
Chapter 6 Data Storage
Remy Sharp
STORING DATA ASSOCIATED with an application is fundamental in nearly all applications, web or desktop. This can include storing a unique key to track page impression, saving usernames, preferences, and so on. The list is endless.
Up until now, storing data in a web app required you either to store it on the server side and create some linking key between the client and the server—which means your data is split between locations—or it would be stored in cookies.
Cookies suck. Not the edible ones, the ones in the browser. They’re rubbish. There’s a number of issues with cookies that make working with them a pain. On starting any new project that requires cookies, I’ll immediately go hunting for my cookie JavaScript library. If I can’t find that, I’ll head over to Google to find Peter-Paul Koch’s cookie code, and copy and paste away.
![]() NOTE Peter-Paul Koch’s cookie code: http://www.quirksmode.org/js/cookies.html
NOTE Peter-Paul Koch’s cookie code: http://www.quirksmode.org/js/cookies.html
![]() NOTE The only saving grace of cookies, and what makes them work, is the fact that they’re shared with the server via a request header. This can be used to help prevent security exploits; otherwise, in most cases, I’ve found web storage kicks a cookie’s butt!
NOTE The only saving grace of cookies, and what makes them work, is the fact that they’re shared with the server via a request header. This can be used to help prevent security exploits; otherwise, in most cases, I’ve found web storage kicks a cookie’s butt!
Looking at how cookies work, they’re overly complicated. Setting a cookie in JavaScript looks like this:
document.cookie = "foo=bar; path=/";
That’s a session-based cookie. Now, if I want to store something for longer, I’ll have to set it in the future, and give it a specific lifetime (and if I want it to persist, I’ll have to keep setting this to be n days in the future):
document.cookie = "foo=bar; path=/; expires=Tues,
¬ 13 Sept 2010 12:00:00";
The time format is important too, which only causes more headaches. Now, the icing on the horrible-tasting cookie: To delete a cookie, I need to set the value to blank:
document.cookie = "foo=; path=/";
In fact, the cookie isn’t really deleted, it’s just had the value changed and had the expiry set to a session, so when the browser is shut down. Delete should really mean delete.
Cookies don’t work because they’re a headache. The new storage specifications completely circumvent this approach to setting, getting, and removing data by offering a clean API.
Storage Options
There are two options when it comes to storing data on the client side:
• Web Storage—supported in all the latest browsers
• Web SQL Databases—supported in Opera, Chrome, and Safari
Conveniently, Web SQL Databases is so named to instantly give you a clue as to how it works: It uses SQL-based syntax to query a local database.
Web Storage is a much simpler system in which you simply associate a key with a value. No learning SQL required. In fact, support for the Web Storage API is much better than for Web SQL Databases. I’ll look at both of these APIs, how they work, and how to debug data in each system.
As a guidance for space, Web Storage typically has a limit of 5Mb (but Safari, for instance, will prompt users if more than 5Mb is used, and ask whether they want to allow the website to go beyond the current default).
On the other side of the fence, the Web SQL Databases specification doesn’t talk about limits, and it’s up to the author to try to gauge an idea of the total size of the database when it’s created.
In both cases, the browser will throw an error if the API wasn’t able to write the data, but I’ll focus on smaller applications where the data stored is around the 100Kb mark.
Web Storage
In a nutshell, the Web Storage API is cookies on steroids. One key advantage of this API is that it splits session data and longterm data properly. For contrast, if you set a “session” cookie (that is, one without expiry data), that data item is available in all windows that have access to that domain until the browser is shut down. This is a good thing, because the session should last the time the window is open, not the browser’s lifetime. The storage API offers two types of storage: sessionStorage and localStorage.
![]() NOTE Cookies on steroids vs. regular cookies: IE6 supports only 20 cookies per domain and a maximum size of 4K per cookie. Web Storage doesn’t have a maximum number of items that can be stored per domain, and it limits the aggregate size to upwards of 5Mb.
NOTE Cookies on steroids vs. regular cookies: IE6 supports only 20 cookies per domain and a maximum size of 4K per cookie. Web Storage doesn’t have a maximum number of items that can be stored per domain, and it limits the aggregate size to upwards of 5Mb.
