
8
Routing in ATM Networks
8.1 Introduction
Asynchronous transfer mode (ATM) is a connection‐oriented switching and network transmission technique introduced in the late 1980s. ATM was introduced in the days when public switched telephone networks (PSTNs) were in common use supporting only voice or data. ATM brought in the technology to support voice, video, and data over a single network. This is a full duplex transmission technology that supports a variety of physical media such as UTP cable and fiber optic cable. ATM can be used in a small LAN as well as between two or more LANs spread across wide distances and connected over a WAN.
As ATM is connection oriented, it ensures delivery of cells in order and with high accuracy. Most of the ATM switching function is implemented in the hardware, and the least number of operations are performed through software. This enhances the speed of the system. Operability over fiber optic cable makes it free from noise interference during transmission and can help ATM reach gigabit transmission rates.
An ATM packet size [1] is fixed at 48 bytes for payload and 5 bytes for the header, leading to a total size of 53 bytes. The fixed packet size leads to removal of information regarding size of the payload in the packet header. The fixed‐size packet also supports the design of ATM‐specific switching hardware to work at higher speed, as the packet size is fixed and known a priori. Even the operating software running on the ATM switches is much simpler and hence faster, as it requires neither any procedure to detect the size of the packet nor any procedure to determine where one packet ends and the other begins. The fixed‐size, 53 byte packet of an ATM is referred to as a ‘cell’. Generally, a small packet size is good for transmission of voice and video over the network, while a big packet size better supports data traffic. A large packet size enables a huge amount of data to be carried with comparatively less overhead of carrying its header. However, a fixed‐size large packet may lead to wastage of data carrying space in the packet owing to non‐availability of sufficient data to fill the complete data space of each packet. The cell size of 53 bytes was decided so as to make the size optimum to support voice as well as data.
The mechanism for handling variable packet size in a network is complex and hence cannot be completely implemented in the hardware. The operating software running on network equipment, such as switches or routers, has to handle a variable packet size and read each bit passing through it to determine the start of the packet, read the information about the size of the packet from the header, detect the end of the header and the start of data payload, distinguish between the actual data and the padding in the data payload, and finally detect the end of the packet in the stream [2].
The packets from various network links are multiplexed over a single line for long‐distance transmission. A sample output of multiplexing packets from three different networks over a single network is depicted in Figure 8.1. The largest‐size packet ‘G’ gets preference over any other packet as it was the first to reach the multiplexer, while the smallest‐size packet ‘F’ has to wait until packets ‘G’ and ‘B’ are transmitted. This leads to a huge waiting time before transmission of the small packets in the example. Fixing priority to the lines would also not help in the scenario because, even if the second line could have been assigned the highest priority, ‘F’ would still be transmitted after ‘G’ as it arrived after ‘G’ and the multiplexer would not keep waiting for ‘F’ to arrive when ‘G’ had already done so, and the time and probability of arrival of ‘F’ are not known to the multiplexer. The only difference that priority‐based multiplexing with highest priority to the second line can make here is that ‘F’ will be transmitted after ‘G’ but before ‘B’. As data packets are generally larger in size than voice and video packets, this example clearly shows the disadvantage that voice and video traffic can have over this type of network.
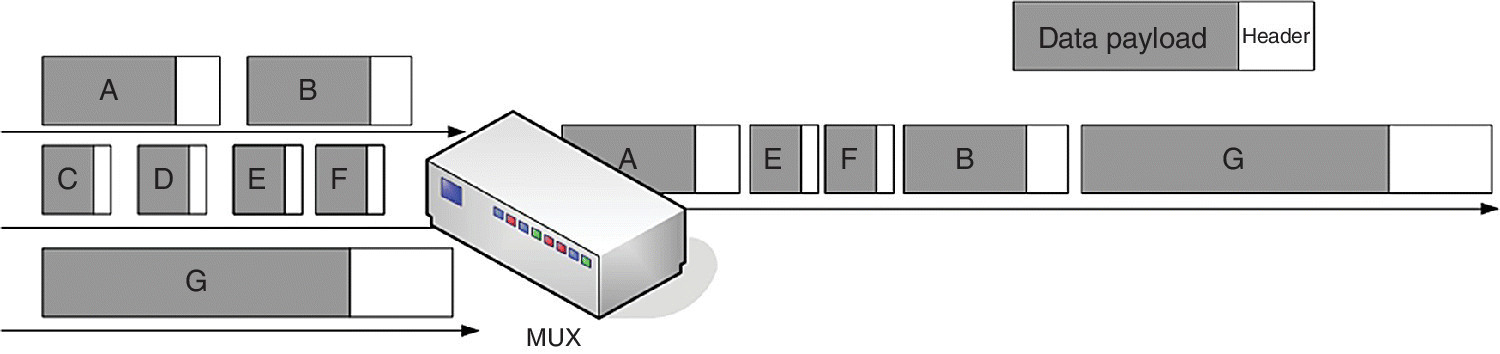
Figure 8.1 Multiplexing packets of variable size from three networks.
Using the same size packets in the network helps in avoiding delays due to the larger packets making the smaller packets wait for channel availability. The larger‐sized packets can be broken into smaller fixed‐size packets, and if the entire network uses the same size packets as depicted in Figure 8.2, the problem depicted in Figure 8.1 is avoided. This also enables picking a packet from each of the channels one after the other, leading to a small waiting time and a small delay between the transmission and reception of two consecutive packets from the same network. The working of ATM is similar to the example depicted in Figure 8.2 and is known as asynchronous time division multiplexing, wherein a number of input channels are multiplexed over a single channel. It is called asynchronous because it picks the data packet, i.e. the ‘cell’, from any of the input channels that has a cell awaiting transmission. The output channel at a particular time slot is empty only if all the input channels do not have any cell to transmit at that time slot.

