
7
Introduction to Cyber Anonymity
In the previous chapter we talked about the artifacts that can be collected by an attacker from individuals and companies from devices, networks, and browsers. Not only attackers but also competitors collect information and artifacts from users. We discussed the tools and techniques that attackers use to compromise networks and we discussed how browsers can be used by the attackers to collect information from users in particular.
This chapter we will be focusing on cyber anonymity. The flow of this chapter will be as follows:
- Definition of cyber anonymity
- Privacy and anonymity
- Levels of cyber anonymity
- Best practices to maintain cyber anonymity
- Developing a cyber anonymity mindset
Definition of cyber anonymity
The term anonymity, like many other English terms, originates from two Greek words. The first half of the word, an, is derived from a Greek word meaning without, and the second half, onoma, is another Greek word meaning name. Combining these two words created the term anonymous – maintaining the state of going unnamed is referred to as anonymity. When it comes to the cyber world, anonymity refers to remaining online without revealing your identity. There are different levels of anonymity, which will be discussed in detail in the third topic of this chapter.
The moment you connect to the internet, your information will be collected in many layers, as we discussed in earlier chapters. The meaning of cyber anonymity is making it impossible for others to find the owner of a message or an act by not revealing their identity while remaining connected. Another definition of cyber anonymity is performing activities connected to the internet without your identity being revealed. As you can see, anonymity is also associated with privacy. When privacy is missing, anonymity cannot be maintained. Whoever would like to maintain cyber anonymity has to protect their privacy first. We use different identity systems in physical interactions, including national identity cards, passports, driver’s licenses, and social security numbers, but in the cyber world, mainly, identities are represented by usernames or user IDs.
On the other hand, being anonymous considerably reduces accountability for any actions performed. This is the main reason for attackers to take precautionary actions to hide their identity when performing illegal acts, which makes it hard or impossible for investigators to trace the perpetrators after the action.
Because of this, it has become a legal requirement for many online services to provide an identity before performing any action. Once an identity is provided, it must be verified, as attackers will impersonate the identity otherwise. There are many different identity verification methods. All the identity verification methods are categorized into six categories. Identity verification is also known as authentication. The following are the commonly available authentication methods:
- Knowledge-based authentication (KBA) – KBA verifies user identities by requiring knowledge-based information. This can simply be a password, a PIN number, or a series of questions that only the user is expected to know. These questions are not very common questions – for the user, it’s easy to answer but very hard for others. This authentication usually hardens with a time limit for the answer and attempt limit. Most importantly, KBA is the easiest method for users to use to authenticate themselves, but the disadvantage is that this can be compromised by attackers gathering information about the target. It’s the user’s responsibility not to reveal sensitive information to the public.
- Multi-Factor Authentication (MFA) – MFA or Two Factor Authentication (2FA) is an authentication method where the user must go through two or more authentication steps by entering a password and a code received on their mobile phone. This authentication uses any two or more of the following authentication types:
- Something you know – something you know to verify your identity (for example, a password or PIN)
- Something you have – something that the user possesses that can verify identity (for example, a smart card, a mobile phone to receive the code, or a digital key to verify your identity)
- Something you are – biometric authentication to verify your identity (facial recognition, fingerprints, iris scanning, or retinal scanning)
Since this verification is commonly used, users generally have an understanding of how to provide MFA or 2FA authentication. This requires users to provide additional verification other than a username and password based on the verification options available.
- Credit bureau-based authentication – With this verification method, when the user requests access, the user will be verified based on their credit status. If you have a good credit history, access is granted – this information is collected from large credit databases. This verification method is used for financial-related authentication, but the downside is that user credit status is used as a verification method.
- Database-based authentication – Database-based authentication is another authentication system that validates the user with the information entered compared to the information stored in the database. For example, when a passport is submitted for renewal, the status of the renewal can be tracked by providing the passport number and the application date. This verification method is generally used to provide the status of an activity and is very easy to use.
The downside of this verification method is that another person can impersonate this by guessing and providing partial information. The following is an example of this verification method:

Figure 7.1 – Database-based authentication
Database-based authentication is used to authenticate by providing information that is already stored in the database. As per this figure, the user must provide both an infringement number and vehicle registration to authenticate and access the system.
- Online authentication – This method is employed by many web portals today, by integrating an external authentication provider. For example, many web applications and websites allow you to access them by providing Facebook or Google authentication. The downside of this method is the service provider does not have visibility into the authentication and someone could impersonate this authentication with fake social media accounts or stolen accounts. When the user needs to authenticate, the service provider redirects the request to the authentication provider. The user then enters the credentials at the identity provider’s portal and authentication happens at the identity provider’s portal:

Figure 7.2 – The service provider provides external authentication providers to authenticate
As per the preceding figure, www.scribed.com provides users with access to a range of books. Users have the option of creating an identity on www.scribed.com or they can use an existing Google or Facebook account. When a user selects an external identity provider, the request will be redirected to the respective identity provider’s portal. Then, the user can provide the credentials:
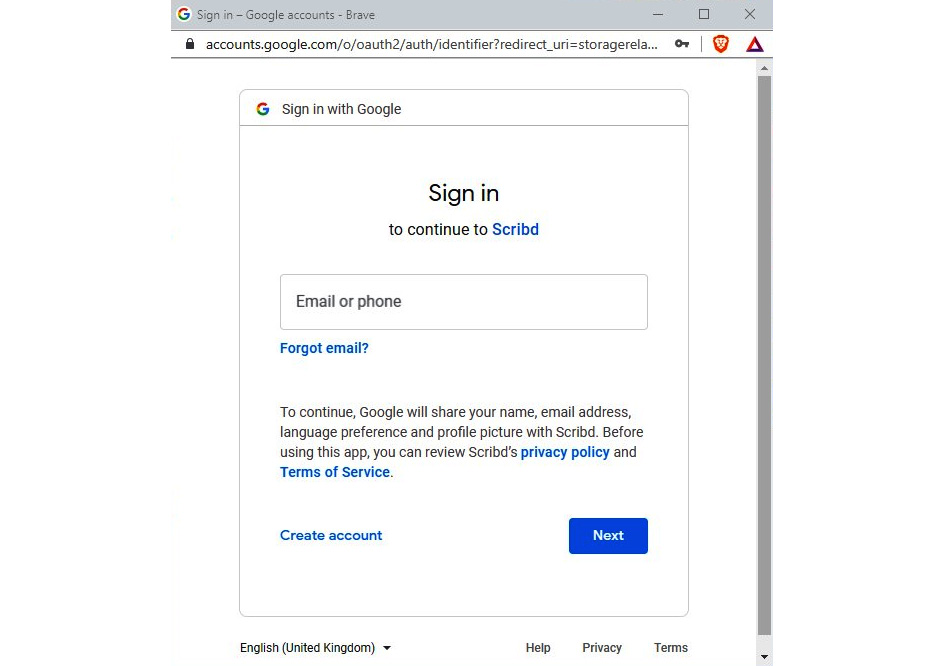
Figure 7.3 – When a user selects Google as a service provider, the request is redirected to Google
When the user provides valid credentials in the identity provider’s portal and is successfully authenticated, the identity provider redirects to the service provider again to provide access to the service.
