
![]()
6.2. The Computational Complexity
6.2.1. SPA Algorithms
Definition 6.1
Assume that in SA search SPRT is used as statistical inference method S, and for judging m 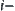 subtrees the significance level
subtrees the significance level 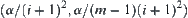 ,
, 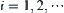 , is chosen. Under the above conditions, the SA search is called SPA1 with significant level
, is chosen. Under the above conditions, the SA search is called SPA1 with significant level 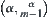 , or simply SPA1 algorithm.
, or simply SPA1 algorithm.
Variable 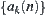 obeys the
obeys the 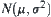 distribution. Construct a simple hypothesis:
distribution. Construct a simple hypothesis:
Lemma 6.1
For judging m  subtrees, the asymptotically mean complexity of SPA1 is
subtrees, the asymptotically mean complexity of SPA1 is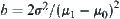
![]()
Proof
From Formula (6.5), when 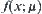 is
is 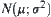 , the mean of stopping variable R can be represented by the following expression approximately.
, the mean of stopping variable R can be represented by the following expression approximately.
![]()
![]()
Therefore, in order to judge m  subtrees with significant level
subtrees with significant level 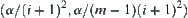 , the asymptotically mean complexity is
, the asymptotically mean complexity is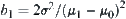 .
.
![]()
Theorem 6.2
Proof
From Lemma 6.1, the mean complexity for judging m i-subtrees is 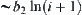 . Thus, using SPA1 algorithm, the mean complexity of finding a goal is:
. Thus, using SPA1 algorithm, the mean complexity of finding a goal is:
![]()
From the Sterling formula 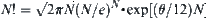 , we obtain:
, we obtain:
![]()
For judging m 1-subtrees, 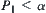 . In general, for judging m i-subtrees,
. In general, for judging m i-subtrees, 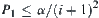 . The total error probability of Type I is:
. The total error probability of Type I is:
![]()
Similarly, 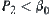 .
.
It is noted that we use the minimum of mean statistics among all i-subtrees to estimate 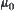 , and the average of mean statistics of the rest (except the minimal one) of i-subtrees to estimate
, and the average of mean statistics of the rest (except the minimal one) of i-subtrees to estimate 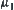 . This will produce new errors. We will construct new SA algorithms to overcome the defect.
. This will produce new errors. We will construct new SA algorithms to overcome the defect.
Corollary 6.2
Assume that 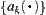 has a distribution function
has a distribution function 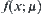 . Let
. Let
![]()
The mean complexity of SPA1 algorithm is O(N ln N).
The theorem and corollary show that SPA1 algorithm can overcome the exponential explosion of complexity only in average sense. This means that in some cases, the statistical inference will still encounter a huge computational complexity. In order to overcome the shortage, we will discuss the revised version SPA2 of SPA1.
Definition 6.2
In SA, SPRT is performed over m i-subtrees using a level 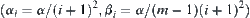 and a given threshold
and a given threshold 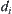 ,
, 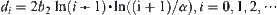 , where
, where 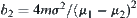 . If the sample size exceeds
. If the sample size exceeds  then the hypothesis
then the hypothesis  is rejected. We define the SA as SPA2 under level
is rejected. We define the SA as SPA2 under level 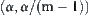 , and denoted by SPA2 for short.
, and denoted by SPA2 for short.
It’s noted that parameters 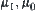 and
and 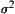 are generally unknown. We may use the following formula to estimate
are generally unknown. We may use the following formula to estimate 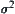 .
.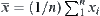 .
.
![]()
Theorem 6.3
Proof
In i-subtrees, the threshold is 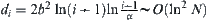 . So the upper bound of the total complexity is
. So the upper bound of the total complexity is 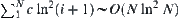 .
.
Thus, the upper bound of complexity of SPA2 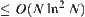 .
.
Now, we consider the error probability.
If in the searching process the sample size has never surpassed the threshold, from Formulas (6.5) and (6.6), it is noted that judging m i-subtrees, the error probability of Type I 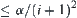 . So the total error probability is:
. So the total error probability is:
![]()
In some searching stage, if the sample size surpasses the threshold and H0 is rejected, the error probability does not change if the subtrees being deleted do not contain the goal, and the error probability will increase if the subtrees being deleted contain the goal. We estimate the incremental error probability as follows.
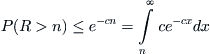
Thus, 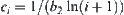 ,
, 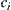 is the value of c corresponding to i-subtrees.
is the value of c corresponding to i-subtrees.
