
Chapter 7
Machine Learning
Artificial intelligence [546–554] aims at making intelligent machines where an intelligent machine or agent is a system that perceives its environment and takes actions to maximize its own utility. The central problems in artificial intelligence include deduction, reasoning [555], problem solving, knowledge representation, learning, and so on.
In order to understand how the brain learns and how the computer or system achieves intelligent behavior, the interdisciplinary study of neuroscience, computer science, cognitive psychology, mathematics, and statistics gives a new research direction of artificial intelligence, called computational neuroscience research. Computational neuroscience tries to build artificial systems and mathematical models to explore the computational principles for perception, cognition, memory, and motion. More related information can be found in Computational Neuroscience Research at Carnegie Mellon University. Leonid Perlovsky, who won the John McLucas Award in 2007, the highest US Air Force Award for science, uses knowledge instinct and dynamic logic to express and model the brain mechanisms of perception and cognition [556]. Especially, dynamic logic is a mathematical description of the knowledge instinct which describes mathematically a fundamental mind mechanism of interactions between bottom-up signals and top-down signals as a process of adaptation from vague to crisp concepts [557]. Besides, bionics also motivates the study of artificial intelligence and extend its capability. Bionics tries to build artificial systems based on the biological methods and systems found in nature.
Machine learning [547, 558–563] is the main branch of artificial intelligence which deals with the design and development of algorithms that allow the machine or computer to evolve behaviors based on example data or past experience. Machine learning algorithms can be organized into different categories: unsupervised learning, semi-supervised learning, supervised learning, transductive inference, active learning, transfer learning, reinforcement learning, and so on.
There are two basic models for machine learning. One is generative model [564] and the other is discriminative model [565]. A generative model can generate observable data given some hidden parameters. Examples of generative models include Gaussian mixture model, hidden Markov model, naive Bayes, Bayesian networks, Markov random fields, and so on. Hence, a generative model is a full probabilistic model of all variables and models the underlying process of how the data is generated [566]. A discriminative model only provides the dependence of the target variables on the observed variables which can be done directly by posterior probabilities or conditional probabilities. Hence, discriminative model can focus computational resources on given task and give better performance. However, a discriminative model looks like a black box and lacks explanatory power of the generative model. Examples of discriminative models include logistic regression, linear discriminant analysis, support vector machine, boosting, conditional random fields, linear regression, neural networks, and so on.
Artificial intelligence as well as machine learning can be generally applied to many different areas, for example, cognitive radio, cognitive radar, smart grid, computational transportation, data mining, robotics, web search engine, human computer interaction, manufacturing, bioengineering, and so on.
- Cognitive Radio and Network. Cognitive radio is a brand new concept for the wireless communication system. The idea of cognitive radio was first presented by Joseph Mitola III in a seminar at KTH, The Royal Institute of Technology, in 1998, and published later in an article [567] by Mitola and Gerald Q. Maguire, Jr in 1999. Software radio provides an ideal platform for the realization of cognitive radio [567], and cognitive radio makes software radio smart. Later Simon Haykin gave a review of cognitive radio and treated it as brain-empowered wireless communications [568]. The goal is to improve the utilization of a precious natural resource: the radio electromagnetic spectrum [568].
- Cognitive Radar and Network. A lot of algorithms which were infeasible decades ago are now coming possible. Such examples are common in machine learning and artificial intelligence. These algorithms revolutionize areas like robotics [579]. Radar is experiencing a similar revolution in the general direction of cognitive radar [580].
- Smart Grid. Smart grid explores and exploits two-way communication technology, advanced sensing, metering and measurement technology, modern control theory, network grid technology, and machine learning in the power and electricity system to make the power and electricity network stable, secure, efficient, flexible, economical and environmentally friendly.
- Computational Transportation. Computational transportation [585, 586] or intelligent transportation [587–592] studies how to improve the safety, mobility, efficiency, and sustainability of transportation system by taking advantage of computer science, communication technology, information technology, sensing technology, computing technology, and control theory. Modeling, planning, and economic aspects of transportation are taken into account. The research topics and enabling solutions to transportation problems range from ride-sharing [593], routing, scheduling, and navigation, to autonomous/assisted driving, travel pattern analysis, and so on. More related information can be found in Computational Transportation Science at University of Illinois at Chicago.
- Data Mining. Data mining [561, 594–598] tries to discover new patterns and extract knowledge or intelligence from large scale data using methods at the intersection of artificial intelligence, statistics, and database system. Data mining can be widely used for science and engineering. Bioinformatics exploits data mining to generate new knowledge of biology and medicine, and discover new models of biological computation, for example, DNA computing, neural computing, evolutionary computing, and so on. Data mining is also useful for business applications. Take Internet advertising as an example, by data mining, more relevant advertisements can be sent to the right Internet audience at the right time.
- Computer Vision. Computer vision tries to obtain, process, analyze, and understand the real-world images or videos [599]. Information and intelligence can be extracted from the large scale data by computer vision. Machine learning is widely used in computer vision for detection, classification, recognition, tracking, and so on [600].
- Robotics. Robot is a virtual intelligent agent which can perform a variety of duties automatically or under guidance [601]. These duties can be part handling, assembly, painting, transport, surveillance, security, home help, and so on. The intelligence of robot is realized in software. Artificial intelligence gives robot the functions of perception, localization, modeling, reasoning, interaction, learning, planning, and so on. UAV can be treated as one kind of mobile robots.
- Web Search Engine. A web search engine [602] is mainly used to search for information on the website. Google, Yahoo, Bing, and so on are widely used web search engines. Machine learning is the powerful tool for web search engine. Commercial web search engines began to use machine learned ranking systems since the past decade. A ranking model is automatically constructed from training data by supervised learning or semisupervised learning. This ranking model for web search engine can reflect the importance of a particular web page.
- Human Computer Interaction. Human computer interaction [603] tries to design the interaction between people and computers. The researches about human computer interaction include cognitive models, speech recognition, natural language understanding, gesture recognition, data visualization, and so on. iPhone 4S can be treated as one kind of human computer interaction devices. iPhone 4s includes a new automated voice control system called Siri. Siri can allow the user to give the iPhone commands.
- Social Network. Social network is a network of social structure, social interdependency, or social relationships of human beings. Friendship, common interest, common belief, financial exchange, and so on are considered in the social network. Data related to social network have exploded recently due to the fast development of information technology. Thus, machine learning is a powerful tool to analyze social network for learning and inference [604–607].
- Manufacturing. Machine learning can be used in manufacturing to perform automatic and intelligent operations. In this way, the efficiency of manufacturing can be improved, especially for the dark factory with no involvement of human labor. The novel developments in machine learning and substantial applications of machine learning in modern industrial engineering and mass production have been presented in [608]. The analysis of data from simulations and experiments in the development phase and measurements during mass production plays a crucial role in modern manufacturing [608]. For example, various machine learning algorithms are applied to detection and recognition of spatial defect patterns in semiconductor fabrication processes [609–612]. These spatial defect patterns generated during integrated circuit (IC) manufacturing processes contain information about potential problems in the processes [612].
- Bioengineering. Bioengineering [613] tries to exploit both concepts of biology and engineering's analytical methodologies to deal with problems in life science. With the developments of mathematics and computer science, machine learning can be used in bioinformatics, medical innovations, biomedical image analysis, and so on.
7.1 Unsupervised Learning
Unsupervised learning [614–616] tries to find hidden or underlying structure from the unlabeled data. The key feature of unsupervised learning is that the data or examples given to the learner are unlabeled.
Clustering and blind signal separation are two categories of unsupervised learning algorithms [616]. Clustering assigns a set of objects into different groups or clusters such that the objects in the same group are similar [617]. The clustering algorithms include:
- k-means or centroid-based clustering [618–621];
- k-nearest neighbors [622, 623];
- hierarchical clustering or connectivity-based clustering;
- distribution-based clustering;
- density-based clustering.
