
Keeping Your Source Code Secret
In the battle between web application developers and attackers, the attackers unfortunately have the upper hand in many ways. Developers have limited (and usually extremely tight) schedules; attackers have as much time as they want. Worse, developers have to make sure every possible avenue of attack has been closed off, while attackers only have to find one flaw to succeed. But web developers do have one great advantage over attackers: attackers don’t have access to the application’s source.
To users and attackers alike, a web application is an opaque black box. They can give input to the black box and get output in return, but they really don’t have any way to see what’s going on in the middle.
An extremely important caveat to this statement is that any code that executes on the client tier of the web application, such as JavaScript or Flash content that runs in the user’s browser, is completely visible to attackers. We’ll cover this topic in more detail later in this chapter, but always remember that only server-side code can be secured from prying eyes.
Keeping potential attackers away from the application source and/or executable files is hugely helpful to defense. Consider what happens with box-product applications that get installed on the user’s machine. As soon as they’re released, attackers tear through them with binary static analysis tools, looking for flaws. There’s nowhere to hide. Plus, the attackers can perform all of their poking and probing on their own local machine. They can completely disconnect from the Internet if they want. There’s no way for the developers to know that their application is under attack.
Again, the situation is completely different for web applications, as illustrated in Figure 8-1. Any code running on the web server should be shielded from potential attackers. They can’t break it down with static analyzers. And any attacking they do has to come through the network, where you’ll have the chance to detect it and block it. But this great advantage that you have is dependent on your keeping the code secret. If it gets out into the hands of attackers, your advantage is lost: they’ll be able to analyze it disconnected from the network, just as if it were a box-product application.
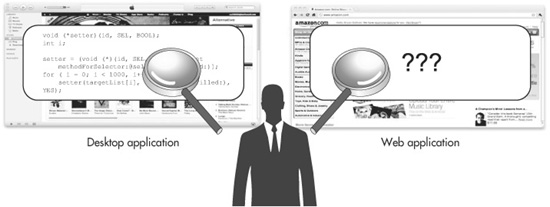
Figure 8-1 An attacker can statically analyze desktop applications, but web applications are like black boxes.
Those of you who are enthusiastic open-source supporters may be bristling at some of the statements we’ve just made. We want to clarify that we’re not knocking open-source code. We love open software, we use it all the time, and we’ve contributed some ourselves. But whether or not you release your code should be your choice to make. If you choose to make your app open, that’s great, but don’t let an attacker steal your code if you want to keep it to yourself.
However, there is one aspect to open-source software that we don’t particularly like. We personally find the “given enough eyeballs, all bugs are shallow” mantra to be pretty weak, especially when it comes to security bugs. By relying on other people to find security issues in your code, you’re making two very big assumptions: one, that they know what kinds of issues to look for; and two, that they’ll report anything they find responsibly and not just exploit it for themselves.
Static Content and Dynamic Content
Before we go any further on the topic of source code security, it’s important that we talk about the distinction between static content and dynamic content. When a user requests a resource from your web server, such as an HTML page or JPEG image, the server either sends him that resource as-is, or it processes the resource through another executable and then sends him the output from that operation. When the server just sends the file as-is, this is called static content, and when it processes the file, that’s dynamic content. The web server decides whether a given resource is static or dynamic based on its file type, such as “HTML” or “JPG” or “ASPX.”
For example, let’s say my photographer friend Dave puts up a gallery of his photographs at www.photos.cxx/gallery.html. This page is simple, static HTML, and whenever you visit this page, the photos.cxx web server will just send you the complete contents of the gallery.html file:

All the JPEG image files referenced on this page are also static content: When you view the gallery.html web page, your browser automatically sends requests for the images named in the <img> tags, and the web server simply sends the contents of those image files back to you.
Now let’s contrast that with some dynamic content files. Let’s say Dave adds a page to the photo gallery that randomly chooses and displays one picture from the archive. He writes this page in PHP and names it www.photos.cxx/random.php.

