
3.3.8 Model-Based Predictive Control
Model-based predictive control (MPC) approaches are advanced methods that can be applied to various areas as well as to mobile robotics were reference trajectory is known beforehand. The use of predictive control approaches in mobile robotics usually relies on a linearized (or also nonlinear) kinematic model or dynamic model to predict future system states. A number of successful implementations to wheeled robotics have been reported such as generalized predictive control in [18], predictive control with Smith predictor to handle the system’s time delay in [19], MPC based on a linear, time-varying system description in [20], nonlinear predictive controller with a multilayer neural network as a system model in [21], and many others. In most approaches the control law solutions are solved by an optimization of a cost function. Other approaches obtain control law as an analytical solution, which is computationally effective and can be easily used in fast, real-time implementations [22].
This section deals with a differentially driven mobile robot and trajectory-tracking control. Reference trajectory needs to be a smooth twice-differentiable function of time. For prediction, a linearized error dynamics model obtained around the reference trajectory is used. The controller minimizes the difference between the robot future tracking error and the reference error with defined desired dynamics.
Model-based control strategies combine a feedforward solution and a feedback action in input vector u, given as follows:

where the feedforward input vector ![]() is calculated from the reference trajectory using relations (3.22), (3.23). The feedback input vector is ufb = [vfbωfb]T, which is the output of the MPC controller.
is calculated from the reference trajectory using relations (3.22), (3.23). The feedback input vector is ufb = [vfbωfb]T, which is the output of the MPC controller.
The control problem is given by the linear tracking error dynamics model (3.39), which in shorter notation reads
where Ac(t) and Bc are matrices of the continuous state-space model and e is the tracking error defined in local robot coordinates, defined by transformation (3.35) and shown in Fig. 3.21.
Discrete MPC
The MPC approach presented in [22] is summarized. It is designed for discrete time; therefore, model (3.86) needs to be written in discrete-time form:
where ![]() , n is the number of the state variables and
, n is the number of the state variables and ![]() , and m is the number of input variables. The discrete matrices A(k) and B can be obtained as follows:
, and m is the number of input variables. The discrete matrices A(k) and B can be obtained as follows:

which is sufficient approximation for a short sampling time Ts.
The main idea of MPC is to compute optimal control actions that minimize the objective function given in prediction horizon interval h. The objective function is a quadratic cost function:

consisting of a future reference tracking error er(k + i), predicted tracking error e(k + i|k), difference between the two errors ϵ(k, i) =er(k + i) −e(k + i|k), and future actions ufb(k + i − 1), where i denotes the ith step-ahead prediction (i = 1, …, h). Q and R are the weighting matrices.
For prediction of the state e(k + i|k) the error model (3.87) is applied as follows:

Predictions e(k + i|k) in Eq. (3.90) are rearranged so that they are dependent on current error e(k), current and future inputs ufb(k + i − 1), and matrices A(k + i − 1) and B. The model-output prediction at the time instant h can then be written as

The future reference error (er(k + i)) defines how the tracking error should decrease when the robot is not on the trajectory. Let us define the future reference error to decrease exponentially from the current tracking error e(k), as follows:
for ![]() . The dynamics of the reference error is defined by the reference model matrix Ar.
. The dynamics of the reference error is defined by the reference model matrix Ar.
According to Eqs. (3.90), (3.91) the robot-tracking prediction-error vector is defined as follows:
where E* is given for the whole interval of the observation (h) where the control vector is
and
The robot-tracking prediction-error vector can be written in compact form:
where
and

where dimensions of F(k) and G(k) are (n ⋅ h × n) and (n ⋅ h × m ⋅ h), respectively.
The robot reference-tracking-error vector is
which in compact form is computed as
where
where Fr is the (n ⋅ h × n) matrix.
The optimal control vector (3.93) is obtained by optimization of Eq. (3.89), which can be done numerically or analytically. The analytical solution is derived in the following.
The objective function (3.89) defined in matrix form reads.
The minimum of Eq. (3.99) is expressed as
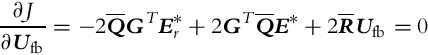
and the solution for the optimal control vector is obtained as
where the weighting matrices are as follows:

and

Solution (3.101) contains control vectors ufbT(k + i − 1) for the whole interval of prediction (i = 1, …, h). To apply feedback control action in the current time instant k only the first vector ufbT(k) (first m rows of Ufb(k)) is applied to the robot. The solution is obtained analytically; therefore, it enables fast real-time implementations that may not be possible if numeric optimization of Eq. (3.89) is used.
Example 3.13
Implement model predictive control given in Eq. (3.101) for trajectory tracking of a differential-drive robot. Reference trajectory and robot are defined in Example 3.9.
The choice for prediction horizon is h = 4, the reference model matrix is Ar = I3×3 ⋅ 0.65, and the weighting matrices are

Solution
Using MPC compute the feedback part of control signal ufb(k) and apply it to the robot together with the feedforward part uff(k). In the following Matlab script (Listing 3.12), possible solution and trajectory tracking results are given. Obtained simulation results are shown in Figs. 3.30 and 3.31.


3.3.9 Particle Swarm Optimization-Based Control
Control of a mobile robot can also be defined as an optimization problem where the best solution among all possible solutions in a search space needs to be found in each control-loop sample time. The obtained control does not have an explicit structure, meaning that the control law cannot be given as a mapping function from system states to control actions. An optimal solution that minimizes some objective function is instead found by an iterative optimization algorithm like Newton methods, gradient descent methods, or stochastic methods such as genetic algorithms, particle swarm optimization (PSO), and the like.
If the objective function is not convex in the minimization problem then most optimization algorithms can be trapped in a local minimum, which is not the optimal solution. Using stochastic optimization the likelihood of local minimum, the solution is usually smaller because the search pattern is randomized to some extent.
PSO is inspired by social behavior of small animals such as bird flocks or fish schools [23, 24]. PSO uses a group (swarm) of particles where each particle presents its own solution hypothesis. Each particle i is characterized by parameter vector xi defining its position in the parameter space and increment vector vi defining velocity in the parameter space. During optimization the population of all candidate solutions are updated according to the objective function that defines a measure of quality. Each particle keeps track of its parameters and remembers the best parameters pBesti achieved so far together with the associated objective function Ji = f(pBesti). During optimization also the best parameter vector obtained so far for the entire swarm gBest is stored. In local version of PSO for each particle the best parameter vector gBesti is tracked for some neighborhood of particles (e.g., k nearest particles, ring topology, and the like [25]). Local versions of PSO are less likely to be trapped in a local minimum.
Next, a basic (global) version of PSO is explained. In each control-loop iteration particles update mimic cognitive and social behavior by means of the following rules:

where ω is the inertia factor, c1 is the self-cognitive constant, and c2 is the social constant. In addition rand(0, 1) is a vector of uniformly distributed values in the range (0, 1). The dimensions of vectors in Eq. (3.104) equal the dimension of the parameter search space. The parameters ω, c1, and c2 are positive tuning parameters. Basic PSO code is given in Algorithm 1.
Example 3.14
Write the controller using the PSO for the robot and trajectory defined in Example 3.9. PSO is applied in each sampling time t = kTs to find the best controls (translational and angular velocity) that would drive the robot as close as possible to the current reference position xref(t), yref(t). Next, the robot pose prediction is computed considering robot kinematics and the particles’ proposed solution (control action). Optimal control minimizes the cost function consisting of the tracking error ![]() and the feedback control effort
and the feedback control effort ![]() . This follows the equation J(t) = e(t)TQe(t) +ufbTRufb, where Q and R are diagonal weighting matrices used to tune the controller behavior.
. This follows the equation J(t) = e(t)TQe(t) +ufbTRufb, where Q and R are diagonal weighting matrices used to tune the controller behavior.
Solution
The control law includes feedforward action and feedback action similarly as in Example 3.9. Feedforward action is obtained from a known trajectory while the feedback action is computed using PSO. The tracking error is expressed in robot local coordinates (see Fig. 3.21) because this makes the optimization more efficient due to the closed-loop system being decoupled better. The error in the local x coordinate can simply be compensated by translational velocity, and errors in y and φ can be compensated by the angular velocity. However, this is not the case when using a global tracking error due to nonlinear rotation transformation in Eq. (3.35).
In Listing 3.13 a Matlab script of a possible solution is given. Obtained simulation results are shown in Figs. 3.32 and 3.33. Similar control results as in Example 3.13 are obtained. However, the computational effort is much higher than in Example 3.13. Results of Example 3.14 are not deterministic because PSO is using randomly distributed particles in optimization to find the best control in each sampling time. Therefore, resulting trajectories of the mobile robot can vary to some extent, especially the initial transition phase, until the robot reaches the reference. However, the obtained results in the majority of simulation runs are at least comparable to the results of other presented deterministic controllers (e.g., from Example 3.9).