If you create data in sessionStorage, it’s available only to that window until the window is closed (for example, when the session has ended). If you opened another window on the same domain, it wouldn’t have access to that session data. This is useful to keep a shopping session within one window, whereas cookies would let the session “leak” from one window to another, possibly causing the visitor to put through an accidental additional transaction.
localStorage is based around the domain and spans all windows that are open on that domain. If you set some data on local storage it immediately becomes available on any other window on the same domain, but also remains available until it is explicitly deleted either by you as the web author or by the user. Otherwise, you can close your browser, reboot your machine, come back to it days later, and the data will still be there. Persistent data without the hassle of cookies: having to reset the expiry again and again.
An Overview of the API
Since both the sessionStorage and localStorage descend from the Web Storage API, they both have the exact same API (from the specification):
readonly attribute unsigned long length;
getter DOMString key(in unsigned long index);
getter any getItem(in DOMString key);
setter creator void setItem(in DOMString key, in any data);
deleter void removeItem(in DOMString key);
void clear();
This API makes setting and getting data very easy. The setItem method simply takes a key and a value. The getItem method takes the key of data you want and returns the content, as shown here:
sessionStorage. setItem ('twitter', '@rem'),
alert( sessionStorage. getItem ('twitter') ); // shows @rem
It’s worth noting that in all the latest browsers the getItem doesn’t return “any” data type. The browsers convert the data type to a string regardless of what’s going in. This is important because it means if you try to store an object, it actually stores “[Object object]”. More importantly, this means numbers being stored are actually being converted to strings, which can cause errors in development.
To highlight the possible problems, here’s an example: Let’s say that Bruce runs a website selling videos of himself parading as a professor of science. You’ve added a few of these videos to your shopping basket because you’re keen to learn more about “synergies.” The total cost of your shopping basket is $12, and this cost is stored in sessionStorage. When you come to the checkout page, Bruce has to add $5 in shipping costs. At an earlier point during your application, $12 was stored in sessionStorage. This is what your (contrived) code would look like:
sessionStorage.setItem('cost', 12);
// once shipping is added, Bruce's site tells you the total
¬ cost:
function costWithShipping(shipping) {
alert(sessionStorage.getItem('cost') + shipping);
}
// then it shows you the cost of the basket plus shipping:
costWithShipping(5);
![]() NOTE Where the specification said we could store “any data,” we can actually store only
NOTE Where the specification said we could store “any data,” we can actually store only DOMString data.
If sessionStorage had stored the value as a number, you would see an alert box showing 17. Instead, the cost of $12 was saved as a string. Because JavaScript uses the same method for concatenation as it does for addition (for example, the plus symbol), JavaScript sees this as appending a number to a string—so the alert box actually shows 125—much more than you’d probably be willing to pay to watch any video of Bruce! What’s going on here is type coercion, whereby upon storing the data in the storage API, the data type is coerced into a string.
With this in mind, the API is (currently) actually:
readonly attribute unsigned long length;
getter DOMString key(in unsigned long index);
getter DOMString getItem(in DOMString key);
setter creator void setItem(in DOMString key, in DOMString
¬ data);
deleter void removeItem(in DOMString key);
void clear();
Finally, it’s worth noting that if the key doesn’t exist when you call getItem, the storage API will return null. If you’re planning on using the storage API to initialise values, which is quite possible, you need to test for null before proceeding because it can throw a pretty nasty spanner in the works if you try to treat null as any other type of object.
Ways to Access Storage
As we’ve already seen, we can use setItem and getItem to store and retrieve, respectively, but there are a few other methods to access and manipulate the data being stored in the storage object.
Using Expandos
Expandos are a short and expressive way of setting and getting data out of the storage object, and as both sessionStorage and localStorage descend from the Web Storage API, they both support setting values directly off the storage object.
Using our example of storing a Twitter screen name, we can do the same thing using expandos:
sessionStorage.twitter = '@rem';
alert( sessionStorage.twitter ); // shows @rem
Unfortunately the expando method of storing values also suffers from the “stringifying” of values as we saw in the previous example, with Bruce’s video website.
Using the Key Method
The API also provides the key method, which takes an index parameter and returns the key associated. This method is useful to enumerate the data stored in the storage object. For example, if you wanted to show all the keys and associated data, you wouldn’t particularly know what the keys were for each of the data items, so loop through the length of the storage object and use the key method to find out:
for (var i = 0; i < sessionStorage.length; i++) {
alert( sessionStorage.key(i) + '=' +
¬ sessionStorage.getItem( sessionStorage.key(i) ) );
}
Another word of warning: It’s conceivable that you might be storing some value under the name of “key,” so you might write some code like the following:
sessionStorage.setItem('key',
¬ '27152949302e3bd0d681a6f0548912b9'),
Now there’s a value stored against the name “key,” and we already had a method called key on the storage object: Alarm bells are ringing, right?