![]() Note
Note
The PHP function “glob” referred to in this code snippet is one of the worst-named functions ever, and if you’re not already a seasoned PHP developer, you probably won’t have any idea what it really does. Although it sounds as if it should declare or set a global variable or something along those lines, glob is actually a file system function that searches for files and directories matching the specified pattern, and returns all of the matches in an array. For example, in the previous code snippet, we searched for the pattern “images/*.jpg,” and glob returned a list of all JPEG filenames in the “images” directory. It’s pretty simple, but just not intuitively named!
However, when Dave first installed the PHP interpreter on his web server, he configured the server to treat PHP files as dynamic content and not static content. Now when you make a request for www.photos.cxx/random.php, the server doesn’t just send you back the raw source contents of the random.php file; instead, it sends the file to the PHP interpreter executable on the server, and then returns you the output of that executable, as illustrated in Figure 8-2.
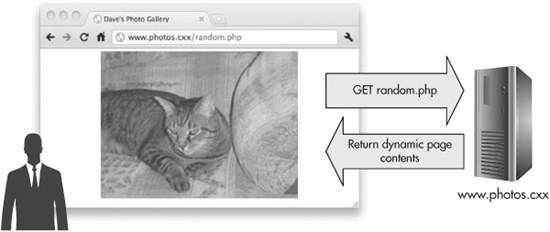
Figure 8-2 The photos.cxx server is configured to process PHP pages as dynamic content.
![]() Note
Note
Just because a page is static content doesn’t mean that there’s nothing to do on that page. Static HTML files can have text box inputs, drop-down boxes, buttons, radio buttons, and all sorts of other controls. And on the other hand, just because a page is dynamic content doesn’t mean that there is anything to do there. I could write a dynamic Perl script just to write out “Hello World” every time someone goes to that page.
The line between static and dynamic gets even blurrier when you look at pages that make extensive use of client-side script, like Ajax or Flash applications. We’ll cover some of the many security implications of these applications later in this chapter, but for right now we’ll focus on the fact that for static content, the source is delivered to the user’s browser, but dynamic content is processed on the server first.
Revealing Source Code
You can see how important it is to configure the server correctly. If Dave had made a mistake when setting up the server, or if he accidentally changes the file-handling configuration at some time in the future, then when you request www.photos.cxx/random.php, you could end up getting the source code for the random.php file, as shown in Figure 8-3. In this particular case that may not be such a big deal. But what if he had put some more sensitive code into that page? What if he had programmed it so that on his wife’s birthday, the page displays the message “Happy Birthday!” and always shows an image of a birthday cake instead of a random picture? If the source code for that leaked out, then his wife might found out ahead of time and the surprise would be ruined.
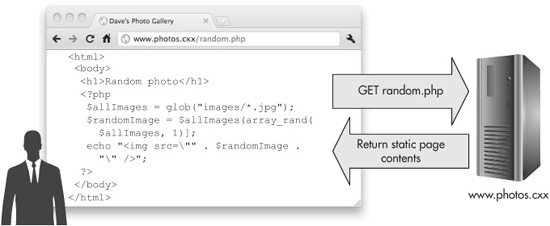
Figure 8-3 The photos.cxx server is misconfigured to serve PHP files as static content, revealing the application’s source code.
Of course, there are other much more serious concerns around source code leakage than just spoiled birthday surprises. Many organizations consider their source to be important intellectual property. Google tightly guards the algorithms that it uses to rank search results. If these were to leak out as the result of a misconfigured server, Google’s revenue and stock price could decline.
It’s bad enough if your source code leaks out and reveals your proprietary algorithms or other business secrets. But it’s even worse if that source code contains information that could help attackers compromise other portions of your application.
