
Access Control Continued
As discussed in the previous chapter, a big part of access control is authentication: making subjects prove who they are. More specifically, proving that they are in fact someone or something that is known to the web application by means of providing one or more credentials such as a name and password, a physical security token, or even a biometric credential like a fingerprint or iris scan. Typically a subject is a user, an actual human being, who has been given an account with the web application. Sometimes subjects are other pieces of software—other web applications, system components, automated maintenance accounts, and so forth.
The other big part of access control is authorization. This simply means deciding whether someone or something is allowed to access part or all of a web application. Think of it like a house party; authentication is when a potential guest stands in front of the peephole on your door so you can see who’s ringing the doorbell (thus providing a biometric credential). Authorization is when you consider various factors in order to decide whether to let them into your party (did you actually invite them? are you still friends since the invitations went out?). By letting them into the party, you are granting them permission to access your party’s resources (eat your snacks, drink your beer, and interact with your other guests).
This chapter discusses the terminology, methodology, and dangers involved in web application authorization. You’ll learn how your web application makes that “decision at the doorway” and subsequent decisions governing your guest’s behavior as the party progresses. If a guest attempts to put a lampshade on his head—or someone else’s—you may have to revoke that guest’s authorization to enjoy the rest of the party; that is, show them the door.
Authorization
Authorization (“AuthZ” for short, or sometimes “A2” because it comes second after authentication) is the process of determining whether a subject has sufficient permission to perform a given operation against a target resource. This is perhaps a more formal definition than is commonly used, but it will suit our purposes. Nor is it the only possible definition. We are defining authorization fundamentally as a process—a verb, if you will. Yet some would argue (see the next “In Actual Practice” sidebar) that authorization is fundamentally policy data—a noun. Most of the time, it is a pedantic distinction anyway. Typically, computer security people use the term “authorization” to mean either one, which is the stance we will take here.
Session Management
Sessions and session management go hand in hand with authorization. We will cover sessions in great detail later. For now, suffice it to say that sessions are related to authorization inasmuch as sessions embody a user’s authentication and authorization for the duration of a user’s interaction with your web application. Session management is the means by which a client and server keep track of who a user is, and it’s closely related to what that user is allowed to do, and what the user is actually doing. Session management is how a web server knows you are you after you’ve authenticated yourself, and can therefore properly provide you with (or deny you, as the case may be) access to resources and actions within the application.
Web application security would be enormously impractical, if not impossible altogether, if not for sessions. The key challenge with web application security is that the HTTP protocol, the lingua franca that mediates every interaction between a web browser and a web application, is stateless. HTTP itself has no built-in mechanisms for tracking anything from one request to the next. Without sessions and session management, a web server has no means of knowing that a particular sequence of requests against a series of URLs represents a unified thread of action by a single user, while another sequence of requests (possibly happening at the same time, in an interleaved fashion) represents a different user.
You can well imagine the problems this would cause if, say, two different customers went to a bank’s online banking application at the same time and the server didn’t know which account balance to send back to which user’s browser. Sessions and session management are another layer of interaction between web browsers and web servers, one that has been built on top of the stateless HTTP protocol, for keeping everything straight. In this manner, it is similar to the way the robust TCP networking protocol, with its guaranteed delivery features and so forth, is built on top of the much less reliable IP protocol.
Modern web browsers and servers have converged on a set of approaches to sessions and session management, such as cookies and URL parameters. Each framework has its strengths and weaknesses. We will explore each in turn as we look at the different ways attackers meddle with sessions to gain illegitimate access to an application.
Authorization Fundamentals
As we have said, AuthZ is the process of deciding whether a user can perform a certain action. Consider Figure 4-1, which builds upon Figure 3-2 from Chapter 3 in order to show how a user could be evaluated by an access control system before being granted the rights to access a particular resource.
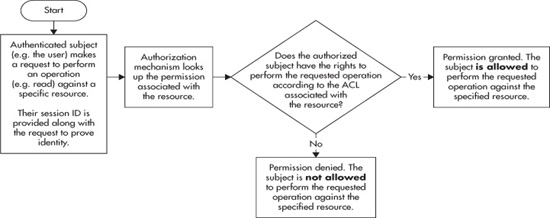
Figure 4-1 A simple model of authorization
As an example to make Figure 4-1 more concrete, consider a user, Joe, accessing a health data application hosted by his doctor’s office. As always, Joe must first authenticate to the application. Joe likely provides a user identifier of some form—his name, his Social Security number, or potentially his health insurance account number—and a password or PIN number. Once he’s authenticated, what can Joe do? He is likely allowed to read most, if not all, of his own data. After all, it is his data. He should be able to see the results of his latest cholesterol test, see the written version of the instructions his doctor gave him during his last physical exam about lowering his fat intake and exercising more, and so forth.
However, Joe is likely not allowed to read data about other patients. That would be a violation of privacy, a likely violation of applicable law, and could potentially open his doctor up to legal liability as well, unless Joe is trying to access the health data of a minor for whom Joe is the parent or legal guardian. As you can see, even determining what resources a user might be allowed to view can be a complex question.
But, can Joe write any data? Even his own data? Some, perhaps. Joe ought to be able to change his address, phone number, insurance policy number, and so on if need be. He has a legitimate reason to have write-access to those records. But should he be able to change, say, that latest cholesterol reading? Of course not. The only way Joe can lower his cholesterol reading is, well, to lower his cholesterol. Diet and exercise, Joe. Even for the resources and data associated with a specific user, different permission levels can apply.
If Joe can’t alter his cholesterol reading, does that mean that no one can? No. A robust application would be designed to handle unusual situations. For example, if a technician at Joe’s doctor’s office discovered that Joe’s blood sample had been accidentally switched with that of another patient, it ought to be possible for an administrator at the doctor’s office to manually switch the data within the system. For that matter, whoever was responsible for uploading the cholesterol results into the system in the first place would clearly need write-access (but not necessarily read access) to patients’ blood results records.
Authorization is a complex subject, one that must take into account the idiosyncratic nature of the web application, the resources managed by that application, and the use-cases the application must enable. There is no one-size-fits-all answer for such questions. The best practice is to carefully consider your application’s requirements during the design phase.
It is worth mentioning that even for a low-profile application such as a doctor’s office health portal, the requirements for authentication and authorization may well have been determined in conjunction with local, regional, or national law. In the United States, for example, a minimum level of protections for health-related data is mandated by the Health Insurance Portability and Accountability Act (HIPAA). It isn’t just banks and nuclear facilities that need robust web security. Spend some time during the requirements-gathering phase of your web application design to research what statutes may govern your web application.
Authorization Goals
AuthZ has three specific goals associated with it, three fundamental reasons why we go through the effort of incorporating authorization into our applications at all. These may seem obvious, but it is worth making sure we’re aware of all of them. We authorize for the following reasons:
![]() To ensure that users can only perform actions within their privilege level.
To ensure that users can only perform actions within their privilege level.
![]() To control access to protected resources using criteria based on a user’s role or privilege level.
To control access to protected resources using criteria based on a user’s role or privilege level.
![]() To mitigate privilege escalation attacks, such as might enable a user to access administrative functions while logged on as a non-administrative user or potentially even an anonymous guest user.
To mitigate privilege escalation attacks, such as might enable a user to access administrative functions while logged on as a non-administrative user or potentially even an anonymous guest user.
Detailed Authorization Check Process
Authorization means determining whether a subject (a user or other computer) is permitted to perform some action on a protected resource. We say a “protected resource” because not all resources in all applications are protected. For example, free web-mail applications grant anyone—even unauthenticated users—the permission to use the create account function. For such applications, that’s pretty much the whole point. Most web applications, however, will want to protect most of their resources—most of the time, anyway.
Think again about Joe accessing his doctor’s health portal application. Authorization means determining that Joe can read his own cholesterol results, but not read Sally’s, and that he cannot change his cholesterol results, while an administrator can. Authorization just means granting or denying access on the basis of a set of rules.
Subjects
In security parlance, a subject is the thing requesting access to protected resources. In normal people parlance, a subject is a user, another application, a component within the same application, and so on. For example, when you attempt to read a file on your personal computer, you are the subject. But when your computer’s nightly backup software attempts to read a file on your computer (you do run nightly backups, right?), that application is the subject. Note that in such cases, both you and the application may be placed into a common security framework—the operating system’s concept of “user,” which may include both human users and pseudo-users created explicitly to represent service accounts such as for the backup software. In the web application world, a subject is commonly any of
![]() An actual human user accessing the web application
An actual human user accessing the web application
![]() A web application accessing another web service
A web application accessing another web service
![]() A web application accessing a back-end database
A web application accessing a back-end database
![]() Any one of the web services or back-end databases accessing their local operating systems
Any one of the web services or back-end databases accessing their local operating systems
![]() Another computer system or host
Another computer system or host
![]() Essentially, anything that has been assigned an identity
Essentially, anything that has been assigned an identity
Consider Joe and the health portal application: Joe is a subject for the health portal. The health portal is a subject to a web service at Joe’s insurance company, should Joe decide he wants to look up what his office visit co-pay amount is. And the health portal is a subject for the back-end database that holds Joe’s cholesterol data. Any person or component that is making a request for something that is held or managed by some other entity, is a subject.