- Biometric authentication – As we discussed under MFA and 2FA authentication, biometric authentication uses biological attributes for authentication, which are not easy to impersonate. Biometric authentication can be part of MFA or 2FA or used as a standalone authentication method.
Typically, once the user is authenticated, the user will be given access based on the least permission policy, which is known as authorization. Most systems, including financial organizations, practice this mechanism. Once the user is authorized (authorization is the level of access given to the user based on the user role), the user will be given access to the resources based on their permissions. The permission will be given based on their role. According to the security policies, the minimum set of permissions that allows them to perform their job tasks will be assigned.
In today’s world with its complex requirements, the preceding authentication systems cannot provide complete security, as attackers can use various tactics, techniques, and tools to compromise security. To overcome this concern, many identity systems incorporate zero-trust-based implementations, which are not only limited to the preceding authentication methods but also validate additional attributes such as the usual location of access, the usual device of access, realistic travel times, IP addresses, and suspicious behaviors.
For example, Azure Active Directory is one of the most used identity systems and provides identity services internally and externally. While supporting MFA or 2FA authentication and biometric authentication, it also supports configuring conditional access policies based on a range of criteria including the following:
- User risk level – If the user’s credentials are compromised, commonly used or weak users will be categorized as high-risk users and we can configure a conditional access policy to restrict access for high-risk users even if the given credentials are correct.
- Sign-in risk level – If the user is logging in from a suspicious IP range or a user’s login history is unrealistic (for example, the same user logged in previously from Singapore 15 minutes ago and now the user is trying to log in from the US), the user will be blocked from logging in even if authentication is successful.
- Device platforms – Restricts access based on the device platforms – users can be blocked from access when they are using Linux systems, for example, even if the provided credentials are correct.
- Locations – Allows or denies access from certain locations based on countries or IP addresses (excludes MFA when the user is connecting from a trustworthy location such as company headquarters).
- Client apps – Blocks or allows based on the app. For example, if the same app is available as a desktop app and a browser-based app, administrators can restrict users from logging into the system using browser-based apps.
- Filter for devices – Provides access based on device properties including device ID, display name, device ownership, manufacturer, model, operating system, operating system version, and many more attributes of the system:

Figure 7.4 – Azure Active Directory provides a conditional access policy to configure zero-trust security
If the user identity is critical, systems and infrastructures can use conditional access policies in addition to main authentication systems. Conditional access supports maintaining zero-trust security. The idea of the zero-trust security implementation is not to trust any request without verification.
For example, when a user provides the correct credentials to log into the system and the system is designed to validate a user only based on the username and password combination, we are assuming that the user credentials will never be compromised. As a result of this implementation, if an attacker compromises the user credentials and tries to access the system, the system will allow the attacker access if the credentials are correct. In today’s world, there are many attacks targeting user credentials. Compromising passwords has become common. If the systems are completely reliant on the username and the password, there can be many attackers accessing the system pretending to be users using compromised passwords.
Therefore, zero-trust implementation is necessary. Even if attackers successfully compromise a password, the system will still have to validate the user based on the different verification methods that we discussed before.
For example, if an attacker compromised a user’s password, typically, the attacker would launch this attack remotely and then try to access the service; if the system is based on a typical castle security implementation, the attacker would be able to successfully access the resources. If the systems are configured with zero-trust security, a username and password would be not enough to access the system even if these credentials have been compromised. When an attacker tries to access the system using the compromised credentials, even if the credentials are correct, the system will try to validate the following:
- Whether the request is coming from the usual location
- Whether the request is coming from the usual device
- Whether the previous attempt to access the service and the current request attempt IPs are coming from the same region, and if not, whether the travel time is realistic
- Whether the current request is coming from a suspicious IP range – systems maintain real-time monitoring systems to collect suspicious IP ranges
- Whether the request is coming from known Virtual Private Network (VPN) systems commonly used by attackers
Since the system is validating the request based on the preceding criteria, even if the attacker is trying to access with compromised credentials, the system will block the attempt in real time, which makes the attacker’s successful attack useless.
This section explained the importance of implementing a proper identity system, as cyber anonymity is based on not revealing your identity. Especially for critical systems, it is very important to maintain a proper identity system – not only systems authenticating based on credentials but also monitoring other attributes that make attackers’ attempts much harder to succeed.
Privacy and anonymity
There are many arguments about privacy and anonymity – some of these arguments try to establish a connection between privacy and anonymity – but privacy and anonymity are two different concepts. In other words, maintaining privacy will not lead to anonymity. Depending on the scenario or the requirement, you might want to choose privacy or anonymity. Having a better and clear understanding of privacy and anonymity will help you to select the right option. For example, when using a mobile app, when accessing a web application, or when installing software, it will tell you that the app or software will maintain your privacy – or that it provides anonymity. Some organizations or companies are being honest here, but some are still playing with words, as most users do not have a very clear understanding of these terms.
What is privacy?
The term privacy refers to the ability to keep your personal or sensitive information exclusively to yourself and have total control over access to your information. In other words, you can control who can access your data, what the level of access is, and when they can access it and you can find out what the purpose of them accessing your information is. As a broader definition, information privacy is the right to have control over your information and how it can be collected, accessed, and used. This will often be dictated by the privacy policy in many organizations or when you are accessing any online service in the cyber world. The privacy policy is treated as a legal document that defines the way customer data is gathered, used, managed, and disclosed.