One extremely bad habit that developers sometimes fall into is to hard-code application credentials into the application’s source code. We saw in Chapter 7 that an application usually connects to its database using a database “application user” identity and not by impersonating the actual end users themselves. Out of convenience, application programmers will sometimes just write the database connection string—including the database application user’s username and password—directly into the application source code. If your application is written this way and the page source code accidentally leaks out, now it’s not just your business logic algorithms that will end up in the hands of attackers, but your database credentials too.
Another example of this same problem happens when developers write cryptographic secrets into their source code. Maybe you use a symmetric encryption algorithm (also called a secret-key algorithm) such as the Advanced Encryption Standard (AES) to encrypt sensitive information stored in users’ cookies. Or maybe you use an asymmetric encryption algorithm (also called a public-key algorithm) such as RSA to sign cookie values so you know that no one, including potentially the user himself, has tampered with the values. In either of these cases, the cryptographic keys that you use to perform the encryption or signing must be kept secret. If they get out, all the security that you had hoped to add through the use of cryptography in the first place will be undone.
Interpreted versus Compiled Code
The photo gallery application we’ve been using as an example is written in PHP, which is an interpreted language. With interpreted-language web applications, you deploy the source code files directly to the web server. Then, as we saw before, when a user requests the file, the interpreter executable or handler module for that particular file format parses the page’s source code directly to “run” that page and create a response for the user. Some popular interpreted languages for web applications include:
![]() PHP
PHP
![]() Perl
Perl
![]() Ruby
Ruby
![]() ASP (that is, “classic” VBScript ASP, not ASP.NET)
ASP (that is, “classic” VBScript ASP, not ASP.NET)
However, not every language works this way; some languages are compiled and not interpreted. In this case, instead of directly deploying the source code files to the web server, you first compile them into executable libraries or archives, and then you deploy those libraries to the server. For example, let’s say you wanted to write an ISAPI (Internet Server Application Programming Interface) extension handler for IIS using C++. You’d write your C++ code, compile the C++ to a Win32 dynamic-link library (DLL), and then copy that DLL to the web server.
![]() Note
Note
There is a third category of languages that combines elements of both interpreted and compiled languages. Languages like Java, Python, and the ASP.NET languages (C#, VB.NET, and so on) are compiled, but not directly into executable images. Instead, they’re compiled into an intermediate, bytecode language. This bytecode is then itself either interpreted or recompiled into an actual executable.
This may seem like a roundabout method of writing applications, but it actually combines the best aspects of both compiled and interpreted languages: you get the performance of compiled code (or close to it) and the machine-independence of interpreted code.
Where this matters from a security perspective is that you shouldn’t think you’re any more secure against source code leakage just because you’re using a compiled language instead of an interpreted one. If an attacker gains access to your Java WAR (Web ARchive) file or your ASP.NET assembly DLL, he may not be able just to open it in a text editor, but there are freely available decompiler tools that can actually turn these files back into source code. (You can see a screenshot of one of these tools, Java Decompiler, in Figure 8-4.) And as we saw at the beginning of the chapter, any type of executable can be scanned for vulnerabilities with static binary analysis tools.
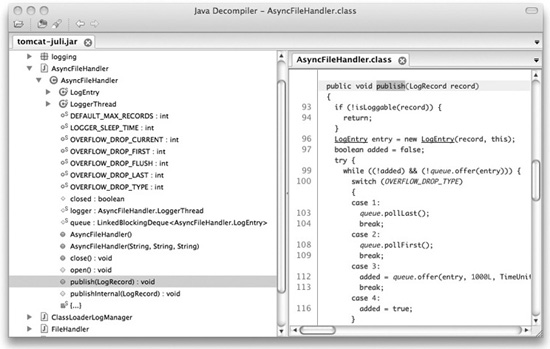
Figure 8-4 The Java Decompiler tool reconstructs Java source code from a compiled JAR file.
