
Chapter 14. Overloaded Operations and Conversions
CONTENTS
Section 14.1 Defining an Overloaded Operator 506
Section 14.2 Input and Output Operators 513
Section 14.3 Arithmetic and Relational Operators 517
Section 14.4 Assignment Operators 520
Section 14.5 Subscript Operator 522
Section 14.6 Member Access Operators 523
Section 14.7 Increment and Decrement Operators 526
Section 14.8 Call Operator and Function Objects 530
Section 14.9 Conversions and Class Types 535
In Chapter 5 we saw that C++ defines a large number of operators and automatic conversions among the built-in types. These facilities allow programmers to write a rich set of mixed-type expressions.
C++ lets us redefine the meaning of the operators when applied to objects of class type. It also lets us define conversion operations for class types. Class-type conversions are used like the built-in conversions to implicitly convert an object of one type to another type when needed.
Operator overloading allows the programmer to define versions of the operators for operands of class type. Chapter 13 covered the importance of the assignment operator and showed how to define the assignment operator. We first used overloaded operators in Chapter 1, when our programs used the shift operators (>> and <<) for input and output and the addition operator (+) to add two Sales_items. We’ll finally see in this chapter how to define these overloaded operators.
Through operator overloading, we can redefine most of the operators from Chapter 5 to work on objects of class type. Judicious use of operator overloading can make class types as intuitive to use as the built-in types. For example, the standard library defines several overloaded operators for the container classes. These classes define the subscript operator to access data elements and * and -> to dereference container iterators. The fact that these library types have the same operators makes using them similar to using built-in arrays and pointers. Allowing programs to use expressions rather than named functions can make the programs much easier to write and read. As an example, compare
![]()
to the more verbose code that would be necessary if IO used named functions:

14.1 Defining an Overloaded Operator
Overloaded operators are functions with special names: the keyword operator followed by the symbol for the operator being defined. Like any other function, an overloaded operator has a return type and a parameter list.
Sales_item operator+(const Sales_item&, const Sales_item&);
declares the addition operator that can be used to “add” two Sales_item objects and yields a copy of a Sales_item object.
With the exception of the function-call operator, an overloaded operator has the same number of parameters (including the implicit this pointer for member functions) as the operator has operands. The function-call operator takes any number of operands.
Overloaded Operator Names
Table 14.1 on the next page lists the operators that may be overloaded. Those that may not be overloaded are listed in Table 14.2.
Table 14.1. Overloadable Operators

Table 14.2. Operators That Cannot Be Overloaded
![]()
New operators may not be created by concatenating other legal symbols. For example, it would be illegal to attempt to define an operator** to provide exponentiation. Overloading new and delete is described in Chapter 18 (p. 753).
Overloaded Operators Must Have an Operand of Class Type
The meaning of an operator for the built-in types may not be changed. For example, the built-in integer addition operation cannot be redefined:
// error: cannot redefine built-in operator for ints
int operator+(int, int);
Nor may additional operators be defined for the built-in data types. For example, an operator+ taking two operands of array types cannot be defined.

An overloaded operator must have at least one operand of class or enumeration (Section 2.7, p. 62) type. This rule enforces the requirement that an overloaded operator may not redefine the meaning of the operators when applied to objects of built-in type.
Precedence and Associativity Are Fixed
The precedence (Section 5.10.1, p. 168), associativity, or number of operands of an operator cannot be changed. Regardless of the type of the operands and regardless of the definition of what the operations do, this expression
x == y +z;
always binds the arguments y and z to operator+ and uses that result as the right-hand operand to operator==.
Four symbols (+, -, *, and &) serve as both unary and binary operators. Either or both of these operators can be overloaded. Which operator is being defined is controlled by the number of operands. Default arguments for overloaded operators are illegal, except for operator(), the function-call operator.
Short-Ciruit Evaluation Is Not Preserved
Overloaded operators make no guarantees about the order in which operands are evaluated. In particular, the operand-evaluation guarantees of the built-in logical AND, logical OR (Section 5.2, p. 152), and comma (Section 5.9, p. 168) operators are not preserved. Both operands to an overloaded version of && or || are always evaluated. The order in which those operands are evaluated is not stipulated. The order in which the operands to the comma are evaluated is also not defined. For this reason, it is usually a bad idea to overload &&, ||, or the comma operator.
Class Member versus Nonmember
Most overloaded operators may be defined as ordinary nonmember functions or as class member functions.
Overloaded functions that are members of a class may appear to have one less parameter than the number of operands. Operators that are member functions have an implicit this parameter that is bound to the first operand.
An overloaded unary operator has no (explicit) parameter if it is a member function and one parameter if it is a nonmember function. Similarly, an overloaded binary operator would have one parameter when defined as a member and two parameters when defined as a nonmember function.
The Sales_item class offers a good example of member and nonmember binary operators. We know that the class has an addition operator. Because it has an addition operator, we ought to define a compound-assignment (+=) operator as well. This operator will add the value of one Sales_item object into another.
Ordinarily we define the arithmetic and relational operators as nonmember functions and we define assignment operators as members:
// member binary operator: left-hand operand bound to implicit this pointer
Sales_item& Sales_item::operator+=(const Sales_item&);
// nonmember binary operator: must declare a parameter for each operand
Sales_item operator+(const Sales_item&, const Sales_item&);
Both addition and compound assignment are binary operators, yet these functions define a different number of parameters. The reason for the discrepancy is the this pointer.
When an operator is a member function, this points to the left-hand operand. Thus, the nonmember operator+ defines two parameters, both references to const Sales_item objects. Even though compound assignment is a binary operator, the member compound-assignment operator takes only one (explicit) parameter. When the operator is used, a pointer to the left-hand operand is automatically bound to this and the right-hand operand is bound to the function’s sole parameter.
It is also worth noting that compound assignment returns a reference and the addition operator returns a Sales_item object. This difference matches the return types of these operators when applied to arithmetic types: Addition yields an rvalue and compound assignment returns a reference to the left-hand operand.
Operator Overloading and Friendship
When operators are defined as nonmember functions, they often must be made friends (Section 12.5, p. 465) of the class(es) on which they operate. We’ll see later in this chapter two reasons why operators might be defined as nonmembers. In such cases, the operator often needs access to the private parts of the class.
Our Sales_item class is again a good example of why some operators need to be friends. It defines one member operator and has three nonmember operators. Those nonmember operators, which need access to the private data members, are declared as friends:

That the input and output operators need access to the private data should not be surprising. After all, they read and write those members. On the other hand, there is no need to make the addition operator a friend. It can be implemented using the public member operator+=.
Using Overloaded Operators
We can use an overloaded operator in the same way that we’d use the operator on operands of built-in type. Assuming item1 and item2 are Sales_item objects, we might print their sum in the same way that we’d print the sum of two ints:
cout << item1 + item2 << endl;
This expression implicitly calls the operator+ that we defined for Sales_items.
We also can call an overloaded operator function in the same way that we call an ordinary function: We name the function and pass an appropriate number of arguments of the appropriate type:
// equivalent direct call to nonmember operator function
cout << operator+(item1, item2) << endl;
This call has the same effect as the expression that added item1 and item2.
We call a member operator function the same way we call any other member function: We name an object on which to run the function and then use the dot or arrow operator to fetch the function we wish to call passing the required number and type of arguments. In the case of a binary member operator function, we must pass a single operand:
![]()
Each of these statements adds the value of item2 into item1. In the first case, we implicitly call the overloaded operator function using expression syntax. In the second, we call the member operator function on the object item1.
14.1.1 Overloaded Operator Design
When designing a class there are some useful rules of thumb to keep in mind when deciding which, if any, overloaded operators to provide.
Don’t Overload Operators with Built-in Meanings
The assignment, address of, and comma operators have default meanings for operands of class types. If there is no overloaded version specified, the compiler defines its own version of these operators:
• The synthesized assignment operator (Section 13.2, p. 482) does memberwise assignment: It uses each member’s own assignment operator to assign each member in turn.
• By default the address of (&) and comma (,) operators execute on class type objects the same way they do on objects of built-in type. The address of operator returns the address in memory of the object to which it is applied. The comma operator evaluates each expression from left to right and returns the value of its rightmost operand.
• The built-in logical AND (&&) and OR(||) operators apply short-circuit evaluation (Section 5.2, p. 152). If the operator is redefined, the short-circuit nature of the operators is lost.
The meaning of these operators can be changed by redefining them for operands of a given class type.