Blind signal separation or blind source separation tries to separate a set of signals from a set of mixed signals without the information about the source signals or the mixing process [624]. The approaches for blind signal separation include:
- principal component analysis [625, 626];
- singular value decomposition [627];
- independent component analysis (ICA) [628–630];
- nonnegative matrix factorization [631–633].
Robust signal classification using unsupervised learning has been discussed in [634]. k-means clustering and the self-organizing map (SOM) are used as unsupervised classifiers. Meanwhile, the countermeasures to the class manipulation attacks are developed [634].
7.1.1 Centroid-Based Clustering
In centroid-based clustering [635], the whole data set is partitioned into different clusters. Each cluster is represented by a central vector. This central vector is not necessarily a member of the data set. Meanwhile, each member in the cluster has the smallest distance from the corresponding mean. If the number of the clusters is k, k-means clustering gives a corresponding optimization problem for centroid-based clustering.
Given a set of data X = {x1, x2, …, xn}, k-means clustering attempts to partition the data set X into k(k ≤ n) sets S1, S2, …, Sk such that the sum of squared distances within the cluster is minimized [618–621]

where yi is the mean of the cluster related to data set Si.
7.1.2 k-Nearest Neighbors
The k-nearest neighbor (k-NN) algorithm assigns a class to an object by a majority vote of its k-nearest neighbors. Genetic programming with k-NN has been used in [636] to perform automatic digital modulation classification.
7.1.3 Principal Component Analysis
PCA is also called Karhunen-Loeve transform, Hotelling transform, or proper orthogonal decomposition [637]. PCA uses an orthogonal transformation to transform a set of correlated variables into a set of uncorrelated variables [637]. These uncorrelated variables are linear combinations of the original variables. They are called principal components. The number of principal components is less than or equal to the number of original variables. Thus, PCA is a widely used linear transformation for dimensionality reduction.
The goal of PCA is to ensure that the first principal component bears the largest variance and the second principal component has the second largest variance. Meanwhile, the directions of different principal components are orthogonal. Generally, PCA can be executed by eigenvalue decomposition of covariance matrix.
Given a set of high-dimensional real data x1, x2, …, xM where xm ∈ RN, PCA can be performed as:
7.2 ![]()
7.3 ![]()
In sum, PCA projects the data from the original directions or bases to the new directions or bases. Meanwhile, the data varies the most along the new directions. These directions can be determined by the eigenvectors of the covariance matrix corresponding to the largest eigenvalues. The eigenvalues relate to the variances of the data along the new directions. PCA gives a way to construct the linear subspace spanned by the new bases from the data.
![]() is extended to
is extended to ![]() . If Y contains as many zeros as possible, this problem is called sparse component analysis [638].
. If Y contains as many zeros as possible, this problem is called sparse component analysis [638].
PCA can also be extended to its robust version. The background of robust PCA [639, 640] is to decompose a given large data matrix M as a low rank matrix L plus a sparse matrix S, that is,
Specifically speaking, PCA finds a rank-![]() approximation of the given data matrix M in an l2 sense by solving the following optimization problem,
approximation of the given data matrix M in an l2 sense by solving the following optimization problem,
7.5 
This problem can be easily solved by SVD. An intrinsic drawback of PCA is that it can work efficiently only when the low rank matrix is corrupted with small and i.i.d. Gaussian noise. That is PCA is suitable for the model of M = L + N where N is the i.i.d. Gaussian noise matrix. PCA will fail when some of the entries in L are strongly corrupted as shown in Equation (7.4) in which the matrix S is a sparse matrix with arbitrarily large magnitude.
In order to find L and S from M, robust PCA tries to solve the following optimization problem,
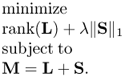
From the convex optimization point of view, the rank function is a nonconvex function. Solving the optimization problem with a rank objective or rank constraint is NP-hard. However, it is known that the convex envelope of rank(L) on the set {L:||L|| ≤ 1} is the nuclear norm ||L||* [641]. Hence, the rank minimization can be relaxed to a nuclear norm minimization problem which is a convex objective function. In this regard, there are a series of papers that have studied the conditions required for successfully applying the nuclear norm heuristic to rank minimization from different perspectives [641–643]. Hence, the optimization problem (7.6) can be relaxed to
7.7 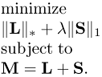
In this way, L and S can be recovered.
Robust PCA is widely used in video surveillance, image processing, face recognition, latent semantic indexing, ranking, and collaborative filtering [639].
7.1.4 Independent Component Analysis
ICA tries to separate a mixed multivariate signal and identify the underlying non-Gaussian source signals or components that are statistically independent or as independent as possible [562, 629, 644]. Even though the source signals are independent, the observed signals are not independent due to the mixture operation. Meanwhile, the observed signals look like normal distributions [562]. A simple application of ICA is the “cocktail party problem.” Assume in the cocktail party, there are two speakers denoted by s1(t) and s2(t) and there are two microphones recording time signals denoted by x1(t) and x2(t). Thus,
7.8 ![]()
where a11, a12, a21, and a22 are some unknown parameters that depend on the distances between the microphones and the speakers [629]. We would like to estimate two source signals s1(t) and s2(t) using only the recorded signals x1(t) and x2(t).
Using the matrix notation, the linear noiseless ICA can be written as
7.9 ![]()
where the rows of S should be statistically independent. Due to the unknown A and S, the variances and the order of the independent components cannot be determined [629]. In order to solve ICA problems, minimization of mutual information and maximization of non-Gaussianity are often used to achieve the independence of the latent sources.
The applications of ICA include separation of artifacts in magnetoencephalography (MEG) data, finding hidden factors in financial data, reducing noise in natural images, blind source separation for telecommunication [629]. ICA can also be used for chemical and biological sensing to extract the intrinsic surface-enhanced Raman scattering spectrum [645].
7.1.5 Nonnegative Matrix Factorization
Matrix decomposition has long been studied. A matrix decomposition is a factorization of a matrix into some canonical form. There are many different matrix decompositions, for example, LU factorization, LDU decomposition, Cholesky decomposition, rank factorization, QR decomposition, rank-revealing QR factorization, SVD, eigen-decomposition, Jordan decomposition, Schur decomposition, and so on.
Nonnegative matrix factorization [633, 646] is one kind of matrix decomposition with the nonnegative constraint on the factors. Mathematically speaking, a matrix X is factorized into two matrices or factors W and H such that
7.10 ![]()
and all entries in W and H must be equal to or greater than zero where E represents approximation error.
There are many useful variants based on nonnegative matrix factorization [633]:
- Symmetric nonnegative matrix factorization,
7.11 ![]()
- Semi-orthogonal nonnegative matrix factorization,
7.12 ![]()
- Three-factor nonnegative matrix factorization,
7.13 ![]()
- Affine nonnegative matrix factorization,
7.14 ![]()
- Multilayer nonnegative matrix factorization,
7.15 ![]()
- Simultaneous nonnegative matrix factorization,
7.16 ![]()
- Nonnegative matrix factorization with sparseness constraints on the each column of W and H [647].
Two-dimensional nonnegative matrix factorization can be extended to n-dimensional nonnegative tensor factorization [633, 648, 649]. Various algorithms for nonnegative matrix and tensor factorization are mentioned in [633]. In [650], Bregman divergences are used for generalized nonnegative matrix approximation.
Similar to robust PCA, the robust version of nonnegative matrix factorization is expressed as
7.17 ![]()
where S is the sparse matrix. The optimization problem for robust nonnegative matrix factorization can be represented as
such that W and H are both the nonnegative matrices. The optimization problem (7.18) is not convex in W, H, and S jointly. Thus, we need to solve them separately [651]:
This procedure will be repeated until the algorithm converges.