Somewhat counterintuitively, a human being is never the actual subject. Not directly. This is because all user actions are mediated by a software stack that communicates the user’s intentions to the web application. In practice, a user/subject is actually just whatever collection of software is acting as the user’s proxy. However, much like the distinction between policy definition and application, this too is an academic distinction that rarely matters. As before, we will continue to refer casually to “the user” rather than “the software components acting on the user’s behalf to communicate user intentions to the web application.”
Resources
Resources are simply the protected objects, either data or functionality, that the subject is attempting to access. Practically anything can be a resource, such as a protected file that a user is trying to open, a table or a record in a database, programs and other units of software, or even connectivity to networks (think firewall ports). Web-specific examples that combine both data and functionality resources include scenarios such as checking balances or transferring funds between accounts in an online banking application, reading archived or other subscription-only articles on a newspaper’s web site, listening to content on a streaming music service, or good old Joe keeping tabs on his cardiovascular health.
The whole issue of resources raises the question of how a web application knows what the resource in question is for any given access request. There are several methods.
Resources, or the identifiers to them, may be encoded in URL parameters. Anything after a question mark in a URL is a parameter. For example, in a URL such as http://www.MyHometownNewspaper.com/archives?article=00293859231, the parameter is “article” with a value of “00293859231.” That value presumably corresponds to some key within a back-end database table that allows the web application to fetch the proper article for the reader.
Resource identifiers may be encoded as path components within the URL. The Representational State Transfer methodology, or REST, does this (see http://www.ics.uci.edu/~fielding/pubs/dissertation/fielding_dissertation.pdf). A well-known example is the URLs for specific books in Amazon.com’s web site, which encode the title as an identifying number within the URL itself. For example, the fiftieth anniversary edition of George Orwell’s Animal Farm may be found at http://www.amazon.com/Animal-Farm-Anniversary-George-Orwell/dp/B000KWSLAO/. The “B000KWSLAO” portion of that URL is Amazon.com’s internal unique identifier for that title.
Resources may be encoded or identified by data stored within the session state as well. In such cases, it is not obvious through casual inspection of the application’s URLs how to identify the resource. That grants a modicum of additional security, but as we will see later when we look at attacks against session state, not very much if you aren’t careful.
Determining Access
Once the web application has determined the subject and what the subject wants to do—read a bank balance, update a mailing address, order a book—it can determine whether the action is permitted. In order to make that determination, the application has to have rules. As discussed earlier, these rules are policy definitions and go by many names such as “permissions,” “access control lists,” or simply “policies,” to name a few. The process of following these rules at run time, or of making yes/no decisions based on those rules, is shown in Figure 4-1.
Policies come in different styles as well. Access control lists, or ACLs, are permissions that are applied to specific resources. Using an ACL thus combines particular subjects, operations, and target resources into discrete bundles. ACLs can potentially be very fine-grained and flexible, at the expense of requiring more active administration.
Role-based authorization instead labels resources with groups of subjects—known as “roles”—who are granted the ability to perform various actions on those resources.
Determining access then requires a two-stage decision; first, assessing what roles can perform the requested action, and second, determining whether the subject is a member of any of those roles. Role-based authorization is considerably easier to administer, at the expense of being less flexible.
The tradeoffs are evident: ACLs, because they are almost infinitely fine-grained, are essentially built around a model of ad-hoc, as-necessary permission granting. ACLs make it very easy to grant exceptions to a general rule such as “nobody else can read or write any of my files, except I want Bryan to have read/write access to the file for the book we’re writing together. Nobody else has access at all.”
Role-based authorization, on the other hand, is built more for the enforcement of general rules that are determined in advance, such as “all managers can see the salaries of employees who report to them.” Roles make bulk application of rule changes easy—just add or remove permissions to do something from a role, and that decision is immediately propagated to all users who hold that role. However, role-based authorization does not facilitate one-off exceptions without creating a special-purpose role to hold the subject(s) who need to have that exception.
Your Plan
The question often arises of how one goes about selecting an access control model and then how to build a list of permissions. There are three general patterns you can follow:
![]() Discretionary Access Control (DAC) In DAC, access control is left to the discretion of the owner of an object or other resource. Although access is primarily controlled by the object owners, there are system-wide or application-wide access control rules such as the ability to debug a process running under a different account or the ability to load kernel code. Such rules can typically be overridden by the owners of objects and resources.
Discretionary Access Control (DAC) In DAC, access control is left to the discretion of the owner of an object or other resource. Although access is primarily controlled by the object owners, there are system-wide or application-wide access control rules such as the ability to debug a process running under a different account or the ability to load kernel code. Such rules can typically be overridden by the owners of objects and resources.
![]() Mandatory Access Control (MAC) In MAC, access control is determined by the system, or by system administrators, rather than object owners. Some web applications use this model because of its stronger limits on what can potentially happen within the application, as well as the simplification of design and user interface that comes with not needing to provide users with a means to manage permissions.
Mandatory Access Control (MAC) In MAC, access control is determined by the system, or by system administrators, rather than object owners. Some web applications use this model because of its stronger limits on what can potentially happen within the application, as well as the simplification of design and user interface that comes with not needing to provide users with a means to manage permissions.
![]() Role-Based Access Control (RBAC) This is another nondiscretionary model, like MAC, but which implements access control by means of roles, as described earlier in this chapter. Access determinations are still made by the system (or by system administrators), but are made in the context of a more general framework. Administrators can, if necessary, define new roles and assign uses to them, which is often not possible in strict MAC-oriented systems.
Role-Based Access Control (RBAC) This is another nondiscretionary model, like MAC, but which implements access control by means of roles, as described earlier in this chapter. Access determinations are still made by the system (or by system administrators), but are made in the context of a more general framework. Administrators can, if necessary, define new roles and assign uses to them, which is often not possible in strict MAC-oriented systems.
![]() Hybrid systems Nothing says you can’t mix and match these three different access control models, and indeed, many web applications do just this. The social media site Facebook, for example, mixes RBAC and DAC; roles such as user and administrator codify broad permission policies, but the application also incorporates elements of discretionary access by allowing users to control who can see what information on their “wall.”
Hybrid systems Nothing says you can’t mix and match these three different access control models, and indeed, many web applications do just this. The social media site Facebook, for example, mixes RBAC and DAC; roles such as user and administrator codify broad permission policies, but the application also incorporates elements of discretionary access by allowing users to control who can see what information on their “wall.”
Which style suits your needs is one of the key design decisions you will need to make for your web application. Either way, authorization serves a function similar to that of keys and locks in the real world. They make the instantaneous decisions to accept or reject, to grant access, or deny. They enforce the policy determinations.
Types of Permissions
We’ve seen that there are two kinds of resources users attempt to access: data and functionality. Both can have permissions, and you will not be surprised to learn that the particular types of permissions that matter are different for data versus functionality. Not all permissions are relevant for all resources. Nevertheless, all permissions fall into three broad types:
![]() Read access Read access just means the ability to see what something is, to have its contents presented for a user’s perusal. For most web applications, read access only matters for data resources. Read access is largely irrelevant for resources that represent functionality. What would it mean to read the funds-transfer function in an online banking application? Reading it is not the same as using it. The fundamental question the authorization system must answer is, “should this user be allowed to see this data?”
Read access Read access just means the ability to see what something is, to have its contents presented for a user’s perusal. For most web applications, read access only matters for data resources. Read access is largely irrelevant for resources that represent functionality. What would it mean to read the funds-transfer function in an online banking application? Reading it is not the same as using it. The fundamental question the authorization system must answer is, “should this user be allowed to see this data?”
![]() Write access Write access is the general ability to change something. And again, in nearly every web application, write access only applies to data resources. The implications of a user being able to write—that is, change—the functionality of a web application are frightening indeed. The fundamental question the authorization system must answer is, “should this user be allowed to change this data?”
Write access Write access is the general ability to change something. And again, in nearly every web application, write access only applies to data resources. The implications of a user being able to write—that is, change—the functionality of a web application are frightening indeed. The fundamental question the authorization system must answer is, “should this user be allowed to change this data?”
![]() Execute access Execute access is the ability to run a piece of code in order to do something. It is the core permission that applies to units of functionality within a web application. Execute access is largely moot when it comes to data resources; there are always exceptions, but generally speaking you can’t run a piece of data in any meaningful way. What would it mean to execute a bank balance, for example? The fundamental question the authorization system must answer is, “should this user be allowed to take this action?”
