
Chapter 1: Getting to Know Google’s Cloud
I was consulting in Canary Warf, London, for a large financial services consultancy a few years ago when I got called into a meeting with a client who’d just signed a significant software development contract to be deployed into Google Cloud. I was invited to help answer Google Cloud questions. I arrived a little early wearing blue jeans, cowboy boots, and a T-shirt showing a father and son walking together. The son asks, “Daddy, what are the clouds made of?” The father replies, “Linux servers mostly.”
Precisely on time, in strolled a British banker. How did I know? I’m American, and if an American closes their eyes and pictures a banker from a 150-year-old brick-and-mortar UK bank, yeah, it was this guy. Former RAF officer, three-piece suit, cufflinks. Suddenly, I felt way underdressed.
The meeting started, and Google Cloud was mentioned for the first time. Mr. Banker looked like he’d just eaten something sour and said (insert posh British accent), “God, I hate the cloud.” And, the room got really quiet. “I hate the cloud, but as The Bank needs to stay competitive in the 21st century, we feel we have no other choice than to move some of our services into it. The cloud gives us the scalability, availability, and access to features that we need, so all the (nasty upstart) dot com start-ups don’t get the best of us.”
I tend to agree.
On the website for the US National Institute of Standards and Technology (NIST), they define cloud computing as: “a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.” (https://csrc.nist.gov/publications/detail/sp/800-145/final)
Yeah, that sounds like a government-created definition, doesn’t it? But what does it mean in the context of Google Cloud?
In this chapter, we’re going to answer this question by covering the following topics:
- How Google Cloud is a lot like a power company
- The four main ways of interacting with Google Cloud
- Organizing Google Cloud logically and physically
- Google’s core services
Let’s get started.
How Google Cloud is a lot like a power company
Most of you probably don’t generate your own power. Why? It’s an economy-of-scale thing. Your core business probably isn’t power generation, so you likely don’t know much about it and wouldn’t do that good a job generating it if you tried. Besides, you and your business simply don’t need enough power to make generating it yourself cost-effective. What do you do instead? You connect to a power grid, like this:
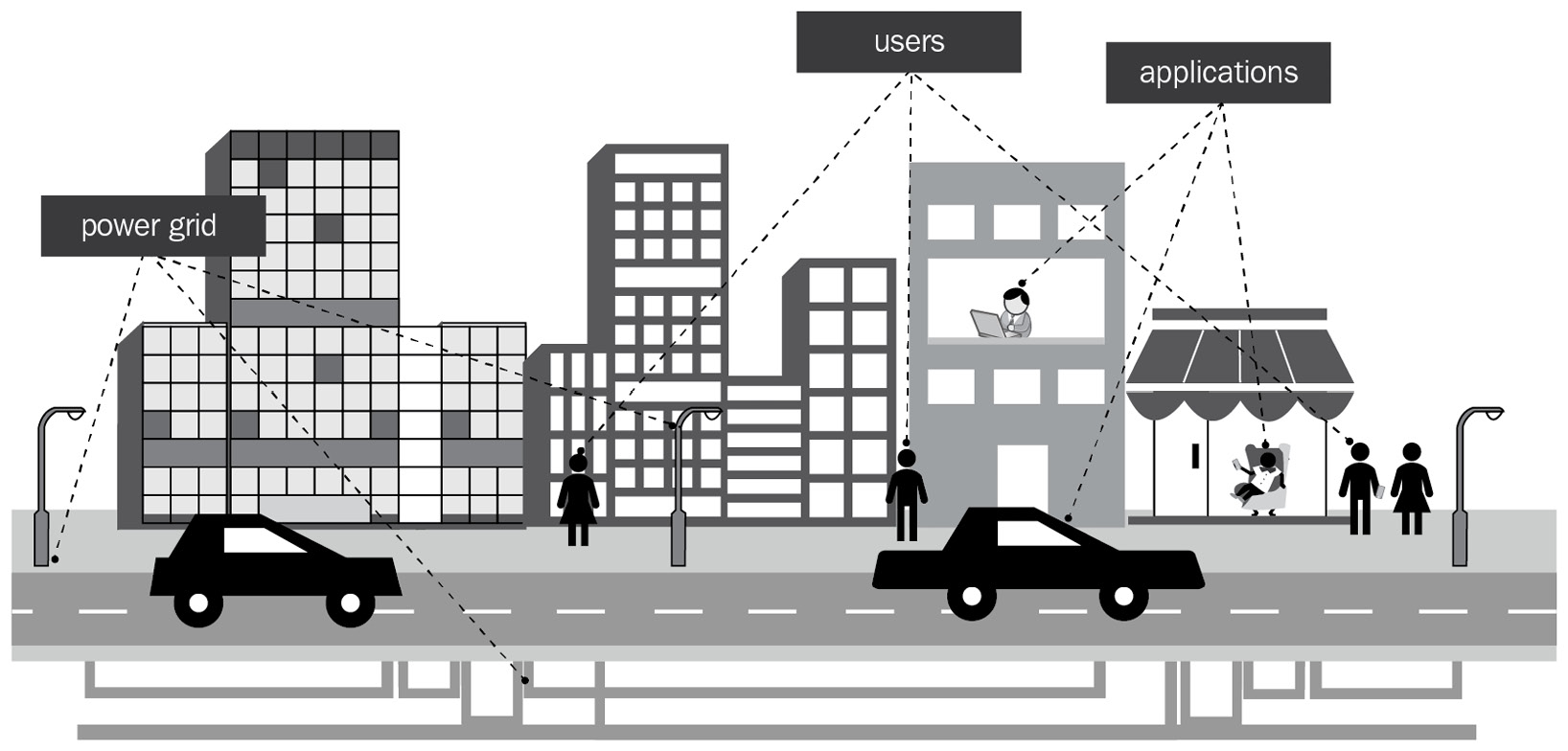
Figure 1.1 – The utility model
As you can see, the power company specializes in generating power at scale, and you plug in and use a little slice of that power however you need. Do you worry about how the power is generated? Not overly, but you do want the power to be there whenever and however you need.
Google Cloud Platform (GCP) works just like a power company, only for IT services. Instead of building your IT infrastructure from scratch, you tap into GCP and use what you need, when you need it.
I have another T-shirt that reads, “There’s no such thing as the cloud; it’s just someone else’s computers.” It’s funny, but it’s also only part of the story. Circling back to that NIST cloud definition, it goes on to say that the cloud model has five key characteristics, all of which apply nicely to GCP:
- On-demand self-service: With Google Cloud, you can create your account, spin up and manage resources, monitor what those resources are doing, and shut down what you don’t need, all from the comfort of your favorite browser, command line, or automation tool.
- Broad network access: Google has tens of thousands of miles of fiber comprising one of the largest private networks in the world. According to Google’s estimates, more than 40% of global internet traffic now moves across Google’s network. Within the global GCP network, you can carve out software-defined private networks known as Virtual Private Clouds (VPCs) when and where needed, to better control and regulate access to network-based services.
- Resource pooling: Back to my T-shirt, GCP isn’t just someone else’s computers. It’s easily more than a million servers, filled with everything from simple compute to cutting-edge IT services, some of which would be difficult or impossible to replicate on-premises. Google provides those services at such a scale that again, GCP becomes a living, breathing example of an economy at scale.
- Rapid elasticity: Once your foundation has been laid, Google offers many easy ways to allow it to scale to meet changing demands over time. For example, if you want to construct a web application that can scale resources up and down based on load, GCP has the pieces and parts you’ll need, from the load balancer distributing the incoming requests to the scalable pool of compute resources generating and assembling the responses, to the datastore behind it all.
- Measured service: Now, the bad news. I hosted a get to know Google Cloud session the other day and one of the attendees started a question: “Does Google charge for…” Let me stop you right there. Google measures your use of most everything, typically by the second, and bills you for it. But the news isn’t all bad. If I go back to our scaling web application from the last point, while on-premises data centers are slow to scale because scaling involves adding or removing physical servers, the cloud scales very quickly. Since you pay for what you use, when your application scales down, you no longer pay for the services you aren’t using. IT services become an operational rather than a capital expenditure. You rent what you need, exactly when you need it.
