
Chapter 10: E-CART
An improved data stream mining approach
Pardeep Kumar Department of Computer Science and Engineering, Jaypee University of Information Technology, Solan, Himachal Pradesh, India
Abstract
Data stream mining has become important because of the emergence of huge, autonomous, complex, and evolving data in different real-world applications like e-commerce, telecommunication providers, credit-card fraud detection, network traffic, natural calamities forecasting, etc. Decision trees are the most popular technique for the mining the data streams. Concept-adapting Very Fast Decision Tree (CVFDT) and Efficient-Concept-adapting Very Fast Decision Tree (E-CVFDT) are the most popular decision tree-based approaches to handle the concept drift problem. The type of concept drift has not been considered effectively in previous decision tree-based data stream mining approaches. This chapter presents a novel decision tree-based stream mining approach named Efficient Classification and Regression Tree (E-CART) as a combination of the Classification and Regression Trees for Data Stream (dsCART) decision tree approach with a E-CVFDT learning system. The proposed E-CART approach mines the streams on the basis of its type of concept drift. Three types of concept drift are taken into consideration, i.e., accidental, gradual, and instantaneous concept drifts. A sliding window concept is used to hold the sample of examples and the size of the window is specified by the user. The proposed approach has been compared with other existing approaches in terms of computation time and accuracy by varying the size of the stream using rotating hyperplane and SEA concept generator on a Massive Online Analysis simulator. The results are more competitive than CVFDT and E-CVFDT.
Keywords
Classification and regression trees; Concept drift; Data stream; Decision trees; E-CART
1. Introduction
Data stream mining is extensively used in applications like sensor data, image data, web data, and so on. Consider any satellite remote sensor that is constantly generating data. The generated data is massive, temporally ordered, potentially infinite, and fast changing. These features make data stream mining a challenging problem. Due to rapid generation and high volume of data, the stream has to be stored or processed immediately otherwise it is lost forever. It is very difficult to store such an overwhelming volume of data, thus effective mining of the data stream is required. The main research objectives in data stream mining are handling high volumes of data and the concept drift problem.Hence, data stream mining is defined as extracting the desired knowledge from the infinite streams of information in the form of models and patterns [1]. The data stream mining process can be figured out as shown in Fig. 10.1:
To limit the amount of processed data, the sliding window concept is used. There are various windowing models explained in [2], i.e., fixed sliding window, adaptive window, landmark window, and damped window. The number of examples within this window length is chosen for further processing. As the processing of an evolving stream as a whole is a very cumbersome job, many researchers have used the hoeffding bounds for mining data streams. In [3], the authors used the hoeffding bound to generate the decision tree, which is the mathematical tool of the hoeffding theorem [4]. The hoeffding bound ensures, with high probability, that the best splitting attribute chosen from the N examples is similar to the few samples chosen from infinite examples of the data stream. In [5], the authors introduced McDiarmid's inequality [6] to choose the best splitting attribute instead of using the hoeffding bound.

Another research problem in data stream mining is concept drift, i.e., detecting promptly evolving concepts because of the highly dynamic nature of data streams. There are several approaches to handling the concept drift problem in data stream mining like Very Fast Decision Tree (VFDT) [3], Concept-adapting Very Fast Decision Tree (CVFDT) [7], and Efficient-Concept-adapting Very Fast Decision Tree (E-CVFDT) [8]. E-CVFDT will be used in this chapter. VFDT Learner is an incremental learning approach for stationary data distribution. CVFDT is an extension of VFDT that deals with the concept drift problem for high-speed data streams. In the traditional CVFDT method, with the change in concept, a new optional subtree is created and a splitting attribute is chosen on the basis of splitting function. It does not consider the type of concepts arriving at the data stream. The type of concept drift plays an important role in reducing the processing time and cost. Suppose the concept, arriving in a stream, is accidental like noise and disappears very quickly. In CVFDT, as this new concept arrives, a new subtree will be created. As this concept will disappear very quickly, after its disappearance the CVFDT algorithm will rebuild that subtree. Thus this affects the processing time as well as the cost. Gang Liu [8] proposed an improved CVFDT approach for mining data streams, i.e., the E-CVFDT. E-CVFDT considers the three types of concept instances, namely, accidental concept drift, gradual concept drift, and instantaneous concept drift. In accidental concept drift, the new concept will appear for a very short timespan and then the old concept will reappear. Suppose the sequence of the old concept is SeqA and the sequence of new concept is Seqb. Then, the accidental concept drift sequence can be represented as S = {A1, A2, A3 … An, B1, B2, B3 … Br, AP … Am}. In gradual concept drift, the new concept will evolve with the old concept. This can be shown as S = {A1, A2, A3 … An, B1, B2, B3 … Br, AP … Aq, Bm … Bs}. In instantaneous concept drift, the new concept will instantly appear and the old concept will disappear. This can be represented as S = {A1, A2, A3 … An, B1, B2, B3 … BM}.