Execute access Execute access is the ability to run a piece of code in order to do something. It is the core permission that applies to units of functionality within a web application. Execute access is largely moot when it comes to data resources; there are always exceptions, but generally speaking you can’t run a piece of data in any meaningful way. What would it mean to execute a bank balance, for example? The fundamental question the authorization system must answer is, “should this user be allowed to take this action?”
It may be tempting to think that your web application is somehow special and requires some new type of permission. This is rarely the case, as real-world scenarios can almost inevitably be conceived in terms of seeing things, changing things, and doing things. For example, if you’re designing a stock trading web application for a brokerage firm, you might think that your application would need special “buy” and “sell” permissions that apply to the objects that represent stocks and other securities. Not so. What you actually need is a way to manage permissions for executing or exercising the “buy” and “sell” functions within the application.
As with most questions in web application security, develop a suspicious eye towards permission decisions that seem obvious and that allow a user to do something. Consider these questions carefully, and with attention to all the use cases your application must satisfy. For example, for an online book-selling application, it might seem obvious that every user should always have the ability to order a book, right? Why wouldn’t you want to let somebody buy something from you? Well, perhaps the user isn’t authenticated. If the user is an anonymous guest on your site, you have no way to deliver the book to them nor to collect money from them. The safer course of action is usually to deny permissions to everything, unless the authorization system can prove the user is allowed. To quote Nancy Reagan, “Just say no.”
Authorization Layers
Authorization is not a one-time thing. Authorization should happen at many points and many times within a web application. These points come at certain common boundaries that exist in most web applications, forming “layers” that can be thought about, designed, and implemented in a holistic fashion.
As you can see in Figure 4-2, authorization occurs both in the horizontal and vertical directions. Horizontally, it takes place at the boundaries between systems on the path from user to application. Vertically, it takes place between interacting components within an individual system. Fundamentally, AuthZ takes place whenever one subject must access another. All of the elements in the figure are software, which means they can do things, which means that for our purposes they are security subjects to the downstream elements. All the transition points in Figure 4-2 represent boundaries at which it is possible for authorization to occur.
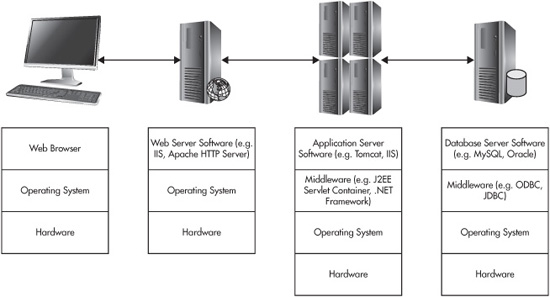
Figure 4-2 Checkpoints where AuthZ occurs
Traditional computer security was only concerned with the vertical direction; with the interaction of software components that were active on the same computer at the same time. Web application security adds the horizontal direction, because a modern web application is composed of a number of discrete components that jointly mediate the user’s interaction with the application. The horizontal layers are as follows:
![]() Web client The “user agent,” in web-speak, also known as the user’s web browser. The browser’s job is to make well-formed HTTP requests to web servers, and to render the results for the user. The computer running the user’s web client should have a minimal role in authorization for your web application; if the web application is relying on the web browser to authorize (or authenticate) the user, then you should stop and reexamine your design because it’s virtually impossible to properly and securely perform authorization on the client. The most common authorization question that the browser needs to answer is, “does this user have permission to run a web browser and connect to the Internet?” Chances are excellent that the answer is yes; otherwise, this web client won’t be talking to your application at all.
Web client The “user agent,” in web-speak, also known as the user’s web browser. The browser’s job is to make well-formed HTTP requests to web servers, and to render the results for the user. The computer running the user’s web client should have a minimal role in authorization for your web application; if the web application is relying on the web browser to authorize (or authenticate) the user, then you should stop and reexamine your design because it’s virtually impossible to properly and securely perform authorization on the client. The most common authorization question that the browser needs to answer is, “does this user have permission to run a web browser and connect to the Internet?” Chances are excellent that the answer is yes; otherwise, this web client won’t be talking to your application at all.
![]() Front-end web server The web server running at the host address that the base URL for your web application resolves to. For example, if MyWebApplication.cxx resolves to the IPv4 address 207.102.99.100, then the front-end web server is the server listening for traffic at that address. The fundamental authorization question this server needs to answer is, “should I be talking to this remote computer at all?” Perhaps yes, but again, beware of granting hasty, blanket permission to anything. There may be reasons why your application (or a firewall) needs to filter the IP addresses of incoming requests. In many B2B scenarios, the IP addresses or address ranges of all legitimate clients are known in advance. Thus, you can significantly reduce the pool of potential attackers by applying basic IP restrictions. This is actually one of the most effective defenses for your web applications. AuthZ may also occur, as the web server must decide whether the client (most likely anonymous at this point) is allowed to access the resources being requested. In most cases, the web server is responsible for providing static content, while the dynamic content is returned by the application servers. Beyond that, the front-end web server must process the AuthN credentials presented by the web client when a user signs on.
Front-end web server The web server running at the host address that the base URL for your web application resolves to. For example, if MyWebApplication.cxx resolves to the IPv4 address 207.102.99.100, then the front-end web server is the server listening for traffic at that address. The fundamental authorization question this server needs to answer is, “should I be talking to this remote computer at all?” Perhaps yes, but again, beware of granting hasty, blanket permission to anything. There may be reasons why your application (or a firewall) needs to filter the IP addresses of incoming requests. In many B2B scenarios, the IP addresses or address ranges of all legitimate clients are known in advance. Thus, you can significantly reduce the pool of potential attackers by applying basic IP restrictions. This is actually one of the most effective defenses for your web applications. AuthZ may also occur, as the web server must decide whether the client (most likely anonymous at this point) is allowed to access the resources being requested. In most cases, the web server is responsible for providing static content, while the dynamic content is returned by the application servers. Beyond that, the front-end web server must process the AuthN credentials presented by the web client when a user signs on.
![]() Back-end application servers The cluster of one or more application servers which, collectively, share and service the aggregate traffic coming to the web application. For high-volume web applications that must serve many thousands of incoming requests per second, distributing the requests to a group of servers is often the only way to handle the load. These servers, being where the bulk of the application logic resides, are usually responsible for the lion’s share of AuthZ management. They do this by comparing the AuthN information validated by the front-end server, plus the resources named in the request URL or session state, against the permissions granted for that user.
Back-end application servers The cluster of one or more application servers which, collectively, share and service the aggregate traffic coming to the web application. For high-volume web applications that must serve many thousands of incoming requests per second, distributing the requests to a group of servers is often the only way to handle the load. These servers, being where the bulk of the application logic resides, are usually responsible for the lion’s share of AuthZ management. They do this by comparing the AuthN information validated by the front-end server, plus the resources named in the request URL or session state, against the permissions granted for that user.
![]() Back-end database The database component that holds the data resources managed by the web application. It could also be another data store such as an LDAP directory, although we will primarily consider traditional databases in this chapter. Depending on the overall application design and capabilities of the database software, the backend database may also participate in authorization decisions. For applications that use stored procedures to mediate all access to the underlying data resources, the database itself may take on some or all authorization duties in addition to managing the storing and fetching of data. In any case, all back-end databases must answer the authorization question, “does the client making this particular request have permission to use this database at all?” Databases that are being used for their stored procedure capabilities must also answer the questions relating to whether the remote user is allowed to execute the stored procedure being requested.
Back-end database The database component that holds the data resources managed by the web application. It could also be another data store such as an LDAP directory, although we will primarily consider traditional databases in this chapter. Depending on the overall application design and capabilities of the database software, the backend database may also participate in authorization decisions. For applications that use stored procedures to mediate all access to the underlying data resources, the database itself may take on some or all authorization duties in addition to managing the storing and fetching of data. In any case, all back-end databases must answer the authorization question, “does the client making this particular request have permission to use this database at all?” Databases that are being used for their stored procedure capabilities must also answer the questions relating to whether the remote user is allowed to execute the stored procedure being requested.
The details may vary from one web application to another—for example, a small-volume application may not have a server farm, or the web server and application server may reside on the same system—but the general picture holds. In the vertical direction, the layers can vary considerably depending on the overall software stack present on a particular computer. But the typical layers are as follows:
![]() User layer The topmost layer on a client system. For the web client machine, the user is the actual human being, as proxied by the user interface software, which translates mouse moves and keyboard clicks into commands.
User layer The topmost layer on a client system. For the web client machine, the user is the actual human being, as proxied by the user interface software, which translates mouse moves and keyboard clicks into commands.
![]() Application layer For a front-end web server, an application server, or a backend database, the topmost layer is likely the web server software, application server software, or database server software, respectively. Note that these application layers have a user associated with them as well, but not the same user as the human being sitting at the web client machine. For the application layer, the user is typically a local service account created for the purpose of applying local permissions to the web server, web application, or database server software. Take care not to confuse these two definitions of “user” within your web application’s design.
