
Chapter Topics
In this chapter, we will discuss how to take code written externally and integrate that functionality into the Python programming environment. We will first give you motivation for doing this, then take you through the step-by-step process on how to do it. We should point out, though, that because extensions are primarily done in the C language, all of the example code you will see in this section is pure C but is easily portable to C++.
In general, any code that you write that can be integrated or imported into another Python script can be considered an extension. This new code can be written in pure Python or in a compiled language like C and C++ (or Java for Jython and C# or VisualBasic.NET for IronPython).
One great feature of Python is that its extensions interact with the interpreter in exactly the same way as the regular Python modules. Python was designed so that the abstraction of module import hides the underlying implementation details from the code that uses such extensions. Unless the client programmer searches the file system, he or she simply cannot tell whether a module is written in Python or in a compiled language.
Core Note: Creating extensions on different platforms
We will note here that extensions are generally available in a development environment where you compile your own Python interpreter. There is a subtle relationship between manual compilation versus obtaining the binaries. Although compilation may be a bit trickier than just downloading and installing binaries, you have the most flexibility in customizing the version of Python you are using. If you intend to create extensions, you should perform this task in a similar environment.
The examples in this chapter are built on a Unix-based system (which usually comes with a compilers), but, assuming you do have access to a C/C++ (or Java) compiler and a Python development environment in C/C++ (or Java), the only differences are in your compilation method. The actual code to make your extensions usable in the Python world is the same on any platform.
If you are developing on a Win32 platform, you will need Visual C++ “Developer Studio.” The Python distribution comes with project files for version 7.1, but you may use older versions of VC++. More information on building extensions on Win32 can be found at:
http://docs.python.org/ext/building-on-windows.html
Caution: Although we know enough not to move binaries between different hosts, it is also a good idea just to compile on the same box and not move extensions between boxes either, even if they are of the same architecture. Sometimes slight differences of compiler or CPU will cause code not to work consistently.
Throughout the brief history of software engineering, programming languages have always been taken at face value. What you see is what you get; it was impossible to add new functionality to an existing language. In today’s programming environment, however, the ability to customize one’s programming environment is now a desired feature; it also promotes code reuse. Languages such as TCL and Python are among the first languages to provide the ability to extend the base language. So why would you want to extend a language like Python, which is already feature-rich? There are several good reasons:
• Added/extra (non-Python) functionality
One reason for extending Python is the need to have new functionality not provided by the core part of the language. This can be accomplished in either pure Python or as a compiled extension, but there are certain things such as creating new data types or embedding Python in an existing application which must be compiled.
• Bottleneck performance improvement
It is well known that interpreted languages do not perform as fast as compiled languages due to the fact that translation must happen on the fly and during runtime. In general, moving a body of code into an extension will improve overall performance. The problem is that it is sometimes not advantageous if the cost is high in terms of resources.
Percentage-wise, it is a wiser bet to do some simple profiling of the code to identify what the bottlenecks are, and move those pieces of code out to an extension. The gain can be seen more quickly and without expending as much in terms of resources.
• Keep proprietary source code private
Another important reason to create extensions is due to one side effect of having a scripting language. For all the ease-of-use such languages bring to the table, there really is no privacy as far as source code is concerned because the executable is the source code.
Code that is moved out of Python and into a compiled language helps keep proprietary code private because you ship a binary object. Because these objects are compiled, they are not as easily reverse-engineered; thus, the source remains more private. This is key when it involves special algorithms, encryption or software security, etc.
Another alternative to keeping code private is to ship pre-compiled .pyc files only. It serves as a good middle ground between releasing the actual source (.py files) and having to migrate that code to extensions.
Creating extensions for Python involves three main steps:
- Creating application code
- Wrapping code with boilerplates
- Compilation and testing
In this section, we will break out all three pieces and expose them all to you.
First, before any code becomes an extension, create a standalone “library.” In other words, create your code keeping in mind that it is going to turn into a Python module. Design your functions and objects with the vision that Python code will be communicating and sharing data with your C code and vice versa.
Next, create test code to bulletproof your software. You may even use the “Pythonic” development method of designating your main() function in C as the testing application so that if your code is compiled, linked, and loaded into an executable (as opposed to just a shared object), invocation of such an executable will result in a regression test of your software library. For our extension example below, this is exactly what we do.
The test case involves two C functions that we want to bring to the world of Python programming. The first is the recursive factorial function, fac(). The second, reverse(), is a simple string reverse algorithm, whose main purpose is to reverse a string “in place,” that is, to return a string whose characters are all reversed from their original positions, all without allocating a separate string to copy in reverse order. Because this involves the use of pointers, we need to carefully design and debug our code before bringing Python into the picture.
Our first version, Extest1.c, is presented in Example 22.1.
Example 22.1. Pure C Version of Library (Extest1.c)
The following code represents our library of C functions which we want to wrap so that we can use this code from within the Python interpreter. main() is our tester function.