Figure 8.2 Multiplexing packets of fixed size from three networks.
8.1.1 ATM Frames
The ATM network has two different interfaces, one for connection between the ATM switches and the other for connection between the ATM switches and the endpoints. The interface between ATM switches is called the network‐to‐network interface (NNI). The endpoints in an ATM network can be computers, workstations, and servers. The interface between ATM switches and endpoints is known as the user‐to‐network interface (UNI). The UNI and NNI are depicted in a sample network shown in Figure 8.3.

Figure 8.3 UNI and NNI depicted in a typical ATM network.
Although the ATM cell header is 5 bytes, there are two different types of cell header in ATM, depending on the endpoints between which the ATM cell travels. When an ATM cell travels between an ATM switch and a network endpoint, the cell uses a UNI header, which is depicted in Figure 8.4. When the ATM cell travels between two ATM switches, it uses an NNI header as depicted in Figure 8.5. As can be seen from the figures of the UNI and NNI headers, the first four bits of the UNI header are for ‘generic flow control’, while even these four bits are used for the virtual path identifier in the NNI header. This is the only disparity between the two headers. Apart from this, the name and the size of all other fields in the headers are the same in both UNI and NNI. The fields in the headers [1] are described in Table 8.1.

Figure 8.4 ATM cell header for the user network interface (ATM switch–endpoint).

Figure 8.5 ATM cell header for the network node interface (ATM switch–ATM switch).
Table 8.1 The fields in the ATM cell header.
| Field | Interface | Bits | Description |
| Generic flow control (GFC) | UNI | 4 | This is used to identify the individual computer at the endpoint. The default value is ‘0000’ and the field is rarely used these days. |
| Virtual path identifier (VPI) | UNI, NNI | 8 UNI 12 NNI | Uniquely identifies the virtual path through the network for the cell. In the case of a control cell for call setup or termination, the value of the field is 0. |
| Virtual circuit identifier (VCI) | UNI, NNI | 16 | This field along with the VPI uniquely identifies the path of the cell through the switched network. Field values of 0 to 15 are reserved for use by the International Telecommunication Union (ITU), and field values of 16 to 32 are for the use of the ATM forum for signaling and control operations. |
| Payload type (PT) | UNI, NNI | 3 | All three bits have separate respective indications. A value of ‘0’ in the first bit indicates that the cell has a data payload, and ‘1’ indicates a control payload. For a data payload, the second bit, which has an initial value of ‘0’ from source, reports network congestion by being changed to ‘1’ by the switch facing congestion. For data payloads, the third bit indicates the last cell of the series in the AAL5 frame. For control payloads, the bit is used for control purposes. |
| Cell loss priority (CLP) | UNI, NNI | 1 | This indicates priority for dropping the cell during network congestion. A field value of ‘0’ indicates a preference for not being dropped, while cells with a field value of ‘1’ are selected for dropping. |
| Header error control (HEC) | UNI, NNI | 8 | This stores the CRC value of the first four bytes of the header. |
8.1.2 ATM Connection
ATM is a connection‐oriented switching network. Hence, a connection has to be established between the endpoints before transmission of the cell stream. Two different types of connection can be established in an ATM – permanent virtual circuit connection (PVC) and switched virtual circuit connection (SVC). PVC between the endpoints can be established only through the network service provider, while SVC is created by the ATM with support from any network layer protocol every time the endpoints want to communicate with each other.
For creating the connection channel, logically three different hierarchies of connection exist in ATM. These are the virtual circuits (VCs), virtual path (VP), and transmission path (TP). The VC between two endpoints carries all the cells of a message and is transmitted from the source to the destination in order through the VC. Virtual circuits are uniquely identified by a 16 bit virtual circuit identifier (VCI). The set of virtual circuits over the same path between switches are bundled together to form the VP. The creation of a virtual patch for the bundled virtual circuits helps to perform common control and management functions together for all the VCs in the VP. The VP is uniquely identified by the virtual path identifier (VPI). All the virtual circuits that are bundled in the same VP have the same VPI. There can be different virtual circuits with the same VCI in two or more different virtual paths. These VCs with the same VCI can be identified uniquely with the help of the VPI. TP is the connection between switches or between the switch and its endpoints. A logical cross‐section of the virtual connection depicting VC, VP, and TP is represented in Figure 8.6. Breaking up the connection into VP and VC helps to create a hierarchy to support better routing strategies. The ATM switches, when communicating with each other, have to use only the VPI, while only the boundary switches that connect to the endpoint have to use VPI and VCI.

Figure 8.6 Cross‐section of a virtual connection indicating VC, VP, and TP.
In Figure 8.3, if endpoints 1 and 2 want to communicate with endpoint 3, two virtual circuits are created, one from endpoint 1 to endpoint 3 and the other from endpoint 2 to endpoint 3. A single virtual path will bundle both these virtual circuits, and this virtual path will be from ATM switch 1 to ATM switch 4 through ATM switch 5. However, if endpoint 4 wants to communicate with endpoint 5 and endpoint 6 wants to communicate with endpoint 7, two virtual circuits and two virtual paths will the formed. The first virtual path will be from ATM switch 4 to ATM switch 3 through ATM switch 5, and the second virtual path will be from ATM switch 3 to ATM switch 2 through ATM switch 5. There may be one or more links between the ATM switches. Assuming that there is only a single link between the switches, as depicted in Figure 8.3, there is a transmission path each from switch 1, switch 2, switch 3, and switch 4 to switch 5.