One of the cost-oriented business advantages of moving to GCP is that it can help provide the IT services you need at a lower overall Total Cost of Ownership (TCO). I would define TCO as everything you pay on your Google bill, added to anything you pay for stuff outside of, but related to, the systems you have in Google. As an example, take a Linux Virtual Machine (VM). I’m going to pay Google to host the VM, but if the VM is running Ubuntu Linux, then I’m going to need someone in my organization who understands the ins and outs of Ubuntu; how to secure it, harden it, patch it, and generally manage it, even if it isn’t running in my on-premises data center. I’m also going to need know-how on securing around it, so who do I have who knows about network security as it relates to Google Cloud? Speaking of Google Cloud, do I know how to build a good foundation that I can drop my VM into? I’m going to need some of those skills, too. Does that mean I need to attend training? Buy a book? Yes! There also may be some costs just for integrating GCP into my organization. Do I need to upgrade my internet connectivity? Buy a VPN proxy? Run fiber to Google? Yeah, there may be other resource costs depending on those needs. So, TCO = Google Cloud bill + external personnel + knowledge + resource costs.
I’m getting a little ahead of myself here. For now, let’s examine the various ways to interact with Google Cloud, and get it doing what we need.
The four main ways of interacting with Google Cloud
Imagine you’ve just visited https://cloud.google.com/getting-started and you now have a new account in Google Cloud. Maybe you even hit https://workspace.google.com/ and created a new organization with a domain, email addresses, Google Drive, the works. What’s the very first thing you should do next?
Wrong! What you should do next is build a foundation for you IT services to stand on in Google Cloud. When people build a house they don’t just grab a board and throw it up anywhere. If you don’t have a solid and secure foundation, whatever you put up is going to be unstable, unreliable, and insecure.
Now, if you want to know how to build that foundation, keep reading. We’re going to get our journey started by examining the four major ways of interacting with GCP: through the Console, from the Command-Line Interface (CLI), through the APIs with code or automation software, and through the mobile app. Let’s start with the Console.
Google Cloud Console
Google Cloud Console is the name Google uses for its web-based UI. On a side note, if your brain typically associates console with command line, then it’s going to need to do some relearning when it comes to Google Cloud. You can get to the GCP Console via the link: https://console.cloud.google.com/. The Cloud Console overview page for a project looks as follows:

Figure 1.2 – Google Cloud Console home page
Note
Google Cloud is constantly evolving and constantly improving, which means little tweaks are made to the UI on a weekly, if not daily, basis. I work in GCP most days of most weeks, and I’m always coming across something new. Sometimes, it’s “Why did they move that?” new, while others, it’s more, “What the heck?” and it’s time to investigate a new feature, new. This means that the moment I take a screenshot, such as the one shown in Figure 1.2, it starts to go out of date. Please forgive me if, by the time you read this, what you are seeing differs from this slice in GCP time.
In the preceding screenshot, I’ve labeled many of the key parts of the page, including the following:
- The main Navigation menu hamburger button
- The currently selected project
- The auto-complete search box
- Link to open Cloud Shell
- Alerts and messages
- Current user avatar
- Information about the currently selected project
- Google Cloud’s current status
- Billing information
- List of key resources
Here, we can see the home page of my patrick-haggerty project.
Note
Using Personally Identifiable Information (PII) when you’re creating projects and folders is not a good idea. Do as I say, not as I do.
We will formally talk about projects in the next section, so for now, a project is a logical group of resources with a billing account attached and paying for them all. I know the project I’m in because the project drop menu (2), in Figure 1.2, tells me so. That drop menu will appear on any project resource page I navigate from here, lest I forget or think I’m in a different project. I can also see which account I’m currently logged in under (6) because I am using a different avatar image for each of my accounts. If I need to switch accounts, I can do it there.
The project home page contains a lot of nice information. There’s an overview of the project-identifying information (7), a list of any known current issues in Google Cloud (8), a summary of my bill for the month so far (9), and a list of key resources I’ve created in the project (10).
While the project home page is just a single page in GCP, the top title bar is standard and appears on most pages. When you want to move between the various Google Cloud products and services, you can either use the Navigation menu (1) or the search box (3). Did you notice my use of title case for the Navigation menu? I’m going to do that so that you know when I’m talking about that hamburger menu (1).
Now, I teach Google Cloud classes multiple times every month, and I am in the habit of using the Navigation menu because I like to show students where things are. I also have a terrible memory for details and sometimes, browsing through the product list helps remind me what I’m looking for. When I was new to GCP, it also showed me the available products. As a result, I rarely use search. That’s not typical. I’ve watched lots of people work with GCP and a lot of them prefer the search box.
So, if I wanted to launch BigQuery and go run some SQL against my data warehouse, I would go to the Navigation menu, then ANALYTICS, and click on BigQuery, as shown in the following screenshot:
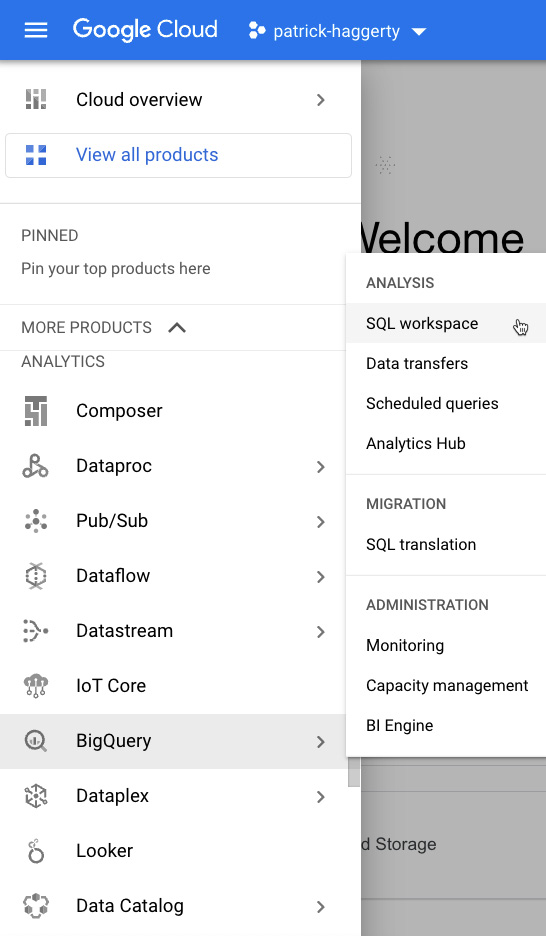
Figure 1.3 – Finding BigQuery in the Navigation menu
By selecting BigQuery, it defaults to that first item in the SQL workspace fly-out menu, but I could have selected anything in the submenu as required.
If you’re visually impaired and not driving with the mouse, or if you just love keyboard commands, pressing ? at any time will bring up a list of keyboard shortcuts. There, you will see that pressing . will open the main Navigation menu, where you can move around with arrow keys and select your choice with Return/Enter. Here’s a screenshot showing the keyboard shortcuts:

Figure 1.4 – Keyboard shortcuts
If you’re more of an auto-complete search box sort of user, or if you are new and find that driving by menu is exhausting, then you’re going to love the search box (back in Figure 1.2). Google knows a thing or two about search (snort). Entering text not only works for product names, but it will also find projects, resources you’ve created with that name, and it will even suggest documentation where you can find more information. So, you could also find BigQuery via the search menu by clicking into the search box or pressing / and typing what you’re looking for, like so:

Figure 1.5 – BigQuery by search
I tend to interact with GCP through the Console when I’m initially building things and I’m in the not sure what I need so I’m experimenting phase. Mostly, though, I find that the UI is the absolute best way to monitor the things I have running.
Driving by UI is nice, but sometimes, you just need a command line.
The Google Cloud SDK and Cloud Shell
If you want to do some simple automation from the CLI, or if you just really love the command line, then you’ll like Cloud Shell and the Cloud SDK. The Cloud SDK is a downloadable set of command-line utilities. I have a section on this near the top of my helpful links file (http://gcp.help). First, you must download and install the SDK (https://cloud.google.com/sdk/docs/install). Once you’ve installed it, open your terminal and type the following:
gcloud init
You will be walked through authenticating into your Google Cloud account, selecting a default project, and (optionally) a default region and zone (more on that in the next section). Once the setup is complete, you can interact with Google Cloud from the command line on your laptop. There are several CLI utilities available, but the most commonly used two are as follows:
- gcloud: gcloud is a CLI way of saying, “Hey Google, here’s what I need you to do.” The order of arguments goes from most general, through the verb, to specific options. So, if I wanted to get a list of Google Compute Engine (GCE) VMs, then I’d execute the following command:
gcloud compute instances list
I’d read that as, “Hey gcloud.” “Google here, with whom would you like to interact?” “Compute.” “Good, but Compute Engine is a huge product, so what part of Compute Engine?” “Instances.” “Oh, I got you. Do you want to create an instance?” “No, give me a list.” In this case, I didn’t need to specify any options, so that part has been left out.