Backup File Leaks
It’s very important to remember that the way a web server handles a request for a file—that is, whether it treats the file as active content and processes it, or treats it as static content and simply sends it along—depends on the file’s extension and not on its contents. Let’s say that I took the random.php file from the example photo gallery application and renamed it to random.txt. If someone were to request the web page www.photos.cxx/random.txt now, the web server would happily send them the static source code of that file. Even though the contents of random.txt would still be the same completely legal and well-formed PHP code they always were, the server doesn’t know or care about that. It doesn’t open up the file to try to determine how to handle it. It just knows that it’s configured to serve .txt files as static content, so that’s what it does.
It’s also important to remember that by default, most web servers will serve any unknown file type as static content. If Dave renames his random.php page to random.abcxyz and doesn’t set up any kind of special handler rule on his server for “.abcxyz” files, then a request for www.photos.cxx/random.abcxyz would be fulfilled with the static contents of the file.
As of this writing, two of the three most popular web servers—Apache (with a reported 60 percent market share) and nginx (with an 8 percent share)—serve file extensions as static content unless specifically configured not to. However, Microsoft Internet Information Services (or IIS, with a 19 percent share) version 6 and later will not serve any file with a filetype that it hasn’t been explicitly configured to serve. IIS’s behavior in this regard is much more secure than Apache’s or nginx’s, and the other web servers would do well to follow IIS’s lead here.
Problems of this type, where dynamic-content files are renamed with static-content extensions, happen surprisingly more often than you’d think. The main culprit behind this is “ad-hoc source control”; or in other words, developers making backup files in a production directory. Here are three examples of how this might happen:
Scenario 1. The current version of random.php is programmed to find only random JPEG files in the image gallery. But Dave has noticed that there are some GIF and PNG files in there too, and right now those will never get chosen as one of the random photos. He wants to edit the code so that it looks for random GIF and PNG files too, but he’s not 100 percent sure of the PHP syntax he needs to do that. So, the first thing he does is to make a copy of random.php called random.bak. This way, if he messes up the code trying to make the change, he’ll still have a copy of the original handy and he can just put it back the way it was to begin with. Now he opens up random.php and edits it. He manages to get the syntax right on the first try, so he closes down his development environment and heads off to get some sleep. Everything looks great, except that he’s forgotten about his backup file random.bak still sitting there on the web server.
Scenario 2. Just as in the first scenario, Dave wants to make a change to random.php, and he’s not positive about the syntax to make the change correctly. He also knows how dangerous it is to edit files directly on the production server—if he did make a mistake, then everyone who tries to visit the site would just get an error until he fixes it. So he syncs his development machine to the current version of the production site, makes a random.bak backup copy of random.php on his local dev box, and then makes the changes to random.php there. He also has a few other features that he’d like to add to some of the other pages in the application, so he takes this opportunity to make those changes too. Once he’s verified that all his changes work, he’s ready to push the new files to production. So far, so good, except that when Dave goes to deploy his changes, instead of just copying and pasting the specific files that he edited, he copies and pastes the entire contents of his development folder, including the random.bak file.
Scenario 3. This time, Dave opens up the source code to make a simple change he’s made dozens of times before. He knows exactly what syntax to use, and he knows he’s not going to make any mistakes, so he doesn’t save a backup file. If Dave doesn’t save a backup file, there’s no chance of accidental source code disclosure, right? Unfortunately, that’s not the case. While Dave may not have explicitly saved a backup file, his integrated development environment (IDE) source code editor does make temporary files while the user is editing the originals. So the moment that Dave fired up the editor and opened random.php, the editor saved a local copy of random.php as random.php~. Normally the editor would delete this temporary file once Dave finishes editing the original and closes it, but if the editor program happens to crash or otherwise close unexpectedly, it may not get the chance to delete its temporary files and the source code would be visible. Even if that doesn’t happen, if Dave is making changes on a live server, then the temporary file will be available for the entire time that Dave has the original open. If he leaves his editor open while he goes to lunch, or goes home for the night, that could be a pretty large window of attack.