Nonnegative matrix factorization is a special case of general matrix factorization. Probabilistic algorithms for constructing approximate matrix factorization have been comprehensively discussed in [652]. The core idea is to find structure with randomness [652]. Compared with standard deterministic algorithms for matrix factorization, the randomized methods are often faster and more robust [652].
7.1.6 Self-Organizing Map
An SOM is one kind of ANN within the category of unsupervised learning. SOM attempts to create spatially organized low-dimensional or internal representation (usually two-dimensional grid) of input signals and their abstractions which is called map [653–655]. SOM is different from other ANNs because a neighborhood function is used to preserve the topology of the input space. Thus, the nearby locations in the map represent the inputs with similar properties.
The training algorithms of SOM are based on the principle of competitive learning [653, 656] which is also used for the well-known vector quantization [657–659].
7.2 Supervised Learning
Supervised learning learns a function from supervised labeled training data [660]. In supervised learning, the training data consist of a set of training examples. Each training example includes an input object together with a desired output value. If the output value is discrete, the learned function is called a classifier. If the output value is continuous, the learned function is called a regression function. Algorithms for supervised learning generalize from the training data to the unseen data. The popular algorithms for supervised learning are:
- linear regression [661–664];
- logistic regression [665, 666];
- artificial neural network [667, 668];
- decision tree learning [669];
- random forests [670];
- naive Bayes classifier [671];
- support vector machines [672–674].
7.2.1 Linear Regression
Linear regression tries to model the relationship between a scalar dependent variable y and one or more explanatory (independent) variables x. Mathematically speaking,
where
7.20 ![]()
a is called the parameter vector or regression coefficients
7.21 ![]()
and ε is the noise or error.
If there are N dependent variables, Equation (7.19) can be extended to
7.22 ![]()
where
7.23 ![]()
7.24 ![]()
7.25 ![]()
7.2.2 Logistic Regression
Logistic regression [675] is a nonlinear regression which can predict the probability of an event occurrence using a logistic function. A simple logistic function is defined as
7.26 ![]()
which always takes on values between zero and one. Thus, logistic regression can be expressed as
7.27 ![]()
where a0 is called intercept and a1, a2, …, aP are called regression coefficients of x1, x2, …, xP.
Logistic regression is a popular way to model and analyze binary phenomena, which means the dependent variable or the response variable is a two-valued variable [676].
7.2.3 Artificial Neural Network
The idea of artificial neural network [677] is borrowed from biological neural network to mimic the real life behavior of neurons. Artificial neural network is an adaptive system used to model relationship between inputs and outputs. The mathematical expression of the simplest artificial neural network is
7.28 
where x1, x2, …, xN are inputs; w1, w2, …, wN are the corresponding weights; o is output; and f is an activation (transfer) function.
Perceptron, one type of artificial neural network, is a binary classifier which maps its inputs to an output with binary values. Given threshold θ, if ![]() , then o = 1; otherwise o = 0. This single-layer perceptron has no hidden layer. The single-layer perceptron can be extended to the multilayer perceptron which consists of multiple layers of nodes in a directed graph. The multilayer perceptron can use backpropagation algorithm to learn the network.
, then o = 1; otherwise o = 0. This single-layer perceptron has no hidden layer. The single-layer perceptron can be extended to the multilayer perceptron which consists of multiple layers of nodes in a directed graph. The multilayer perceptron can use backpropagation algorithm to learn the network.
7.2.4 Decision Tree Learning
A decision tree [678] is a tree-like graph or model for decision, prediction, classification, and so on. In a decision tree, each internal node tests an attribute. Each branch corresponds to one possible value of attribute. Each leaf node assigns a classification for the observation. Decision tree learning tries to learn a function which can be represented as a decision tree [679]. A number of decision trees can be used together to form a random forest classifier which is an ensemble classifier [680]. In random forest, each tree is grown at least partially at random. Bootstrap aggregation is used for parallel combination of learners which is independently trained on distinct bootstrap samples. Final result is the mean prediction or class with maximum votes. Random forest can increase accuracy by reducing prediction variance.
7.2.5 Naive Bayes Classifier
A naive Bayes classifier [681] is a probabilistic classifier based on Bayes' theorem with independence assumptions.
Based on Bayes' theorem, the naive Bayes probabilistic model can be expressed as,
7.29 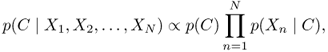
where C is a dependent class variable and X1, X2, …, XN are the feature variables. p(C | X1, X2, …, XN) is the posterior probability. p(C) is the prior probability. p(Xn | C) is the likelihood probability.
According to the maximum a posteriori (MAP) decision rule, A naive Bayes classifier can be written as [671]
7.30 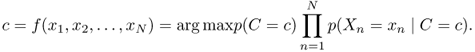
7.2.6 Support Vector Machines
SVM [682] is a set of the supervised learning algorithms used for classification and regression. SVM includes linear SVM, kernel SVM [683, 684], multiclass SVM [685–692], support vector regression [693–697]. Design of learning engine based on SVM in cognitive radio has been mentioned in [698]. Both classification and regression results of SVM for eight kinds of modulation modes are demonstrated. The experimental data come from 802.11a protocol platform. SVM is used for MAC protocol classification in a cognitive radio network [699]. The received power mean and variance are chosen as two features for SVM. Two MAC protocols, time division multiple access and slotted Aloha, are classified.
Let's study SVM from the linear two-class SVM [674]. Given the training data set having M pairs of inputs and outputs,
7.31 ![]()
and
7.32 ![]()
SVM attempts to find the separating hyperplane
7.33 ![]()
with the largest margin satisfying the following constraints:
in which w is the normal vector of the hyperplane and · stands for inner product. The constraint (7.34) can be combined into:
7.35 ![]()
The distance between two hyperplanes w · xi − b = 1 and w · xi − b = − 1 is ![]() . In order to obtain the largest margin, the following optimization is used [674]
. In order to obtain the largest margin, the following optimization is used [674]

The dual form of the optimization problem (7.36) by introducing Lagrange multipliers αi ≥ 0, i = 1, 2, …, M is [674]
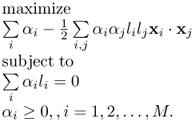
The solution to w can be expressed in terms of a linear combination of the training vectors as
7.38 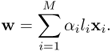
Those xi, i = 1, 2, …, MSV with αi > 0 are called support vectors which lie on the margin and satisfy li(w · xi − b) = 1. Thus, b can be obtained as
7.39 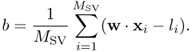
Thus, a classifier based on SVM can be written as [674]
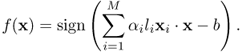
When the number of classes for outputs is more than two, multiclass SVM can be used to perform multiclass classification. The common approach for multiclass SVM is to decompose the single multiclass classification problem into multiple two-class classification problems. Each two-class classification problem can be addressed by the well known two-class SVM. Within this framework, one-against-all and one-against-one are widely used [692]. Besides, a pairwise coupling strategy can be exploited to combine the probabilistic outcomes of all the one-against-one two-class classifiers to obtain the estimates of the posterior probabilities for the test input [692, 700].
Based on the idea of SVM, the multiclass classification problem can also be handled by solving one single optimization problem [685, 688, 701].
The linear two-class SVM can be modified to tolerate some misclassification inputs, which is called soft margin SVM [674]. Soft margin SVM can be done by introducing a nonnegative slack variable ξi, i = 1, 2, …, M which measures the degree of misclassification for the input xi. Hence, the constraint (7.34) should be modified as
7.41 ![]()
which can be combined into
7.42 ![]()
and ξi ≥ 0, i = 1, 2, …, M.