For more information, see https://cloud.google.com/sdk/docs/cheatsheet and https://cloud.google.com/sdk/gcloud/reference.
- gsutil: We’ll get into some specifics on products in Google Cloud later in this chapter, but suffice it to say that Google Cloud Storage (GCS) for offsite file storage is a biggie, and gsutil is the CLI tool for interacting with it. Its arguments are reminiscent of Linux file commands, only prefaced with gsutil. So, if I wanted to copy a file from my local system up into my patrick-haggerty Cloud Storage bucket, the command would look as follows:
gsutil cp delete-me.txt gs://patrick-haggerty
For a reference, see https://cloud.google.com/storage/docs/gsutil.
Besides downloading and installing the Google Cloud SDK, there is another way to use the CLI, and that’s through Google’s web-based Cloud Shell. If you recall my GCP web page interface overview back in Figure 1.2, number 4 was just below the link for opening Cloud Shell. When you open it for the first time, Cloud Shell will appear as a terminal window across the bottom of the web page, sharing space with the GCP Console:
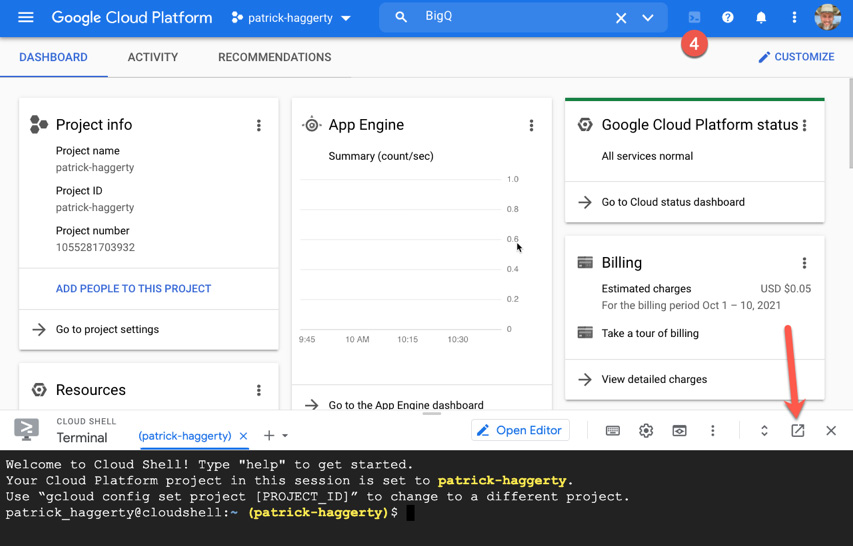
Figure 1.6 – Opening Cloud Shell
Now, I don’t particularly like the Google Cloud Console sharing space with the Cloud Shell terminal, so I like to click that up-to-the-right icon and open Cloud Shell in a separate tab. Once the new tab comes up and stabilizes, you can close the Cloud Shell terminal at the bottom of the console page. As a result, you’ll have one browser tab displaying the GCP Console and another displaying Cloud Shell.
Here, you can see I’ve done exactly that. My first tab is displaying the Console, while the second tab (which you can see in the following screenshot) is showing Cloud Shell with both the editor and the terminal active:

Figure 1.7 – Cloud Shell on a separate tab
In the preceding screenshot, I’ve labeled several key features:
- Toggle on/off the Theia editor
- Toggle on/off the terminal window
- Theia editor settings (font size is a handy one)
- Terminal settings
What Google does to enable Cloud Shell is launch a (free) virtual machine, drop in your user’s hard drive, and give you the interface you can see in the preceding screenshot. The Cloud Shell hard drive persists across sessions and is tied to your user account. It isn’t very large (5 GB), but you can store a file on it now and it will still be there when you log in next time, provided it’s within the next 120 days. Google also has all the SDK CLI tools installed, along with all sorts of Linux utilities, coding languages and APIs, and they even have Theia installed. Theia (besides being a Titan and sister, who is also his wife (I know, gross), to Hyperion) is part of the Eclipse editor family, but it looks a lot like Visual Studio Code (VS Code) and supports many VS Code features and extensions.
Cloud Shell can be a big help when you need to pop into GCP, edit a configuration file, and push a quick change. The CLI in general is frequently the first step toward basic automation. Need to automate the creation of a couple of VMs so that you can do it over and over? How about a simple Bash script with a couple of gcloud commands? That will get the job done, but some automation software, such as Terraform, may do a better job.
The Google Cloud APIs
Everything in Google Cloud is a service. Service can mean “something that provides value” and GCP services are that, but each GCP service is also a web API service. If you know how to format the correct JSON input, and you send it the right URL, authenticated the right way, then you could use GCP that way too.
To see an example, you can head over to Google’s APIs Explorer at https://developers.google.com/apis-explorer. Locate the API for Compute Engine and with a little hunting around, you’ll see that there’s an instances.list function. Here’s a direct link: https://cloud.google.com/compute/docs/reference/rest/beta/instances/list. Over on the side is a Try It! button. The API explorer will prompt you for input parameters, and you’ll have to enter the name of a project and a compute zone where the VMs live. Once you’ve done that, click Execute and it will send a JSON request to GCP, as well as showing you the input and returned message, as shown here:
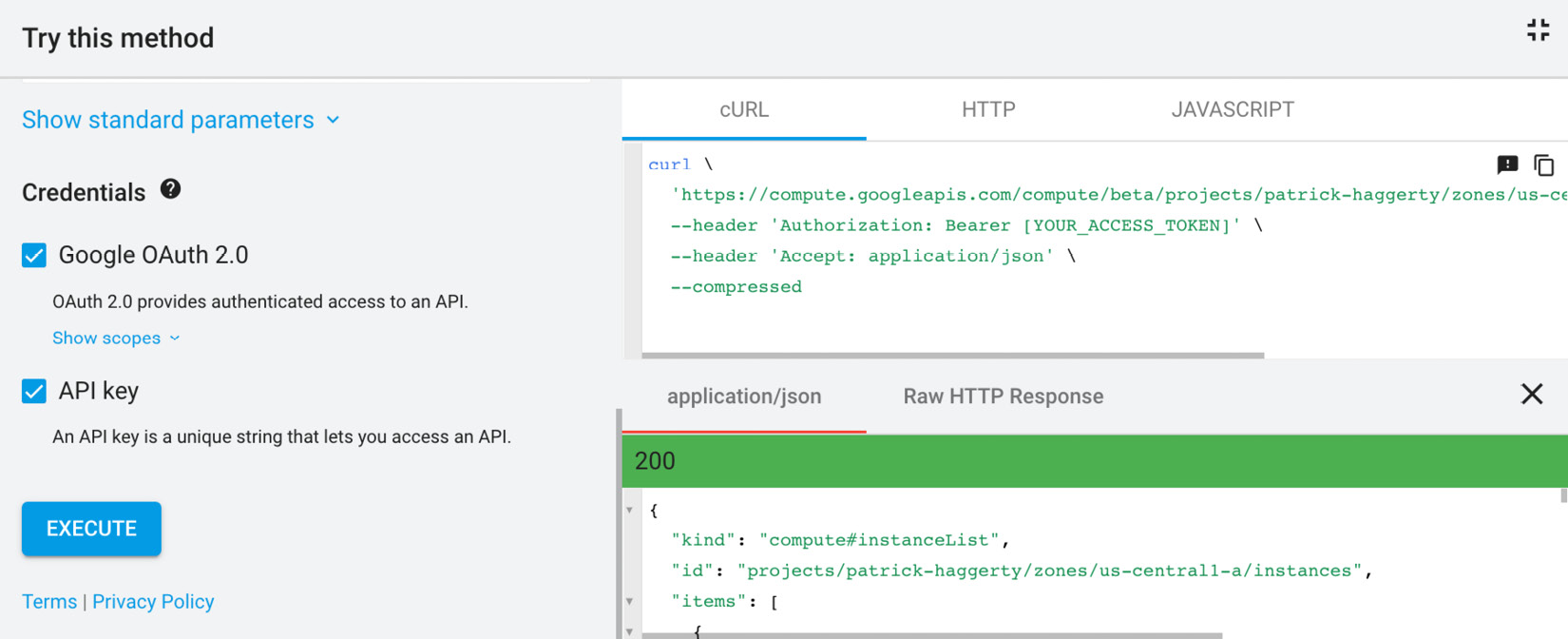
Figure 1.8 – Manual API request
This is a nice example, but this isn’t the way to use the APIs – not if you are working in one of the languages Google has created client APIs for. Take a look at https://cloud.google.com/apis/docs/cloud-client-libraries. To use that same command, get a list of VMs in my patrick-haggerty project, which is situated in us-central1-a, while working in Node.js:
const compute = require(‘@google-cloud/compute’);
const projectId = ‘patrick-haggerty’;
const zone = ‘us-central1-a’
async function quickStart() {const instancesClient = new compute.InstancesClient();
const [instanceList] = await instancesClient.list({project: projectId,
zone,
});
for (const instance of instanceList) { console.log(‘${instance.name}’);}}
quickStart();
Now, besides custom code accessing Google Cloud services, the API is also the way the various automation tools, such as Terraform, interact with Google. We will talk about Terraform a bit later.
