
Throughout this book, we have evaluated various persistence technologies. Up until now, the mechanisms we examined in this book have been standards based or open-source Java solutions—or both. In this chapter, we are going to deviate from this pattern and evaluate pureQuery, a commercial solution from IBM that represents a different approach. There are a number of reasons we think you should find it worthwhile to examine pureQuery:
You may want to exploit new languages or new architectures. For example, in Chapter 2, “High-Level Requirements and Persistence,” we discussed the emergence of Web 2.0 and how data access patterns are different. You may want a persistence solution that is optimized around the Web 2.0 style of development (sometimes called Web Oriented Architecture or Web Extended SOA). Today’s Java standards and solutions are geared toward enterprise applications.
Often, solutions use scripting languages such as Ruby on Rails; and a simplified persistence solution that exploits these languages will be required. In this chapter, we illustrate the use of a Java-based scripting language called Groovy and how pureQuery can be used in such a scripting environment.
Performance may be the most important factor you consider in your requirements. In this case, a solution that is optimized for SQL or even a particular vendor’s database product that you already use may be ideal.
You will likely find that monitoring the end-to-end data access paths is required. Sometimes, persistence technologies optimized for a database can contain opportunities to inject (either through tooling or code) entry-points to data access monitoring features provided by the vendor. In this chapter, we explore the ability to monitor within pureQuery.
pureQuery is an IBM solution for Java data access designed for performance and exploiting SQL. As with iBATIS evaluated in Chapter 6, the goal is to embrace rather than hide SQL. Unlike iBATIS, SQL can be embedded directly in the Java application code (as was done with SQL for Java), rather than specified indirectly in an annotation or a separate mapping file. To make this even easier, pureQuery can be used with a set of Eclipse Java plug-ins that can provide SQL assist inside your programs.
At the core, pureQuery is a table gateway framework. However, all the patterns we have examined in this book can be implemented to some degree within pureQuery because it has multiple layers. For example, you can use the runtime API directly and implement the transaction script pattern. Using the pureQuery tools, you can generate a set of data objects based on SQL statements and database schemas and implement the gateway pattern. Finally, pureQuery can be used as an underlying layer to another ORM, which then can implement a full Domain Mapper—in this case, you might be using pureQuery indirectly through another mechanism and not even know it!
Java persistence has been dominated primarily by ORM frameworks. History has shown that since Java EE was created, there have been various attempts at ORM (CMP, JDO, Hibernate, and so on.). JPA seems to be the current emergent winner in that space. However, as stated, there is a considerable amount of time invested in tuning ORM-based applications for performance. In addition, there is a class of applications that use SQL directly for reasons we stated in the introduction to this chapter. Beyond these reasons, enterprise customers were explicitly asking IBM for a persistence framework to meet a number of additional requirements that we discussed briefly in Chapter 2. Figure 9.1 (repeated from Chapter 2) illustrates some of these requirements.
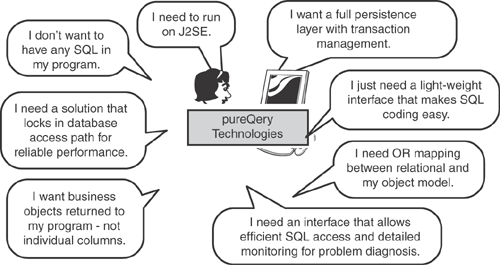
IBM decided to create pureQuery as a common query engine that could be used in various environments to meet these and other requirements.
pureQuery is a high-performance Java data access platform focused on simplifying the tasks of developing and managing applications that access data. Its goal is to improve the life cycle of Java applications that access data. pureQuery takes an end-to-end view of the data access life cycle, from Java code to the relational database. Figure 9.2 illustrates this life cycle.
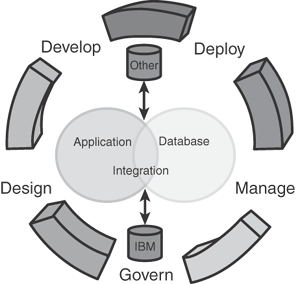
At each life-cycle stage, pureQuery attempts to meet several requirements and design goals:
Design
Enable querying of different data sources, including Database, Cache, Collections, XML
Multiple API “styles” to integrate well with popular Java frameworks, including JPA
Minimize path length from application code to data access, including passing application SQL directly to the database
Develop
Provide tools to embed SQL in a Java source file
Expose SQL APIs that are easy to invoke and extend
Deploy
Generate code automatically when metadata styles are used
Optimize both dynamic and static SQL access paths for efficiency
Manage
Make packaging as simple as possible
When data access problems occur, track SQL back to individual application source code components quickly across the application tiers
Align with enterprise change control processes
Make security and access control to the data as simple as possible
From an architectural point of view, pureQuery is designed as a very thin layer on top of JDBC so that it can be used with many JDBC-compliant databases and serve as an implementation engine for other frameworks. Figure 9.3 shows an overview of pureQuery’s layered architecture. It is worth noting that running pureQuery under a different ORM such as Hibernate and JPA is shown in the figure to illustrate what is possible. However, at the time of publication, these implementations are not yet available to the general public.
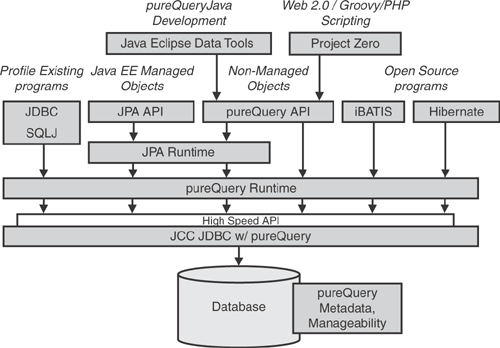
This architecture enables pureQuery to meet the requirements listed for most databases, especially in the Design, Develop, and Deploy life cycle stages. However, because pureQuery is optimized to work with IBM DB2, it can exploit enhancements in the IBM DB2 JCC driver to achieve additional benefits, such as the following:
Single API for joins in-memory across cache, relational, and in-memory objects. Joins in-memory across XML documents.
Static SQL for better performance.
Access path locked in at deployment for more reliable production runtime behavior.
Multiple versions of the access path and the ability to easily revert to prior versions.
Tooling to gather performance metrics, including historical trends at both the application and statement level.
All SQL statements and access paths recorded in the DB2 server, which helps DBA with problem determination and capacity planning.
Application origin captured for all SQL statements for rapid problem source identification across the application tiers and runtime stack.
The pureQuery technology itself is currently not part of a standard. That said, pureQuery-based applications can run inside Java SE and Java EE environments, and can be used in scripting environments such as Groovy. With pureQuery, your code will work with most JDBC-compliant databases, so you will not lose portability. In addition, if you use pureQuery under another framework, you can achieve better development productivity and runtime performance without your end users needing to know about it.
pureQuery was built by the IBM Information Management team in response to these requirements and is being extended by ProjectZero as needed to support Web 2.0 applications. Project Zero is an IBM incubator project focused on agile development of Web 2.0 applications based on Service Oriented Architecture (SOA). Web 2.0 applied to SOA allows Web artifacts based on HTTP and RESTful principles to extend the reach of SOA. This new architecture is referred to as Web Extended SOA. We will discuss these principles throughout this chapter. Fielding is the definitive source for more information on RESTful principles [Fielding].
The way the two are related is that pureQuery is used as a query engine for Project Zero. In addition to using the data APIs, Project Zero provides the capability to make use of scripting languages to access data directly through SQL. Project Zero allows for executing pureQuery using Groovy and PHP. Additionally, Milestone 2 includes a Resource Mapping for creating a standard mapping between RESTful services and data that exploits pureQuery.
Another thing that makes ProjectZero very exciting is its exciting new development approach called Community-Driven Commercial Development (CD/CD, or CD2). CD2 enables the user community to observe and influence technical decisions for ProjectZero (also called “Zero”). Furthermore, users have direct access to the Zero development team and the source code itself.
This approach should not be confused with Open Source, where the community can contribute to any aspect of the technology. Although you can contribute requirements, prototypes, and extensions to Zero, you cannot contribute directly to the core.
But similar to Open Source and Standards bodies, Project Zero’s goals are both technical and social in nature.