In all of these cases, the backup files wouldn’t be “advertised” to potential attackers. There wouldn’t be any links to these pages that someone could follow. But these mistakes are common enough to make it worth an attacker’s time to go looking for them. If an attacker sees that a web application has a page called random.php, he might make blind requests for files like:
![]() random.bak
random.bak
![]() random.back
random.back
![]() random.backup
random.backup
![]() random.old
random.old
![]() random.orig
random.orig
![]() random.original
random.original
![]() random.php
random.php
![]() random.1
random.1
![]() random.2
random.2
![]() random.xxx
random.xxx
![]() random.php.bak
random.php.bak
![]() random.php.old
random.php.old
And so on, and so on. The more obvious the extension, the sooner he’s likely to guess it; so he’d find random.php.1 before he’d find random.xyzabc. But the solution here is not to pick obscure extensions: the solution is to not store backups in production web folders.
Include-File Leaks
While there’s never a good reason to keep backup files on your live web server—at least, there’s never a good enough reason to outweigh the danger involved—there’s another situation that’s a little more of a security gray area.
It’s pretty common for multiple pages in a web application to share at least some of their functionality. For example, each page in Dave’s photo gallery app might have a section where viewers can rate photos or leave comments on what they like and don’t like. It would be a little silly for him to re-implement this functionality from scratch for each different file. Even cutting and pasting code from one file to the next means that every time he makes a change in one place, he’ll need to remember to go make that exact same change in every other place. This is fragile and inefficient.
Instead of copying the same bit of code over and over in multiple places, it’s better just to write it once into a single module. Every page that needs that particular functionality can then just reference that module. For compiled web applications, that module might be a library the application can link with, but for interpreted applications, it will just be another file full of source code. Now you have a new problem: what file extension should you give these included file modules?
In some programming languages, you don’t have any real choice as to the file extension of your include modules. Python modules, for example, must be named with a .py file extension. But in others, such as PHP, you can choose any extension you want. Some developers like to name include modules with an extension like .inc or .include because it helps them keep straight which files are meant to be publicly accessible and which are meant to be include-only. The problem with this approach is that, unless configured otherwise, the web server will serve these files as static content to anyone who asks for them.
Keep Secrets Out of Static Files
So far, we’ve talked a lot about the importance of keeping the source code for your dynamic content pages out of the hands of potential attackers. There is an equally important flip side to this coin, however: You need to make sure that you never put sensitive information into static content pages.
The most common way you’ll see this mistake is when developers write information into comments in HTML or script files. Since 99 percent of legitimate users (and QA testers) never view the page source, it can be easy to forget that comment text is only a “View Source” click away. It’s unfortunately all too common to see HTML like this:

Doing this is like hiding your front door key under the welcome mat: It’s the first place an attacker will look. But realistically, it’s doubtful that anyone does this knowingly; they either forget that HTML comments are visible in the page source, or they mix up client-side and server-side comments. Consider the following two snippets of mixed PHP/HTML code. Here’s the first snippet:

Now compare that with this snippet:

These two pieces of code are almost completely identical, and if you look at each of the resulting pages in browser windows, you wouldn’t see any difference at all. But the first snippet used PHP comment syntax to document the upcoming sale price of the store item, and the second snippet used HTML comment syntax. The interpreter won’t render PHP comments (or the comments of any other dynamic language like Java or C#) in the page output; it’ll just skip over them. But the HTML comments do get written to the page output. That one little change from “//” to “<--” is all it took to reveal that a big sale is coming up and maybe convince some people to hold off on their purchases.
Besides HTML, you’ll also see sensitive information in JavaScript comments. Even though you can make highly interactive sites with JavaScript—Google’s Gmail, Docs, and Maps (shown in Figure 8-5) applications come to mind as great examples of JavaScript UI—it’s still just a “static” language in that JavaScript files get served to the browser as source code. Any comments you write in JavaScript code will be visible to users.

