
It has taken a lot of persistence (in the “perseverance” sense of the term) for you to get to this chapter. Congratulations!
So you should know by now that this book has been all about asking and then answering common questions that you may encounter when deciding which persistence mechanism to use in a given application development project.
Having reached this point, we find that the most common question we are asked is “What do I do now?” In other words, how do you put the theory of the first four chapters and the knowledge contained in the detailed evaluations of the next five chapters into practice?
Answering that question is the purpose of this final chapter.
Now that you have seen each framework in isolation, how do they stack up together? Let us briefly summarize each section of the questionnaire into a table (see Table 10.1 through Table 10.6) for easy reference and, as described in Chapter 4, “Evaluating Your Options,” for an apples-to-apples comparison. For details on the meaning of each, see the related evaluations in Chapters 5 through 9.
Table 10.2. Architectural Overview at a Glance
JDBC | iBATIS | Hibernate Core | Open JPA | pureQuery | |
|---|---|---|---|---|---|
Standards Supported | JDBC 1.2, 3.0, 4.0 | None | None | JPA 1.0; EJB 3.0 | None |
(Hibernate JPA, JPA 1.0) | |||||
Minimum Platform | JSE | JSE | JSE | JSE | JSE |
Dependencies | JDBC Driver | JDBC Driver Several Apache Projects shipped with product. | JDBC Driver Several Apache Projects shipped with product. | JDBC Driver Several Apache Projects shipped with product. | JDBC Driver, JCC Driver for enhanced performance |
Vendors | Many | Apache | JBoss | BEA, IBM | IBM |
Licenses | Many | Apache | LGPL | Apache | IBM |
Table 10.3. Programming Model at a Glance
JDBC | iBATIS | Hibernate Core | Open JPA | pureQuery | |
|---|---|---|---|---|---|
Initialization | DriverManager DataSource | SQLMap | Session Factory | Entity Manager Factory | Data Factory Interface |
Injection inside EJB 3 Container | |||||
Connection | Connection | SQLMap Instance | Session | Entity Manager | Data |
Transactions |
|
| JDBC, JTA API, EJB CMT | Entity Transaction JTA, EJB CMT | Data Interface demarcation, JTA, EJB CMT |
Create | SQL insert | SQL insert | HQL insert, getters, Native SQL, Criteria, | getters, | SQL insert |
Retrieve | SQL select | SQL select | HQL select, HQL from clause, getters, Native SQL select, Criteria API, | EJB-QL select, assessors, Native, | SQL select |
Update | SQL update | SQL update | HQL Update, setter, Native SQL, Criteria, | EJB-QL UPDATE, getter, Native SQL Update, | SQL update |
Delete | SQL delete | SQL delete | HQL, assessors, Native SQL, Criteria | EJB-QL, assessors, Native | SQL delete |
Stored Procedures | SQL Callable Interface | Stored procedure tags | Native SQL | Native SQL | SQL Callable Annotation and API |
Batch | Batch statements | Batch statements | Insert, Update, Delete batching | Update, Delete Catching, ISome vendors Tx Batching | Batch Statements |
Extension Points | Driver implementations | Cache, types | Cache, types | Cache, types | Scripting, cache, types |
Error Handling | Checked SQLException or subclass | Checked SQL Exception or subclass | Unchecked Hibernate Exception | Unchecked Exceptions | Unchecked DataRuntime Exception |
Table 10.4. ORM Features Supported at a Glance
JDBC | iBATIS | Hibernate Core | Open JPA | pureQuery | |
|---|---|---|---|---|---|
Objects | Row | POJO to SQL in SQLMap | POJO to Domain in XML (JPA annotations supported) | JPA annotations or XML | Integrated query, annotation, or XML |
Inheritance | Simulated via root-leaf and union tables | Custom | Single Table, Concrete subclass, Full inheritance chain | Single Table, Concrete subclass, Full inheritance chain | Custom |
Keys | ROW_ID retrieval in JDBC 4.0 | Key retrieval through | Supported for generated key and automatic retrieval, composite | Supported for generated key and automatic retrieval, composite | Custom, ROW_ID retrieval |
Attributes | Columns | Setters/getters | XML or annotation | XML or annotation | XML or annotation |
Contained Objects | Limited types, Custom assembled columns | Support for populating graph from SQL | Component (including collections) | Embeddable Objects | Custom |
Relationships | Foreign keys, association tables | Support for Join to Object Graph | 1-to-1, 1-to-Many, Many-to-Many, uni- and bidirectional, Secondary Table | 1-to-1, 1-to-Many, Many-to-Many, uni- and bidirectional, Secondary Table | Partial support for Join to Object Graph |
Constraints | Limited, e.g., Null, Not Null, Unique | DB | In ORM and DB | In ORM and DB | DB |
Derived Attributes | Limited, e.g., | Custom | Life cycle | Life cycle | Custom |
Table 10.5. Tuning Options at a Glance
JDBC | iBATIS | Hibernate Core | Open JPA | pureQuery | |
|---|---|---|---|---|---|
Query Optimizations | Manual | Manual | Lazy or eager columns | Lazy or eager columns | Manual |
Caching | Manual | Support to cache results, plug-in third-party caches | Support to cache objects and results, plug-in third-party caches | Support to cache objects and results, plug-in third-party caches | Support to cache results, plug-in third-party caches |