Algorithm 1
Particle swarm optimization


PSO is a generic algorithm that can be applied to numerous applications as long as the computational effort and time required to find the solution meet the real time requirements of the system being controlled.
MPC With PSO
Solving optimization of objective function in MPC can also be done by PSO, where the best parameters (control actions) are searched for the prediction interval (t, t + hTS) where h is horizon. If a system has m = 2 control inputs then the optimization needs to find m ⋅ h optimal parameters, which may be computationally intense and therefore problematic for systems with short control-loop sampling times. However, there are some possibilities to lower the computational time as follows. One possibility is to assume constant controls in the prediction horizon. If the control action does not change significantly in a relatively short horizon time, then constant controls can be assumed in the horizon interval. This means that only m parameters instead of m ⋅ h need to be optimized. Another possibility is to lower the required iterations in optimization for each control-loop sampling time. This can be done by initializing the particles around the optimal solution from the previous time sample. Doing so, this would hopefully require less iterations for the particles to converge.
A possible solution of implementing MPC on PSO is given in Example 3.15.
Example 3.15
Extend Example 3.14 to a model-based predictive controller with prediction horizon h = 3.
Solution
The presented solution supposes that the control action (feedback part) in the prediction horizon interval is constant ufb(t + (i − 1)TS) =ufb. Feedforward action (uff) is obtained from known trajectory, while the feedback action is computed using PSO. From the current robot pose the h-step-ahead prediction is made using the robot kinematic model and control actions u(t + (i − 1)TS) =ufb +uff(t + (i − 1)TS) (i = 1, …, h) are obtained as follows:
where the initial state equals ![]() and i = 1, …, h. The control action is obtained by optimizing the cost function for the horizon period
and i = 1, …, h. The control action is obtained by optimizing the cost function for the horizon period

where e(⋅) is the tracking error in local coordinates. The optimal control action is calculated using PSO as is given in the Matlab script in Listing 3.14. Simulation results are shown in Figs. 3.34 and 3.35. A smaller tracking error and a better initial transition compared to the results in Example 3.14 are obtained.