In the previous chapter, we discussed cookies – especially, we discussed how third-party cookies will collect information from users and often share it with other companies or organizations. As you may have noticed, many websites you visit today have cookie policies. Even though users frequently won’t read it, the cookie policy defines the information that they gather and how the information will be used. As an example, let’s visit the https://www.packtpub.com website. If this is your first time visiting this website using this browser, you will be prompted with a cookie policy acceptance notification.
This website has given users options to decide on collecting information. As it clearly says, “This website uses cookies and other tracking technology to analyse traffic, personalise ads and learn how we can improve the experience for our visitors and customers. We may also share information with trusted third-party providers.” Once the users give consent, their information will be collected. On the other hand, cookies will be used to provide a more personalized and rich experience for the users based on their choice:

Figure 7.5 – Cookie policy to get user consent on information collection
If you click More info, this website will take you to the privacy center where you can select what type of information collection you consent to. There are usually a few options: this website explains the privacy information, the cookies necessary for the website to function properly, which usually users cannot turn off, performance cookies, which typically do not collect information, and the third-party cookies that we discussed in the previous chapter:
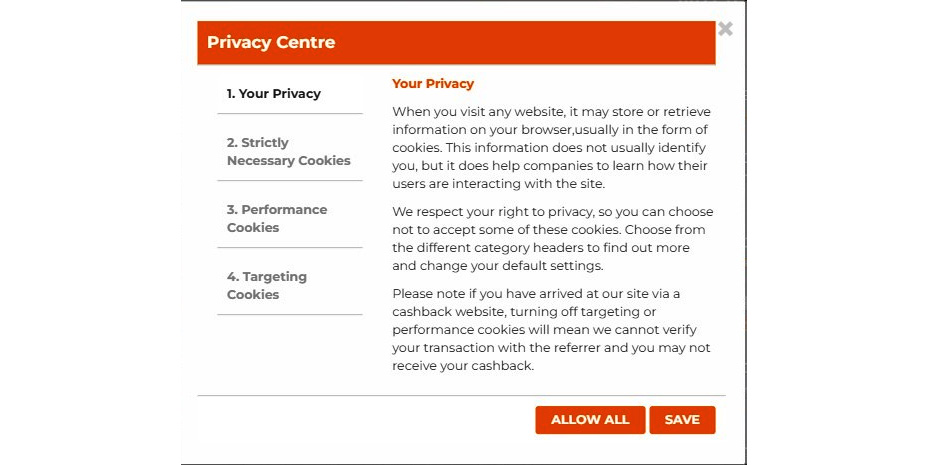
Figure 7.6 – Privacy statement on cookies
If you select the second option, Strictly Necessary Cookies, it will not allow the user to perform any action or turn off cookies that will affect the site functionality.
When you select Performance Cookies, you can allow or disallow cookies to be active. Performance cookies collect performance-related data but not personal information about the users. For example, these cookies collect information such as how many users visited this website, how long they stayed on the website, and the number of pages visited. You can select whether you want to enable these cookies or disable them. The fourth option, which is Targeting Cookies, is cookies from third-party providers. In particular, these cookies will collect information and may share it with third-party providers. This will be used by third-party providers to personalize advertisements.
If you click on the Learn more link of this website, it will take you to the company privacy policy, which explains how they collect customer data, including the information collected through cookies, what type of data they are collecting from customers, how they manage the data they collect, how long they will keep the data, with whom they will be sharing this information, and where the personal data will be processed:

Figure 7.7 – Privacy policy of the organization
If you read through the policy, you will find out how they collect the data. For example, they will collect data when you visit their website, when you make online purchases, when you engage with their social media, when you install their app, or when you create an account with them. They explain what type of information they collect from the customer, including customer name, date of birth, billing information, job title, telephone number, and billing information. They also explain why they collect customer data and how they manage customer data.
This example shows how this website collects customer data, manages customer data, and uses customer data. The customer has the option to decide what type of data they can collect.
What is anonymity?
Anonymity refers to hiding your identity but not your actions. As we discussed before, when you interact with the cyber world, different entities will be collecting your information in various layers. In the cyber world, you can be anonymous by preventing these entities from collecting your identity-related information. It’s more like in the physical world when someone is covering their face to prevent others from identifying them. In many robberies, robbers used to wear face masks to prevent others from identifying them. In that way, they could be anonymous, but their actions were still visible. For example, if the robbers rob a bank and wear face masks, the action is still visible, as many have seen the bank robbery take place, but they cannot identify the robbers, as they were wearing face masks. In many cases, investigators are able to catch the robbers by using a tiny bit of information that can still identify the robbers. Sometimes, it can be a tattoo on one robber’s hand, for example, which can be used by the investigators to trace the person even though they were wearing face masks.
In the same way, in the digital world, there are ways that you can be anonymous, but a small mistake can reveal your real identity. Attackers wanted to maintain anonymity all the time, as their intentions are bad and they never want to get caught. As users, our intention to be anonymous is based on ethical reasons, as we don’t want our information to be collected and processed without our consent.
Since user data will be collected in multiple layers and multiple entities, it’s not simple to be anonymous in the digital world, especially for users. When it comes to attackers and hackers being anonymous, it’s not that hard, as they are aware of these layers – as in, the ways that different entities collect identifiable information. However, for users, remaining anonymous is challenging. This is the reason we discussed various types of data collection methods. When you understand the ways that the information is collected, then you can understand and plan to prevent your data from being collected at various layers.
In the next few sections, we will be talking about different levels of cyber anonymity and the best practices when it comes to cyber anonymity. If you really want to maintain anonymity when you are interacting with the cyber world, developing the required mindset is very important. As I explained earlier, through a single mistake, investigators can trace a robber; the same thing can happen when you neglect a single piece of the process and reveal your identity.
Levels of cyber anonymity
As we discussed earlier, cyber anonymity is trying to hide your identity without hiding the action. The meaning of being anonymous is hiding your identity but your actions still being visible. Back in 1996, there was a paper published in the Journal of Universal Computer Science by Bill Finn and Hermann Maurer, who were from the computer science department at the University of Auckland. It first introduced the levels of anonymity (https://www.jucs.org/jucs_1_1/levels_of_anonymity/Flinn_B.pdf). This paper introduced multiple levels of anonymity. According to the paper, networked computer systems required multiple levels of anonymity. The paper explains five levels of anonymity, but these levels were introduced in 1996, so it does not provide categorization for the techniques and tactics used today. However, it establishes a few points to continue our discussion.