The optimization problem for soft margin SVM is expressed as [674]

where C is a trade-off parameter to compromise the slack variable penalty and the size of margin. The dual form of the optimization problem (7.43) is [674]
7.44 
If the value of output li is continuous, the learned function is called a regression function. SVM can be extended to supoort vector regression. Analogously to the soft margin SVM, the optimization problem for support vector regression can be written as [697]

where ε is a parameter to determine the region bounded by li ± ε, i = 1, 2, …, M which is call li ± ε -insensitive tube. The dual form of the optimization problem (7.45) is [697]
7.46 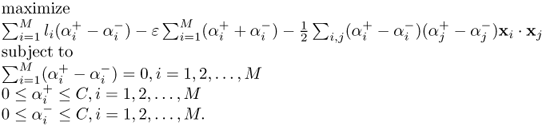
Thus,
7.47 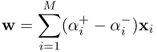
and
7.48 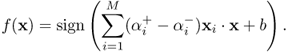
7.3 Semisupervised Learning
Supervised learning exploits the labeled data for training to learn the function. However, the labeled data, sometimes, are hard or expensive to obtain and generate. While the unlabeled data are more plentiful than the labeled data [702]. In order to make use of both labeled data and unlabeled data for training, semisupervised [703] learning can be explored. Semisupervised learning falls between unsupervised learning and supervised learning. The underlying phenomenon behind semisupervised learning is that a large amount of unlabeled data used together with a small amount of labeled data for training can improve machine learning accuracy [704, 705].
7.3.1 Constrained Clustering
Constrained clustering [706–708] can be treated as clustering with side information or additional constraints. These constraints include pairwise must-link constraints and cannot-link constraints. The must-link constraints mean two members or data points must be in the same cluster while the cannot-link constraints mean two data points cannot be in the same cluster. Take the k-means clustering as an example. The penalty cost function related to the must-link constraints and the cannot-link constraints can be added to the optimization problem (7.1) to form the optimization problem for the constrained k-means clustering. Besides, if the partial label information is given, a small amount of labeled data can aid the clustering of unlabeled data [709]. In [709], the seed clustering is used to initialize the k-means algorithm.
7.3.2 Co-Training
Co-training is also a semisupervised learning technique [702, 710]. In co-training, the features of each input are divided into two different feature sets. These two feature sets should be conditionally independent given the class of the input. Meanwhile, the class of the input can be accurately predicted from each feature set alone. In other words, each feature set contains sufficient information to determine the class of the input [702]. Co-training first learns two different classifiers based on two different feature sets using the labeled training data. Then, each classifier will label several unlabeled data with more confidence. These data will be used to construct the additional labeled training data. This procedure will be repeated until convergence.
7.3.3 Graph-Based Methods
Recently, graph-based methods for semisupervised learning have become popular [711]. Graph-based methods for semisupervised learning are nonparametric, discriminative, and transductive in nature [711]. The first step of graph-based methods is to create the graph based on both labeled data and unlabeled data. The data correspond to the nodes on the graph. The edge together with the weight between two nodes is determined by the inputs of the corresponding data. The weight of the edge reflects the similarity of two data inputs. The second step of graph-based methods is to estimate a smooth function on the graph. This function can predict the classes for all the nodes on the graph. Meanwhile, the predicted classes of the labeled nodes should be close to the given classes. Thus, how to estimate this function can be expressed as the optimization problem with two terms [711]. The first term is a loss function and the second term is a regularizer [711].
7.4 Transductive Inference
Transductive inference [712–714] is similar to semisupervised learning. Transductive inference tries to predict outputs for the test inputs based on the training data and test inputs. Transduction is different from the well-known induction. In induction, general rules are first obtained from the observed cases; then these general rules are applied to the test cases. Thus, the performances transductive inference are inconsistent on different test cases.
7.5 Transfer Learning
Transfer learning or inductive transfer [715, 716] focuses on gaining knowledge from solving one problem or previous experience and applying it to a different but related problem. Markov logic networks [717] and Bayesian networks [718] have already been exploited for transfer learning.
Multitask learning or learning to learn is one kind of transfer learning [719]. Multitask learning tries to learn a problem together with other related problems simultaneously, with consideration of the commonality among the problems.
7.6 Active Learning
Active learning is also called optimal experimental design [720, 721]. Active learning is a form of supervised learning in which the learner can interactively ask for information. Specifically speaking, the learner actively queries the user, teacher, or expert to label the unlabeled data. And then, supervised learning is exploited. Since the learner can select the training examples, the number of examples to learn a function can often be smaller than the number needed in common supervised learning. However, there is a risk for active learning. Unimportant or even invalid examples may be chosed. The basic experimental design types for active learning include A-optimal design which minimizes the trace of the matrix, D-optimal design which minimizes the log-determinant of the matrix, and E-optimal design which minimizes the maximum eigenvalue of the matrix. All these design problems can be solved by convex optimization. Active learning based on locally linear reconstruction is presented in [722] where local structure of the data space is taken into account.
7.7 Reinforcement Learning
Reinforcement learning [723–725] is a very useful and fruitful area of machine learning. Reinforcement learning tries to learn how to act in response to an observation of the world in order to maximize some kind of cumulative reward. Every action taken has some influence on the environment. The environment will give its feedback through rewards to the learner. This feedback can guide the learner to make the decision for the next action. Reinforcement learning is widely studied in control theory, operation research, information theory, economics, and so on. Many algorithms for reinforcement learning are highly related to dynamic programming [726, 727]. Reinforcement learning is a dynamic and life-long learning with focus on the online performance. Thus, there is a trade-off between exploration and exploitation in reinforcement learning [728, 729]. The basic components in reinforcement learning should include environment states, possible actions, possible observations, transitions between states, and rewards.
Reinforcement learning is widely used in cognitive radio network for exploration and exploitation [730–746]. Three learning strategies will be presented in detail:
- Q-learning;
- Markov decision process;
- partially observable Markov decision process.
7.7.1 Q-Learning
Q-learning is a simple but useful reinforcement learning technique [747, 748]. Q-learning learns a utility function of a given action in a given state. Q-learning follows a fixed state transition and does not require the environment information.
Given the current state st and the action at, the utility function Q(st, at) is learned or updated as
where αt(st, at) ∈ (0, 1] is the learning rate; r(st, at) is the immediate reward; γ ∈ [0, 1) is the discount factor; st+1 is the next state due to the state transition from the current state st by the action at. If αt is equal to 1 for all the states and all the actions, Equation (7.49) can be reduced to
7.50 ![]()
Finally, the utility function can be learned through iteration. For each state, the selected action should be
7.51 ![]()
Q-learning and its variants are widely used in cognitive radio network [734, 749–762].
7.7.2 Markov Decision Process
MDP [763] is a mathematical framework for studying the decision-making problem. MDP can be treated as an extension of Markov chain. Mathematically speaking, a Markov chain is a sequence of random variables X1, X2, X3, …, Xt, … with the Markov property, that is, the memoryless property of a stochastic process,
7.52 ![]()
which means the following states and the previous states are independent given the current state.
An MDP consists of [723]:
- a set of states S;
- a set of actions A;
- a reward function R(s, a);
- a state transition function T(s, a, s′) = Pr(st+1 = s′ | st = s, at = a).
The goal of MDP is to find a policy a = π(s) for the decision maker. When the police is fixed, MDP behaves like a Markov chain. Typically, the optimization problem of MDP can be formulated as
7.53 ![]()
There are three basic methods to solve MDP:
- value Iteration;
- policy Iteration;
- linear programming [764–767].