Loading Related Objects | Manual with Join | Manual with Join | Eager or lazy relationships | Eager or lazy relationships | Manual with Join |
Locking | Isolation Levels | Isolation Levels | Isolation Levels, Lock API, Version Number support | Isolation Levels, Lock API, Version Number support | Isolation Levels |
Table 10.6. Development Process at a Glance
JDBC | iBATIS | Hibernate Core | Open JPA | pureQuery | |
|---|---|---|---|---|---|
Defining the Objects | Create POJO | Create POJO and SQLMap | Create POJO and Hibernate Mapping files | Create POJO with annotations, or POJO with XML | Create POJO with annotations, and execute in SQL |
Implementing the Services | Code using APIs | Code using SQLMap | Code using Session | Code using the Entity Manger | Special Service Annotation for SQL generation or use of Data API |
Packaging the Components | Bytecode enhancement for lazy loading | Bytecode enhancement | Precompile options for static SQL |
As we have done before in this book, let us start with what not to do in order to better motivate you for what you should do.
Chapters 5 through 9 and the summary tables in the previous sections explore the details of JDBC, iBATIS, Hibernate Core, OpenJPA, and pureQuery within the context of our questionnaire. Within this context, you can see that each mechanism has its strengths and weaknesses. In other words, none is perfect for every situation; so you will likely have to make trade-offs for whichever mechanism you choose. For example:
JDBC is good for applications in which the queries are dynamic and you need programmatic control of various tuning features to maximize performance. However, as the coding examples show, JDBC is relatively complex to use because you have to code the persistence logic yourself.
iBATIS does a great job of insulating your object programmers from the details of JDBC and SQL by providing some ORM functions and keeping the SQL in a separate config file—especially applications that are based heavily on Stored Procedures or well-architected SQL from a DBA. However, if you prefer not to explicitly code SQL or if your domain objects have a complex life cycle, then iBATIS is not likely the best choice for you.
Hibernate Core has a much more advanced ORM layer and has served as the basis for the new JPA standard; however, developers should begin to use the Hibernate JPA APIs if standards are important. Also, if you are using the JBoss Application Server, using Hibernate Core is a natural choice.
OpenJPA, like Hibernate, has an excellent ORM layer that lets your Java programmers think in object terms. It has the additional advantage of being based on an industry standard and the capability to annotate the code and forgo the need for a mapping XML. ISVs may find the Apache license a better option for shipping software solutions based on OpenJPA. In addition, if you are using the WebSphere Application Server or WebLogic Server, using the OpenJPA-based runtime shipped with their container makes the most sense.
pureQuery enables relational queries to be embedded in the Java code itself; however, it is relatively new as of publication and may undergo a number of changes that could impact code you write today. That said, it can have major advantages from a performance and tracing standpoint, especially if using DB2. Furthermore, pureQuery can be used in other types of environments, such as Web 2.0-based environments. Like iBATIS, applications that are based heavily on stored procedures or SQL written by a separate role such as a DBA should consider pureQuery as well. It is also worth noting that another persistence mechanism, such as the Groovy API’s in Project Zero, may choose to implement on top of the pureQuery engine to exploit the performance and management features.
Some architects will not be willing to make the trade-offs associated with each of these mechanisms and will instead use this knowledge as an excuse to invent their own persistence framework exactly tailored to their requirements. Although inventing your own persistence layer can be fun, especially for architects with a strong computing science background, we advise against doing so because it puts your programmers in the middleware business instead of developing mission-critical enterprise applications.
Why is this? Because it may seem relatively simple to develop a framework on top of a mechanism such as JDBC, but the runtime aspects of such a framework are only the tip of the iceberg. Very quickly, you will find yourself having to develop a number of tools to support other aspects of the application such as:
Analysis, design, coding, and unit testing of each component
Configuration and assembly of an end-to-end functional application
Functional verification testing and debugging
Deployment into system test or production environments
Operations, including admin, monitoring, problem determination, and tuning
Further, if you build your own homegrown framework, you must also write documentation and create training programs for each of these tools geared toward the roles that use them. The reality is that the need to support your framework with tooling, documentation, and training will totally consume the resources of your team, leaving them no time to build any enterprise applications.