It is usually not a good idea to overload the comma, address-of, logical AND, or logical OR operators. These operators have built-in meanings that are useful and become inaccessible if we define our own versions.
We sometimes must define our own version of assignment. When we do so, it should behave analogously to the synthesized operators: After an assignment, the values in the left-hand and right-hand operands should be the same and the operator should return a reference to its left-hand operand. Overloaded assignment should customize the built-in meaning of assignment, not circumvent it.
Most Operators Have No Meaning for Class Objects
Operators other than assignment, address-of, and comma have no meaning when applied to an operand of class type unless an overloaded definition is provided. When designing a class, we decide which, if any, operators to support.
The best way to design operators for a class is first to design the class’ public interface. Once the interface is defined, it is possible to think about which operations should be defined as overloaded operators. Those operations with a logical mapping to an operator are good candidates. For example,
• An operation to test for equality should use operator==.
• Input and output are normally done by overloading the shift operators.
• An operation to test whether the object is empty could be represented by the logical NOT operator, operator!.
Compound Assignment Operators
If a class has an arithmetic (Section 5.1, p. 149) or bitwise (Section 5.3, p. 154) operator, then it is usually a good idea to provide the corresponding compound-assignment operator as well. For example, our Sales_item class defined the + operator. Logically, it also should define +=. Needless to say, the += operator should be defined to behave the same way the built-in operators do: Compound assignment should behave as + followed by =.
Equality and Relational Operators
Classes that will be used as the key type of an associative container should define the < operator. The associative containers by default use the < operator of the key type. Even if the type will be stored only in a sequential container, the class ordinarily should define the equality (==) and less-than (<) operators. The reason is that many algorithms assume that these operators exist. As an example, the sort algorithm uses < and find uses ==.
Caution: Use Operator Overloading Judiciously
Each operator has an associated meaning from its use on the built-in types. Binary +, for example, is strongly identified with addition. Mapping binary + to an analogous operation for a class type can provide a convenient notational shorthand. For example, the library string type, following a convention common to many programming languages, uses + to represent concatenation—“adding” one string to the other.
Operator overloading is most useful when there is a logical mapping of a built-in operator to an operation on our type. Using overloaded operators rather than inventing named operations can make our programs more natural and intuitive. Overuse or outright abuse of operator overloading can make our classes incomprehensible.
Obvious abuses of operator overloading rarely happen in practice. As an example, no responsible programmer would define operator+ to perform subtraction. More common, but still inadvisable, are uses that contort an operator’s “normal” meaning to force a fit to a given type. Operators should be used only for operations that are likely to be unambiguous to users. An operator with ambiguous meaning, in this sense, is one that supports equally well a number of different interpretations.
If the class defines the equality operator, it should also define !=. Users of the class will assume that if they can compare for equality, they can also compare for inequality. The same argument applies to the other relational operators as well. If the class defines <, then it probably should define all four relational operators (>, >=, <, and <=).
Choosing Member or Nonmember Implementation
When designing the overloaded operators for a class, we must choose whether to make each operator a class member or an ordinary nonmember function. In some cases, the programmer has no choice; the operator must be a member. In other cases, there are some rules of thumb that can help guide the decision. The following guidelines can be of help when deciding whether to make an operator a member or an ordinary nonmember function:
• The assignment (=), subscript ([]), call (()), and member access arrow (->) operators must be defined as members. Defining any of these operators as a nonmember function is flagged at compile time as an error.
• Like assignment, the compound-assignment operators ordinarily ought to be members of the class. Unlike assignment, they are not required to be so and the compiler will not complain if a nonmember compound-assignment operator is defined.
• Other operators that change the state of their object or that are closely tied to their given type—such as increment, decrement, and dereference—usually should be members of the class.
• Symmetric operators, such as the arithmetic, equality, relational, and bitwise operators, are best defined as ordinary nonmember functions.
14.2 Input and Output Operators
Classes that support I/O ordinarily should do so by using the same interface as defined by the iostream library for the built-in types. Thus, many classes provide overloaded instances of the input and output operators.
14.2.1 Overloading the Output Operator <<
To be consistent with the IO library, the operator should take an ostream& as its first parameter and a reference to a const object of the class type as its second. The operator should return a reference to its ostream parameter.
The general skeleton of an overloaded output operator is

The first parameter is a reference to an ostream object on which the output will be generated. The ostream is nonconst because writing to the stream changes its state. The parameter is a reference because we cannot copy an ostream object.
The second parameter ordinarily should be a const reference to the class type we want to print. The parameter is a reference to avoid copying the argument. It can be const because (ordinarily) printing an object should not change it. By making the parameter a const reference, we can use a single definition to print const and nonconst objects.
The return type is an ostream reference. Its value is usually the ostream object against which the output operator is applied.
The Sales_item Output Operator
We can now write the Sales_item output operator:

Printing a Sales_item entails printing its three data elements and the computed average sales price. Each element is separated by a tab. After printing the values, the operator returns a reference to the ostream it just wrote.
Output Operators Usually Do Minimal Formatting
Class designers face one significant decision about output: whether and how much formatting to perform.
Generally, output operators should print the contents of the object, with minimal formatting. They should not print a newline.
The output operators for the built-in types do little if any formatting and do not print newlines. Given this treatment for the built-in types, users expect class output operators to behave similarly. By limiting the output operator to printing just the contents of the object, we let the users determine what if any additional formatting to perform. In particular, an output operator should not print a newline. If the operator does print a newline, then users would be unable to print descriptive text along with the object on the same line. By having the output operator perform minimal formatting, we let users control the details of their output.
IO Operators Must Be Nonmember Functions
When we define an input or output operator that conforms to the conventions of the iostream library, we must make it a nonmember operator. Why?
We cannot make the operator a member of our own class. If we did, then the left-hand operand would have to be an object of our class type:
// if operator<< is a member of Sales_item
Sales_item item;
item << cout;
This usage is the opposite of the normal way we use output operators defined for other types.
If we want to support normal usage, then the left-hand operand must be of type ostream. That means that if the operator is to be a member of any class, it must be a member of class ostream. However, that class is part of the standard library. We—and anyone else who wants to define IO operators—can’t go adding members to a class in the library.
Instead, if we want to use the overloaded operators to do IO for our types, we must define them as a nonmember functions. IO operators usually read or write the nonpublic data members. As a consequence, classes often make the IO operators friends.
Exercises Section 14.2.1
Exercise 14.7: Define an output operator for the following CheckoutRecord class:

Exercise 14.8: In the exercises to Section 12.4 (p. 451) you wrote a sketch of one of the following classes:
(a) Book (b) Date (c) Employee
(d) Vehicle (e) Object (f) Tree
Write the output operator for the class you chose.
14.2.2 Overloading the Input Operator >>
Similar to the output operator, the input operator takes a first parameter that is a reference to the stream from which it is to read, and returns a reference to that same stream. Its second parameter is a nonconst reference to the object into which to read. The second parameter must be nonconst because the purpose of an input operator is to read data into this object.
A more important, and less obvious, difference between input and output operators is that input operators must deal with the possibility of errors and end-of-file.
The Sales_item Input Operator
The Sales_item input operator looks like:

This operator reads three values from its istream parameter: a string value, which it stores in the isbn member of its Sales_item parameter; an unsigned, which it stores in the units_sold member; and a double, which it stores in a local named price. Assuming the reads succeed, the operator uses price and units_sold to set the object’s revenue member.
Errors During Input
Our Sales_item input operator reads the expected values and checks whether an error occurred. The kinds of errors that might happen include:
- Any of the read operations could fail because an incorrect value was provided. For example, after reading
isbn, the input operator assumes that the next two items will be numeric data. If nonnumeric data is input, that read and any subsequent use of the stream will fail. - Any of the reads could hit end-of-file or some other error on the input stream.
Rather than checking each read, we check once before using the data we read:
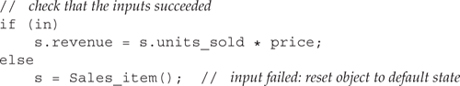
If one of the reads failed, then price would be uninitialized. Hence, before using price, we check that the input stream is still valid. If it is, we do the calculation and store it in revenue. If there was an error, we do not worry about which input failed. Instead, we reset the entire object as if it were an empty Sales_item. We do so by creating a new, unnamed Sales_item constructed using the default constructor and assigning that value to s. After this assignment, s will have an empty string for its isbn member, and its revenue and units_sold members will be zero.
Handling Input Errors
If an input operator encounters an error, it normally should ensure that the object being read into is left in a usable and consistent state. Doing so is especially important if the object might have been partially updated before the error occurred.
For example, in the Sales_item input operator, we might successfully read a new isbn, and then encounter an error on the stream. An error after reading isbn would mean that the units_sold and revenue members of the old object were unchanged. The effect would be to associate a different isbn with that data.
In this operator, we avoid giving the parameter an invalid state by resetting it to the empty Sales_item if an error occurs. A user who needs to know whether the input succeeded can test the stream. If the user ignores the possibility of an input error, the object is in a usable state—its members are all defined. Similarly, the object won’t generate misleading results—its data are internally consistent.
When designing an input operator, it is important to decide what to do about error-recovery, if anything.
Indicating Errors
In addition to handling any errors that might occur, an input operator might need to set the condition state (Section 8.2, p. 287) of its input istream parameter. Our input operator is quite simple—the only errors we care about are those that could happen during the reads. If the reads succeed, then our input operator is correct and has no need to do additional checking.
Some input operators do need to do additional checking. For example, our input operator might check that the isbn we read is in an appropriate format. We might have read data successfully, but these data might not be suitable when interpreted as an ISBN. In such cases, the input operator might need to set the condition state to indicate failure, even though technically speaking the actual IO was successful. Usually an input operator needs to set only the failbit. Setting eofbit would imply that the file was exhausted, and setting badbit would indicate that the stream was corrupted. These errors are best left to the IO library itself to indicate.
14.3 Arithmetic and Relational Operators
Ordinarily, we define the arithmetic and relational operators as nonmember functions, as we do here with our Sales_item addition operator:

Exercises Section 14.2.2
Exercise 14.9: Describe the behavior of the Sales_item input operator if given the following input:
(a) 0-201-99999-9 10 24.95
(b) 10 24.95 0-210-99999-9
Exercise 14.10: What is wrong with the following Sales_item input operator?

What would happen if we gave this operator the data in the previous exercise?
Exercise 14.11: Define an input operator for the CheckoutRecord class defined in the exercises for Section 14.2.1 (p. 515). Be sure the operator handles input errors.
The addition operator doesn’t change the state of either operand; the operands are references to const objects. Instead, it generates and returns a new Sales_item object, which is initialized as a copy of lhs. We use the Sales_item compound-assignment operator to add in the value of rhs.
An arithmetic operator usually generates a new value that is the result of a computation on its two operands. That value is distinct from either operand and is calculated in a local variable. It would be a run-time error to return a reference to that variable.
Classes that define both an arithmetic operator and the related compound assignment ordinarily ought to implement the arithmetic operator by using the compound assignment.
It is simpler and more efficient to implement the arithmetic operator (e.g., +) in terms of the compound-assignment operator (e.g., +=) rather than the other way around. As an example, consider our Sales_item operators. If we implemented += by calling +, then += would needlessly create and destroy a temporary to hold the result from +.
14.3.1 Equality Operators
Ordinarily, classes in C++ use the equality operator to mean that the objects are equivalent. That is, they usually compare every data member and treat two objects as equal if and only if all corresponding members are the same. In line with this design philosophy, our Sales_item equality operator should compare the isbn as well as the sales figures:

The definition of these functions is trivial. More important are the design principles that these functions embody:
• If a class defines the == operator, it defines it to mean that two objects contain the same data.
• If a class has an operation to determine whether two objects of the type are equal, it is usually right to define that function as operator== rather than inventing a named operation. Users will expect to be able to compare objects using ==, and doing so is easier than remembering a new name.
• If a class defines operator==, it should also define operator!=. Users will expect that if they can use one operator, then the other will also exist.
• The equality and inequality operators should almost always be defined in terms of each other. One operator should do the real work to compare objects. The other should call the one that does the real work.
Classes that define operator== are easier to use with the standard library. Some algorithms, such as find, use the == operator by default. If a class defines ==, then these algorithms can be used on that class type without any specialization.
14.3.2 Relational Operators
Classes for which the equality operator is defined also often have relational operators. In particular, because the associative containers and some of the algorithms use the less-than operator, it can be quite useful to define an operator<.
Although we might think our Sales_item class should support the relational operators, it turns out that it probably should not. The reasons are somewhat subtle and deserve understanding.
As we’ll see in Chapter 15, we might want to use an associative container to hold Sales_item transactions. When we put objects into the container, we’d want them ordered by ISBN, and wouldn’t care whether the sales data in two records were different.
However, if we were to define operator< as comparison on isbn, that definition would be incompatible with the obvious definition of ==. If we had two transactions for the same ISBN, neither record would be less than the other. Yet, if the sales figures in those objects were different, then these objects would be !=. Ordinarily, if we have two objects, neither of which is less than the other, then we expect that those objects are equal.
Because the logical definition of < is inconsistent with the logical definition of ==, it is better not to define < at all. We’ll see in Chapter 15 how to use a separate named function to compare Sales_items when we want to store them in an associative container.
The associative containers, as well as some of the algorithms, use the < operator by default. Ordinarily, the relational operators, like the equality operators, should be defined as nonmember functions.
14.4 Assignment Operators
We covered the assignment of one object of class type to another object of its type in Section 13.2 (p. 482). The class assignment operator takes a parameter that is the class type. Usually the parameter is a const reference to the class type. However, the parameter could be the class type or a nonconst reference to the class type. This operator will be synthesized by the compiler if we do not define it ourselves. The class assignment operator must be a member of the class so the compiler can know whether it needs to synthesize one.
Additional assignment operators that differ by the type of the right-hand operand can be defined for a class type. For example, the library string class defines three assignment operators: In addition to the class assignment operator, which takes a const string& as its right-hand operand, the string class defines versions of assignment that take a C-style character string or a char as the right-hand operand. These might be used as follows:

To support these operations, the string class contains members that look like

Assignment operators can be overloaded. Unlike the compound-assignment operators, every assignment operator, regardless of parameter type, must be defined as a member function.
Assignment Should Return a Reference to *this
The string assignment operators return a reference to string, which is consistent with assignment for the built-in types. Moreover, because assignment returns a reference there is no need to create and destroy a temporary copy of the result. The return value is usually a reference to the left-hand operand. For example, here is the definition of the Sales_item compound-assignment operator:

Ordinarily, assignment operators and compound-assignment operators ought to return a reference to the left-hand operand.
14.5 Subscript Operator
Classes that represent containers from which individual elements can be retrieved usually define the subscript operator, operator[]. The library classes, string and vector, are examples of classes that define the subscript operator.
Providing Read and Write Access
One complication in defining the subscript operator is that we want it to do the right thing when used as either the left- or right-hand operand of an assignment. To appear on the left-hand side, it must yield an lvalue, which we can achieve by specifying the return type as a reference. As long as subscript returns a reference, it can be used on either side of an assignment.
It is also a good idea to be able to subscript const and nonconst objects. When applied to a const object, the return should be a const reference so that it is not usable as the target of an assignment.
Ordinarily, a class that defines subscript needs to define two versions: one that is a nonconst member and returns a reference and one that is a const member and returns a const reference.
Prototypical Subscript Operator
The following class defines the subscript operator. For simplicity, we assume the data Foo holds are stored in a vector<int>:

The subscript operators themselves would look something like:

14.6 Member Access Operators
To support pointerlike classes, such as iterators, the language allows the dereference (*) and arrow (->) operators to be overloaded.
Operator arrow must be defined as a class member function. The dereference operator is not required to be a member, but it is usually right to make it a member as well.
Building a Safer Pointer
The dereference and arrow operators are often used in classes that implement smart pointers (Section 13.5.1, p. 495). As an example, let’s assume that we want to define a class type to represent a pointer to an object of the Screen type that we wrote in Chapter 12. We’ll name this class ScreenPtr.
Our ScreenPtr class will be similar to our second HasPtr class. Users of ScreenPtr will be expected to pass a pointer to a dynamically allocated Screen. The ScreenPtr class will own that pointer and arrange to delete the underlying object when the last ScreenPtr referring to it goes away. In addition, we will not give our ScreenPtr class a default constructor. This way we’ll know that a ScreenPtr object will always refer to a Screen. Unlike a built-in pointer, there will be no unbound ScreenPtrs. Applications can use ScreenPtr objects without first testing whether they refer to a Screen object.
As does the HasPtr class, the ScreenPtr class will use-count its pointer. We’ll define a companion class to hold the pointer and its associated use count:

This class looks a lot like the U_Ptr class and has the same role. ScrPtr holds the pointer and associated use count. We make ScreenPtr a friend so that it can access the use count. The ScreenPtr class manages the use count:

Because there is no default constructor, every object of type ScreenPtr must provide an initializer. The initializer must be another ScreenPtr or a pointer to a dynamically allocated Screen. The constructor allocates a new ScrPtr object to hold that pointer and an associated use count.
An attempt to define a ScreenPtr with no initializer is in error:
![]()
Supporting Pointer Operations
Among the fundamental operations a pointer supports are dereference and arrow. We can give our class these operations as follows:

Overloading the Dereference Operator
The dereference operator is a unary operator. In this class, it is defined as a member so it has no explicit parameters. The operator returns a reference to the Screen to which this ScreenPtr points.
As with the subscript operator, we need both const and nonconst versions of the dereference operator. These differ in their return types: The const member returns a reference to const to prevent users from changing the underlying object.
Overloading the Arrow Operator
Operator arrow is unusual. It may appear to be a binary operator that takes an object and a member name, dereferencing the object in order to fetch the member. Despite appearances, the arrow operator takes no explicit parameter.
There is no second parameter because the right-hand operand of -> is not an expression. Rather, the right-hand operand is an identifier that corresponds to a member of a class. There is no obvious, useful way to pass an identifier as a parameter to a function. Instead, the compiler handles the work of fetching the member.
When we write
point->action();
precedence rules make it equivalent to writing
(point->action)();
In other words, we want to call the result of evaluating point->action. The compiler evaluates this code as follows:
- If
pointis a pointer to a class object that has a member namedaction, then the compiler writes code to call theactionmember of that object. - Otherwise, if
pointis an object of a class that definesoperator->, thenpoint->actionis the same aspoint.operator->()->action. That is, we executeoperator->()onpointand then repeat these three steps, using the result of executingoperator->onpoint. - Otherwise, the code is in error.
Using Overloaded Arrow
We can use a ScreenPtr object to access members of a Screen as follows:
![]()
Because p is a ScreenPtr, the meaning of p->display isthe same as evaluating (p.operator->())->display. Evaluating p.operator->() calls the operator-> from class ScreenPtr, which returns a pointer to a Screen object. That pointer is used to fetch and run the display member of the object to which the ScreenPtr points.
Constraints on the Return from Overloaded Arrow
The overloaded arrow operator must return either a pointer to a class type or an object of a class type that defines its own operator arrow.
If the return type is a pointer, then the built-in arrow operator is applied to that pointer. The compiler dereferences the pointer and fetches the indicated member from the resulting object. If the type pointed to does not define that member, then the compiler generates an error.
If the return value is another object of class type (or reference to such an object), then the operator is applied recursively. The compiler checks whether the type of the object returned has a member arrow and if so, applies that operator. Otherwise, the compiler generates an error. This process continues until either a pointer to an object with the indicated member is returned or some other value is returned, in which case the code is in error.
14.7 Increment and Decrement Operators
The increment (++) and decrement (--) operators are most often implemented for classes, such as iterators, that provide pointer like behavior on the elements of a sequence. As an example, we might define a class that points to an array and provides checked access to elements in that array. Ideally, our checked-pointer class could be used on arrays of any type, which we’ll learn how to do in Chapter 16 when we cover class templates. For now, our class will handle arrays of ints:

Like ScreenPtr, this class has no default constructor. We must supply pointers to an array when we create a CheckedPtr. A CheckedPtr has three data members: beg, which points to the first element in the array; end, which points one past the end of the array; and curr, which points to the array element to which this CheckedPtr object currently refers.
The constructor takes two pointers: one pointing to the beginning of the array and the other one past the end of the array. The constructor initializes beg and end from these pointers and initializes curr to point to the first element.
Defining the Increment/Decrement Operators
There is no language requirement that the increment or decrement operators be made members of the class. However, because these operators change the state of the object on which they operate, our preference is to make them members.
Before we can define the overloaded increment and decrement operators for CheckedPtr, we must think about one more thing. For the built-in types, there are both prefix and postfix versions of the increment and decrement operators. Not surprisingly, we can define both the prefix and postfix instances of these operators for our own classes as well. We’ll look at the prefix versions first and then implement the postfix ones.
Defining Prefix Increment/Decrement Operators
The declarations for the prefix operators look as one might expect:

For consistency with the built-in operators, the prefix operations should return a reference to the incremented or decremented object.
This increment operator ensures that the user can’t increment past the end of the array by checking curr against end. We throw an out_of_range exception if the increment would move curr past end; otherwise, we increment curr and return a reference to the object:

The decrement operator behaves similarly, except that it decrements curr and checks whether the decrement would move curr past beg:

Differentiating Prefix and Postfix Operators
There is one problem with defining both the prefix and postfix operators: They each take the same number and type of parameters. Normal overloading cannot distinguish between whether the operator we’re defining is the prefix version or the postfix.
To solve this problem, the postfix operator functions take an extra (unused) parameter of type int. When we use the postfix operator, the compiler supplies 0 as the argument for this parameter. Although our postfix function could use this extra parameter, it usually should not. That parameter is not needed for the work normally performed by a postfix operator. Its sole purpose is to distinguish the definition of the postfix function from the prefix version.
Defining the Postfix Operators
We can now add the postfix operators to CheckedPtr:

For consistency with the built-in operators, the postfix operators should return the old (unincremented or undecremented) value. That value is returned as a value, not a reference.
The postfix operators might be implemented as follows:

The postfix versions are a bit more involved than the prefix operators. They have to remember the current state of the object before incrementing the object. These operators define a local CheckedPtr, which is initialized as a copy of *this— that is, ret is a copy of the current state of this object.
Having kept a copy of the current state, the operator calls its own prefix operator to do the increment or decrement, respectively:
++*this
calls the CheckedPtr prefix increment operator on this object. That operator checks that the increment is safe and either increments curr or throws an exception. Assuming no exception was thrown, the postfix function completes by returning the stored copy in ret. Thus, after the return, the object itself has been advanced, but the value returned reflects the original, unincremented value.
Because these operators are implemented by calling the prefix versions, there is no need to check that the curr is in range. That check, and the throw if necessary, is done inside the corresponding prefix operator.
Calling the Postfix Operators Explicitly
As we saw on page 509, we can explicitly call an overloaded operator rather than using it as an operator in an expression. If we want to call the postfix version using a function call, then we must pass a value for the integer argument:

The value passed usually is ignored but is necessary to alert the compiler that the postfix version is desired.
Ordinarily it is best to define both the prefix and postfix versions. Classes that define only the prefix version or only the postfix version will surprise users who are accustomed to being able to use either form.
14.8 Call Operator and Function Objects
The function-call operator can be overloaded for objects of class type. Typically, the call operator is overloaded for classes that represent an operation. For example, we could define a struct named absInt that encapsulates the operation of converting a value of type int to its absolute value:

This class is simple. It defines a single operation: the function-call operator. That operator takes a single parameter and returns the absolute value of its parameter.
We use the call operator by applying an argument list to an object of the class type, in a way that looks like a function call:
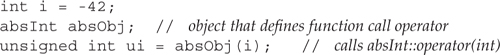
Even though absObj is an object and not a function, we can make a “call” on that object. The effect is to run the overloaded call operator defined by the object absObj. That operator takes an int value and returns its absolute value.
The function-call operator must be declared as a member function. A class may define multiple versions of the call operator, each of which differs as to the number or types of their parameters.
Objects of class types that define the call operator are often referred to as function objects—that is, they are objects that act like functions.
14.8.1 Using Function Objects with Library Algorithms
Function objects are most often used as arguments to the generic algorithms. As an example, recall the problem we solved in Section 11.2.3 (p. 400). That program analyzed words in a set of stories, counting how many of them were of size six or greater. One part of that solution involved defining a function to determine whether a given string was longer than six characters in length:

We used GT6 as an argument to the count_if algorithm to count the number of words for which GT6 returned true:
![]()
Function Objects Can Be More Flexible than Functions
There was a serious problem with our implementation: It hardwired the number six into the definition of the GT6 function. The count_if algorithm runs a function that takes a single parameter and returns a bool. Ideally, we’d pass both the string and the size we wanted to test. In that way, we could use the same code to count strings of differing sizes.
We could gain the flexibility we want by defining GT6 as a class with a function-call member. We’ll name this class GT_cls to distinguish it from the function:

This class has a constructor that takes an integral value and remembers that value in its member named bound. If no value is provided, the constructor sets bound to zero. The class also defines the call operator, which takes a string and returns a bool. That operator compares the length of its string argument to the value stored in its data member bound.
Using a GT_cls Function Object
We can do the same count as before but this time we’ll use an object of type GT_cls rather than the GT6 function:
![]()
This call to count_if passes a temporary object of type GT_cls rather than the function named GT6. We initialize that temporary using the value 6, which the GT_cls constructor stores in its bound member. Now, each time count_if calls its function parameter, it uses the call operator from GT_cls. That call operator tests the size of its string argument against the value in bound.
Using the function object, we can easily revise our program to test against another value. We need to change only the argument to the constructor for the object we pass to count_if. For example, we could count the number of words of length five or greater by revising our program as follows:
![]()
More usefully, we could count the number of words with lengths greater than one through ten:

To write this program using a function—instead of a function object—would require that we write ten different functions, each of which would test against a different value.
14.8.2 Library-Defined Function Objects
The standard library defines a set of arithmetic, relational, and logical function-object classes, which are listed in Table 14.3 on the following page. The library also defines a set of function adaptors that allow us to specialize or extend the function-object classes defined by the library or those that we define ourselves. The library function-object types are defined in the functional header.
Table 14.3. Library Arithmetic Function Objects

Each Class Represents a Given Operator
Each of the library function-object classes represents an operator—that is, each class defines the call operator that applies the named operation. For example, plus is a template type that represents the addition operator. The call operator in the plus template applies + to a pair of operands.
Different function-object classes define call operators that perform different operations. Just as plus defines a call operator that executes the + operator; the modulus class defines a call operator that applies the binary % operator; the equal_to class applies ==; and so on.
There are two unary function-object classes: unary minus (negate<Type>) and logical NOT (logical_not<Type>). The remaining library function objects are binary function-object classes representing the binary operators. The call operators defined for the binary operators expect two parameters of the given type; the unary function-object types define a call operator that takes a single argument.
The Template Type Represents the Operand(s) Type
Each of the function-object classes is a class template to which we supply a single type. As we know from the sequential containers such as vector, a class template is a class that can be used on a variety of types. The template type for the function-object classes specifies the parameter type for the call operator.
For example, plus<string> applies the string addition operator to string objects; for plus<int> the operands are ints; plus<Sales_item> applies + to Sales_items; and so on:

Using a Library Function Object with the Algorithms
Function objects are often used to override the default operator used by an algorithm. For example, by default, sort uses operator< to sort a container in ascending order. To sort the container in descending order, we could pass the function object greater. That class generates a call operator that invokes the greater-than operator of the underlying element type. If svec is a vector<string>
// passes temporary function object that applies > operator to two strings
sort(svec.begin(), svec.end(), greater<string>());
sorts the vector in descending order. As usual, we pass a pair of iterators to denote the sequence that should be sorted. The third argument is used to pass a predicate (Section 11.2.3, p. 402) function to use to compare elements. That argument is a temporary of type greater<string>, which is a function object that applies the > operator to two string operands.
14.8.3 Function Adaptors for Function Objects
The standard library provides a set of function adaptors with which to specialize and extend both unary and binary function objects. The function adaptors are divided into the following two categories.
- Binders: A binder is a function adaptor that converts a binary function object into a unary function object by binding one of the operands to a given value.
- Negators: A negator is a function adaptor that reverses the truth value of a predicate function object.
The library defines two binder adaptors: bind1st and bind2nd. Each binder takes a function object and a value. As you might expect, bind1st binds the given value to the first argument of the binary function object, and bind2nd binds the value to the second. For example, to count all the elements within a container that are less than or equal to 10, we would pass count_if the following:
![]()
The third argument to count_if uses the bind2nd function adaptor. That adaptor returns a function object that applies the <= operator using 10 as the right-hand operand. This call to count_if counts the number of elements in the input range that are less than or equal to 10.
The library also provides two negators: not1 and not2. Again, as you might expect, not1 reverses the truth value of a unary predicate function object, and not2 reverses the truth value of a binary predicate function object.
To negate our binding of the less_equal function object, we would write
![]()
Here we first bind the second operand of the less_equal object to 10, effectively transforming that binary operation into a unary operation. We then negate the return from the operation using not1. The effect is that each element will be tested to see if it is <= to 10. Then, the truth value of that result will be negated. In effect, this call counts those elements that are not <= to 10.
14.9 Conversions and Class Types
In Section 12.4.4 (p. 461) we saw that a nonexplicit constructor that can be called with one argument defines an implicit conversion. The compiler will use that conversion when an object of the argument type is supplied and an object of the class type is needed. Such constructors define conversions to the class type.
In addition to defining conversions to a class type, we can also define conversions from the class type. That is, we can define a conversion operator that, given an object of the class type, will generate an object of another type. As with other conversions, the compiler will apply this conversion automatically. Before showing how to define such conversions, we’ll look at why they might be useful.
14.9.1 Why Conversions Are Useful
Assume that we want to define a class, which we’ll name SmallInt, to implement safe small integers. Our class will allow us to define objects that could hold the same range of values as an 8-bit unsigned char—that is, 0 to 255. This class would catch under- and overflow errors and so would be safer to use than a built-in unsigned char.
We’d want our class to define all the same operations as are supported by an unsigned char. In particular, we’d want to define the five arithmetic operators (+, -, *, /, and %) and the corresponding compound-assignment operators; the four relational operators (<, <=, >, and >=); and the equality operators (== and !=). Evidently, we’d need to define 16 operators.
Supporting Mixed-Type Expressions
Moreover, we’d like to be able to use these operators in mixed-mode expressions. For example, it should be possible to add two SmallInt objects and also possible to add any of the arithmetic types to a SmallInt. We could come close by defining three instances for each operator:
int operator+(int, const SmallInt&);
int operator+(const SmallInt&, int);
SmallInt operator+(const SmallInt&, const SmallInt&);
Because there is a conversion to int from any of the arithmetic types, these three functions would cover our desire to support mixed mode use of SmallInt objects. However, this design only approximates the behavior of built-in integer arithmetic. It wouldn’t properly handle mixed-mode operations for the floating-point types, nor would it properly support addition of long, unsigned int, or unsigned long. The problem is that this design converts all arithmetic types— even those bigger than int—to int and does an int addition.
Conversions Reduce the Number of Needed Operators
Even ignoring the issue of floating-point or large integral operands, if we implemented this design, we’d have to define 48 operators! Fortunately, C++ provides a mechanism by which a class can define its own conversions that can be applied to objects of its class type. For SmallInt, we could define a conversion from SmallInt to type int. If we define the conversion, then we won’t need to define any of the arithmetic, relational, or equality operators. Given a conversion to int, a SmallInt object could be used anywhere an int could be used.
If there were a conversion to int, then
![]()
would be resolved by
- Converting
sito anint. - Converting the resulting
inttodoubleand adding it to the double literal constant3.14159, yielding adoublevalue.
14.9.2 Conversion Operators
A conversion operator is a special kind of class member function. It defines a conversion that converts a value of a class type to a value of some other type. A conversion operator is declared in the class body by specifying the keyword operator followed by the type that is the target type of the conversion:

A conversion function takes the general form
operator type();
where type represents the name of a built-in type, a class type, or a name defined by a typedef. Conversion functions can be defined for any type (other than void) that could be a function return type. In particular, conversions to an array or function type are not permitted. Conversions to pointer types—both data and function pointers—and to reference types are allowed.
A conversion function must be a member function. The function may not specify a return type, and the parameter list must be empty.
All of the following declarations are errors:

Although a conversion function does not specify a return type, each conversion function must explicitly return a value of the named type. For example, operator int returns an int; if we defined an operator Sales_item, it would return a Sales_item; and so on.
Conversion operations ordinarily should not change the object they are converting. As a result, conversion operators usually should be defined as const members.
Implicit Class-Type Conversions
Once a conversion exists, the compiler will call it automatically (Section 5.12.1, p. 179) in the same places that a built-in conversion would be used:
• In expressions:
![]()
• In conditions:
![]()
• When passing arguments to or returning values from a function:
![]()
• As operands to overloaded operators:
// convert si to int then call operator<< on the int value
cout << si << endl;
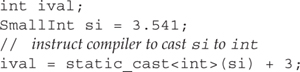
Class-Type Conversions and Standard Conversions
When an expression contains an object of class type that must be implicitly converted, the conversion function need not generate an exact match for the needed type. An implicit class-type conversion can be followed by a standard conversion (Section 5.12.3, p. 181) to obtain the necessary type. For example, in the comparison between a SmallInt and a double
![]()
si is first converted from a SmallInt to an int, and then the int value is converted to double.
Only One Implicit Class-Type Conversion May Be Applied
An implicit class-type conversion may not be followed by another implicit class-type conversion. If more than one implicit class-type conversion is needed then the code is in error.
For example, assume we had another class, Integral, that could be converted to SmallInt but that had no conversion to int:

We could use an Integral where a SmallInt is needed, but not where an int is required:

When we create si, we use the SmallInt copy constructor. First int_val is converted to a SmallInt by invoking the Integral conversion operator to generate a temporary value of type SmallInt. The (synthesized) SmallInt copy constructor then uses that value to initialize si.
The first call to calc is also okay: The argument si is automatically converted to int, and the int value is passed to the function.
The second call is an error: There is no direct conversion from Integral to int. To get an int from an Integral would require two class-type conversions: first from Integral to SmallInt and then from SmallInt to int. However, the language allows only one class-type conversion, so the call is in error.
Standard Conversions Can Precede a Class-Type Conversion
When using a constructor to perform an implicit conversion (Section 12.4.4, p. 462), the parameter type of the constructor need not exactly match the type supplied. For example, the following code invokes the constructor SmallInt(int) defined in class SmallInt to convert sobj to the type SmallInt:

If needed, a standard conversion sequence can be applied to an argument before a constructor is called to perform a class-type conversion. To call the function calc(), a standard conversion is applied to convert dobj from type double to type int. The SmallInt(int) constructor is then invoked to convert the result of the conversion to the type SmallInt.
Exercises Section 14.9.2
Exercise 14.40: Write operators that could convert a Sales_item to string and to double. What values do you think these operators should return? Do you think these conversions are a good idea? Explain why or why not.
Exercise 14.41: Explain the difference between these two conversion operators:

Are either of these conversions too restricted? If so, how might you make the conversion more general?
Exercise 14.42: Define a conversion operator to bool for the CheckoutRecord class from the exercises in Section 14.2.1 (p. 515).
Exercise 14.43: Explain what the bool conversion operator does. Is that the only possible meaning for this conversion for the CheckoutRecord type? Explain whether you think this conversion is a good use of a conversion operation.
14.9.3 Argument Matching and Conversions