Here, a cached system is also used for storing the new concepts. As the new concepts arrive, the examples are stored in an array and if this concept seems to be useless, then these examples can be dropped. The appropriate sequence of examples is thus selected for the mining purpose. The number of examples is determined by the hoeffding bound. From these examples, the best splitting attribute is chosen and the corresponding decision tree will be created, i.e., incremental learning will be performed. Classification and Regression Tree (CART) decision tree induction is used for mining and classification purposes.
The rest of the chapter is structured as follows: Section 2 discusses the related state of the art. It explains the hoeffding bound CART decision tree induction approach and E-CVFDT algorithm. Section 3 explains the proposed approach, Section 4 shows the experimental results of the proposed work, and lastly Section 5 concludes.
2. Related study
For the last several years, classification has played an important role in data mining [3,9–11]. The data classification problem in data mining is a two-step process [9]. In the first step, a model is built by learning from the training dataset. And in the second step, the unclassified data is labeled by using the rules extracted from that model. Let Xi denote the set of possible values of attributes ai where i = (1, 2 … D). The classification task is used to find a classifier that classifies an unlabeled set of attribute values Ai into labeled classes K, i.e., H: {A1, A2 … Ad} → {1, 2 … K}. Classification is done with the help of the training set S: (Xi, Ki) =  . Various algorithms have been proposed for classifying the static datasets in the literature. The most popular are neural networks [12,13], Bayesian classification, K-nearest neighbor classification [14], and decision trees [15–17]. As soon as the data streams came into the role, researchers adopted the data stream mining techniques. Decision trees are powerful tools for data stream mining. The main goal of the decision tree is to find the best splitting attribute at each node. The choice of attribute depends on some impurity measure. The split measure function for each attribute is calculated and the attribute with the highest measured value is chosen as the splitting attribute. There are various algorithms for building decision trees like ID3, C4.5, and CART [9]. The split measure function in ID3 is information gain, which is based on the information entropy, whereas gain ratio is used as a split measure function in C4.5. In CART, a binary decision tree is built by using the Gini index as a split measure function. But these algorithms cannot be applied directly for mining data streams because the data elements of the data stream come into the system at a very high rate. Moreover, concept drift also occurs in the data stream. Thus to handle these issues, various approaches have been discussed in the literature. In this chapter, we refer to the data stream-CART (dsCART, Descartes) algorithm [18] with some modification for improved performance and accuracy.
. Various algorithms have been proposed for classifying the static datasets in the literature. The most popular are neural networks [12,13], Bayesian classification, K-nearest neighbor classification [14], and decision trees [15–17]. As soon as the data streams came into the role, researchers adopted the data stream mining techniques. Decision trees are powerful tools for data stream mining. The main goal of the decision tree is to find the best splitting attribute at each node. The choice of attribute depends on some impurity measure. The split measure function for each attribute is calculated and the attribute with the highest measured value is chosen as the splitting attribute. There are various algorithms for building decision trees like ID3, C4.5, and CART [9]. The split measure function in ID3 is information gain, which is based on the information entropy, whereas gain ratio is used as a split measure function in C4.5. In CART, a binary decision tree is built by using the Gini index as a split measure function. But these algorithms cannot be applied directly for mining data streams because the data elements of the data stream come into the system at a very high rate. Moreover, concept drift also occurs in the data stream. Thus to handle these issues, various approaches have been discussed in the literature. In this chapter, we refer to the data stream-CART (dsCART, Descartes) algorithm [18] with some modification for improved performance and accuracy.