3.3.10 Visual Servoing Approaches for Solving the Control Problems in Mobile Robotics
This part will present the use of visual servoing (VS) approaches for solving the control problems in mobile robotics. The main emphasis is on development of a mobile robotic system that is able to autonomously complete the desired task based only on visual information provided by a camera mounted on the mobile system.
In the field of VS the estimated signals obtained from images that are used in order to determine the control error are known as features. Features can be points, lines, circles, area of an object, angles between lines, or something else. The control error of a general VS control scheme can be written as a difference between the desired feature vector xref(t) and current feature vector x(y(t), ζ) [26]:
The K-element feature state vector ![]() in Eq. (3.105) is obtained based on image-based measurements y(t) (e.g., position, area, or shape of patterns in image) and some additional time-invariant knowledge about the system ζ (e.g., intrinsic camera parameters, known properties of the observed scene, system constraints). One of the crucial challenges in designing a visual control is the appropriate definition of feature vector, since this vector is used to determine control error. If the feature vector is not defined appropriately more than one situation may exist in which the control error is minimal—the problem of local minimums. Some features may only be appropriate for some classes of motions (e.g., only translations) and may be completely inappropriate for some other class of motions (e.g., translation with rotation). If the features are not selected carefully, in some situations undesired, unnecessary, or even unexpected control motions can occur—a problem also known as camera retreat. During visual servoing some tracked features may leave the camera field of view that may disable completion of the VS task. Therefore the visual control algorithm should prevent the features from leaving the camera’s field of view, use alternative features if some features are inevitably lost, or estimate locations of features that are temporarily outside of the field of view.
in Eq. (3.105) is obtained based on image-based measurements y(t) (e.g., position, area, or shape of patterns in image) and some additional time-invariant knowledge about the system ζ (e.g., intrinsic camera parameters, known properties of the observed scene, system constraints). One of the crucial challenges in designing a visual control is the appropriate definition of feature vector, since this vector is used to determine control error. If the feature vector is not defined appropriately more than one situation may exist in which the control error is minimal—the problem of local minimums. Some features may only be appropriate for some classes of motions (e.g., only translations) and may be completely inappropriate for some other class of motions (e.g., translation with rotation). If the features are not selected carefully, in some situations undesired, unnecessary, or even unexpected control motions can occur—a problem also known as camera retreat. During visual servoing some tracked features may leave the camera field of view that may disable completion of the VS task. Therefore the visual control algorithm should prevent the features from leaving the camera’s field of view, use alternative features if some features are inevitably lost, or estimate locations of features that are temporarily outside of the field of view.
According to the definition of the feature vector x, VS control approaches can be classified into three main categories [27]: position-based visual servoing (PBVS), image-based visual servoing (IBVS), and hybrid VS. In the case of PBVS the control error is defined as the error between the desired and current robot pose in the 3D task space. The camera in the PBVS control scheme is used in order to estimate the 3D positions of objects and robot in the environment from the image, which is a projection of the environment. Therefore all the control approaches that have already been presented in the rest of this chapter can be used directly in this class of control approaches. Normally with the PBVS approach optimum control actions can be achieved; however, the approach requires accurate camera calibration or else the true control error cannot be eliminated. On the other hand, the control error in the IBVS control scheme is defined directly in the 2D image space (e.g., as a difference between two image points). Since the control error is defined directly in image, IBVS is less susceptible to accuracy of camera calibration. However, IBVS normally achieves less optimum trajectories than can be achieved with PBVS approach, and the IBVS approach is more susceptible to the camera retreat problem if the image features are not chosen appropriately. IBVS approaches are especially interesting, since they enable in-image task definition and the control approach known as teach-by-showing. HVS approaches try to combine good properties of PBVS and IBVS control schemes. Some control schemes only switch between PBVS and IBVS controllers according to some switching criteria that selects the most appropriate control approach based on the current system states [28]. In some other hybrid approaches the control error is composed of features from 2D image space and features from 3D task space [29, 30]. Visual control of nonholonomic systems is considered a difficult problem [31–34]. Visual control schemes are sometimes used in combination with some additional sensors [35] that may provide additional data or ease image processing.