In an ATM network, the ATM switches perform cell routing with the help of a switching table maintained in it. The boundary switches that are connected to the endpoints at one interface and some other switch or endpoint at the other interface have to use the virtual circuit identifier as well as the virtual path identifier for cell switching. As shown in Figure 8.7, the switching table has six columns of information per row, three each for input and output respectively. These columns are the interface number, VPI, and VCI for both the input and the output. When a cell arrives at the interface of a switch, the VPI and the VCI are known through the header of the cell, and the arrival interface number is determined from the interface on which the packet has arrived. The switch checks the routing table entry corresponding to this triad of < Interface No. (input), VPI (input), VCI (input) > and, on locating the entry corresponding to this information, gets the switching information in the form of < Interface No. (output), VPI (output), VCI (output)>. Based on this output information, the switch forwards the cell through the interface number mentioned in the switching table with the changed VPI and VCI as obtained from the switching table [2]. Thus, it is observed that the VCI and VPI are of local significance, restricted to a single link and changing with each hop. When a cell is forwarded from one ATM switch to another ATM switch, the switching table is used to change the value of VCI and VPI of the cells passing through the ATM switch.

Figure 8.7 Structure of an ATM switching table.
8.1.3 ATM Architecture
ATM is a three‐layer protocol that is represented in Figure 8.8, and these layers from top to bottom are:
- ATM adaptation layer,
- ATM layer,
- physical layer.

Figure 8.8 Three‐layered ATM protocol stack.
ATM adaptation layer. The ATM adaptation layer can be divided into two sublayers – the convergence sublayer (CS) and the segmentation and reassembly sublayer (SAR). The CS sublayer receives the data frame from the upper layer and encapsulates it in a format for supporting reassembly at the other end. The SAR sublayer divides the data into 48 byte segments and passes it on to the ATM layer, where a 53 byte cell is created with this 48 byte payload. As the layer divides the data into 48 byte segments at the transmitting end and reassembles the 48 byte data into the complete message at the receiving end, it has been named the segmentation and reassembly sublayer.
Several versions of AAL have been defined. These are AAL0, AAL1, AAL2, AAL3/4, and AAL5. The most commonly used among these are AAL1, which is used for time‐dependent applications at constant bit rates such as voice and video, and AAL5, which also has the error control mechanism for applications with variable bit rates. AAL2 was designed for variable‐data‐rate bit streams for applications such as compressed voice and video, and the layer was later modified for low‐bit‐rate, short‐frame traffic. AAL3/4 was designed for a variable‐bit‐rate connection‐oriented (AAL3) and variable‐bit‐rate connectionless (AAL4) service for applications such as data transfer over LAN.
ATM layer. The ATM layer takes a 48 byte segment from the AAL, adds the 5 byte header to it, and makes a 53 byte ATM cell. The ATM layer is responsible for multiplexing‐demultiplexing, switching, routing, flow control, and traffic management. The ATM layer is also responsible for monitoring the connection for QoS. However, unlike equivalent layers in the other protocols, the ATM layer is not responsible for error correction.
Physical layer. The physical layer is responsible for actual transmission of the cells in the network. ATM cells can be carried by any of the commonly used physical layer transmission mediums such as metallic wire or fiber optic cable. Although ATM was initially designed to work over SONET at the physical layer, now it is not limited to any transmission medium, and even wireless transmission can be used at the physical layer for ATM. The physical layer can be subdivided into two sublayers – the physical‐medium‐dependent sublayer (PMD) and the transmission convergence sublayer (TC). PMD is responsible for interfacing with the actual transmission medium and performing the signal encoding for the same. The design of the physical layer has enabled ATM to transmit over different types of physical network by creating and defining a variety of PMDs. TC is the interface between the ATM layer and the PMD. The TC layer takes the cell from the ATM layer and maps it to the specific frame for the PMD.
The ATM switches do not require the AAL while communicating with each other, and they use only the two lower layers, i.e. the physical layer and the ATM layer. All three layers, including the AAL, are required for communication between endpoints.
8.1.4 Service Categories
Initially ATM reserved a specified and fixed amount of bandwidth for a connection to ensure the service quality. However, all the applications do not require a fixed amount of bandwidth throughout the period of connection as every application has got its different traffic pattern, bandwidth requirement and bandwidth consumption pattern. The requirement can be for a real time support or non real time support for a variety of traffic patterns such as traffic at constant rate, bursty traffic or it can even manage with any available bandwidth. Though all these traffic arrive in the form of 53 bytes cell streams, each has a different requirement for traffic flow based on the application and hence ATM has specified the following service categories to handle different types of traffic:

The application scenario, bandwidth requirement, and service levels for the five service categories specified in ATM are explained in Table 8.2.
Table 8.2 ATM service categories.