The main task in decision tree induction is to determine the best splitting attribute from the sample of data because it is impossible to get it from the infinite size of the stream. In the literature, there are various approaches that ensure that the best attribute chosen from the sample of data is the same as the best attribute chosen from the whole stream with some high probability.
In this context, P. Domingo and G. Hulten [3] introduced the commonly used algorithm the “hoeffding tree,” which is based on the hoeffding theorem [4].
Theorem 1. If X1, X2 … Xn are independent random variables and ai ≤ Xi ≤ bi where 1 ≤ i ≤ n, then:
where  is the mean value of
is the mean value of 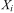 and
and  is the expected value of . This theorem states that after n observations the true mean of the random variable having range R must satisfy the equation:
is the expected value of . This theorem states that after n observations the true mean of the random variable having range R must satisfy the equation:
where  and bi = b(i = 1, 2 … n) and
and bi = b(i = 1, 2 … n) and
But later on, researchers showed that this theorem violates the split measure function. In [5] Rutkowski et al. proposed McDiarmid's inequality instead of the hoeffding bound. McDiarmid's inequality states that:
then, with the probability  , attribute
, attribute  is better split than attribute
is better split than attribute  .
.
In this chapter, we refer to the dsCART algorithm [18], where the authors proposed a different theorem for making the best split attribute.
Theorem 2. If there are two attributes ax and ay, then let ΔG be the difference between the Gini gain function for ax and ay, i.e.:
If  satisfies for
satisfies for
Where 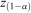 is the
is the  th quantile of the standard normal distribution N (0,1)
th quantile of the standard normal distribution N (0,1)
then  is greater than Giniay with probability , i.e.,
is greater than Giniay with probability , i.e., 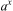 is a better split attribute than .
is a better split attribute than .
Theorem 2 allows the authors to design CART for a data stream [18]. In this algorithm, the authors introduced a tie-breaking mechanism that depends on the parameter  . It ensures the split of the node after some fixed number of examples even if the best two attributes do not satisfy Eq. (10.9). This mechanism is used to avoid the blocking of splitting the node permanently due to the comparable values of Gini gain for these attributes, i.e., the decision to split the considered node is determined by the conditions:
. It ensures the split of the node after some fixed number of examples even if the best two attributes do not satisfy Eq. (10.9). This mechanism is used to avoid the blocking of splitting the node permanently due to the comparable values of Gini gain for these attributes, i.e., the decision to split the considered node is determined by the conditions:
After satisfaction of the foregoing condition, the node is split on an attribute having maximum gain value among the best two attributes and .
In the dsCART algorithm, the authors do not consider the concept drift issue. Thus we used the E-CVFDT approach [8] to the dsCART algorithm [18] to get much better results.
In E-CVFDT, the examples that will participate in the Gini gain calculation are cached. The caching system is helpful in reducing the cost required for the computation. E-CVFDT considers three types of drifts, i.e., accidental, gradual, and instantaneous concept drifts. In the case of an accidental concept drift where the probabilities appear small, a cache mechanism is used to increase the performance efficiency. This algorithm puts all the examples in an array “discard.” When this array is full, then all the examples are sent back in the process of decision tree creation. In the case of gradual concept drift where the concept drift occurs in an evolving style, regrouping of the evolving data is done into the memory, i.e., the new concept examples are delayed while original concepts are used for the Gini calculation first. This classifies the same concept examples first and avoids the complex distribution of an evolving data stream. To handle the instantaneous concept drift where the new concept arrives instantaneously and the old concept disappears, the traditional CVFDT suits well (Table 10.1).