In [26, 36] the authors have presented the general control design approach that can be used regardless of the class of VS scheme. Let us consider the case where the reference feature state vector in Eq. (3.105) is time invariant (xref(t) =xref = const.). Commonly a velocity controller is used. The velocity control vector can be written as a combination of a translational velocity vector v(t) and an angular velocity vector ω(t) in a combined vector ![]() . In general the velocity vector and angular velocity vector of an object in a 3D space both consist of three velocities, that is, vT(t) = [vx(t), vy(t), vz(t)] and ωT(t) = [ωx(t), ωy(t), ωz(t)]. However, in the case of wheeled mobile robotics these two control vectors normally have some zero elements, since the mobile robot in normal driving conditions is assumed to move on a plane, and no tumbling or lifting is expected. The relation between the velocity control vector uT(t) and the rate of feature states
. In general the velocity vector and angular velocity vector of an object in a 3D space both consist of three velocities, that is, vT(t) = [vx(t), vy(t), vz(t)] and ωT(t) = [ωx(t), ωy(t), ωz(t)]. However, in the case of wheeled mobile robotics these two control vectors normally have some zero elements, since the mobile robot in normal driving conditions is assumed to move on a plane, and no tumbling or lifting is expected. The relation between the velocity control vector uT(t) and the rate of feature states ![]() can be written as follows:
can be written as follows:
where the matrix ![]() is known as the interaction matrix. From relations (3.105), (3.106) the rate of error can be determined:
is known as the interaction matrix. From relations (3.105), (3.106) the rate of error can be determined:
The control action u(t) should minimize the error e. If exponential decay of error e is desired in the form ![]() , g > 0, the following control law can be derived:
, g > 0, the following control law can be derived:
where L†(t) is the Moore-Penrose pseudoinverse of the interaction matrix L(t). If the matrix L(t) is of full rank, its pseudoinverse can be computed as L†(t) = (LT(t)L(t))−1LT(t). If the interaction matrix is of square shape (K = M) and it is not singular (![]() ), the calculation of pseudoinverse in Eq. (3.108) simplifies to the ordinary matrix inverse L−1(t).
), the calculation of pseudoinverse in Eq. (3.108) simplifies to the ordinary matrix inverse L−1(t).
In practice only an approximate value of the true interaction matrix can be obtained. Therefore in control scheme (3.108) only the interaction matrix estimate ![]() or estimate of the interaction matrix inverse
or estimate of the interaction matrix inverse ![]() can be used:
can be used:
The interaction matrix inverse estimate ![]() can be determined from linearization of the system around the current system state (
can be determined from linearization of the system around the current system state (![]() ) or around the desired (reference) system state (
) or around the desired (reference) system state (![]() ). Sometimes a combination in the form
). Sometimes a combination in the form ![]() is used [36].
is used [36].
If the control (3.109) is inserted into Eq. (3.107), the differential equation of the closed-loop system is obtained:
A Lyapunov function ![]() can be used to check stability of the closed-loop system (3.110). The derivative of the Lyapunov function is
can be used to check stability of the closed-loop system (3.110). The derivative of the Lyapunov function is
A sufficient condition for global stability of the system (3.110) is satisfied if the matrix ![]() is semipositive definite. In the case the number of observed features K equals to the number of control inputs M (i.e., K = M) and the matrices L(t) and
is semipositive definite. In the case the number of observed features K equals to the number of control inputs M (i.e., K = M) and the matrices L(t) and ![]() both have full rank; the closed-loop system (3.110) is stable if the estimate of the matrix
both have full rank; the closed-loop system (3.110) is stable if the estimate of the matrix ![]() is not too coarse [26]. However, it should be noted that in the case of IBVS it is not simple to select appropriate features in the image space that eliminate the desired control problem in the task space.
is not too coarse [26]. However, it should be noted that in the case of IBVS it is not simple to select appropriate features in the image space that eliminate the desired control problem in the task space.
Example 3.16
A camera, C, is mounted on the wheeled mobile robot R with differential drive at ![]() with orientation
with orientation ![]() Ry(−90 degree)Rx(45 degree). The intrinsic camera parameters are αxf = αyf = 300, no skewness (γ = 0), and the image center is in the middle of the image with a dimension of 1024 × 768. Design an IBVS control that drives the mobile robot from initial pose [x(0), y(0), φ(0)] = [1 m, 0, 100 degree] to the goal position xref = 4 m and yref = 4 m. For the sake of simplicity assume that the rotation center of the mobile robot is visible in the image.
Ry(−90 degree)Rx(45 degree). The intrinsic camera parameters are αxf = αyf = 300, no skewness (γ = 0), and the image center is in the middle of the image with a dimension of 1024 × 768. Design an IBVS control that drives the mobile robot from initial pose [x(0), y(0), φ(0)] = [1 m, 0, 100 degree] to the goal position xref = 4 m and yref = 4 m. For the sake of simplicity assume that the rotation center of the mobile robot is visible in the image.
Solution
The camera is observing the scene in front of the mobile robot. Since the camera is mounted without any roll around the optical axis center, a decoupled control can be designed directly based on image error between the observed goal position and image of the robot’s center of rotation. A possible implementation of the solution in Matlab is shown in Listing 3.15. The obtained path of the mobile robot is shown in Fig. 3.36 and the path of the observed goal in the image is shown in Fig. 3.37. The control signals are shown in Fig. 3.38. The results confirm the applicability of the IBVS control scheme. The robot reaches the goal pose, since the observed feature (goal) is visible during the entire time of VS (Fig. 3.37).