Application layer For a front-end web server, an application server, or a backend database, the topmost layer is likely the web server software, application server software, or database server software, respectively. Note that these application layers have a user associated with them as well, but not the same user as the human being sitting at the web client machine. For the application layer, the user is typically a local service account created for the purpose of applying local permissions to the web server, web application, or database server software. Take care not to confuse these two definitions of “user” within your web application’s design.
![]() Middleware layer Whatever components fit the definition of “the thing on top of which this part of the web application is running.” For the web-server layer, the middleware is likely to be a web server such as Microsoft’s Internet Information Server (IIS) or the open-source Apache server. On server-farm tiers, the middleware is often a Java servlet container or the .NET Framework. Additional web frameworks such as Ruby on Rails, Drupal, Joomla!, Spring, or any of dozens of others may also fall into this category. For the back-end database, the middleware layer may involve various components that allow the application servers to communicate with the backend database, especially if it’s using a special type of message format or queuing (for example, ODBC, RPC, SOA, ORB, or Web services).
Middleware layer Whatever components fit the definition of “the thing on top of which this part of the web application is running.” For the web-server layer, the middleware is likely to be a web server such as Microsoft’s Internet Information Server (IIS) or the open-source Apache server. On server-farm tiers, the middleware is often a Java servlet container or the .NET Framework. Additional web frameworks such as Ruby on Rails, Drupal, Joomla!, Spring, or any of dozens of others may also fall into this category. For the back-end database, the middleware layer may involve various components that allow the application servers to communicate with the backend database, especially if it’s using a special type of message format or queuing (for example, ODBC, RPC, SOA, ORB, or Web services).
![]() Operating system layer The low-level software that manages the physical resources of the computer: memory, disk space, CPU time, network bandwidth, and so on. In most applications, access to the file system is also mediated by the operating system layer.
Operating system layer The low-level software that manages the physical resources of the computer: memory, disk space, CPU time, network bandwidth, and so on. In most applications, access to the file system is also mediated by the operating system layer.
![]() Hardware layer The physical material of the computer. Although this is the layer where the actions of a user are “made real,” the hardware layer doesn’t interact strongly with a typical web application’s authorization system. For the most part, hardware does as it is told by the operating system. The notable exception here is the networking stack, which often does have some type of IP address filtering, port authorization, or other firewall-type security mechanisms mediating its behavior.
Hardware layer The physical material of the computer. Although this is the layer where the actions of a user are “made real,” the hardware layer doesn’t interact strongly with a typical web application’s authorization system. For the most part, hardware does as it is told by the operating system. The notable exception here is the networking stack, which often does have some type of IP address filtering, port authorization, or other firewall-type security mechanisms mediating its behavior.
As this book is about web application security, we won’t spend a lot of time discussing the nuances of the vertical direction. Just don’t forget that it exists, and that you should spend an appropriate amount of effort securing the vertical software stacks of, and physical access to, your front-end web server, server farm, and database systems.
Securing Web Application Authorization
If the preceding section scared you by showing just how many potential authorization points there are to deal with, don’t worry. In this section, we’ll look at the ones that are most specific to web applications and what you need to do about them. For this section, we will assume an overall architecture that matches the one shown in Figure 4-2.
Controls by Layer
Since the typical web application is structured into the horizontal layers shown in Figure 4-2, we’ll take things layer by layer.
Web Server Layer
In the web server layer, there are a number of checkpoints where authorization can be enforced.
IP Address Blacklisting At the front-line boundary of your web application, you can check the source IP address on the incoming request, and reject it if necessary. For example, you might deny requests from IP addresses that have tried to attack your server previously with a distributed denial-of-service attack (DDoS attack). For such requests, the application might return a “403 Forbidden” HTTP response, or might simply ignore the request without sending any response at all (also known as “dropping” the request).
IP Address Whitelisting Conversely, if your application is such that you know in advance the exact IP addresses or range of addresses that should ever be allowed to access the application, you can simply watch for those source IP numbers and reject everything else. This is not a common scenario for public-facing applications, but for applications on private networks (for example, a corporate intranet operating within a well-known set of IP addresses, or a B2B web application that will be used by people in predefined partner companies), it is a viable and highly effective strategy.
If this option is available to you, this is one of the single best things you can do to reduce your application’s overall attack surface; the fewer computers that can even see your application, the fewer can attack it. This is also a convenient means to limit access within a private network when the network topology follows useful organizational boundaries. For example, if all the computers in the Human Resources department at your company are known to reside on one single subnet, then IP filtering can be used to block access to an HR-only web portal from computers that aren’t located on the HR department’s subnet.
URL Authorization Some web servers (including Microsoft IIS, Apache, and nearly all Java web servers) and some web application frameworks provide facilities for limiting access to specific URLs. Through various settings or configuration files, you can specify which users and groups can access what URLs. Details of the configuration files vary from server to server, so check your server’s documentation, but they are generally similar to this web.config configuration file excerpt for IIS:

Operating System Authorization The operating system’s job is to manage (and thus, protect) the computer’s physical resources as well as logical resources exposed by the OS itself. Because the web server and/or web application must run in some context within the OS, and because such contexts are typically integrated into the same overall security framework as regular users, usually there is some kind of user account associated with your server and application. You can use the OS’s native security framework of file and directory permissions, security groups, ACLs, and so on, to govern what the web application’s account as a whole can and cannot do. The point here is largely defensive: if the server or web application process is compromised, well-designed and implemented OS controls can limit what the server’s process can access, and therefore, what damage an attacker can potentially do.
OS authorization is managed by system administrators. This is not typically a hurdle for web applications, because the ability to deploy and configure a web server and web application typically requires administrative access anyway. However, if the application is designed with a heavy reliance on OS authorization to provide access control on data resources that the application creates, modifies, and destroys, your application won’t be able to manage these permissions on its own. Thus, you are implicitly signing up for the ongoing work of having a human being with administrator privileges maintain the permissions on the objects the application uses.
You might say, “That’s easy, just let the application run as an administrator so it can manage its own permissions.” Yes, but that essentially negates the defensive purpose of OS authorization; see also the “principle of least privilege,” later in this chapter.
Application Server Layer
For web applications that use a server farm to handle high traffic levels, the basic strategies are the same as for the web server layer. You can use IP address blacklisting and whitelisting, URL authorization, and operating system authorization.
Application Compartmentalization Web applications that do use a server farm have an additional trick up their sleeves, though. If a whole farm of servers is handling traffic for your application, it is possible to segregate different areas of functionality within your application onto different physical machines. Particularly sensitive functionality can be placed onto specific machines, in order to be “walled off” from the bulk of the application. This enables you to employ custom IP blacklists or whitelists for those portions, different URL authorization rules, and different (presumably more stringent) OS authorizations for the most sensitive parts of your application.
Servlet and App Server Restrictions Web applications implemented on the Java platform can make use of the resource management configuration features built into that middleware stack. The configuration functionality is robust enough that you can actually implement features like users, user groups, roles, and an entire access control system in a purely declarative manner within configuration files such as the “web.xml” file and others.
Naturally, this is a complex undertaking and requires some care to do correctly. For example, here is an excerpt from a web.xml configuration file that purports to limit access to everything under the “/secure/*” path to only the HTTP “GET” and “POST” verbs:

This doesn’t work because it doesn’t take into account the default verb permissions, which are to allow access to any verbs for which there is no specific overriding access declaration. Anybody making a PUT or TRACE request, for example, would not be blocked. For more information on improperly configuring Java’s web.xml mechanism, see http://software-security.sans.org/blog/2010/08/11/security-misconfigurations-java-webxml-files.
Application Server Code When most people contemplate how to implement authorization within their web application, this is what they typically think of: using the business logic within the web application to implement authorization. And indeed, it is a powerful option. With the right code, you can implement practically any authorization scheme you can dream up. When it comes to application server code, there are three ways you can go.
![]() Use a built-in framework Many web development platforms come with some kind of built-in framework for implementing authorization. The developers of these platforms have already done the heavy lifting for you in terms of overall design and testing. What is left for you is the comparatively much simpler task of appropriately plugging your application software into that framework. Microsoft’s .NET platform has built-in security modules for role-based security. The ASP.NET platform has a Membership framework that is primarily intended for form-based AuthN, but does allow you to validate and manage users through prebuilt libraries. ASP.NET also provides role-based management for AuthZ; see http://msdn.microsoft.com/en-us/library/5k850zwb.aspx for more.
Use a built-in framework Many web development platforms come with some kind of built-in framework for implementing authorization. The developers of these platforms have already done the heavy lifting for you in terms of overall design and testing. What is left for you is the comparatively much simpler task of appropriately plugging your application software into that framework. Microsoft’s .NET platform has built-in security modules for role-based security. The ASP.NET platform has a Membership framework that is primarily intended for form-based AuthN, but does allow you to validate and manage users through prebuilt libraries. ASP.NET also provides role-based management for AuthZ; see http://msdn.microsoft.com/en-us/library/5k850zwb.aspx for more.