The technical goals are to provide a scalable platform that simplifies Web Extended SOA application development in three important dimensions:
Create—. Simplify development with support for scripting languages (currently Groovy and PHP), conventions that promote RESTful patterns, and catalogs of reusable assets.
Assemble—. Enable rapid access and aggregation of disparate services into unified applications, including data flows, orchestrations, and custom mediations.
Deploy—. Provide an application-centric runtime environment based on the well-known and stable Java VM, and optimized for agile development (small footprint; fast restart).
The social goals relate to the CD2 process itself. In keeping with CD2, all the information about Zero is “open” and available at www.projectzero.org. At the time we wrote this chapter, Project Zero had released Milestone 1 and was close to releasing Milestone 2. We expect the platform to evolve as time goes on, and may even become a de facto standard in its own right.
The pureQuery runtime requires an underlying JDBC driver like most persistence frameworks. You can use it to build Java SE applications. Other dependencies will be specific to the environment in which pureQuery is used. For example, when using pureQuery inside of Project Zero, you need to download its platform from the website [Zero 1].
Besides the JDBC drivers and environment-specific dependencies, there are no other dependencies for the pureQuery runtime. The pureQuery technology also includes tools to generate code and optimizations. They are based on the Eclipse Platform and require an Eclipse runtime with Data Tool support. The IBM Data Studio contains the pureQuery tools. We show examples of this tooling throughout the chapter. See the IBM Data Studio web page for more details [IBM DS].
The pureQuery technology is licensed by IBM, and its runtime and tools ship with the IBM Data Studio product. Please refer again to [IBM DS] for details on the license. The pureQuery runtime also comes with Project Zero. For details on the Project Zero license, see the FAQ page [Zero 2].
The pureQuery technology is a fairly new technology. However, some practiced articles and tutorials are already available. Table 9.1 lists some examples.
Table 9.1. Available Literature
Title | Source | Description |
|---|---|---|
“Overview of pureQuery Tools” A.9.1 | www.ibm.com/developerworks/db2/library/techarticle/dm-0709surange/ | General overview of the pureQuery tools |
“pureQuery: IBM’s New Paradigm for Writing Java Database Applications” A.9.2 | www.ibm.com/developerworks/db2/library/techarticle/dm-0708ahadian/ | General introduction to pureQuery |
“Detect and Fix SQL Problems Inside Java Program” | www.ibm.com/developerworks/db2/library/techarticle/dm-0709surange2/ | Article showing how to use the pureQuery tools to detect SQL problems with your application A.9.3 |
“Configuring Data Access with Project Zero” [Zero 3] | www.projectzero.org/wiki/bin/view/DocumentationMilestoneOne/DataAccess | Developer Guide for using Data Access APIs with Project Zero |
“Building RESTful Services for your Web Application with Project Zero” | Tutorial on Project Zero showing Data APIs in Action A.9.4 | |
“RESTful applications in an SOA: Part 2” | Follow-on tutorial on Project Zero showing Data APIs and ZRM in Action A.9.5 | |
“Use Project Zero’s data access APIs to build a simple wiki” | Article illustrating the data access API’s in Project Zero in the context of building a Wiki. A.9.6 |
In this section, we examine three distinct patterns for application development using pureQuery technology:
Direct use of the Data API—. pureQuery provides a complete set of Java methods for executing queries and update operations. These methods take an SQL statement and associated parameters as input and, where applicable based on the statement type, return results in numerous forms including: (a) scalar and primitive types, (b) Java collection types, and (c) user-defined Bean types. With this Data API style pattern, the SQL query or update statement can be embedded directly in the application code and appears as a parameter on the associated method invocation. This approach, sometimes referred to as “Inline Method Style,” offers simplicity and tight integration between the SQL and the Java languages.
Annotated Method Style—. pureQuery allows Data access and update methods to be declared in a user-created Java interface using annotations that express the specific query or update operations in standard SQL. Using Java-annotated class definitions (often on classes that follow the conventions for Java Beans [Java Beans]), a code generator automatically creates the implementation of the specified methods. The Annotated Method style offers the advantage of separating the data access declarations and the associated SQL from the application’s business logic. The application simply invokes the methods defined in the interface and uses familiar Java objects, beans, and collections for providing parameters to the method and for receiving query results. In essence, this approach is tooling that hides the details of the Data API from the developer.
Indirectly—. Sometimes the pureQuery API is used underneath another platform, such as the Groovy wrappers available in Project Zero.
Throughout this chapter, we emphasize the Data API and wrappers through Project Zero; however, in certain sections of the template, we will show examples of the underling Java API.
When discussing Project Zero, we use the Groovy scripting language as the concrete example. Groovy is a scripting language for Java developers. The Groovy website [Groovy] defines it like this:
An agile and dynamic language for the Java Virtual Machine
Builds upon the strengths of Java but has additional power features inspired by languages like Python, Ruby, and Smalltalk
Makes modern programming features available to Java developers with an almost-zero learning curve
Supports Domain-Specific Languages and other compact syntax so your code becomes easy to read and maintain
Makes writing shell and build scripts easy with its powerful processing primitives, OO abilities, and an Ant DSL
Increases developer productivity by reducing scaffolding code when developing web, GUI, database, or console applications
Simplifies testing by supporting unit testing and mocking out-of-the-box
Seamlessly integrates with all existing Java objects and libraries
Compiles straight to Java bytecode so you can use it anywhere you can use Java
We will show pureQuery initialization both for the pureQuery API and for the Groovy extensions. It is worth noting that the pureQuery Data API can be used directly in Project Zero based applications.
The Data API is the core of the pureQuery API. It provides the methods you need to execute queries. To access it, you need to execute one of the get Data methods of a DataFactory. pureQuery allows you to pass in a JDBC Connection or a DataSource. It leaves it up to the developer to create a connection or DataSource. Listing 9.1 shows an example of using JDBC to create a connection.
Example 9.1. Getting an Instance of Data with a JDBC Connection
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
String url = "jdbc:derby://localhost/test";
String username = "myUserName";
String password = "myPassword";
Connection connection = DriverManager.getConnection(
url, username, password
);
Data data = DataFactory.getData (connection);The decision to delegate the initialization to the application context allows it to be reusable in various environments. Listing 9.2 shows how you can pass a DataSource into the DataFactory.
Frameworks built on top of pureQuery provide their own style of bootstrapping, as we will see in the discussion of Project Zero.
Project Zero provides query wrappers that enable you to invoke queries within the Groovy and PHP scripting languages. To do this, it provides a scripting abstraction to the Data API. In Milestone 1 of Project Zero, this is called a Manager. This Manager wraps the pureQuery Data API and provides extensions for executing queries using Groovy programming constructs, such as GString, where you can declare regular expressions that refer to other parts of your code. We show examples later in the sections on Create, Retrieve, Update, and so on. A Manager is configured in a Zero configuration file. For details on how Zero configuration works, see the Project Zero website [Zero 4].
Listing 9.3 shows an example of a Zero configuration file. In Milestone 1, Project Zero used “stanzas” in their configuration file. As of Milestone 3, the configuration syntax changed to use a JSON format instead. The example in this book works with Milestone 1. Each stanza starts by declaring a Global Context where all state is maintained in a Project Zero application. The Global Context has zones into which you can store data. The zone defines the scope and life cycle for the data. A configuration key takes the following format: /app/db/<manager_name>/config. You will use the <manager_name> to create an instance of a Manager in your code, as we will see in the “Connections” section.
The Project Zero website has a specific page that contains more information on the Global Context [Zero 5].
In this section, we show how to access connections using both the Data API and Project Zero.