| Service Category | Application | Bandwidth Requirement | Service Level |
| CBR | Real‐time applications – voice, video, videoconference, telephone call, video on demand, radio, TV. | The maximum bandwidth is required whenever the application is in use. The rate of flow of information received at destination is equal to the rate of transmission at source. | Guaranteed constant bandwidth. |
| rt‐VBR | Compressed voice or video, teleconferencing. | Traffic varies with time, bursty in nature, but time sensitive. | Transfer delay and delay variation are tightly controlled. Network resources allocated at minimum sustainable cell rate. |
| nrt‐VBR | Reservation system, process monitoring, store/compress and forward video. | Bursty traffic that can tolerate delays. The peak cell rate, average cell rate, and expected frequency of burst are specified. | Delay variation is not controlled, cell loss is controlled. Network resource is allocated to provide low delay and minimal cell loss. |
| ABR | Critical file transfer, financial transactions, fax. | The bandwidth requirement of the application changes with the traffic condition. It may specify a minimum required bandwidth, but may use more if available. | Best‐effort service with congestion control. |
| UBR | File transfer, remote terminal, mailing, network monitoring. | No specific bandwidth or QoS required. Use the available bandwidth. | Best‐effort connection. |
At any point in time, out of the available link bandwidth, a certain amount of bandwidth is reserved for carrying CBR traffic. Thereafter, from the remaining bandwidth, first the rt‐VBR and then the nrt‐VBR are assigned bandwidth. From the remaining small amount of bandwidth left in the link, ABR is assigned the bandwidth as it has specified the bare minimum bandwidth it requires which is generally very small and it may use more bandwidth if available. If some bandwidth is still available owing to non‐utilization by the remaining four services or underutilization by these four services, that bandwidth is assigned to the UBR, which has the least priority. The concept can be seen in Figure 8.9, which is a logical representation of time‐varying bandwidth allocation to the different service categories in ATM.
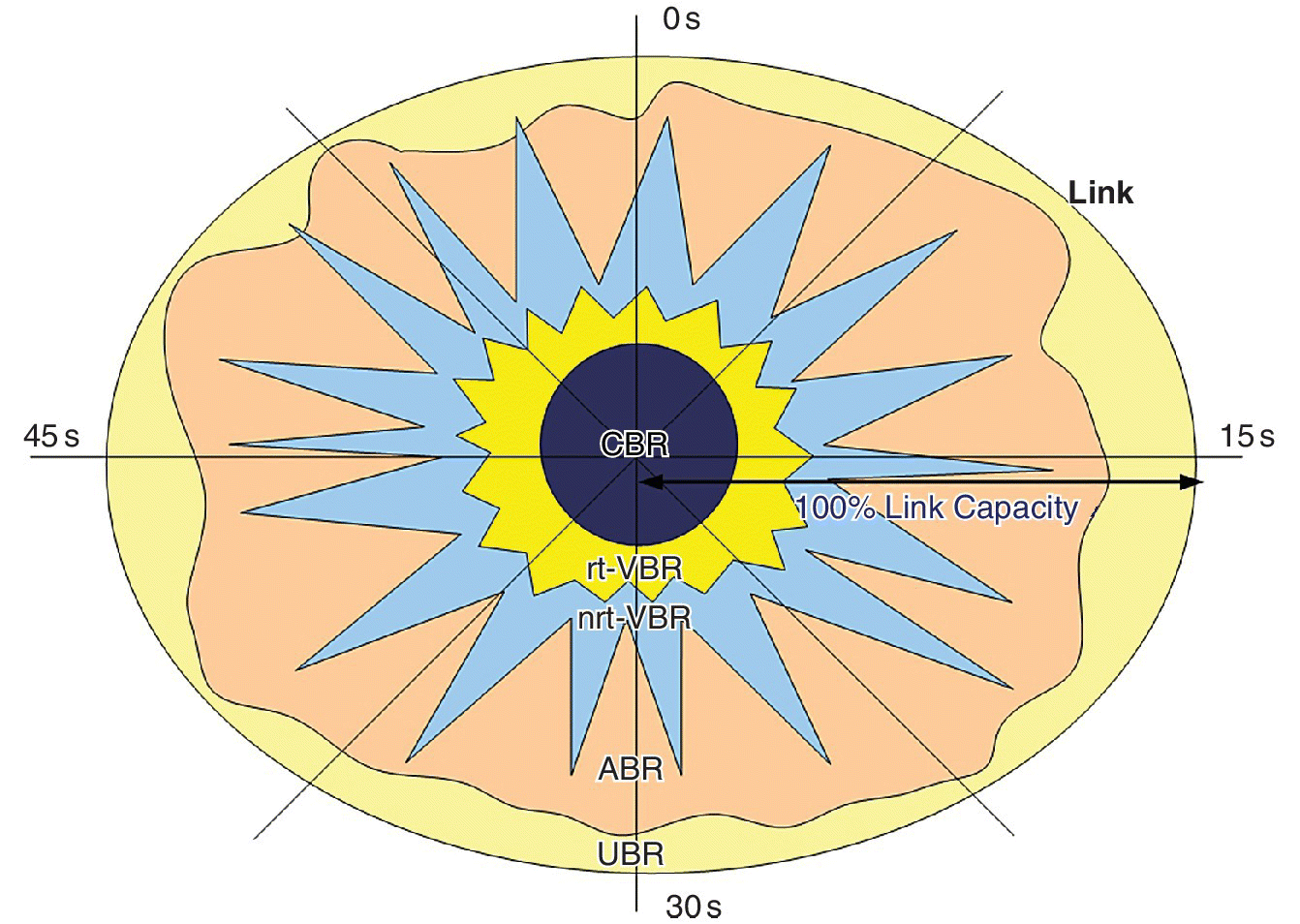
Figure 8.9 Bandwidth distribution for different service categories in ATM over circular time‐variant display.
8.2 PNNI Routing
Routing in ATM networks is more complex than routing in IP networks because in IP networks only the routes for packet forwarding have to be discovered, while in ATM routing, not only does the route have to be determined, but also the QoS has to be guaranteed. Before selecting a route in the ATM network, it has to be ensured that sufficient network resources are available and reserved for the data to reach the destination. There are a number of QoS parameters in ATM routing, which further complicates the routing process. ATM is a source‐based routing and not a hop‐by‐hop routing. As this source‐based routing should also ensure QoS, the QoS information about all the intermediate switches in all the possible paths should be known to the source before forwarding the cell [3]. There can also be variation in the network load and the network condition. Thus, it requires a regular exchange of resource availability information between the switches.