For now, what if you’re on the phone and you need to check in with Google Cloud?
The Google Cloud mobile client
Yes, Google Cloud has a client you can run on your mobile device. Yes, it is a quick and easy way you can investigate what’s happening in Google Cloud. No, it is not the preferred way of interacting with GCP in a general sense. If you want to overview what’s happening in the cloud, or perhaps do some quick monitoring, then it’s a good tool. You can also send alerts to individual mobile devices, so it may help with alerting. Here, you can see a couple of screenshots of my mobile app, where I chose to look at the list of VMs I have running in my patrick-haggerty project:
Figure 1.9 – The Google mobile app
Honestly, my favorite feature on the model app is that little Cloud Shell link in the top-right corner. Typically, if I wanted to see the resources I had in my project from my iPhone, I’d just use the web page. The standard GCP Console works well on phones and tablets. But the web page version of Cloud Shell on my iPhone? Not so fun. The mobile app, which has a custom keyboard, is the only way to use Cloud Shell on a phone.
Great – now that you’re clicking, typing, coding, or tapping your way into Google Cloud, how exactly does Google structure resources?
Organizing Google Cloud logically and physically
Everything in Google Cloud has both a logical and a physical organization to it. A virtual machine, for example, could logically belong to a department and physically run in London, and decisions need to be made around both these organizational forms. Let’s start with the logical aspect.
Definition time! The core elements of Google Cloud’s logical organization are as follows:
- Resource: In that NIST definition they stated, “a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services)” so likely, if it’s part of Google Cloud and costs money, then it’s a resource.
- Project: A logical collection of resources with an owner and with a billing account (paying for all the resources in this project) attached.
- Folder: A logical collection of projects and/or other folders that’s used to create groupings to form logical or trust-related boundaries.
- Organization: The root node of the logical organization hierarchy. It’s tied to an organizational domain, has some form of identity, and has an organizational administrator.
Chapter 4, Terraforming a Resource Hierarchy, of this book will go into some details of setting this logical structure up. For now, let’s look at an example. If you have access to view your organizational structure, then you can go to the Navigation menu, click on IAM & Admin, followed by Manage resources. You will see something like this:
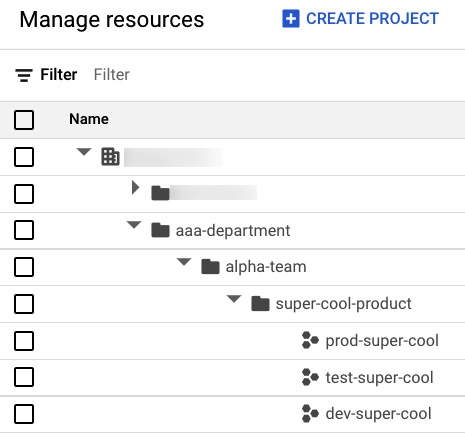
Figure 1.10 – Manage resources
Here, you can see that I’ve blurred out my organization name and that top-level folder, but under that is the structure I created for this example. I have a folder for aaa-department, which creates a logical unit of organization and a trust boundary. Inside that folder, I have another folder for the alpha-team developers. Under that, I have created three different projects for my super-cool application – one where we do development work, one where we do the testing and staging, and one where we have super-cool running in production. I’m not saying this is the way you must do things, but this is an example of a hierarchy I’ve seen used in production.
If the organization, folder, and project are the major units of logical organization, how does physical organization work?
Physically, Google Cloud is broken down into data centers, where we can create resources. The key definitions that are related to physical organization are as follows:
- Region: A data center in a particular geographic area of the world. europe-west2 is in London, England.
- Zone: A unit of isolation inside a region. With a single exception, all generally available data centers have three isolation zones. europe-west2-a, b, and c would be the sub-units of the London region.
- Multi-Regional: Some GCP services can run in two or more regions simultaneously, typically to offer better redundancy and higher availability.
- Global: A service that is available and running in every GCP data center in the world.
Let’s start with an example. us-central1 is one of the largest Google Cloud regions, and the only region in the world to have four zones. It’s located in Council Bluffs, Iowa, and you can find it on Google Maps if you search for it. It looks like this:

Figure 1.11 – Google Cloud us-central1 data center
Do you know what that is? It’s a big concrete box full of hardware, with lots of security, and very few people. Inside that big box are four zones (remember, most regions have three), which I would imagine as smaller concrete sub-boxes. Each zone is essentially a failure domain. If us-central1-a fails, that failure is unlikely to impact b, c, or f (yeah, don’t ask). In the entire history of Google Cloud, they’ve never lost a whole region, but they’ve had zonal failures.
Speaking physically, every product in Google Cloud is realized in a zone, in multiple zones of a region, in multiple regions, or globally. When you’re planning an architecture, one of the things that should be on your to-do list is to determine where exactly to run each of the services you’re planning on using. Only by understanding a GCP service’s inherent redundancy, and your needs, will you be able to plan your regions.
Speaking of GCP services and how they are logically and physically organized, how about we look at a few concrete examples in the next section?
Google’s core services
Google Cloud is simply enormous, both in terms of its physical size and features. A nice place to see this enormity is the Google Cloud Developer’s Cheat Sheet (https://github.com/priyankavergadia/google-cloud-4-words). There, you will find a list of most Google Cloud services, each one with a short description and a pair of links where you can find more information. The chain-link icons take you to the product’s overview page, and the links that resemble dog-eared pages take you to the product’s main documentation page.
The Google Cloud Developer’s Cheat Sheet also has an excellent service overview graphic:

Figure 1.12 – Google Cloud Developer’s Cheat Sheet
Time to get out the magnifying glass! It probably works better as a poster, but you get the idea. They even now have a dynamic version you can find here: https://googlecloudcheatsheet.withgoogle.com/
A big part of moving to the cloud is using the right products, the right way. There is a term people toss around: cloud native. The first time I heard about cloud native, it concerned moving code to the cloud. If you write or rewrite your application to best leverage what the cloud offers, then it becomes cloud native. Over the last few years, however, the term has taken on a life of its own and now it tends to mean the general concept of best utilizing what the cloud offers, not just in terms of coding.
Now, this book is attempting to help you lay a solid Google Cloud foundation, which means I’m not going to be doing a detailed analysis of a lot of Google Cloud’s services. This also means that you will need to spend time digging into service details before you use them. And you may also wish to keep an eye out for (shameless plug) some other books that Packt and I have in the planning stage.
There’s a lot of ways you can categorize Google’s services, and we can only comfortably examine the major ones, so let’s focus on the two most ubiquitous categories: compute and data. If you want more information on any product I mention, see the links in the Developer’s Cheat Sheet. I also have a constantly evolving Google Helpful Links Doc: http://gcp.help. If your organization doesn’t like my redirect URL, or if you can’t access Google Docs at work, try at home or on your mobile device and create a PDF copy. Just remember that I am always adding/tweaking/evolving the live document, so your PDF will slowly become out of date. If you prefer, I’ve created a PDF copy of my own here: http://files.gcp.how/links.pdf, which I update every couple of weeks or so.