This code consists of a pair of functions, fac() and reverse(), which are implementations of the functionality we described above. fac() takes a single integer argument and recursively calculates the result, which is eventually returned to the caller once it exits the outermost call.
The last piece of code is the required main() function. We use it to be our tester, sending various arguments to fac() and reverse(). With this function, we can actual tell whether our code works (or not).
Now we should compile the code. For many versions of Unix with the gcc compiler, we can use the following command:
$ gcc Extest1.c -o Extest
$
To run our program, we issue the following command and get the output:

We stress again that you should try to complete your code as much as possible, because you do not want to mix debugging of your library with potential bugs when integrating with Python. In other words, keep the debugging of your core code separate from the debugging of the integration. The closer you write your code to Python interfaces, the sooner your code will be integrated and work correctly.
Each of our functions takes a single value and returns a single value. It’s pretty cut and dried, so there shouldn’t be a problem integrating with Python. Note that, so far, we have not seen any connection or relationship with Python. We are simply creating a standard C or C++ application.
The entire implementation of an extension primarily revolves around the “wrapping” concept that we introduced earlier in Section 13.15.1. You should design your code in such a way that there is a smooth transition between the world of Python and your implementing language. This interfacing code is commonly called “boilerplate” code because it is a necessity if your code is to talk to the Python interpreter.
There are four main pieces to the boilerplate software:
- Include Python header file
- Add
PyObject*Module_func()Python wrappers for each module function - Add
PyMethodDefModuleMethods[]array/table for each module function - Add
voidinitModule()module initializer function
The first thing you should do is to find your Python include files and make sure your compiler has access to that directory. On most Unix-based systems, this would be either /usr/local/include/python2.x or /usr/include/python2.x, where the “2.x” is your version of Python. If you compiled and installed your Python interpreter, you should not have a problem because the system generally knows where your files are installed.
Add the inclusion of the Python.h header file to your source. The line will look something like:
#include "Python.h"
That is the easy part. Now you have to add the rest of the boilerplate software.
This part is the trickiest. For each function you want accessible to the Python environment, you will create a static PyObject* function with the module name along with an underscore ( _ ) prepended to it.
For example, we want fac() to be one of the functions available for import from Python and we will use Extest as the name of our final module, so we create a “wrapper” called Extest_fac(). In the client Python script, there will be an “import Extest” and an “Extest.fac()” call somewhere (or just “fac()” for “from Extest import fac”).
The job of the wrapper is to take Python values, convert them to C, then make a call to the appropriate function with what we want. When our function has completed, and it is time to return to the world of Python, it is also the job of this wrapper to take whatever return values we designate, convert them to Python, and then perform the return, passing back any values as necessary.
In the case of fac(), when the client program invokes Extest.fac(), our wrapper will be called. We will accept a Python integer, convert it to a C integer, call our C function fac() and obtain another integer result. We then have to take that return value, convert it back to a Python integer, then return from the call. (In your head, try to keep in mind that you are writing the code that will proxy for a “def fac(n)” declaration. When you are returning, it is as if that imaginary Python fac() function is completing.)
So, you’re asking, how does this conversion take place? The answer is with the PyArg_Parse*() functions when going from Python to C, and Py_BuildValue() when returning from C to Python.
The PyArg_Parse*() functions are similar to the C sscanf() function. It takes a stream of bytes, and, according to some format string, parcels them off to corresponding container variables, which, as expected, take pointer addresses. They both return 1 on successful parsing and 0 otherwise.
Py_BuildValue() works like sprintf(), taking a format string and converting all arguments to a single returned object containing those values in the formats that you requested.
You will find a summary of these functions in Table 22.1.

A set of conversion codes is used to convert data objects between C and Python; they are given in Table 22.2.