The various levels of cyber anonymity are as follows:
- Level 5 – Super-identification – According to the explanation in the paper, this level completely identifies the user and authenticates the user using the user ID and the password to the system in a unique way. All the communication transactions carried out by each user will be stored as an audit trail for later investigation if required. In those days, enterprise systems with mainframe computers used this secure identification system. When you compare this idea with today’s technology, it’s pretty much like the zero-trust authentication we discussed. In those days, it applied to mainframe systems with closed environments (closed infrastructures are not exposed to other networks or the internet).
- Level 4 – Usual identification – This is explained as systems that totally rely on a username and password combination only. If anyone has the correct username and password, the system will allow the user to access the system and access resources without validating other attributes. If you compare usual identification to today’s systems, this is like systems that authenticate users only based on credentials. We discussed castle security and zero-trust security before. If an attacker compromises the username and the password, they can access the target system without any problem, as the system only validates the user based on the username and password combination.
- Level 3 – Latent or potential identification – In this identification system, users use pseudonyms in the system. Each user has a pseudonym and is mutually disjoined, which means each user will have a screen name or username in the system, but one user cannot identify another user in the system in a real, personally identifiable way. As a result, two users cannot identify the other user’s identity directly. While the system has complete knowledge of each user, user-to-user communication is always pseudonymized. When you compare this type of identity with today’s scenario, it’s mostly in community discussions, technological forums, and bulletin board discussions that people use stage names and pseudonyms to introduce themselves. You can only identify users by the stage name or commonly used profile name. You can also find this on social media such as Twitter, YouTube, and TikTok – many people use profile names, not their real identity. Some profile users can see the person so they can identify the person, but on many profiles, they maintain some level of anonymity outwardly while providing their real identity to the system.
- Level 2 – Pen-name identification – This identity system is a bit like latent or potential identification, as users can use pseudonyms, but the difference is that even for the system, their real identity is not visible. With latent or potential identification, even though the user’s real identity is not visible, the system has complete knowledge about the user. In pen-name identification systems, even the system does not have complete knowledge about the users. The user can create an account by providing an email address – if the email system can be used to communicate and activate the account, the user can create an identity using a pen-name identification system. Since many systems provide free email accounts, users can create an email address without properly identifying themselves; thus, these systems do not have complete knowledge about the users. To apply this level of identification to today’s world, some online gaming platforms use pen-name identification, as do some community and discussion boards.
- Level 1 – Anonymous identification – In this identification system, users are identified by the system but not as addressable users. No username is required. Neither the system nor the other users can uniquely identify the user. The system keeps logs of events related to this entity and its activities but is not able to distinguish the user, mainly to tailor system interactions based on user activities. On examining this identification, I would recognize this as partial anonymous identification, not fully anonymous identification. When comparing this to today’s technology, this is very similar to the technique we discussed in the previous chapter related to direct cookies. Direct cookies keep information about the user without an identity system. Direct cookies collect information related to the user’s device, browser, location, or IP address, but cookies will not be able to identify the user by a username.
- Level 0 – No identification of user – This identity system does not require any identity or password combination at all. Users can access the system without user IDs. The system still collects information about the user activities, as that’s how the systems are designed, but cannot distinguish the user by username or any other identity mechanism whatsoever. I would like to refer to this as partial anonymous identification; the reason is that even these systems collect information about the user’s behavior and keep information that can be used to tailor interaction with the user. This is like what third-party cookies do today. They don’t uniquely identify the user, but they collect data related to the user behaviors and search for patterns that will help them to send tailored advertisements – they can share these with other providers and these can send similar advertisements. According to the paper, this provided the highest level of anonymity at that time. Now, there are newer and better technologies introduced to maintain a better and higher level of anonymity.
The reason to start our discussion based on this paper is that this paper establishes the ground to continue our discussion of further levels of anonymity. As you may notice, Level 1 and Level 0 discussed in Bill Finn and Hermann Maurer’s paper do not provide proper anonymity, as they collect information about the user, even though they don’t collect identity-related information. Since this paper was published two decades ago, we would need to achieve a greater level of anonymity in today’s complex systems.
Beyond Level 1 and Level 0
According to the paper we discussed, the highest levels of anonymity were provided by Level 1 and Level 0, but as we understood, even though both Level 1 and Level 0 do not collect the identity or do not require authentication, both implementations collect user activity-related information. The reason behind this categorization is the definition of anonymity. By definition, anonymity hides identity, not actions. Since Level 1 and Level 0 do not collect information related to identity, the paper presented by the University of Auckland defined even Level 1 as an anonymous system.
When we compare this situation with today’s world with more complex implementations, collected information can contain sensitive and personally identifiable information even though the user identity is not collected. For example, as we discussed, direct cookies and third-party cookies collect information related to the device, browser, location, user behavior-related information, IP address, and any items that the user is interested in. Combining all this information, you could probably uniquely identify the user. If we want to establish another level beyond Level 1 and Level 0, we need to look at a system or method where none of this information is collected from the user, including the user’s device, browser, IP, or anything related to the user’s activities. If we suggested a system that did not even collect this information, it could be named a super-anonymous level.
Super-anonymous level
If we were to implement a super-anonymous level, mainly, it shouldn’t have any identity or authentication requirements as per the definition of anonymity. Then, the real challenge would be to protect users from the systems established to collect user activity-related information, as we discussed under Level 1 and Level 0. Since most of the applications developed today use web-based technologies and are accessible over browsers, inherently, browsers use direct and third-party cookies to collect information. A super-anonymous level will be a level that does not collect identifying information or any other user device-based, browser-based, or behavior-based information during the interaction with the web-based application or website. Ideally, when accessing the system, it should not only avoid collecting identification-related information but also any activity-related or behavioral information.
To maintain a super-anonymous level, we need to follow the best practices to be anonymous on the internet. As discussed, user data is collected in multiple layers, so we need to follow best practices to prevent data collection when on the internet.