One final note before I dig into some individual services: everything you do in the cloud becomes part of a shared responsibility model. Whichever product you use and whatever it does for you, you will own and control parts of it, and Google will own and control other parts. Always make sure you research exactly what you’re responsible for (securing, configuring, managing, and so on), and what Google moves off your plate and takes care of for you.
Now, let’s look at some services, starting with compute.
Compute
If you run software in the cloud, whether it’s custom coded by your organization or something you buy off the shelf, then it’s going to likely run in one of Google’s compute services.
Now, there’s a Developer Advocate who works for Google named Priyanka Vergadia who calls herself the Cloud Girl. You can find a lot of good videos on Google Cloud that have been created by her on the Google YouTube channel (https://www.youtube.com/user/googlecloudplatform), and she also has a website (https://thecloudgirl.dev/) where she has created a lot of fantastic graphics related to Google Cloud. She has one apropos to our current discussion:

Figure 1.13 – Where should I run my stuff?
I’m going to approach the GCP compute technologies in the same order as the Cloud Girl by moving from left to right, starting with GCE.
Google Compute Engine
GCE is someone else’s (very secure, very reliable, feature-rich) computer. If you are used to ordering servers, or you regularly spin up VMs using technologies such as vSphere, KVM, or Hyper-V, and you want to do virtually (cough) the same thing in Google Cloud, then this is the product you’re looking for. You can pick the chipset, the vCPU count, the memory, the size of the boot disk, what OS comes loaded on it, whether it has externally accessible IPs, drive type sizes and counts, and a whole slew of other things. Then, you press the button, and in no time, your server will be up, running, and accessible.
If you need a group of identical VMs all cloned from the same base image, then GCE also offers Instance Groups. An Instance Group joined up with one of GCP’s load balancers is a good way to build highly scalable, highly available, Compute Engine-based applications.
Of all the Google compute options, this is the one that’s most frequently utilized by organizations that are new to GCP. It’s a VM, and most organizations know how to create and manage VMs. They already have the Linux, Windows, networking, and security experts in-house, precisely because it’s a type of compute they are used to working with. The problem? It’s frequently the least cloud-native compute option with the highest TCO, so using it for every possible workload is not a best practice.
The following are the pros of GCE:
- Of all the GCP compute options, this is the ultimate in terms of flexibility and configurability.
- It’s familiar to organizations currently using on-premises VMs.
- It’s the single most popular first compute product for companies migrating into GCP.
- It’s easy to scale vertically (bigger machine) and/or horizontally (more machine clones).
- Pay per second with a number of price break options for long running machines.
The following are the cons of GCE:
- All that flexibility means more to manage, control, and secure.
- Frequently requires specialized skillsets, just like on-premises VMs.
- It has a high relative TCO and you take a big slice of the shared responsibility pie.
Use GCE when you’re doing the following:
- Lifting and shifting VMs to the cloud with as few changes as possible.
- Running custom or off-the-shelf workloads with specific OS requirements.
- You really need the flexibility provided by a VM.
The following are the location options you have:
- Zonal: A VM, or an Instance Group with multiple VMs, in a single zone.
- Regional: A VM can never span more than a single zone, but an Instance Group could place VM clones in different zones across a region.
Now, instead of having a full, do-it-yourself VM, if your application is containerized and you need a good container orchestration system, then you’ll love Google Kubernetes Engine.
Google Kubernetes Engine
Google Kubernetes Engine (GKE) is a fully managed implementation of the wildly popular container orchestration technology, Kubernetes (also known as k8s, because there are 8 letters between the k and the s). If you want an overview of what a container is, check out https://www.docker.com/resources/what-container. If you want to see how Kubernetes can help you manage containers at scale, then look at the What is Kubernetes? page over on the main Kubernetes site (https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/) and spend a few minutes watching (not a joke) The Illustrated Children’s Guide to Kubernetes on YouTube (https://youtu.be/4ht22ReBjno).
Quick side discussion: in the preceding paragraph, I introduced a term you hear a lot regarding GCP: fully managed. Fully managed means that Google is going to take care of the implementation details for you. If you wanted to stand Kubernetes up on-premises, you might use something such as kOps to help with the installation, and you would be responsible for setting up the machines and managing them, the OSs, the OS and k8s patches, the security – the works. Instead, if you spin up a cluster in GKE, Google takes over the responsibility of managing the OS, the machines, and their security and patching. Google will even update your k8s version if you select a release channel option. Essentially, Google hands you an up-and-running set of machines, all ready and waiting with k8s installed – all you have to do is use it. GKE is one of Google Cloud’s fully managed-by-Google services.
GKE has two operational modes: Standard and Autopilot. Standard mode is mostly what I described previously. You select your options, then Google builds your k8s cluster and hands you the keys. From there, Google keeps k8s up, running, up to date, and happy, and you use it however you want.
The following are the pros of GKE Standard:
- Easy way to get a turnkey Kubernetes cluster in under 5 minutes.
- Managed by Google with a typically lower TCO than GCE.
- Based on a widely used open source technology.
- Very popular with companies modernizing toward containers.
- Offers discounted and committed-use pricing for long-running clusters.
The following are the cons of GKE Standard:
- If your application isn’t containerized, then you can’t run it in k8s.
- Like any k8s cluster, you require specialized k8s skills to manage it.
- Not as flexible as GCE.
Use GKE Standard when you’re doing the following:
- Running containerized workloads and you need control over the k8s environment.
- The container is long-running, stateful, or accessed through non-HTTP protocols (Cloud Run is not an option).
- You have in-house k8s skills, and you don’t want to pay for Autopilot.
The following are the location options you have:
- Zonal: All cluster VMs in a single zone.
- Regional: A group of machines in each of three zones of a given region.
Besides GKE Standard, Google also offers an Autopilot version, where Google does more managing and you focus more on your workloads. But first, there’s a new term I need to introduce: serverless. When Google talks about serverless products, what they mean is that you don’t see, configure, or in any way manage the infrastructure where the product runs.
It kind of sounds like fully managed, right? But it’s not quite the same. If you construct a GKE Standard cluster, there are actual VMs out there and you can see them if you look in GCE, but where a standard Compute Engine VM is managed by you and your team, in a fully managed situation such as GKE Standard, the machine is there but Google is taking care of it and its needs. Google then bills you a nominal cluster management fee, plus the cost of the VMs in your cluster. If your cluster is busy or doing almost nothing, it doesn’t matter in GKE Standard because you’re paying for the cluster itself.
GKE Autopilot is serverless, so Google takes on all the responsibilities related to Kubernetes administration and configuration, all the way down to selecting how many machines of what type comprise the cluster. Essentially, there’s a k8s cluster out there, but the shared responsibility line has moved, and Google is taking on more of the administrative tasks for it.
I’ll admit, the term serverless makes my eye twitch when I think about it too much. Of course there are servers out there somewhere just like with a GKE Standard cluster, but the difference here is they are now abstracted to such a degree that I no longer even see them as part of my project.
The following are the pros of GKE Autopilot:
- Essentially, this is the Kubernetes easy button.
- The k8s cluster becomes Google’s problem.
- You create your containers, submit them to the cluster, and they just work.
- GKE Autopilot also offers discounted and committed-use pricing for long-running pods.
The following are the cons of GKE Autopilot:
- Not as flexible in terms of supported workloads.
- You have less control over cluster configuration (a double-edged sword).
- Pod resources are not as configurable.
- You pay a standard GKE cluster management fee, and a per second fee for the resources utilized by each of your pods.
Use GKE Autopilot when you need to run a container that can’t run in Cloud Run, and you don’t have the in-house k8s skills to go with GKE Standard.
There is a Regional location option.
For a good Autopilot and Standard GKE cluster comparison, see https://cloud.google.com/kubernetes-engine/docs/concepts/autopilot-overview#comparison.
OK; so, go for GKE Standard if you want to run a container and you need full control over the Kubernetes environment, but use GKE Autopilot if you want to run a container and you’re willing to pay Google to manage the Kubernetes environment for you. But what if you want something cheaper and even easier than Autopilot? Oh, then you’ll love Cloud Run.
Cloud Run
Cloud Run is another fully managed serverless (see what I did there?) technology for running containers. Where GKE Autopilot is a k8s cluster that’s managed completely by Google, in Cloud Run, there is no k8s cluster. Google has constructed some tech for running containers in a super-flexible, super-easy-to-use, super-scalable environment of their devising (originally built for App Engine). Then, they combined that with an open source add-on for Kubernetes called Knative, which simplifies how developers configure and deploy particular types of containers. Pulling in Knative helps avoid vendor lock-in by providing an API that can be used to deploy and manage applications in Cloud Run, just as it could with any normal Kubernetes cluster running Knative.