These conversion codes are the ones given in the respective format strings that dictate how the values should be converted when moving between both languages. Note: The conversion types are different for Java since all data types are classes. Consult the Jython documentation to obtain the corresponding Java types for Python objects. The same applies for C# and VB.NET.
Here we show you our completed Extest_fac() wrapper function:

The first step is to parse the data received from Python. It should be a regular integer, so we use the “i” conversion code to indicate as such. If the value was indeed an integer, then it gets stored in the num variable. Otherwise, PyArg_ParseTuple() will return a NULL, in which case we also return one. In our case, it will generate a TypeError exception that tells the client user that we are expecting an integer.
We then call fac() with the value stored in num and put the result in res, reusing that variable. Now we build our return object, a Python integer, again using a conversion code of “i.” Py_BuildValue() creates an integer Python object which we then return. That’s all there is to it!
In fact, once you have created wrapper after wrapper, you tend to shorten your code somewhat to avoid extraneous use of variables. Try to keep your code legible, though. We take our Extest_fac() function and reduce it to its smaller version given here, using only one variable, num:

What about reverse()? Well, since you already know how to return a single value, we are going to change our reverse() example somewhat, returning two values instead of one. We will return a pair of strings as a tuple, the first element being the string as passed in to us, and the second being the newly reversed string.
To show you that there is some flexibility, we will call this function Extest.doppel() to indicate that its behavior differs from reverse(). Wrapping our code into an Extest_doppel() function, we get:

As in Extest_fac(), we take a single input value, this time a string, and store it into orig_str. Notice that we use the “s” conversion code now. We then call strdup() to create a copy of the string. (Since we want to return the original one as well, we need a string to reverse, so the best candidate is just a copy of the string.) strdup() creates and returns a copy, which we immediate dispatch to reverse(). We get back a reversed string.
As you can see, Py_BuildValue() puts together both strings using a conversion string of “ss.” This creates a tuple of two strings, the original string and the reversed one. End of story, right? Unfortunately, no.
We got caught by one of the perils of C programming: the memory leak, that is, when memory is allocated but not freed. Memory leaks are analogous to borrowing books from the library but not returning them. You should always release resources that you have acquired when you no longer require them. How did we commit such a crime with our code (which looks innocent enough)?
When Py_BuildValue() puts together the Python object to return, it makes copies of the data it has been passed. In our case here, that would be a pair of strings. The problem is that we allocated the memory for the second string, but we did not release that memory when we finished, leaking it. What we really want to do is to build the return object and then free the memory that we allocated in our wrapper. We have no choice but to lengthen our code to:

We introduce the dupe_str variable to point to the newly allocated string and build the return object. Then we free() the memory allocated and finally return back to the caller. Now we are done.
Now that both of our wrappers are complete, we want to list them somewhere so that the Python interpreter knows how to import and access them. This is the job of the ModuleMethods[] array.
It is made up of an array of arrays, with each individual array containing information about each function, terminated by a NULL array marking the end of the list. For our Extest module, we create the following ExtestMethods[] array:

The Python-accessible names are given, followed by the corresponding wrapping functions. The constant METH_VARARGS is given, indicating a set of arguments in the form of a tuple. If we are using PyArg_ParseTupleAndKeywords() with keyworded arguments, we would logically OR this flag with the METH_KEYWORDS constant. Finally, a pair of NULLs properly terminates our list of two functions.
The final piece to our puzzle is the module initializer function. This code is called when our module is imported for use by the interpreter. In this code, we make one call to Py_InitModule() along with the module name and the name of the ModuleMethods[] array so that the interpreter can access our module functions. For our Extest module, our initExtest() procedure looks like this:
![]()
We are now done with all our wrapping. We add all this code to our original code from Extest1.c and merge the results into a new file called Extest2.c, concluding the development phase of our example.
Another approach to creating an extension would be to make your wrapping code first, using “stubs” or test or dummy functions which will, during the course of development, be replaced by the fully functional pieces of implemented code. That way you can ensure that your interface between Python and C is correct, and then use Python to test your C code.
Now we are on to the compilation phase. In order to get your new wrapper Python extension to build, you need to get it to compile with the Python library. This task has been standardized (since 30) across platforms to make life a lot easier for extension writers. The distutils package is used to build, install, and distribute modules, extensions, and packages. It came about back in Python 2.0 and replaced the old 1.x way of building extensions using “makefiles.” Using distutils, we can follow this easy recipe:
- Create
setup.py - Compile and link your code by running
setup.py - Import your module from Python
- Test function
The next step is to create a setup.py file. The bulk of the work will be done by the setup() function. All the lines of code that come before that call are preparatory steps. For building extension modules, you need to create an Extension instance per extension. Since we only have one, we only need one Extension instance:
Extension('Extest', sources=['Extest2.c'])
The first argument is the (full) extension name, including any high-level packages if necessary. The name should be in full dotted-attribute notation. Ours is standalone, hence the name “Extest.” sources is a list of all the source files. Again, we only have the one, Extest2.c.
Now we are ready to call setup(). It takes a name argument for what it is building and a list of the items to build. Since we are creating an extension, we set it a list of extension modules to build as ext_modules. The syntax will be like this:
setup('Extest', ext_modules=[...])
Since we only have one module, we combine the instantiation of our extension module into our call to setup(), setting the module name as “constant” MOD on the preceding line:
MOD = 'Extest'
setup(name=MOD, ext_modules=[
Extension(MOD, sources=['Extest2.c'])])
There are many more options to setup(), which are too numerous to list here. You can find out more about creating setup.py and calling setup() in the official Python documentation that we refer to at the end of this chapter. Example 22.2 shows the complete script that we are using for our example.