Best practices to maintain cyber anonymity
We discussed the layers of cyber anonymity and how the different entities collect user information while the user is on the internet. As this process is collecting information in different layers, we need to concentrate on all the layers, not just the browser. The best practices that we are going to discuss here not only concentrate on the browser but also all the layers. Let’s look at some best practices to maintain cyber anonymity:
- Using a VPN – Whenever we connect to the internet, as we discussed, our IP can be collected by the respective web application or service. When you connect to the internet, there will be two IP addresses, called a private IP and public IP address. What they collect is our public IP address, which is assigned to you and is unique. This means there cannot be two devices that have the same public IP address at the same time, which means it will be unique. If you type ipconfig into your terminal window, it will show your private IP:

Figure 7.8 – This shows your private IP address
This will show your private IP address. In this system, the private IP address is 10.10.10.8. If you want to check your public IP address, there are multiple ways to do that. The easiest way to check your public IP is by accessing https://ip.me or you can just search whats my ip on Google:

Figure 7.9 – The ip.me site shows your public IP address and other information
When you access https://ip.me, it will show you your public IP address and other information including your internet service provider, country, location, and postal code. If you are using a VPN service, you can send your traffic over a VPN server and this will prevent the web application from detecting your public IP. There are different types of VPN services available, which we will be discussing in the next section. For now, I will use OpenVPN to show you how the traffic is sent over the VPN server. Let’s download the OpenVPN community edition client first by accessing https://openvpn.net/community-downloads/, and once downloaded, install the software onto our device. Then, we need to download the configuration file – we can download many configuration files on https://www.vpnbook.com/. There are many connectivity details available, but select OpenVPN, as we need connection details for OpenVPN:
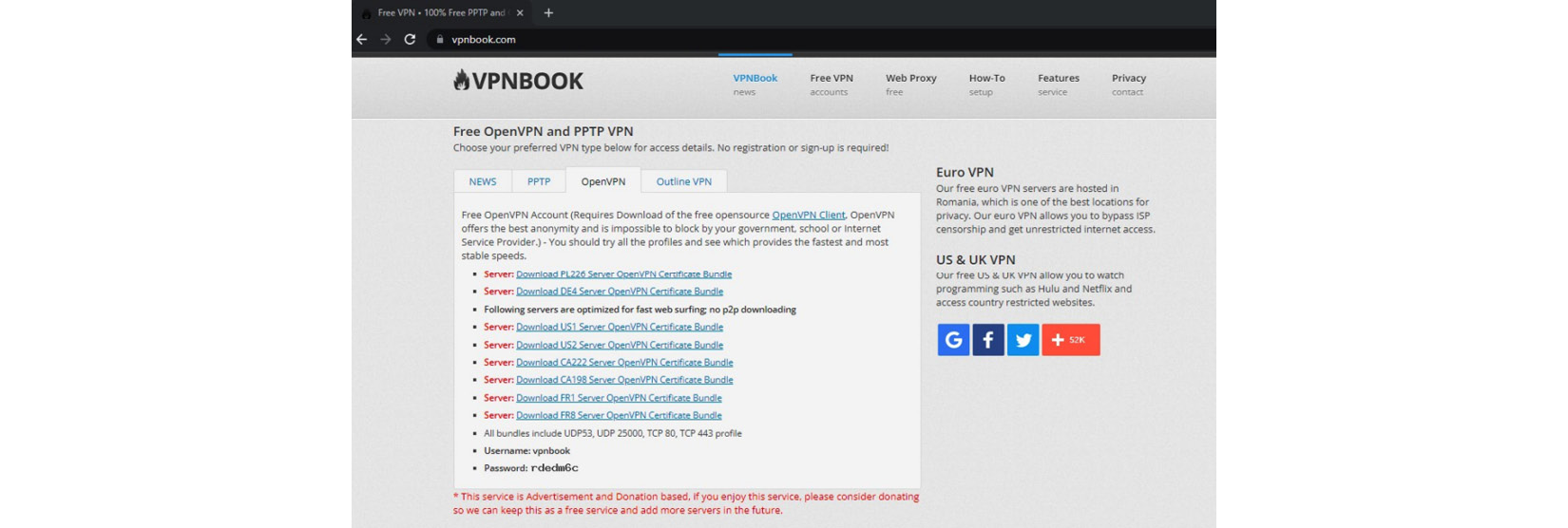
Figure 7.10 – Configuration files for OpenVPN for different servers