OK – I know what you’re thinking. You’re wondering why Cloud Run exists when it sounds mostly like the same product as GKE Autopilot. This isn’t going to be the only time you feel that way, trust me. Frequently, Google Cloud offers several different ways to do the same thing. I mean, we’re in the middle of talking about compute technologies, right? All of them do the same thing in general, but they have strengths and weaknesses, and the devil is in those details. Truly being cloud native in GCP is going to require patience and research.
Let’s get back to Cloud Run.
Cloud Run specializes in stateless (don’t remember user data between requests) containers, which listen and serve requests on a configured port, doesn’t run outside serving requests, are short-lived (return an answer in less than 60 minutes), and use the HTTP/1 or HTTP/2 (including gRPC) protocols. In other words, if you’re building a web application or a web service API, and that page or API takes a request, does something, returns an answer, and then moves on to serve the next request, then this is a great place to run it.
Cloud Run also supports the CloudEvents open source standard, so instead of running in response to an HTTP request, a container could automatically react to something else going on in Google Cloud. For example, let’s say that a new file just showed up over here in Cloud Storage. You could wake up a Cloud Run container, have it translate the file from English into Spanish, store a Spanish text file, and then go back to sleep.
Cloud Run also has the option to scale to zero. Scale to zero, when applied to a GCP service, means that if no one is using the service, then it will scale down automatically until it costs you nothing. That’s right – if you aren’t using Cloud Run, you can configure it such that you won’t be paying for Cloud Run. In GKE Autopilot, so long as you have deployed a pod, you will be paying for the pod per second. In Cloud Run, Google measures the time it takes to handle a particular client request, rounds it to the closest 100 ms, and bills you for that. No requests? Nothing to bill for.
Cloud Run also has a free tier. That is, if your usage is below a certain threshold, then it doesn’t cost you anything. Cloud Run is one of more than 20 products in GCP that has free tiers (https://cloud.google.com/free/docs/gcp-free-tier). I could have mentioned this in the GKE discussion, because the GKE cluster management fee for a zonal or Autopilot cluster, which is currently $.10/hour, is free for your first cluster, though you’re still paying by VM or by pod. In Cloud Run, though, it’s free-free. Your Cloud Run container runtime has to reach a base level of use before it costs you anything. While you are coding and testing, and until you hit that baseload level, you can get going with an app in Cloud Run for free.
The following are the pros of Cloud Run:
- Super-easy way to run HTTP1/2-based web and web service containers.
- Super-easy way to create automated cloud event handlers.
- It has a short and sweet learning curve with no Kubernetes to learn or manage.
- Auto-scales and auto-load balances.
- Managed implementation of open source Knative and CloudEvents projects.
The following are the cons of Cloud Run:
- Containers must be in Linux x86_64 ABI format, short-lived, stateless, and be accessed via requests coming in through HTTP1/2 or via a predefined set of triggers.
- Limited configurability.
Use Cloud Run when the workload is a container hosting a short-lived, stateless web app or a CloudEvents (trigger), and you don’t need any of the configurability GKE provides.
The location option you have is Regional, where each service will be served out of a single GCP region, though you can run multiple clone Cloud Run instances in different regions and then load balance across them.
As cool as Cloud Run is, it wasn’t the first GCP product to work this way. Long before Cloud Run was a gleam in the eye of the Google Cloud engineering team, there was App Engine.
App Engine
App Engine is one of the original Google Cloud (2008) services. It was cool long before Kubernetes, before Docker, and before the term container was a byword in the development community. Behind the scenes, it operates essentially the same way and in the same servers as Cloud Run. Arguing that Cloud Run is a next-generation replacement for App Engine wouldn’t be far off the mark. Also, like Cloud Run, it primarily supports HTTP-accessible requests, which means more web applications and more web service API endpoints.
In Cloud Run, you build your container, put it in a registry somewhere Cloud Run can access, create your service, and you’re off to the races. With App Engine, you are restricted to particular versions of particular languages: Java, Node.js, Python, C#, PHP, Ruby, or Go. You upload your source code and a configuration file to App Engine using a command-line tool, and Google creates a sandbox around your application and runs it in that sandbox.
App Engine offers multiple ways to scale, so it can be completely automatic like Cloud Run, or you can do basic or manual scaling where you have a lot more control to allow it to do things such as background tasks.
The following are the pros of App Engine:
- Easy to deploy and use, with a small learning curve
- Another option for web applications and API endpoints
- Can auto-scale and auto-load balance
- Scales to zero
The following are the cons of App Engine:
- Proprietary to Google, with an App Engine-specific config file.
- Runs in a sandbox, so your code has to be particular versions of particular languages.
- Some of the original App Engine support services have been moved out to make them more generally available.
- You should probably be looking at Cloud Run.
The location option you have is Regional, where each service will be served out of a single GCP region.
App Engine isn’t designed to support events, such as CloudEvents triggers in Cloud Run, but another member of the App Engine family can. Let’s find out what that is.
Cloud Functions
Cloud Functions is event-driven functions that run in essentially the same place as Cloud Run containers and App Engine applications. The function can respond to internal cloud events, such as a new file appearing in a Cloud Storage bucket or a new message showing up in a Pub/Sub topic, or it can act as a basic endpoint responding to HTTP requests. Like App Engine, you create Cloud Functions by coding them in particular versions of essentially the same list of languages. At the time of writing, Cloud Functions is being extended to also support CloudEvents APIs such as Cloud Run Triggers.
The following are the pros of Cloud Functions:
- You can easily create event handlers for several common GCP event types.
- Cost-effective (to a point) and scales to zero.
The following are the cons of Cloud Functions:
- The list of event types is limited (though CloudEvents will extend).
- Proprietary to Google (again, not if you’re using CloudEvents).
- It uses sandboxes, so your code has to be particular versions of particular languages.
- Consider Cloud Run and triggers as a more container friendly alternative.
The location option you have is Regional, where each service will be served out of a single GCP region.
Great – so we’ve looked at several popular Google Cloud compute services, but what’s compute without data? I’m sure that most applications that run in or out of the cloud depend on some sort of data storage, so let’s turn around and take a peek at what Google offers in the way of data storage.
Data storage
Compute, data storage, and data processing were probably the three prime driving forces behind Google creating their cloud. Google currently has nine products with over a billion users each: Android, Chrome, Gmail, Google Drive, Google Maps, Google Search, Google Play Store, YouTube, and Google Photos. And all those users? They upload 400 hours or more of videos to YouTube (a petabyte) every minute. They upload 18 PBs of pictures to Google Photos per day. And that’s not even talking about the huge storage and processing problem that is Google Search.