Invariably your requirements will change as user expectations and underlying technologies change, leaving you in the same situation you are in now—needing to understand how to make hard choices and real trade-offs among existing mechanisms.
If after understanding the challenges you still find yourself tempted to build your own proprietary persistence mechanism, we recommend that you keep in mind the overarching goals of any framework, whether used for providing persistence or another major aspect of the solution architecture:
Less skill required to build solutions through separating the concerns
Higher quality solutions through reuse of assets and best practices
Faster development times through tooling that targets the roles involved
We also recommend that you use the template developed in Chapter 4 as a guide to the questions you must be prepared to answer. In other words, reuse the questionnaire as an outline of your requirements, and fill in the details of each section the way you imagine your framework will be.
Our hope is that this exercise will lead you back to choosing an existing mechanism instead of building one yourself. But with that said, there may come a time when you must do some invention to meet specific project requirements that cannot be met in any other way.
In this case, we strongly recommend that you exploit an open-source community project like iBATIS or OpenJPA and extend it only as much as is needed for your project. This approach will let you piggyback on the skills and supporting tools developed by the community—including vendors who have embraced the project and any associated standards.
Assuming you take our advice to focus on the business applications that support your enterprise, you can submit your extensions back to the open-source community so that you aren’t stuck supporting them. You will be surprised at how quickly runtime components and associated tools and documentation you never dreamed of will emerge from the collective wisdom of the open-source community.
Exploiting the open-source community is one way to embrace change rather than trying to insulate your team from it. You can design your development processes to embrace change as well. We have found that agile approaches are best because they focus your attention on the practical problems that need to be solved during development of small but essential “increments” of application functions.
Agile incremental approaches fit well with our philosophy to “think before you act—just don’t do all of your thinking before acting.” That is, you should analyze the requirements before you design a solution, and then code, test, and deploy the application components; however, you should not do all the analysis, then design the entire solution, and then code the entire application before you test it on your users.
Although it is not the intent of this book to be a definitive guide for agile methods, Figure 10.1, a graphic from the Rational Unified Process (RUP), shows how a disciplined software engineering method (thinking before you act) can work together with an agile approach (not doing all of your thinking before acting).
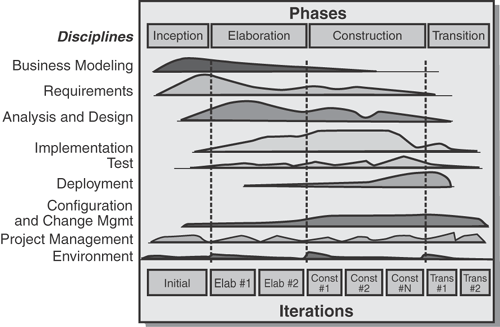
See the excellent IBM Press book on RUP by Joshua Barnes for more details [RUP]; however, the basic idea is that you use all the disciplines (shown as rows in Figure 10.1) to some extent or another in every phase (shown as columns)—each of which represents a project in its own right. And each phase can have a number of smaller, possibly overlapping increments to further break down the deliverable units. The graphs shown in each row indicate the amount of effort devoted to that discipline within that phase or iteration. So, for example, in the early inception phase, which is all about trying to prove the feasibility of the project, you will see more focus on modeling the business processes being supported and their requirements, but with enough analysis, design, implementation, test, and deployment to understand the end-to-end process.
The benefit of an agile approach like RUP boils down to early and often validation, which leads to refactoring the application components into better and better solutions before inertia sets in to your design and makes it nearly impossible to change.
Here is how we have applied RUP to meeting enterprise persistence requirements:
Establish project constraints. Scope a release to support some essential business processes. Chapter 2, “High-Level Requirements and Persistence,” serves as a good guide to capture the high-level functional and quality-of-service requirements you are intending to meet.
Identify representative use cases. Pick some use cases out of the complete list that are indicative of the points of variability within the architecture, and then model them in detail. Chapter 3, “Designing Persistent Object Services,” will help here. Use these requirements to customize your questionnaire for evaluation; we recommend starting with the one provided in Chapter 4. (See the Download site for an electronic version that you can edit.)
Develop candidate architectures. Design, implement, and test solutions for those use cases using one or more of the mechanisms that best fit the requirements. For a real project we would go a step beyond the unit tests described in Chapters 5 through 9, and actually “stress” test these candidates in as close to a real production environment as possible. (See the Download site for code you can use as a starting point and Appendix A for instructions on setup and executing the test cases in an Eclipse environment.)