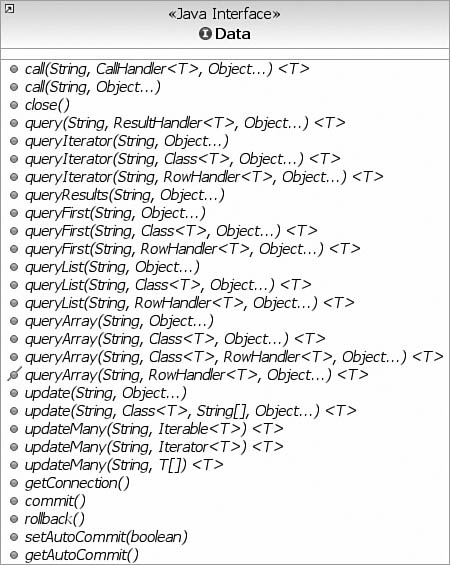
We showed in the “Initialization” section how the Data API makes a connection. After you bootstrap Connections or DataSource objects into your application context, all you need to do is get an instance to a data object. This was shown earlier in Listings 9.1 and 9.2. The Data Interface contains the query method necessary to execute SQL. Figure 9.4 shows the Interface for the Query API.
In Project Zero, rather than asking for a Data instance, you can get an instance of the Manager to use within your Groovy scripts. All you have to do is call the create method on the Manager, as shown in Listing 9.4.
This is the pattern for creating an instance in Milestone 1. Future milestones may provide a slightly different API. The Manager Object wraps the Data API and adds some more convenient methods for patterns in a Web 2.0 environment. Some of these patterns are shown later in the chapter.
In this section, we show how to handle transactions using pureQuery’s data API and Project Zero.
Transactions can be managed in pureQuery using methods on the Data API. PureQuery will then delegate to the underlying JDBC Connection object. If you want to use pureQuery in a distributed transaction rather than use the Data API to demarcate transactions, you must manage your transactions using the JTA API or Container Managed Transactions in an EJB container. When getting an instance of the Data API, you just pass in the DataSource. Listing 9.5 shows an example.
Keep in mind that Project Zero is an environment for writing Web 2.0-based applications where you normally do not concern yourself with managing distributed transactions. However, the Manager class provides convenient methods for starting, committing, rolling back, and ending transactions. It will delegate to the underlying pureQuery API. Listing 9.6 shows an example of the typical sequence of calls to explicitly manage a transaction.
Example 9.6. Explicitly Demarcating Local Transactions in Project Zero
db.startTransaction();
try {
db.update("INSERT...");
db.update("UPDATE...");
db.update("DELETE...");
db.commitTransaction();
}
catch (Exception e) {
db.rollbackTransaction();
} finally {
db.endTransaction();
}Scripting languages like Groovy have programming constructs, called closures, that are like parameterized macros that get defined and “unrolled” inline when used. A closure can greatly simplify your code by handling housekeeping functions that normally must be coded explicitly. Fully explaining Groovy closures can take an entire chapter by itself; the website devotes a whole section to it [Groovy 2].
In any event, the Manager API provides a transaction closure called inTransaction that allows you to wrap a piece of code inside a transaction and automatically handle the commit and rollback logic. Listing 9.7 shows an example.
Example 9.7. Transaction Closure with Groovy
public Order openOrder(int customerId)
throws CustomerDoesNotExistException, OrderAlreadyOpenException {
Order newOrder = new Order();
db.inTransaction
{
db.update("INSERT...");
db.update("UPDATE...");
db.update("DELETE...");
}
return newOrder;
}Zero provides similar abstractions in the PHP language. A specific section is devoted to PHP on the Project Zero website [Zero 6], so we will not show the details here.
Now that we have the bootstrapping completed, the connection made, and the transaction started, we are ready to create some persistent data. We will start with the Data API and then examine how you can create data in Project Zero applications.
As stated earlier, there are two styles of development in pureQuery: the inline code style and the annotated method style. The inline code style requires you to use the Data API where you can use the special :<property_name> convention to insert variables from a specified bean into the queries. This saves you from having to explicitly map fields. Listing 9.8 shows an example that creates an Order in a bean and uses an insert statement.
The other style of development is the annotated method style. In this style, you create a Java Interface that contains a method prefaced with an @Update annotation that contains the SQL insert statement. Listing 9.9 shows an example.
To create an order anywhere in your code, you simply invoke the createOrder method with an Order bean as specified. This annotated interface is then used to generate the actual code using the pureQuery tooling. Figure 9.5 shows an example of the generated artifacts.
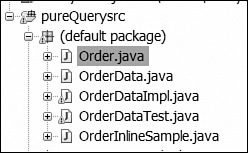
For more detail on the pureQuery tools, refer to the developerWorks website.
A.9.1
Like OpenJPA, pureQuery also allows you to externalize the SQL into an XML file and run the generator against the interface and XML file. As a matter of fact, pureQuery uses the JPA syntax for naming native queries so that they can be used in your code. Listing 9.10 shows an example of the XML syntax.
Example 9.10. Native Query Method
<entity-mappings xmlns="java.sun.com/xml/ns/persistence/orm">
<named-native-query
name="org.pwte.domain.OrderData#createOrder(Order)"
>
<query>
insert into ORDERS (CUSTOMER_ID, STATUS, TOTAL)
values( :customerId, :status, :total)
</query>
</named-native-query>
<entity class="Order">
</entity>
</entity-mappings>If you prefer to create fewer artifacts and do not mind modifying the SQL directly in your code, you will likely prefer the annotated style. Otherwise, if you prefer to externalize your SQL so that it can be reviewed and maintained separately, then you will likely prefer the XML approach.
Project Zero extends the query APIs to enable you to use scripting advantages. For example, Groovy supports the notion of GString, which allows you to enter an expression within a string. Listing 9.11 shows an example of inserting a LineItem. Strings that are declared inside double quotes in Groovy can contain arbitrary expressions inside them, as shown in Listing 9.11 using the ${expression} syntax in a similar way to JSP EL, Velocity, and JEXL. Any valid Groovy expression can be enclosed in the ${...}, including method calls and such. GStrings are defined the same way as normal Strings would be created in Java.
What actually happens is whenever a string expression contains a ${...} expression, then rather than a normal java.lang.String instance, a GString object is created that contains the text and values used inside the String. GString uses lazy evaluation, so it’s not until the toString() method is invoked that the GString is evaluated. More information on GStrings can be found in a special section of the Groovy website [Groovy 3]. The Project Zero API will take the handle to the GString object, get an array of items, and replace the expression with ? needed for a prepared statement. (Keep in mind that anything that causes the GString to evaluate to a String, like the + concatenation in Java, will not allow for using the GString substitution.)
Example 9.11. Insert Using GStrings
LineItem lineItem = new LineItem();
lineItem.setOrderId(openOrder.getOrderId());
lineItem.setProductId(product.getProductId());
lineItem.setAmount(amount);
lineItem.setProduct(product);
lineItem.setQuantity(quantity);
db.update(
"INSERT INTO LINE_ITEM (ORDER_ID,PRODUCT_ID,amount,quantity)
VALUES (
${lineItem.orderId},
${lineItem.productId},
${lineItem.amount},
${lineItem.quantity}
)"
);Project Zero also supports other scripting patterns that allow you to bind properties from multiple objects into the SQL with a ?#.property syntax, where # is the number of the object passed as input. These are inherited from pureQuery. Listing 9.12 shows an example.
Example 9.12. Binding Properties from Multiple Objects into an Update
Object order = // obtained perhaps through defaultJsonInput
Customer customer = // obtained somehow through another source
data.update(
"INSERT INTO
orders (
orderId, customerId, itemId, quantity, price, address
)
VALUES (
?1.orderNum, ?2.custId, ?1.itemNum, ?1.quantity,
?1.price, ?2.address
)
",
order, customer
);As we did with create, we will first examine approaches to retrieve data enabled by the pureQuery Data API, and then examine those enabled by ProjectZero.
Also as in the “Create” section, you can enter any SQL and use the :<propertyName> or ? pattern for issuing queries. Listing 9.13 shows an example of getting an instance of a customer using the ? pattern and the queryFirst method. The queryFirst method takes three parameters. The first is the query itself. The second parameter is the class the result will be mapped to. And the third parameter is the id value that maps to the ? parameter. The later “ORM Features Supported” section describes the details of how the mapping is done. The default is to match the column name to the fields on the class by name.
Example 9.13. Retrieving Customer
Customer getCustomer = db.queryFirst (
"select
CUSTOMER_ID, OPEN_ORDER, NAME, BUSINESS_VOLUME_DISCOUNT,
BUSINESS_PARTNER, BUSINESS_DESCRIPTION,
RESIDENTIAL_HOUSEHOLD_SIZE, RESIDENTIAL_FREQUENT_CUSTOMER,
TYPE
from CUSTOMER where CUSTOMER_ID = ?