Cloud Girl time again. The way Google currently categorizes data storage products is into storage and databases. Let’s start with storage:
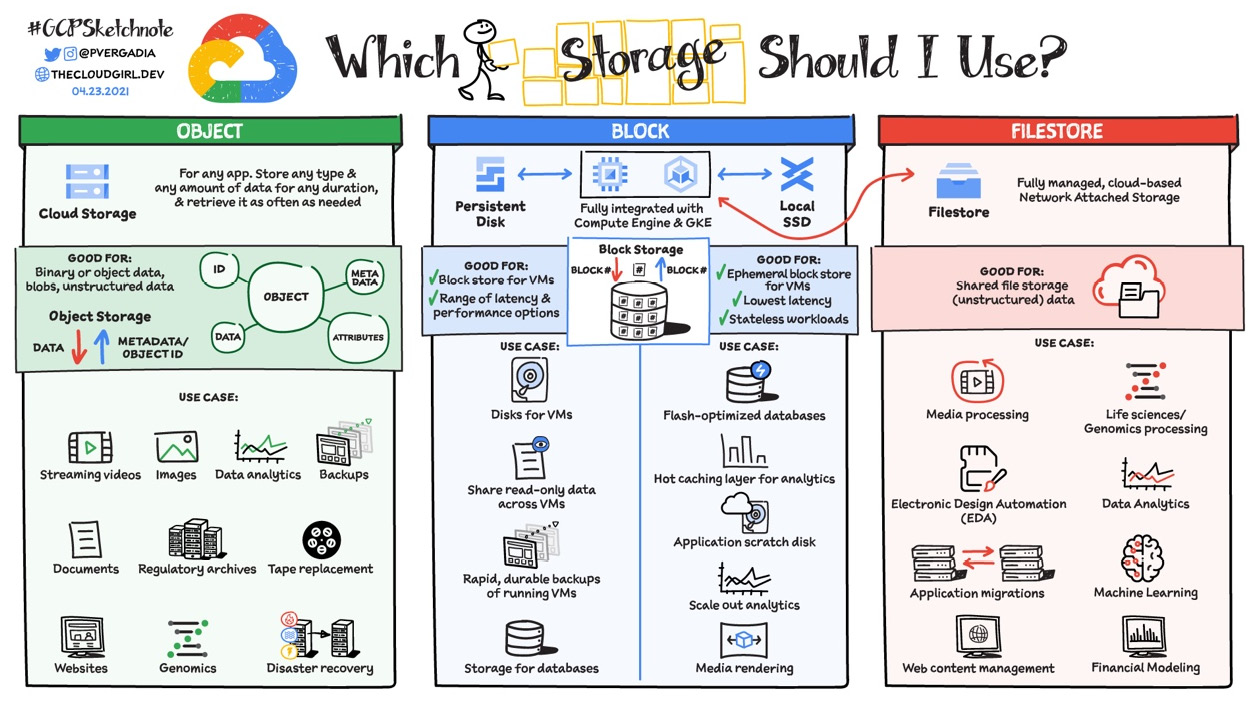
Figure 1.14 – Which storage should I use?
Let’s take a closer look at Google Cloud’s storage options.
Google Cloud Storage
GCS is a Binary Large Object (BLOB) store and, together with Compute Engine, it is one of the most popular first-step Google Cloud products. It’s designed to be a cheap and easy way to store files off-site. Of all Google Cloud’s data products, and probably all the GCP products period, it’s something that most people are familiar with. Even non-technical people these days have stuff backing up to Google Drive, Google Photos, iCloud, and the like.
GCS sits on an enormous storage array that Google has constructed, called Colossus. You can find some information online about Colossus in the Data section of my http://gcp.help document. One of the features that Colossus passes to GCS is 99.999999999% (11 9s) of durability. This means that the chance of you loading a file into GCS and of Google then losing it is next to nothing. To put this into perspective, the chance of you not winning the typical lottery is about 99.99999% (7 9s), which is about a tenth of the chance of being bitten by a shark. You’re way more likely to be struck by lightning, with a chance of about 99.999% (5 9s). You get the idea.
The following are the pros of GCS:
- Easy to use, highly durable, and always encrypted
- Supports versioning, locks, auto-deletes, and automated life cycle configurations
- Little to configure and you don’t have to tell Google whether you’re storing a little or a lot
- Low cost and you only pay for the actual data that’s stored
- Low latency, with a time to the first byte in the tens of milliseconds
- Could store a virtually unlimited amount of data
- Several different pricing options for active and inactive data storage
The following are the cons of GCS:
- Does not provide block storage.
- Folders are simulated.
- Append operations and file moves necessitate full file replacements.
- It’s probably not good for operations that require speed over many, many, small files.
Use GCS in the following cases:
- You want a cost-effective, off-site file store.
- You need to host images, .js, .css, or other static files behind a web application.
- You need stage files for batch data processing.
The following are the location options you have:
- Regional: Files are replicated across all the zones of a single region.
- Multi-regional: Files are copied across all the zones of two regions, at least 100 miles apart, and in the same region of the world (such as the US).
- Dual-regional: Same as multi-regional but you know the exact two regions.
Well, that’s one way to store files, but what if you want something that’s block storage and more like a traditional hard drive?
Persistent disks
Persistent Disks (PDs) are used when you need durable block storage. If you are running a GCE VM or a GKE cluster that needs drive space, then this is where that data lives. They aren’t physical disks in the traditional sense. Instead, they are block storage backed by Colossus, so you still get the same 11 9s of durability and auto-encryption.
PDs are subdivided into several subtypes, depending on the IOPS, throughput, and spend requirements, and there’s even a special PD type called Local SSDs, which is optimized for when you need blazing IOPS performance but only for temporary cache storage.
The following are the pros of PDs:
- Designed for persistent block storage – think laptop hard drives
- Resizable on demand (up, not down)
- Automatic encryption with several options as to how the keys are managed
- 11 9s of durability and excellent overall performance
- Easy to back up and restore with geo-replicated snapshots
The following are the cons of PDs:
- You pay for what you allocate, regardless of use.
- If you just want simple file storage, consider Cloud Storage.
- Restricted to a single zone, or pair of zones.
Use PDs in the following circumstances:
- When you need a drive for a VM or GKE workload
- When your application requires block storage
The following are the location options you have:
- Zonal: All the file data is stored within a single zone.
- Dual-zonal: There’s an active drive in one zone, while a passive duplicate is kept in a second zone in the same region.
What if you need something more along the lines of a traditional, on-premises, network shared drive? For this, there’s Filestore.
Filestore
Filestore (not to be confused with Firestore) is a fully managed Network-Attached Storage (NAS). It supports access from any NFSv3-compatible client and has several different configurable options, depending on your price, IOPS, throughput, and availability goals. GCE VMs or GKE workloads that need to share a read/write file storage location could leverage Filestore.
The following are the pros of Filestore:
- Fast (IOPS and throughput) and easy-to-use file store
- Predictable pricing
- Supports shared read and write access
- Networked
The following are the cons of Filestore:
- NAS is a file store rather than a block store.
- You pay for what you allocate, which can be expensive.
Use Filestore in the following situations:
- When your workload requires a NAS
- When you need to share read/write access to a drive
The following are the location options you have:
- Zonal: When set to Basic or High Scale tier
- Regional: When set to Enterprise tier
When your storage needs lean away from a simple object or file storage and toward databases, Google has options for you there as well:
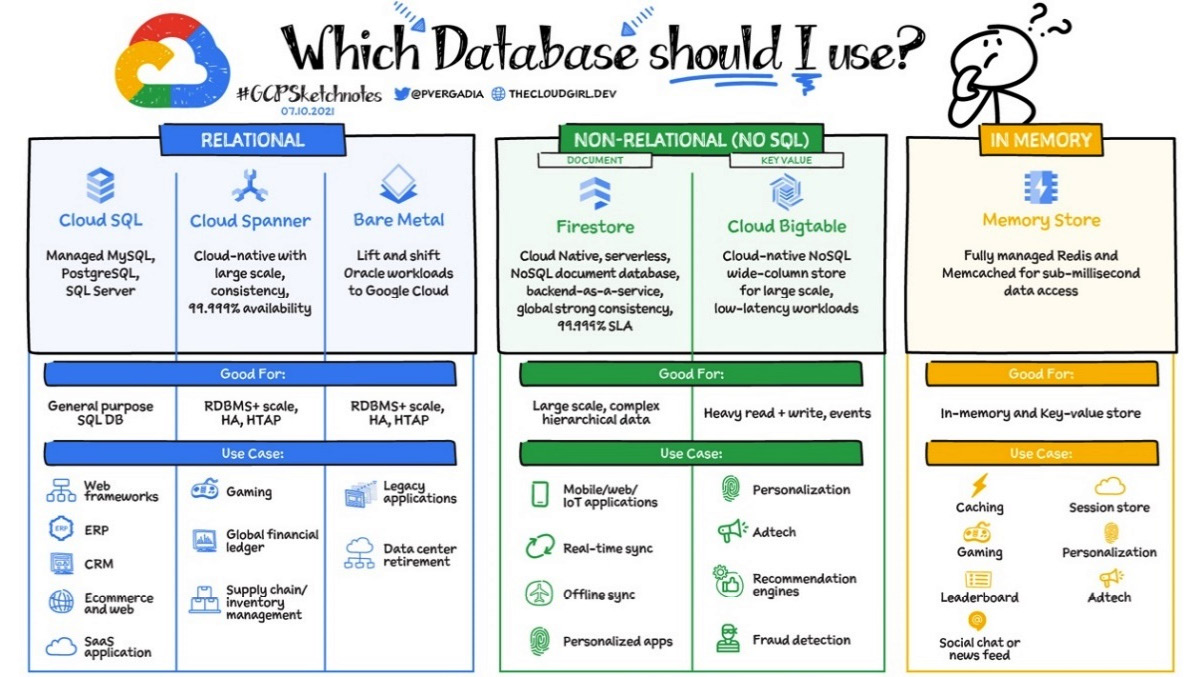
Figure 1.15 – Which database should I use?