ATM is a connection‐oriented protocol and hence a virtual connection is established between the source and the destination before sending the data. The entire data is sent to the destination through this path, and hence the individual cells are not required to carry the destination address in the header and all the cells follow the same path. As all the cells will follow the same virtual circuit between source and destination, the path selection algorithm should also attempt to select the optimum path from among the multiple available paths.
In ATM the routing is in terms of signaling messages. The signaling messages help to establish the switched virtual connection among the ATM switches. The routing can be between two ATM switches or between two ATM networks. To support routing between two ATM switches, the private network–node interface (PNNI) is used. The private network‐to‐network interface (PNNI) is used for routing between two ATM networks. PNNI helps in the interconnection of switches from various vendors over different networks. PNNI was introduced after Interim Interface Signaling Protocol (IISP), which is a static routing protocol for the ATM network.
PNNI comprises a routing protocol and a signaling protocol. The routing protocol defines the mechanism for creation of a hierarchical topology, neighbor discovery, sharing of topology information among the nodes, creation of peer groups, selection of peer group leaders, link aggregation, node aggregation, and finally path selection. The signaling protocol is responsible for establishing the connection between nodes, indicating any resource starvation at nodes or links before establishment of the path through them, and thereafter setting up alternative routing paths.
8.2.1 PNNI Interface
An ATM network comprises ATM switches, physical links, and end systems. An end system can be a computer or a server. End systems are connected to a switch, and the switches are connected to each other to extend the network. The connectivity between the switches or between the end system and the switch can be point to point or point to multipoint through the physical links. These physical links can be over fiber, copper cables, or even wireless. The point of connectivity of a link with the switch is termed the ‘port’. Thus, for clear identification of the connectivity between two switches, the switch identifier and the port identifier have to be mentioned. The links are bidirectional and duplex in nature. The traffic flowing in each direction is generally different in terms of the amount of data being carried, the time of link utilization, and the amount of data to be transferred. This leads to differences in the characteristics of the link in the two directions. Further to variation in the traffic load through the link in the two directions, the link characteristics may themselves be different in the two directions, leading to variation in its capacity. Hence the physical links have to be identified separately for each direction.
8.2.2 PNNI Hierarchy
PNNI routing being source based, all the nodes should be aware of the entire network topology as well as the condition of the network in terms of resource availability, node congestion, and link congestion for ensuring QoS. If a flat routing is used, the scalability will be highly constrained owing to the large amount of information required to be stored at each node, as well as the regular update on the condition of each link and node. The hierarchical topological structure built up using PNNI ensures scalability by reducing overheads and makes routing efficient in an ATM network. PNNI can have a hierarchical level from 1 to 10.
In PNNI routing, the nodes are grouped into peer groups, and there are peer groups at various hierarchical levels. Each peer group elects a peer group leader. In addition to the other activities performed by the peer group leader, it also participates as a representative of the peer group in the next peer group which is in the next higher hierarchical level. The nodes in a peer group share topology information with each other through flooding. All the nodes in a peer group thus have the same topological information.
Figure 8.10 illustrates a network organized in a hierarchy. The network has six lowest‐level peer groups (PGs) named PG‐A.1, PG‐A.2, PG‐A.3, PG‐B.1, PG‐B.2, and PG‐C. The nodes, which have been depicted by the node IDs A.1.1, A.1.2, A.1.3, and A.1.4, form the peer group PG‐A.1, and the node A.1.1 is the peer group leader of PG‐A.1. Similarly, the nodes A.2.1, A.2.2, A.2.3, A.2.4, and A.2.5 form the peer group PG‐A.2, and the node A.2.2 is the peer group leader. The other peer group nodes and the peer group leaders are indicated in a similar manner. This notation of the peer group as PG‐x.y and a node as a.b.c.d is just for indicating the nodes and peer groups in a simple way during description of the protocol. The actual addressing of the node uses a 20 byte addressing scheme, which indicates clearly the node ID and the peer group. The peer groups PG‐A and PG‐B are the second‐hierarchical‐level peer groups formed by the peer group leaders of its lower‐level peer groups. PG‐A has in it a logical node each from PG‐A.1, PG‐A.2, and PG‐A.3, and similarly PG‐B has in it a logical node each from PG‐B.1 and PG‐B.2. The second‐hierarchical‐level peer groups also select a peer group leader among them to represent the peer group in the next hierarchical level. The highest‐hierarchical‐level peer group in the example has a logical node each from PG‐A, PG‐B, and PG‐C. The highest‐level peer group does not require any peer group leader within its logical nodes. However, if the nodes in the ATM network increase by a large number and the hierarchical levels of the PNNI increase further, the peer group that is presently the highest will have another level of peer group above it, and hence a leader will be required to be elected to represent the peer group in the newly formed topmost hierarchical peer group.

Figure 8.10 Hierarchically configured nodes for PNNI routing.
