands for the conjugate and transpose (Hermitian) of a complex matrix.
Random matrices form a *-algebra. For example, consider X11, X12, X21, X22 to be four bounded (classical) scalar random variables on a probability space. Then
![]()
is a bounded 2 × 2 random matrix. The set X of all such matrices has a *-algebra structure when the unit matrix operations are considered, and ![]() is a noncommunitative probability space when, for example,
is a noncommunitative probability space when, for example,
![]()
A C*-algebra is a *-algebra ![]() which is endowed with a norm such that
which is endowed with a norm such that
![]()
and furthermore, ![]() is a Banach space with respect to this norm.
is a Banach space with respect to this norm.
Gelfand and Naimark give two important theorems concerning the representation of C*-algebras.
Combination of the above two theorems yields a form of the spectral theorem. For a linear functional φ of a C*-algebra,
![]()
is equivalent to
![]()
A noncommunitative probability space ![]() will be called a C*-probability space when
will be called a C*-probability space when ![]() is a C*-algebra and φ is a state on
is a C*-algebra and φ is a state on ![]() .
.
All real bounded classical scalar random variables may be considered as noncommunicative random variables.
A.6 Distances and Projections
For projections, we freely use [1475]. Let ![]() denote the algebra of linear operators acting on a finite-dimensional Hilbert space
denote the algebra of linear operators acting on a finite-dimensional Hilbert space ![]() . The von Neumann entropy of a state ρ, i.e. that is, a positive operator of unit trace in
. The von Neumann entropy of a state ρ, i.e. that is, a positive operator of unit trace in ![]() , is given by S(ρ) = − Trρlogρ.
, is given by S(ρ) = − Trρlogρ.
For ![]() , the absolute value |A| is defined as
, the absolute value |A| is defined as ![]() and it is a positive matrix. The trace norm of A − B is defined as
and it is a positive matrix. The trace norm of A − B is defined as
![]()
This trace norm||A − B||1 is a nature distance between complex n × n matrices A and B, ![]() . Similarly,
. Similarly,

is also a natural distance. We can define the p-norm as
![]()
It was Von Neumann who showed first that the Hoelder inequality remains true in the matrix setting
![]()
If A is a self-adjoint and written as
![]()
where the vector ei form an orthonormal basis, then it is defined as
![]()
Then A = {A ≥ 0} + {A < 0} = A+ + A− and |A| = {A ≥ 0} − {A < 0} = A+ − A−. The decomposition is called the Jordan decomposition of A. Corresponding definitions apply for the other spectral projections {A < 0}, {A > 0}, and {A ≤ 0}. For two operators, {A < B}, {A > B}, and {A ≤ B}.
For self-adjoint operators A, B and any positive operator 0 ≤ P ≤ I we have
![]()
Identical conditions hold for strict inequalities in the spectral projections {A < B} and {A > B}.
The trace distance between operators A and B is given by
![]()
The fidelity of states ρ and ρ′ is defined as
![]()
The trace distance between two states is related to the fidelity as follows:
![]()
For self-adjoint operators A, B and any positive operator 0 ≤ P ≤ I, the inequality
![]()
for any ![]() > 0, implies that
> 0, implies that
![]()
The “gentle measurement” lemma is given here: For a state ρ and any positive operator 0 ≤ P ≤ I, if Tr(ρP) ≥ 1 − δ, then
![]()
The same holds if ρ is only a subnormalized density operator, that is, Trρ ≤ 1.
If ρ is a state and P is a projection operator such that Tr(Pρ) > 1 − δ for a given δ > 0, then
![]()
where
![]()
and ![]() .
.
Consider a state ρ and a positive operator σ ∈ Bε(ρ), for some ![]() > 0. If πσ denote the projection onto the support of σ, then
> 0. If πσ denote the projection onto the support of σ, then
![]()

The singular values of a matrix A ∈ Mn are the eigenvalues of its absolute value ![]() , we have fixed the notation s(A) = (s1(A), …, sn(A)) with s1(A) ≥…≥ sn(A). Singular values are closely related to the unitary invariant norm. Singular values inequalities are weaker than Löwner partial order inequalities and stronger than unitarily invariant norm inequalities in the following sense [133]:
, we have fixed the notation s(A) = (s1(A), …, sn(A)) with s1(A) ≥…≥ sn(A). Singular values are closely related to the unitary invariant norm. Singular values inequalities are weaker than Löwner partial order inequalities and stronger than unitarily invariant norm inequalities in the following sense [133]:
![]()
for all unitarily invariant norms. The norm ||A||1 = Tr|A| is unitarily invariant. Singular values are unitarily invariant: s(UAV) = s(A) for every A and all unitary U, V. A norm || · || is called unitarily invariant if
A.2 ![]()
for all A ∈ Mn and all unitary U, V ∈ Mn. ||A|| ≤ ||B|| for all unitarily invariant norms if and only if ![]() that is,
that is,
A.3 ![]()
The differences of two positive semidefinite matrices A, B ∈ Mn are often encountered. Denote the block diagonal matrix
![]()
by the notation A ⊕ B. Then [133]
Note that the weak log majorization ![]() is stronger than the weak majorization
is stronger than the weak majorization ![]() .