For value iteration and policy iteration, the optimal value function is defined as [723],
7.54 
and given the optimal value function, the optimal policy can be obtained as [723],
7.55 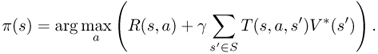
Value iteration tries to find the optimal value function and then obtain the optimal policy. The core part of value iteration is [723]:
7.56 ![]()
7.57 ![]()
Policy iteration updates the policy directly. The core part of policy iteration is [723]:
7.58 ![]()
7.59 
MDP and its variants can be exploited in cognitive radio network [736, 737, 740, 768–775, 775–782].
7.7.3 Partially Observable MDPs
POMDP is an extension of MDP. The system dynamics are modeled by MDP. However, the underlying state cannot be fully observed. POMDP models the interaction procedure of an agent with the outside world [783]. An agent first observes the outside world, then it tries to estimate the belief state using the current observation. The solution of POMDP is the optimal policy for choosing actions.
An POMDP consists of
- a set of states S;
- a set of actions A;
- a set of observations O;
- a reward function R(s, a);
- a state transition function T(s, a, s′) = Pr(st+1 = s′ | st = s, at = a);
- an observation function Ω(o, s′, a) = Pr(ot+1 = o | st+1 = s′, at = a).
Define a belief state over the states as
7.60 
where ![]() and ∑s∈Sb(s) = 1. There are uncountably infinite number of belief states.
and ∑s∈Sb(s) = 1. There are uncountably infinite number of belief states.
Given bt and at, if o ∈ O is observed with probability Ω(o, s′, a), bt+1 can be obtained as [784]
where
7.62 ![]()
Define the belief state transition function as [784]
and τ(b, a, b′) = Pr(o | a, b) if b′, b, a, and o follows Equation (7.61); otherwise τ(b, a, b′) is equal to zero. Thus, POMDP can be treated as infinite state MDP with [784, 785]
- a set of belief states B;
- a set of actions A;
- a belief state transition function shown in Equation (7.63);
- a reward function ρ(b, a) = ∑s∈Sb(s)R(s, a).
Solving a POMDP is not easy. The first detailed algorithms for finding exact solutions of POMDP were introduced in [786]. There exist some software tools for solving POMDP, such as pomdp-solve [787], MADP [788], ZMDP [789], APPL [790], and Perseus [791]. Among them, APPL is the fastest one in most cases [790].
POMDP and its variants are widely used in cognitive radio network [792–818].
7.8 Kernel-Based Learning
Kernel-based learning [819] is the great extension of machine learning by different kernel functions. Kernel SVM [683, 684], kernel PCA [820–823], and kernel Fisher discriminant analysis [824, 825] are widely used. Kernel functions can implicitly map the data from original low-dimensional linear space x to high-dimensional feature nonlinear space Φ(x).
Kernel function K(x, y) is defined as the inner product of Φ(x) and Φ(y). If we know the analytic expression of kernel function and we only care about the inner product of Φ(x) and Φ(y), then we do not need to know the mapping nonlinear function Φ explicitly. This is called the kernel trick. The commonly used kernel functions are:
- Gaussian kernels:
 ;
; - homogeneous polynomial kernels: K(x, y) = (x · y)d;
- inhomogeneous polynomial kernels: K(x, y) = (x · y + 1)d;
- sigmoid kernels:
 .
.
Gaussian kernels, polynomial kernels, and sigmoid kernels are all data independent. Given kernel functions and training data, we can get kernel matrix. However, kernel matrix can also be learned and optimized from data [388, 826–828]. In [829], Bregman matrix divergences are used to learn the low-rank kernel matrix.
The brilliance of the optimization problem (7.37) and Equation (7.40) is that the inner product between inputs is used. By applying the kernel trick, linear two-class SVM can be easily extended to the nonlinear kernel SVM. In the feature space [683, 684],
7.64 
and
7.65 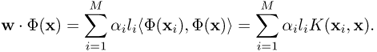
Thus, a classifier based on kernel SVM can be written as
7.66 
Besides, kernel principal angles are explored for machine learning related tasks [830, 831]. The principal angles, also called canonical angles, give information about the relative position of two subspaces of a Euclidean space [832–835].
7.9 Dimensionality Reduction
In large scale cognitive radio networks, there is a significant amount of data. However, in practice, the data is highly correlated. This redundancy in the data increases the overhead of cognitive radio networks for data transmission and data processing. In addition, the number of degrees of freedom (DoF) in large scale cognitive radio networks is limited. The DoF of a K user M × N MIMO interference channel has been discussed in [836]. The total number of DoF is equal to min(M, N) * K if K ≤ R, and ![]() if K > R, where
if K > R, where ![]() . This is achieved based on interference alignment [541, 837, 838]. Theoretical analysis about DoF in cognitive radio has been presented in [839, 840]. The DoF corresponds to the key variables or key features in the network. Processing the high-dimensional data instead of the key variables will not enhance the performance of the network. In some cases, this could even degrade the performance. Hence, compact representations of the data using dimensionality reduction is critical in cognitive radio networks.
. This is achieved based on interference alignment [541, 837, 838]. Theoretical analysis about DoF in cognitive radio has been presented in [839, 840]. The DoF corresponds to the key variables or key features in the network. Processing the high-dimensional data instead of the key variables will not enhance the performance of the network. In some cases, this could even degrade the performance. Hence, compact representations of the data using dimensionality reduction is critical in cognitive radio networks.
Due to the curse of dimensionality and the inherent correlation of data, dimensionality reduction [841] is very important for machine learning. Meanwhile, machine learning provides the powerful tools for dimensionality reduction. Dimensionality reduction tries to reduce the number of random variables or equivalently the dimension of the data under consideration. Dimensionality reduction can be divided into feature selection and feature extraction [842]. Feature selection tries to find a subset of the original variables or features. Feature extraction transforms the data from the high-dimensional space to low-dimensional space. PCA is a widely used linear transformation for feature extraction. However, there are also many powerful nonlinear dimensionality reduction techniques.
Many nonlinear dimensionality reduction methods are related to manifold learning algorithms [843–846]. The data set most likely lies along a low-dimensional manifold embedded in a high-dimensional space [847]. Manifold learning attempts to uncover the underlying manifold structure in a data set. These methods include:
- kernel principal component analysis [820–823];
- multidimensional scaling [848–850];
- isomap [843, 851–853];
- locally-linear embedding [854–856];
- Laplacian eigenmaps [857, 858];
- diffusion maps [859, 860];
- maximum variance unfolding or semidefinite embedding [861–864].
7.9.1 Kernel Principal Component Analysis
Kernel PCA is a kernel-based machine learning algorithm. It uses the kernel function to implicitly map the original data to a feature space, where PCA can be applied. Assuming the original dimensionality data are a set of M samples xi ∈ RN, i = 1, 2, …, M, the reduced dimensionality samples of xi are yi ∈ RK, i = 1, 2, …, M, where K ![]() N. xij and yij are componentwise elements in xi and yi, respectively.
N. xij and yij are componentwise elements in xi and yi, respectively.
Kernel PCA uses the kernel function
to implicitly map the original data into a feature space F, where φ is the mapping from original space to feature space and · represents inner product. In F, PCA algorithm can work well.
A function is a valid kernel if there exists a mapping φ satisfying Equation (7.67). Mercer's condition [683] gives us the condition about what kind of functions are valid kernels.
If K(·, ·) is a valid kernel function, the matrix
7.68 
must be positive semidefinite [865]. The matrix K is the so-called kernel matrix.