Select any of the listed servers to download the configuration file and extract it to any folder. Then, open the OpenVPN community edition software and import the files. Just select the FILE option and click BROWSE to select the configuration file’s location or you can simply drag and drop the files:
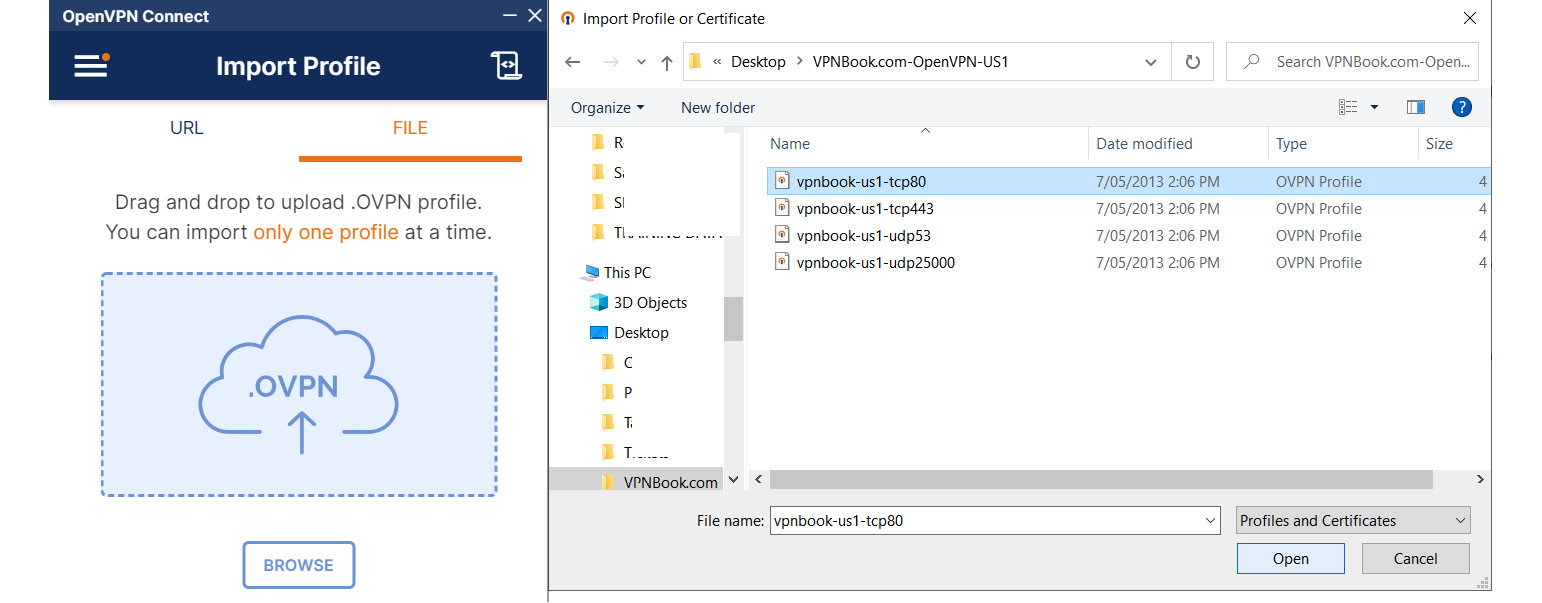
Figure 7.11 – Importing configuration files for OpenVPN for the servers
Once the configuration file is imported, you can specify the username provided by the https://www.vpnbook.com/ site and click CONNECT:
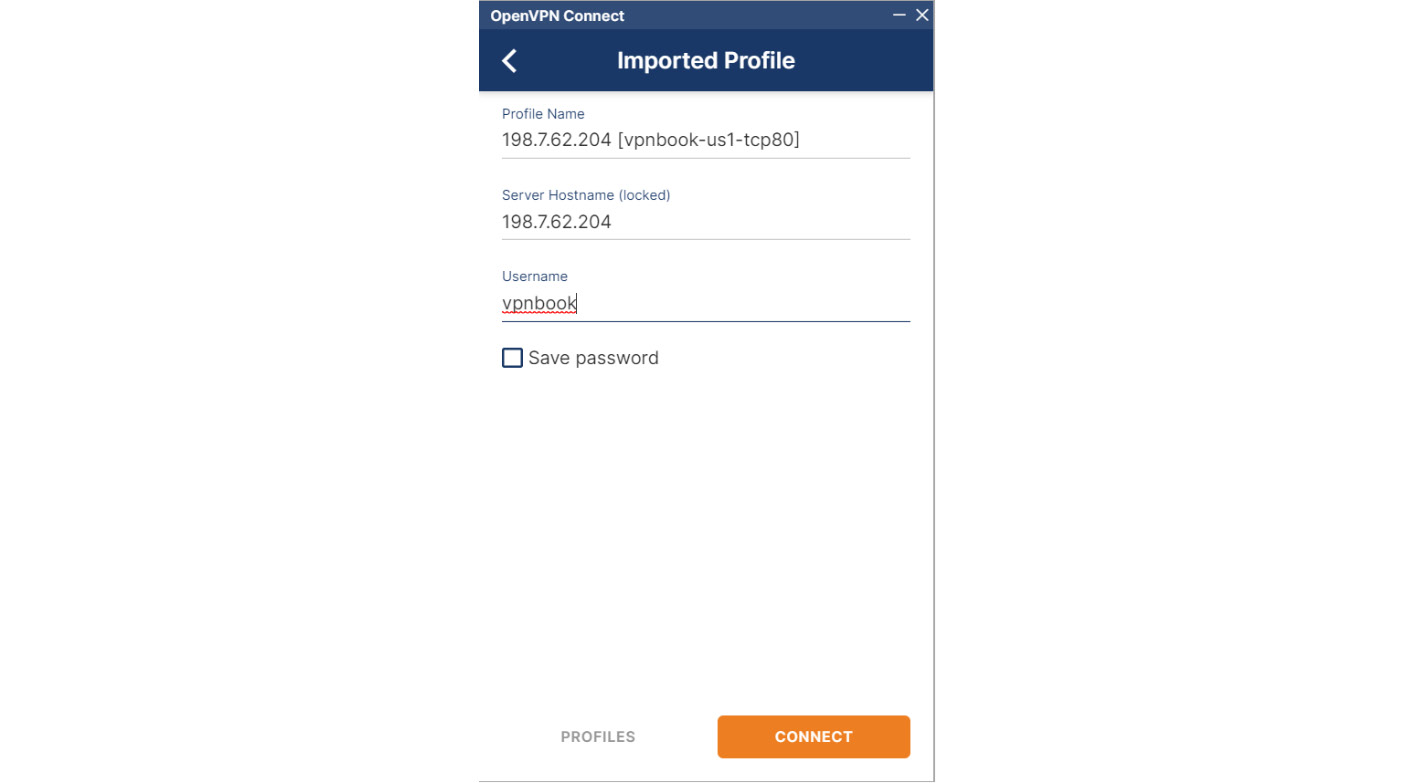
Figure 7.12 – Connecting to the VPN server
Once you click on CONNECT, it will prompt the password. You can provide the password provided by the https://www.vpnbook.com/ site when you downloaded the configuration file:

Figure 7.13 – Connected to the VPN server
Once the VPN client is successfully connected to the server, your traffic will be redirected through the VPN server. If you access any internet service now, they will be detecting the VPN server’s public IP address instead of your public IP. Now, when you try the same site, see the IP address shown there:

Figure 7.14 – Once connected to the VPN server, your public IP will be changed
Once you connected through the VPN service as shown, it will not disclose your real public IP; instead, it will show the VPN service-connected IP address. Traffic will be encrypted from your device to the VPN server. This ensures anonymity while you are interacting with the internet.
Another important thing to remember is that the VPN is only connecting you through its server, so the VPN service should be trustworthy. If you use an untrusted VPN service, that VPN service provider can also collect your information. Some browsers and operating systems have VPN services built in. The Tor browser is the best example, which we will discuss in detail later.
- Use a secure device – Since devices collect information while we are interacting, if you want to maintain cyber anonymity, you need to use a secure device. The meaning of a secure device is a device that you have total control over. If the device is shared, there are multiple people using the same device, so they can collect your data, but when you are using your own device, you can keep information to yourself, or you can even use virtual appliances to make it more secure, which we will discuss later. Once you use your device, you have the freedom to remove any data or logs created on your device. To make it more secure, you can encrypt the device using a strong encryption algorithm. You can use either BitLocker or VeraCrypt to encrypt the device.