Databases and Database Management Systems (DBMSs) are designed to aid applications by offering fast and secure storage and information retrieval. Having said that, the preceding diagram shows multiple options because, within that purview, databases tend to be optimized for particular usage models. Let’s start with the classic relational options in the following two sections.
Cloud SQL
Relational databases have been a mainstay in the database world for decades. They are flexible, efficient, and do a good job with transactional data. If you want a classic relational MySQL, PostgreSQL, or Microsoft SQL Server database, and you’d like Google to set it up and manage it for you, then go no further than Cloud SQL.
The following are the pros of Cloud SQL:
- Classic relational database backed by MySQL, PostgreSQL, or MS SQL Server.
- The machine, DBMS, and backups are all managed and maintained by Google.
- You can configure the read/write instance size to fit your load and budgetary requirements (bigger machine, can do more work, but costs more money).
- Optional HA configuration with an active copy in one zone, and a passive backup in another, with auto-failover.
- Can scale out read-only replicas.
The following are the cons of Cloud SQL:
- The single read/write machine means scaling writes happens vertically. The machine can get bigger in terms of resources, but there are limits.
- Writes will always be made to a single machine, in a single zone.
- Maintenance events, when Google is patching or updating the OS and/or DBMS, can take the database down for upward of 60 seconds (check out the Maintenance window settings).
Use Cloud SQL in the following circumstances:
- You need a small to midsized, zonal, relational database.
- You’re migrating on-premises MySQL, PostgreSQL, or MS SQL Server databases to GCP, and would like to make the system a little more cloud native.
The following are the location options you have:
- Zonal: The single active read/write instance will always be in a single zone.
- Regional or multi-regional: Only applied to the read-only replicas.
I like MySQL, PostgreSQL, and MS SQL Server as much as the next guy, but what about when I need a mission-critical relational database and its write requirements are either too large for what even the biggest single machine can handle, or it needs to be geographically distributed for latency reasons? Well, in that case, you should take a closer look at Spanner.
Spanner
Spanner is a Google-invented relational database. Its origin goes back to the early 2010s and a need to be able to store advertising-related data with strongly consistent transactions at a level bigger than a single region. Spanner is a strongly consistent, transactional, relational database that can horizontally scale to meet almost any demand.
As I sit here writing this, I’m wearing a pair of Lucchese cowboy boots. Lucchese boots are beautiful, comfortable, and you can wear them all day long, but you’re going to pay for the privilege.
Spanner is the relational database equivalent to my boots.
The following are the pros of Spanner:
- Strongly consistent, transactional, and relational.
- Linear scaling with processing units (100 at a time), practically without boundaries.
- Serverless with no maintenance windows.
- A database can be bigger than a single region.
- Offers an on-premises simulator for development.
- You get exactly what you pay for.
- Can enable support for the PostgreSQL ecosystem.
The following are the cons of Spanner:
- It is not simply a managed version of an existing DBMS, so you will need someone to learn to administer and optimize it.
- Scaling up processing units, especially across regions, can get expensive.
Use Spanner in the following circumstances:
- You need a relational database that can scale horizontally for large loads.
- You need a single relational database that can operate across multiple regions.
- Your workload can’t tolerate the Cloud SQL maintenance cycle.
The following are the location options you have:
- Regional
- Multi-regional: Within the same continent and multi-continent options
Relational databases may be a classic, but what if you’re willing to move past the traditional and into the realm of non-relational storage? A good option to consider here would be Firestore.
Firestore (Datastore)
Firestore (not to be confused with Filestore) is a document-style NoSQL database. NoSQL (terrible name) means non-relational. Firestore doesn’t store data as tables of records of fields. Instead, it’s a document or entity database, and it stores “things” as chunks of data. If you’ve ever worked with a JSON store such as CouchDB or an object store such as MongoDB, then this is the Google equivalent.
Think about an order. An order is a hierarchal structure that likely contains some order details such as date and order total, but it also contains some customer data such as shipping and billing address, and a list of order items with counts and product details. We think “order” because it’s a logical unit. In a relational database, you’d shred that data into different tables and do a join when you want the whole order back again. With Firebase, you can skip the whole shred/join steps because document-style databases can natively store complex structures such as orders, products, reviews, or customer states.
The following are the pros of Firestore:
- Fully managed non-relational document store database.
- Strongly consistent and transactional.
- Cost-effective, with a free tier and can scale to zero.
- Easy-to-use API and (non-SQL) query language.
- Scales fast and well.
The following are the cons of Firestore:
- Not all developers are familiar with NoSQL datastores.
- No SQL, no join queries, and no aggregations.
Use Firestore in the following circumstances:
- When you are storing “things” and a document/entity store can do the job.
- You are developing web or mobile devices and need an easy, cost-effective database.
The following are the location options you have:
- Regional
- Multi-regional
If I’m willing to go NoSQL, are there any databases that are built for sheer performance and throughput? Yes – if you want a datastore you can firehose data into for something such as IoT sensor data purposes, then check out Bigtable.
Bigtable
Bigtable is exactly that – it is a wide-column NoSQL datastore consisting of a single big table (similar to HBase or Cassandra). How big? That’s up to you, but there could be hundreds or even thousands of columns and a virtually unlimited number of rows. This is the datastore behind Google products such as Search and Maps. Bigtable doesn’t support transactions in the traditional sense, and by default, it is eventually consistent, so changes in one cluster will eventually replicate everywhere, but this can take seconds to minutes. The only indexed column is the row key, which means that schema design is extremely important, especially in regards to the row key. It is another GCP product in the “get what you pay for” category, so make sure it’s the right option before you choose it.
The following are the pros of Bigtable:
- Managed, wide-column, NoSQL datastore.
- Ability to scale to handle virtually any required R/W performance.
- Extremely low latency.
- Supports the HBase API.
The following are the cons of Bigtable:
- You will have to learn how to configure and use it.
- Not transactional and eventually consistent.
- It can get pricey.
Use Bigtable in the following circumstances:
- When you are working with IoT, Adtech, fast lookup, or time series data and you need the ability to read and/or write many records with extreme performance.
- Store the data here, because it’s so fast, then analyze it later, with code or other tools.
The following are the location options you have:
- Regional
- Multi-regional
If you’re looking for a highly available memory cache, rather than a brute-force performance database, then you should look into the two options provided by Memorystore.
Memorystore
Memorystore is a highly available, Google-managed version of the open source memory caches Redis or Memcached. It is designed to act as a sub-millisecond, in-memory cache. So, it’s another NoSQL database, but this time, it’s a simple key-value store. You pick the open source cache engine and Google takes it from there.
The following are the pros of Memorystore:
- It provides a sub-millisecond in-memory cache that’s 100% compatible with OSS Redis or Memcached.
- Fully managed, highly available, and secure.
- Different service tiers and sizes, depending on your need.
The following are the cons of Memorystore:
- Some features from the OSS versions are not supported.
- It has a simple key-value store that’s optimized for fast lookup.
Use Memorystore in the following circumstances:
- When you need a shared super-fast, in-memory key-value store
- When you’re caching session information, a shared set of products, a leaderboard, and more
The following are the location options you have:
- Zonal
- Regional (cross-zone active-passive replication with automatic failover)
Whew – that’s a lot of services and, honestly, we’ve barely scratched the surface. What you need, though, before you start throwing services at a problem, is a secure and scalable foundation to construct them on. That’s right – and you’ve come to just the right place to figure out how.
Summary
In this chapter, we started by providing a high-level overview of the cloud itself, likening it to a power company, and illustrating some of its key advantages: on-demand, broad network access, resource pooling, elasticity, pay for what you use, and economy of scale. From there, we moved on to examine the four ways of interacting with Google Cloud: through the Google Cloud Console (web UI), the command line (SDK and Cloud Shell), the APIs with code or automation software such as Terraform, and via the mobile app. Lastly, we did a quick pass over several different Google Cloud services in the two key areas: compute and data.
From here, there are a lot of directions we could go, but this is a book about laying a Google Cloud foundation, so we need to keep focused on that. Well, if you want to lay a good foundation, then you should probably start with the next chapter.