Some browsers, WebKit specifically, overwrite the key method with your new value. The knock-on effect is the developer tools in WebKit make use of the key method to enumerate and display all the data associated with the storage object—so the “Storage” view for that storage type (sessionStorage, in our example) will now be broken until that value has been removed.
![]() NOTE I expect that as the browsers continue to develop, this kind of bug will be crushed—but in the meantime I’d say do your very best to avoid using names that already exist on the storage API.
NOTE I expect that as the browsers continue to develop, this kind of bug will be crushed—but in the meantime I’d say do your very best to avoid using names that already exist on the storage API.
Other browsers such as Firefox will keep the key method and your key value stored separately. Using the expando syntax will give you the method, and using getItem(‘key’) will give you the value.
Removing Data
There are two ways to remove data from the storage object programmatically: removeItem and clear. The removeItem method takes a key, the same key used in setItem and getItem, and deletes the entry for that particular item.
Using clear removes all entries, clearing the entire storage object. For example:
sessionStorage.setItem('bruce', "Think he's a professor of
¬ synergies");
sessionStorage.setItem('remy', "Think Bruce is a loony
¬ professor of synergies");
alert( sessionStorage.length ); // shows 2
sessionStorage.removeItem('bruce'),
alert( sessionStorage.length ); // show 1
sessionStorage.clear();
alert( sessionStorage.length ); // shows 0
Storing More Than Strings
You can work around the “stringifying” of objects by making use of JSON. Since JSON uses text to represent a JavaScript object, we can use this to store objects and convert stored data back into objects, but it’s really a wrapper for this bug. It depends whether the browsers intend to support the any data storage eventually, but this is easy to test for. However, it would require putting a wrapper on the set and get methods, which (depending on your application) may or may not be an option.
![]() NOTE JSON (JavaScript Object Notation) is a text based open standard for representing data. The specification found at http://json.org is so simple it actually fits on the back of a business card!
NOTE JSON (JavaScript Object Notation) is a text based open standard for representing data. The specification found at http://json.org is so simple it actually fits on the back of a business card!
All the latest browsers (either nightly or final releases) support native JSON encoding using the JSON.parse and JSON.stringify methods. For those browsers that don’t have JSON support, we can include Douglas Crockford’s JSON library (available at http://www.json.org/json2.js).
Now you can wrap setItem and getItem as follows:

As I stated in the API overview section, if the key doesn’t exist in the storage object, then it will return null. This isn’t a problem for the native JSON parsers as JSON.parse(null) returns null—as you would expect. However, for Douglas Crockford’s JavaScript version, passing null will throw an error. So if you know it’s possible that Douglas’ JSON JavaScript library is being loaded, protect against this error by using the following:
var videoDetails = JSON.parse(sessionStorage.getItem
¬ ('videoDetails') || 'null'),
This ensures that if null is returned from the getItem method, you pass in a JSON-encoded version of null, and thus the JavaScript based JSON parser won’t break.
Using Debugging Tools
Although there’s good support for the Web Storage API, the debuggers are still maturing. So aside from introspecting the sessionStorage or the localStorage there’s not too many tools available.
Webkit’s Developer Tools
Whilst I refer to WebKit, in this section I’m covering Safari, the nightly build of Safari (WebKit), and Google Chrome. WebKit’s developer tool allows us to view the localStorage and sessionStorage values stored as shown in Figure 6.1. From here you can modify keys and values and delete entries.
![]() NOTE To enable the Developer menu in Safari, go to Preferences and from the Advanced tab, check the Show Developer Menu in Menu Bar box.
NOTE To enable the Developer menu in Safari, go to Preferences and from the Advanced tab, check the Show Developer Menu in Menu Bar box.
FIGURE 6.1 WebKit’s storage debugger.

Firefox’s Firebug
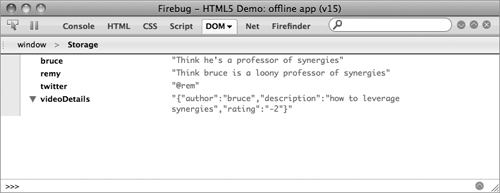
Using the Firebug plugin for Firefox you can easily introspect the storage objects. If you enter “sessionStorage” or “localStorage” in the console command and execute the code, the storage object can now be clicked on and its details can be seen (Figure 6.2).