Assuming the mean of feature space data φ(xi), i = 1, 2, …, M is zero, that is,
7.69 
The covariance matrix in F is
7.70 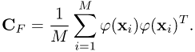
In order to apply PCA in F, the eigenvectors ![]() of CF are needed. As we know that the mapping φ is not explicitly known, thus the eigenvectors of CF can not be as easily derived as PCA. However, the eigenvectors
of CF are needed. As we know that the mapping φ is not explicitly known, thus the eigenvectors of CF can not be as easily derived as PCA. However, the eigenvectors ![]() of CF must lie in the span [86] of φ(xj), j = 1, 2, …, M, that is,
of CF must lie in the span [86] of φ(xj), j = 1, 2, …, M, that is,
7.71 
It has been proved that ![]() are eigenvectors of kernel matrix K [86]. In which αij are component-wise elements of
are eigenvectors of kernel matrix K [86]. In which αij are component-wise elements of ![]() .
.
Then the procedure of kernel PCA can be summarized in the following six steps:
7.72 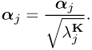
7.73 
So far the mean of φ(xi), i = 1, 2, …, M has been assumed to be zero. In fact, the zero mean data in the feature space are
7.74 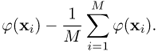
The kernel matrix for this centering or zero mean data can be derived by [86]
7.75 ![]()
in which ![]() is the so-called centering matrix, I is an identity matrix, 1 is all-one vector.
is the so-called centering matrix, I is an identity matrix, 1 is all-one vector.
Kernel PCA can be used for noise reduction which is a nontrivial task. S. Mika and co-workers have proposed an iterative scheme on noise reduction for Gaussian kernels [821]. This method needs to rely on the nonlinear optimization. However, a distance-constraint based method has been proposed by J. Kwok and I. Tsang which just relies on linear algebra [823]. In order to apply kernel PCA for noise reduction, the pre-image ![]() (in original space) of yi (in feature space) is needed. The distance-constraint based method for noise reduction makes use of the distance relationship [866] found by Williams between original space and feature space for some specific kernels. It tries to find the distance between
(in original space) of yi (in feature space) is needed. The distance-constraint based method for noise reduction makes use of the distance relationship [866] found by Williams between original space and feature space for some specific kernels. It tries to find the distance between ![]() and xj once the distance between yi and φ(xj) is known. d(xi, xj) is used to represent distance between two vectors xi and xj.
and xj once the distance between yi and φ(xj) is known. d(xi, xj) is used to represent distance between two vectors xi and xj.
It has been proved that the squared distance between yi and φ(xj) can be derived by [823]
7.76 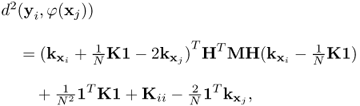
where ![]() and
and ![]() in which
in which ![]() and
and ![]() are the k-th largest eigenvalues and corresponding column eigenvectors of
are the k-th largest eigenvalues and corresponding column eigenvectors of ![]() .
.
By making use of the distance relationship [866] between original space and feature space, if the kernel is the radial basis kernel, then
7.77 ![]()
Once the above distances are derived, ![]() can be reconstructed [823].
can be reconstructed [823].
7.9.2 Multidimensional Scaling
Multidimensional scaling (MDS) is a set of data analysis techniques used to explore the structure of similarities or dissimilarities in data [867]. The high-dimensional data can be displayed in 2-D or 3-D visualization.
Given a set of the high-dimensional data {x1, x2, …, xM}, the distance between xi and xj is δij. Arbitrary distance function can be used to define the similarity between xi and xj. Take Euclidean distance as an example, the goal of MDS is to find a set of the low-dimensional data {y1, y2, …, yM} such that
7.78 ![]()
for all i = 1, 2, …, M and j = 1, 2, …, M. The low dimensional embedding can preserve pairwise distances. Thus, MDS can be expressed as an optimization problem [848–850]
7.79 ![]()
where the sum of the squared differences between ideal distances in the original space and actual distances in the low-dimensional space is used as the cost function. Stress majorization can be used as a solver. It is well known that classical MDS is equivalent to PCA when Euclidean distance is used for some particularly selected cost functions [843] which simplifies the algorithm for MDS.
Local MDS is a technique for the nonlinear dimensionality reduction [850, 868]. MDS is executed locally instead of globally. Mathematically speaking, the optimization problem of local MDS can be expressed as
where Ω is a symmetric set of nearby pairs (i, j) which describes the local fabric of a high-dimensional manifold [868]; δ∞ is a very large value of dissimilarity and w is a small weight. If δ∞ goes to infinity and ![]() , the optimization problem (7.80) can be reduced to [868]
, the optimization problem (7.80) can be reduced to [868]
7.81 ![]()
where the first term forces ||yi − yj|| to approach δij locally and the second term pushes nonlocal data far away from each other [868].
7.9.3 Isomap
Isomap is classical MDS where small pairwise distances between neighboring data are preserved while large pairwise distances between faraway data are replaced by geodesic distances which can be estimated by computing the shortest path distances along the neighborhood graph [843, 868, 869]. There are three steps to perform Isomap [843]. The first step is to construct neighborhood graph. The neighborhood graph can be determined by ![]() -neighborhoods or k-nearest neighbors. The second step is to compute shortest paths to estimate geodesic distances. Floyd-Warshall algorithm can be applied. The third step is to apply classical MDS to the matrix of graph distances and obtain the low-dimensional embedding.
-neighborhoods or k-nearest neighbors. The second step is to compute shortest paths to estimate geodesic distances. Floyd-Warshall algorithm can be applied. The third step is to apply classical MDS to the matrix of graph distances and obtain the low-dimensional embedding.
7.9.4 Locally-Linear Embedding
Locally linear embedding (LLE) tries to discover low-dimensional, neighborhood preserving embedding of the high-dimensional data by using a locally linear approximation of the data manifold. Hence, data can be represented as the linear combinations of their neighbors. The first step for LLE is to calculate the weight matrix W based on the following optimization problem [854],
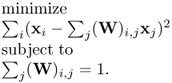
where xi can only be reconstructed from its neighbors [854]. Hence, (W)i, j will be equal to zero if xi and xj are not neighbors.
The second step of LLE is to perform dimensionality reduction by solving the optimization problem shown below [854]:
7.83 ![]()
where W is the solution to the optimization problem (7.82). Meanwhile, the local affine structure is preserved.
7.9.5 Laplacian Eigenmaps
Laplacian eigenmaps use the notion of the Laplacian of the graph to compute a low-dimensional representation of the high-dimensional data that can optimally preserve local neighborhood information [857]. Similar to LLE, the first step of Laplacian eigenmaps is to construct the neighborhood graph. The second step is to get weight matrix based on the neighborhood graph. If xi and xj are neighbors, then (W)i, j = 1 and (W)j, i = 1; otherwise (W)i, j = 0. Thus, W is the symmetric matrix. The third step is to perform dimensionality reduction by computing eigenvalues and eigenvectors for the generalized eigen-decomposition problem [857],
7.84 ![]()
where D is a diagonal matrix and (D)i, i = ∑j(D)i, j;L = D − W is the Laplacian matrix which is a positive semidefinite matrix. The embedding of the low-dimensional data is given by the eigenvectors corresponding to the smallest nonzero eigenvalues.
7.9.6 Semidefinite Embedding
Within the framework of manifold learning, the current trend is to learn the kernel using SDP [8, 388] instead of defining a fixed kernel. The most prominent example of such a technique is semidefinite embedding (SDE) or maximum variance unfolding (MVU) [861]. MVU can learn the inner product matrix of yi automatically by maximizing their variance, subject to the constraints that yi are centered, and local distances of yi are equal to the local distances of xi. Here, the local distances represent the distances between yi (xi) and its k-nearest neighbors, in which k is a parameter.
The intuitive explanation of this approach is that when an object such as string is unfolded optimally, the Euclidean distances between its two ends must be maximized. Thus, the optimization objective function can be written as [861–864]
7.85 ![]()
subject to the constraints,
7.86 ![]()
in which ηij = 1 means xi and xj are k-nearest neighbors otherwise ηij = 0.