![]() Use an existing, open plug-in AuthZ module There are a number of AuthZ modules that plug in to various web development frameworks in order to provide authorization features not present (or deemed insufficient) within the frameworks themselves. These include OAuth, BBAuth, AuthSub, and others. Check the documentation for your web development framework or ask around on community support forums for your framework; the ecosystem of security modules is constantly evolving and improving, so by the time you read this, there may well be better options available than those at the time this book went to press.
Use an existing, open plug-in AuthZ module There are a number of AuthZ modules that plug in to various web development frameworks in order to provide authorization features not present (or deemed insufficient) within the frameworks themselves. These include OAuth, BBAuth, AuthSub, and others. Check the documentation for your web development framework or ask around on community support forums for your framework; the ecosystem of security modules is constantly evolving and improving, so by the time you read this, there may well be better options available than those at the time this book went to press.
![]() Develop a custom framework Again, if you dream it, you can potentially build it. But just because you can doesn’t mean you should. Designing and developing a proper authorization framework is a significant undertaking. If at all possible, use an existing framework or plug-in module. We’ll talk more about custom frameworks later in this chapter.
Develop a custom framework Again, if you dream it, you can potentially build it. But just because you can doesn’t mean you should. Designing and developing a proper authorization framework is a significant undertaking. If at all possible, use an existing framework or plug-in module. We’ll talk more about custom frameworks later in this chapter.
Code Access Security Code access security, or CAS, is the idea of performing AuthZ on pieces of code themselves, to determine whether the code is allowed to run with the capabilities it wishes to use. It is related to the idea of assessing whether a user has execute permission for some piece of functionality, but with the difference that CAS treats a piece of code as if it were a subject on its own. CAS evaluates code in much the same way that AuthZ evaluates a user.
CAS is not often applicable to web applications, but it’s nice to know that it’s a technique you can apply if necessary. Most web applications have their units of functionality, all their code, baked into them ahead of time. Rare is the web application that needs to dynamically load and execute code, and rarer still is the web application that needs to do so for code that comes from a potentially untrusted source.
CAS is typically used to prevent uploaded or downloaded components from performing dangerous actions; to place potentially dangerous code in an isolated “sandbox” environment where it can do little damage if it turns out to be rogue code; to place CAS-approved hosted code in an isolated environment where it cannot affect (or be affected by) other hosted code; to limit the power of your own components as a defensive measure in case your components are compromised by malicious code.
The full details of how to implement CAS are beyond the scope of this book, but in short, CAS evaluates available evidence such as the code’s origin, its publisher, its assembly’s strong name (for .NET), its checksum, to determine whether the code should be run. Properly implemented, CAS accounts for these factors regardless of any user identities that are involved in the action that led to invoking CAS. That is, a system that uses CAS should not even run code loaded by someone with administrative permissions unless that code also passes the CAS system’s evaluations.
Database Server Layer
Practically every web application of any substance has, on its back end, a database. And databases are robust tools that have evolved over the past several decades to be capable of doing quite powerful things. A modern database is almost like an operating system in its own right, managing the resources of the underlying data store. Databases such as Microsoft’s SQL Server, Oracle, and others have their own implementations of concepts like users, roles, permissions, and so forth. Thus, it is not surprising that a web application can take advantage of the database’s rich feature set to implement part of the application’s authorization scheme.
One could write a whole book on how to do database security for a front-end application (and indeed, many people already have). We won’t repeat that material here, as it is all essentially the same for a web application as for a traditional desktop or intranet-based application. Indeed, the database itself doesn’t really care that your application happens to be a web application accepting requests from remote users, rather than a traditional application with a user sitting right there at the system’s own console. The high-level guidance is as follows:
![]() Wrap every request to create, read, update, or delete data within properly parameterized stored procedures. This means that you will not have your web application generating SQL query strings and submitting them to the database directly. There will be no statements like SELECT serum_hdl FROM bloodwork WHERE patient_id = “ + requested_patient_id” in your health portal application code. Instead, you will carefully list every action the web application might need to make against the database, and map those to a set of stored procedures that implement the queries you need. Your application will invoke a get_patient_serum_hdl (patient_id) stored procedure, and will leave it to the code in the stored procedure to work out what that means for a particular patient_id value. In this manner, you can revoke direct access permissions from all the tables in the database, leaving the stored procedures as the only entities that have access to those tables. This greatly reduces the database’s overall attack surface.
Wrap every request to create, read, update, or delete data within properly parameterized stored procedures. This means that you will not have your web application generating SQL query strings and submitting them to the database directly. There will be no statements like SELECT serum_hdl FROM bloodwork WHERE patient_id = “ + requested_patient_id” in your health portal application code. Instead, you will carefully list every action the web application might need to make against the database, and map those to a set of stored procedures that implement the queries you need. Your application will invoke a get_patient_serum_hdl (patient_id) stored procedure, and will leave it to the code in the stored procedure to work out what that means for a particular patient_id value. In this manner, you can revoke direct access permissions from all the tables in the database, leaving the stored procedures as the only entities that have access to those tables. This greatly reduces the database’s overall attack surface.
![]() Map all the interactions between the application and the database to a set of database user accounts, and reduce the permissions those accounts have to the bare minimum. Ideally, such accounts should not have any database permissions higher than the ordinary “user” role.
Map all the interactions between the application and the database to a set of database user accounts, and reduce the permissions those accounts have to the bare minimum. Ideally, such accounts should not have any database permissions higher than the ordinary “user” role.
Where Should You Put Authorization Logic?
As we’ve seen, you can put your authorization logic, the code that enforces those permission policy decisions, into the web application itself or into the database layer, or even both, if you really want to. Which is best?
Most applications put the code in the web application. Not necessarily because it’s the best thing to do, but because it’s the most obvious thing to do. They give the application all the smarts to determine who can and cannot do what, and then grant the application itself full and unfettered access to the database. This simplifies the design and development process, because there’s only one body of code where authorization needs to be considered. But it complicates deployment and maintenance, because in practice web server administrators and database administrators are often different people.
But does it make sense for the data store—the place where the application’s crown jewels are kept, the data the application manages—to have its doors left wide open? Perhaps not, which is why some web application designers put all the authorization logic into the database layer. They use stored procedures, they limit permissions to database tables, and they use the other mechanisms discussed earlier.
Note that stored procedures can contain both business logic and application logic. The business logic is essentially in the use of a stored procedure to map between high-level conceptual operations—for example, “get the names of all employees who report to a certain vice-president, who are themselves managers of other employees”—to a potentially complex set of database queries. In this regard, stored procedures act as an application-specific abstraction layer over the database, so the application does not need to have any knowledge whatsoever about how the data is organized within the database.
Stored procedures can contain authorization logic inasmuch as, during the process of breaking down an incoming request into a complex SQL join statement or what-have-you, the stored procedure can also make subqueries about the relationships among users, resources, and permissions. That is, before running that query to find all the managers who report under some vice president, the stored procedure can first figure out whether the user making the request is allowed to do so.
So, application logic or database layer? Neither is necessarily right or wrong. Just make sure you’re making the right choice for reasons that have to do with actual security, rather than short-term convenience or out of an unwillingness to think beyond what might at first seem obvious. For a good reference on this subject, see the following article on the Microsoft MSDN web site, http://msdn.microsoft.com/en-us/library/ee817656.aspx. Also, see Chapter 7 and its section on setting database permissions.
Custom Authorization Mechanisms
So you’re thinking about writing a custom authorization mechanism? First, let me try to scare you off. Security code of any type is notoriously difficult to get right, and attackers are notoriously clever about finding and exploiting hidden weaknesses that application designers never thought of.
If at all possible, strive to use a built-in framework or an existing plug-in AuthZ module instead. Not only will this save you a lot of time, effort, and expense in terms of design and development work, but it allows you to benefit from the expertise of the security experts who developed those frameworks and modules. It also gets you the peace of mind of knowing that you’re using a code base that has had considerably more real-world testing than you are likely to be able to apply to your own custom code. And when it comes to the intricacies of integrating that code into your application, the mainstream frameworks and modules have both paid support and lively Internet forums for community support.
If you reinvent the wheel, you’re on your own. You get none of those benefits and will probably end up with a wheel that’s less round than the off-the-shelf ones.
But sometimes it isn’t possible to use an off-the-shelf component. If you do need to roll your own, it’s important to know how to do it right. If that’s you, read on.
The 3×3 Model of Authorization
Any authorization framework, whether pre-existing or custom, should be designed around a three-by-three matrix of factors (also referred to as a lattice). Considering the full set of pairings between the items on each axis of the matrix gives you a systematic basis for designing your authorization framework. It ensures you will consider all the critical authorization points in your application.