.
A.6.1 Matrix Inequalities
Let ![]() be a linear mapping from finite-dimensional Hilbert spaces
be a linear mapping from finite-dimensional Hilbert spaces ![]() and
and ![]() . α is called positive if it sends positive (semidefinite) operators to positive (semidefinite) operators. Let
. α is called positive if it sends positive (semidefinite) operators to positive (semidefinite) operators. Let ![]() be a positive, unital linear mapping and
be a positive, unital linear mapping and ![]() be a convex function. Then, it follow [34, p. 189] that
be a convex function. Then, it follow [34, p. 189] that
A.4 ![]()
for every ![]() Here sa denotes the self-adjoint case.
Here sa denotes the self-adjoint case.
Let A and B be positive operators, then for 0 ≤ s ≤ 1,
![]()
The triangle inequality for the matrix ![]() is [114, p. 237]
is [114, p. 237]
where A and B are any square complex matrices of the same size, and U and V are unitary matrices. Taking the trace of (A.5) leads to the following
Replacing B in (A.6) with B + C leads to
![]()
Similarly, we have
A.7 ![]()
For positive operators A and B,
![]()
The n-tuples of the coefficients of real numbers may be regarded as diagonal matrices and the majorization can be extended to self-adjoint matrices. Suppose that A, B ∈ Mn are so. Then ![]() means that the n-tuple of eigenvalues of A is majorized by the n- tuple of eigenvalues of B; similarly for the weak majorization. Since the majorization depends only on the spectrums,
means that the n-tuple of eigenvalues of A is majorized by the n- tuple of eigenvalues of B; similarly for the weak majorization. Since the majorization depends only on the spectrums, ![]() holds if and only if
holds if and only if ![]() for some unitaries U and V. It follows from Birkhoff's theorem [34] that
for some unitaries U and V. It follows from Birkhoff's theorem [34] that ![]() implies that
implies that
![]()
for some pi > 0 with ∑ipi = 1 and for some unitaries.
A.6.2 Partial Ordering of Positive Semidefinite Matrices
Let A ≥ 0 and B ≥ 0 be of the same size. Then
If A ≥ B ≥ 0, then
Let A, B ∈ Mn be positive semidefinite. Then for any complex number and any unitarily invariant norm [133],
![]()
A.6.3 Partial Ordering of Hermitian Matrices
We follow [126, p. 273] for a short review. [115] has the most exhaustive collection. Positive definite and semi-definite matrices are important since covariance matrix and sample covariance matrix (used in practice) are semi-definite. A Hermitian matrix ![]() is called positive definite if
is called positive definite if
![]()
and positive semidefinite if the weaker condition xHAx ≥ 0 holds. A Hermitian matrix is positive definite if and only if all of its eigenvalues are positive, and positive semidefinite if and only if all of its eigenvalues are nonnegative. For ![]() , we write A > B when A − B is positive definite, and A ≤ B if B − A is positive definite. This is a partial ordering of the set of n × n Hermitian matrices. It is partial because we may have
, we write A > B when A − B is positive definite, and A ≤ B if B − A is positive definite. This is a partial ordering of the set of n × n Hermitian matrices. It is partial because we may have ![]() and
and ![]() .
.
Let A ≥ 0 and B ≥ 0 be of the same size and C is nonsingular. We have
The partitioned Hermitian matrix
![]()
with square blocks A and D, is positive definite if and only if A > 0 and its Schur complement D − BHA−1B > 0, or D > BHA−1B.
The Hadamard determinant inequality for a positive semidefinite ![]() is
is
![]()
The Minkowski determinant inequality for positive definite ![]() is
is
![]()
with equality if and only if B = cA for some constant c.
If f is convex then
![]()
and
A.8 ![]()