Now that we have our setup.py file, we can build our extension by running it with the “build” directive, as we have done here on our Mac (your output will differ based on the version of the operating system you are running as well as the version of Python you are using):
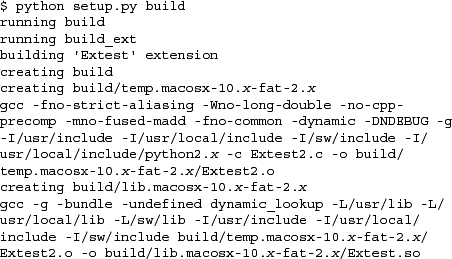
Your extension module will be created in the build/lib.* directory from where you ran your setup.py script. You can either change to that directory to test your module or install it into your Python distribution with:
$ python setup.py install
If you do install it, you will get the following output:

Now we can test out our module from the interpreter:

The one last thing we want to do is to add a test function. In fact, we already have one, in the form of the main() function. Now, it is potentially dangerous to have a main() function in our code because there should only be one main() in the system. We remove this danger by changing the name of our main() to test() and wrapping it, adding Extest_test() and updating the ExtestMethods array so that they both look like this:

The Extest_test() module function just runs test() and returns an empty string, resulting in a Python value of None being returned to the caller.
Now we can run the same test from Python:

In Example 22.3, we present the final version of Extest2.c that was used to generate the output we just witnessed.


In this example, we chose to segregate our C code from our Python code. It just kept things easier to read and is no problem with our short example. In practice, these source files tend to get large, and some choose to implement their wrappers completely in a different source file, i.e., ExtestWrappers.c or something of that nature.
You may recall that Python uses reference counting as a means of keeping track of objects and deallocating objects no longer referenced as part of the garbage collection mechanism. When creating extensions, you must pay extra special attention to how you manipulate Python objects because you must be mindful of whether or not you need to change the reference count for such objects.
There are two types of references you may have to an object, one of which is an owned reference, meaning that the reference count to the object is incremented by one to indicate your ownership. One place where you would definitely have an owned reference is where you create a Python object from scratch.
When you are done with a Python object, you must dispose of your ownership, either by decrementing the reference count, transferring your ownership by passing it on, or storing the object. Failure to dispose of an owned reference creates a memory leak.
You may also have a borrowed reference to an object. Somewhat lower on the responsibility ladder, this is where you are passed the reference of an object, but otherwise do not manipulate the data in any way. Nor do you have to worry about its reference count, as long as you do not hold on to this reference after its reference count has decreased to zero. You may convert your borrowed reference to an owned reference simply by incrementing an object’s reference count.
Python provides a pair of C macros which are used to change the reference count to a Python object. They are given in Table 22.3.