FIGURE 6.2 Firebug’s storage introspector.
Opera’s Dragonfly
DragonFly comes shipped with Opera, and from the Storage tab you can access all the data stored in association with the current page. In particular, there are separate tabs for Local Storage and Session Storage to inspect all the data linked with those data stores (Figure 6.3).
FIGURE 6.3 Opera’s DragonFly debugger to inspect storage.

Fallback Options
As the storage API is relatively simple, it’s possible to replicate its functionality using JavaScript, which could be useful if the storage API isn’t available.
For localStorage, you could use cookies. For sessionStorage, you can use a hack that makes use of the name property on the window object. The following listing shows how you could replicate sessionStorage functionality (and ensure the data remains locked to the current window, rather than leaking as cookies would) by manually implementing each of the Storage API methods. Note that the following code expects that you have JSON support in the browser, either natively or by loading Douglas Crockford’s library.

The problem with implementing sessionStorage manually (as shown in the previous code listing) is that you wouldn’t be able to write sessionStorage.twitter = ‘@rem’. Although technically, the code would work, it wouldn’t be registered in our storage object properly and sessionStorage.getItem(‘twitter’) wouldn’t yield a result.
With this in mind, and depending on what browsers you are targeting (that is, whether you would need to provide a manual fall-back to storage), you may want to ensure you agree within your development team whether you use getItem and setItem.
Web SQL Databases
![]() NOTE Mozilla and Microsoft are hesitant about implementing SQL database support. Mozilla is looking at a specification called Indexed Database API which is only in early betas of Firefox 4 and is beyond the scope of this chapter. But it’s worth keeping an eye on it in the future.
NOTE Mozilla and Microsoft are hesitant about implementing SQL database support. Mozilla is looking at a specification called Indexed Database API which is only in early betas of Firefox 4 and is beyond the scope of this chapter. But it’s worth keeping an eye on it in the future.
Web SQL Databases are another way to store and access data. As the name implies, this is a real database that you are able to query and join results. If you’re familiar with SQL, then you should be like a duck to water with the database API. That said, if you’re not familiar with SQL, SQLite in particular, I’m not going to teach it in this chapter: There are bigger and uglier books that can do that, and the SQLite website is a resource at http://sqlite.org.
The specification is a little bit grey around the size limits of these databases. When you create a new database, you, the author, get to suggest its estimated maximum size. So I could estimate 2Mb or I could estimate 20Mb. If you try to create a database larger than the default storage size in Safari, it prompts the user to allow the database to go over the default database size. Both Opera and Google Chrome simply allow the database to be created, regardless of the size. I strongly suggest that you err on the side of caution with database sizes. Generally, browsers are limiting, by default, databases to 5Mb per domain. Now that you’re suitably worried about SQL and database sizes, one really neat feature of the Web SQL Databases API is that all the methods allow you to pass a callback that will be executed once the fandango SQL magic has completed. Callbacks are a common trait of JavaScript libraries such as jQuery. If you’re not familiar with this syntax, it looks something like what follows (but don’t worry, I’ll hold your hand throughout the examples later on):
transaction.executeSql(sql, [], function () {
// my executed code lives here
});
Due to the nature of the callback system, it also means that the database API is asynchronous. This means you need to be careful when authoring the JavaScript to deal with the database to ensure that the sequence of events runs correctly. However, the SQL statements are queued and run in order, so this is one slight advantage you have over processing order: You can create tables and know that the table will be in place before you run queries on the tables.
Put plainly, if you want your code to run after the database interaction has completed, use the callback. If you don’t need to wait, and you want your code to continue regardless, continue after the database API call.
Using the Web SQL Database API
The typical database API usage involves opening the database and then executing some SQL. Note that if I were working with a database on the server side, I would typically close the database connection. This isn’t required with the database API, and in fact there’s no method to do this at all. That all said, you can open a database multiple times.