The probability that the sample size surpasses the threshold 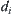 is
is
![]()
Namely, when the sample size surpasses the threshold, the rejection of H0 will cause the new error probability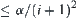 . The totally incremental error probability of Type I is
. The totally incremental error probability of Type I is
![]()
Finally, the total error probability of Type I is 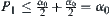 .
.
Similarly, Type II error 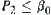 .
.
Certainly, when the sample size surpasses the threshold, the rejection of H0 does not change the error probability of Type II.
Corollary 6.3
Assume that 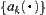 has a distribution function
has a distribution function 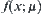 and satisfies
and satisfies
![]()
The upper bound of the complexity of SPA2 is 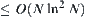 .
.
SPA algorithms constructed have the following shortcoming. The distribution function 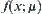 should be known beforehand. Generally this is unpractical so it has to be assumed as a normal distribution
should be known beforehand. Generally this is unpractical so it has to be assumed as a normal distribution 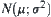 sometime. Even so, its parameters
sometime. Even so, its parameters 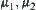 and
and 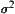 are still unknown generally. Although their values can be estimated from some data it will cause new errors certainly. We will use ASM statistical inference method to overcome the shortcoming.
are still unknown generally. Although their values can be estimated from some data it will cause new errors certainly. We will use ASM statistical inference method to overcome the shortcoming.
6.2.2. SAA Algorithms
Assume that 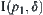 is the leftmost interval among m confidence intervals along a number line. If
is the leftmost interval among m confidence intervals along a number line. If 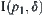 and
and 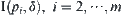 are disjoint,
are disjoint, 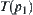 is accepted; otherwise all subtrees are rejected and the algorithm fails.
is accepted; otherwise all subtrees are rejected and the algorithm fails.
In fact, ASM is a sequential testing method. First, letting R=1 and using Formula (6.6) as hypothesis testing, if the formula is satisfied, then we have the corresponding interval 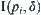 , otherwise the sampling continues.
, otherwise the sampling continues.
Definition 6.3
In SA search, if the ASM is used as statistical inference method S, and when testing i-subtrees 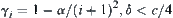 , then the SA search is called SAA algorithm with level
, then the SA search is called SAA algorithm with level  , or simply SAA algorithm.
, or simply SAA algorithm.
Theorem 6.4
Assume that 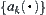 satisfies Hypothesis I and has a finite forth moment. Given
satisfies Hypothesis I and has a finite forth moment. Given 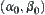 , letting
, letting 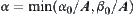 ,
, 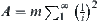 , then SAA algorithm with level
, then SAA algorithm with level  can find the goal with probability
can find the goal with probability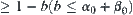 , and the order of its mean complexity is
, and the order of its mean complexity is 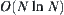 .
.
Proof
Since for i-subtrees 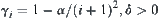 , from Formula (6.8) we have that the order of mean complexity of ASM for testing i-subtrees is
, from Formula (6.8) we have that the order of mean complexity of ASM for testing i-subtrees is
![]()
Thus, the order of total mean complexity is
![]()
For judging i-subtrees, the error probability of Type I is 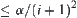 and Type II is
and Type II is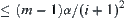 . The total error probability for judging i-subtrees is
. The total error probability for judging i-subtrees is 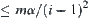 .
.
Thus, the total error probability of SAA algorithm is
![]()
SAA is superior to SPA in that it's no need to know what distribution function 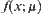 is in advance, and the calculation of statistics is quite simple.
is in advance, and the calculation of statistics is quite simple.
In general, 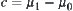 is unknown. So it’s difficulty to choose a proper width of confidence interval in SAA based on
is unknown. So it’s difficulty to choose a proper width of confidence interval in SAA based on  . In practice, approximate
. In practice, approximate 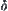 can be chosen as a rule of thumb. Sometime, SAA may work in the following way. Given an arbitrary constant δ1, if
can be chosen as a rule of thumb. Sometime, SAA may work in the following way. Given an arbitrary constant δ1, if 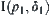 intersects with other intervals
intersects with other intervals 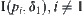 , new constant
, new constant 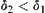 is tried, until a proper value of δ is got.
is tried, until a proper value of δ is got.
The revised SAA is as follows.