VeraCrypt is a free and open source tool that uses strong AES256 encryption to encrypt data – you can use VeraCrypt to completely encrypt a device, including its operating system.
BitLocker also supports the Trusted Platform Module (TPM), a hardware module that provides trusted technology to protect sensitive data, which provides encryption much stronger and that’s connected to the hardware device. When stronger encryption is used and the TPM is enabled, even if the device is stolen, a third party will not be able to retrieve the data.
- Use a safe network – When you are connecting to the internet, even the network connection collects information about you. Don’t use free or public networks to connect to the internet, as you never know what they collect about you. When you are using your own trustworthy network connectivity with a stronger Wi-Fi password, at least you know that no one is sniffing your communication. If the Wi-Fi network password is guessable or weak, attackers can connect to your network easily and collect information using various techniques including sniffing. Using stronger encryption is important in the network – currently, WPA2 or WPA3 can be used as encryption to the WiFi network.
- Using a secure browser – We discussed secure browsers in the previous chapter. Brave can be a better option when compared with other browsers such as Chrome. Google heavily collects data from users and using Chrome exacerbates this. Using Tor is the best option, but for general usage, Brave will be sufficient.
- Disable cookies – We discussed this in the previous chapter in terms of important information, especially about direct cookies and third-party cookies – how the direct cookies and third-party cookies collect information and the types of information collected by them. We also discussed how we can disable third-party cookies on commonly used browsers along with the steps to do so.
- Use a stronger password – Even though we discussed many authentication systems, the username and password combination is still treated as the most used and convenient authentication method. When you are accessing your device, connecting to the network, and encrypting a device, you require passwords. When configuring passwords, we need to use super-strong passwords, as there are many password-related attacks. Many passwords are guessable and many passwords contain known information about you. There are methods to recover these passwords quite easily. Typically, a stronger password is a password that has more than eight characters with a combination of an uppercase character, a lowercase character, a special character, and a digit, but many users use passwords such as Qwerty@123, Test@123, and Admin@777, which fulfill the criteria required to become a strong password but can be commonly found in many password word lists.
If you use known information about you within the password, attackers use a method called Common User Passwords Profiler (CUPP) to generate a tailored wordlist generated to break your password. There are many tools you can find to generate CUPP passwords. I’m using cupp.py to generate this. You can download cupp.py from www.github.com/Mebus/cupp:

Figure 7.15 – CUPP generating a tailored password wordlist
Cupp.py is a Python script into which an attacker can enter known information about the user, including first name and last name, a spouse’s name, a child’s name, and birthdays. Then, the script will jumble the entered words, changing capital and simple letters and common special characters to create a long wordlist to crack the password.
Because of this, we shouldn’t be using information about ourselves or family members within our passwords. One of the ways to overcome this issue is using passphrases, as phrases are easier to remember than complex passwords and they are lengthy. Therefore, they are not as easy to break using common password-breaking techniques.
There are online services that support passphrase generation, such as https://www.useapassphrase.com/ and https://untroubled.org/pwgen/ppgen.cgi.
When you use https://www.useapassphrase.com/, it generates passwords based on the number of words:

Figure 7.16 – useapassphrase has generated a four-word passphrase
You can select the number of words you need to create the passphrase and our given example has used a four-word passphrase. The advantage of passphrases is that they are easy to remember and extremely hard to guess or break. If you noticed, the approximate crack time is given by centuries.
When you use https://untroubled.org/pwgen/ppgen.cgi to generate a passphrase, a number of options are given, including the number of words, the length of the words, enabling random capitalization, and inserting digits. This page only generates data and will not be stored by any means and it shows the number of combinations possible:

Figure 7.17 – untroubled.org password generator can generate passphrases
The untroubled.org password generator can generate passphrases that are extremely hard to guess and break using common password-cracking tools. The source code for the password generator is available to download to confirm that this site does not collect this data, but the drawback of this passphrase is that it is not easy to remember. Users need to use password managers such as KeepPass or BitWarden, which we discussed in previous chapters.
- Using secure email service – Using Gmail is secure but as we discussed, it does not provide the expected privacy. Google provides a complete ecosystem with many free services, which many users are fascinated by, but when it comes to privacy, Google keeps all our information and the traces of our activities, which is not our objective when it comes to privacy and anonymity. To maintain cyber anonymity, we need to use a more secure option such as ProtonMail. Being a Switzerland-based company, ProtonMail provides a higher level of privacy, apart from end-to-end encryption. Since Switzerland is not a member of the surveillance alliance the Five Eyes (FVEY), an intelligence alliance comprising Australia, Canada, New Zealand, the United Kingdom, and the United States, the government cannot request customer data. Being an open source product, ProtonMail provides a secure and free email service that is accessible over a browser, Android, and iOS. When you compose a mail using ProtonMail, the email will be encrypted using a client-side encryption mechanism even before the mail is sent to the ProtonMail mail servers. ProtonMail provides customers with complete privacy – in other words, the user can control who has access to the user data, and not even internal employees of ProtonMail will have access to your emails.
- User secure storage – We all are fascinated by Google services, including Google Drive, but when it comes to privacy, Google Drive is no different. We store our data in the Google services and Google collects all our information and has access to all our data. If you want to maintain cyber anonymity, it’s high time to think about secure storage options other than Google Drive. There are better and more secure solutions for storing your data. There are a few options when it comes to secure cloud storages that provide complete encryption:
- sync.com – Provides client-side, end-to-end encryption, which will not even allow hackers or internal employees to access your data. Sync does not collect, share, or sell user information to third parties. The user can completely control their privacy when using Sync.
- pcloud.com – pCloud uses TLS/SSL encryption and client-side encryption, which protects files even before they leave the client’s device. Unencrypted files never leave the customer’s device. They provide zero-knowledge privacy, which means encrypted keys will never be uploaded to the servers. They use 4096-bit RSA and 256-bit AES for encryption.
- Icedrive.com – Icedrive provides client-side encryption to everything, including file and folder names. Everything will be encrypted even before it reaches the Icedrive secure cloud. Icedrive uses TwoFish encryption and provides zero-knowledge encryption so that only the user can access and view the data.