Opening and Creating Databases
By opening a database for the first time, the database is created. You can only have one version of your named database on the domain at any one time, so if you create version 1.0 you can’t then open 1.1 without the database version having been specifically changed by your application. For the rest of this chapter, I’m going to ignore versioning and stick to one version only due to the previously stated warning.
var db = openDatabase('mydb', '1.0', 'My first database',
¬ 2 * 1024 * 1024);
The latest version of the SQL databases spec includes a fifth argument to openDatabase, but this isn’t supported in any of the browsers right now. It offers a callback when the database is created for the first time. You’ve now created a new database called “mydb,” version 1.0, with a text description of “My first database,” and you’ve set the size of the data to 2Mb (this has to be set in bytes which is why I multiply 2 * 1024 * 1024). To ensure our app works and detects support for the Web SQL database API, you should also test for database support in the browser, so you wrap our code with the openDatabase test:
var db;
if (window.openDatabase) {
db = openDatabase('mydb', '1.0', 'My first database',
¬ 2 * 1024 * 1024);
}
It’s as simple at that. The next thing to do is set up a new table in the database, which will go through the exact same methods as selecting and updating tables: via executeSql.
Creating Tables
With creating tables (and any other transaction on the database), you must start a database “transaction” and, within the callback, create the table. The transaction callback receives an argument containing the transaction object, which is the thing that allows you to run SQL statements and run the executeSql method (tx in the following example). This is done using the database object that was returned from openDatabase and calling the transaction method as so:
var db;
if (window.openDatabase) {
db = openDatabase('tweetdb', '1.0', 'All my tweets',
¬ 2 * 1024 * 1024);
db.transaction(function (tx) {
tx.executeSql('CREATE TABLE tweets (id, date, tweet)'),
});
}
The executeSql method takes four arguments, of which only the first is required:
- SQL
- Arguments to SQL (such as field values)
- Success callback
- Error callback
In the previous example, you only use the SQL parameter. Of course if the statement to create a table runs and our table already exists there’s actually an error being triggered, but since you’re not catching it and it doesn’t affect our program flow, in this instance you don’t care.
However, the next step of this application is to load the database with tweets from Twitter, and this has to happen once the table is in place (because of the asynchronous nature of the Web SQL Database API), you’ll have to get the tweets in the complete callback. Herein lies a problem: If the table exists, the transaction will fail and won’t trigger the success callback. The code will run fine the first time around, but not the second. So to get around this, you’ll say to only create the table if the table doesn’t exist; this way the success callback fires if the table is created and if the table already exists, and the error callback is only called if there’s some other problem.
var db;
if (window.openDatabase) {
db = openDatabase('tweetdb', '1.0', 'All my tweets',
¬ 2 * 1024 * 1024);
db.transaction(function (tx) {
tx.executeSql('CREATE TABLE IF NOT EXISTS tweets
¬ (id, date, tweet)', [], function () {
// now go and load the table up with tweets
});
});
}
Inserting and Querying
Now let’s say you hit Twitter for a search query for all the mentions of HTML5, you store all those tweets in your database, then you allow the user to select the time range of tweets from the past 5 minutes, 30 minutes, 2 hours, and then all time. The time range selection will be radio buttons with click handlers, and you’ll run your query to show only the tweets from that time range.
The crux of this application is split between storing the tweets in your database and showing the tweets depending on the time range.
Before any of your code runs, first you must create the database and tweets table, which will include a date column whose type is integer—which is important to allow you to query the database later on in your application:
function setupDatabase() {
db = openDatabase('tweets', '1.0', 'db of tweets',
¬ 2 * 1024 * 1024);
db.transaction(function (tx) {
tx.executeSql('CREATE TABLE tweets (id unique,
¬ screen_name, date integer, text)'),
});
getTweets();
}
A few things to note about the code are:
- I’m using a global
dbvariable. (I’m just using a global for the contrived example; global is generally bad in JavaScript.) - I’m telling the tweets database that the
idcolumn is unique. This means if there’s a duplicateINSERTattempt, theINSERTfails. - If the
CREATE TABLEfails, it’s fine because it will only fail because the table already exists, and you’re not doing anything else in that transaction. - Once it’s done, I call
getTweets, which will make the API request to Twitter, which will in turn call the storing function.
![]() NOTE You’re creating a new transaction for each stored tweet, I’ll explain transactions in more detail in the next section, but by wrapping individual
NOTE You’re creating a new transaction for each stored tweet, I’ll explain transactions in more detail in the next section, but by wrapping individual INSERT statements you’re ensuring that all the new tweets are stored, irrespective of whether you already have these in the database.