Customize the development process. Based on the results (which may result in more than one choice of mechanism depending on the use case requirements), create an architecture “cookbook” for each representative use case that your team can use in later phases to develop the remaining use cases of that “type.” You should test this cookbook on a “typical” team of developers in order to validate that you can get the same results as you did with the lead architects who designed the solution, possibly with process assist tools developed with the Rational Method Composer [A.10.1].
A.10.1
Also consider using the new “pattern authoring tools,” such as the new extended Java Emitter Template (JET) engine to build code generators based on your designs (see the excellent developerWorks article by Chris Gerken and Roland Barcia [A.10.2] for details). You can read more about JET at the associated website [JET].
A.10.2
We like to do these steps as early in the process as possible—such as during the inception phase (although they apply to any phase). Figure 10.2 shows these steps graphically.
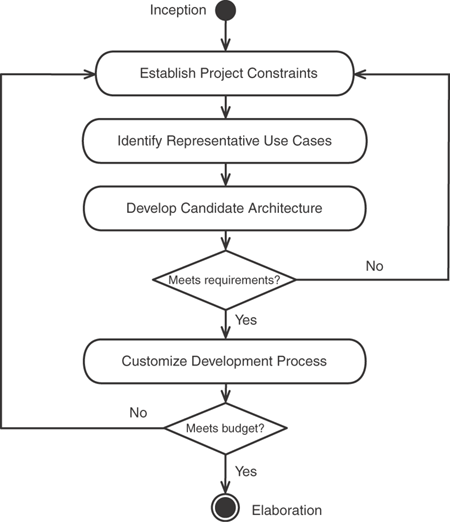
This approach ensures that you meet the IT requirements associated with persistence before you invest too much time in a particular “pattern.”
We also recommend that you document your decisions as you make them so that (a) you do not continually have the same discussions over and over again, and (b) you can more easily determine the impact of changing your mind or refactoring the design by understanding the dependencies between decisions. Minimally, we like to capture the following aspects of each decision (again, listed as a set of questions that need to be answered for those who follow you):
Issue—. What is the problem you were trying to solve?
Context—. Where in the architecture does this issue come up? What were the assumptions?
Forces—. What are the functional and nonfunctional requirements that will drive the decision?
Alternatives—. What approaches did you consider? How do they solve the issue? What were the pros and cons of each, taking into account the context and forces?
Decision—. What was your decision and why?
Related issues—. Based on your decision, what other issues come up that are dependent on this one?
Within the context of persistence in the enterprise and this book, Chapter 4 documents the general set of forces we like to consider (with Chapters 1-3 providing the background); and Chapters 5 through 9 give you a good head start on the alternatives to consider, as well as details on how they solve the problem. Your specific project requirements add to the context and forces and will enable you to enumerate the pros and cons and make your decision. Documenting these decisions and dependencies will help you retrace only the steps necessary when and if you change your mind.
A journey of 1,000 miles begins with the first step. And though it may seem like you have come 1,000 miles already, the journey has really just begun. Our hope is to have given you the right mix of abstract theory and concrete examples so that you can put these principles into practice.
Specifically, this book has done the following:
Recounted a brief history of object-relational mapping approaches that positioned the leading Java persistence mechanisms with respect to those that have been used to develop successful enterprise solutions in the past.
Explored the high-level requirements of enterprise applications and how they drive the need for persistence of data and object-relational mapping.
Explored how domain modeling can be used to capture the detailed design and introduced a hypothetical Order Management application to illustrate the three basic ORM approaches.
Introduced a method for an “apples to apples” comparison of persistence mechanisms based on a questionnaire derived from these enterprise requirements and a common example.
Analyzed five popular Java persistence mechanisms in the context of this questionnaire—both to give you a fish for today and to teach you how to fish for tomorrow.
Hopefully, we have asked and answered enough of the typical questions and provided enough “escape valves” for embracing change that you feel confident enough to take the next step on your own.
And finally, we sincerely wish you luck in your adventures in providing persistence within the enterprise—one step at a time.
Rational Method Composer, Part 1: Key Concepts | |
This first of a series by Peter Haumer describes the basics of the Rational Method Composer. | |
www-128.ibm.com/developerworks/rational/library/dec05/haumer/index.html |
A.10.2 | Get Started with Model Driven Development using the Design Pattern Toolkit |
This excellent two part series on how to use the Design Pattern Toolkit to make Model Driven Development a practical reality was authored by Chris Gerken, the primary inventor of DPTK, and Roland Barcia, one of the authors of this book. | |
Part 1: www.ibm.com/developerworks/websphere/techjournal/0607_barcia/0607_barcia.html | |
Part 2: www.ibm.com/developerworks/websphere/techjournal/0610_barcia/0610_barcia.html |