Table 10.1
| Input: |
| w: user-specified window size |
| n: number of examples which have to be checked |
| S: Sample of examples |
| n_discard: maximum number of discarded examples |
| discardArray: array of discarded examples |
| Output: |
| acceptedArray: array of examples to be accepted |
Let W be empty then return NULL Let n(w) be the current number of examples in Window W Let S (I) be an array of each example, initially set empty If |W|< w and n(w)<=n_discard for each example S(i) in w Add S(j) to acceptedArray If |W|<w and n(W)<= n∗ n_discard then, for each example in s(j) in w add S(j) to discardArray Remove this example from window of primary algorithm Let W be empty then return NULL If |W|<w and n(W)>= n∗ n_discard then, Remove this example from window of primary algorithm Return acceptedArray |
3. E-CART: proposed approach
There are various techniques for data stream mining as explained in the previous section. A new approach named E-CART, i.e., E-CVFDT-based CART algorithm, has been proposed, which is the combination of E-CVFDT and dsCART algorithms of data stream mining.
In E-CART, the sample of an example first checks for the type of concept drift. A similar type of conceptual data is mined first. Thus on the basis of type of concept drift, mining is performed. Three types of concept drift are taken into consideration, i.e., accidental, gradual, and instantaneous concept drifts. A sliding window concept is used. The sample of examples is collected within a window. The size of the window, i.e., the number of examples in a window, is specified by the user. When the sample arrives into the window, three possibilities could occur. If the stream is of accidental concept drift type, then the stream of new concept will be discarded because their occurrence probability was very low and the old concept stream is sent for the Gini calculation. If the stream is of gradual type, then the new concept is cached into another array and used for the Gini calculation after some delay. In case of instantaneous concept drift, the decision tree is built on the basis of the arrived concept.
Thus this algorithm is better than the Gaussian decision tree (GDT) [19], because in the case of GDT, for every new concept, a new decision tree is built, which is useless in case of noise, i.e., accidental concept drift. Thus it computes the stream in an efficient and effective manner.
The E-CART works as follows:
Instead of computing the splitting function for each and every example having a new concept, it checks the type of concept drift occurring in the data stream.
If the stream scenario belongs to an accidental concept drift like noise, then the computation will not be recomputed for this new concept. The decision tree will result on the basis of the old concept.
If the gradual concept drift occurs in the stream, then both the concepts are of importance. In that case, a cache system is used. The new concept is cached into an array and the size of the array is specified by the user. When the size fulfills the user-specified condition, then this new concept is encountered for the calculation of splitting attribute function.
In case of instantaneous concept drift, the algorithm simply builds the decision tree on the basis of a new concept arriving there. It works similar to the GDT data stream mining technique (Table 10.2).
Table 10.2
Algorithm:
Procedure chooseSeq(S,w,cached_array, n_discard,n)
Let W be the window of examples of different concepts Let S(i) be the sample-array of each example If |W| > w then Add each sample S(j) to accept_array If |W| < w and n(w)<= n∗n_discard then Add each sample S(j) to cached_array and used later. If |W|<w and n(w)>=n∗n_discard then Remove this example from the primary processing. Return accept_array
Procedure E_CART(accept_array, A)
Let T be a decision tree with single leaf (the root node) X0 Let A0 = A For each attributeFor each attribute value λ of class c The number of examples are
For each example e in accept_array Sort e in leaf
For each attribute
and class is c then Increment
Label the leaf node
, i.e. left set
and right

Computeusing

Computeby using theorem 2
then, Make
as an internal node by replacing
and let
at
For each value
for attribute
and class = c,
end=end+1 Return T.
Here, is the number of elements from the c th class of leaf with attribute value λ for attribute  .
.  is the Gini gain computed for attribute at leaf Lq.
is the Gini gain computed for attribute at leaf Lq.
4. Experiment
This chapter compares the E-CART with the E-CVFDT and CART decision tree with Gaussian approximation. The experiment is done by using a SEA concept generator and rotating hyperplane generator on Massive Online Analysis [20].