The forEach method in the following code is a new JavaScript method available in all the latest browsers, allowing you to loop through an array. Mozilla’s site provides simple code for implementing this in browsers that don’t have it natively: https://developer.mozilla.org/en/Core_JavaScript_1.5_Reference/Global_Objects/Array/forEach. Once the Twitter API call completes it will call saveTweets, which will do the storing of each of the tweets:

The INSERT statement is the most important part, and now you can see how the field arguments work:
tx.executeSql('INSERT INTO tweets (id, screen_name, date,
¬ text) VALUES (?, ?, ?, ?)', [tweet.id, tweet.from_user,
¬ time / 1000, tweet.text]);
Each “?” in the INSERT statement maps to an item in the array that is passed in as the second parameter to executeSql. So the first “?” maps to tweet.id, the second to tweet.from_user, and so on.
You can also see that I’ve divided the time by 1000; this is because JavaScript time goes to milliseconds, whereas SQLite doesn’t. SQLite goes down to whole seconds. This is only important for your query later on in the code where you show tweets that are 5 minutes old. This matters because you’re storing dates as integers, and one second using JavaScript’s getTime method gives us 1000, whereas one second using SQLite gives us 1. So you divide by 1000 to store seconds rather than milliseconds.
Finally, when the radio buttons are clicked, you call the show function with the amount of time as the argument:

On initial review this code may look complicated, but there are actually only a couple of things happening here:
- Start a new transaction
- Run a single SQL statement, whose structure is determined by whether you want “all” or not
- Loop through the results constructing the HTML, and then set it to the
tweetEl(a<ul>element)innerHTML
There’s two states the SQL query can be, either:
SELECT * FROM tweets
or
SELECT * FROM tweets WHERE date > strftime("%s", "now",
¬ "-5 minutes")
Where I’ve put -5 minutes, this can change to -30 minutes or any number that’s passed in to the show function. The strftime SQLite function is generating the number of seconds from 1-Jan-1970 until “now” minus N minutes. Since the “date” field is being stored as an integer, you’re now able to grab all the rows that were tweeted within the last N minutes.
Now you’ve used the third argument to the executeSql method, the success callback. The success callback receives a transaction object (just as the transaction callback does so you could run another executeSql if you wanted), and more importantly, the result set. The result set contains three attributes:
insertId(set only if you’ve inserted a row or rows)—I didn’t use this in this example.rowsAffected—Since this is a SELECT statement, this value is 0.rows—This isn’t an array, it’s a collection, that does contain a length and item getter method. You make use of the rows object, and run aforloop from 0 to the length of the rows, and useresults.rows.item(i)to get the individual rows. The individual row is an object representing the different column names, soresults.rows.item(0).screen_namegives us thescreen_namefield from the first row.
Finally, once you have looped through all the rows that match, you can set a <ul> element to the HTML you’ve built up. In this example, the <ul> is stored in the variable called tweetEl.
Here is the complete code listing, which includes the database support detection and the click handler code for the radio buttons:




Creating Transactions—and What They’re Good For
I’ve skipped over transactions so far. They’re more than meets the eye. They’re not just the way to run queries; they serve a particularly useful purpose. Transactions are like closed environments in which you can run your queries. You can run just one query or a group of queries within a transaction. In fact, you can’t run a query without being inside a transaction, since the executeSql method is only available from the SQLTransaction object.
Possibly the most important aspect of the transactions is this: If something fails inside the transaction (vanilla code or SQL statements), then the whole transaction is rolled back. This means it’s as if the whole transaction block of code never happened.
The transaction method takes two arguments: The first is the contents of the transaction; the second, optional, is the error handler if it’s triggered. Below is a contrived example that shows you how a transaction will rollback your failed transaction:

What you’re doing in the previous code is:
- Start a transaction that creates the table foo and then inserts a single row
- Start a transaction that drops the table foo and then incorrectly tries to insert a new row in foo
- This transaction will fail, and rollback the statements (that is, it’s as if step 2 never happened)
- Start a transaction that selects all the rows from foo and alerts the number of rows
- The SQL query succeeds and shows “found 1 row”
Transactions are used to ensure an atomic block of queries execute and if any part fails, it rolls back.
Summary
In this chapter, you learned about two different APIs for storing data locally in the browser that beats the pants off using cookies (and there’s more storage specs in the works with Indexed Database API).
These storage APIs allow you to store a lot more data than the traditional cookie and make the associated programming a lot easier than before. On top of which, the Web Storage API has really good support in all the latest browsers (and older browsers can be supported using JavaScript), so it means you can drop the awful and stale cookies of today!