3.4 Optimal Velocity Profile Estimation for a Known Path
Wheeled mobile robots often need to drive on an existing predefined path (e.g., road or corridor) that is defined spatially by some schedule parameter u as xp(u), yp(u), u ∈ [uSP, uEP]. To drive the robot on this path a desired velocity profile needs to be planned. A velocity profile is important if the robot needs to arrive from some start point SP to some end point EP in the shortest time and to consider robot capabilities and the like. To drive the robot on such path its position therefore becomes dependent on time x(t), y(t), with defined velocity profile v(t), ω(t), as shown next.
Suppose there is the special case u = t; the reference path becomes a trajectory with an implicitly defined velocity profile. The robot therefore needs to drive on the trajectory with the reference velocities v(t) = vref(t) and ω(t) = ωref(t) calculated from the reference trajectory using relations (3.22), (3.23).
To plan the desired velocity profile for the spatially given path, one needs to find the schedule u = u(t). The planned velocity profile must be consistent with the robot constraints (maximum velocity and maximum acceleration that motors can produce and which assures safe driving without longitudinal and lateral slip of the wheels). Reference velocities are similar to those in Eqs. (3.22), (3.23) are expressed as follows:

and curvature is

where primes denote derivatives with respect to u, while dots denote derivatives with respect to t. Time derivatives of the path therefore consider the schedule u(t) as follows: ![]() ,
, ![]() .
.
The main idea of velocity profile planning is adopted from [37] and is as follows. For a given path a velocity profile is determined considering pure rolling conditions, meaning that command velocities are equal to the real robot velocities (no slipping of the wheels). This is archived by limitation of the overall allowable acceleration,
where

are the tangential and radial acceleration, respectively. Maximum acceleration that prevents sliding is defined by friction force Ffric:

where m is the vehicle mass, g is the gravity acceleration, and cfric is the friction coefficient. Due to vehicle construction, maximal tangential acceleration aMAXt and radial acceleration aMAXr are usually different and can be estimated by experiment. Therefore the overall acceleration should be somewhere inside the ellipse

or always on the boundary in the case of time-optimal planning. In path turns the robot needs to drive slower due to higher radial acceleration. Therefore to estimate the schedule u(t), first the turning points (TPs) of the path (where the absolute value of the curvature is locally maximal) are located where u is in the interval [uSP, uEP]. Positions of TPs are denoted u = uTPi, where i = 1, …, nTP and nTP is the number of TPs. In TPs translational velocity is locally the lowest, tangential acceleration is supposed to be 0, and radial acceleration is maximal. Tangential velocity in TPs can then be calculated considering Eq. (3.116)

Before and after the TP, the robot can move faster, because the curvature is lower than in the TP. Therefore the robot must decelerate before each TP (u < uTPi) and accelerate after the TP (u > uTPi) according to the acceleration constraint (3.118).
From Eq. (3.112) it follows that in each fixed point of the path v(t) and vp(u) are proportional with proportional factor ![]() defined in time. A feasible time-minimum velocity profile is therefore defined by the derivative of the schedule
defined in time. A feasible time-minimum velocity profile is therefore defined by the derivative of the schedule ![]() , where the minmax solution is computed as described next (minimizing maximum velocity profile candidates to comply with acceleration constrains). The radial and the tangential acceleration are expressed from Eq. (3.116) considering Eq. (3.112) as follows:
, where the minmax solution is computed as described next (minimizing maximum velocity profile candidates to comply with acceleration constrains). The radial and the tangential acceleration are expressed from Eq. (3.116) considering Eq. (3.112) as follows:

where dependence on time for u(t) is omitted due to shorter notation. Taking the boundary case of Eqs. (3.118), (3.120), Eq. (3.121) results in an optimal schedule differential equation