The data examples generated from the hyperplane generator are similar to the gradual concept drift data stream. By adjusting the data generation rate, the instantaneous concept drift stream is tested, whereas the examples generated from the SEA generator are similar to the instantaneous concept drift.
Computation time for building the decision tree by using the E-CART is calculated for the hyperplane generator and SEA generator and compared with the CVFDT algorithm. It is observed that the computation time for the SEA generator is very similar to the CVFDT approach, whereas in the case of the hyperplane generator, E-CART takes less computation time for building the decision tree classifier than CVFDT.
Table 10.3 represents the time taken by the CVFDT algorithm and the E-CART algorithm for the data examples generated by the SEA generator. The comparison is visualized in Fig. 10.2.
Table 10.3
| Classification | SEA generator | ||
|---|---|---|---|
| n = 1,000,000 | n = 100,000 | N = 10,000 | |
| CVFDT | 3.20 s | 0.25 s | 0.05 s |
| E-CART | 3.37 s | 0.32 s | 0.06 s |


This graph shows that the performance of the E-CART is somewhat similar to the CVFDT approach given by G. Hulten and P. Domingos [7]. As said earlier, in the instantaneous concept drift data stream, the concept drift occurs instantaneously and then the older concept disappears immediately. When the new concept arrives in the stream, decision tree construction starts immediately rather than caching it as is done in the CVFDT approach to decision tree construction to mine the data stream.
Table 10.4 represents the comparison of E-CART and CVFDT approach in terms of performance efficiency on the dataset generated by the hyperplane generator. The computation time decreases with the proposed approach compared to the CVFDT.
Table 10.4
| Classification | Hyperplane generator | ||
|---|---|---|---|
| n = 1,000,000 | n = 100,000 | N = 10,000 | |
| CVFDT | 9.87 s | 0.73 s | 0.16 s |
| E-CART | 7.30 s | 0.34 s | 0.15 s |


The tabulated data shown in Table 10.4 is visualized in Fig. 10.3.
The graph represented in Fig. 10.3 shows that the computation time decreases by using the proposed approach compared to the CVFDT. This happens because the proposed approach E-CART takes the concept drift into consideration. Thus in case of accidental concept drift, it ignores the new concept because the probability of the new concept appearing is very small. Thus rebuilding the decision tree for such a new concept is totally inefficient. Generally, the accidental concept drifts result in case of any noise in the data stream. In case of gradual concept drift, the cached system is used by the proposed approach, which makes it more efficient. This proposed approach results in 93.23% accuracy with the data size of 1,000,000,000 examples as compared to the accuracy of the CART decision tree approach proposed by Rutkowski et al., which is 90%. Accuracy visualization is shown in Fig. 10.4.

This graph shows an accuracy of 93.23%. It shows that the proposed approach for data stream mining is more efficient and better than the previous approaches.
5. Conclusion
Data stream mining is the process of extracting useful information from the continuous stream of information. The main issue in data stream mining is the concept drift. As a data stream is a continuous stream of data, concept changes dynamically, which must be dealt with during the mining procedure. This chapter mainly concentrated on the classification functionality of data mining. There are various approaches for the classification process like decision trees, Bayesian classification, K-nearest neighbor classification, and support vector machine classifiers. But the decision tree is considered to be the most popular tool for data stream classification. The CART algorithm, given by Rutkowski, was reviewed and it was found that the authors do not consider the concept drift aspect of the data stream. In this approach, with the change in concept in the data stream, a new decision tree rebuilds with this new concept. This results in more execution time. Thus, in the proposed approach, the concept drift scenario is added to the CART approach as applied by G. Liu [8]. Three types of concept drifts are considered in the proposed approach. These are accidental concept drift, gradual concept drift, and instantaneous concept drift. It is observed that the proposed approach performs better than the CVFDT approach and it is also observed that E-CART is more accurate than the CART decision tree without considering the concept drift. The computation time for the instantaneous concept drift scenario is similar to the CVFDT, whereas the computation time for the streams having gradual concept drifts and accidental concept drifts is less.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.