Why is this necessary? Because the alternative is having your designers brainstorm a list of every place in the application that needs to consider authorization. It’s all too easy to simply forget an important area, thus leaving part of your application open to attack. The last thing you want is for a haphazard design process to turn your custom authorization framework into a game of Russian roulette—“gee, I hope we thought of everything!”
Figure 4-3 illustrates a diagram of a 3×3 authorization system in action.
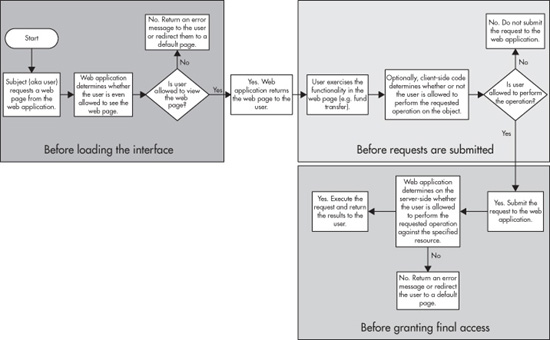
Figure 4-3 A 3×3 authorization system in action
What The first axis in the 3×3 model matrix is the “what” axis. It considers the categories of items that participate in authorization. We have given extensive consideration to these “what” elements earlier in this chapter, so it is sufficient simply to remind ourselves of what they are here.
![]() Users/subjects Any entity that’s making a request against a resource.
Users/subjects Any entity that’s making a request against a resource.
![]() Operations The functionality resources in your web application; the specific actions that subjects can take.
Operations The functionality resources in your web application; the specific actions that subjects can take.
![]() Objects These are the resources managed by your web application, the underlying things, such as data, that your web application cares about.
Objects These are the resources managed by your web application, the underlying things, such as data, that your web application cares about.
When The second axis is the “when” axis. It considers the times when permission checks need to happen and approvals granted or denied. To a degree, this axis also captures where these checks need to take place, but as any interaction between a subject and a web application can be serialized in time, where and when are more or less equivalent.
Before loading the interface. Web applications have their user interfaces distributed among a collection of HTML pages containing text, images, and links, and HTML forms that users can interact with, but which are not all loaded at once. Consequently, the mere act of a user seeing the application’s UI is spread out in time. The application does not need to make a one-time, all-or-nothing decision to allow users to see its entire interface.
Thus, this particular “when” is pretty much what it sounds like. “Before loading the interface” means that your web application will perform authorization checks before ever sending that part of the interface to the user’s web browser. There are two main ways you can do this (and in my opinion, you should do both). As an example, let’s consider an online banking application, and the authorization checks made before loading the UI for transferring money.
To get to the page where the actual money transfer HTML form is, the user is going to need a link to it from some other page. For example, if the user is on the “view” page for a particular account, there could be a navigation bar on one side of the page containing links to all the actions the user can take for that account. At the time the web application generates the HTML for this view, it could perform AuthZ checks with respect to all those actions. Is the user allowed to see the transaction history? Is the user allowed to rename the account? Is the user allowed to move money out of the account? If the user was not authorized to transfer money out of the account (perhaps the user is a bank auditor, not the owner of the account, whose job should only involve looking at accounts but never modifying them), then the web application could simply omit the link to the transfer money form. If the subject can’t get to the form, he/she/it can’t easily attempt to transfer money.
Filtering an application’s navigation URLs in that manner is a form of hiding the very existence of sensitive functionality from users who aren’t authorized to perform those functions. And it is a helpful step, but it is not sufficient. As we’ll see in more detail when we talk about forceful browsing, there are simply too many ways for a user to discover the existence of such UI elements—ways that are wholly out of your control. For example, that same bank auditor may well also have a personal account at that same bank. When the auditor is at home, using the web application to do her own personal online banking, she’ll discover the existence of the transfer money function, and could write down the URL for how to get there. When she is next at work, looking at someone else’s account, she could manually type in that URL and potentially gain access to the transfer money function for the account she is auditing. And hm, I wonder where she might transfer that money to?
Thus, when the web client makes a request for the URL of the form that embodies the UI for that function, the web application should first perform the exact same authorization check that it did when it filtered the links out of the earlier “view” page. If the check passes, fine; load the form and send it to the user’s browser. But if the check fails, give an HTTP response (401 Unauthorized, 403 Forbidden, or 404 Not Found; true, some of these are lies, but telling the truth to a potential attacker? It only helps them work around your system), redirect them back to the referring page, terminate their session, or take whatever other secure failure action is appropriate.
Before requests are submitted. Modern web browsers can do more than just render HTML code and make HTTP requests. They can also run code themselves, usually JavaScript, to create various interactive effects on a web page that don’t require interaction with the server. This creates the possibility of using client-side code to implement additional authorization checking.
But before we talk about that, first, a huge caveat: Client-side AuthZ is only for performance purposes, and offers zero protection against a determined attacker. Read that again: zero. Client-side code can deter casual attackers driven by curiosity more than actual malice, but for someone intent on cracking your system, client-side checks are trivial to bypass. They exist mainly to prevent ordinary, honest users from accidentally doing things they aren’t allowed to do, thus saving your server from dealing with requests that will only be denied.
Client-side code can also filter the links or form controls present on a web page, just as discussed in the previous section. If they can’t see it, they can’t click it. That doesn’t mean the links and controls aren’t there—they are, if your application sent them as part of the HTML for the page the user is viewing—they’re just hidden from view through manipulation of Cascading Style Sheet (CSS) properties, or of the web page’s Document Object Model (DOM). An attacker will simply reverse-engineer the raw HTML to figure out what those hidden links and forms were anyway. But a casual user won’t bother or won’t even know that they could do that.
Client-side code can also defend against a user interacting with UI elements at the wrong time. For example, this code can disable the “submit” button on a form if the user has not filled out all the required fields of the form, or if any fields have improper values, and so on. Again, all this does is prevent casual users from submitting malformed requests. An attacker who wants to submit improperly filled-out forms will simply fake the submit request with arbitrary values.
Think of client-side code like putting yellow warning tape around a freshly poured section of sidewalk. The tape does nothing to stop anybody who is determined to scrawl their name in the wet cement, but it does make everyone aware that such actions are not sanctioned.
Client-Side Attack
Anyone who has booked their own flight on an airline’s web site recently has probably experienced a web page where they can pick what seats they want to reserve. There is often a nice little map of the seating layout, one that makes use of complicated CSS and JavaScript tricks to position all the seats just so on the map, to color-code which ones are available and which are not, and to allow you to select which ones you want to reserve.
Perhaps the airline allocates rows 1 through 4 for members of their Frequent Flyer program. It’s a nice amenity, because when you’re sitting near the front of the plane, you can de-plane several minutes sooner. It beats sitting in the back and having to wait for the 150 people sitting forward of you to lug their junk out from under the seats and overhead bins and make their way off the plane.
Let’s say the last time you flew this airline, it was for business and because your company was paying for it, you got to reserve one of those forward seats. But now you’re flying coach on your own nickel and when you go to select your seat, you see that the map shows that the plane is barely full at all (most of the seats are shown as available), except for the first four rows, which are all shown as unavailable.
Now, that client-side scripting code probably isn’t making Ajax requests to the server to verify the seat availability every time you click a seat. Chances are, when you click “submit,” the browser is going to send whatever seat number you can convince it to send. No problem! Just use a browser extension like Firebug for the Firefox browser to locate the code that handles the form’s submit button, and edit it to hard-code whatever seat-number you want. Seat 1A, perhaps, the window seat closest to the door. If 1A ends up double-booked, you figure you’ll just make sure to get to the airport early so you can check in before whatever poor sucker thought he was going to get that seat.
Alternately, you could select any arbitrary seat, like 32F way in the back, submit the form, but intercept the resulting HTTP request before it leaves the computer. This would require more extensive setup on the user’s part, but is certainly possible. You parse through the request to find the string “32F” attached to some form field that looks like it represents the seat number, change it to 1A, and let the request proceed on to the server.
Will this actually work, though? It will, if the web application blindly trusts that the client-side JavaScript code has done the job of managing the user’s seat selection process. Obviously, such trust is misplaced. Client-side checks are helpful for keeping most users honest and for improving overall system performance by keeping most bad requests from reaching the server. But they are not a substitute for actual authorization checks elsewhere in the 3×3 model.
Before granting final access. The most important time to perform authorization checks, and the most important place to perform them, is on the server immediately before granting final access to anything. Note that the particular server in question here can be either the web application server, the database server, or both, depending on how you decided to allocate authorization duties between those two server elements.
The strongest guarantees of security come from server-side authorization, precisely because it is the server that mediates interaction with the resources managed by the application. The server is thus the last line of defense for those resources. The further out from the data store a component is, the more vulnerable it is to compromise, which is why servers should fundamentally not trust any subject until that subject proves it is trustworthy.