In our above Extest_test() function, we return None by building a PyObject with an empty string; however, it can also be accomplished by becoming an owner of the None object, PyNone, incrementing your reference count to it, and returning it explicitly, as in the following alternative piece of code:

Py_INCREF() and Py_DECREF() also have versions that check for NULL objects. They are Py_XINCREF() and Py_XDECREF(), respectively.
We strongly urge the reader to consult the Python documentation regarding extending and embedding Python for all the details with regard to reference counting (see the documentation reference in the Appendix).
Extension writers must be aware that their code may be executed in a multithreaded Python environment. Back in Section 18.3.1, we introduced the Python Virtual Machine (PVM) and the Global Interpreter Lock (GIL) and described how only one thread of execution can be running at any given time in the PVM and that the GIL is responsible for keeping other threads from running. Furthermore, we indicated that code calling external functions such as in extension code would keep the GIL locked until the call returns.
We also hinted that there was a remedy, a way for the extension programmer to release the GIL, for example before performing a system call. This is accomplished by “blocking” your code off to where threads may (and may not) run safely using another pair of C macros, Py_BEGIN_ALLOW_THREADS and Py_END_ALLOW_THREADS. A block of code bounded by these macros will permit other threads to run.
As with the reference counting macros, we urge you to consult with the documentation regarding extending and embedding Python as well as the Python/C API reference manual.
There is an external tool available called SWIG, which stands for Simplified Wrapper and Interface Generator. It was written by David Beazley, also the author of Python Essential Reference. It is a software tool that can take annotated C/C++ header files and generate wrapped code, ready to compile for Python, Tcl, and Perl. Using SWIG will free you from having to write the boilerplate code we’ve seen in this chapter. You only need to worry about coding the solution part of your project in C/C++. All you have to do is create your files in the SWIG format, and it will do the background work on your behalf. You can find out more information about SWIG from its main Web site located at the following Web address (URL):
One obvious weakness of creating C/C++ extensions (raw or with SWIG) is that you have to write C/C++ (surprise, surprise), with all of its strengths, and, more importantly, its pitfalls. Pyrex gives you practically all of the gains of writing extensions but not the headache. Pyrex is a new language created specifically for writing Python extensions. It is a hybrid of C and Python, leaning much more toward Python: in fact, the Pyrex Web site goes as far as saying that, “Pyrex is Python with C data types.” You only need to write code in the Pyrex syntax and run the Pyrex compiler on the source. Pyrex creates C files, which can then be compiled and used as a normal extension would. Some have sworn off C programming forever upon discovering Pyrex. You can get Pyrex at its home page:
http://cosc.canterbury.ac.nz/~greg/python/Pyrex
Pyrex gives us the advantage that you no longer have to write pure C; however, do you need to learn its syntax, “yet another language.” In the end, your Pyrex code turns into C anyway. You use C/C++, C/C++ with SWIG, or Pyrex because you still want that performance boost you are looking for. What if you can obtain performance gains without changing your Python code?
Psyco’s concept is quite different from those other approaches. Rather than writing C code, why not just make your existing Python code run faster? Psyco serves as a just-in-time (JIT) compiler so you do not have to change to your source other than importing the Psyco module and telling it to start optimizing your code (during runtime).
Psyco can also profile your code to see where it can make the most significant improvements. You can even enable logging to see what Psyco does while optimizing your code. For more information, go to its main Web site:
Embedding is another feature available in Python. It is the inverse of an extension. Rather than taking C code and wrapping it into Python, you take a C application and wrap a Python interpreter inside it. This has the effect of giving a potentially large, monolithic, and perhaps rigid, proprietary, and/or mission-critical application the power of having an embedded Python interpreter. Once you have Python, well, it’s like a whole new ball game.
For extension writer, there is a set of official docs that you should refer to for additional information.
Here are links to some of the Python documentation related to this chapter’s topics:
Extending and Embedding
Python/C API
Distributing Python Modules
22-1. Extending Python. What are some of the advantages of Python extensions?
22-2. Extending Python. Can you see any disadvantages or dangers of using extensions?
22-3. Writing Extensions. Obtain or find a C/C++ compiler and write a small program with it to (re)familiarize yourself with C/C++ programming. Find your Python distribution directory and locate the Misc/Makefile.pre.in file. Take the program you just wrote and wrap it in Python. Go through the steps necessary to create a shared object. Access that module from Python and test it.
22-4. Porting from Python to C. Take several of the exercises you did in earlier chapters and port them to C/C++ as extension modules.
22-5. Wrapping C Code. Find a piece of C/C++ code, which you may have done a long time ago, but want to port to Python. Instead of porting, make it an extension module.
22-6. Writing Extensions. In Exercise 13-3, you created a dollarize() function as part of a class to convert a floating point value to a financial numeric string with embedded dollar signs and commas. Create an extension featuring a wrapped dollarize() function and integrate a regression testing function, i.e., test(), into the module. Extra credit: In addition to creating a C extension, also rewrite dollarize() in Pyrex.
22-7. Extending versus Embedding. What is the difference between extending and embedding?