8.2.3 Building the Network Topology
The nodes on either side of a link are the neighboring nodes. The neighboring nodes may be in the same peer group or in different peer groups. The neighboring nodes periodically exchange ‘hello packets’ with each other, indicating their peer group IDs. If the peer group IDs of the neighboring nodes are different, topology information is not exchanged between them. A node with its neighbor in another peer group is known as a ‘border node’. If the peer group IDs of the neighboring nodes are the same, they share topology information with each other. Two different peer groups can communicate with each other if both have border nodes that connect to a border node in the other peer group. The connectivity can also be through some other intermediate peer groups that are connected to these peer groups. The peer group is aware of the border nodes available in it, and all the nodes in the peer group communicate with other peer groups through these border nodes. The border nodes also share information about their higher‐level peer group and the peer group leader representing the peer group in the higher level with their neighbor node belonging to the other peer group. This helps the border nodes to locate the lowest‐level peer group, which is logically connected to both the border nodes. In Figure 8.10, the nodes C.1 and B.2.2 are the border nodes and the highest‐level PG in the network is the peer group that logically connects these lowest‐level nodes, and the connectivity is: C.1 – highest‐level PG [C–B] – PG‐B [B.2] – B.2.2. The nodes A.2.2 and A.3.1 are border nodes and the lowest‐level peer group that connects these border nodes is PG‐A, and the connectivity is: A.2.2 – PG‐A [A.2–A.3] – A.3.1.
The peer group leader may not be the border node, but it uses the border node to route its traffic. Thus, the connectivity between A.1, A.2, and A.3 in PG‐A depicted in Figure 8.10 is not through direct links but through logical links indicating connectivity between the peer groups through some other nodes in the peer group. At the lowest hierarchical level, the links between the nodes are generally physical links or virtual circuits. The links inside a peer group are called ‘horizontal links’, while the links between nodes in separate peer groups are called ‘outside links’.
As soon as a link becomes operational, the nodes at either side of it start periodic exchange of ‘hello packets’. The ‘hello packet’, in addition to containing the peer group ID of the node, also contains information about its node ID and the port ID. This exchange of information is done over the routing control channel through a virtual circuit setup over the link between the nodes. This regular exchange of ‘hello packets’ between the neighboring nodes not only gives information about the continuation of connectivity but also provides information such as link delays and processing delays at the neighboring node owing to high resource utilization.
The state information of a node is passed on to its peer group members through messages called PNNI topology state elements (PTSEs). A PTSE contains nodal information and topology state information. Nodal information comprises system capabilities and nodal state parameters, i.e. outgoing resource availability and a nodal information group that has next higher‐level binding information. Topology state information contains information about horizontal links, uplinks, internal reachable ATM addresses, and exterior reachable ATM addresses. Some attributes and metrics of the PTSEs are static, while certain others are dynamic with different rates of change in information. However, the dynamic and static parameters are exchanged in a combined way between the nodes through the PTSEs. The dynamic parameters are not exchanged at a greater frequency between the nodes. Each node floods its PTSEs in the peer group, and thus all the nodes in a peer group have the PTSEs of all other nodes, giving them a complete view of the entire peer group. The aggregated topology information is also passed up in the hierarchy through the peer group leader, through which it reaches the other peer groups. Similarly, the peer group leader passes the information it receives from other peer groups down in the hierarchy to the lower‐level nodes, giving each node a view of the complete network. The collection of all PTSE information in a node generates the topology database for the node. This topology database can provide path information from the node to any other node in the network. PTSEs are exchanged between nodes using PNNI topology state packets (PTSPs), which also use the routing control channel (RCC) over the virtual circuits between the neighboring nodes.
8.2.4 Peer Group Leader
The selection of the peer group leader (PGL) is based on the value of ‘leadership priority’. A node in a peer group with highest ‘leadership priority’ is selected as the leader. Once the node is selected as a leader, its ‘leadership value’ is further increased so as to ensure that it continues to remain the peer group leader. This continuity leads to stability in the peer group with respect to aggregations and communication and avoids change of the peer group leader at short intervals. However, in the case of failure of the peer group leader or joining of a new node with a higher ‘leadership value’, the PGL election algorithm, which keeps running continuously, selects the new PGL.
Every peer group has only one peer group leader. A peer group is sometimes partitioned owing to failure of links or nodes in the peer group. This leads to the creation of two peer groups with the same peer group ID, but each with a separate PGL. The PGL performs three major activities – link aggregation, node aggregation, and representation of the peer group in the higher‐level hierarchy by acting as a logical group node (LGN). If a network has only one peer group, a PGL is not required.
Link aggregation is the process of representing multiple links between two peer groups by using a single logical link. Two peer groups may be connected with each other using one or more border nodes. A border node in a peer group may be connected to two or more different border nodes in another peer group. Alternatively, two or more border nodes in a peer group may be connected to two or more border nodes in another peer group. These links are represented in the lowest‐level hierarchy. However, while representing the PNNI in the higher‐level hierarchies, these multiple links between any two peer groups are represented in the aggregated form of a single logical link. For example, in Figure 8.10 the logical link between A.1 and A.2 is an aggregation of the links (A.1.1–A.2.4) and (A.1.3–A.2.4), and the logical link between A.2 and A.3 is an aggregation of the links (A.2.1–A.3.3) and (A.2.2–A.3.1). Even at the highest level of hierarchy, the logical link between A and B is an aggregation of the links (A.2.5–B.1.2) and (A.3.1–B.1.1).
In a hierarchical representation of a peer group, the peer group leader represents the entire peer group in the next upper hierarchical peer group. Thus, all the nodes in a peer group are aggregated as a single node through its peer group leader in the next higher peer group, a process known as node aggregation.
The peer group leader, which becomes the logical group node (LGN) in the next hierarchical level, is responsible for sending information from its peer group to the other peer groups. Full topology and addressing information is not sent to other peer groups by exchanging PTSEs or topology databases. Aggregated topology information and summarized reachability information are sent through the PGL to the next level in the hierarchy, and from there it goes to the other peer groups through the LGN. The summarized reachability information is in terms of addresses than can be reached through its lower‐level peer group.