The rest of this chapter covers a somewhat advanced topic. It can be safely skipped on first reading.
Class-type conversions can be a boon to implementing and using classes. By defining a conversion to int for SmallInts, we made the class easier to implement and easier to use. The int conversion lets users of SmallInt use all the arithmetic and relational operators on SmallInt objects. Moreover, users can safely write expressions that intermix SmallInts and other arithmetic types. The class implementor’s job is made much easier by defining a single conversion operator instead of having to define 48 (or more) overloaded operators.
Class-type conversions can also be a great source of compile-time errors. Problems arise when there are multiple ways to convert from one type to another. If there are several class-type conversions that could be used, the compiler must figure out which one to use for a given expression. In this section, we look at how class-type conversions are used to match an argument to its corresponding parameter. We look first at how parameters are matched for functions that are not overloaded and then look at overloaded functions.
Used carefully, class-type conversions can greatly simplify both class and user code. Used too freely, they can lead to mysterious compile-time errors that can be hard to understand and hard to avoid.
Argument Matching and Multiple Conversion Operators
To illustrate how conversions on values of class type interact with function matching, we’ll add two additional conversions to our SmallInt class. We’ll add a second constructor that takes a double and also define a second conversion operator to convert SmallInt to double:

Ordinarily it is a bad idea to give a class conversions to or from two built-in types. We do so here to illustrate the pitfalls involved.
Consider the simple case where we call a function that is not overloaded:

Either conversion operator could be used in the call to compute:
operator intgenerates an exact match to the parameter type.operator doublefollowed by the standard conversion fromdoubletointmatches the parameter type.
An exact match is a better conversion than one that requires a standard conversion. Hence, the first conversion sequence is better. The conversion function SmallInt::operator int() is chosen to convert the argument.
Similarly, in the second call, fp_compute could be called using either conversion. However, the conversion to double is an exact match; it requires no additional standard conversion.
The final call to extended_compute is ambiguous. Either conversion function could be used, but each would have to be followed by a standard conversion to get to long double. Hence, neither conversion is better than the other, so the call is ambiguous.
If two conversion operators could be used in a call, then the rank of the standard conversion (Section 7.8.4, p. 272), if any, following the conversion function is used to select the best match.
Argument Matching and Conversions by Constructors
Just as there might be two conversion operators, there can also be two constructors that might be applied to convert a value to the target type of a conversion.
Consider the manip function, which takes an argument of type SmallInt:

In the first call, we could use either of the SmallInt constructors to convert d to a value of type SmallInt. The int constructor requires a standard conversion on d, whereas the double constructor is an exact match. Because an exact match is better than a standard conversion, the constructor SmallInt(double) is used for the conversion.
In the second call, the reverse is true. The SmallInt(int) constructor provides an exact match—no additional conversion is needed. To call the SmallInt constructor that takes a double would require that i first be converted to double. For this call, the int constructor would be used to convert the argument.
The third call is ambiguous. Neither constructor is an exact match for long. Each would require that the argument be converted before using the constructor:
- standard conversion (
longtodouble) followed bySmallInt(double) - standard conversion (
longtoint) followed bySmallInt(int)
These conversion sequences are indistinguishable, so the call is ambiguous.
When two constructor-defined conversions could be used, the rank of the standard conversion, if any, required on the constructor argument is used to select the best match.
Ambiguities When Two Classes Define Conversions
When two classes define conversions to each other, ambiguities are likely:

The argument int_val can be converted to a SmallInt in two different ways. The compiler could use the SmallInt constructor that takes an Integral object or it could use the Integral conversion operation that converts an Integral to a SmallInt. Because these two functions are equally good, the call is in error.
In this case, we cannot use a cast to resolve the ambiguity—the cast itself could use either the conversion operation or the constructor. Instead, we would need to explicitly call the conversion operator or the constructor:
![]()
Moreover, conversions that we might think would be ambiguous can be legal for what seem like trivial reasons. For example, our SmallInt class constructor copies its Integral argument. If we change the constructor so that it takes a reference to const Integral
class SmallInt {
public:
SmallInt(const Integral&);
};
our call to compute(int_val) is no longer ambiguous! The reason is that using the SmallInt constructor requires binding a reference to int_val, whereas using class Integral’s conversion operator avoids this extra step. This small difference is enough to tip the balance in favor of using the conversion operator.
The best way to avoid ambiguities or surprises is to avoid writing pairs of classes where each offers an implicit conversion to the other.
14.9.4 Overload Resolution and Class Arguments
As we have just seen, the compiler automatically applies a class conversion operator or constructor when needed to convert an argument to a function. Class conversion operators, therefore, are considered during function resolution. Function overload resolution (Section 7.8.2, p. 269) consists of three steps:
- Determine the set of candidate functions: These are the functions with the same name as the function being called.
- Select the viable functions: These are the candidate functions for which the number and type of the function’s parameters match the arguments in the call. When selecting the viable functions, the compiler also determines which conversion operations, if any, are needed to match each parameter.
- The best match function is selected. To determine the best match, the type conversions needed to convert argument(s) to the type of the corresponding parameter(s) are ranked. For arguments and parameters of class type, the set of possible conversions includes class-type conversions.
Standard Conversions Following Conversion Operator
Which function is the best match can depend on whether one or more class-type conversions are involved in matching different functions.
If two functions in the overload set can be matched using the same conversion function, then the rank of the standard conversion sequence that follows or precedes the conversion is used to determine which function has the best match.
Otherwise, if different conversion operations could be used, then the conversions are considered equally good matches, regardless of the rank of any standard conversions that might or might not be required.
On page 541 we looked at the effect of class-type conversions on calls to functions that are not overloaded. Now, we’ll look at similar calls but assume that the functions are overloaded:
void compute(int);
void compute(double);
void compute(long double);
Assuming we use our original SmallInt class that only defines one conversion operator—the conversion to int—then if we pass a SmallInt to compute, the call is matched to the version of compute that takes an int.
All three compute functions are viable:
• compute(int) is viable because SmallInt has a conversion to int. That conversion is an exact match for the parameter.
• compute(double) and compute(long double) are also viable, by using the conversion to int followed by the appropriate standard conversion to either double or long double.
Because all three functions would be matched using the same class-type conversion, the rank of the standard conversion, if any, is used to determine the best match. Because an exact match is better than a standard conversion, the function compute(int) is chosen as the best viable function.
The standard conversion sequence following a class-type conversion is used as a selection criterion only if the two conversion sequences use the same conversion operation.
Multiple Conversions and Overload Resolution
We can now see one reason why adding a conversion to double is a bad idea. If we use the revised SmallInt class that defines conversions to both int and double, then calling compute on a SmallInt value is ambiguous:

In this case we could use the operator int to convert si and call the version of compute that takes an int. Or we could use operator double to convert si and call compute(double).
The compiler will not attempt to distinguish between two different class-type conversions. In particular, even if one of the calls required a standard conversion following the class-type conversion and the other were an exact match, the compiler would still flag the call as an error.
Using a Cast to Disambiguate
A programmer who is faced with an ambiguous conversion can use a cast to indicate explicitly which conversion operation to apply:

This call is now legal because it explicitly says which conversion operation to apply to the argument. The type of the argument is forced to int by the cast. That type exactly matches the parameter of the first version of compute that takes an int.
Standard Conversions and Constructors
Let’s look at overload resolution when multiple conversion constructors exist:

The problem is that both classes, Integral and SmallInt, provide constructors that take an int. Either constructor could be used to match a version of manip. Hence, the call is ambiguous: It could mean convert the int to Integral and call the first version of manip, or it could mean convert the int to a SmallInt and call the second version.
This call would be ambiguous even if one of the classes defined a constructor that required a standard conversion for the argument. For example, if SmallInt defined a constructor that took a short instead of an int, the call manip(10) would require a standard conversion from int to short before using that constructor. The fact that one call requires a standard conversion and the other does not is immaterial when selecting among overloaded versions of a call. The compiler will not prefer the direct constructor; the call would still be ambiguous.
Explicit Constructor Call to Disambiguate
The caller can disambiguate by explicitly constructing a value of the desired type:
![]()
Needing to use a constructor or a cast to convert an argument in a call to an overloaded function is a sign of bad design.
14.9.5 Overloading, Conversions, and Operators
Overloaded operators are overloaded functions. The same process that is used to resolve a call to an overloaded function is used to determine which operator— built-in or class-type—to apply to a given expression. Given code such as
ClassX sc;
int iobj = sc + 3;
Exercises Section 14.9.4
Exercise 14.44: Show the possible class-type conversion sequences for each of the following initializations. What is the outcome of each initialization?

Exercise 14.45: Which calc() function, if any, is selected as the best viable function for the following call? Show the conversion sequences needed to call each function and explain why the best viable function is selected.

there are four possibilities:
• There is an overloaded addition operator that matches ClassX and int.
• There are conversions to convert sc and/or to convert an int to types for which + is defined. If so, this expression will use the conversion(s) followed by applying the appropriate addition operator.
• The expression is ambiguous because both a conversion operator and an overloaded version of + are defined.
• The expression is invalid because there is neither a conversion nor an over-loaded + to use.
Overload Resolution and Operators
The fact that member and nonmember functions are possible changes how the set of candidate functions is selected.
Overload resolution (Section 7.8.2, p. 269) for operators follows the usual three-step process:
- Select the candidate functions.
- Select the viable functions including identifying potential conversions sequences for each argument.
- Select the best match function.
Candidate Functions for Operators
As usual, the set of candidate functions consists of all functions that have the name of the function being used, and that are visible from the place of the call. In the case of an operator used in an expression, the candidate functions include the built-in versions of the operator along with all the ordinary nonmember versions of that operator. In addition, if the left-hand operand has class type, then the candidate set will contain the overloaded versions of the operator, if any, defined by that class.
Ordinarily, the candidate set for a call includes only member functions or nonmember functions but not both. When resolving the use of an operator, it is possible for both nonmember and member versions of the operator to be candidates.
When resolving a call to a named function (as opposed to the use of an operator), the call itself determines the scope of names that will be considered. If the call is through an object of a class type (or through a reference or pointer to such an object), then only the member functions of that class are considered. Member and nonmember functions with the same name do not overload one another. When we use an overloaded operator, the call does not tell us anything about the scope of the operator function that is being used. Therefore, both member and nonmember versions must be considered.
Conversions Can Cause Ambiguity with Built-In Operators
Let’s extend our SmallInt class once more. This time, in addition to a conversion operator to int and a constructor from int, we’ll give our class an overloaded addition operator:

Now we could use this class to add two SmallInts, but we will run into ambiguity problems if we attempt to perform mixed-mode arithmetic:
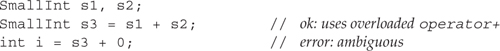
The first addition uses the overloaded version of + that takes two SmallInt values. The second addition is ambiguous. The problem is that we could convert 0 to a SmallInt and use the SmallInt version of +, or we could convert s3 to int and use the built-in addition operator on ints.
Providing both conversion functions to an arithmetic type and over-loaded operators for the same class type may lead to ambiguities between the overloaded operators and the built-in operators.
Viable Operator Functions and Conversions
We can understand the behavior of these two calls by listing the viable functions for each call. In the first call, there are two viable addition operators:
• operator+(const SmallInt&, const SmallInt&)
• The built-in operator+(int, int)
The first addition requires no conversions on either argument— s1 and s2 match exactly the types of the parameters. Using the built-in addition operator for this addition would require conversions on both arguments. Hence, the overloaded operator is a better match for both arguments and is the one that is called. For the second addition
int i = s3 + 0; // error: ambiguous
the same two functions are viable. In this case, the overloaded version of + matches the first argument exactly, but the built-in version is an exact match for the second argument. The first viable function is better for the left operand, whereas the second viable function is better for the right operand. The call is flagged as ambiguous because no best viable function can be found.
Exercises Section 14.9.5
Exercise 14.46: Given the following declarations, which operator+, if any, is selected as the best viable function for the addition expression used to initialize res? List the candidate functions, the viable functions, and the type conversions on the arguments for each viable function.

Chapter Summary
Chapter 5 described the rich set of operators that C++ defines for the built-in types. That chapter also covered the standard conversions, which automatically convert operands from one type to another.
We can define a similarly rich set of expressions for objects of our own types (i.e., class or enumeration types) by defining overloaded versions of the built-in operators. An overloaded operator must have at least one operand of class or enumeration type. An overloaded operator has the same number of operands, associativity, and precedence as the corresponding operator when applied to the built-in types.
Most overloaded operators can be defined as class members or as ordinary non-member functions. The assignment, subscript, call, and arrow operators must be class members. When an operator is defined as a member, it is a normal member function. In particular, member operators have an implicit this pointer, which is bound to the first (only operand for unary operators, left-hand operand for binary operators) operand.
Objects of classes that overload operator(), the function call operator, are known as “function objects.” Such objects are often used to define predicate functions to be used in combination with the standard algorithms.
Classes can define conversions that will be applied automatically when an object of one type is used where an object of a different type is needed. Constructors that take a single parameter and are not designated as explicit (Section 12.4.4, p. 462) define conversions from the class type to other types. Overloaded operator conversion functions define conversions from other types to the class type. Conversion operators must be members of the class that they convert. They have no parameters and define no return value. Conversion operators return a value of the type of the operator—for example, operator int returns an int.
Both overloaded operators and class-type conversions can make types easier and more natural to use. However, care should be taken to avoid designing operators or conversions that are not obvious to users of the type and to avoid defining multiple conversions between one type and another.
Defined Terms
A class that has a function-call operator and represents one of the binary operators, such as one of the arithmetic or relational operators.
An adaptor that binds an operand of a specified function object. For example, bind2nd(minus<int>(), 2) generates a unary function object that subtracts two from its operand.
Conversions to or from class types. Non-explicit constructors that take a single parameter define a conversion from the parameter type to the class type. Conversion operators define conversions from the class type to the type specified by the operator.
Conversion operators are member functions that define conversions from the class type to another type. Conversion operators must be a member of their class. They do not specify a return type and take no parameters. They return a value of the type of the conversion operator. That is, operator int returns an int, operator Sales_item returns a Sales_item, and so on.
Library type that provides a new interface for a function object.
Object of a class that defines an overloaded call operator. Function objects can be used where functions are normally expected.
An adaptor that negates the value returned by the specified function object. For example, not2(equal_to<int>()) generates a function object that is equivalent to not_equal_to<int>.
A class that defines pointer-like behavior and other functionality, such as reference counting, memory management, or more thorough checking. Such classes typically define overloaded versions of dereference (operator*) and member access (operator->).
A class that has a function-call operator and represents one of the unary operators, unary minus or logical NOT.