Let 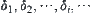 be a sequence of strictly and monotonically decreasing positive numbers, e.g.,
be a sequence of strictly and monotonically decreasing positive numbers, e.g., 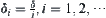 . In the i-th turn search, let the width of confidence interval be
. In the i-th turn search, let the width of confidence interval be 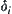 . Since
. Since 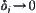 so long as
so long as 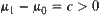 , c is a constant, there always exists
, c is a constant, there always exists 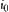 such that if
such that if 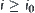 then
then 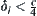 . So we can overcome the difficulty brought about by the unknown c; certainly the computational complexity of SAA will increase
. So we can overcome the difficulty brought about by the unknown c; certainly the computational complexity of SAA will increase 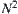 times, i.e., the order of complexity becomes
times, i.e., the order of complexity becomes 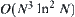 .
.
If we choose a lower bound 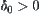 of
of 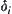 , when
, when 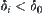
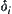 no longer decreases, i.e., let
no longer decreases, i.e., let 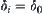 . Then, the order of mean complexity of SAA will not increase.
. Then, the order of mean complexity of SAA will not increase.
Under the same significance level, the mean 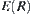 of stopping variable of SPRT is minimal, i.e., the mean complexity of SA constructed by SPRT is minimal. But the distribution function
of stopping variable of SPRT is minimal, i.e., the mean complexity of SA constructed by SPRT is minimal. But the distribution function 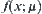 should be known beforehand in the SPA search, i.e., under a more rigor condition.
should be known beforehand in the SPA search, i.e., under a more rigor condition.
6.2.3. Different Kinds of SA
In Section 6.2.1 and 6.2.2 we construct SA by using SPRT and ASM as statistical inference methods. Since the two methods are sequential and fully similar to search, it’s easy to understand that the introducing the methods to the benefit of search. If there is any other kind of statistical inference method, e.g., non-sequential, can this get the same effect? We'll discuss below.
Assume that 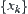 and
and 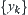 are two i.i.d. random variables having finite fourth moments. Their distribution functions are
are two i.i.d. random variables having finite fourth moments. Their distribution functions are 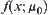 are
are  , respectively. Let simple hypotheses be
, respectively. Let simple hypotheses be 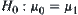 ,
, 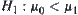 . From statistics, it's known that if a statistical inference method S satisfies the following properties, the statistical decision can be made in a polynomial time.
. From statistics, it's known that if a statistical inference method S satisfies the following properties, the statistical decision can be made in a polynomial time.
The properties are
(1) Given significance level  , the mean of the stopping variable R satisfies
, the mean of the stopping variable R satisfies 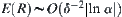 , where E(R) is the mean of R and
, where E(R) is the mean of R and 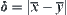 .
.
(2) 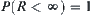 , S terminates with probability one.
, S terminates with probability one.
(3) When n>0, 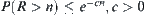 , where c>0 is a constant.
, where c>0 is a constant.
As we know, both SPRT and ASM satisfy the above properties. 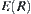 is proportional to
is proportional to 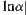 which underlies the complexity reduction of the SA search algorithms by using SPRT and ASM as statistical inference methods. If the variances
which underlies the complexity reduction of the SA search algorithms by using SPRT and ASM as statistical inference methods. If the variances 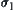 and
and 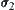 of
of 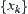 and
and 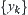 are known,
are known,  test and t-test may be adopted. For example, using
test and t-test may be adopted. For example, using  test to determine the validity of
test to determine the validity of 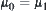 , that is, whether the mean of random variable X is equal to that of Y, we may use the following composite statistic.
, that is, whether the mean of random variable X is equal to that of Y, we may use the following composite statistic.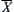 and
and 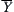 are the means of
are the means of 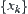 and
and 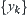 , respectively, l and n are the sample sizes of
, respectively, l and n are the sample sizes of 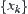 and
and 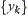 , respectively.
, respectively.
![]()
When search reaches node p it has m sub-nodes 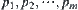 . Let
. Let 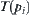 be a sub-tree rooted at
be a sub-tree rooted at 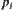 . The means of statistics
. The means of statistics 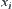 of sub-trees
of sub-trees 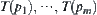 are assumed to be
are assumed to be 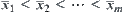 , respectively.
, respectively.
Now, we use 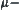 testing method to judge whether the means of
testing method to judge whether the means of 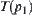 and
and 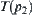 are equal. Significance level
are equal. Significance level 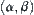 and sample size
and sample size 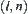 are given, where
are given, where 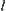 and
and  are the numbers of expanded nodes of
are the numbers of expanded nodes of 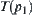 and
and 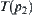 , respectively. In the testing process, sample size
, respectively. In the testing process, sample size 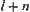 is gradually increased, for example,
is gradually increased, for example, 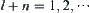 .
.
From 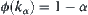 , we have
, we have 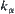 , where
, where 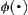 is a standard normal distribution function.
is a standard normal distribution function.