8.2.5 Advertizing Topology
When a neighbor node comes up at the other side of the link, this node may not have any topology information available with it as the node might be newly joining the network. In such a case, the entire topology database from the node already operating in the network is copied to the neighboring node that has newly joined the network. Once the network is in operation, the nodes in a peer group regularly exchange PTSE information to have a similar and updated topology database. The topology database in a node has detailed topology of all other nodes in the peer group and abstract topology information about the entire PNNI routing network. Before sending the complete PTSE to the neighbor, a node first exchanges the PTSE header with the neighboring node, indicating availability of a new PTSE with it. If the PTSE header indicates a newer version than the one already existing in the neighboring node, this neighboring node sends back a request to the node that has sent it the PTSE header and requests for the complete PTSE. On receiving the complete PTSE, this neighboring node updates the topology database. After updating its own topology database, the header of this new version of PTSE is sent to the other neighboring nodes except the one from which the PTSE was received, and the process is repeated in the other nodes in the peer group. This leads to a hop‐by‐hop flooding of PTSE information in the peer group. PTSE information, once entered in the topology database, does not remain there forever. The PTSE has a life and is removed from the topology database if an updated version is not received within the predefined life of the PTSE.
The topology database exchange in peer groups at the higher level is similar to that in the peer groups at the lowest level of the hierarchy. In the case of lowest‐level peer groups, there are logical nodes with horizontal links, while in the case of higher‐level peer groups there are ‘logical group nodes’ connected by horizontal links. A PTSE never moves up in the hierarchy, but there are PTSEs in the higher‐level peer groups that are exchanged between the logical group nodes. A routing control channel is established between the LGN in a peer. Still, a ‘hello packet’ is exchanged between the peers to confirm this connectivity and membership to the same peer group. Thereafter there is topological database exchange between these LGNs in the peer. However, this topological database is different from the one that the nodes exchange with each other at the lower hierarchical level. This topology database is based only on the PTSEs from the LGNs flooded within the higher‐level peer group. As PTSEs can flow downwards, the higher‐level peer groups also receive PTSEs from the peer groups above it in the hierarchy, and they too add to the topology database of the LGNs.
8.2.6 Setting up Connection
PNNI routing [4] provides all the switching nodes with complete topological information of the ATM network. This helps the source node to select the path up to the destination node using source routing without dependency on any other node for routing. All the route calculation is done in the source node, and hence there are no chances of any loop formation. Source routing also makes the network free from running the same routing and path selection algorithm in all the intermediate nodes. Setting up of a connection between two nodes for transfer of data using ATM cells comprises two steps – path selection from the source to the destination and setting up of connections between all the nodes in the selected path. The connections should be in the selected sequence of links in the case of multiple links between the nodes. In an ATM network, the user can specify the minimum bandwidth requirement and the other QoS parameters.
It might happen that a node in the selected path is unable to provide the assured QoS parameters at the time of connection setup. Such a situation occurs when an intermediate node has to assign its resources, after transmitting the last update, to some other connection or this update has not yet reached all the other nodes including the source node. In such a scenario, at the time of connection setup through the intermediate nodes, a node that cannot assure resource availability as per the QoS refuses the connection. On refusal of connection by the intermediate node, an alternative route has to be calculated again from the last connected intermediate node with assured QoS. In this case the last connected node with the assured QoS has to take the routing decision, calculating an alternative path to the destination that the path selection algorithm running on the node feels can provide the assured QoS. This process of rolling back the connection to the last node with assured QoS is known as ‘crankback’.
If the source and the destination are in the same peer group, the source node calculates the entire route. However, if the source and the destination nodes are in different peer groups, a designated transit list (DTL) is created by the source node, which contains the entire path in the peer group of the source node up to the border node of the peer group. Thereafter, the DTL contains the abstract path in terms of logical group nodes in the higher‐level peer groups and optionally the logical links between them. The path is optimized by selecting the LGN in the lowest common peer group. The logical group node at the higher‐level peer group is responsible for routing the path through its lowest‐level peer group across the two border nodes in the lowest peer group so as to keep the detailed path consistent with the abstract path described by the source node. If the border node detects the destination in its peer group, it calculates the route to the destination. If the border node detects the destination to be out of the peer group, it calculates a suitable route to another border node in the peer group that the entry border node feels is in the path towards the destination and consistent with the initial abstract path. PNNI gives a great degree of interoperability among the ATM switches as the nodes can have different path selection algorithms.
References
- 1 S. Mueller. Upgrading & Repairing Networks, Chapter 16. Que, 4th edition.
- 2 B. A. Forouzan. Data Communications and Networking. Tata McGraw‐Hill, 3rd edition, 2004.
- 3 K. Sumit. ATM Networks: Concepts and Protocols. Tata McGraw‐Hill, 2nd edition, 2006.
- 4 The ATM Forum Technical Committee, Private Network–Network Interface Specification Version 1.0. http://www.broadband‐forum.org/ftp/pub/approved‐specs/af‐pnni‐0055.000.pdf, March 1996.