Apply inner product matrix
7.87 ![]()
of yi to the above optimization can make the model simpler. The procedure of MVU can be summarized as follows:
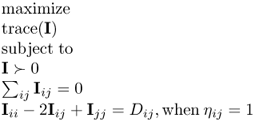
7.89 ![]()
Landmark-MVU (LMVU) [870] is a modified version of MVU which aims at solving larger-scale problems than MVU. It works by using the inner product matrix A of randomly chosen landmarks from xi to approximate the full matrix I, in which the size of A is much smaller than I.
Assuming the number of landmarks is m which are a1, a2, …, am, respectively. Let Q [870] denote a linear transformation between landmarks and original dimensional data xi ∈ RN, i = 1, 2, …, M, accordingly,
7.90 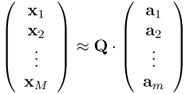
in which
7.91 ![]()
Assuming the reduced dimensionality landmarks of a1, a2, …, am are ![]() , and the reduced dimensionality samples of x1, x2, …, xM are y1, y2, …, yM, then the linear transformation between y1, y2, …, yM and
, and the reduced dimensionality samples of x1, x2, …, xM are y1, y2, …, yM, then the linear transformation between y1, y2, …, yM and ![]() is Q as well [870], consequently,
is Q as well [870], consequently,
7.92 
Matrix A is the inner-product matrix of a1, a2, …, am,
7.93 ![]()
Hence the relationship between I and A is
7.94 ![]()
The optimization problem (7.88) can be reformulated into the following form:

where
7.96 ![]()
7.97 ![]()
and ![]() represents A is positive semidefinite. The optimization problem (7.95) differs from the optimization problem (7.88) in that equality constraints for nearby distances are relaxed to inequality constraints in order to guarantee the feasibility of the simplified optimization model.
represents A is positive semidefinite. The optimization problem (7.95) differs from the optimization problem (7.88) in that equality constraints for nearby distances are relaxed to inequality constraints in order to guarantee the feasibility of the simplified optimization model.
LMVU can increase the speed of programming but at the cost of accuracy.
7.10 Ensemble Learning
Ensemble learning tries to use multiple models to obtain better predictive performance which means a target function is learned by training a finite set of individual learners and combining their predictions [871]. Ideally, if there are M models with uncorrelated errors, simply by averaging them the average error of a model can be reduced by a factor of M [872]. The common combination schemes include [873]:
- voting;
- sum, mean, median;
- generalized ensemble;
- adaptive weighting;
- stacking;
- borda count;
- logistic regression;
- class set reduction;
- Dempster-Shafer;
- fuzzy integrals;
- mixture of local experts;
- hierarchical mixture of local experts;
- associative switch;
- bagging;
- boosting;
- random subspace;
- neural tree;
- error-correcting output codes [874].
Sometimes, the more general concept than ensemble learning is meta learning. Meta learning [875] tries to learn the interaction between the mechanism of learning and the concrete contexts in which that mechanism is applicable based on meta data [876].
7.11 Markov Chain Monte Carlo
MCMC methods [877–879] are a class of sampling algorithms. A Markov chain is constructed such that the equilibrium distribution of Markov chain is the same as the desired density of the sampled probability distribution.
The key point of Monte Carlo principle is to draw a set of i.i.d. samples xn, n = 1, 2, …, N from the PDF p(x) defined on a high-dimensional space [878]. These N samples can be exploited to approximate the PDF p(x) as [878]

Based on Equation (7.98), Monte Carlo integration tries to compute integral using large randomly-generated numbers,
7.99 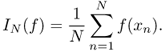
As N → ∞, then,
7.100 ![]()
Suppose we want to calculate the integral ∫f(x)q(x)dx. However, the samples from the PDF q(x) are hard to generate. But ![]() is easy to evaluate. Thus,
is easy to evaluate. Thus,
7.101 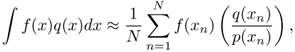
where xn is drawn from the PDF p(x). This method is called importance sampling.
The Metropolis-Hastings algorithm is one of the most popular MCMC methods [878]. In order to get samples from the PDF p(x), the Metropolis-Hastings algorithm is performed as [878]:
The Metropolis-Hastings algorithm can be reduced to the Metropolis algorithm if the proposal distribution is symmetric, that is,
7.103 ![]()
and the calculation of α in Equation (7.102) can be simplified as
7.104 ![]()
MCMC can work for various algorithms and applications within the framework of machine learning [878, 880–898]. MCMC can be explored for various optimization problems, especially for large-scale or stochastic optimization [899–907].
Gibbs sampling is a special case of the Metropolis-Hastings algorithm. Gibbs sampling gets samples from the simple conditional distributions instead of the complex joint distributions. If the joint distribution of {X1, X2, …, XN} is p(x1, x2, …, xN), the k-th sample ![]() can be obtained sequentially as follows [908]:
can be obtained sequentially as follows [908]:
7.105 
MCMC has also been applied to cognitive radio network [909–912].
7.12 Filtering Technique
Filtering is the common approach in signal processing. For communication or radar, filtering can be used to perform frequency band selection, interference suppression, noise reduction, and so on. In machine learning, the meaning of filtering is greatly extended. Kalman filtering and particle filtering are explored to deal with the sequential data, for example, time series data. Collaborative filtering are exploited to perform recommendations or predictions.
7.12.1 Kalman Filtering
Kalman filtering is a set of mathematical equations that provides an efficient computational and recursive strategy to estimate the state of a process such that the mean of squared error can be minimized [913, 914]. Kalman filtering is very popular in the areas of autonomous or assisted navigation and moving target tracking.
Let's start from the simple linear discrete Kalman filtering to understand how Kalman filtering works. There are two basic equations in Kalman filtering. One is the state equation to represent the state transition. The other is the measurement equation to obtain the observation. The linear state equation can be expressed as
7.106 ![]()
where
- xn is the current of a process or a dynamic system and xn−1 is the previous state;
- An represents the current state transition model;
- un is the current system input;
- Bn is the current control model;
- wn is the current state noise which follows a zero mean multivariate normal distribution with covariance Wn.
The linear measurement equation is represented as
7.107 ![]()
where
- zn is the measurement of the current state xn;
- Hn is the current observation model;
- vn is the current measurement noise which follows a zero mean multivariate normal distribution with covariance Vn.
The goal of Kalman filtering is to estimate ![]() given x0. Meanwhile, An, Bn, Hn, Wn, and Vn are all known. State noises and measurement noises are all mutually independent.
given x0. Meanwhile, An, Bn, Hn, Wn, and Vn are all known. State noises and measurement noises are all mutually independent.
There are two main steps in Kalman filtering [913]. One is the predict step and the other is update step. These two steps are performed iteratively.
The procedure of the predict step is [913]:
7.108 ![]()
7.109 ![]()
The procedure of the update step is [913]
7.110 ![]()
7.111 ![]()
7.112 ![]()
7.113 ![]()
7.114 ![]()
Linear Kalman filtering can be extended to the extended Kalman filtering and the unscented Kalman filtering to deal with the general nonlinear dynamic system. In the nonlinear Kalman filtering, the state transition function and state measurement function can be the nonlinear functions shown as
7.115 ![]()
and
7.116 ![]()
If the nonlinear functions are differentiable, the extended Kalman filtering computes the Jacobian matrix to linearize the nonlinear functions [913]. The state transition model An can be represented as
7.117 ![]()
and the state observation model Hn can be represented as
7.118 ![]()
If the functions f and g are highly nonlinear and the state noise and measurement noise are involved in the nonlinear functions, the performance of the extended Kalman filtering is poor. We need to resort to the unscented Kalman filtering to handle this tough situation [915, 916].