If 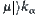 then
then 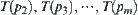 are deleted.
are deleted.
If 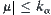 then the total sample size
then the total sample size 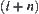 is increased by 2, i.e., sub-trees
is increased by 2, i.e., sub-trees 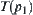 and
and 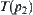 are expanded by search algorithm A.
are expanded by search algorithm A. 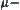 test continues.
test continues.
It’s noted that in the 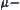 test, when calculating the composite statistic
test, when calculating the composite statistic  we replace
we replace 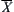 by
by 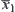 and
and 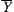 by
by 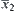 .
.
In order to terminate the search in time, we choose a threshold 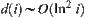 for the i-th level nodes. If the sample size
for the i-th level nodes. If the sample size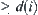 , then sub-tree
, then sub-tree 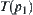 is accepted.
is accepted.
It can be proved that the above algorithm has the same order of mean complexity as that of SPA algorithm.
If the variances of 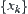 and
and 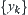 are finite but unknown, the sequential t-test constructed from Cox theorem can be used.
are finite but unknown, the sequential t-test constructed from Cox theorem can be used.
By combining different kinds of statistical inference methods and heuristic searches and successively using these searches, a variety of SA algorithms can be obtained.
If the global statistics extracted from each subtree in G satisfy Hypothesis I, then the SA search constructed from S has the following properties which are our main conclusions about SA.
(1) The mean complexity of the SA is 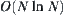 , N is the depth at which the goal is located.
, N is the depth at which the goal is located.
(2) Given 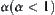 , using the SA search for the first time the goal can be found with probability α.
, using the SA search for the first time the goal can be found with probability α.
(3) Based on the property 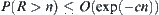 , given a proper threshold, then the upper bound of the complexity of each time SA search is
, given a proper threshold, then the upper bound of the complexity of each time SA search is 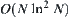 .
.
(4) In some SA search stage, a wrong search direction might be chosen but the search can terminate in a polynomial mean time, due to the polynomial judgment time of the statistical inference. Consequently, by applying the SA search successively, the goal can also be found with polynomial mean complexity.
6.2.4. The Successive Algorithms
In a word, under a given significance level 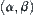 , the SPA (SPA1 or SPA2) search can avoid the exponential explosion and results in the polynomial complexity
, the SPA (SPA1 or SPA2) search can avoid the exponential explosion and results in the polynomial complexity 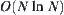 (or
(or 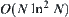 ). Unfortunately, the solution path may mistakenly be pruned off or a wrong path may be accepted, i.e., the error probability is
). Unfortunately, the solution path may mistakenly be pruned off or a wrong path may be accepted, i.e., the error probability is 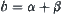 . In other words, in light of the SPA search, a real goal can only be found with probability (1-b).
. In other words, in light of the SPA search, a real goal can only be found with probability (1-b).
The mean of stopping variable R of the statistical inference is 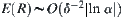 . No matter the i-subtree containing goal can be found or not, the search stops with mean computation
. No matter the i-subtree containing goal can be found or not, the search stops with mean computation 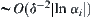 certainly. Thus, the search stops with mean complexity
certainly. Thus, the search stops with mean complexity 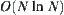 in the first round search. Imagine that if the goal node cannot be found in the first round search, SA search is applied to the remaining part of G once again. Thus, the probability of finding a real goal is increased by
in the first round search. Imagine that if the goal node cannot be found in the first round search, SA search is applied to the remaining part of G once again. Thus, the probability of finding a real goal is increased by 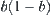 , or error probability is decreased to
, or error probability is decreased to 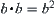 ,…, the repeated usage of SA continues until the goal is found. We call this procedure successive SA, or SA for short. How about its computational complexity? Does it still remain the polynomial time?
,…, the repeated usage of SA continues until the goal is found. We call this procedure successive SA, or SA for short. How about its computational complexity? Does it still remain the polynomial time?
Using the SA search, in the first time the probability of finding the goal is 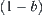 . Its complexity is
. Its complexity is 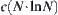 . Thus, the equivalent complexity is
. Thus, the equivalent complexity is
![]()
In general, the probability that the goal is found by SA search just in the i-th time is 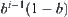 , and the complexity is
, and the complexity is 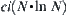 . The equivalent complexity is
. The equivalent complexity is
![]()
The total mean complexity of SA is
![]()
Since 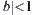 , we have
, we have
![]()
We have the following theorem.
Theorem 6.5
In a uniform m-ary tree, using the successive SA search, a goal can be found with probability one, and the order of its mean complexity remains 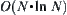 .
.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.