Figure 8-5 Google Maps uses client-side JavaScript extensively in order to provide a responsive user interface.
Another way you’ll often see this kind of problem is in overly helpful documentation comments. (This usually comes up more often in JavaScript but sometimes in HTML too.) Most developers learn early on in their careers that it’s important for them to properly document their code. It can be a nightmare trying to work on someone else’s undocumented code, usually years after that person has left the organization, and you have no idea what they were thinking when they wrote it.
So documentation does have an important place in development, but that place is on the server, not the client. See how much information you can pull out of this seemingly innocent code comment:

There are a few readily apparent pieces of sensitive information being shared here. First, we can see that while there was a timeout bug in the code that was recently fixed for Internet Explorer, the bug is still present for Firefox. It’s possible that there’s a way an attacker could take advantage of that, maybe by intentionally creating a race condition.
Second, we can see that an old version of the page is stored at dev02.site.cxx/kyle/page.php. We may not have even been aware that there was such a domain as dev02.site.cxx before; here’s a whole new site to explore and attack. And we know this site has old code, so there may be security vulnerabilities that are fixed on the main site that are still present on this dev site. And if there’s a dev02.site.cxx, is there also a dev01.site.cxx, or a dev03.site.cxx?
There are a couple of other more subtle pieces of information an attacker can get from the comments that might lead him to take a closer look. First of all, the code is very old (by Internet standards, at least): it was originally written in January 2004. While it’s not a hard rule, in general older code will often have more vulnerabilities than newer code. New vulnerabilities are developed all the time, and it’s less likely that code dating back to 2004 would be as secure against a vulnerability published in 2008 as newer code would be.
![]() Note
Note
Another factor to consider is that today’s threats are a lot more severe than they were in 2004. Code of that era wasn’t built to withstand concerted attacks from LulzSec-type organizations or from foreign government agencies with dedicated “Black-Ops” hacking teams.
Another subtle vulnerability predictor is that the code has been under a lot of churn in a short amount of time. Seven years went by without a single change, and then it was modified three times by three different people in the space of one week. Again, this doesn’t necessarily mean the code has vulnerabilities in it, but it’s something that might catch an attacker’s eye and lead him to probe more deeply.
Exposing Sensitive Functionality
The final thing we need to discuss before we move on to other file security issues is the importance of keeping sensitive functionality away from attackers. We’re drifting a little away from the overall chapter topic of file security now, but since we’re already on the subject of keeping other sensitive information such as source code and comments safely tucked away on the server, this will be a good time to cover this important topic.
Many modern web applications do almost as much processing on the client-side tier as they do on the server-side. Some do even more. For example, think about online word processing applications like Google Docs, Microsoft Office Live, or Adobe Acrobat.com. All of the document layout, formatting, and commenting logic of these applications is performed on the client tier, in the browser, using JavaScript or Flash. These kinds of client-heavy web apps are called Rich Internet Applications, or RIAs for short.
RIAs can have a lot of advantages over standard server-heavy web applications. They can offer a more interactive, more attractive, and more responsive user interface. Imagine trying to write a full-featured word processor, spreadsheet, or e-mail app without client-side script. It might not be technically impossible, but the average user would probably spend about 30 seconds using such a slow and clunky application before giving up and going back to his old box-product office software. It’s even worse when you’re trying to use server-heavy apps on a mobile browser like a smartphone or tablet that has a slower connection speed when it’s outside WiFi range.
Another advantage of RIAs is that you can move some of the business logic of the application to the client tier to reduce the burden on the server. Why spend server time calculating spreadsheet formulas when you can have the user’s browser do it faster and cheaper? However, not all business logic is appropriate for the client to handle. Computing spreadsheet column sums and spell-checking e-mail messages with client-side script is one thing; making security decisions is totally different.