",
Customer.class, customerId
);The Data API also allows you to retrieve Lists and Arrays with the queryList and queryArray methods. You can even get an iterator directly, as shown in Listing 9.14.
You also can use the @Select annotation or native query method in the same way as we illustrated in the “Create” section.
Exactly as we did in the create scenario, you can use GString to get results. Listing 9.15 shows an example of getting Product data.
Besides retrieving JavaBeans, you can retrieve a Java Map or primitives. You can also retrieve Lists of JavaBeans, Maps, or primitives. Project Zero is optimized for passing JSON objects, XML, or Data Feeds. Listing 9.16 shows an example used by a Project Zero application to extract XML out of a result. You will see another use of a closure associated with the Manager—this time called eachRow. The Select statement is the parameter to the left of the arrow, and the closure statement is to the right of the arrow.
Example 9.16. XML Results
def data = zero.data.groovy.Manager.create('mydb')
def xml = new groovy.xml.MarkupBuilder(request.writer)
xml.records() {
data.eachRow('SELECT * FROM table'){ row ->
item(id: row['id'], name: row.name)
}
}
// creates the following XML:
// <records>
// <item id="10" name="Geoff" />
// <item id="11" name="Roland" />
// <item id="15" name="Kyle" />
// </records>Again, we will look at how to update persistent objects using the pureQuery Data API followed by examples using ProjectZero and Groovy.
You can execute update statements to modify data using the pureQueryAPI exactly as you can execute insert and select statements. Listing 9.17 shows an example of using the inline style to update the CUSTOMER database row from properties in a Customer instance.
Example 9.17. Executing Updates
Customer customer = // get instance.
db.update(
"update CUSTOMER
set CUSTOMER_ID = :customer_id, OPEN_ORDER = :open_order,
NAME = :name,
BUSINESS_VOLUME_DISCOUNT = :business_volume_discount,
BUSINESS_PARTNER = :business_partner,
BUSINESS_DESCRIPTION = :business_description,
RESIDENTIAL_HOUSEHOLD_SIZE = :residential_household_size,
RESIDENTIAL_FREQUENT_CUSTOMER =
:residential_frequent_customer,
TYPE = :type
where CUSTOMER_ID = :customer_id
",
customer
);As with the other CRUD operations we have examined so far, all the coding styles are supported. Listing 9.18 shows the annotated query style being used to update an Order.
Listing 9.19 shows code from the implementation of the submit method from the common example that highlights the use of the Groovy GString style and the inTransaction closure.
Example 9.19. Use of Update in Project Zero using GString style
public void submit(int customerId)
throws CustomerDoesNotExistException,
OrderNotOpenException, NoLineItemsException {
db.inTransaction
{
//Code to get and make changes to openOrder
db.update(
"UPDATE ORDERS
SET STATUS = ${Order.Status.SUBMITTED.toString()}
where ORDER_ID = ${openOrder.orderId}"
);
db.update("UPDATE CUSTOMER SET OPEN_ORDER = NULL");
};
}This section shows that deleting data in the pureQuery Data API or Project Zero and Groovy is no different from the other CRUD methods.
Listing 9.20 shows an example of using the Data API to delete an order with a given status.
Listing 9.21 shows how you can use the @Update annotation to cause two methods to be generated that you can use in your code. The first method has a parameter for passing the order id; the second has a parameter for passing an Order object, from which the ID is extracted.
Example 9.21. Annotated Style of Delete
// Delete ORDERS by parameters @Update(sql="delete from ORDERS where ORDER_ID = ?") int deleteOrder(int order_id); // Delete one ORDERS by Order object @Update(sql="delete from ORDERS where ORDER_ID = :order_id") int deleteOrder(Order o);
Listing 9.22 shows part of the removeLineItem method from the common example. You can see that we use the Groovy Pattern of GString in much the same way we do with other patterns.
Example 9.22. Delete in removeLineItem
public void removeLineItem(int customerId,int productId )
throws CustomerDoesNotExistException, OrderNotOpenException,
ProductDoesNotExistException, NoLineItemsException,
GeneralPersistenceException {
db.inTransaction
{
//Code to retrieve and determine object can be deleted
db.update(
"DELETE FROM LINE_ITEM
WHERE PRODUCT_ID = ${productId} AND
ORDER_ID = ${customer.openOrder.orderId}"
);
}
}The Data API enables you to invoke stored procedures using the call statement, much like you can call any other SQL statement. Listing 9.23 shows an example.
This same method is used to call stored procedures in Project Zero.
You can also cause a method to be generated using the special @Call annotation, as shown in Listing 9.24.
You then use this method in your application code, effectively separating the SQL from the code that uses it. The Manager API can be used to call stored procedures in a similar fashion.
The Data API in pureQuery has an updateMany method that enables you to send a batch of statements to the database. Listing 9.25 shows an example of passing an ArrayList of LineItems into the updateMany statement. Project Zero’s DataManager API has a version of this method as well.
There are various ways of extending pureQuery. Project Zero is an example of extending pureQuery to support various additional patterns. One of the most common ways to extend pureQuery is with ResultHandlers and RowFactories. Figure 9.6 shows the relationship between the Data Interface and the handlers.
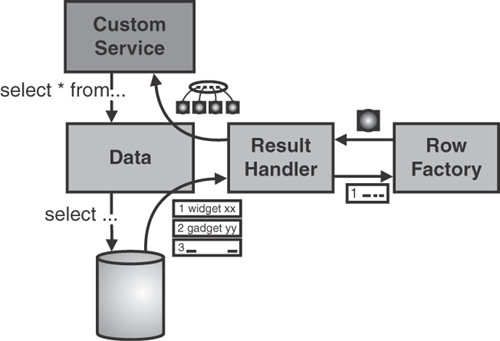
The most common scenario is to write your own handlers to provide custom result formats. For example, pureQuery provides result handlers to return specialized results. Listing 9.26 shows an example of using a JSONResultHandler to create a custom JSON result handler. Notice that you have to pass the ResultHandler into the generic query method.
Example 9.26. Custom ResultHandler
//code that uses the custom handler
String json = d.query(
"select * from Customer", new JSONResultHandler()
);
...
//Definition of Handler...
class JSONResultHandler implements ResultHandler
{
String handle(ResultSet rs)
{
sb.append("{");
for (int x=1; x<=cols; x++) {
sb.append("""+ m.getColumnName(x) +""="");
sb.append(rs.getString(x) +""");
if (x<cols) sb.append(",");
}
sb.append("}");
}
}You can also use a RowHandler to create custom results a row at a time within the context of the queryFirst method, as shown in Listing 9.27. Unlike a ResultHandler, which gets passed to the generic query method, The RowHandler can be passed into the various query methods, such as queryFirst or queryList. After the RowHandler, you can add any of the inputs necessary, like the hard coded 100 in Listing 9.27.
Example 9.27. Custom RowHandler
CustomClass myCustCls = data.queryFirst(
"SELECT column1,column2 FROM sometable WHERE id=?",
new RowHandler() {
public CustomClass createNext(
ResultSet resultSet, CustomClass obj
)
{
CustomClass custom = new CustomClass();
custom.customProp1 = resultSet.getString(1);
custom.customProp2 = resultSet.getDate(2);
return custom;
}
},
100
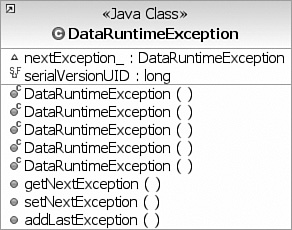
);The Data API throws an unchecked DataRuntimeException for most errors. This exception is shown in class diagram notation in Figure 9.7.
The pureQuery framework is optimized for relational database queries. However, as we have shown, you can pass Objects into and out of queries through various shortcuts. pureQuery provides a set of Java Annotations that can be used to add extra metadata in case your table names do not match the class. The goal is not to be a full Domain Mapper, but to provide flexibility in class names.