A solution of a differential equation is found by means of explicit simulation integrating from the TPs forward and backward in time. When accelerating a positive sign is used, and a negative sign is used when decelerating. The initial condition u(t) and ![]() are defined by the position of TPs uTPi and from Eq. (3.120), knowing that the radial acceleration is maximal allowable in the TPs:
are defined by the position of TPs uTPi and from Eq. (3.120), knowing that the radial acceleration is maximal allowable in the TPs:

Only a positive initial condition (3.123) is shown because u(t) has to be a strictly increasing function. The differential equations are solved until the violation of the acceleration constraint is found or u leaves the interval [uSP, uEP].
The violation usually appears when moving (accelerating) from the current TPi toward the next TP (i − 1 or i + 1), and the translational velocity becomes much higher than allowed by the trajectory. The solution of the differential equation (3.122) therefore consists of the segments of ![]() around each turning point:
around each turning point:
where ![]() is the derivative of the schedule depending on u, and
is the derivative of the schedule depending on u, and ![]() ,
, ![]() are the lth segment borders. Here the segments in Eq. (3.124) are given as a function of u although the simulation of Eq. (3.122) is done with respect to time. This is because time offset (time needed to arrive in TP) is not yet known; what is known at this point is the relative time interval corresponding to each segment solution
are the lth segment borders. Here the segments in Eq. (3.124) are given as a function of u although the simulation of Eq. (3.122) is done with respect to time. This is because time offset (time needed to arrive in TP) is not yet known; what is known at this point is the relative time interval corresponding to each segment solution ![]() .
.
The solution of the time-minimum velocity profile obtained by accelerating on the slipping edge throughout the trajectory is possible if the union of the intervals covers the whole interval of interest ![]() . Actual
. Actual ![]() is found by minimizing the individual ones:
is found by minimizing the individual ones:
Absolute time corresponding to the schedule u(t) is obtained from inverting ![]() to obtain
to obtain ![]() and its integration:
and its integration:

where ![]() must not become 0. In our case the time-optimal solution is searched; therefore, the velocity (and also
must not become 0. In our case the time-optimal solution is searched; therefore, the velocity (and also ![]() ) is always higher than 0.
) is always higher than 0. ![]() would imply that the velocity is zero, meaning the system would stop, and that cannot lead to the time-optimal solution.
would imply that the velocity is zero, meaning the system would stop, and that cannot lead to the time-optimal solution.
Also, initial (in SP) and terminal (in EP) velocity requirements can be considered as follows. Treat SP and EP as normal TPs where the initial velocities vSP, vp(uSP), vEP, vp(uEP) are known so the initial condition for ![]() ,
, ![]() can be computed. If these initial conditions for SP or EP are larger than the solution for
can be computed. If these initial conditions for SP or EP are larger than the solution for ![]() (obtained from TPs), then the solution does not exist because it would be impossible to make it through the first turning point, even if the robot brakes maximally. If the solution for given SP and EP velocities exist then also include segments of
(obtained from TPs), then the solution does not exist because it would be impossible to make it through the first turning point, even if the robot brakes maximally. If the solution for given SP and EP velocities exist then also include segments of ![]() computed for SP and EP to Eqs. (3.124), (3.125).
computed for SP and EP to Eqs. (3.124), (3.125).
From the computed schedule u(t), ![]() , the reference trajectory is given by
, the reference trajectory is given by ![]() and
and ![]() , and the reference velocity is given by Eqs. (3.22), (3.23).
, and the reference velocity is given by Eqs. (3.22), (3.23).