- Use disposable email addresses when necessary – If you want to receive an activation link, download link, or One-Time Password (OTP) only once, use a temporary disposable email address. Attackers use this method to harvest email addresses for future attacks in particular. They will come up with creative ideas such as registering to download an e-book or entering your email address to receive a download link. Once you enter your email address, you will start receiving a lot of unwanted emails and spam. To avoid your email address being harvested, you can use a disposable email address.
- Stop overexposure – We discussed many layers that collect your information without your knowledge or consent. Now, we know the best practices that will prevent your information from being collected from you, but still, you might be overexposing yourself. We discussed how an image can carry your information. This can happen on your social media, forums, emails, vacancy advertisements that you are posting, in telephone conversations with unknown parties, in telephone conversations with known parties in public areas, when filling out a form, and through various other activities without thinking about it. All these acts can overexpose you.
- Don’t share sensitive or personal information – While interacting online, make sure you never share any personally identifiable information online including your address, phone number, and social security number. I have seen many people disclose their phone numbers in public when cashiers ask about a loyalty card. There are many loyalty programs, including in supermarkets, where when you are in the queue, the cashier asks what your loyalty number is. When you share your number, others in the same queue can memorize, write down, type, or record it on their phones.
- Personnel assistance programs – Personnel voice assistance systems such as Amazon Alexa make your life convenient and easy but when it comes to privacy, voice assistant programs are so bad. According to the Times Magazine, Amazon.com, Inc recruits thousands of people around the world to improve the Alexa digital assistant. These teams listen to the recordings captured by Alexa personnel assistance devices in homes and offices. Then, the recordings will be transcribed, annotated, and again fed into the software to eliminate the gaps. This shows that personal assistant programs are not that great when it comes to privacy. If you want to maintain cyber anonymity, keep personal assistant programs away.
- Secure connectivity – Whenever you interact with the internet, make sure the web applications are using https:// URLs. Simply check your browser shows the padlock sign and secure connectivity. If you are communicating with any website which does not have https, there are chances that attackers can intercept your communication as the communication is not encrypted. Hypertext Transfer Protocol Secure (HTTPS) encrypts the communication between your browser and the web application using SSL encryption. You can check this by clicking on the padlock sign on the URL:

Figure 7.18 – Secure connection established by https
If the web application doesn’t show the padlock sign as shown in the figure, your communication is not encrypted, which means that attackers can see what you are doing, even sensitive information such as your passwords and bank information, or whatever information you are communicating.
Developing a cyber anonymity mindset
When interacting with the cyber world, there are multiple components working together to establish connectivity. Once connectivity is established, data will flow through multiple layers. When you work on applications, data will be sent over multiple layers during client-server communication. As we discussed in the previous sections, we need to look at all these elements to maintain anonymity in the cyber world. Due to the vast number of elements involved, it’s not easy to maintain cyber anonymity, as all these elements are collecting information as per the design. Especially for your typical user, concentrating on all areas is going to be hard. When you concentrated on the Best practices to maintain cyber anonymity section, you may have noticed that we must be extremely mindful to maintain cyber anonymity. The best way to maintain cyber anonymity is to develop a cyber anonymity mindset.
This can be started now and applied to devices that you use all the time – these can be mobile devices, laptops, desktops, smart devices, or even personal assistance devices. Just think about whether your own device is secure. You can assess whether your own device is secure by answering the following questions:
- Is my device physically secured? Can anyone steal my device? Do I leave my device unattended?
- Is my device protected with a passcode or biometric authentication?
- Is my device encrypted? If someone steals my device, can they access my data?
- Are the applications installed in my device known applications and installed by me? Or are there any applications that came with the device I'm not aware of?
- Is my device purchased brand new as a sealed pack or did I get it second-hand? Was it gifted?
- When I got the device, did I perform a factory reset before using it? This applies to a pre-owned or gifted device.
- Is my phone connection under my name? Do I have total control over the ownership of the mobile connection? Am I the one who is receiving my bills? Am I very sure that no one can access my billing information or divert ownership of my mobile number?
- Do I receive my phone bills and statements, physically or digitally? Does anyone else have access to this information? If I receive them physically, do I shred or discard them?
- Are the apps on my device installed from an app store (if it is an Android device, from Google Play Store, if it is an iOS device, from the App Store, and if it is a Microsoft device, from Microsoft Store)? Are apps given the minimum permissions?
- Do I connect to public, open, or untrusted Wi-Fi networks?
- Do I avoid clicking on links or opening attachments sent by unknown senders?
- Are the accounts connected to my device (Google Account, Apple ID, or Microsoft Account) secure and MFA-enabled?
- Are the secret questions provided to these accounts not guessable, even by my closest contacts?
If the answers to these questions are yes, to at least most of the questions, you will know you are using a secure device. If not, you can take action to make your devices more secure. With these questions, you can understand the importance of other elements connected to your devices, such as the accounts connected and billing accounts. For example, if someone can claim and get a SIM card for your number by claiming ownership or as a replacement for a misplaced SIM, they will have access to everything of yours, meaning they can receive all your OTPs (sent to reset your passwords and access devices and accounts including Google or Apple IDs). Then, you need to think about the other connections that are used to access the internet from your device.
This way, you can start developing a mindset to maintain anonymity in the cyber world. Once you started practicing, it will become a habit, and you will be suspicious whenever you come across anything that can potentially compromise your privacy and you will be able to prevent yourself from being exposed when on the internet.
Summary
This chapter focused on understanding cyber anonymity and the layers of cyber anonymity. We discussed the basics of cyber anonymity in the Definition of cyber anonymity section. Then, we tried to understand the difference between privacy and anonymity. Then, we defined and understood the different layers of cyber anonymity in the Levels of cyber anonymity section. We also discussed the best practices to maintain cyber anonymity and developing a mindset to maintain anonymity in the cyber world. During this chapter, we developed a set of skills for maintaining anonymity:
- Understanding cyber anonymity
- Understanding the difference between privacy and anonymity
- Understanding the different layers of cyber anonymity
- Best practices to maintain cyber anonymity
- Developing the correct mindset
In the next chapter, you will be provided with information on how to plan for cyber anonymity and the prerequisites to maintaining cyber anonymity. In the next part, we will try to understand the scope of access and the plan for connectivity and understand the level of access. Then, we will prepare the device and the applications for anonymity.