Time of check to time of use. The very best time to make server-side authorization checks is as close as possible to the time when an action is to be taken. Ideally, the server would make an authorization check, grant access, and the action thus authorized would immediately follow. The reason for this is what is called the “time of check to time of use” problem, or TOCTTOU for short (also sometimes seen as just TOCTOU). The idea is to minimize the interval between these two times, because an overly lengthy interval can create the potential for abuse.
For web applications, TOCTTOU can show up in a couple of different forms. First, there is the possibility of a different person using an authenticated and authorized user’s account without the account owner’s permission. This is like leaving yourself logged on to an application like Facebook while you go out to a restaurant for dinner, only to find when you return that your roommate has used your Facebook account to break up with your sweetheart on your behalf.
Another concern is that a subject’s permissions can change. If a permission is changed from “allow” to “deny,” then the interval between the time of check to the time of use represents a window in which the subject could potentially do something he or she is no longer allowed to do. See the example in the following section, “TOCTTOU Exploit,” for a scenario illustrating this.
At the very least, a web application server should guarantee some upper limit on the TOCTTOU interval. That limit represents a time beyond which the server isn’t even willing to trust its own prior authorization check. A secure server is a paranoid server (although the converse does not necessarily hold). What you don’t want is to grant a privilege, and then let the subject hold on to that privilege like a golden ticket for as long as they want before using it.
TOCTTOU Exploit
A married couple is divorcing. They and their lawyers are in a conference room, dividing up their joint assets. But the husband comes into the room with a sneaky plan. Unknown to anyone else, before he left his new apartment, he signed his personal computer on to the online banking system for the bank where the couple holds their joint account. He has loaded up the page for funds transfer. The web application has dutifully checked his permissions before loading that UI for him, has discovered that he is indeed still an account holder of record, and all is well. And there the transfer form sits, on his screen. He leaves it there, disables his screen saver and auto-logout, and heads out to the settlement meeting.
In the meeting, he generously agrees that she can keep the account; they’ll go to the bank afterward to have his name taken off. She can just write him a check for half the remaining balance, which he will deposit into the new account he has created at a bank closer to his new apartment. The suggestion seems reasonable, so the wife and the lawyers breathe a sigh of relief at avoiding a conflict over such a touchy subject. They move on to arguing about the furniture.
After the meeting, the couple goes to the bank as agreed. The bank removes him from the list of account holders, and she writes him a check for $15,668.50, half of what was in their joint account. They shake hands and go their merry way. He, however, does not go to his bank. He goes to his apartment, fills out the waiting funds transfer form that was loaded several hours prior, and transfers exactly $15,668.50 to the account at his new bank.
Then he waits a couple of weeks until the end of the month, for the bank to issue her a statement, which shows her what she expects: a withdrawal in the amount of $15,668.50 on the day they signed the papers. Only then does he deposit the still perfectly valid check into his new bank account. Thanks to an overly generous TOCTTOU policy, he ends up with 100% of what had been their joint assets, rather than his fair share.
Automatically Invalidating the Session
The most common strategy for dealing with the TOCTTOU problem in the web world is through session management. We’ll see much more on session management later, but the basic idea is that when a user authenticates, they are issued some kind of transient session identifier. The validity of that identifier becomes a part of all authorization checks the web application subsequently makes. TOCTTOU problems can be avoided by automatically invalidating the session on the basis of various criteria. A session that has been idle for too long can be expired—thus preventing your roommate from breaking you up with your sweetheart when you go out to dinner without logging off. A session that has simply been in existence for too long can be expired, thus preventing a customer whose online newspaper subscription is about to expire from continuing to use the newspaper’s web site simply by never logging out. A session can be forcibly expired if the timestamp on the permission records for the user is newer than the creation timestamp of the session ID, thus indicating that the user’s permissions have changed, and preventing users from performing actions for which their permission has just been revoked.
Web Authorization Best Practices
When designing or implementing your own authorization system, the following best practices should be taken into account.
Failing Closed
Design your application such that if anything fails, it will fail into a secure state. The result of bad input, a bug raising an unexpected exception within your application code, and so on, should always result in the application behaving in the most secure manner possible. Commonly this means that functionality is not executed or data is not returned, which in turn usually means establishing strict default permissions. Remember to “just say no.” Consider configuring the topmost exception-handling mechanisms in your web application framework to take some kind of known-safe action when encountering an unexpected, unhandled error, for example, immediately invalidating the user’s session ID and redirecting the user’s browser back to the web application’s root URL. From the user’s perspective, “restart everything on failure of anything” may seem like a brutal and inconvenient policy, but it’s better than allowing unexpected failures to turn into exploitable security holes.
Operating with Least Privilege
Operating with least privilege means designing your web application to work with the fewest possible rights and permissions while still allowing the application to accomplish what it needs to do. Commonly this means your web application runs on the host operating system as a restricted or normal user process, rather than as an administrator process. That way, if an attacker does hijack your application’s code, at least it won’t be given carte blanche to do anything it wants on the host system. It means designing your application’s internal security model such that users can be given exactly the permissions they need to do whatever they need to do, but no more. It means having the web application access the database through a low-privilege account that does not have schema-modification privileges. This might not always be exactly the model, but the idea is that the bare minimum rights are granted to each user or account.
It also means not making lazy authorization policy decisions during maintenance and use of the application. For example, if one user in a particular role ends up needing special permission to do something that role can’t normally do, “least privilege” doesn’t mean granting permission to perform that action to the entire role. Instead, it means either elevating that specific user to a different role if there is an appropriate one available, creating a new role with appropriate permissions and putting the user in that role, or (probably best of all) denying the permission request entirely and delegating the high-privilege task to someone whose role does permit it.
Separating Duties
Business user accounts should not be administrators, and vice versa. Regular users and administrators have very different jobs, and perform very different kinds of actions within the application. A regular user should never need to perform administrative actions. If they do, then they should have an administrative account and use that instead. Likewise, if an administrator ever needs to perform regular user actions, let him use a separate user account for that purpose. Use dedicated, role-based accounts to carefully segregate and limit the number of people who can access administrative functionality. Similarly, anonymous or guest users should not be given the same rights as authenticated users.
Defining Strong Policies
Even the best-designed authorization system will fail if it is not used correctly. Define strong permission policies up front, even to the point of paranoia, and make sure they are carried out. This cannot be stressed strongly enough. Security exploits in the wild are just as likely to be due to a misapplication of well-intentioned policies within a perfectly good authorization mechanism, as they are to be due to a bona fide bug in the code or other such flaw. Vulnerabilities introduced through human error are the bane of security systems.
Keeping Accounts Unique
Don’t let users share accounts. Ever. Make sure every user has a unique account—or more than one, as in the case of administrators who sometimes also need to be users. If you let users share accounts, then the process of authorization becomes virtually impossible to do rigorously. How is the system to know which human being is using the account at any given moment? Also, if any incidents do happen with a shared account, it becomes nearly impossible to audit and investigate in order to find out who was responsible.
Authorizing on Every Request
A good practice is for the web application to perform a final authorization check immediately before performing any action on the user’s behalf. This necessitates that the application performs at least one authorization check on every request that comes into the system. Every page that is loaded, every piece of data that is fetched for display, every function the user requests to run: all of these should be checked, every time. Authorizing every request also prevents security problems due to forceful browsing, which is discussed later in this chapter.
Centralizing the Authorization Mechanism
Design a clean authorization architecture that can be easily shared across the entire application. A common mistake is to craft some authentication code for use in one spot in an application, then copy that same code to everywhere else in the application that needs it. That’s a poor practice, because if a vulnerability is ever discovered in that code, it must then be updated in every place it is used. Factor your authorization code into a library that can be easily called wherever needed. That way, any bug fixes or updates can be applied to the shared implementation, and will immediately benefit the entire web application.
Minimizing Custom Authorization Code
As discussed earlier, writing custom authorization code is difficult, expensive, and prone to give you worse results than if you used a reliable, well-tested, off-the-shelf authorization module. Use it if you need to, but minimize the amount of custom AuthZ code you write.
Protecting Static Resources
Be very cautious about trusting the host operating system’s file system with anything. Ideally, your application should generate any highly sensitive content dynamically, at the moment of request. This is preferable to having that content stored persistently on disk, because anyone who manages to get access to the underlying operating system can easily find that content (or steal it, or modify it, and so on). The literature is full of examples of security exploits against web applications whose own authorization mechanisms were just fine because the attacker was able to bypass the application entirely and find the sensitive data just sitting there in the host computer’s file system.
If you do have to use the file system for persistent storage, implement authorization checks to prevent anonymous access. Use random filenames or GUIDs as filenames if possible, as attackers are likely to search the file system for files whose names contain obvious strings such as “users,” “accounts,” “password,” and so forth.
And finally, do not store sensitive static content in directory paths that are part of the web application’s own file hierarchy. This means that there should be no URL path that maps to the underlying directory path where the sensitive content is stored. Instead, you should store this content in a directory that is fully outside of the application’s directory structure, and proxy the application’s access to that data through a handler that can properly authorize and log any access to the file. On the ASP.NET platform, methods like HTTPResponse.WriteFile() can perform this type of functionality.