Class names that match table names do not need to be mapped. However, pureQuery provides Java Annotations to override default mappings. The annotations are very similar to those of the JPA specification. Listing 9.28 shows the use of the @Table annotation.
pureQuery can populate objects that are part of an inheritance hierarchy based on a query; however, you have to determine the type of mapping as described in Chapter 3. There is no specific support for a particular inheritance mapping. Listing 9.29 shows the AbstractCustomer and ResidentialCustomer used in our example, using the @Table annotation to map both to the same table. The listing shows how you would map using the single table inheritance style. Listing 9.30 shows how you would populate the Objects.
In Listing 9.30, we first query the type to check what instance to populate when we load a Customer from the database.
Example 9.30. Populate Inheritance Chain
public AbstractCustomer loadCustomer(int customerId)
throws CustomerDoesNotExistException {
String customerQuery = "
SELECT
c.CUSTOMER_ID, c.NAME, c.BUSINESS_VOLUME_DISCOUNT,
c.BUSINESS_PARTNER, c.BUSINESS_DESCRIPTION,
c.RESIDENTIAL_HOUSEHOLD_SIZE,
c.RESIDENTIAL_FREQUENT_CUSTOMER, c.TYPE,
o.ORDER_ID, o.STATUS, o.TOTAL,
l.PRODUCT_ID, l.QUANTITY, l.AMOUNT,
p.PRICE,p.DESCRIPTION
FROM CUSTOMER c
LEFT OUTER JOIN ORDERS o ON c.OPEN_ORDER = o.ORDER_ID
LEFT OUTER JOIN (
LINE_ITEM l JOIN PRODUCT p ON l.PRODUCT_ID = p.PRODUCT_ID
) ON o.ORDER_ID = l.ORDER_ID
WHERE c.CUSTOMER_ID = ${customerId}
";
def typeRow = db.queryFirst(
"SELECT type FROM CUSTOMER c
WHERE c.CUSTOMER_ID = ${customerId}
"
);
AbstractCustomer customer = null;
if(typeRow == null)
throw new CustomerDoesNotExistException();
else if (typeRow.type.equals(CustomerType.RESIDENTAL.toString())) {
customer = db.query(
customerQuery,
new JoinResultHandler(ResidentialCustomer)
).get(0);
else if (typeRow.type.equals(CustomerType.BUSINESS.toString()))
customer = db.query(
customerQuery,
new JoinResultHandler(BusinessCustomer)
).get(0);
else
throw new CustomerDoesNotExistException();
if (customer == null)
throw new CustomerDoesNotExistException();
return customer;
}Using this technique, we must issue an extra query each time we load an object. Another technique is to write your own RowHandler and check the type first as you traverse the ResultSet. We leave this as an exercise to the interested reader using similar techniques as described in the section “Extending the Framework.”
Because pureQuery exposes SQL, you do not need to explicitly create keys; however, pureQuery provides the @Id annotation for use in your POJO class, as shown in Listing 9.31. The pureQuery tools do not make use of it directly, but extensions can make use of it for optimizations. We show an example in the “Relationships” section.
In Project Zero, there is a specialized insert method that extends the pureQuery support for keys. In cases in which tables generate the key, the insert method will return that key to the program. Listing 9.32 shows an example of this.
Example 9.32. Special Insert Method for Project Zero applications
newOrder.setStatus(Order.Status.OPEN.toString()); newOrder.setTotal(new BigDecimal(0)); newOrder.setCustomer(customer); def orderId = db.insert( "INSERT INTO ORDERS (STATUS,TOTAL,CUSTOMER_ID) VALUES ( ${Order.Status.OPEN.toString()}, ${new BigDecimal(0)}, ${customerId} )", ['ORDER_ID'] ); newOrder.setOrderId(orderId.intValue());
You can use the @Column annotation to map attributes to columns. Listing 9.33 shows this pattern.
Example 9.33. @Column
@Table(name="PRODUCT", schema="APP")
public class Product implements Serializable {
private static final long serialVersionUID = 2435504714077372968L;
@Id
@Column(name="PRODUCT_ID")
protected int productId;
@Column(name="PRICE")
protected BigDecimal price;
@Column(name="DESCRIPTION")
protected String description;
//setters and gettersThere is no direct support for contained objects. However, you can easily populate a contained object using a RowHandler.
The pureQuery runtime currently does not support populating an object graph; however, the Project Zero extension does. In Listing 9.34, you can see the use of the special @Join annotation and JoinResultHandler to populate Object graphs from joins.
Example 9.34. @Join
@Table(name="ORDERS")
public class Order implements Serializable {
private static final long serialVersionUID = 7779370942277849463L;
@Id
@Column(name="ORDER_ID")
protected int orderId;
protected BigDecimal total;
public static enum Status { OPEN, SUBMITTED, CLOSED }
protected String status;
protected AbstractCustomer customer;
@Join
protected Set<LineItem> lineitems;After you have defined which fields you want to Join, you can issue a query and pass in the JoinResultHandler, as shown in Listing 9.35. The JoinResultHandler will use the @Id annotation of the related class to determine the foreign key.
Example 9.35. JoinResultHandler
String customerQuery = "
SELECT
c.CUSTOMER_ID, c.NAME, c.BUSINESS_VOLUME_DISCOUNT,
c.BUSINESS_PARTNER, c.BUSINESS_DESCRIPTION,
c.RESIDENTIAL_HOUSEHOLD_SIZE,
c.RESIDENTIAL_FREQUENT_CUSTOMER, c.TYPE,
o.ORDER_ID, o.STATUS, o.TOTAL,
l.PRODUCT_ID, l.QUANTITY, l.AMOUNT,
p.PRICE, p.DESCRIPTION
FROM CUSTOMER c
LEFT OUTER JOIN ORDERS o ON c.OPEN_ORDER = o.ORDER_ID
LEFT OUTER JOIN (
LINE_ITEM l JOIN PRODUCT p ON l.PRODUCT_ID = p.PRODUCT_ID
) ON o.ORDER_ID = l.ORDER_ID
WHERE c.CUSTOMER_ID = ${customerId}
";
AbstractCustomer customer = db.query(
customerQuery,
new JoinResultHandler(ResidentialCustomer)
).get(0);Constraints in a full ORM framework are hints to the persistence framework from metadata specified in various ways. These hints are often used to either (or both) generate application code to enforce the constraints, or to generate DDL with constraints in the underlying datastore. Because you deal directly with SQL in pureQuery and Project Zero, they do not have any special meta data considerations for constraints beyond those already discussed.
Because pureQuery is a gateway framework that exposes the SQL in one or more of your application artifacts, you can get the exact SQL you want. The thinness of the pureQuery Data API is optimized for getting your queries and updates from your application code to the database as efficiently as possible. Therefore, tuning generally involves optimizing the SQL for the exact usage pattern needed in the service operation.
To maximize the maintainability of your applications, we recommend separating any SQL from the business logic that uses it through encapsulation. As you have seen throughout this chapter, pureQuery and Project Zero provide many techniques for this—including through annotations, which enable you to separate the SQL into service interface classes that are then used in your code, or through the use of the XML mapping files to provide the mapping metadata. Either approach is excellent and has its advantages and disadvantages.
In the remainder of this section, we discuss some common approaches used with pureQuery and Project Zero to optimize queries, cache data, load related objects, and handle locking. See Chapter 3 for additional discussion of best practices associated with these design trade-offs.
Using the Annotated method of development, you can choose to generate a static SQL implementation of the services. Using the pureQuery API with the JCC DB2 drivers, the static SQL is stored in the DB2 catalog. Figure 9.8 shows the benefits of using static SQL optimization.
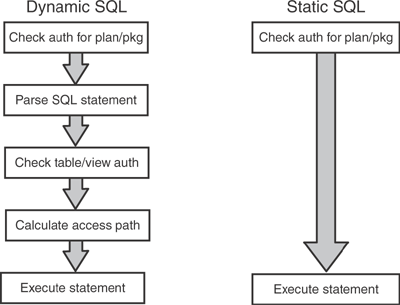
It is worth noting that similar performance enhancements can be achieved with dynamic SQL and a prepared statement cache solution. However, static SQL can be significantly faster because the optimization happens at compile time and can create elaborate plans for processing the associated statements on the database. A PreparedStatement cache for dynamic SQL is somewhat slower, because the plan must be re-created during the first invocation or whenever the cache is invalidated. In addition, the memory requirements in the application and the database to maintain the cache can be significant, especially if there are a huge number of queries to be cached. Table 9.2 gives some more details to consider between static SQL and dynamic SQL.