For a real-world example of inappropriate client-side logic, let’s look at the MacWorld Expo web site circa 2007. The year 2007 was huge for MacWorld Expo; this was the show where Steve Jobs first unveiled the iPhone in his keynote address. If you had wanted to see this event in person, you would have had to pony up almost $1,700 for a VIP “platinum pass”—but at least one person found a way to sneak in completely for free.
The MacWorld conference organizers wanted to make sure that members of the press and other VIPs got into the show for free, without having to pay the $1,700 registration fee. So, MacWorld e-mailed these people special codes that they could use when they went to register for their conference passes on the MacWorld Expo web site. These codes gave the VIPs a special 100 percent discount—a free pass.
In an attempt to either speed up response time or take some load off their server, the conference web site designers implemented the discount feature with client-side code instead of server-side code. All of the logic to test whether the user had entered a valid discount code was visible right in the browser for anyone who cared to look for it. It was a simple matter for attackers—including at least one security researcher who then reported the issue to the press—to open the client-side JavaScript and reveal the secret discount codes.
The takeaway here is that you should never trust the client to make security decisions for itself. If the MacWorld Expo web site designers had kept the discount code validation logic on the server side, everything would have been fine. But by moving this logic to the client, they opened themselves to attack. Authentication and authorization functionality (which is essentially what a discount code validation is) should always be performed on the server. Remember, you can’t control what happens on the client side. If you leave it up to the user to decide whether they should get a free pass to see Steve Jobs’ keynote or whether they should pay $1,700, chances are they’re going to choose the free option whether that’s what you wanted or not.
Programmers often refer to making function calls as “issuing commands” to the system. This is a Web 1.0 mindset. You may be able to think of server-side code as “commands,” but when it comes to client-side code, you can only offer “suggestions.” Never forget that an attacker can alter your client-side logic in any way he wants, which means that all the really important decisions need to be made on the server, where you have a better chance of guaranteeing that they’re made the way you want them to be made.
Your Plan
![]() Don’t hard-code login information such as test account credentials or database connection strings into your application. Doing this not only makes the code harder to maintain, but it also presents a potential security risk if the application source code were to be accidentally revealed.
Don’t hard-code login information such as test account credentials or database connection strings into your application. Doing this not only makes the code harder to maintain, but it also presents a potential security risk if the application source code were to be accidentally revealed.
![]() Never make backup copies of web pages in production folders, even for a second. Be sure not to deploy local backup copies to production, too: it’s easy to forget this if your deployment procedure is just to copy all the files in your local development folder and paste them to the production machine.
Never make backup copies of web pages in production folders, even for a second. Be sure not to deploy local backup copies to production, too: it’s easy to forget this if your deployment procedure is just to copy all the files in your local development folder and paste them to the production machine.
![]() When possible, it’s best to name any include files with the same extension as your main source files (for example, .php instead of .inc or .include).
When possible, it’s best to name any include files with the same extension as your main source files (for example, .php instead of .inc or .include).
![]() For dynamic content pages, write code comments using the comment syntax for the dynamic language and not in HTML. HTML comments will be sent to the client where attackers can read them.
For dynamic content pages, write code comments using the comment syntax for the dynamic language and not in HTML. HTML comments will be sent to the client where attackers can read them.
![]() For static content pages, make sure that absolutely no sensitive information, including links to non-public files or directories, is written in the code comments. When possible, use your testing framework to flag all comments so that you or your quality assurance team can check them before you deploy.
For static content pages, make sure that absolutely no sensitive information, including links to non-public files or directories, is written in the code comments. When possible, use your testing framework to flag all comments so that you or your quality assurance team can check them before you deploy.
![]() Always remember that code you write for the client tier is not a set of “commands,” just a set of “suggestions.” An attacker can change this code to anything he wants. If you make security decisions like authentication or authorization in client-side code, you may as well not make them at all.
Always remember that code you write for the client tier is not a set of “commands,” just a set of “suggestions.” An attacker can change this code to anything he wants. If you make security decisions like authentication or authorization in client-side code, you may as well not make them at all.