Further, if you’re storing data in the file system, design the access such that no part of the final filename or path to the file comes from user input. Allowing the user to specify any part of the filename opens the application up to potential injection attacks, due to the ability of most file systems to support relative path components such as “..” within a pathname.
Avoiding Insecure Client-Side Authorization Tokens
Don’t use insecure client-side tokens—that is, data that is stored at the web client and submitted with each request—to hold authorization data of any kind. It is often tempting for web developers to take this route, because the mechanisms for client-side token storage (cookies and the like) are incredibly simple to use and thus avoid the complexity of implementing server-side sessions and session management.
But don’t. Just don’t do it. Remember, you don’t control the web client. The attacker controls the web client, and the attacker can do anything he wants to inspect, modify, forge, and otherwise lie about the existence or contents of any token your application establishes.
Cryptographically secured client-side tokens are fine—ones that are made opaque through strong encryption and where the decryption keys are not available to the client. It’s the unencrypted tokens that are insecure, and which you should banish from your application entirely.
IMHO
Firesheep is a tool that highlights the weakness of unencrypted cookies. The use of unencrypted cookies is such a serious security vulnerability that they have led some security activists to exploit them on purpose, merely to demonstrate how insecure they really are. Firesheep is a browser extension for the Firefox browser, which literally makes it point-and-click easy for someone to steal session IDs from certain popular social networking web sites and impersonate other users.
Firesheep works by packet sniffing. It watches for the unencrypted session ID values stored in cookies to pass by on whatever section of Internet traffic it can see, captures those values, and presents them to the attacker within the attacker’s web browser along with the victim’s name. When the attacker double-clicks on a victim’s name, Firesheep substitutes the stolen session ID value in place of its own, which allows the attacker to impersonate the victim.
There is no way of knowing how many victims have had their social networking identities hijacked in this manner. What is known is that Firesheep was so effective in demonstrating the egregious insecurity in the designs of several social networking sites that it was a major force in causing those sites to make the switch to using HTTPS encryption for traffic—as they should have been doing all along.
Using Server-Side Authorization
Authorization checks should happen on the server and never solely on the client. Remember, client-side authorization code is never trustworthy. It is useful for performance UI interactivity reasons, but should never be the only line of defense. Client-side checks are simply too easy to bypass.
Never trust a user to provide an accurate accounting of that user’s roles or permissions. A secure server is a paranoid server. Servers should rely on only trusted data sources, such as LDAP or a back-end database, to provide a user’s access rights at run time. Once AuthN has been accomplished, the server should control all information related to AuthZ decisions.
On a request-by-request basis, the only information the user—or rather, the web client—should supply is an opaque session identifier—that is, a secure client-side authorization token. The web application will compare the identifier with its list of unexpired, active session IDs to determine that the session is genuine. This also establishes the identity of the user associated with the request, so the application can look up the user’s access rights in order to authorize the request.
The key is to guarantee that the client does not tell the server what access rights it possesses. Instead, the user proves his, her, or its identity, and the server correlates that identity with access rights from a trusted source. This strategy avoids trusting the client, which is something you can never do if you want to be secure, because clients can’t be trusted.
What doesn’t work is to use tricks like hidden form fields, URL parameters, and anything else that is sent to the client, because again, attackers can trivially see, steal, reverse-engineer, modify, or replay such values. Consequently, access rights should always be stored and maintained on the server.
Attacks Against Authorization
Now that we know the best practices behind the design and implementation of authorization, it’s worth understanding the different types of attacks that these practices are intended to defend against.
Forceful Browsing
Forceful browsing occurs when a user manually enters the URL for a page that is not directly navigable from wherever they happen to be in the application’s user interface. Forceful browsing exploits can occur because of a common, but incorrect, assumption on the part of web application designers: designers assume that users couldn’t have reached the URL unless they had permission to use the functions exposed by this URL. That’s simply not true.
For example, an attacker might use a cross-site scripting vulnerability in a completely unrelated web site to obtain a user’s browsing history. That browsing history might contain any number of URLs to pages within your web application, allowing the attacker to now map out large chunks of your web application’s UI without ever even visiting your site. Similarly, attackers can conduct forceful browsing by guessing the addresses of pages on your site; URLs such as “main.html” or “admin.php” are both easily guessable and surprisingly common.
This is the key reason for one of those best practices from earlier: authorizing on every request. Failing to authorize every HTTP request that comes in to the application represents a potential failure of “security through obscurity,” which is tantamount to no security at all. Remember, access to protected resources must always be authorized.
Input Authorization/Parameter Tampering
Input authorization, or parameter tampering, occurs when an attacker or malicious user alters the parameters of a request before the request reaches the web application. Any data stored in URL parameters, cookies, or form fields is subject to tampering. Consequently, reliance on those values to conform to what the web application expects is dangerous.
For example, let’s say a corporation’s management application uses hidden form fields to track a user’s permissions. Employee Dan has just been promoted to management and now has two employees reporting to him. He receives training on the company’s HR application, through which he can submit performance review data for his employees, give them raises and bonuses, and so on.
The end of the year rolls around, and Dan finds himself short on cash. As he’s assigning holiday bonus amounts to his employees, he decides to see if he can’t put a little something in his own stocking. The bonus amount is an obvious entry field on the form, and there is a handy drop-down list of the employees that report to Dan for him to pick from. He inspects the HTML code for the form, and discovers a hidden form field called “managerlevel,” for which his value is “1.” And he sees that the employee drop-down list maps to an “employeeid” field, which contains the employee ID numbers of Dan’s two direct reports. Dan remembers from the training session hearing the trainer talk about level 1 managers, level 2 managers, and so forth.
Right there in the live web page on his browser, Dan uses Firebug to alter the value of the hidden managerlevel form field to “2.” He alters the drop-down list to contain himself as one of the options, fills out a cool twenty-thousand-dollar bonus, and submits the form. Dan proceeds to enjoy a very merry holiday season in Tahiti on the company dime, because the web application naively trusted that no one would ever modify the value in the hidden field.
Input authorization and parameter tampering attacks rely on an application’s failure to follow the best practice of mistrusting everybody. Dan’s company’s HR application should have relied on fetching Dan’s manager level value out of a trusted database, rather than trusting Dan’s web browser to provide (and protect) that information.
Every HTTP request contains a few lines of header text that contain metadata about the request: typically, the “User Agent” (what browser made the request), the URL of the referring page, the user’s preferred language (for sites that do internationalization), and of course, cookies. HTTP responses contain headers too, although those aren’t relevant for this discussion.
Most web applications ignore the data within the header, with the exception of cookies that hold session ID values. This is good, because the header is generated by the web client, which the web application should never trust. For example, a web developer might be tempted to use the value in the “Referer” field (yes, the HTTP protocol really does misspell the name of this field) to verify that the request originated at a URL that is also part of the same application. The developer might reason that this offers some protection against forceful browsing (see the next section, “Cross-Site Request Forgery”), because if an attacker entered a target URL to somewhere deep within the application directly, the Referer header would be set to “localhost” or “127.0.0.1” or some other such value. Not true. An attacker can easily forge the Referer header to contain any value at all.
Also beware of the “Accept-Language” header, used for internationalization. By design, this header is supposed to contain language identifiers that the application can use to look up translated strings or translated versions of web pages. The danger is in using the value of the Accept-Language header directly as an input to a database query. Doing so opens the application up to SQL injection attacks, which can be devastating to the database.
Cross-Site Request Forgery (CSRF)
Cross-site request forgery (CSRF) occurs when an attacker tricks a victim’s browser into making an HTTP request against a target web application. Usually, the victim is already authenticated to the target site. The attacker is taking advantage of the trust that the target web application has for the web client of the victim, on the basis of the victim holding a valid session ID for the target web application.
Let us imagine, as before, that an attacker has stolen Joe’s web browsing history by means of a cross-site scripting attack. The attacker discovers that Joe does online banking through his bank’s web interface, and discovers the URLs for the funds transfer function, which Joe recently used to pay for a vintage 1957 Chevy Bel Air side-mirror he bought on eBay. The attacker also notices that Joe uses a chat forum web site for vintage car restorers. The attacker crafts a posting on that forum, containing the following HTML fragment:
This posting is designed specifically to lure Joe’s browser into making a request for what it believes to be an image, when in fact it is a request for a funds transfer. If Joe loads the posting, and the bank’s web application is not designed to protect against CSRF attacks, then Joe is going to be out five hundred bucks. From the bank’s web application’s perspective, it received what appears to be a legitimate transfer request from Joe’s browser. Moral of the story? Make sure that sensitive operations are properly authorized (or that they require additional authorization beyond a valid session ID), and that your application aggressively expires idle or overly long sessions.