The unscented transformation is the basis of the unscented Kalman filtering. The unscented transformation can calculate the statistics of a random variable which goes through a nonlinear function [915]. Given an L-dimensional random variable x with mean ![]() and covariance Cx, we would like to calculate the statistics of y which satisfies y = f(x). Based on the unscented transformation, 2L + 1 sigma vectors are sampled according to the following rule,
and covariance Cx, we would like to calculate the statistics of y which satisfies y = f(x). Based on the unscented transformation, 2L + 1 sigma vectors are sampled according to the following rule,
7.119 
where λ is a scaling parameter and ![]() is the l-th column of the matrix square root [916]. These sigma vectors go through the nonlinear function to get the samples of y,
is the l-th column of the matrix square root [916]. These sigma vectors go through the nonlinear function to get the samples of y,
7.120 ![]()
Thus, the mean and covariance of y can be approximated by the weighted sample mean and the weighted sample covariance [916],
7.121 
and
7.122 
where ![]() and
and ![]() are given deterministically [916].
are given deterministically [916].
The state transition function and the state measurement function for the unscented Kalman filtering can be written as [916]
7.123 ![]()
and
7.124 ![]()
The state vector for the unscented Kalman filtering is redefined as the concatenation of xn, wn, and vn [916],
7.125 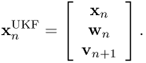
There are three steps in the unscented Kalman filtering. The first step is to calculate sigma vectors. The second step is the predict step and the third is the update step. These three steps are performed iteratively. The whole procedure of the unscented Kalman filtering is [916],
7.126 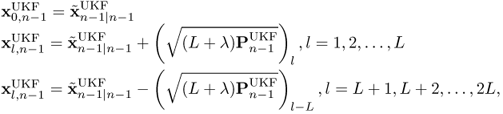
7.127 
7.128 ![]()
7.129 
7.130 
7.131 ![]()
7.132 
7.133 ![]()
7.134 
7.135 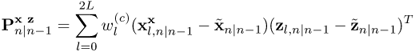
7.136 ![]()
7.137 ![]()
7.138 ![]()
Kalman filtering and its variants have been used in cognitive radio network [917–927].
7.12.2 Particle Filtering
Particle filtering is also called sequential Monte Carlo method [878, 928, 929]. Particle filtering is the sophisticated model estimation technique based on simulation [928]. Particle filtering can perform the on-line approximation of probability distribution using a set of randomly chosen weighted samples or particles [878]. Similar to PSO, multiple particles are generated in particle filtering and these particles can evolve.
Similar to Kalman filtering, particle filtering also has an initial distribution, a dynamic state transition model, and the state measurement model [878]. Assume x0, x1, x2, …, xn, … are the underlying or latent states and y1, y2, …, yn, … are the corresponding measurements.
- The initial distribution of x is p(x0).
- The dynamic state transition model is p(xn | x0:n−1, y1:n−1), n = 1, 2, … .
- The state measurement model is p(yn | x0:n, y1:n−1), n = 1, 2, … .
x0:n = {x0, x1, …, xn} and y1:n = {y1, y2, …, yn}. Markov conditional independence can be used to simplify the models as p(xn | x0:n−1, y1:n−1) = p(xn | xn−1) and p(yn | x0:n, y1:n−1) = p(yn | xn) [878].
The basic goal of particle filtering is to approximate the posterior p(x0:n | y1:n) as
7.139 
where L is the number of particles used in particle filtering; xl, 0:n is the l-th particle maintaining the whole trajectory; wl, n is the corresponding weight which should be normalized,
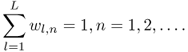
Based on the concept of importance sampling, sequential importance sampling is used to generate the particle and the associated weight [930]. The importance function is chosen such that [930]
7.141 ![]()
Given xl, 0:n−1, l = 1, 2, …, L and wl, n−1, l = 1, 2, …, L, particle filtering updates the particle and the weight as follows [878, 930]:
7.142 ![]()
7.143 ![]()
If the importance function is simply given by p(xn | xl, n−1), then the weight can be updated as [928, 930],
7.144 ![]()
However, after a few iterations for sequential importance sampling, most of the particles have a very small weight. The particles fail to represent the probability distribution accurately [928]. In order to avoid this degeneracy problem, sequential importance resampling is exploited. Resampling is a method that gets rid of particles with small weights and replicates particles with large weights [930]. Meanwhile, the equal weight is assigned to each particle.
Particle filtering and its variants have been used in cognitive radio network [931–933].
7.12.3 Collaborative Filtering
Collaborative filtering [934] is the filtering process of information or pattern. Collaborative filtering deals with large scale data involving collaboration among multiple data sources. Collaborative filtering is a method to build the recommender system, which exploits the known preferences of some users to make recommendation or prediction of the unknown preferences for other users [935]. Item-to-item collaborative filtering is used by Amazon.com to match each of the user's purchased and rated items to the similar items which are combined into a recommendation list [936]. Netflix, an American provider of on-demand Internet streaming media, held an open competition for the best collaborative filtering algorithm. A large scale industrial dataset with 480,000 users and 17,770 movies was used for the competition [935].
The challenges of collaborative filtering are [935]:
- data sparsity;
- scalability;
- synonymy;
- gray sheep and black sheep;
- shilling attacks;
- personal privacy.
Matrix completion [643, 937] can be used to address the issue of data sparsity in collaborative filtering. The data matrix for collaborative filtering can be recovered even if this matrix is extremely sparse as long as the matrix is well approximated by a low-rank matrix [937, 938].
There are three categories for collaborative filtering algorithms [935]:
- memory-based collaborative filtering, for example, neighborhood-based collaborative filtering, top-N recommendation, and so on;
- model-based collaborative filtering, for example, Bayesian network collaborative filtering, clustering collaborative filtering, regression-based collaborative filtering, MDP-based collaborative filtering, latent semantic collaborative filtering, and so on;
- hybrid collaborative filtering.
Collaborative filtering can be explored for cognitive radio network [939–942].
7.13 Bayesian Network
Bayesian network [943, 944] is also called belief network or directed acyclic graphical model. Bayesian network explicitly uncovers the probabilistic structure of dependency in a set of random variables. It uses a directed acyclic graph to represent the dependency structure, in which each node denotes a random variable and each edge denotes the relation of dependency. Bayesian network can be extended to dynamic Bayesian network to model the sequential data or the dynamic system. The sequential data can be anywhere. Speech recognition, visual tracking, motion tracking, financial forecasting and prediction, and so on are the temporal sequential data [945].
The well-known hidden Markov model (HMM) can be treated as one simple dynamic Bayesian network. Meanwhile, the variants of HMM can be modeled as dynamic Bayesian networks. These variants include [945]:
- auto-regressive HMM;
- HMM with mixture-of-Gaussians output;
- input-output HMM;
- factorial HMM;
- coupled HMM;
- hierarchical HMM;
- mixtures of HMM;
- semi-Markov HMM;
- segment HMM.
State space model and its variants can also be modeled as dynamic Bayesian networks [945]. The basic state space model is also known as dynamic linear model or Kalman filter model [945].
Bayesian network is a powerful tool for learning and inference in cognitive radio network. Various applications of Bayesian network in cognitive radio network can be found in [536, 946–949].
7.14 Summary
In this chapter, machine learning has been presented. Machine learning can be applied everywhere to make the system intelligent. In order to give readers the whole picture of machine learning, almost all the topics related to machine learning have been covered in this chapter which include unsupervised learning, supervised learning, semi-supervised learning, transductive inference, transfer learning, active learning, reinforcement learning, kernel-based learning, dimensionality reduction, ensemble learning, meta learning, MCMC, Kalman filtering, particle filtering, collaborative filtering, Bayesian network, HMM, and so on. Meanwhile, the references about applications of machine learning in cognitive radio network have been given. Machine learning will be the basic tool to make cognitive radio network practical.