Table 9.2. Dynamic Versus Static SQL Comparison
Dynamic SQL | Static SQL | |
|---|---|---|
Performance | It is possible to approach static SQL performance with help from dynamic SQL caches. However, cache misses are costly. | All SQL parsing and catalog access is done at BIND time, resulting in fully optimized execution at runtime. |
Access Path Reliability | Any prepare can result in a new access path plan as statistics or host variables change, resulting in nondeterministic performance characteristics, even for queries you may have optimized. | The access path is locked in at BIND time. All SQL is available ahead of time for analysis by EXPLAIN. The result is much more deterministic performance characteristics. |
Authorization | Privileges are handled at object level. All users or groups must have privileges to every table that could be accessed in a Statement, which can either be a security exposure, an administrative burden, or both. | Privileges are based on the Java package in which the SQL appears. Only the DB administrator needs table access. Users and Groups have authority to access a specific package. This makes it easier to administer and to prevent nonauthorized SQL execution. |
Monitoring, Problem Determination | There is no easy way to tell where any particular SQL statement came from in the application, except by manually examining a stack trace. | Knowing the class and package where the SQL originated at compile time makes it simple to record as part of the plan, and track back to the SQL statement location in the application at runtime. |
Capacity Planning, Forecasting | It is difficult to summarize performance data at program level. | The Package Level Accounting feature provides a view of the workload to aid accurate forecasting. |
Tracking Dependent Objects | There is no record of which objects are referenced by a compiled SQL statement. | Object dependencies are registered in database catalog. |
You can use an external cache like ObjectGrid to cache resultsets and write a customer handler. In Project Zero, you can cache data inside the Global Context.
In the relationship section, we showed the use of the @Join annotation to load related objects “eagerly” as part of your query. Judicious use of this feature, balancing it with lazy loading approaches, is important to your application performance.
The purpose of this section is to show how the programming model, ORM mapping, and tuning features come together in the context of the end-to-end development process. This end-to-end view provides a relatively complete picture of how the framework will be used in practice. As stated earlier, pureQuery supports various development modes, each of which will have an impact on the approach to development and deployment. The style you select will determine the artifacts you build and the tooling you use.
pureQuery is probably most productive using a style of development where you drive to the details of the database very quickly (the “endpoints” of the ORM problem associated with design discussed in Chapter 3). Then you think about exploiting the database as efficiently as possible in your application code—akin to the Transaction Script style discussed in Chapter 5. The reason that pureQuery is most productive with this approach is that its Java development environment is strongly integrated with the database you are coding against. Figure 9.9 gives you an example.
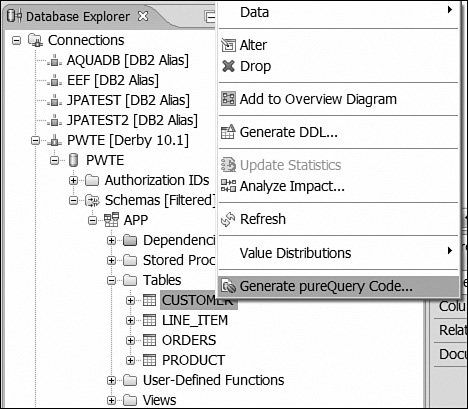
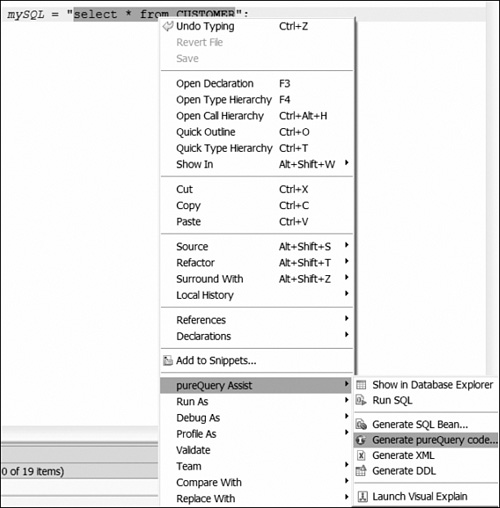
The pureQuery tooling gives you options to generate domain objects, annotated interfaces, and test query methods (using both the Data API and annotated interface). The pureQuery tooling also allows you to migrate existing SQL-based applications into pureQuery applications. You can highlight any SQL and generate annotated interfaces against it, as shown in Figure 9.10.
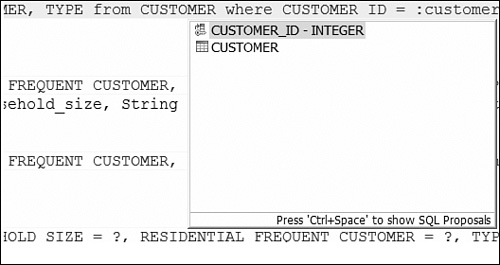
The Java Editors have been enhanced to support SQL assist as well. Figure 9.11 shows an example.
Taken together, the pureQuery tooling greatly increases productivity when you are building database applications.
We chose to implement the common example using the Project Zero platform. The Project Zero platform by default does not utilize some of the pureQuery tools, specifically because Project Zero is based on scripting languages. We will use the same Java Domain Model and Java Interface, but we implemented the service as a Groovy class. The remaining sections discuss how you can use Project Zero on top of pureQuery to define the objects, implement the associated services, package the components, unit test the application, and deploy it to production.
In this section, we show the domain objects in our common example. We have used some of the pureQuery annotations to map attributes to tables. Next, we show our domain objects. The domain objects themselves are still Java objects. At the time we wrote and reviewed the bulk of this chapter, Project Zero was based on Groovy 1.0, so no Java Annotations were available. Project Zero now supports Groovy 1.5, which allows for Java Annotations.
It is worth saying that you may not choose to implement a Domain Model this way in Project Zero because the goal for Web 2.0-based applications is to create RESTful services. Project Zero provides the capability to query directly into JSON objects that can be consumed by AJAX style browser applications. We kept the example the same for the evaluation purposes. We show a short listing of the Zero Resource Model as a “forward look” in the Summary section.
For now, Listing 9.36 shows the AbstractCustomer class. Notice the use of the annotations to substitute names. You will also notice we use the @Join annotation for the current order that will allow a Join statement to populate the object graph correctly.
Example 9.36. AbstractCustomer
@Table(name="CUSTOMER")
public abstract class AbstractCustomer implements Serializable {
@Id
@Column(name="CUSTOMER_ID")
protected int customerId;
@Column(name="NAME")
protected String name;
@Column(name="TYPE")
protected String type;
@Join
protected Order openOrder;
protected Set<Order> orders;
//Insert setters and gettersThe ResidentialCustomer class is shown in Listing 9.37. We annotate the table name to Customer.
Example 9.37. ResidentialCustomer
@Table(name="CUSTOMER")
public class ResidentialCustomer
extends AbstractCustomer implements Serializable {
@Column(name="RESIDENTIAL_HOUSEHOLD_SIZE")
protected short householdSize;
@Column(name="RESIDENTIAL_FREQUENT_CUSTOMER")
protected boolean frequentCustomer;
//Insert setters and gettersSimilarly, Listing 9.38 shows the BusinessCustomer class.
Example 9.38. BusinessCustomer
@Table(name="CUSTOMER")
public class BusinessCustomer
extends AbstractCustomer implements Serializable {
@Column(name="BUSINESS_VOLUME_DISCOUNT")
protected boolean volumeDiscount;
@Column(name="BUSINESS_PARTNER")
protected boolean businessPartner;
@Column(name="BUSINESS_DESCRIPTION")
protected String description;
//Insert setters and gettersThe Order class is shown in Listing 9.39. You will notice we use the @Join annotation for the collection of LineItems. The @Join annotation can be used on collections as well as single valued objects.