Abbreviations/Terminologies
- AAL
- ATM adaptation layer
- ABR
- Available Bit Rate
- ATM
- Asynchronous Transfer Mode
- CBR
- Constant Bit Rate
- CLP
- Cell Loss Priority
- CS
- Convergence Sublayer
- DTL
- Designated Transit List
- GFC
- Generic Flow Control
- HEC
- Header Error Control
- IISP
- Interim Interface Signaling Protocol
- IP
- Internet Protocol
- ITU
- International Telecommunication Union
- LAN
- Local Area Network
- LGN
- Logical Group Node
- MUX
- Multiplexer
- NNI
- Network‐to‐Network Interface
- nrt‐VBR
- non‐real‐time Variable Bit Rate
- PG
- Peer Group
- PGL
- Peer Group Leader
- PMD
- Physical‐Medium‐Dependent Sublayer
- PNNI
Private Network–Node Interface
Private Network‐to‐Network Interface
- PSTN
- Public Switched Telephone Network
- PT
- Payload Type
- PTSE
- PNNI Topology State Element
- PTSP
- PNNI Topology State Packet
- PVC
- Permanent Virtual Circuit
- QoS
- Quality of Service
- RCC
- Routing Control Channel
- rt‐VBR
- real‐time Variable Bit Rate
- SAR
- Segmentation and Reassembly Sublayer
- SONET
- Synchronous Optical Networking
- SVC
- Switched Virtual Circuit
- TC
- Transmission Coverage Sublayer
- TP
- Transmission Path
- UBR
- Unspecified Bit Rate
- UNI
- User‐to‐Network Interface
- UTP
- Unshielded Twisted Pair (cable)
- VBR
- Variable Bit Rate
- VC
- Virtual Circuit
- VCI
- Virtual Channel Identifier
- VP
- Virtual Path
- VPI
- Virtual Path Identifier
- WAN
- Wide Area Network
Questions
- Explain with a diagram how a multiplexer handles variable‐size packets and why it is not good for a network to have a mix of very small as well as very large packets.
- State the difference between the UNI header and the NNI header.
- Explain all the fields in an NNI header, along with the number of bits occupied by each field.
- State the three different types of connection channel in ATM and explain their relation with an example.
- Describe the three‐layered ATM architecture. Also mention the sublayers within each layer.
- Draw the structure of an ATM switching table and explain its entries.
- Distinguish between real‐time and non‐real time service categories.
- Explain the bandwidth distribution among the five service categories.
- What is the difference between a private network–node interface and a private network‐to‐network interface?
- Describe the hierarchical structure of peer groups in PNNI.
- What is a peer group and how is the peer group leader elected?
- Explain the following processes:
- link aggregation,
- node aggregation,
- crankback.
- Explain the process of source routing in PNNI.
- Differentiate between a group node and a logical group node.
- Starting from exchange of ‘hello packets’, explain the process of exchange of PTSEs among the nodes in a peer group.
- Why is ATM called a connection‐oriented protocol?
- How is QoS ensured in PNNI?
- 1024 bytes of data has to be sent across an ATM network. How many cells will be formed?
- State whether the following statements are true or false and give reasons for the answer:
- The size of an ATM cell is 48 bytes.
- In an ATM connection, the cells reach the destination in the same order in which they were transmitted.
- A permanent virtual circuit between endpoints can be set up only through the service provider.
- Two different virtual circuits in an ATM network cannot have the same VCI.
- Segmentation and reassembly (SAR) is a sublayer of AAL.
- Transmission convergence is a sublayer of the ATM layer.
- Video conference can be done on an ATM network with ‘available bit rate’.
- A peer group can generally have only one peer group leader.
- There can be multiple border nodes in a peer group.
- Two different peer groups in the same hierarchical level exchange PTSEs with each other through the border nodes.
- For the following, mark all options that are correct:
- The size of an ATM cell is:
- 5 bytes,
- 48 bytes,
- 53 bytes,
- 1024 bytes.
- The interface between ATM switches is called:
- the switch‐to‐switch interface,
- the logical link interface,
- the network‐to‐network interface,
- the user‐to‐network interface.
- The virtual path identifier in UNI is:
- 4 bits,
- 8 bits,
- 12 bits,
- 16 bits.
- Which field is not present in the ATM cell header for NNI?
- header error control,
- cell loss priority,
- payload type,
- generic flow control.
- Which is not a type of connection in ATM?
- transmission path,
- virtual path,
- virtual circuit,
- virtual channel.
- The real‐time services are:
- ABR,
- CBR,
- rt‐VBR,
- UBR.
- PNNI stands for:
- private network–node interface,
- private node‐to‐node interface,
- private network‐to‐network interface,
- private non‐network interface.
- The size of an ATM cell is:
Exercises
- 100 MB has to be transmitted between two computers connected over ATM. How many cells will be created? How many bytes will remain unutilized in the last cell?
- Please refer to Figure 8.1. What will be the output of the multiplexer for each of these rules implemented on the multiplexer: ‘last in first out’, ‘shortest job first’, ‘longest job first’? What will be the output of the multiplexer in Figure 8.2 if it follows ‘last in first out’?
- Please refer to Figure 8.3. Node 2, node 3, node 4, node 5, node 6, node 7, and node 8 have to transmit data to node 1 using ATM. How many virtual circuits and virtual paths will be formed?
- Please refer to Figure 8.3. Node 1 wants to communicate with node 5. Write down the contents of the ATM cell header for user network interfaces and network node interfaces. Necessary assumptions may be made.
- Please refer to the network transmission scenario as mentioned in exercise 3 above. Draw the switching tables with the entries for all the ATM switches in the network.
- Please refer to Figure 8.3. Node 1 wants to communicate with node 5. Mention the layers of the ATM protocol stack that will operate from source to destination between the various devices and endpoints in the connection.
- Consider the network given below. Organize the network in hierarchy for PNNI routing by taking four nodes (in ascending order of node identifier number) in the peer group at the lowermost hierarchy level. The peer group finally constructed may have less than four nodes.

- How many levels of hierarchy are created?
- How many border nodes are there?
- Indicate the route of connectivity between node 1 and node 10 with all the intermediate peer groups in‐between.
- If logical links are created between various peer groups, how many logical links will be created and what will be the number of links aggregated for each of these logical links?
- What will be the levels of hierarchy if each peer group has six nodes?