Example 9.39. Order
@Table(name="ORDERS")
public class Order implements Serializable {
@Id
@Column(name="ORDER_ID")
protected int orderId;
protected BigDecimal total;
public static enum Status { OPEN, SUBMITTED, CLOSED }
protected String status;
protected AbstractCustomer customer;
@Join
protected Set<LineItem> lineitems;
//Insert setters and gettersThe LineItem object is shown in Listing 9.40. It uses the substitution annotations in the same way as the other objects. It also uses the @Join annotation to load the Product.
Example 9.40. LineItem
@Table(name="LINE_ITEM")
public class LineItem implements Serializable {
@Id
@Column(name="ORDER_ID")
protected int orderId;
@Id
@Column(name="PRODUCT_ID")
protected int productId;
@Column(name="QUANTITY")
protected long quantity;
@Column(name="AMOUNT")
protected BigDecimal amount;
@Join
protected Product product;
//Insert setters and gettersListing 9.41 shows the Product object for our example.
Example 9.41. Product
@Table(name="PRODUCT")
public class Product implements Serializable {
@Id
@Column(name="PRODUCT_ID")
protected int productId;
@Column(name="PRICE")
protected BigDecimal price;
@Column(name="DESCRIPTION")
protected String description;
//Insert setters and gettersThe Service Implementation is a Groovy class that implements the common Java Interface we used throughout the book. The code in Listing 9.42 assumes you have created an instance of the Zero Manager for the class using the configuration shown earlier in Listing 9.3 and code shown in Listing 9.4.
The loadCustomer method uses the data manager to execute the desired SQL. There is some extra logic in that we need to check the type first by issuing a query just for the type to instantiate. We could have implemented a row handler, but the code would have been more complex. Notice we can issue complex SQL. Listing 9.42 shows the example.
Example 9.42. loadCustomer
public AbstractCustomer loadCustomer(int customerId)
throws CustomerDoesNotExistException {
def typeRow = db.queryFirst(
"SELECT type FROM CUSTOMER c WHERE c.CUSTOMER_ID = ${customerId}"
);
String customerQuery =
"SELECT c.CUSTOMER_ID, c.NAME, c.BUSINESS_VOLUME_DISCOUNT,
c.BUSINESS_PARTNER, c.BUSINESS_DESCRIPTION,
c.RESIDENTIAL_HOUSEHOLD_SIZE,
c.RESIDENTIAL_FREQUENT_CUSTOMER, c.TYPE,
o.ORDER_ID, o.STATUS, o.TOTAL,
l.PRODUCT_ID, l.QUANTITY, l.AMOUNT,
p.PRICE, p.DESCRIPTION
FROM CUSTOMER c
LEFT OUTER JOIN ORDERS o ON c.OPEN_ORDER = o.ORDER_ID
LEFT OUTER JOIN (
LINE_ITEM l JOIN PRODUCT p ON l.PRODUCT_ID = p.PRODUCT_ID
) ON o.ORDER_ID = l.ORDER_ID
WHERE c.CUSTOMER_ID = ${customerId}
";
AbstractCustomer customer = null;
if(typeRow == null)
throw new CustomerDoesNotExistException();
else if (typeRow.type.equals(
CustomerType.RESIDENTAL.toString()))
customer = db.query(
customerQuery,
new JoinResultHandler(ResidentialCustomer)
).get(0);
else if (typeRow.type.equals(CustomerType.BUSINESS.toString()))
customer = db.query(
customerQuery,
new JoinResultHandler(BusinessCustomer)
).get(0);
else
throw new CustomerDoesNotExistException();
if (customer == null)
throw new CustomerDoesNotExistException();
return customer;
}The openOrder method executes all code within a Groovy closure for transaction demarcation. Listing 9.43 illustrates again how Groovy GStrings are used as input in a more complete example.
Example 9.43. openOrder
public Order openOrder(int customerId)
throws CustomerDoesNotExistException, OrderAlreadyOpenException {
Order newOrder = new Order();
db.inTransaction
{
AbstractCustomer customer = loadCustomer(customerId);
if (customer.getOpenOrder() != null )
throw new OrderAlreadyOpenException();
newOrder.setStatus(Order.Status.OPEN.toString());
newOrder.setTotal(new BigDecimal(0));
newOrder.setCustomer(customer);
def orderId = db.insert(
"INSERT INTO ORDERS (STATUS,TOTAL,CUSTOMER_ID)
VALUES (
${Order.Status.OPEN.toString()},
${new BigDecimal(0)},${customerId}
)
", ['ORDER_ID']
);
newOrder.setOrderId(orderId.intValue());
db.update(
"UPDATE CUSTOMER SET OPEN_ORDER = ${newOrder.orderId}"
);
}
return newOrder;
}The implementation of the addLineItem service operation first checks to see whether the Product exists using the em.find. It then queries to check whether a LineItem already exists, and updates the quantity if it does. Listing 9.44 shows the relevant code.
Example 9.44. addLineItem
public LineItem addLineItem(
int customerId, int productId, long quantity
)
throws CustomerDoesNotExistException,
OrderNotOpenException,InvalidQuantityException,
ProductDoesNotExistException {
if(quantity <= 0 ) throw new InvalidQuantityException();
LineItem li = null;
db.inTransaction
{
Product product = db.queryFirst(
"select * from Product where product_id = ${productId}",
Product.class
);
if(product == null) throw new ProductDoesNotExistException();
AbstractCustomer customer = loadCustomer(customerId);
Order openOrder = customer.getOpenOrder();
if (openOrder == null) throw new OrderNotOpenException();
BigDecimal amount = product.getPrice().multiply(
new BigDecimal(quantity)
);
db.update(
"UPDATE ORDERS SET
TOTAL = ${amount.add(openOrder.getTotal())}"
);
LineItem el = db.queryFirst(
"select * from LINE_ITEM
where ORDER_ID = ${openOrder.orderId} and
PRODUCT_ID = ${productId}
", LineItem.class
);
if(el == null)
{
LineItem lineItem = new LineItem();
lineItem.setOrderId(openOrder.getOrderId());
lineItem.setProductId(product.getProductId());
lineItem.setAmount(amount);
lineItem.setProduct(product);
lineItem.setQuantity(quantity);
db.update(
"INSERT INTO LINE_ITEM (
ORDER_ID,PRODUCT_ID, amount, quantity)
VALUES (
${lineItem.orderId}, ${lineItem.productId},
${lineItem.amount}, ${lineItem.quantity})"
);
li = lineItem;
}
else {
el.setQuantity(el.getQuantity()+ quantity);
el.setAmount(el.getAmount().add(amount));
db.update(
"UPDATE LINE_ITEM SET
quantity = ${el.getQuantity()},
amount = ${el.getAmount()}"
);
li = el;
}
}
return li;
}This service implementation simply issues a delete in the context of an inTransaction, as shown in Listing 9.45.
Example 9.45. removeLineItem
public void removeLineItem(int customerId,int productId )
throws CustomerDoesNotExistException, OrderNotOpenException,
ProductDoesNotExistException, NoLineItemsException,
GeneralPersistenceException {
db.inTransaction
{
Product product = db.queryFirst(
"select * from Product
where product_id = ${productId} ", Product.class
);
if(product == null) throw new ProductDoesNotExistException();
AbstractCustomer customer = loadCustomer(customerId);
Order openOrder = customer.getOpenOrder();
if (openOrder == null) throw new OrderNotOpenException();
db.update(
"DELETE FROM LINE_ITEM
WHERE PRODUCT_ID = ${productId} AND
ORDER_ID = ${customer.openOrder.orderId}"
);
}
}This service method changes the status of the order and removes it from the openOrder property of the abstract customer class. Listing 9.46 shows the implementation.
Example 9.46. submitOrder
public void submit(int customerId)
throws CustomerDoesNotExistException,
OrderNotOpenException, NoLineItemsException {
db.inTransaction
{
AbstractCustomer customer = loadCustomer(customerId);
Order openOrder = customer.getOpenOrder();
if (openOrder == null) throw new OrderNotOpenException();
if (openOrder.getLineitems() == null ||
openOrder.getLineitems().size() <= 0)
throw new NoLineItemsException();
db.update(
"UPDATE ORDERS
SET STATUS = ${Order.Status.SUBMITTED.toString()}
where ORDER_ID = ${openOrder.orderId}"
);
db.update("UPDATE CUSTOMER SET OPEN_ORDER = NULL");
};
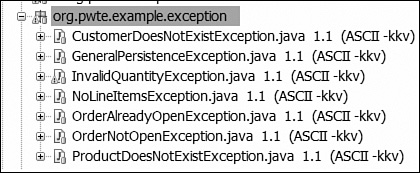
}Figure 9.12 shows the common exceptions. You can examine them in code form from the download.
Project Zero applications have a particular layout for their directory structure. This layout provides organization around the parts that make up your application and convention around how your application works. If you follow the conventions and structure defined by Project Zero, your application will be easier to construct and maintain, and you will have less configuration information to provide with the application. Figure 9.13 shows the basic layout of a Project Zero Module and folder structure. The Project Zero Website has a section explaining the complete details [Zero 7].
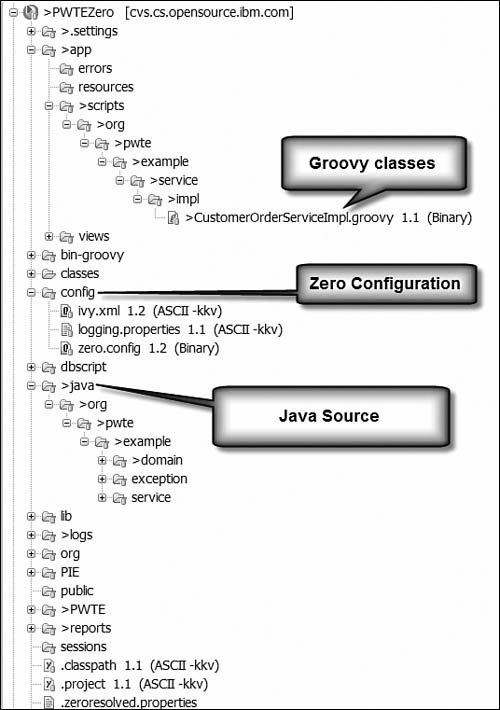
In the config directory, you will find an ivy.xml file. Ivy is a build system from Apache that can ensure your application is using the right versions of the libraries you declare as dependencies in the config file. In Ivy, these libraries are called modules. A module represents an artifact, which is code packaged as either a JAR file or a Zero ZIP file. Zero then uses Ivy to find a module that matches each dependency you declared. Ivy can search the local repository that Zero creates on your system, or it can search remote repositories such as the Project Zero package repository. When a match is found, Ivy downloads the module’s artifact into your local repository as necessary and updates your application’s classpath to include the dependency. For more information on Ivy, see [Ivy]. Listing 9.47 shows the ivy.xml file for our example where we specify Zero packages and database drivers.
Example 9.47. ivy.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <ivy-module version="1.3"> ... <!--removed package info in text--> <dependencies> <dependency name="zero.core.webtools" org="zero" rev="1.0+"/> <dependency name="zero.core" org="zero" rev="1.0+"/> <dependency name="commons-dbcp" org="commons-dbcp" rev="1.2.1"/> <dependency name="commons-logging" org="commons-logging" rev="1.0.4"/> <dependency name="commons-pool" org="commons-pool" rev="1.3"/> <dependency name="derbyclient" org="org.apache.derby" rev="10.2.2+"/> <dependency name="zero.data" org="zero" rev="1.0+"/> <dependency name="junit" org="junit" rev="4.1"/> <dependency name="ant" org="ant" rev="1.6.5"/> </dependencies> </ivy-module>
The other important configuration file is zero.config, which contains runtime properties stored in the Global Context. Listing 9.48 shows the zero.config we use to define the DataSource that the Zero Manager will use—it should look familiar to you as it is nearly identical to Listing 9.3.
Example 9.48. zero.config
# HTTP port (default is 8080) [/app/http] port=8080 # This config is for Apache Derby databases: [/app/db/pie/config] class=org.apache.derby.jdbc.ClientDataSource serverName=localhost portNumber=1527 databaseName=PWTE connectionAttributes=create=true
We created a separate Project Zero application with specialized unit testing in a Web 2.0 environment. The Unit Test Project includes our application via the ivy.xml file. Figure 9.14 shows the layout of the Unit Test Zero application.

The source for our unit test is implemented in Groovy. It is the same common unit test we used to test the other frameworks examined in this book, except we used the Groovy extensions to JUnit instead of Java. Examine the downloadable source for details (see Appendix A, “Setting Up the Common Example”).
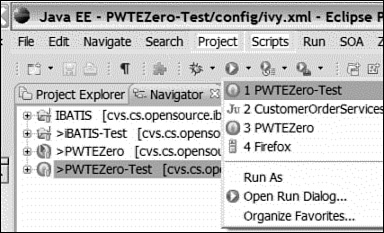
The Project Zero applications execute in a standalone VM. The goal is to just run the application. For testing, you can right-click on any Zero Project and run it as illustrated in Figure 9.15. In our case, you run the Unit Test Project, which in itself is a Project Zero application. As stated earlier, you can include Zero packages inside of another.
The persistence layer of a Project Zero application does not have any extra considerations for deployment. The Project Zero architecture allows you to override configurations, so you can provide an override for the Data Source definition as part of your deployment process.
The Project Zero tooling allows you to export applications to be copied for deployment.
You would use the command-line tools for Project Zero to run the application. As a matter of fact, Project Zero allows for pure command-line development of applications as well. The deployment process would just involve running the application using the command-line tools. See the Project Zero developer guide for how to use the command line features [Zero 8].
This chapter showed how pureQuery technology is optimized for SQL-based development; and how your ability to exploit its tooling may make it well worth choosing pureQuery over straight JDBC or other Table Gateway type frameworks like iBATIS. We also discussed its tight integration with IBM databases so that if you prefer to use an ORM-based framework, especially with an IBM database as the platform of choice, choosing one that is built on top of pureQuery may be your best solution. As concrete examples of this, we showed how the JPA provider could exploit the option to precompile your mapping to generate underlying static SQL. IBM’s JPA provider based on OpenJPA is being enhanced to support this feature.
In addition, if you need to move beyond the Enterprise into Web 2.0-based development, using pureQuery in the context of Project Zero may be ideal. We showed you a brief preview of Project Zero using pureQuery to execute the SQL needed to persist objects in the context of applications written in the Groovy scripting language.
We also discussed how pureQuery is in its initial release and the IBM Data Tools continue to evolve to support the full SOA life cycle.
We discussed how Project Zero is evolving, as well. We examined Milestone 1 in detail, and touched on how Milestone 2 and beyond of Project Zero detailed in the website introduces the Zero Resource Model [Zero 9] for mapping database data to RESTful services. As a “sneak peek” of this future state (subject to change, of course), you can define a model as shown in Listing 9.49 in a file named customer.groovy within a folder called /app/models.
A developer would be able to invoke a RESTful service directly through an HTTP request, or invoke it programmatically from applications written in other languages.
This sneak peek illustrates one of the most important aspects of Project Zero that we covered—its pioneering use of Community-Driven Commercial Development (CD2), where you can follow the progress and provide your input to impact the future direction. The end-goal of developing Project Zero on top of pureQuery is that you can generate fully functional web services around optimized SQL with minimal steps to meet your enterprise requirements now and in the future.
A.9.1 | Overview of pureQuery Tools |
General overview of the pureQuery tools | |
www.ibm.com/developerworks/db2/library/techarticle/dm-0709surange/ | |
A.9.2 | pureQuery: IBM’s New Paradigm for Writing Java Database Applications |
General introduction to pureQuery. | |
www.ibm.com/developerworks/db2/library/techarticle/dm-0708ahadian/ | |
A.9.3 | Detect and Fix SQL Problems Inside Java Program |
Article showing how to use the pureQuery tools to detect SQL problems with your application | |
www.ibm.com/developerworks/db2/library/techarticle/dm-0709surange2/ | |
A.9.4 | Building RESTful Services for Your Web Application with Project Zero |
Tutorial on Project Zero showing Data APIs in Action | |
A.9.5 | RESTful applications in an SOA |
Part 2 of tutorial on Project Zero showing Data APIs and ZRM in Action | |
A.9.6 | Use Project Zero’s Data Access APIs to Build a Simple Wiki |
An article illustrating the data access API’s in Project Zero in the context of building a Wiki. | |